
Let’s be honest—Amazon is basically the mall, the supermarket, and the electronics store for the entire internet. If you’re in sales, e-commerce, or operations, you already know that what happens on Amazon doesn’t stay on Amazon—it shapes your pricing, your inventory, and even your next big product launch. But here’s the catch: all those juicy product details, prices, ratings, and reviews are locked behind a web interface built for shoppers, not for data-hungry teams. So, how do you get your hands on that data without spending your weekends copying and pasting like it’s 1999?
That’s where web scraping comes in. In this guide, I’ll show you two ways to extract Amazon product data: the classic “roll up your sleeves and code it in Python” approach, and the modern “let AI do the heavy lifting” route with a no code web scraper like . I’ll walk through real Python code (with all the gotchas and workarounds), then show you how Thunderbit can get you the same data in just a couple of clicks—no coding required. Whether you’re a developer, a business analyst, or just someone who’s tired of manual data entry, I’ve got you covered.
Why Extract Amazon Product Data? (amazon scraper python, web scraping with python)
Amazon isn’t just the world’s biggest online retailer—it’s also the world’s biggest open-air market for competitive intelligence. With and , Amazon is a goldmine for anyone who wants to:

- Monitor prices (and adjust yours in real time)
- Analyze competitors (track their new launches, ratings, and reviews)
- Generate leads (find sellers, suppliers, or even potential partners)
- Forecast demand (by watching stock levels and sales ranks)
- Spot market trends (by mining reviews and search results)
And it’s not just theory—real businesses are seeing real ROI. For example, one electronics retailer used scraped Amazon pricing data to , while another brand saw a after automating competitor price tracking.
Here’s a quick table of use cases and the kind of ROI you can expect:
| Use Case | Who Uses It | Typical ROI / Benefit |
|---|---|---|
| Price Monitoring | E-commerce, Ops | 15%+ profit margin boost, 4% sales lift, 30% less analyst time |
| Competitor Analysis | Sales, Product, Ops | Faster price adjustments, improved competitiveness |
| Market Research (Reviews) | Product, Marketing | Faster product iteration, better ad copy, SEO insights |
| Lead Generation | Sales | 3,000+ leads/month, 8+ hours saved per rep per week |
| Inventory & Demand Forecast | Ops, Supply Chain | 20% reduction in overstock, fewer stock-outs |
| Trend Spotting | Marketing, Execs | Early detection of hot products and categories |
And here’s the kicker: now report measurable value from data analytics. If you’re not scraping Amazon, you’re leaving insights (and money) on the table.
Overview: Amazon Scraper Python vs. No Code Web Scraper Tools
There are two main ways to get Amazon data out of the browser and into your spreadsheets or dashboards:
-
Amazon Scraper Python (web scraping with python):
Write your own script using Python libraries like Requests and BeautifulSoup. This gives you full control, but you’ll need to know how to code, handle anti-bot measures, and maintain your script as Amazon changes its site.
-
No Code Web Scraper Tools (like Thunderbit):
Use a tool that lets you point, click, and extract data—no programming required. Modern tools like even use AI to figure out what data to grab, handle subpages and pagination, and export straight to Excel or Google Sheets.
Here’s how they stack up:
| Criteria | Python Scraper | No Code (Thunderbit) |
|---|---|---|
| Setup Time | High (install, code, debug) | Low (install extension) |
| Skill Needed | Coding required | None (point & click) |
| Flexibility | Unlimited | High for common use cases |
| Maintenance | You fix code | Tool updates itself |
| Anti-bot Handling | You handle proxies, headers | Built-in, handled for you |
| Scalability | Manual (threads, proxies) | Cloud scraping, parallelized |
| Data Export | Custom (CSV, Excel, DB) | One-click to Excel, Sheets |
| Cost | Free (your time + proxies) | Freemium, pay for scale |
In the next sections, I’ll walk you through both approaches—first, how to build an Amazon scraper in Python (with real code), then how to do the same thing with Thunderbit’s AI web scraper.
Getting Started with Amazon Scraper Python: Prerequisites & Setup
Before we dive into code, let’s get your environment set up.
You’ll need:
- Python 3.x (download from )
- A code editor (I like VS Code, but anything works)
- The following libraries:
requests(for HTTP requests)beautifulsoup4(for HTML parsing)lxml(fast HTML parser)pandas(for data tables/export)re(regular expressions, built-in)
Install the libraries:
1pip install requests beautifulsoup4 lxml pandasProject setup:
- Create a new folder for your project.
- Open your editor, create a new Python file (e.g.,
amazon_scraper.py). - You’re ready to go!
Step-by-Step: Web Scraping with Python for Amazon Product Data
Let’s walk through scraping a single Amazon product page. (Don’t worry, we’ll get to scraping multiple products and pages in a bit.)
1. Sending Requests and Fetching HTML
First, let’s fetch the HTML for a product page. (Replace the URL with any Amazon product.)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)Heads up: This basic request is likely to get blocked by Amazon. You might see a 503 error or a CAPTCHA instead of the product page. Why? Because Amazon knows you’re not a real browser.
Handling Amazon’s Anti-Bot Measures
Amazon is not a fan of bots. To avoid getting blocked, you’ll need to:
- Set a User-Agent header (pretend to be Chrome or Firefox)
- Rotate User-Agents (don’t use the same one every time)
- Throttle your requests (add random delays)
- Use proxies (for large-scale scraping)
Here’s how to set headers:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)Want to get fancy? Use a list of User-Agents and rotate them for each request. For big jobs, you’ll want to use a proxy service (there are plenty out there), but for small-scale scraping, headers and delays are usually enough.
Extracting Key Product Fields
Once you have the HTML, it’s time to parse it with BeautifulSoup.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")Now, let’s extract the good stuff:
Product Title
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else NonePrice
Amazon’s price can be in a few places. Try these:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textRating and Review Count
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # e.g., "1,554 ratings"Main Image URL
Amazon sometimes hides high-res images in JSON inside the HTML. Here’s a quick regex approach:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else NoneOr, grab the main image tag:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else NoneProduct Details
Specs like brand, weight, and dimensions are usually in a table:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueOr, if Amazon uses the “detailBullets” format:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()Print your results:
1print("Title:", product_title)
2print("Price:", price)
3print("Rating:", rating, "based on", reviews_count, "reviews")
4print("Main image URL:", main_image_url)
5print("Details:", details)Scraping Multiple Products and Handling Pagination
One product is nice, but you probably want a whole list. Here’s how to scrape search results and multiple pages.
Get Product Links from a Search Page
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)Handle Pagination
Amazon’s search URLs use &page=2, &page=3, etc.
1for page in range(1, 6): # scrape first 5 pages
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... extract product links as above ...Loop Through Product Pages and Export to CSV
Collect your product data in a list of dictionaries, then use pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # list of dicts
3df.to_csv("amazon_products.csv", index=False)Or to Excel:
1df.to_excel("amazon_products.xlsx", index=False)Best Practices for Amazon Scraper Python Projects
Let’s be real—Amazon is constantly changing its site and fighting scrapers. Here’s how to keep your project running:
- Rotate headers and User-Agents (use a library like
fake-useragent) - Use proxies for large-scale scraping
- Throttle requests (random
time.sleep()between requests) - Handle errors gracefully (retry on 503, back off if blocked)
- Write flexible parsing logic (look for multiple selectors per field)
- Monitor for HTML changes (if your script suddenly returns
Nonefor everything, check the page) - Respect robots.txt (Amazon disallows scraping many sections—scrape responsibly)
- Clean your data as you go (strip currency symbols, commas, whitespace)
- Stay connected to the community (forums, Stack Overflow, Reddit’s r/webscraping)
Checklist for maintaining your scraper:
- [ ] Rotate User-Agents and headers
- [ ] Use proxies if scraping at scale
- [ ] Add random delays
- [ ] Modularize your code for easy updates
- [ ] Monitor for bans or CAPTCHAs
- [ ] Export data regularly
- [ ] Document your selectors and logic
For a deeper dive, check out my .
The No Code Alternative: Scraping Amazon with Thunderbit AI Web Scraper
Okay, so you’ve seen the Python way. But what if you don’t want to code—or you just want to get the data in two clicks and move on with your life? That’s where comes in.
Thunderbit is an AI web scraper Chrome Extension that lets you extract Amazon product data (and data from pretty much any website) with zero coding. Here’s why I love it:
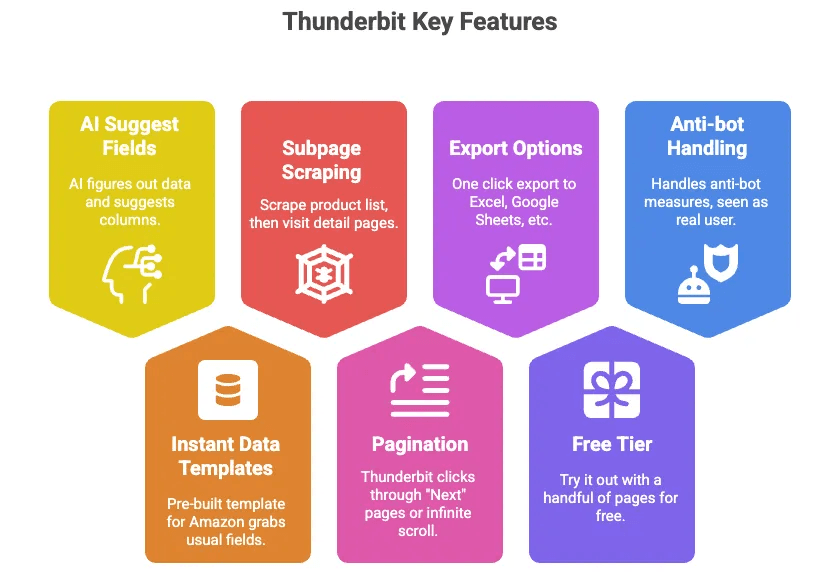
- AI Suggest Fields: Just click a button, and Thunderbit’s AI figures out what data is on the page and suggests columns (like Title, Price, Rating, etc.).
- Instant Data Templates: For Amazon, there’s a pre-built template that grabs all the usual fields—no setup needed.
- Subpage Scraping: Scrape a list of products, then let Thunderbit visit each product’s detail page and pull more info automatically.
- Pagination: Thunderbit can click through “Next” pages or infinite scroll for you.
- Export to Excel, Google Sheets, Airtable, Notion: One click, and your data is ready to use.
- Free Tier: Try it out with a handful of pages for free.
- Handles anti-bot stuff for you: Since it runs in your browser (or in the cloud), Amazon sees it as a real user.
Step-by-Step: Using Thunderbit to Scrape Amazon Product Data
Here’s how easy it is:
-
Install Thunderbit:
Download the and sign in.
-
Open Amazon:
Go to the Amazon page you want to scrape (search results, product detail, whatever).
-
Click “AI Suggest Fields” or Use a Template:
Thunderbit will suggest columns to extract (or you can pick the Amazon Product template).
-
Review Columns:
Adjust the columns if you want (add/remove fields, rename, etc.).
-
Click “Scrape”:
Thunderbit grabs the data from the page and shows it in a table.
-
Handle Subpages & Pagination:
If you scraped a list, click “Scrape Subpages” to visit each product’s detail page and pull more info. Thunderbit can also auto-click through “Next” pages.
-
Export Your Data:
Click “Export to Excel” or “Export to Google Sheets.” Done.
-
(Optional) Schedule Scraping:
Need this data every day? Use Thunderbit’s scheduler to automate it.
That’s it. No code, no debugging, no proxies, no headaches. For a visual walkthrough, check out the or the .
Amazon Scraper Python vs. No Code Web Scraper: Side-by-Side Comparison
Let’s put it all together:
| Criteria | Python Scraper | Thunderbit (No Code) |
|---|---|---|
| Setup Time | High (install, code, debug) | Low (install extension) |
| Skill Needed | Coding required | None (point & click) |
| Flexibility | Unlimited | High for common use cases |
| Maintenance | You fix code | Tool updates itself |
| Anti-bot Handling | You handle proxies, headers | Built-in, handled for you |
| Scalability | Manual (threads, proxies) | Cloud scraping, parallelized |
| Data Export | Custom (CSV, Excel, DB) | One-click to Excel, Sheets |
| Cost | Free (your time + proxies) | Freemium, pay for scale |
| Best For | Developers, custom needs | Business users, fast results |
If you’re a developer who loves tinkering and needs something super custom, Python is your friend. If you want speed, simplicity, and zero code, Thunderbit is the way to go.
When to Choose Python, No Code, or AI Web Scraper for Amazon Data
Go with Python if:
- You need custom logic or want to integrate scraping into your backend systems
- You’re scraping at massive scale (tens of thousands of products)
- You want to learn how scraping works under the hood
Go with Thunderbit (no code, AI web scraper) if:
- You want data fast, with no coding
- You’re a business user, analyst, or marketer
- You need to empower your team to get data themselves
- You want to avoid the hassle of proxies, anti-bot measures, and maintenance
Use both if:
- You want to prototype quickly with Thunderbit, then build a custom Python solution for production
- You want to use Thunderbit for data collection and Python for data cleaning/analysis
For most business users, Thunderbit will cover 90% of your Amazon scraping needs in a fraction of the time. For the other 10%—the super custom, large-scale, or deeply integrated stuff—Python is still king.
Conclusion & Key Takeaways
Scraping Amazon product data is a superpower for any sales, e-commerce, or operations team. Whether you’re tracking prices, analyzing competitors, or just trying to save your team from endless copy-paste, there’s a solution for you.
- Python scraping gives you full control, but comes with a learning curve and ongoing maintenance.
- No code web scrapers like Thunderbit make Amazon data extraction accessible to everyone—no coding, no headaches, just results.
- The best approach? Use the tool that fits your skills, your timeline, and your business goals.
If you’re curious, give Thunderbit a try—it’s free to start, and you’ll be amazed how quickly you can get the data you need. And if you’re a developer, don’t be afraid to mix and match: sometimes the fastest way to build is to let the AI do the boring parts for you.
FAQs
1. Why would a business want to scrape Amazon product data?
Scraping Amazon allows businesses to monitor prices, analyze competitors, gather reviews for product research, forecast demand, and generate sales leads. With over 600 million products and nearly 2 million sellers on Amazon, it’s a rich source of competitive intelligence.
2. What are the main differences between using Python and no-code tools like Thunderbit for scraping Amazon?
Python scrapers offer maximum flexibility but require coding skills, setup time, and ongoing maintenance. Thunderbit, a no-code AI web scraper, lets users extract Amazon data instantly through a Chrome extension—no coding required, with built-in anti-bot handling and export options to Excel or Sheets.
3. Is it legal to scrape data from Amazon?
Amazon’s terms of service generally prohibit scraping, and they actively implement anti-bot measures. However, many businesses still scrape publicly available data while ensuring they operate responsibly, such as respecting rate limits and avoiding excessive requests.
4. What kind of data can I extract from Amazon using web scraping tools?
Common data fields include product titles, prices, ratings, review counts, images, product specs, availability, and even seller information. Thunderbit also supports subpage scraping and pagination to capture data across multiple listings and pages.
5. When should I choose Python scraping over a tool like Thunderbit (or vice versa)?
Use Python if you need full control, custom logic, or plan to integrate scraping into backend systems. Use Thunderbit if you want fast results without coding, need to scale easily, or are a business user looking for a low-maintenance solution.
Want to go deeper? Check out these resources:
Happy scraping—and may your spreadsheets always be up to date.