Amazon 是全球最大的数字化市场,但如果你曾经手动收集商品价格、评论或卖家信息,就会知道这事儿就像在海滩上数沙子——又慢、又乱,最后不是晒伤,就是至少手腕酸痛。全球有超过 ,还有 ,Amazon 的数据对销售、营销和运营团队来说简直就是一座金矿。但手动收集数据?那也太 2015 了。
现在,最聪明的团队都在转向 Amazon 网页爬虫——尤其是像 这样由 AI 驱动、无需代码的工具——把原本要花好几个小时的重复工作,压缩成几分钟就能出结果的洞察。有了合适的 Amazon 网页爬虫,你就能大规模监控竞品价格、分析评论、追踪商品趋势,还能一边喝咖啡,一边感慨自己怎么没早点用上它。接下来,我们来看看一个好的 Amazon 网页爬虫该有什么能力、Thunderbit 如何把流程变得更简单,以及你该怎么把 Amazon 数据真正用到业务里。
什么是 Amazon 网页爬虫?先理解基础概念
Amazon 网页爬虫是一种可以自动从 Amazon 网站提取数据,并将其整理成结构化格式的工具——你可以把它理解成表格,而不是便利贴。简单来说,它就像一个超强助手,能读取 Amazon 页面,并提取商品名称、价格、评论、评分、ASIN、卖家信息、图片等内容 ()。不用逐条复制粘贴,爬虫只要点几下,就能抓取数百甚至数千行数据。
你可以从 Amazon 提取哪些数据?
- 商品标题和描述
- 价格(标价、促销价、折扣)
- 评分和评论数量
- ASIN,以及卖家/品牌信息
- 商品规格和库存状态
- 图片和图片 URL
- 评论文本和评论者信息
Amazon 网页爬虫的类型:
- 浏览器扩展(如 Thunderbit):无需编码,点选式操作,特别适合业务用户。
- 云平台 / API:输入 URL 或查询条件,返回数据(例如 ScrapingBee、Bright Data)。
- 自定义代码方案:使用 Python 脚本和 BeautifulSoup、Scrapy 等库——功能强,但维护成本高。
优秀的 Amazon 网页爬虫能够应对 Amazon 不断变化的页面布局、反爬机制和复杂的页面结构——这样你就不用自己折腾了。
为什么要用 Amazon 网页爬虫?核心业务价值
说实话:Amazon 的数据不只是“有更好”——对销售、营销或运营团队来说,它往往是决定成败的关键。下面看看各类团队是怎么借助 Amazon 网页爬虫领先一步的:
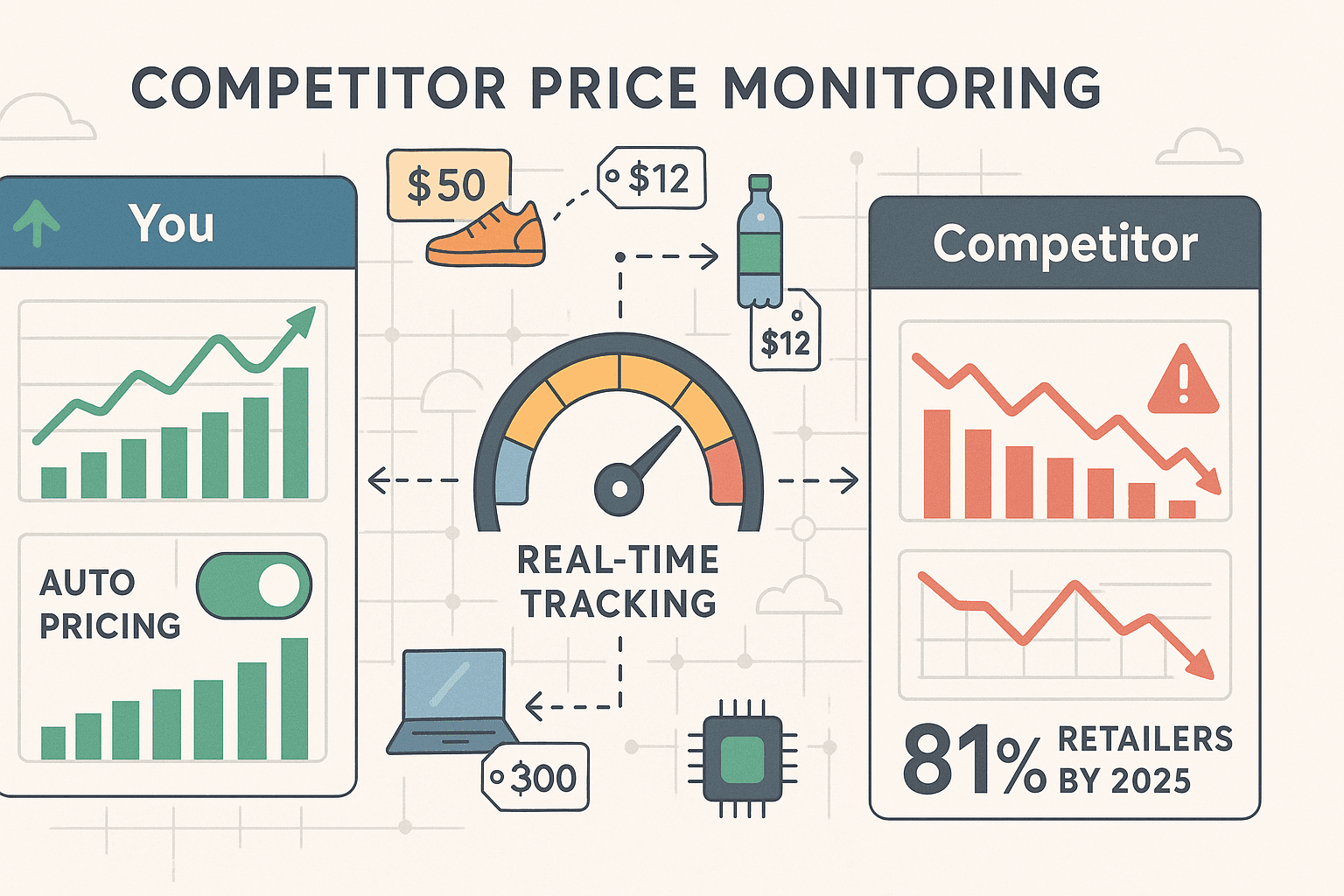
- 竞品价格监控: 实时追踪竞争对手的价格和库存。在对手还没反应过来之前,就先调整你的定价策略。。
- 市场与产品研究: 找出畅销品、捕捉趋势,并通过分析评论来优化自己的产品 ()。
- 竞品分析与对标: 比较功能、评分和评论,发现市场空白,优化你的策略。
- 评论聚合与情感分析: 收集并分析成千上万条评论,了解客户情绪,或者定位产品问题。
- 线索挖掘: 为合作和外联建立 Amazon 卖家或品牌名单 ()。
- 库存与 MAP 合规监控: 确保你的产品没有被未授权卖家恶意低价冲击。
下面快速总结一下:
| 使用场景 | 目标数据 | 业务结果 |
|---|---|---|
| 价格监控 | 价格、库存、折扣 | 保持竞争力,支持动态定价 |
| 竞品分析 | 功能、评分、评论 | 发现差距,优化产品,打磨文案 |
| 产品研究 | 畅销品、评论 | 识别趋势,优化品类组合 |
| 线索挖掘 | 卖家/品牌信息 | 建立外联名单,寻找合作伙伴 |
| 评论聚合 | 评论文本、评分 | 分析情感,改进产品 |
| MAP 合规 | 卖家/价格信息 | 执行定价政策,保护品牌价值 |
自动化 Amazon 数据收集,不只是省时间——它还能让你在速度和准确性都很重要的市场里真正领先一步。
如何选择合适的 Amazon 网页爬虫:最重要的是什么
并不是所有爬虫都一样,尤其当面对 Amazon 这种规模大、结构复杂的平台时。选型时可以重点看这些方面:
- 易用性: 非技术人员能不能很快出结果,还是得先学一整套 Python?
- 自动化与 AI: 工具会不会用 AI 自动识别字段、适配 Amazon 的变化,还是你得手动配置提取规则?
- 数据准确性与稳定性: 能不能处理动态内容、分页和反机器人限制?
- 复杂页面处理能力: 支不支持抓取子页面(比如商品详情页)和分页结果?
- 预置模板: 有没有现成的 Amazon 常见任务模板?
- 导出与集成: 能不能无额外费用导出到 Excel、Google Sheets、Airtable、Notion 或 CSV?
- 速度与可扩展性: 抓取速度有多快?大批量任务能不能用云端抓取?
- 学习成本与支持: 文档、教程和客服响应是否到位?
传统爬虫(如 Octoparse 或自定义脚本)虽然功能强,但通常需要手动配置、写代码以及持续维护。现代 AI 无代码工具(如 Thunderbit)则更强调简单、自动化和对业务友好的功能——非常适合想要结果而不是麻烦的团队。
Thunderbit 的独特优势?
- AI 驱动的字段识别(“AI 推荐字段”)
- 2 步抓取(选择字段,点击“抓取”)
- 预设 Amazon 模板
- 支持子页面和分页抓取
- 免费且不限量导出
- 价格亲民,支持响应迅速
对大多数业务用户来说,这就是最合适的平衡点。
如何使用 Thunderbit 提取 Amazon 商品与评论数据
接下来我来带你走一遍操作流程——我和成千上万 Thunderbit 用户都是这样在几分钟内抓取 Amazon 数据的:无需代码,也不用抓狂。
1. 安装 Thunderbit Chrome 扩展
前往 安装 Thunderbit。用 Google 或邮箱登录后,你会在工具栏里看到 Thunderbit ⚡ 图标。
2. 打开 Amazon 并启动 Thunderbit
进入你想抓取的 Amazon 页面——可以是商品搜索页、类目页或详情页。点击 Thunderbit 图标,选择网页爬虫工具。
3. 使用“AI 推荐字段”自动识别数据
点击 “AI 推荐字段”。Thunderbit 的 AI 会扫描页面,并自动建议相关列——比如商品名称、价格、评分、评论数、商品 URL 和图片 URL。在商品详情页上,你还可能看到标题、价格、品牌、ASIN、库存状态和卖家等字段。
4. 调整或添加字段(可选)
想要更多数据?你可以编辑字段名、修改数据类型,或者新增字段。你甚至可以直接用自然语言描述你想要的内容(例如“卖家名称”),Thunderbit 会通过它的字段 AI 提示词功能帮你抓取。
5. 启用分页或子页面抓取
如果数据分布在多个页面,打开 分页 并设置要抓取的页数。如果你想从每个商品的详情页提取更多信息,启用 子页面抓取——Thunderbit 会逐个点击进入,提取更多字段,再返回列表页。
6. 点击“抓取”,看数据自动进入表格
点击 抓取。Thunderbit 会实时高亮并提取数据,按需在不同页面和子页面之间自动跳转。几分钟后,你就会得到一张完整的数据表。
7. 预览并导出
检查提取后的表格是否准确。然后可免费导出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON。Thunderbit 会保留数据类型;如果导出到 Notion 或 Airtable,甚至还能把图片上传到你的云工作区。
就是这么简单:安装、打开、AI 推荐、抓取、导出。整个过程快到你甚至还有时间再喝一杯咖啡。
在 Thunderbit 中使用预设 Amazon 爬虫模板
Thunderbit 不只是提供 AI 推荐,它还为 Amazon 提供了 即用型爬虫模板。这些模板是针对常见任务预先配置好的方案:
- Amazon 商品爬虫: 从搜索页或类目页抓取商品标题、价格、评分、评论数、ASIN 等信息。
- Amazon 商品详情: 从单个商品页提取深度信息——规格、卖家、库存状态等。
- Amazon 评论爬虫: 从商品评论区提取评论者姓名、评论日期、星级评分、评论文本和有帮助投票数 ()。
有了模板,你几乎可以完全跳过设置步骤——只要加载模板、点击“抓取”,就完成了。相比手动配置,模板能节省大量时间,并减少出错,尤其适合重复性任务。
抓取 Amazon 子页面并处理分页
Amazon 商品目录非常庞大,数据通常分布在多个页面,或者藏在子页面里。Thunderbit 可以无缝应对这两种情况:
- 分页: 只要指定要抓取多少页,Thunderbit 就会自动点击“下一页”,把每一页的数据都抓回来。再也不用担心漏掉第 2 页、第 3 页,甚至第 20 页。
- 子页面抓取: 需要每个商品更多细节?Thunderbit 可以逐个点击进入每一项,提取额外字段(比如规格或卖家信息),再合并到主表里。这对深度调研,或者摘要信息不够用的场景特别有帮助。
Thunderbit 的 AI 会帮你处理导航逻辑,所以你无需自己写复杂的循环,也不用担心漏数据。
如何应用 Amazon 数据:销售、营销与价格监控场景
那这些 Amazon 数据到底能做什么?下面是我每周都会看到的一些真实场景:
- 动态定价: 将竞品价格输入你的定价引擎,实时调整报价。借助 Thunderbit 的定时功能,你可以自动按天或按小时抓取,始终保持数据最新。
- 商品趋势分析: 抓取畅销榜,找出正在崛起的爆款,或者识别正在增长的功能点。用这些信息指导产品开发或营销活动。
- 客户情绪: 聚合并分析评论,找出客户喜欢或讨厌你和竞品产品的哪些地方。把这些洞察用于优化产品或信息表达。
- 线索挖掘: 为你的细分领域建立 Amazon 卖家或品牌名单,用于外联、合作或销售。
- MAP 合规: 监控你的商品在 Amazon 上的价格,确保没有人低于你的最低广告价。
Thunderbit 能轻松把这些数据导出到 Excel、Google Sheets、Airtable 或 Notion,让你可以立刻接入仪表盘、报告或分析工具。
Thunderbit vs. 其他 Amazon 网页爬虫:快速对比
我们来看看 Thunderbit 和其他常见 Amazon 网页爬虫比起来表现如何:
| 功能 | Thunderbit | Octoparse | ScrapingBee | ParseHub |
|---|---|---|---|---|
| 无代码,易上手 | 是(2 步) | 可视化,但设置更多 | 否(API,需要编码) | 可视化,但仍需设置 |
| AI 字段识别 | 是 | 基于规则 | 否 | 否 |
| Amazon 模板 | 是 | 是(很多) | 否 | 是 |
| 子页面抓取 | 是(自动) | 手动设置 | 脚本式 | 手动 |
| 分页处理 | 是(自动) | 手动设置 | 脚本式 | 手动 |
| 导出格式 | Excel、Sheets、Airtable、Notion、CSV、JSON(全部免费) | CSV、Excel、JSON(API 需付费) | JSON(API) | CSV、Excel、JSON |
| 免费额度 | 是(6–10 页) | 是(有限) | 否 | 是(有限) |
| 起步价格 | 15 美元/月 | 约 119 美元/月 | 按用量计费 | 149 美元/月 |
| 支持 | 邮件、教程、YouTube | 24/7(付费) | 文档 | 文档 |
Thunderbit 的差异化优势:
- 极易上手,连非技术人员也能用
- AI 驱动的字段识别,无需后续维护
- Amazon 任务一键模板
- 可免费且不限量导出到你常用的工具
- 定价透明,价格亲民
为什么 Thunderbit 是业务团队首选的 Amazon 网页爬虫
这就是 Thunderbit 成为我首选 Amazon 网页爬虫的原因——也正因如此,越来越多销售、营销和运营团队都在迁移过来:
- 无需编程: 从销售代表到市场经理,任何人都能用。不用等 IT,也不用学 Python。
- AI 提速: 几分钟就能出结果,而不是几个小时。Thunderbit 的 AI 会适配 Amazon 的变化,所以你不用天天盯着爬虫。
- 全面支持 Amazon: 列表页、商品详情、评论、图片、分页、子页面——Thunderbit 全都能处理。
- 数据准确,维护省心: 每次都能拿到结构化、干净的数据。AI 会跟上 Amazon 的调整,你的数据管道不会轻易断掉。
- 高性价比且可扩展: 免费额度充足,付费方案也很实惠,而且没有隐藏导出费用。
- 响应迅速的支持: Thunderbit 团队回复很快,而且产品一直在持续改进。
Thunderbit 让业务用户把精力放在洞察上,而不是技术障碍上。这就是我希望自己几年前就能拥有的工具。
分步骤指南:用 Thunderbit 提取 Amazon 数据
准备开始了吗?下面是你的快速清单:
- 安装 Thunderbit: 并登录。
- 打开 Amazon: 进入你要抓取的页面(搜索结果、类目页或商品详情页)。
- 启动 Thunderbit: 点击 ⚡ 图标,选择网页爬虫。
- AI 推荐字段: 点击“AI 推荐字段”,自动识别相关列。
- 检查 / 调整字段: 按需编辑或新增字段(可选)。
- 启用分页 / 子页面: 如需多页或深度数据,可按需开启。
- 点击“抓取”: 观看 Thunderbit 实时提取数据。
- 导出数据: 选择 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON——免费且即时。
- 分析并使用: 将数据接入仪表盘、报告或分析工具。
小提示:如果是重复任务,可以用 Thunderbit 的定时功能,自动执行每天或每周的抓取。
结论与关键要点
Amazon 的数据对业务团队来说是一座宝藏——前提是你能高效地拿到它。手动抓取既慢又容易出错。现代 Amazon 网页爬虫,尤其是像 Thunderbit 这样由 AI 驱动、无需代码的工具,让数据提取变得快速、可靠,而且人人都能用。
关键要点:
- Amazon 网页爬虫可以为定价、产品研究、竞品分析等场景解锁实时洞察。
- Thunderbit 在易用性、AI 自动化、模板和适合业务场景的导出方面表现突出。
- 有了 Thunderbit,你可以在几分钟内从“我需要这份数据”变成“这是我的表格”——无需编码,也没有压力。
准备好亲自体验差异了吗?,免费抓取一次,感受 Amazon 数据提取本该有的样子。想了解更多技巧和深度解析,请查看 。
常见问题
1. 什么是 Amazon 网页爬虫,为什么我需要它?
Amazon 网页爬虫是一种可以自动从 Amazon 提取数据(如商品价格、评论、评分和卖家信息),并将其整理到电子表格或数据库中的工具。它能帮你节省数小时的手动复制粘贴时间,并支持实时业务洞察。
2. Thunderbit 和其他 Amazon 网页爬虫相比有什么不同?
Thunderbit 使用 AI 自动识别字段、处理分页和子页面抓取,并为 Amazon 任务提供一键模板。它专为非技术用户设计,支持免费导出,价格也很实惠。
3. Thunderbit 能处理 Amazon 复杂页面吗,比如多页结果或商品详情页?
可以。Thunderbit 同时支持分页抓取(抓取多页)和子页面抓取(点击进入每个商品获取更多细节),而且只需简单开关,无需手动配置。
4. 如何从 Thunderbit 导出 Amazon 数据?
抓取完成后,你可以免费将数据导出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON。Thunderbit 会保留数据类型,并在支持的情况下将图片上传到云工作区。
5. 使用像 Thunderbit 这样的 Amazon 网页爬虫合法吗,安全吗?
Thunderbit 只抓取公开可见的数据,并在你的浏览器中运行,兼顾隐私和安全。请始终负责任地使用爬虫,遵守 Amazon 的服务条款,并避免给其服务器造成过大负载。
准备好解锁 Amazon 数据了吗?,今天就开始更聪明地抓取。
了解更多