

网站里有死链、孤立页面,甚至还有一张 2019 年的“测试”页面,不知道怎么就被 Google 收录了。只要你在管网站,这些问题你一定不陌生。
一款好用的网站爬虫,能把这些问题一把梳理干净,还能把整个站点结构完整理出来,让你真正有办法去修。可很多人会把“网页爬取”和“网页抓取”混为一谈,其实这两者根本不是一回事。
我在真实网站上测试了 10 款免费爬虫。有些特别适合做 SEO 审计,有些则更擅长数据提取。下面我来聊聊哪些工具表现亮眼,哪些又不太行。
什么是网站爬虫?先弄懂基础概念
先把概念讲清楚:网站爬虫 和 网页抓取器 不是同一种工具。虽然这两个词常常被混着用,但本质上差别很大。你可以把爬虫想象成网站的“测绘员”——它会把每个角落都走一遍,沿着链接一路探索,并画出整站页面地图。它的任务是发现:找出 URL、梳理站点结构、建立内容索引。像 Google 这样的搜索引擎机器人就是这么工作的,SEO 工具也会用它来检查网站健康状况(Thunderbit 博客:什么是网页爬虫?)。
而 网页抓取器 更像数据“采矿工”。它不关心整张地图,只想直接把值钱的信息挖出来:商品价格、公司名称、评论、邮箱等等。抓取器会从爬虫找到的页面里提取指定字段(Thunderbit 博客:如何抓取网站?)。
打个比方:
- 爬虫: 像在超市里把每个货架都逛一遍,记录所有商品。
- 抓取器: 直接走到咖啡区,把每一种有机咖啡的价格抄下来。
为什么要区分这两者?因为如果你的目标只是把网站里的所有页面找出来(比如做 SEO 审计),你需要的是爬虫;如果你想把竞品网站上的所有商品价格拿下来,你需要的是抓取器——或者最好,是一款两者都能做的工具。
为什么要用在线网页爬虫?它能给业务带来什么
那为什么还要费劲用网页爬虫?因为互联网不会变小。事实上,超过 54% 的企业品牌都在使用专门的爬取平台 来优化网站,而一些 SEO 工具每天会抓取高达 70 亿 页面。
网页爬虫能帮你做这些事:
- SEO 审计: 找出死链、缺失标题、重复内容、孤立页面等问题(SEO.ai)。
- 链接检查与 QA: 在用户碰到 404 或重定向死循环之前先发现它们(Screaming Frog)。
- 站点地图生成: 自动生成 XML 站点地图,方便搜索引擎抓取和内部规划(PowerMapper)。
- 内容盘点: 列出所有页面、层级结构和元数据。
- 合规与可访问性: 检查每个页面是否符合 WCAG、SEO 和法律要求(SiteOne Crawler)。
- 性能与安全: 标记加载慢的页面、过大的图片或安全问题(SiteOne Crawler)。
- AI 与分析数据: 将抓取到的数据喂给分析工具或 AI 工具(Thunderbit 博客:Crawl4AI 评测)。
下面这张表可以快速对应不同业务场景和适用角色:
| 使用场景 | 适合人群 | 价值 / 结果 |
|---|---|---|
| SEO 与站点审计 | 市场营销、SEO、小企业主 | 发现技术问题,优化站点结构,提升排名 |
| 内容盘点与 QA | 内容经理、网站管理员 | 审核或迁移内容,发现死链/坏图 |
| 潜在客户开发(抓取) | 销售、业务拓展 | 自动化拓客,为 CRM 填充新线索 |
| 竞争情报 | 电商、产品经理 | 跟踪竞品价格、新品、库存变化 |
| 站点地图与结构克隆 | 开发者、DevOps、顾问 | 为改版或备份复制站点结构 |
| 内容聚合 | 研究人员、媒体、分析师 | 汇总多个网站的数据用于分析或趋势监测 |
| 市场研究 | 分析师、AI 训练团队 | 收集大规模数据用于分析或 AI 模型训练 |
我们是如何筛选最佳免费网站爬虫工具的
这些年我花了不少深夜时间(咖啡也喝了不少)研究各种爬虫工具、翻文档、跑测试任务。我的筛选标准主要有这些:
- 技术能力: 能不能处理现代网站(JavaScript、登录、动态内容)?
- 易用性: 对非技术用户是否友好,还是必须会命令行?
- 免费版限制: 真的免费,还是只是个试用噱头?
- 在线可访问性: 是云工具、桌面应用,还是代码库?
- 独特功能: 有没有 AI 提取、可视化站点地图、事件驱动爬取这类亮点?
我逐个测试了这些工具,查看用户反馈,并横向对比功能。如果某个工具让我想把电脑扔出窗外,那它肯定没进榜单。
快速对比:10 款最佳免费网站爬虫一览
| 工具与类型 | 核心功能 | 最佳使用场景 | 技术要求 | 免费版详情 |
|---|---|---|---|---|
| BrightData(云端/API) | 企业级爬取、代理池、JS 渲染、CAPTCHA 处理 | 大规模数据采集 | 需要一定技术基础 | 免费试用:3 个爬虫,每个 100 条记录(总计约 300 条) |
| Crawlbase(云端/API) | API 爬取、反爬处理、代理、JS 渲染 | 需要后端爬取基础设施的开发者 | 需要 API 集成 | 免费:7 天约 5,000 次 API 调用,之后每月 1,000 次 |
| ScraperAPI(云端/API) | 代理轮换、JS 渲染、异步爬取、预置端点 | 开发者、价格监测、SEO 数据 | 配置很少 | 免费:7 天 5,000 次 API 调用,之后每月 1,000 次 |
| Diffbot Crawlbot(云端) | AI 爬取 + 提取、知识图谱、JS 渲染 | 大规模结构化数据、AI/ML | 需要 API 集成 | 免费:每月 10,000 积分(约 1 万页面) |
| Screaming Frog(桌面端) | SEO 审计、链接/元标签分析、站点地图、自定义提取 | SEO 审计、站点管理 | 桌面应用、图形界面 | 免费:每次爬取 500 个 URL,仅核心功能 |
| SiteOne Crawler(桌面端) | SEO、性能、可访问性、安全、离线导出、Markdown | 开发者、QA、迁移、文档 | 桌面端/CLI、图形界面 | 免费且开源,GUI 报告最多 1,000 个 URL(可配置) |
| Crawljax(Java,开源) | 面向事件的动态网站爬取、静态导出 | 开发者、动态 Web 应用 QA | Java、CLI/配置 | 免费且开源,无限制 |
| Apache Nutch(Java,开源) | 分布式、插件化、Hadoop 集成、自定义搜索 | 自建搜索引擎、大规模爬取 | Java、命令行 | 免费且开源,仅需承担基础设施成本 |
| YaCy(Java,开源) | 点对点爬取与搜索、隐私、本地/内网索引 | 私有搜索、去中心化 | Java、浏览器界面 | 免费且开源,无限制 |
| PowerMapper(桌面端/SaaS) | 可视化站点地图、可访问性、QA、浏览器兼容性 | 代理公司、QA、可视化建模 | 图形界面,易上手 | 免费试用:30 天,桌面版每次扫描 100 页,在线版每次 10 页 |
BrightData:企业级云端网站爬虫

BrightData 可以说是网页爬取领域里的“重型装备”。它是一个云平台,拥有庞大的代理网络、JavaScript 渲染、CAPTCHA 处理功能,还提供用于自定义爬取的 IDE。如果你要做大规模数据采集——比如持续监测数百个电商网站的价格——BrightData 的基础设施很难被超越(aimultiple.com)。
优势:
- 能处理各种带反爬措施的复杂网站
- 可扩展性强,适合企业级需求
- 提供常见网站的预置模板
局限:
- 没有长期免费版,只有试用:3 个爬虫,每个 100 条记录
- 对于简单审计来说可能过于“重装”
- 非技术用户需要一点学习成本
如果你需要大规模抓取网页,BrightData 就像是在租一辆 F1 赛车。只是别指望试驾完之后它还能免费用(BrightData 定价)。
Crawlbase:面向开发者的 API 驱动免费网页爬虫

Crawlbase(前身为 ProxyCrawl)主打程序化爬取。你只要把 URL 交给它的 API,它就会返回 HTML,同时在后台帮你处理代理、地理定位和 CAPTCHA(Capterra)。
优势:
- 成功率高(99%+)
- 适合处理 JavaScript 密集型网站
- 很适合集成到你自己的应用或工作流里
局限:
- 需要一定 API 或 SDK 集成能力
- 免费版:7 天约 5,000 次 API 调用,之后每月 1,000 次
如果你是开发者,想在不维护代理的前提下实现大规模爬取(甚至抓取),Crawlbase 是个很稳的选择(Crawlbase 定价)。
ScraperAPI:让动态网页爬取更简单

ScraperAPI 可以理解成“你帮我把这个页面拿回来就行”的 API。你提供一个 URL,它会自动处理代理、无头浏览器和反爬机制,然后把 HTML(某些站点还会直接返回结构化数据)交给你。它特别适合动态页面,而且免费额度也比较大方(ScraperAPI 定价)。
优势:
- 对开发者非常友好(就是一次 API 调用)
- 能处理 CAPTCHA、IP 封禁、JavaScript
- 免费:7 天 5,000 次 API 调用,之后每月 1,000 次
局限:
- 没有可视化爬取报告
- 如果你要跟踪链接,还是得自己写爬取逻辑
如果你想在几分钟内把网页爬取能力接入代码库,ScraperAPI 基本是无脑选项。
Diffbot Crawlbot:自动发现网站结构

Diffbot Crawlbot 的厉害之处在于“更聪明”。它不只是爬网页,还会用 AI 对页面进行分类,并把文章、商品、活动等结构化数据提取成 JSON。它就像一个真正看得懂内容的机器人实习生(Diffbot 免费计划)。
优势:
- 不只是爬取,还能做 AI 驱动的提取
- 能处理 JavaScript 和动态内容
- 免费:每月 10,000 积分(约 1 万页面)
局限:
- 更偏开发者使用(需要 API 集成)
- 不是可视化 SEO 工具,更适合数据项目
如果你需要大规模结构化数据,尤其是用于 AI 或分析项目,Diffbot 是个很强的工具。
Screaming Frog:免费桌面 SEO 爬虫

Screaming Frog 是 SEO 审计领域的经典桌面爬虫。免费版每次可抓取最多 500 个 URL,功能很全:死链、元标签、重复内容、站点地图等等,一应俱全(Screaming Frog 用户指南)。
优势:
- 速度快、检查细、在 SEO 圈口碑很好
- 不需要写代码,输入 URL 就能开始
- 免费版每次可爬取 500 个 URL
局限:
- 只有桌面版,没有云端版本
- 高级功能(如 JS 渲染、定时任务)需要付费许可
如果你认真做 SEO,Screaming Frog 基本是必备工具——只是别指望它免费帮你爬一个 1 万页的网站。
SiteOne Crawler:静态站点导出与文档化

SiteOne Crawler 是技术审计里的瑞士军刀。它开源、跨平台,既能爬取、审计,还能把网站导出为 Markdown,用于文档整理或离线使用(SiteOne Crawler)。
优势:
- 覆盖 SEO、性能、可访问性、安全性
- 可导出网站用于归档或迁移
- 免费且开源,没有使用次数限制
局限:
- 比一些图形界面工具更技术向
- GUI 审计报告默认最多 1,000 个 URL(可配置)
如果你是开发者、QA 或顾问,想获得更深入的洞察,又喜欢开源工具,SiteOne 是个被低估的宝藏。
Crawljax:用于动态页面的开源 Java 网页爬虫
Crawljax 是一个专精型工具:它通过模拟用户交互(点击、填写表单等)来爬取现代 JavaScript 密集型 Web 应用。它是事件驱动的,甚至可以把动态网站导出成静态版本(Wikipedia:Crawljax)。
优势:
- 对 SPA 和大量 AJAX 的网站几乎无可替代
- 开源且可扩展
- 没有使用限制
局限:
- 需要 Java,以及一定的编程/配置能力
- 不适合非技术用户
如果你需要像真实用户一样去爬 React 或 Angular 应用,Crawljax 会很顺手。
Apache Nutch:可扩展的分布式网站爬虫

Apache Nutch 是开源爬虫里的“老祖宗”。它专为超大规模、分布式爬取而设计——比如自己搭建搜索引擎,或者索引数百万甚至数十亿页面(Martechvibe)。
优势:
- 配合 Hadoop 可扩展到十亿级页面
- 高度可配置、可扩展
- 免费且开源
局限:
- 学习曲线陡峭(Java、命令行、配置项)
- 不适合小网站或普通用户
如果你想大规模爬网,而且不怕折腾命令行,Nutch 很适合你。
YaCy:点对点网页爬虫与搜索引擎
YaCy 是一款非常独特的去中心化爬虫和搜索引擎。每个实例都会爬取并索引网站,你还可以加入点对点网络,与其他用户共享索引(TechRadar:YaCy)。
优势:
- 强调隐私,没有中心服务器
- 很适合搭建私有搜索或内网搜索
- 免费且开源
局限:
- 结果取决于网络覆盖范围
- 需要一定配置(Java、浏览器界面)
如果你对去中心化感兴趣,或者想自己搭一个搜索引擎,YaCy 是个很有意思的选择。
PowerMapper:面向 UX 和 QA 的可视化站点地图生成器

PowerMapper 的重点是把网站结构“看得见”。它会爬取网站并生成可交互的站点地图,同时还能检查可访问性、浏览器兼容性和基础 SEO(Slickplan Review)。
优势:
- 可视化站点地图很适合代理公司和设计师
- 可检查可访问性与合规性
- 图形界面简单易用,不需要技术背景
局限:
- 只有试用版(30 天,桌面版每次 100 页 / 在线版每次 10 页)
- 完整版本需要付费
如果你要向客户展示站点结构,或检查合规情况,PowerMapper 是个很方便的工具。
如何为你的需求选择合适的免费网页爬虫
选项这么多,到底怎么挑?给你一个简单建议:
- 做 SEO 审计: Screaming Frog(小站)、PowerMapper(可视化)、SiteOne(深度审计)
- 做动态 Web 应用: Crawljax
- 做大规模或自定义搜索: Apache Nutch、YaCy
- 开发者需要 API 接口: Crawlbase、ScraperAPI、Diffbot
- 做文档或归档: SiteOne Crawler
- 想要企业级能力但先试用: BrightData、Diffbot
重点考虑因素:
- 可扩展性: 你的网站或任务规模有多大?
- 易用性: 你能接受写代码,还是更想点点鼠标就能用?
- 数据导出: 你需要 CSV、JSON,还是要和其他工具集成?
- 支持: 卡住时有没有社区或文档可查?
当网页爬取遇上网页抓取:为什么 Thunderbit 是更聪明的选择
使用 AI 从任何网站抓取数据 Get Started Free
现实情况是:大多数人做网站爬取,并不是为了做一张漂亮的站点结构图。真正的目标通常是拿到结构化数据——比如商品列表、联系方式,或者内容清单。这正是 Thunderbit 发挥作用的地方。
Thunderbit 不只是爬虫,也不只是抓取器——它是一个把两者结合起来的 AI 驱动 Chrome 扩展。它的工作方式如下:
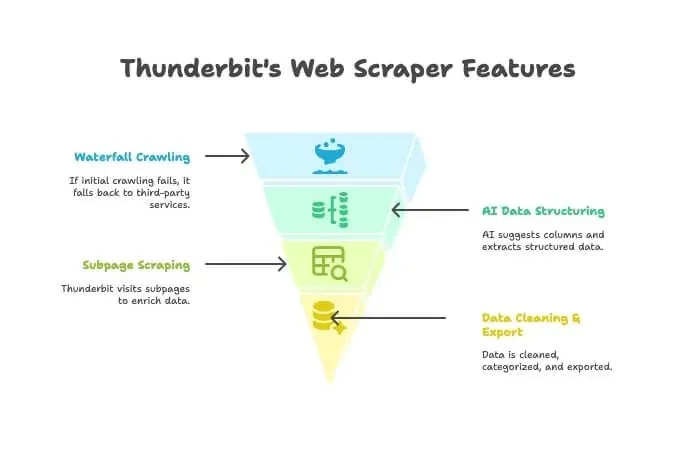
- AI 爬取: Thunderbit 会像爬虫一样探索网站。
- 瀑布式爬取: 如果 Thunderbit 自己的引擎拿不到页面(比如遇到了强力反爬墙),它会自动切换到第三方爬取服务,不需要你手动配置。
- AI 数据结构化: 一旦拿到 HTML,Thunderbit 的 AI 就会自动建议合适的列,并提取结构化数据(名称、价格、邮箱等),你甚至不需要写任何选择器。
- 子页面抓取: 如果你需要每个商品详情页的信息,Thunderbit 可以自动访问每个子页面并丰富你的表格。
- 数据清洗与导出: 它可以一键摘要、分类、翻译,并把数据导出到 Excel、Google Sheets、Airtable 或 Notion。
- 零代码体验: 只要你会用浏览器,就能用 Thunderbit。不写代码,不折腾代理,不头痛。
什么时候该用 Thunderbit,而不是传统爬虫?
- 当你的最终目标是得到一份干净、可直接使用的表格,而不是一串 URL。
- 当你想把“爬取、提取、清洗、导出”全部放在一个地方自动完成。
- 当你希望节省时间,也节省精力。
你可以 在这里下载 Thunderbit 的 Chrome 扩展,亲自看看为什么这么多业务用户都在转向它。
总结:如何充分利用免费网站爬虫
什么是数据抓取,以及如何操作 Get Started Free
网站爬虫这些年已经进化很多。无论你是营销人员、开发者,还是只想把网站维护好的站长,总能找到适合你的免费工具,或者至少是可试用的工具。从 BrightData 和 Diffbot 这样的企业级平台,到 SiteOne 和 Crawljax 这样的开源宝藏,再到 PowerMapper 这样的可视化工具,选择比以往更丰富。
但如果你想用一种更聪明、更一体化的方式,把“我需要这些数据”快速变成“这是我的表格”,不妨试试 Thunderbit。它是为希望直接拿到结果,而不只是看报告的业务用户打造的。
准备开始爬取了吗?先下载一个工具,跑一次扫描,看看你之前遗漏了什么。要是你想把“爬取”变成“两步拿到可用数据”,不妨看看 Thunderbit。
想了解更多深度解析和实用指南,欢迎访问 Thunderbit 博客。
试试 AI 网页爬虫 Get Started Free
常见问题
网站爬虫和网页抓取器有什么区别?
爬虫负责发现并梳理网站的所有页面(可以理解为制作目录);抓取器则从这些页面里提取具体数据字段(比如价格、邮箱或评论)。爬虫负责找,抓取器负责挖(Thunderbit 博客:什么是网页爬虫?)。
哪款免费网页爬虫最适合非技术用户?
如果是小网站或 SEO 审计,Screaming Frog 很好上手;如果你更看重可视化站点地图,PowerMapper 在试用期内很不错。若你的目标是结构化数据,并且想要零代码、基于浏览器的体验,Thunderbit 是最容易上手的选择。
有些网站会屏蔽网页爬虫吗?
有的——有些网站会通过 robots.txt 文件或反爬机制(比如 CAPTCHA 或 IP 封禁)来阻止爬虫。像 ScraperAPI、Crawlbase 和 Thunderbit(通过瀑布式爬取)通常能绕开这些限制,但前提是你要负责任地使用,并遵守网站规则(BrightData 定价)。
免费网站爬虫会限制页面数或功能吗?
大多数都会。比如 Screaming Frog 免费版每次最多抓取 500 个 URL;PowerMapper 试用版每次最多 100 页。基于 API 的工具通常会限制每月积分或调用次数。像 SiteOne 或 Crawljax 这样的开源工具一般没有硬性限制,但会受你的硬件能力限制。
使用网页爬虫合法吗?会不会涉及隐私合规?
通常来说,爬取公开网页是合法的,但你仍然应该查看网站的服务条款和 robots.txt。不要在未经许可的情况下抓取私密或受密码保护的数据;如果你提取的是个人信息,也要注意隐私法规要求(Crawlbase 指南)。




