Tumblr Scraper
Trusted by professionals at leading companies














Unlock Tumblr data with Thunderbit
Effortlessly extract tumblr data like post content and like counts.
Get the full Tumblr story
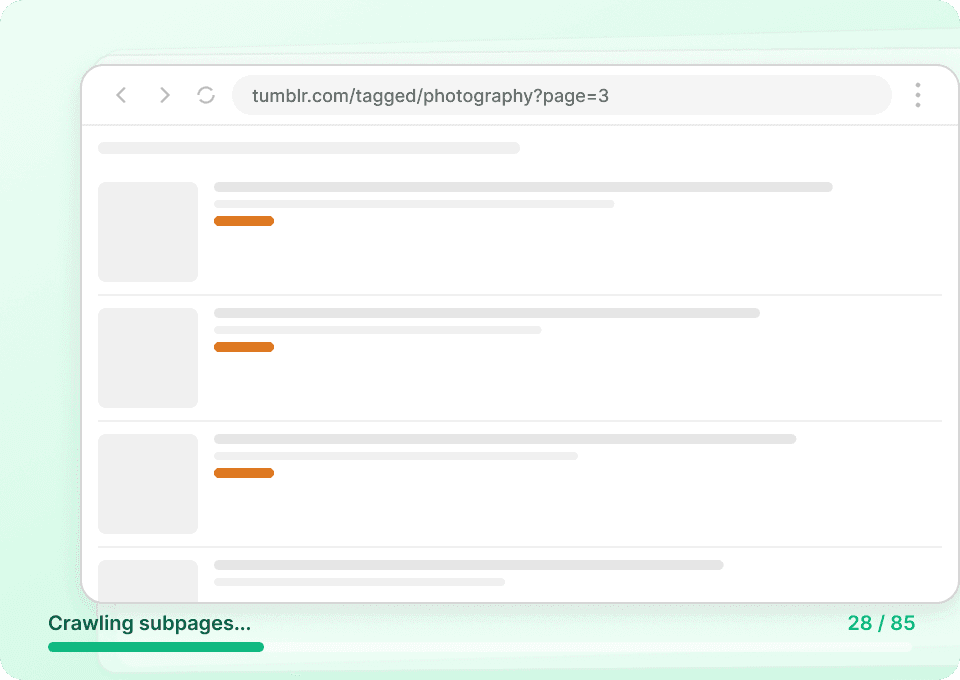
Tumblr listing pages only show snippets. To get the full picture, you need the entire post content, author details, and all the associated data. Thunderbit automatically visits each linked subpage, extracts the details, and appends it as new columns, so you can easily grab post_id, post_date, and more without manual clicking.
Automate your Tumblr data collection
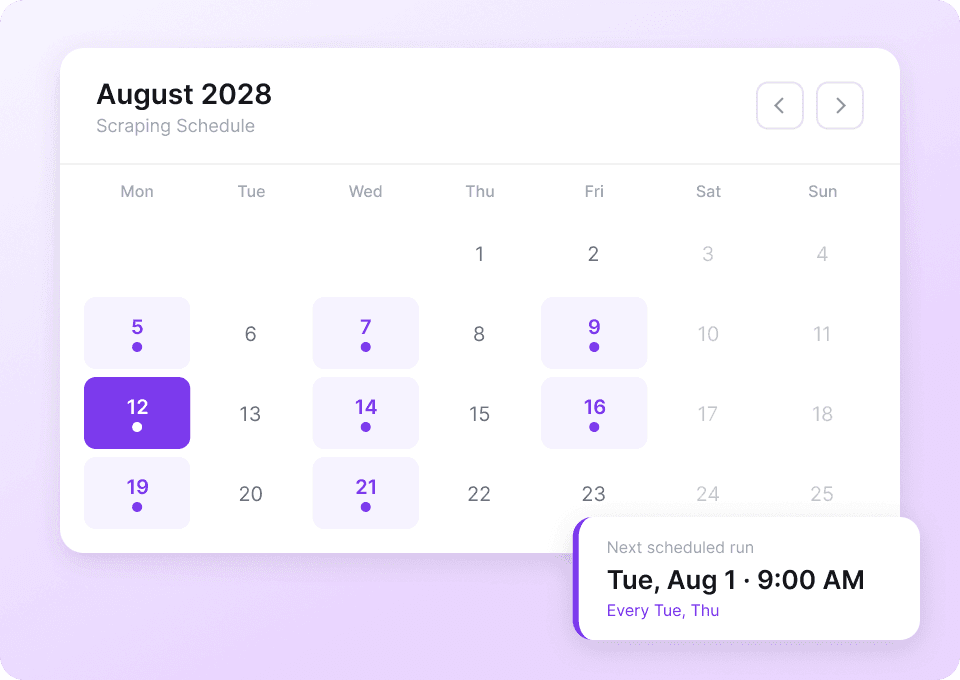
Tumblr data is constantly changing. Manually scraping the same blogs over and over is a chore. With Thunderbit's scheduled scraping, you can set up recurring tasks on autopilot. Get fresh data like like_count and post_content delivered directly to Google Sheets without lifting a finger.
Scrape Tumblr posts in two clicks
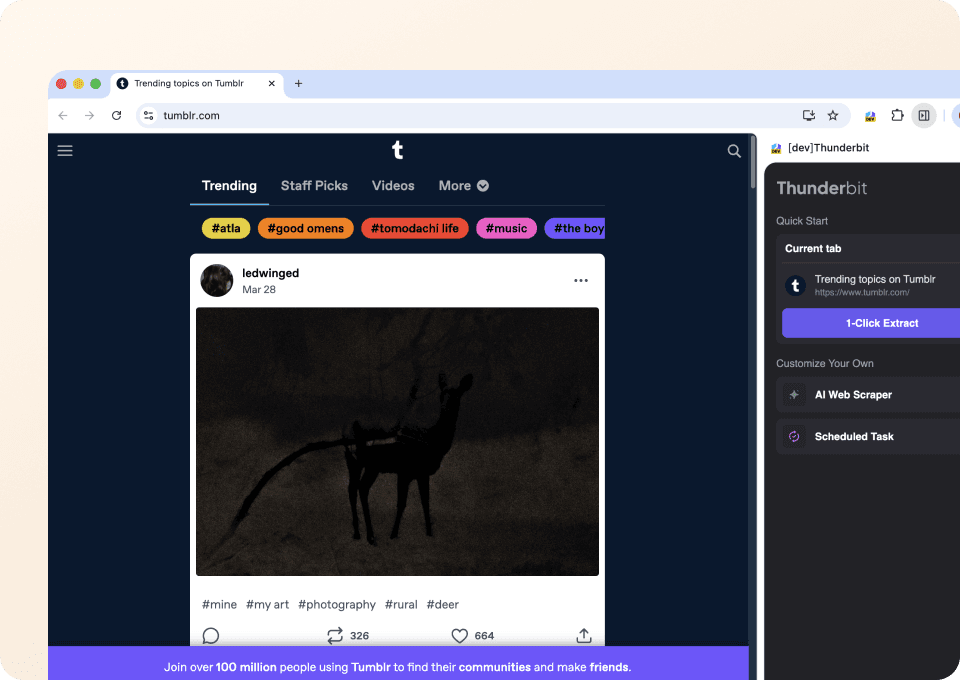
Forget complicated code or CSS selectors. Thunderbit lets you extract tumblr data in just two clicks. Simply point at the data you want, and Thunderbit's semantic AI detects the relevant fields (like post_type and post_author), then extracts it. No coding needed to get the data you need from tumblr.
Why is Thunderbit different from traditional tumblr scrapers?
Extract Tumblr data effortlessly, even when layouts shift or change unexpectedly.
Traditional scrapers
The old way of doing thingsThunderbit AI
The smarter approachDon't just take our word for it
See what our users have to say about Thunderbit.






Frequently asked questions
Related use cases
Explore more use cases of Thunderbit's web scraper.

People-Search Scraper
The Thunderbit People-Search Scraper lets you extract structured data from People-Search profiles and reverse phone lookup pages. Use AI-powered field suggestions to quickly gather names, locations, phone numbers, emails, and more for research, marketing, or lead generation. Ideal for marketers, researchers, and businesses seeking public records and contact details.
Learn more ->
Tieba Scraper
The Thunderbit Tieba Scraper enables you to extract data from Baidu Tieba, including trending topics and forum categories. Use AI-powered field suggestions to quickly gather topic names, URLs, post counts, and user activity for research, marketing, or content creation. Ideal for analyzing social media trends and discussions on Tieba.
Learn more ->
UNIQLO Scraper
Harvest Uniqlo product data like names, prices, and available sizes with just 2 clicks, thanks to Thunderbit's Chrome extension.
Learn more ->
United Airlines scraper
Point and click to collect United Airlines flight data like flight number, arrival time, and departure airport — Thunderbit AI handles the rest.
Learn more ->
BestPrice GR Scraper
Thunderbit's AI-powered BestPrice GR Scraper enables you to extract product listings, prices, and detailed information from BestPrice.gr in just a few clicks. Perfect for sales, marketing, and e-commerce teams looking to gather structured data quickly and efficiently.
Learn more ->
UpCity Scraper
The Thunderbit UpCity Scraper lets you extract data from UpCity's advertising agency listings and provider reviews. Use AI-powered field suggestions to quickly gather agency names, locations, ratings, contact info, and detailed review content for analysis or research. Ideal for marketers, researchers, and business owners seeking structured UpCity data.
Learn more ->Ready to supercharge your data extraction?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Free trial provides unlimited credits for 8 webpages.