2025 年的互联网可以说是“野性满满”——你在网上看到的一半流量,其实都不是人类在访问。没错,现在超过 50% 的网络活动都来自机器人和爬虫(),而真正“有用”的机器人(比如搜索引擎、社交媒体预览、数据分析助手)其实只占很小一部分。剩下的那些?说白了,很多根本不是来帮忙的。作为一个长期在 做自动化和 AI 工具开发的工程师,我太清楚一个爬虫的好坏,能直接影响你的 SEO 排名、数据分析的准确性、带宽消耗,甚至可能带来安全隐患。
不管你是企业老板、网站管理员,还是想守护自己数字资产的普通人,搞清楚“谁”在访问你的服务器,比以往任何时候都更重要。所以我整理了这份 2025 年最全爬虫指南,帮你认清主流爬虫、了解它们的行为特征,还会教你怎么让好爬虫畅通无阻,同时有效拦截那些不怀好意的机器人。
什么样的爬虫算“已知”?User-Agent、IP 和验证方式
先来点基础知识:什么叫“已知”爬虫?简单说,就是那些会用固定 User-Agent(比如 Googlebot/2.1 或 bingbot/2.0)主动表明身份,并且(理想情况下)来自官方公布的 IP 段或 ASN(自治系统号),你可以通过官方文档或工具验证()。像 Google、Microsoft、百度、Yandex、DuckDuckGo 这些主流厂商都会公开爬虫信息,甚至直接给出 JSON 文件列出官方 IP(、、)。
但问题来了:只看 User-Agent 并不靠谱。伪造 User-Agent 的现象太常见了,很多恶意爬虫会假装自己是 Googlebot 或 Bingbot 混进你的防线()。所以,最稳妥的做法是双重验证:既要查 User-Agent,也要核对 IP 或 ASN(可以用反向 DNS 或官方列表)。如果你用 这类工具,可以自动化完成日志提取、User-Agent 匹配、IP 交叉验证,实时生成靠谱的爬虫名单。
如何用爬虫列表?
拿到一份“已知爬虫”名单,具体能干啥?我的建议如下:
- 白名单管理: 确保你想要的爬虫(比如搜索引擎、社交媒体预览)不会被防火墙、CDN 或 WAF 误拦。用官方 IP 和 User-Agent 精准设置白名单。
- 分析过滤: 做数据分析时把爬虫流量剔除,让你的访问数据只反映真实用户,而不是 Googlebot、AhrefsBot 这些爬虫刷出来的假流量()。
- 爬虫管理: 针对激进的 SEO 工具设置抓取延迟或限速,对未知或恶意爬虫直接拦截或挑战。
- 自动化日志分析: 借助 AI 工具(比如 Thunderbit)自动提取、分类、标记日志里的爬虫行为,及时发现趋势、识别伪装者,动态调整安全策略。
维护爬虫名单不是“一劳永逸”的事。新爬虫不断冒出来,老爬虫的行为也会变,攻击者的手法年年翻新。用 Thunderbit 自动抓取官方文档或 GitHub 仓库,能帮你省下不少时间和精力。
1. Thunderbit:AI 驱动的爬虫识别与数据管理
不只是 AI 网页爬虫,更是团队级的数据助手,帮你洞察和管理爬虫流量。它的独特优势包括:

- 语义级预处理: Thunderbit 在提取数据前,会把网页和日志转成 Markdown 风格的结构化内容。AI 能真正理解上下文、字段和逻辑,特别适合处理复杂、动态或大量 JS 的页面(比如 Facebook Marketplace 或长评论区),传统爬虫经常搞不定。
- 双重验证: Thunderbit 能自动收集主流爬虫的官方 IP 文档和 ASN 列表,并和你的服务器日志比对,生成“可信爬虫白名单”,不用你手动核查。
- 自动日志提取: 只要上传原始日志,Thunderbit 就能自动生成结构化表格(Excel、Sheets、Airtable),标记高频访问者、可疑路径和已知爬虫。你还可以把结果对接到 WAF 或 CDN,实现自动拦截、限速或验证码挑战。
- 合规与审计: Thunderbit 的语义提取过程自带清晰的审计链路——谁、什么时候、怎么访问了什么,方便应对 GDPR、CCPA 等合规需求。
很多团队用上 Thunderbit 后,爬虫管理的工作量直接减少了 80%,终于能分清哪些爬虫是帮手,哪些是麻烦,哪些又是假冒伪劣。
2. Googlebot:搜索引擎的标杆
是网页爬虫的“黄金标准”,负责为 Google 搜索建立索引——如果你屏蔽了它,等于给自己的网站挂上了“暂停营业”的牌子。
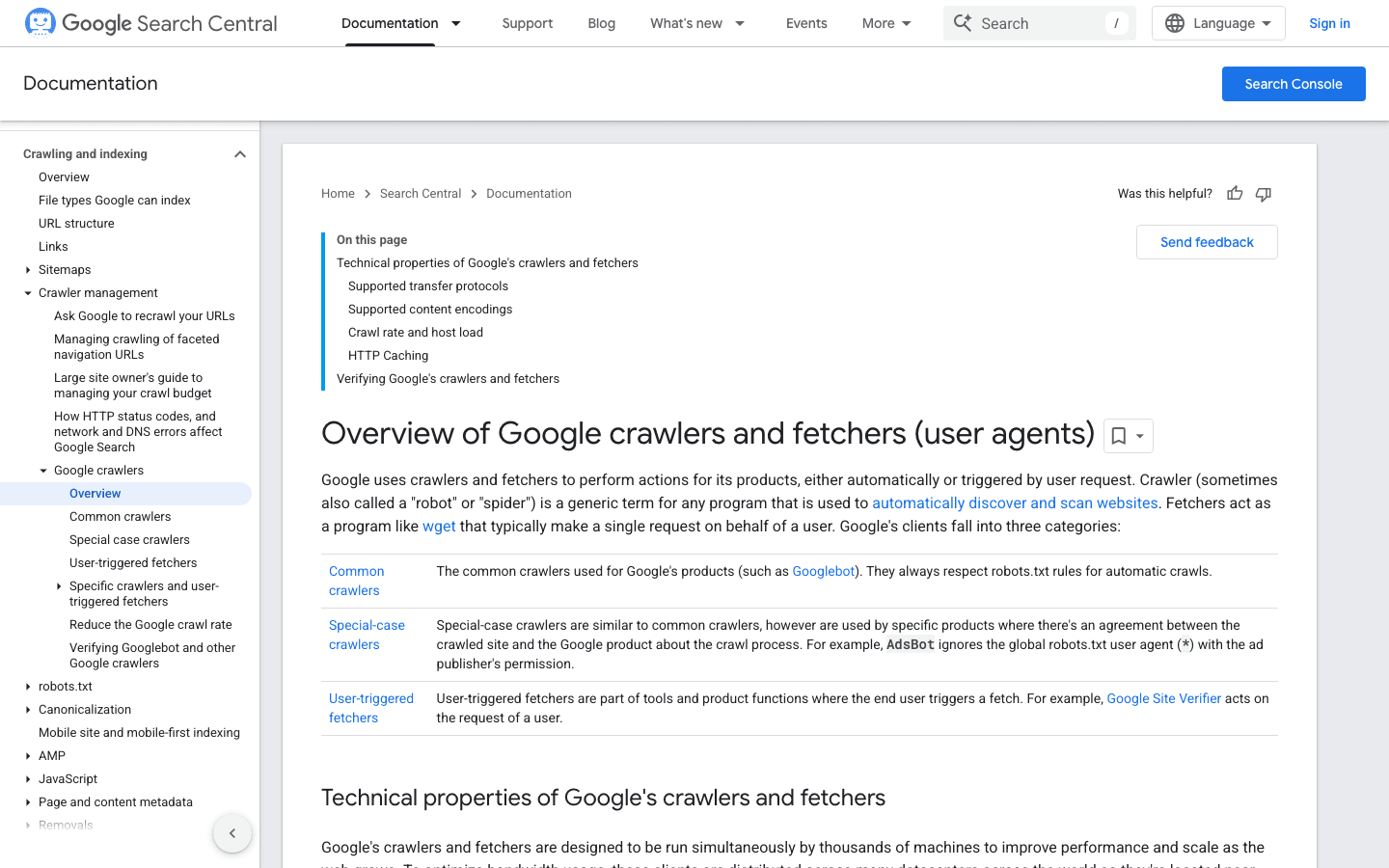
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - 验证方式: 用 或 。
- 管理建议: 永远允许 Googlebot 访问。用 robots.txt 指导(而不是屏蔽)它的抓取行为,必要时可以在 Google Search Console 调整抓取频率。
3. Bingbot:微软的网页探索者
支持 Bing 和 Yahoo 的搜索结果,是大多数网站仅次于 Googlebot 的重要爬虫。
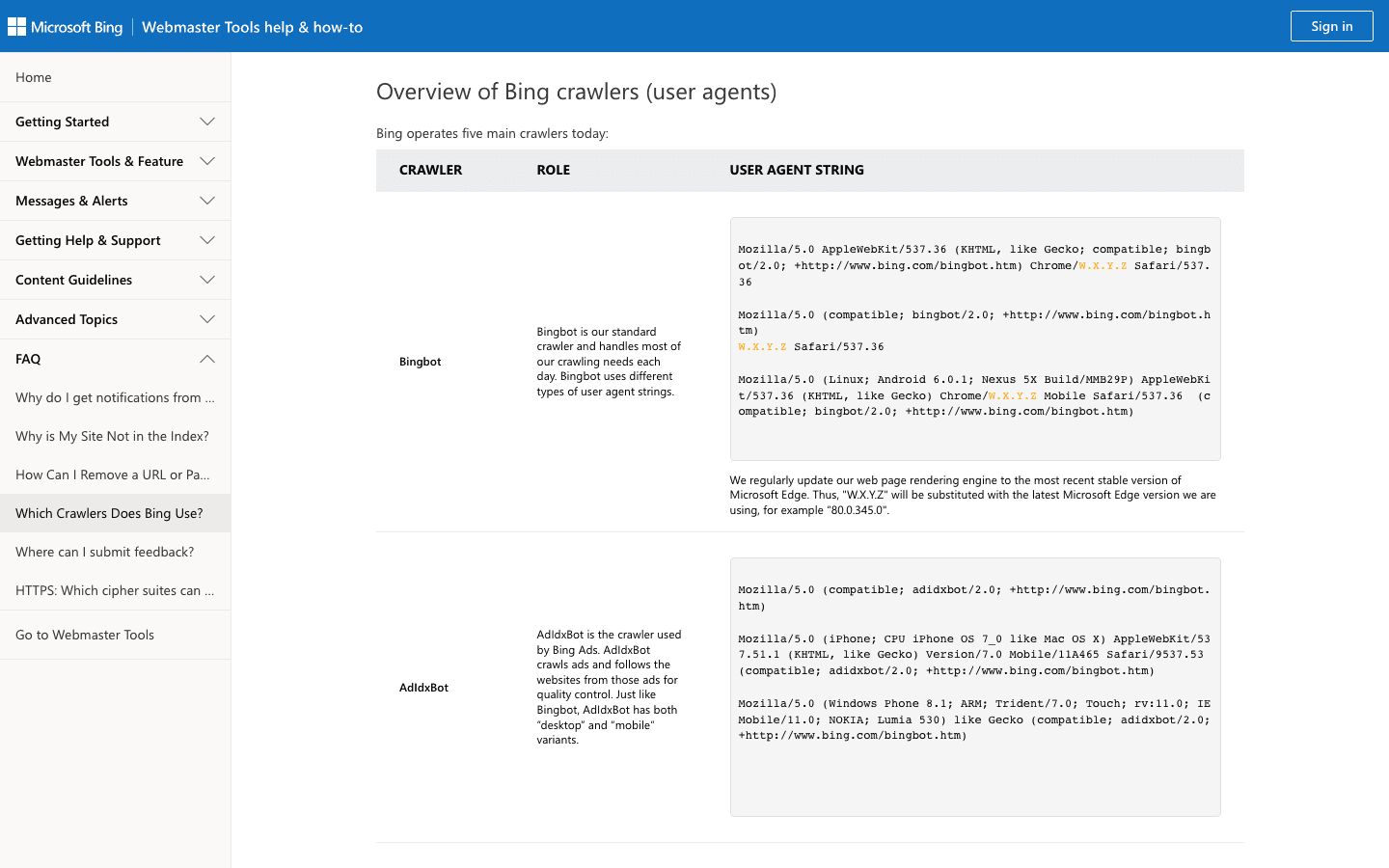
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - 验证方式: 用 和 。
- 管理建议: 允许 Bingbot 访问,可以在 Bing Webmaster Tools 管理抓取频率,并用 robots.txt 细化规则。
4. Baiduspider:中国主流搜索爬虫
是获取中国搜索流量的关键。
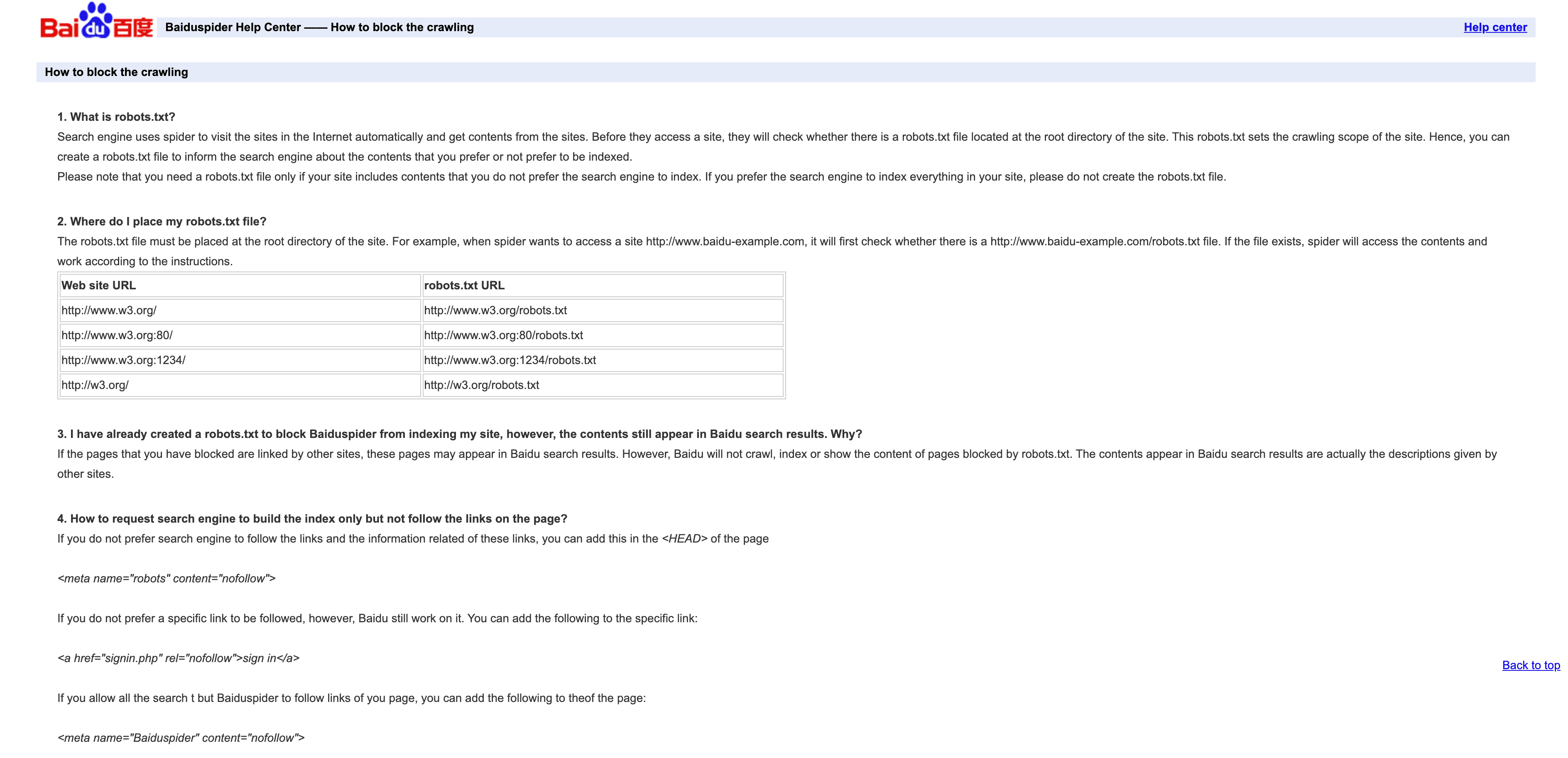
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - 验证方式: 没有官方 IP 列表,可以通过反向 DNS 检查是不是
.baidu.com,但有一定局限。 - 管理建议: 如果你需要中国流量,建议允许其访问。用 robots.txt 设定规则,但 Baiduspider 有时候会无视。要是不做中国 SEO,可以考虑限速或屏蔽,节省带宽。
5. YandexBot:俄罗斯搜索引擎爬虫
是俄罗斯及独联体市场的核心爬虫。
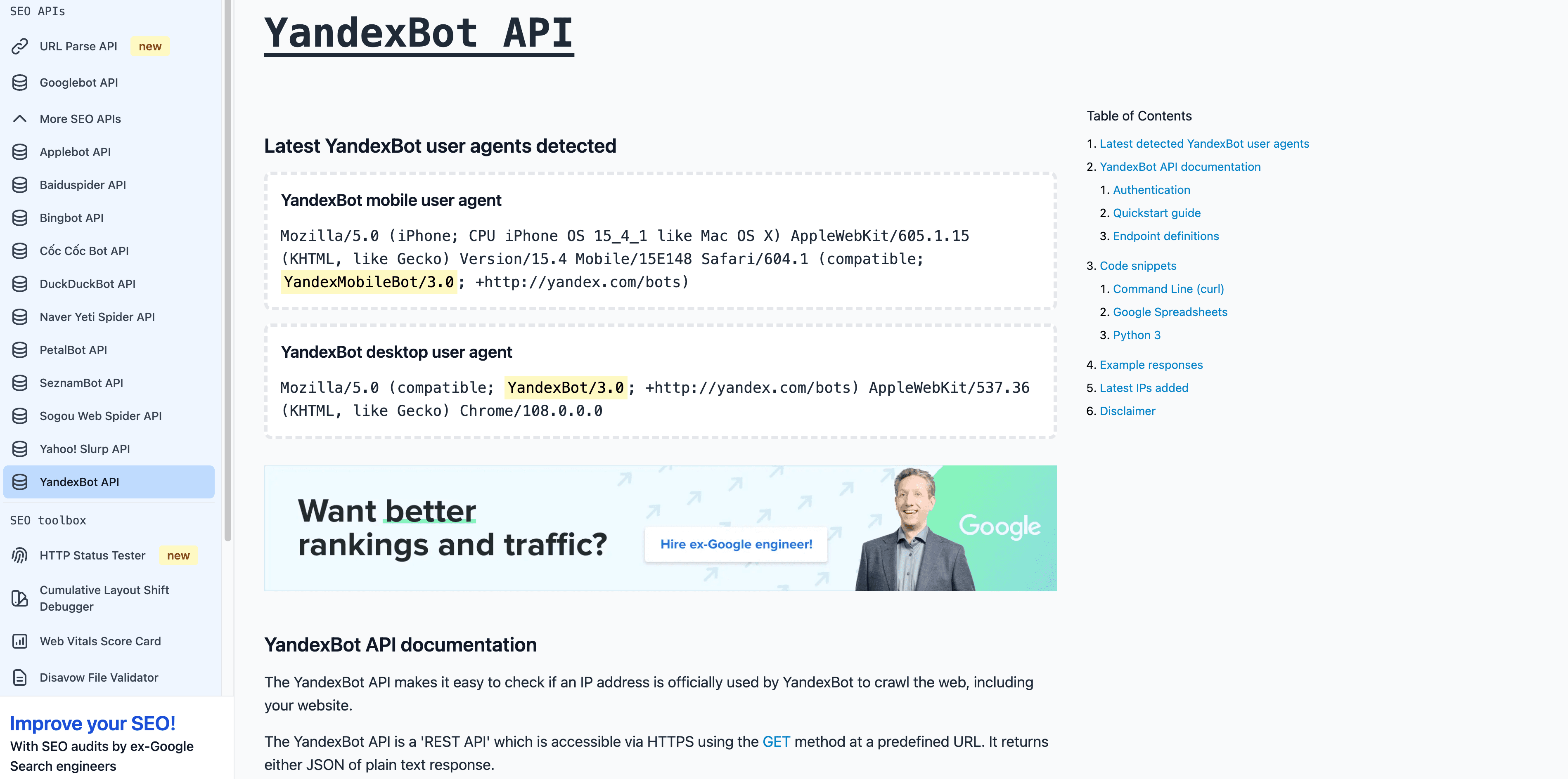
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - 验证方式: 反向 DNS 应该以
.yandex.ru、.yandex.net或.yandex.com结尾。 - 管理建议: 针对俄语市场建议允许访问,可以用 Yandex Webmaster 控制抓取。
6. DuckDuckBot:注重隐私的搜索爬虫
支持 DuckDuckGo 的隐私搜索。
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - 验证方式: 。
- 管理建议: 除非你完全不在意隐私用户,否则建议允许。抓取频率低,管理起来很轻松。
7. AhrefsBot:SEO 与外链分析爬虫
是主流 SEO 工具爬虫,适合外链分析,但带宽消耗比较大。
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - 验证方式: 没有公开 IP 列表,可以通过 UA 和反向 DNS 验证。
- 管理建议: 如果你用 Ahrefs 建议允许。可以用 robots.txt 设置抓取延迟或屏蔽。也可以。
8. SemrushBot:SEO 竞争分析爬虫
是另一大 SEO 工具爬虫。
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(还有如SemrushBot-BA、SemrushBot-SI等变体) - 验证方式: 只通过 User-Agent,没有公开 IP 列表。
- 管理建议: 用 Semrush 建议允许,否则可以用 robots.txt 或服务器规则限速或屏蔽。
9. FacebookExternalHit:社交媒体预览爬虫
用于抓取 Facebook 和 Instagram 的 Open Graph 预览数据。
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - 验证方式: 通过 User-Agent,IP 属于 Facebook ASN。
- 管理建议: 允许访问可以获得丰富的社交预览。屏蔽后 Facebook/Instagram 链接就没有缩略图或摘要了。
10. Twitterbot:X(Twitter)链接预览爬虫
用于抓取 X(Twitter)的卡片数据。
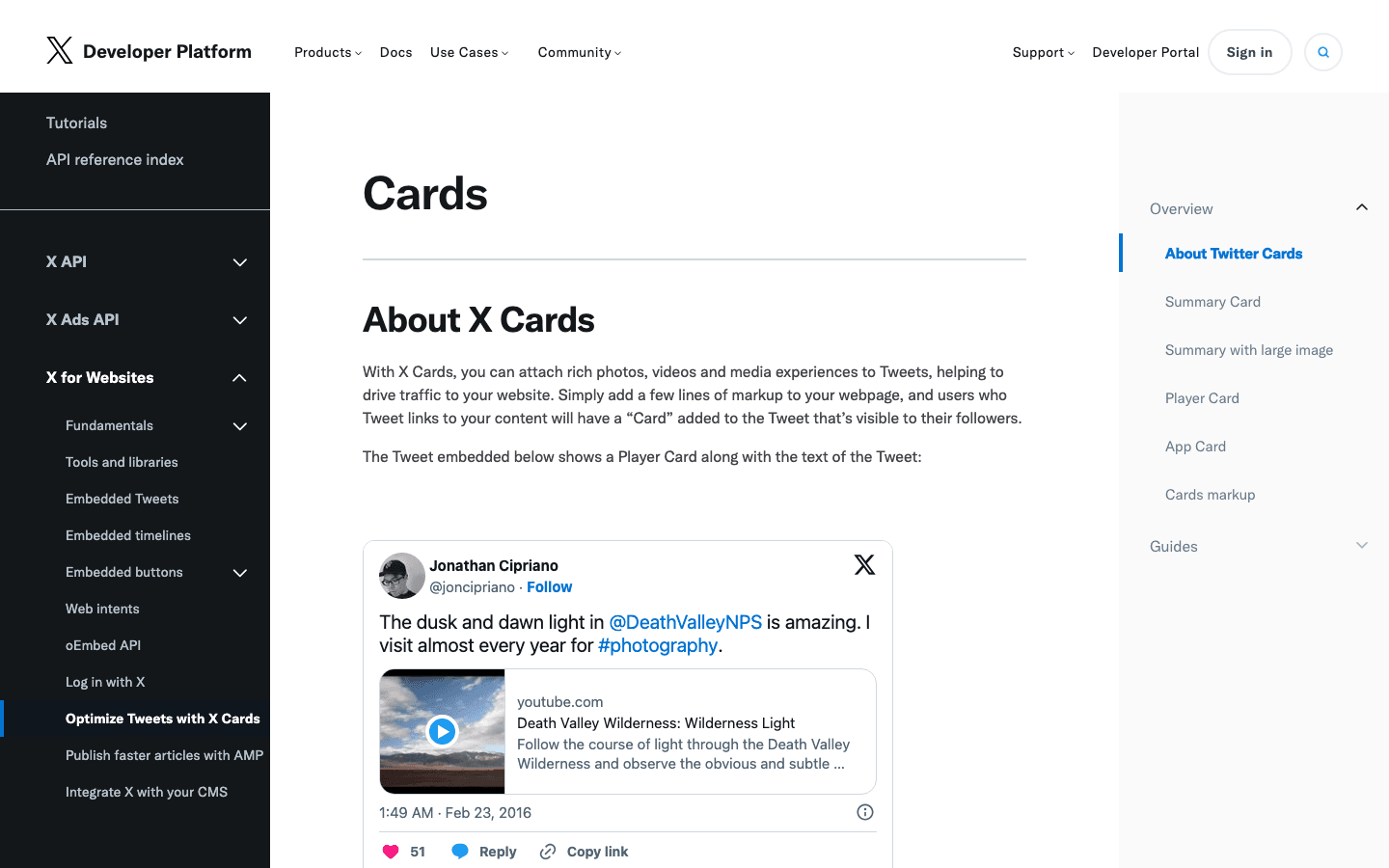
- User-Agent:
Twitterbot/1.0 - 验证方式: 通过 User-Agent,Twitter ASN(AS13414)。
- 管理建议: 允许访问可以获得 Twitter 预览。建议加上 Twitter Card 元标签来优化展示。
一览表:主流爬虫对比速查
| 爬虫 | 用途 | User-Agent 示例 | 验证方式 | 业务影响 | 管理建议 |
|---|---|---|---|---|---|
| Thunderbit | AI 日志/爬虫分析 | N/A(工具,非爬虫) | N/A | 数据管理、爬虫分类 | 用于日志提取、白名单构建 |
| Googlebot | Google 搜索索引 | Googlebot/2.1 | DNS & IP 列表 | SEO 核心 | 永远允许,Search Console 管理 |
| Bingbot | Bing/Yahoo 搜索 | bingbot/2.0 | DNS & IP 列表 | Bing/Yahoo SEO 重要 | 允许,Bing Webmaster Tools 管理 |
| Baiduspider | 百度搜索(中国) | Baiduspider/2.0 | 反向 DNS、UA | 中国 SEO 关键 | 针对中国市场允许,关注带宽 |
| YandexBot | Yandex 搜索(俄罗斯) | YandexBot/3.0 | 反向 DNS 至 .yandex.ru | 俄/东欧市场关键 | 针对 RU/CIS 允许,Yandex 工具管理 |
| DuckDuckBot | DuckDuckGo 搜索 | DuckDuckBot/1.1 | 官方 IP 列表 | 隐私用户 | 允许,影响小 |
| AhrefsBot | SEO/外链分析 | AhrefsBot/7.0 | UA、反向 DNS | SEO 工具,带宽消耗大 | 允许/限速/屏蔽,robots.txt 管理 |
| SemrushBot | SEO/竞争分析 | SemrushBot/1.0(含变体) | UA | SEO 工具,抓取激进 | 允许/限速/屏蔽,robots.txt 管理 |
| FacebookExternalHit | 社交链接预览 | facebookexternalhit/1.1 | UA、Facebook ASN | 社交媒体互动 | 允许预览,使用 OG 标签 |
| Twitterbot | Twitter 链接预览 | Twitterbot/1.0 | UA、Twitter ASN | Twitter 互动 | 允许预览,使用 Twitter Card 标签 |
2025 年爬虫管理最佳实践
- 定期更新: 爬虫生态变化快,建议每季度复查一次,并用 Thunderbit 等工具自动抓取、比对官方名单()。
- 验证而不是盲信: 一定要双重验证 User-Agent 和 IP/ASN,别让伪装者混进来,影响你的数据和安全()。
- 白名单好爬虫: 确保搜索和社交爬虫不会被防火墙或反爬规则误拦。
- 限速或屏蔽激进爬虫: 对抓取频率高的 SEO 工具用 robots.txt、抓取延迟或服务器规则加以限制。
- 自动化日志分析: 用 AI 工具(比如 Thunderbit)自动提取、分类、标记爬虫行为,省时省力,及时发现新趋势。
- 平衡 SEO、分析和安全: 别屏蔽对业务有益的爬虫,也别让恶意机器人随意捣乱。
总结:让你的爬虫名单始终高效可用
到了 2025 年,爬虫名单管理早就不是 IT 部门的小事,而是关乎 SEO、数据分析、安全和合规的核心工作。现在网络流量大部分都来自机器人,你必须搞清楚谁在访问、目的是什么、该怎么应对。保持名单实时更新,能自动化的就交给工具(比如 ),才能在越来越拥挤的网络世界里站稳脚跟。智能、可执行的爬虫策略,是你在“机器人时代”攻防兼备的最佳武器。
常见问题
1. 为什么要维护最新的爬虫名单?
因为现在超过一半的网络流量都来自机器人,而真正有用的只占少数。保持名单更新,能确保好爬虫畅通无阻(有利于 SEO 和社交预览),同时拦截或限速恶意爬虫,保护你的数据分析、带宽和安全。
2. 如何判断爬虫是真实还是伪造?
不要只信 User-Agent,一定要结合官方 IP 或 ASN 验证(比如反向 DNS)。Thunderbit 等工具可以自动把日志和官方爬虫 IP、User-Agent 匹配,大大提升识别效率。
3. 如果遇到未知爬虫抓取怎么办?
先查查它的 User-Agent 和 IP。如果不在白名单也不是已知爬虫,建议限速、挑战或直接屏蔽。可以用 AI 工具对新出现的爬虫进行分类和监控。
4. Thunderbit 如何帮助爬虫管理?
Thunderbit 利用 AI 自动提取、结构化、分类日志里的爬虫行为,方便你构建白名单、识别伪装者、自动执行安全策略。它的语义级预处理对复杂或动态网站特别有效。
5. 屏蔽 Googlebot 或 Bingbot 有什么风险?
屏蔽主流搜索引擎爬虫会让你的网站被移出搜索结果,流量会骤减。一定要检查防火墙、robots.txt 和反爬规则,确保不会误伤关键爬虫。
延伸阅读: