

想象一下:你刚上线网站,满心期待迎来大量客户,却发现一半流量……竟然是机器人。不是科幻片里的那种,而是数字爬虫——搜索引擎、AI 机器人、分析爬虫——它们日夜不停地在你的网站上四处“巡视”,像一场没完没了的隐形访客游行。到了 2026 年,这早就不是服务器日志里一个有趣的小插曲,而是新常态。弄清楚是谁(或者什么)在抓取你的网站、抓取频率有多高、又为什么抓取,已经成了任何在线业务的核心课题。
作为在 SaaS、自动化和 AI 领域深耕多年的人,我亲眼看着网页爬取从幕后技术细节,变成如今摆在台前的商业挑战。数据相当惊人:机器人现在几乎占了互联网流量的一半,在某些地方甚至比人类还多。随着 AI 驱动的爬虫不断抓取内容,用于训练大语言模型,基础设施、预算和品牌面临的压力前所未有。下面我们就来看看最新的网页爬取统计、行业基准,以及这些数据在 2026 年对你的业务意味着什么。
2026 年的网页爬取:全景速览
用 AI 从任何网站抓取数据 Get Started Free
网页爬取的规模和复杂度已经进入全新阶段。每天,数十亿自动化请求在互联网上飞速穿梭,背后是越来越多的爬虫参与者。过去,像 Googlebot 和 Bingbot 这样的搜索引擎机器人是主角,它们负责索引页面,方便用户在搜索结果中找到内容。但现在,AI 数据爬虫、社交媒体爬虫、分析爬虫等新一代角色也加入了进来。
最关键的数据来了,而且会因统计口径不同而略有差异。Cloudflare 的 2025 年回顾 显示,截至 2025 年 12 月初,机器人和 AI 爬虫合计约占其网络上 53% 的 HTML 请求,而人类流量降至 47%。Imperva 在其 2026 年坏机器人报告(2026 年 4 月 29 日发布)中,基于企业客户群也得出了同样的结论——在 2025 自然年里,53% 来自机器人,47% 来自人类,而上一年还是 51/49。两个视角不同,结论一致:自动化流量已经成了网页流量中的更大部分。变化的不只是流量规模,更是参与者构成。以前机器人流量几乎由搜索索引爬虫主导;到了 2026 年,越来越大的一部分来自为聊天机器人和答案引擎提供数据的 AI 训练爬虫。
这个生态比以往任何时候都更丰富:
- 良性机器人: 搜索索引器、网站可用性监控、合规的数据抓取工具。
- 恶意机器人: 垃圾信息、入侵、未授权抓取。
- AI 爬虫: 新兴力量,为 AI 训练和实时问答收集内容。
AI 爬虫的行为往往和传统搜索引擎爬虫不同。它们可能会抓取整页内容用于语义分析,而不只是索引关键词,而且往往以高频率运行——有时几天内就会向网站发起数百万次请求。结果就是:网页爬取如今无处不在、持续增长且类型越来越多样,把传统索引与 AI 对数据的巨大需求融合到了一起。
每个企业都该知道的关键网页爬取统计数据
下面我们看看正在塑造 2026 年网络格局的数据。这些统计不只是茶余饭后的谈资,它们应该直接影响你的基础设施、内容策略和最终收益。
机器人 vs 人类:流量大战谁在赢?
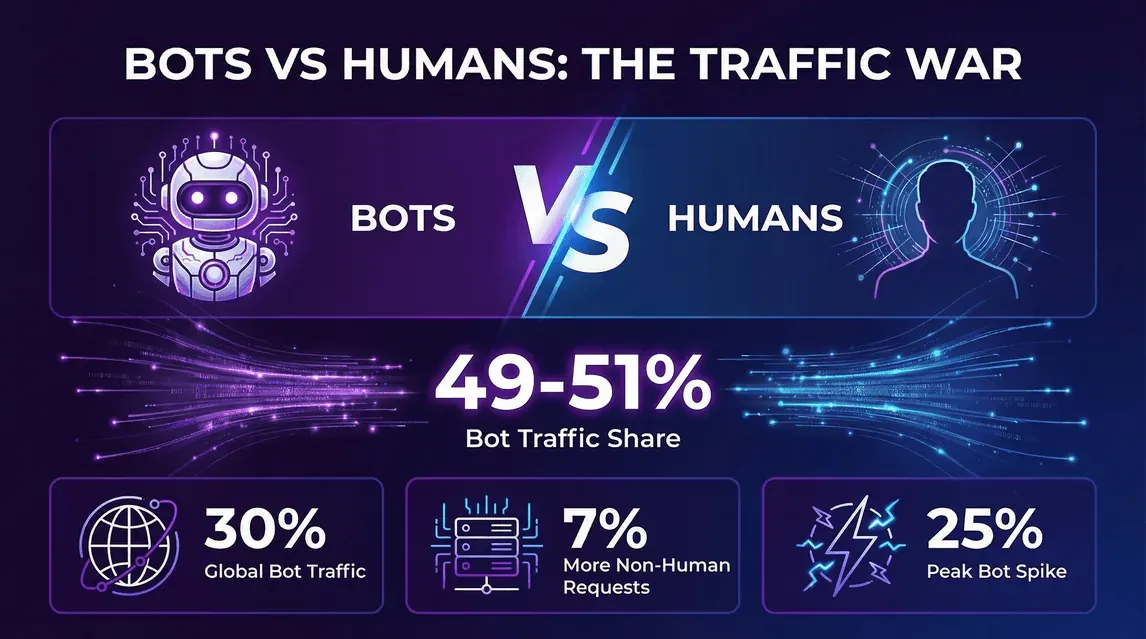
- Imperva,2026 年坏机器人报告(2026 年 4 月): 2025 年自动化流量占全部网页流量的 53%,高于 2024 年的 51%。相应地,人类流量从 49% 下降到 47%。
- Cloudflare 2025 年回顾: 截至 2025 年 12 月 2 日,Cloudflare 网络上的 HTML 请求中,47% 来自人类,44% 来自非 AI 机器人,另有约 9% 来自 AI 机器人和 Googlebot。
- 这不是某一个季度的偶然波动——Imperva 自 2019 年以来每年都看到机器人占比上升,而 2024 到 2025 年的跃升主要由 AI 训练爬虫推动,而不是传统抓取/撞库那一类流量。
- 这对站长意味着什么: 如果你的分析系统不做机器人过滤,那么你看到的原始请求里大约一半并不是来自真人。若按原始日志直接估算基础设施规模而不区分机器人,往往会高估;但如果机器人处理能力配得太低,又会直接伤害那一半真实用户。
AI 爬虫的爆发式增长
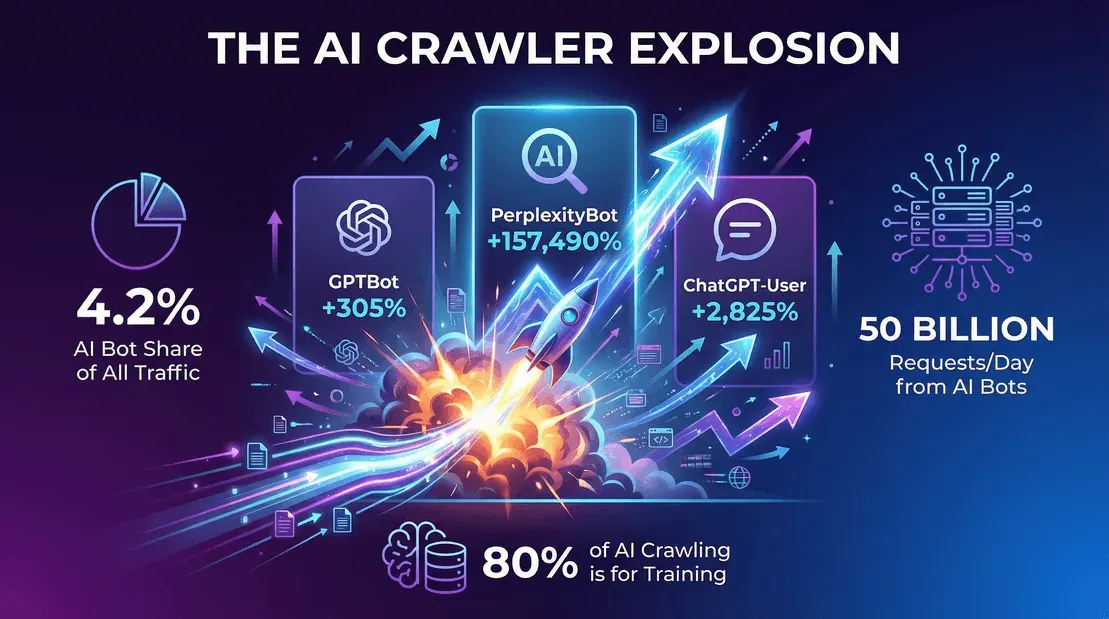
- AI 机器人流量占比仍在上升。 根据 Cloudflare 的 2025 年回顾,到 2025 年末,AI 机器人(不含 Googlebot)约占 4.2% 的 HTML 请求,而 Googlebot 本身又占 4.5%。三年前还不存在的类别,如今规模几乎已经和 Googlebot 本身相当。
- OpenAI 的 GPTBot 从 2025 年 5 月占爬虫请求的 7.7%,下降到 2025 年末按独立页面请求计算的 3.6%(Cloudflare YIR 2025)。这个比例看起来变小了,是因为 Cloudflare 更换了分母,改为按独立页面统计,同时赛道也变得更拥挤。不过从原始量看,GPTBot 仍然是公开网络上排名前三的 AI 爬虫之一。
- Anthropic 的 ClaudeBot 在 2025 年末与 Meta-ExternalAgent 并列,约占 2.4% 的独立页面请求。ClaudeBot 的相对占比在同比中有所下滑(在 Cloudflare 2024 年 5 月至 2025 年 5 月窗口内下降了 46%),随后随着 Anthropic 重启训练而反弹。
- PerplexityBot 绝对规模仍然很小——2025 年末约占 0.06% 的独立页面请求——但它的增长曲线是所有主流 AI 机器人里最陡的。
- Googlebot 仍然是公开网络上体量最大的单一爬虫,且优势非常明显。Cloudflare 的 2025 年回顾显示,它的独立页面量大约是 PerplexityBot 的 200 倍。
现实场景中的爬虫流量
这里有一个来自 2025 年末 Reddit 讨论串 的真实例子——一位开发者拉取了 30 天的服务器日志:
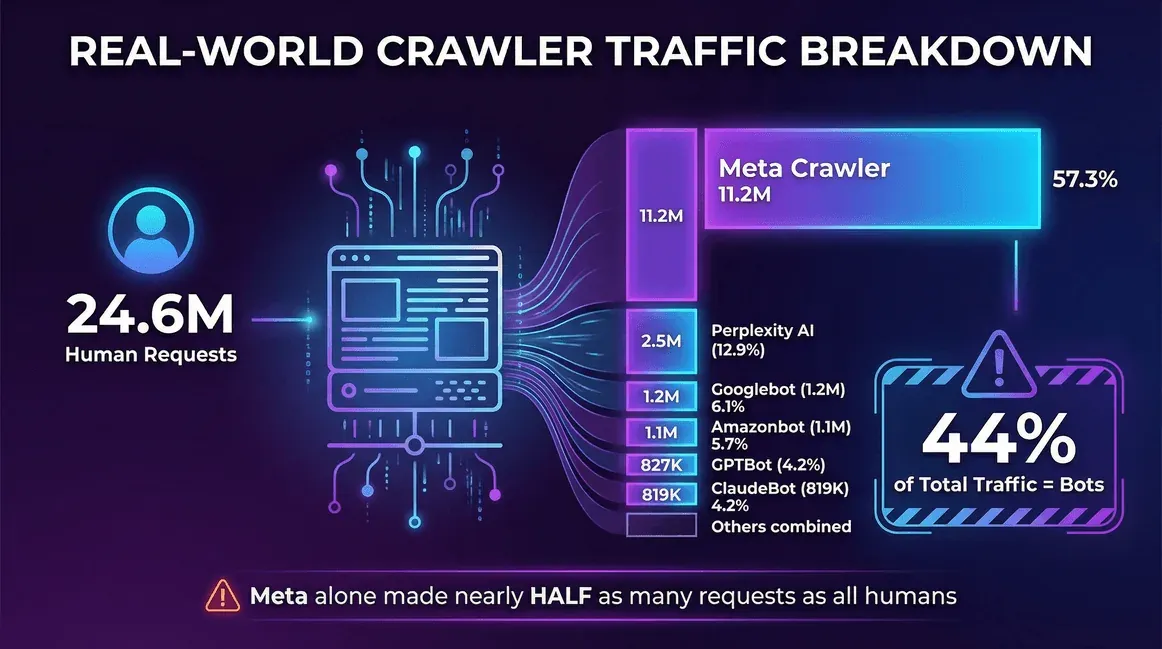
| 流量来源 | 请求数(每月) | 爬虫占比 |
|---|---|---|
| 真人用户 | 24,647,904 | -- |
| Meta 爬虫(Facebook) | 11,175,701 | 57.3% |
| Perplexity AI | 2,512,747 | 12.9% |
| Googlebot | 1,180,737 | 6.1% |
| Amazonbot | 1,120,382 | 5.7% |
| OpenAI GPTBot | 827,204 | 4.2% |
| ClaudeBot(Anthropic) | 819,256 | 4.2% |
| Bingbot | 599,752 | 3.1% |
| ChatGPT-User(OpenAI) | 557,511 | 2.9% |
| Ahrefs 爬虫 | 449,161 | 2.3% |
| 字节跳动爬虫 | 267,393 | 1.4% |
在这个网站上,机器人占总流量的 44%——而仅 Meta 的爬虫一项,请求量就几乎相当于所有真人用户总和的一半。
大局观
- 爬虫流量(搜索 + AI 机器人)在 2024 年 5 月到 2025 年 5 月之间增长了 18%,样本来自一组稳定的网站(blog.cloudflare.com)。
- 在一些主要 CDN 上,LLM 训练机器人几乎占据了全部“机器人”流量的 80%(webscraft.org)。
- 截至 2025 年末,仅 Cloudflare 网络上的 AI 机器人每天就发起约 500 亿次爬取请求(webscraft.org)。
AI 爬虫的崛起:AI 如何改变网页爬取
我们来谈谈眼前这头“巨兽”——或者说机器人。AI 爬虫不只是为搜索索引你的网站,它们还在大量抓取内容,用来训练大语言模型,或者为用户提供即时的 AI 答案。其规模之大,连最激进的搜索引擎都可能自叹不如。
是什么推动了 AI 爬虫热潮?
- 数据饥渴的 AI 模型: 现代 LLM 需要海量且多样化的数据集。网络就是它们的自助餐,而你的内容就在菜单上。
- 训练 vs 实时问答: 大约 80% 的 AI 机器人爬取是为了训练,而不只是响应实时查询。
- 新的爬取模式: AI 机器人可以在短时间内对网站发起大规模突袭,尤其是在模型重训或更新期间,几天就能抓取数百万页面。
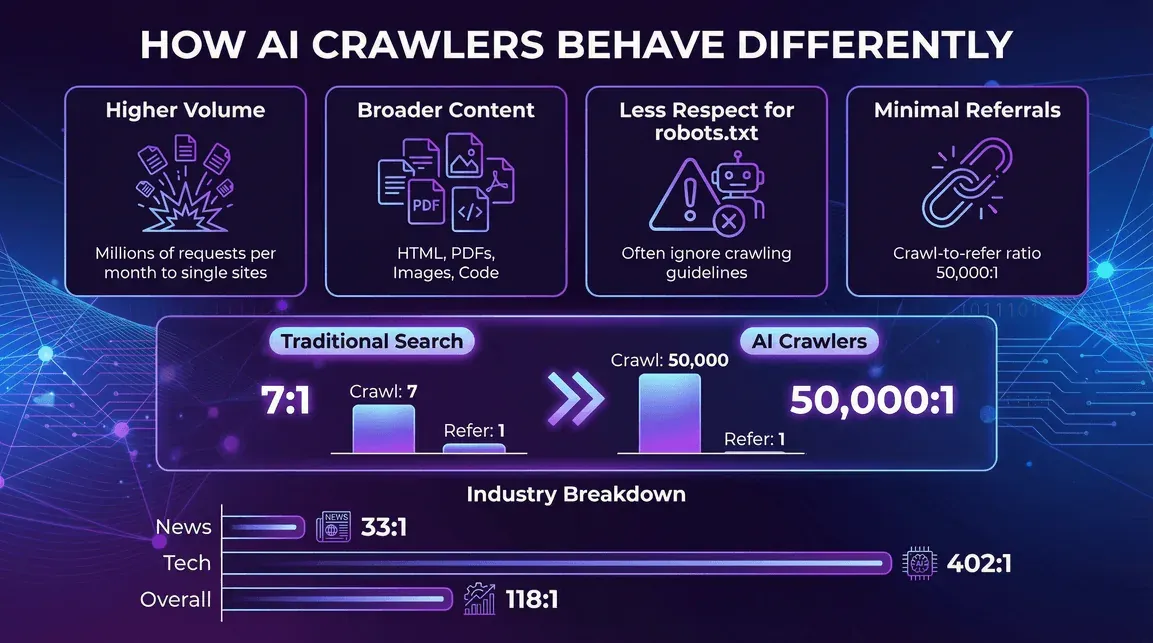
AI 爬虫的行为有何不同
- 单个爬虫的流量更大: 一个 AI 机器人每月就可能对同一网站发起数百万次请求(Reddit 例子)。
- 抓取内容类型更广: 不只是 HTML,PDF、图片、代码,凡是能拿到的都抓。
- 对 robots.txt 的尊重更少: 一些 AI 爬虫会忽略爬取规则,或者只部分遵守(blog.cloudflare.com)。
- 回流流量极少。 这一点对出版商最值得警惕。Cloudflare 在 2025 年 7 月的抓取-点击分析中给出的比例大约是:Anthropic 每 抓取 38,000 页才带来 1 次引荐访问,OpenAI 为 1,091:1,Perplexity 为 194:1。相比之下,Google 的传统搜索爬虫每抓取几页就会带来一次引荐。AI 爬虫拿走很多,回来的很少——而随着越来越多答案直接显示在聊天机器人界面里,而不是让用户点击进入网站,这一差距还在继续扩大。
不同行业的 AI 爬虫流量
并不是所有行业都被同样程度地爬取。比如:
- 新闻与出版: AI 爬虫活动很重,但引荐比略好一些(例如,Perplexity 在新闻网站上的抓取-引荐比为 33:1,而整体为 118:1)(blog.cloudflare.com)。
- 科技与电子: GPTBot 和 Amazonbot 占主导,但抓取-引荐比仍然很高(例如,OpenAI 在科技行业的比例为 402:1)(blog.cloudflare.com)。
- 金融、学术及其他行业: 各行业的机器人组合和回流比率都不同,但趋势很明确:AI 爬虫无处不在,而且大多数几乎不会把流量带回来。
2026 年主要网页爬虫:谁在抓取最多?
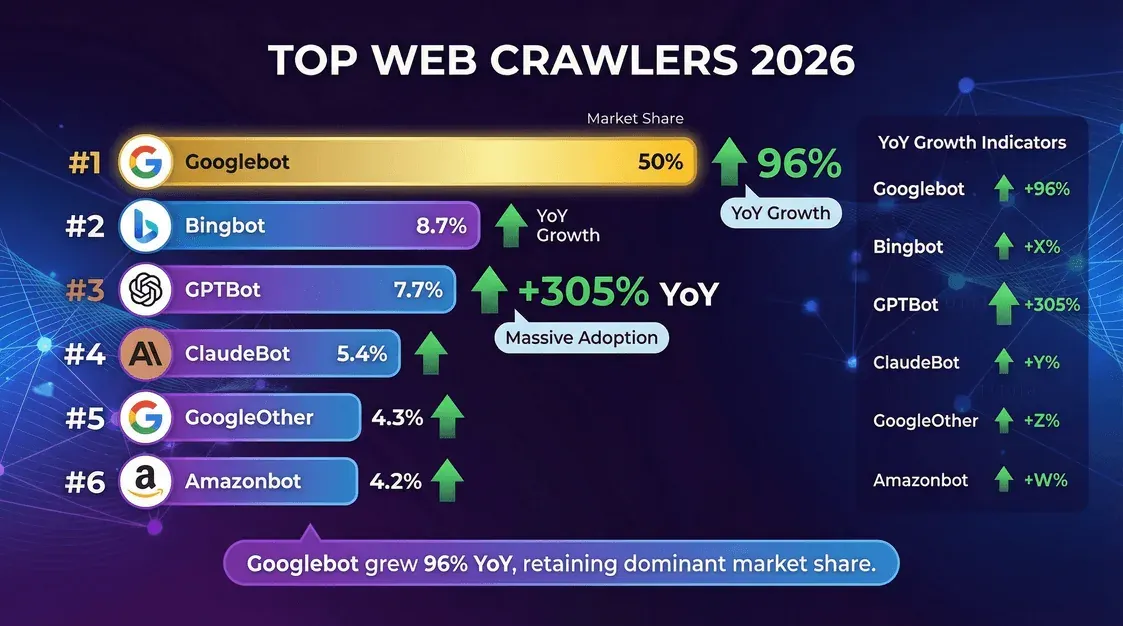
这场爬取大戏的主角是谁?根据 Cloudflare 2025 年中期数据,榜单如下:
| 爬虫(归属方) | 独立页面请求占比(2025 年 10–11 月) | 说明 |
|---|---|---|
| Googlebot(Google) | 11.6% | 仍然是体量最大的单一爬虫。Cloudflare YIR 2025:其规模约为 PerplexityBot 的 200 倍。 |
| GPTBot(OpenAI) | 3.6% | 最大的专用 AI 训练爬虫。由于 Cloudflare 更换了分母且 AI 机器人数量激增,其占比低于 2025 年 5 月。 |
| Bingbot(Microsoft) | 2.6% | 同时支撑 Bing 搜索和 Copilot 的检索基础。 |
| Meta-ExternalAgent | 2.4% | Meta 用于抓取内容并训练 Llama 的爬虫。2025 年冲进前五。 |
| ClaudeBot(Anthropic) | 2.4% | 2025 年末在年初大幅同比下滑后反弹。 |
| Applebot(Apple) | 增长很快 | 根据对 Cloudflare 数据的二次分析,2026 年第一季度迅速冲入第一梯队。 |
| PerplexityBot | 0.06% | 绝对占比很小,但在主要 AI 机器人中相对增长最快。 |
来源:Cloudflare 2025 年回顾,按 2025 年 10–11 月抓取的独立页面占比统计。注意:这与早期报告中使用的 2025 年 5 月“全部爬虫请求占比”分母不同——排名可比较,但百分比不能直接对照。
几个关键结论:
- Googlebot 仍然是王者,负责了全部爬取活动的一大半。
- GPTBot 和 Meta 的爬虫 是增长最快的两个角色,GPTBot 的占比一年内翻了三倍。
- PerplexityBot 和 ChatGPT-User 这类代理在总占比上仍然很小,但增长速度极快。
网页爬取基准:抓取速度、吞吐量与性能
 网页爬取不只是看规模,还要看速度和效率。下面是你在 2026 年需要了解的抓取速率和性能基准。
网页爬取不只是看规模,还要看速度和效率。下面是你在 2026 年需要了解的抓取速率和性能基准。
抓取速率:爬虫抓页面有多快?
- 抓取速率 通常按每秒页面数(或每秒请求数)衡量(IBM)。
- 线程/并行连接数: 线程越多,潜在抓取速率越高。比如,200 个线程、每个站点延迟 2 秒,大约可达到每秒 100 页(IBM)。
- 现实基准: 在配置良好的服务器集群上,一个优化得不错的爬虫通常能达到每秒 100–200 页。
- Google 和 Bing: 它们在全球范围内分布式抓取,合起来每秒很可能处理成千上万页。
影响抓取速率的因素
- 线程/并行抓取器数量: 线程越多,速度越快(直到碰到其他瓶颈)。
- 活跃站点数量: 并行抓取多个域名会放大吞吐量。
- 抓取延迟/等待时间: 延迟越长,抓取速率越慢。
- 资源限制: 带宽、CPU、数据库写入速度都可能成为瓶颈。
- 目标站点性能: 站点越慢或限速越严,抓取速度就越受拖累。
举个例子,如果你的爬虫有 100 个线程、每个站点延迟 1 秒,那理论上每秒大概可以抓取 100 页——除非你的数据库跟不上,那瓶颈就会从网络转到存储。
网页爬取的商业影响:成本、机会与风险
网页爬取不只是技术上的“有趣现象”,它也是一个实打实的商业问题,既有成本,也有机会。
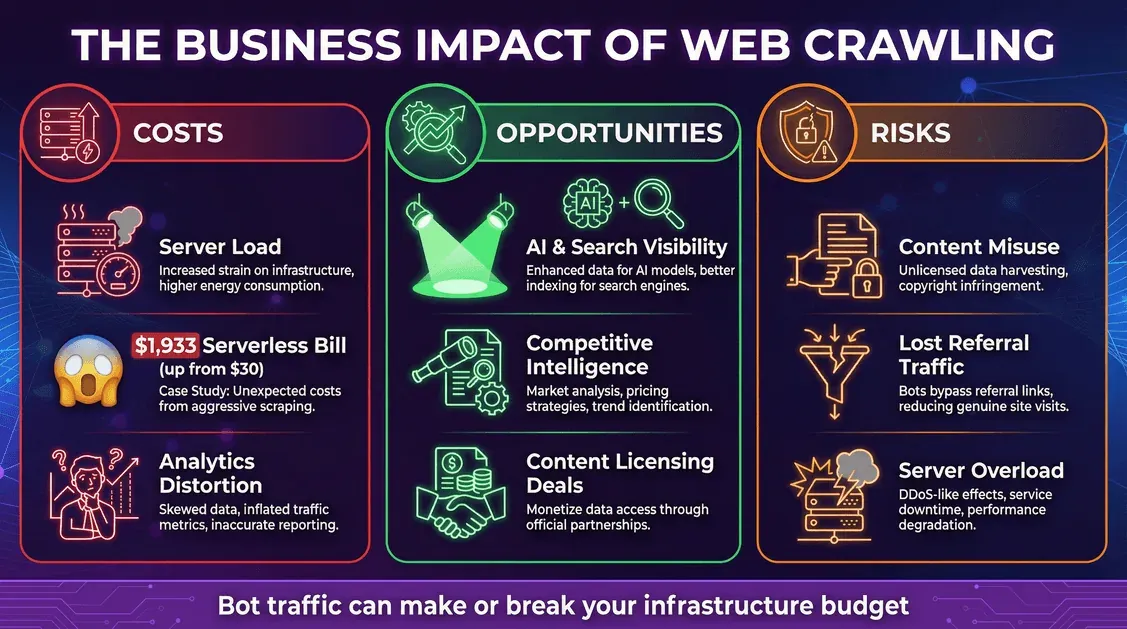
成本:基础设施和意外账单
- 服务器负载: 每一次机器人请求都会消耗 CPU、内存和带宽。
- 云服务账单: 如果你使用按量计费模式(比如无服务器),机器人可能会把费用堆得很高。有位开发者发现,Meta 的爬虫一个月生成了 1100 万次请求,导致无服务器账单飙到 1,933 美元(原本只有 30 美元)。
- 分析失真: 机器人会扭曲你的网页分析数据,让你更难判断真实用户行为。
机会:可见性与数据杠杆
- AI 和搜索可见性: 被纳入 AI 训练数据或搜索索引,能提升品牌曝光度(blog.cloudflare.com)。
- 竞争情报: 企业会用爬虫做市场研究、价格监控等工作。
- 变现: 一些出版商现在开始把内容授权给 AI 公司。
风险:内容滥用与流量流失
- 内容滥用: AI 爬虫可能把你的内容吸收到模型中,有时并没有明确授权或补偿。
- 引荐流量流失: AI 答案可能直接满足用户需求,而不把他们送到你的网站,这就叫“去中介化”。
- 安全与宕机: 激进的爬虫可能压垮服务器,导致变慢甚至宕机。
管理网页爬虫流量:最佳实践
那么,怎么防止机器人把你的午饭——或者你的云预算——吃光?
1. 优化 robots.txt
- 使用
robots.txt来允许或禁止特定机器人。大多数信誉良好的爬虫(如 Googlebot)会遵守,但很多 AI 机器人未必会遵守(blog.cloudflare.com)。 - 截至 2025 年中,大约 14% 的头部网站已经开始为 AI 机器人添加明确规则(blog.cloudflare.com)。
2. 使用机器人管理工具
- Web 应用防火墙(WAF)和机器人管理服务可以拦截或对可疑流量进行限速。
- Cloudflare 等服务提供机器人缓解功能,甚至还有面向内容创作者的“AI 审计”工具(blog.cloudflare.com)。
3. 实施速率限制和缓存
- 对来自单一机器人的高频请求进行限速。
- 尽可能向机器人返回缓存内容——不要让它们触发昂贵的无服务器函数或数据库查询(Reddit 例子)。
4. 监控并分析机器人流量
- 持续查看服务器日志。弄清楚哪些机器人在访问你、访问频率如何、何时访问。
- 为异常流量峰值设置告警。
5. 领先一步,跟上新标准
- 关注新的 meta 标签或用于 AI 使用授权的 HTTP 标头,例如
<meta name="ai:allow" content="no">。 - 关注行业倡议,例如 ContentSignals.org 和支付协议 x402。
2026 年及以后值得关注的网页爬取趋势
什么是数据抓取,以及如何在 2025 年完成 Get Started Free
网页爬取格局正在快速演变。以下是我在关注的方向,你也应该留意:
- AI 驱动的爬取只会继续上升: 预计会有更多 AI 机器人抓取更多类型的内容(文本、图片、视频)。
- 内容授权与支付标准。 “狂野西部”式的说法已经越来越不贴切。Anthropic 在 2025 年末就训练数据争议与作者达成了 15 亿美元和解,这是迄今最大的出版商与 AI 相关和解案。Meta 与 CNN、Fox News、People Inc. 和 USA Today 签下了多年内容授权协议,而 2025 年前期的 AP–Google 和 Axios–OpenAI 交易,如今已经更像模板而非例外。新的诉讼仍在不断出现——2026 年 5 月 5 日,五家出版商在曼哈顿起诉 Meta——所以法律格局远未稳定,但方向已经很清楚:内容正在被定价、付费、诉讼,而不只是被抓取。在协议层面,x402 和 ContentSignals.org 正逐渐分别成为机器支付层和机器授权层的有力候选者。
- 监管正在到来: 未来会有更多关于机器人能做什么、不能做什么的法律明确,尤其是围绕 AI 训练数据(reuters.com)。
- 内容使用的技术标准: 留意新的 meta 标签、robots.txt 扩展,以及机器可读的机器人声明。
- 出版商与 AI 的协作: 与其被动挨抓,越来越多的出版商会与 AI 公司协商结构化数据源或 API。
结论:这些网页爬取统计对你的业务意味着什么
一句话总结:网页爬取在 2026 年已经是主导力量,而且还在加速。自动化机器人——尤其是 AI 爬虫——如今已经占据了你流量中的很大一部分,它们对基础设施、预算和内容策略的影响只会越来越大。
你该怎么做?
- 预期会有大量机器人流量: 相应规划你的基础设施、预算和监控。
- 了解你的爬虫: 不是所有机器人都一样——要对不同类型采取不同策略。
- 监控你的指标: 跟踪机器人流量,就像你跟踪真人访客一样。
- 保护你的内容和钱包: 用技术控制、法律协议和新兴标准来防护。
- 利用上行收益: 被纳入 AI 和搜索索引可以提升品牌影响力——只是别忘了确保自己也从中获得价值。
- 持续关注并快速适应: 爬取格局变化很快,时刻留意新标准、监管和商业模式。
作为一个多年从事自动化和 AI 工具构建的人(现在在 Thunderbit),我可以告诉你:在这个新时代里真正能跑出来的企业,都是把网页爬取当作战略重点,而不是把它当成单纯的技术麻烦。无论你做销售、电商、营销还是房地产,理解网页爬取统计和行业基准,已经是基本功。
所以下次你打开服务器日志,看到一队机器人时,别只顾叹气然后划走。利用数据,给你的网站做基准对比,调整策略。也请记住:在 AI 时代,机器人不是“正在到来”——它们早就已经在这里了。让它们为你工作,而不是反过来。
保持警惕,保持好奇,愿你的服务器日志永远向着你。
想进一步了解网页抓取、自动化和 AI 驱动的生产力?欢迎查看 Thunderbit 的博客,那里有深度解析、操作指南和最新趋势。如果你已经准备好掌控自己的数据,不妨试试 Thunderbit Chrome 扩展 进行 AI 驱动的网页抓取——无需代码,不费劲,直接出结果。
试用 AI 网页爬虫 Get Started Free
引用与延伸阅读:




