Next Scraper
Trusted by professionals at leading companies














Effortlessly extract product data on Next
Thunderbit lets you scrape product data, simply and reliably from next.
Get the full product story
Listing pages only show the basics. Get the full story from every product page on next. Thunderbit automatically visits each subpage, extracting details like full descriptions, available colours, and high-resolution image URLs, then adds them as columns alongside product names and prices.
Clean up product data automatically
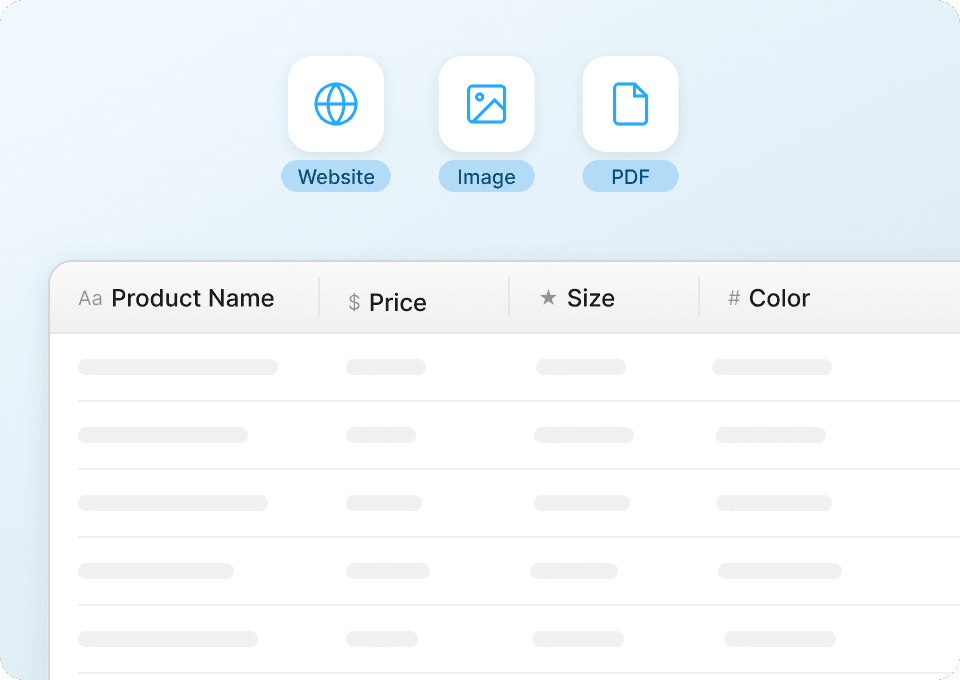
Raw data is messy and time-consuming to clean. Thunderbit automatically structures and formats product data as it scrapes from next. Export clean product names, prices, descriptions, and availability directly to Google Sheets or Notion, ready for analysis or use.
Adapts to Next layout changes
Scrapers that break after every website update are a headache. Thunderbit understands page content semantically, not by fixed selectors. When next changes its layout, Thunderbit adapts automatically so you keep scraping product data without interruption.

Why is Thunderbit different from traditional next scrapers?
Thunderbit adapts to change, unlike brittle traditional scraping methods.
Traditional scrapers
The old way of doing thingsThunderbit Ai
The smarter approachDon't just take our word for it
See what our users have to say about Thunderbit.






Frequently asked questions
Related use cases
Explore more use cases of Thunderbit's web scraper.

Tieba Scraper
The Thunderbit Tieba Scraper enables you to extract data from Baidu Tieba, including trending topics and forum categories. Use AI-powered field suggestions to quickly gather topic names, URLs, post counts, and user activity for research, marketing, or content creation. Ideal for analyzing social media trends and discussions on Tieba.
Learn more ->On the Beach Scraper
The Thunderbit On the Beach Scraper lets you extract holiday and hotel listings, prices, ratings, and more from On the Beach in just two clicks. Use AI-powered field suggestions to quickly collect and organize travel data for analysis, comparison, or planning. Ideal for travel professionals, analysts, and vacation planners.
Learn more ->
HKTVmall Scraper
Collect product names, prices, and even customer ratings from HKTVmall listings with just a couple of clicks — no complex setup required.
Learn more ->Substack scraper
Get Substack subscriber counts, article titles, and publication descriptions into a clean spreadsheet — no code, the AI does the structuring.
Learn more ->
BestPrice GR Scraper
Thunderbit's AI-powered BestPrice GR Scraper enables you to extract product listings, prices, and detailed information from BestPrice.gr in just a few clicks. Perfect for sales, marketing, and e-commerce teams looking to gather structured data quickly and efficiently.
Learn more ->
White Pages Scraper
The Thunderbit White Pages Scraper lets you extract data from White Pages phone and business listings with AI-powered field suggestions. Gather names, phone numbers, addresses, and website URLs for lead generation, marketing, or research in just a few clicks.
Learn more ->Ready to supercharge your data extraction?
Join 100,000+ professionals already using Thunderbit to automate their web scraping workflows.
Free trial provides unlimited credits for 8 webpages.