Simple Twitter post scraper














Unlock Twitter post data with Thunderbit
Effortlessly extract valuable data from Twitter posts with just a few clicks.
Get clean Twitter post data, instantly
Tired of messy, unstructured tweet data? Thunderbit automatically cleans and formats tweet text, usernames, timestamps, like counts, and more as it extracts. Get structured, analysis-ready data without any manual cleaning required.
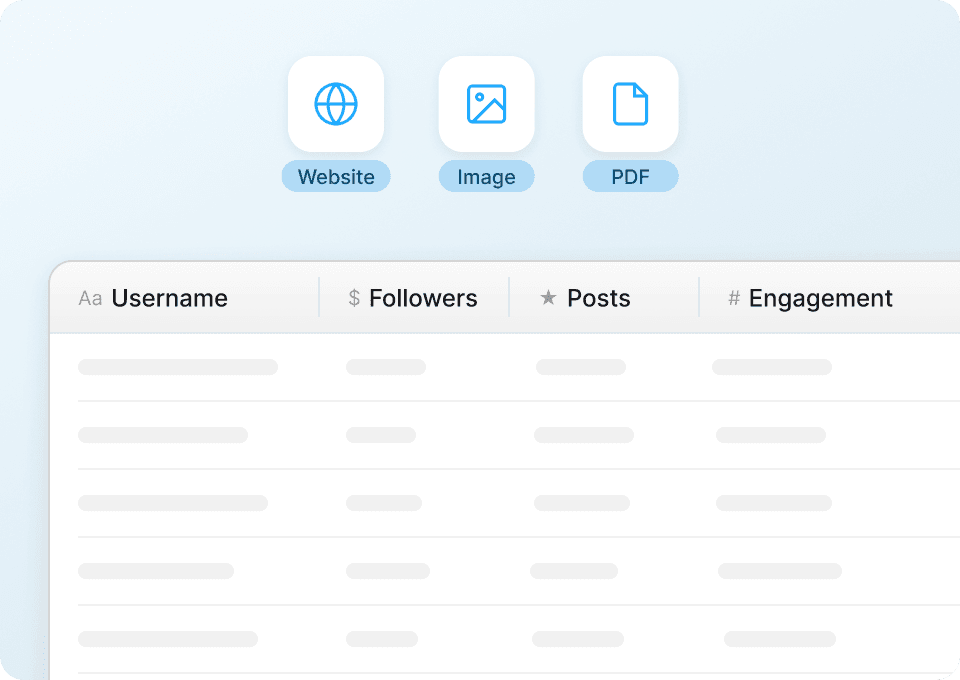
Export Twitter post data, one click
Stop wasting time copying and pasting tweet data. With Thunderbit, export your scraped Twitter posts directly to Google Sheets, Notion, Airtable, or Excel in a single click. Analyze tweet text, user handles, retweet counts, and more in your favorite tools, instantly.
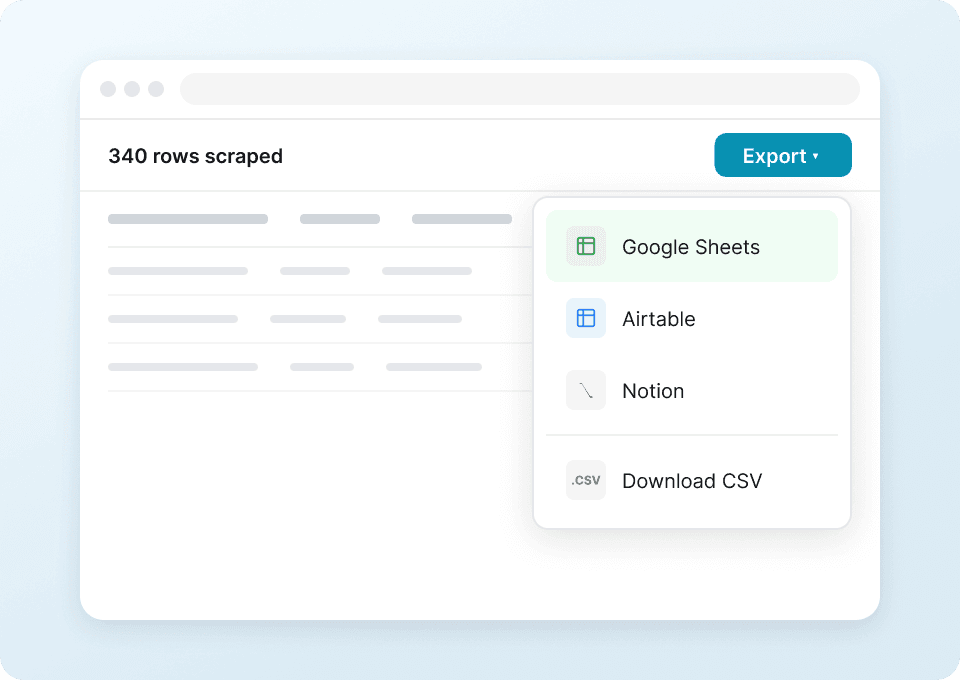
Two-click Twitter post data extraction
Forget complicated setups and coding. Thunderbit lets you extract data from Twitter posts in just two clicks. Simply point to the fields you want — tweet text, username, like count — and click to extract. It's that simple.
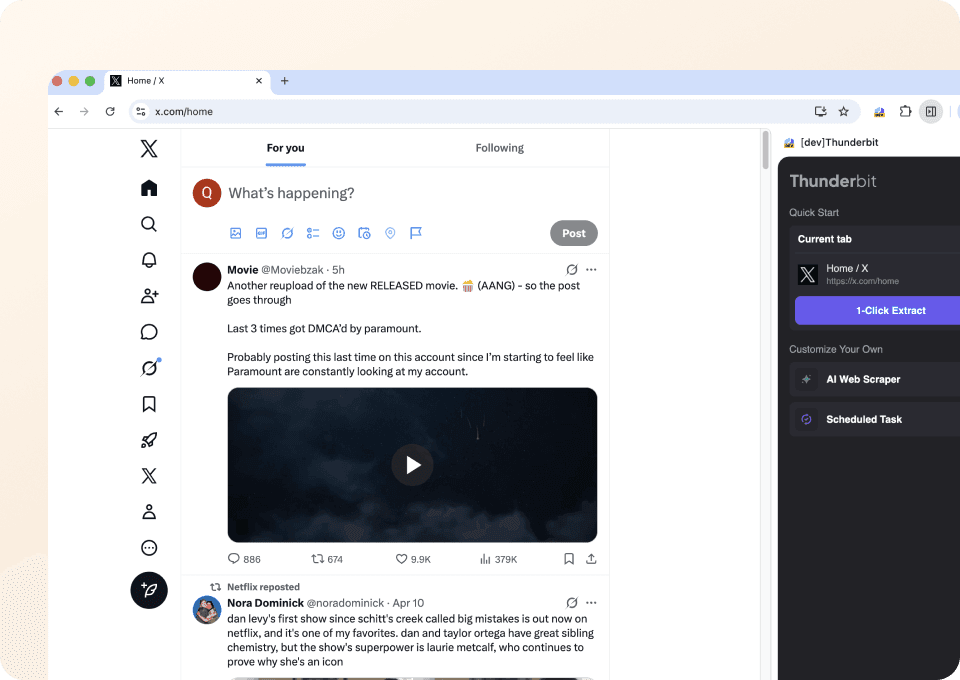
Why is Thunderbit different from traditional Twitter post scrapers?
Extract data from twitter-post without the headaches of traditional scrapers.
Traditional scrapers
The old way of doing thingsThunderbit AI
The smarter approachDon't just take our word for it
See what our users have to say about Thunderbit.





Frequently asked questions
Related use cases
Explore more use cases of Thunderbit's web scraper.

HKTVmall Scraper
Extract product names, prices, ratings, and more from HKTVmall listings in 2 clicks — no coding required. Export directly to Excel, Google Sheets, or Notion and turn HKTVmall data into actionable insights.
Learn more ->Substack scraper
Extract Substack subscriber counts, article titles, and publication descriptions in 2 clicks — then export to Excel, Google Sheets, or Notion. No code needed; Thunderbit's AI handles the structuring for you.
Learn more ->
ReverseAustralia Scraper
The Thunderbit ReverseAustralia Scraper lets you extract data from ReverseAustralia complaint and comment pages. Use AI-powered field suggestions to quickly gather phone numbers, complaint descriptions, comment texts, user names, and more for analysis or research. Ideal for marketers, researchers, and businesses seeking structured feedback data.
Learn more ->
iBegin Scraper
The Thunderbit iBegin Scraper lets you extract business search results and detailed business information from the iBegin website. Use AI-powered field suggestions to quickly gather business names, contact details, addresses, ratings, and more for lead generation, research, or marketing analysis.
Learn more ->
White Pages Scraper
The Thunderbit White Pages Scraper lets you extract data from White Pages phone and business listings with AI-powered field suggestions. Gather names, phone numbers, addresses, and website URLs for lead generation, marketing, or research in just a few clicks.
Learn more ->
UpCity Scraper
The Thunderbit UpCity Scraper lets you extract data from UpCity's advertising agency listings and provider reviews. Use AI-powered field suggestions to quickly gather agency names, locations, ratings, contact info, and detailed review content for analysis or research. Ideal for marketers, researchers, and business owners seeking structured UpCity data.
Learn more ->Ready to supercharge your data extraction?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Free trial provides unlimited credits for 8 webpages.



