Substack scraper

Trusted by professionals at leading companies














Unlock Substack data with Thunderbit
Send Substack data directly to your apps
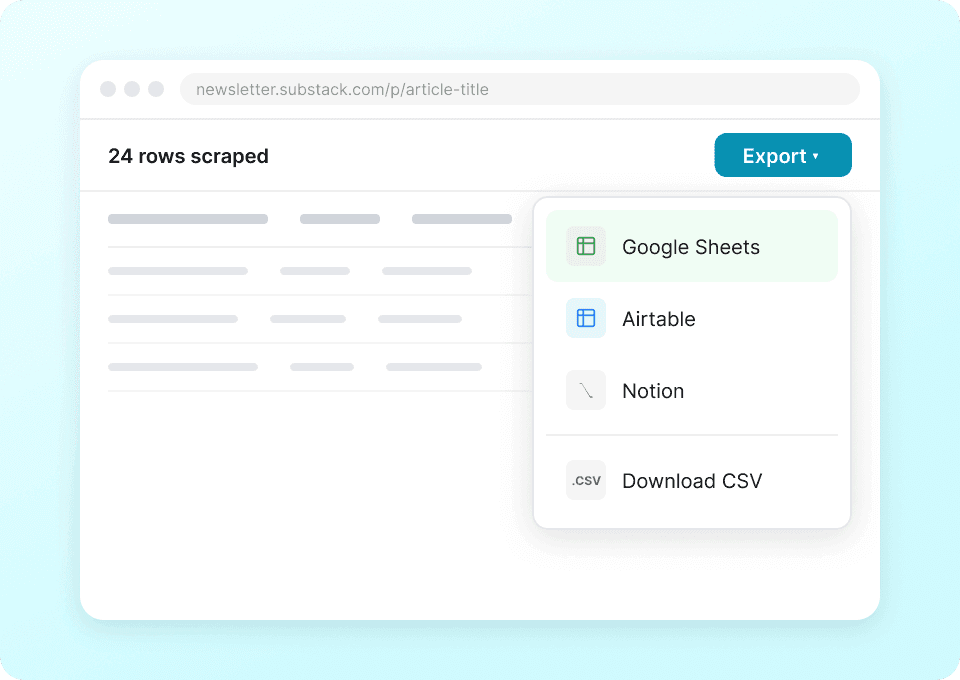
Stop manually copying and pasting Substack publication details like author name, article title, and subscriber count. With Thunderbit, just one click sends your extracted data directly to Google Sheets, Notion, or Airtable. Analyze publication trends and content performance without the tedious manual work.
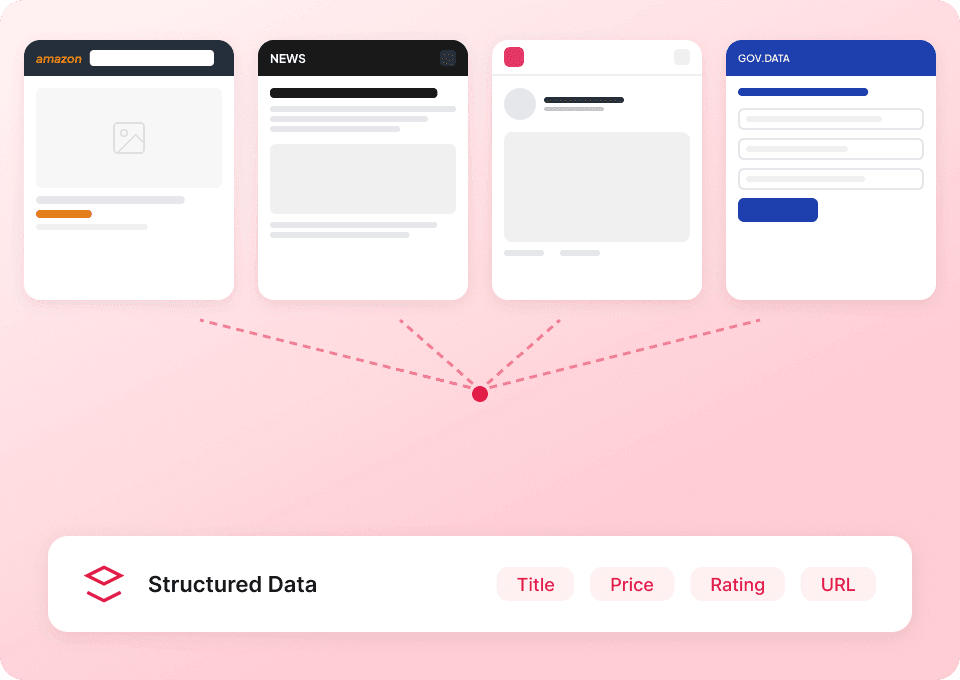
One scraper for Substack and beyond
Don't get stuck using a different scraper for every website. Thunderbit works on Substack right out of the box, and includes over 50 pre-built templates for other popular platforms. Extract publication descriptions, article content, and more, then use the same tool to gather data from anywhere else.
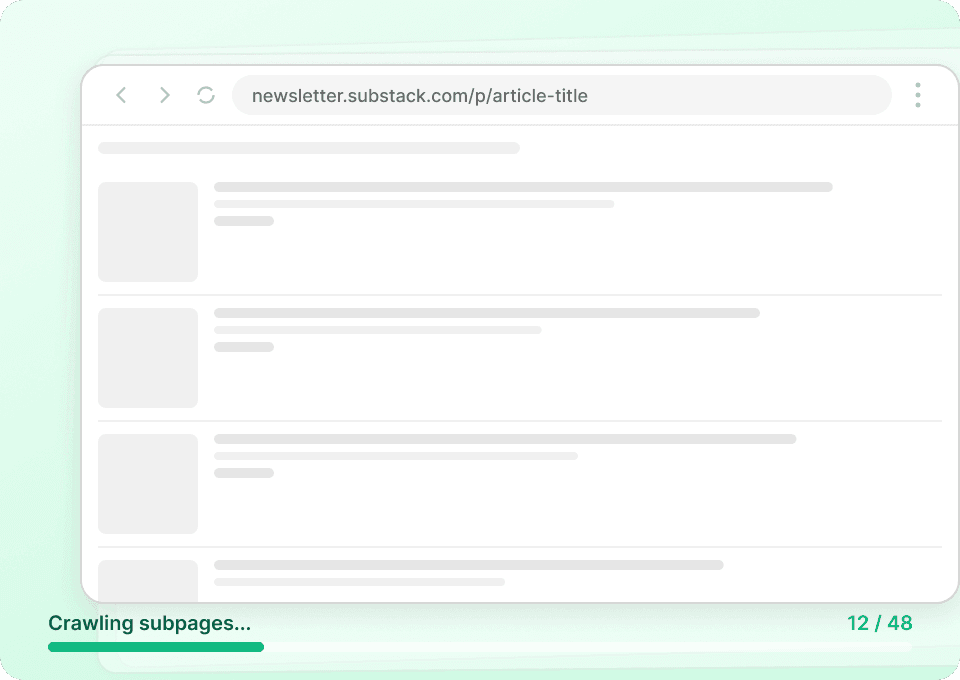
Get the full Substack story
Substack publication listing pages only show summaries. Thunderbit automatically visits each article subpage to extract the full content, giving you a complete dataset. Get the entire article title, author name, publication name, and article content in one go.
Struggling to scrape Substack effectively?
See why Thunderbit beats traditional scrapers for substack data.
Traditional scrapers
The old way of doing thingsThunderbit
The smarter approachDon't just take our word for it
See what our users have to say about Thunderbit.






Frequently asked questions
Related use cases
Explore more use cases of Thunderbit's web scraper.

United Airlines scraper
Point and click to collect United Airlines flight data like flight number, arrival time, and departure airport — Thunderbit AI handles the rest.
Learn more ->
HKTVmall Scraper
Collect product names, prices, and even customer ratings from HKTVmall listings with just a couple of clicks — no complex setup required.
Learn more ->Tradera Scraper
The Thunderbit Tradera Scraper lets you extract data from Tradera listings and product pages with ease. Use AI-powered field suggestions to gather product names, prices, categories, images, and descriptions for analysis or inventory management. Ideal for e-commerce sellers, collectors, and researchers seeking structured Tradera data.
Learn more ->
Rakuten Travel Scraper
The Thunderbit Rakuten Travel Scraper lets you extract data from Rakuten Travel hotel listings and details pages. Use AI-powered field suggestions to quickly gather hotel names, prices, ratings, room types, and amenities for research or travel planning. Ideal for travel agents, researchers, and businesses seeking structured travel data.
Learn more ->DialIndia Scraper
The Thunderbit DialIndia Scraper lets you extract data from DialIndia's business profiles and travel directories with AI-powered field suggestions. Gather business names, contact details, locations, and descriptions for research, marketing, or lead generation in just a few clicks.
Learn more ->
White Pages Scraper
The Thunderbit White Pages Scraper lets you extract data from White Pages phone and business listings with AI-powered field suggestions. Gather names, phone numbers, addresses, and website URLs for lead generation, marketing, or research in just a few clicks.
Learn more ->Ready to supercharge your data extraction?
Join 100,000+ professionals already using Thunderbit to automate their web scraping workflows.
Free trial provides unlimited credits for 8 webpages.