

Webben växer i en takt som nästan är svår att ta in. Varje dag publiceras miljarder nya sidor, produkter, recensioner och datamängder – som driver allt från marknadsundersökningar och AI-träning till din nästa shoppingrunda på Amazon. Efter många år inom SaaS och automation har jag sett hur rätt data kan avgöra om ett affärsbeslut blir succé eller fiasko. Men problemet är det här: att samla in, uppdatera och förstå all denna webbdata blir bara svårare, inte enklare. Traditionella webbskrapor har svårt att hänga med, och företag söker en smartare och snabbare väg att förvandla internet till användbara insikter. Här kommer molncrawlern in i bilden – ett verktyg som i tysthet förändrar hur organisationer hittar och utnyttjar webbdata i stor skala.
Så, vad är egentligen en molncrawler? Hur skiljer den sig från de webbskrapor du kanske redan känner till? Och varför satsar team inom allt från sälj till drift på den här tekniken för att ligga steget före i en datadriven värld? Låt oss reda ut begreppen, skala bort buzzorden och se hur molncrawlers, särskilt Thunderbits lösning, förändrar spelplanen för moderna företag.
Vad är en molncrawler? Nästa steg inom datainsamling
Samla in data från valfri webbplats med AI Get Started Free
Låt oss bryta ner det: en molncrawler är inte bara en webscraper som råkar ligga i molnet. Det är snarare en motor för datainsamling och upptäckt – ett smart, molnbaserat system som automatiskt hittar, extraherar och analyserar enorma datamängder från hela internet. Medan en traditionell webscraper hämtar information från några få sidor i taget, ofta från en och samma enhet, arbetar en molncrawler på en helt annan nivå. Den körs i kraftfulla molndatacenter, crawlar tusentals eller till och med miljontals sidor samtidigt och kan hantera allt från text till bilder och PDF-filer – oavsett hur komplex eller omfattande webbplatsen är.
Tänk så här: om en webscraper är som en ensam bibliotekarie som kopierar ut stycken ur en bok, så är en molncrawler som ett team av superdatorer som skannar varje bok i hela biblioteket samtidigt, samtidigt som de taggar, sorterar och analyserar innehållet. Resultatet? Företag får rikare, färskare och mer användbar data – utan flaskhalsar från lokal hårdvara eller manuellt arbete (Sitebulb, Octoparse).
Molncrawler kontra traditionell webscraper: vad är den verkliga skillnaden?
Om du någon gång har använt en webscraper känner du till grunderna: peka den mot en sida, definiera vad du vill ha och låt den hämta datan. Men när webben blir större och mer komplex börjar den gamla metoden visa sina begränsningar. Så här står sig molncrawlers och traditionella webbscrapers mot varandra:
| Egenskap/Aspekt | Traditionell webscraper | Molncrawler |
|---|---|---|
| Driftsättning | Körs på din lokala enhet eller server | Körs i molnet (på fjärrstyrda datacenter) |
| Skalbarhet | Begränsas av datorns kapacitet | Massivt parallell – tusentals sidor samtidigt |
| Hastighet | Långsammare, särskilt vid stora jobb | Snabb batchbearbetning |
| Underhåll | Kräver frekventa uppdateringar, går sönder när webbplatser ändras | Molnbaserad, uppdateras automatiskt, mindre känslig |
| Datatyper | Oftast text, ibland bilder | Text, bilder, PDF:er, komplexa layoutar |
| Åtkomst | Bunden till din enhet/nätverk | Tillgänglig var som helst, från vilken enhet som helst |
| Schemaläggning | Manuell eller enkel automatisering | Avancerad schemaläggning, återkommande jobb |
| Bäst för | Små projekt, enkla webbplatser | Stora, återkommande eller komplexa databehov |
Molncrawlers är byggda för den moderna webben – där data finns överallt och där fart och skala inte är förhandlingsbara (GPTBots, Octoparse).
Så effektiviserar molncrawlers datainsamling
Här blir det riktigt intressant. Molncrawlers använder molnets beräkningskraft för att bearbeta tusentals webbsidor parallellt. Det betyder att du kan skrapa en hel e-handelskatalog, bevaka konkurrenters priser på dussintals webbplatser eller samla bostadsannonser från alla stora portaler – på en bråkdel av den tid en traditionell scraper skulle behöva.
Varför spelar det roll? För i branscher som e-handel, finans och fastigheter är färsk data avgörande. Priser, lager och marknadstrender kan ändras från minut till minut. Att vänta timmar eller dagar på att en lokal scraper ska bli klar är helt enkelt inte rimligt. Molncrawlers begränsas inte av din bärbara dators RAM-minne eller kontorets Wi‑Fi – de skalar upp efter behov, så att du kan hantera riktigt stora jobb utan att gå på knäna (Zyte, Octoparse).
Branscher som har särskilt stor nytta av den här effektiviteten är bland annat:
- E-handel: Prisbevakning, sammanslagning av produktkataloger, analys av recensioner
- Fastigheter: Sammanställning av annonser, spårning av marknadstrender, jämförelser av objekt
- Finans: Nyhets- och sentimentanalys, bevakning av aktier/krypto, regulatorisk uppföljning
- Sälj & marknadsföring: Leadgenerering, konkurrentbevakning, trendspaning
Och ärligt talat, det är bara toppen av isberget. Om du behöver webbdata i stor skala är en molncrawler din nya bästa vän.
Thunderbits lösning för molncrawling: snabb, flexibel och kraftfull
Jag tar på mig Thunderbit-hatten en stund (okej, jag tar egentligen aldrig av den). Thunderbits molnskrapningsläge är vårt svar på den moderna datautmaningen – en molncrawler byggd för affärsanvändare som vill ha resultat, inte huvudvärk.
Det här är det som gör Thunderbits molncrawler unik:
- Batchskrapning i hög hastighet: Skrapa upp till 50 sidor åt gången, med molnservrar i USA, EU och Asien för global räckvidd. Slipp vänta medan din laptop kämpar sig igenom långa listor.
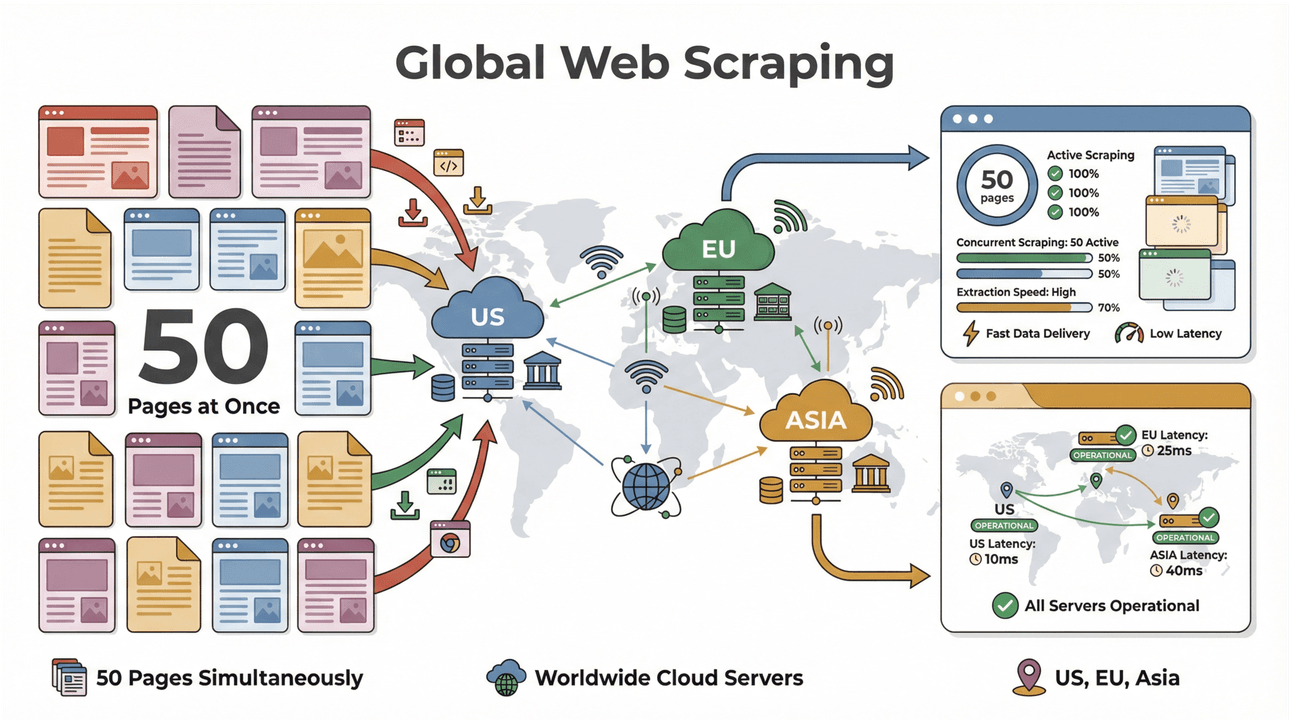
- Stöd för komplexa sidor: Thunderbits AI klarar allt från dynamiska e-handelssajter till knepiga PDF-filer och till och med extrahering av bilder. Finns det på webben kan Thunderbit förmodligen skrapa det (Thunderbit).
- Crawling av undersidor: Behöver du berika din data med detaljer från undersidor, som produktspecifikationer eller författarpresentationer? Thunderbits AI kan besöka varje undersida och slå ihop resultaten med din huvuddatamängd (Thunderbit).
- Smart datastrukturering: Använd “AI Suggest Fields” för att låta Thunderbit läsa av webbplatsen och föreslå de bästa kolumnerna – ingen kodning eller mallbyggnad krävs.
- Exportera dit du vill: Skicka datan direkt till Excel, Google Sheets, Airtable eller Notion. Eller ladda ner som CSV/JSON – välj det som passar ditt arbetsflöde (Thunderbit).
- Inget underhåll krävs: Thunderbits AI anpassar sig när webbplatser förändras, så du slipper hela tiden laga trasiga scrapers (Thunderbit).
Och ja, du kan testa allt detta med en gratisnivå – så du behöver inte bara lita på mig.
Testa Thunderbit Cloud Scraper gratis
Driftsättning av molncrawler: moln eller lokalt – vad passar dig bäst?
En av de största fördelarna med molncrawlers är flexibiliteten i driftsättningen. Med en traditionell crawler som körs lokalt är du bunden till en viss enhet, ett visst nätverk och ofta en hel del installationsstrul. Om datorn går i viloläge eller internetförbindelsen bryts stoppas skrapningen. Vill du skala upp måste du köpa mer hårdvara eller köra flera skript.
Molncrawlers vänder på det hela:
- Ingen specialhårdvara krävs: Allt tungt arbete sker i molnet. Du kan starta stora scrapingjobb från en Chromebook, en Mac eller till och med din telefon.
- Åtkomst var som helst: På resa? Arbetar på distans? Inga problem – din molncrawler är alltid tillgänglig.
- Enkel skalning: Behöver du skrapa 10 000 sidor i stället för 100? Öka bara jobbstorleken – ingen IT-insats behövs.
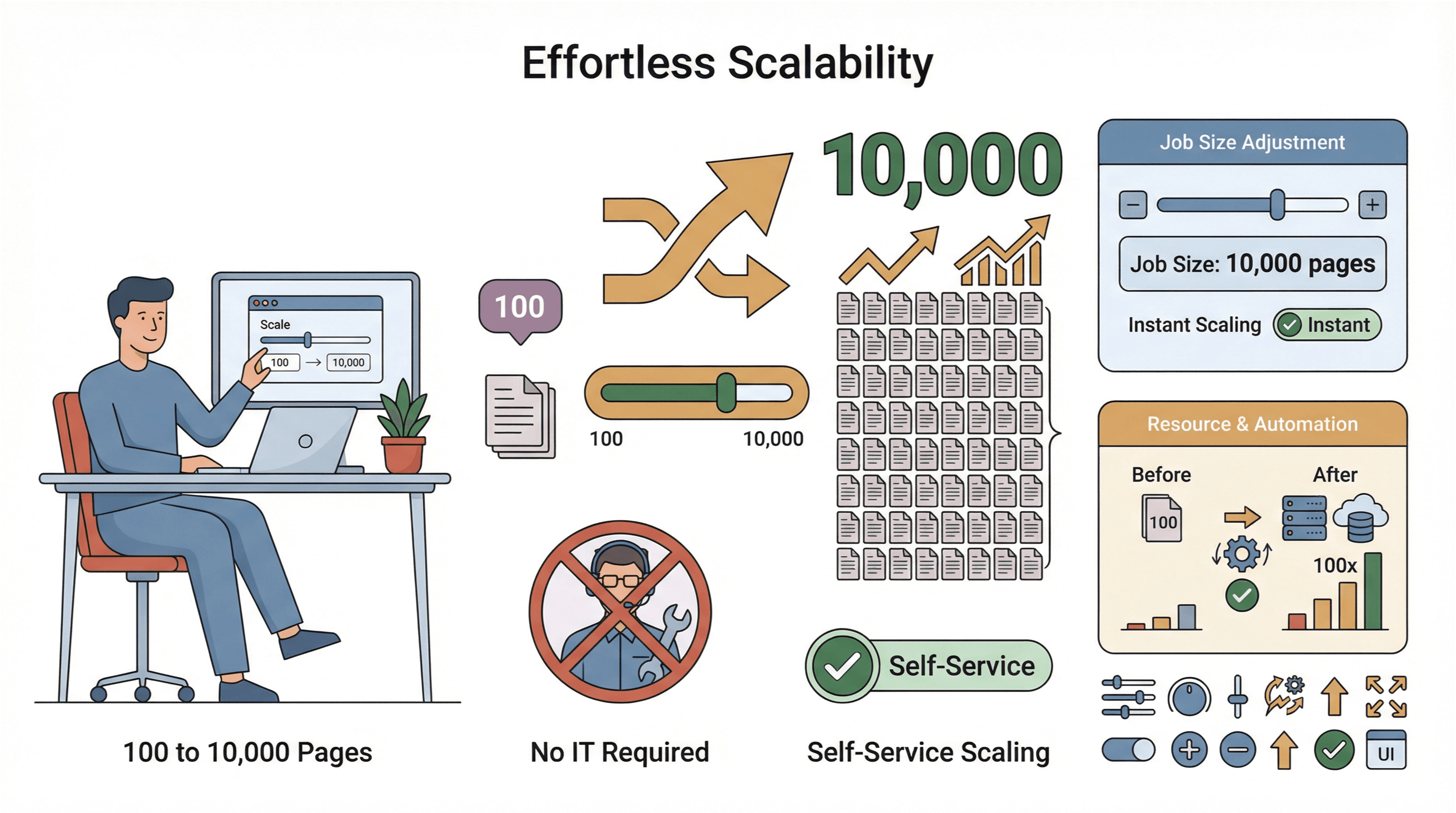
- Global datainsamling: Med molnservrar i flera regioner kan du komma åt geografiskt begränsat innehåll och hantera regelefterlevnad enklare (PromptCloud).
Självklart är säkerhet och regelefterlevnad alltid viktiga frågor. De bästa molncrawlerserna, inklusive Thunderbit, använder krypterade anslutningar, respekterar webbplatsers villkor och erbjuder funktioner som hjälper dig att hantera känslig data på ett ansvarsfullt sätt.
Verklig effekt: hur molncrawlers förändrar datadrivna strategier
Låt oss bli konkreta. Varför byter företag till molncrawlers? För att de ser tydliga, mätbara resultat:
- Marknadsanalys i realtid: Återförsäljare använder molncrawlers för att bevaka konkurrenters priser och lagerstatus i realtid, vilket möjliggör dynamisk prissättning och snabbare reaktioner på marknadsförändringar (Zyte).
- Förutsägelse av konsumenttrender: Varumärken samlar in recensioner, inlägg i sociala medier och forumdiskussioner för att upptäcka nya trender och justera kampanjer direkt.
- Sälj & leadgenerering: Säljteam bygger uppdaterade leadlistor från kataloger, eventwebbplatser och till och med PDF-filer – och matar in färska, kvalificerade kontakter i CRM-systemet (Thunderbit).
- Drift & compliance: Finansbolag använder molncrawlers för att bevaka regulatoriska uppdateringar, nyheter och rapporter i flera jurisdiktioner – vilket minskar risk och hjälper dem att ligga steget före förändringar.
Det gemensamma? Molncrawlers gör det möjligt för team att arbeta snabbare, fatta smartare beslut och springa förbi konkurrenter som fortfarande sitter fast i slow lane.
Viktiga funktioner att leta efter i en molncrawler
Se Thunderbits priser och funktioner Get Started Free
Alla molncrawlers är inte lika bra. Om du utvärderar alternativ är det här de viktigaste funktionerna att titta efter – och där Thunderbit verkligen sticker ut:
- Skalbarhet: Klarar den tusentals sidor samtidigt? Blir den långsammare när jobben blir större?
- Användarvänlighet: Är gränssnittet lätt för icke-tekniska användare? Går det att sätta upp en scraping på några klick?
- Stöd för flera datatyper: Text, bilder, PDF:er, undersidor – klarar den allt?
- Integration: Kan den exportera till dina favoritverktyg (Excel, Sheets, Notion, Airtable)?
- Schemaläggning: Kan du sätta upp återkommande jobb så att datan alltid är färsk?
- AI-stöd: Finns smarta fältförslag, databerikning och automatisk anpassning till ändringar på webbplatsen?
- Säkerhet & regelefterlevnad: Är din data och dina inloggningsuppgifter skyddade? Hjälper den dig att följa integritetslagar?
Thunderbit checkar av alla dessa rutor och är därför ett starkt val för team som vill ha kraft utan krångel.
Kom igång: så använder du en molncrawler för ditt företag
Redo att köra igång? Så här kan en vanlig affärsanvändare komma igång med en molncrawler som Thunderbit:
- Installera Thunderbit Chrome Extension: Snabb installation, inget IT-stöd behövs.
- Välj ditt mål: Öppna webbplatsen, listan eller dokumentet du vill skrapa.
- Klicka på “AI Suggest Fields”: Låt Thunderbits AI analysera sidan och föreslå de bästa kolumnerna att extrahera.
- Anpassa vid behov: Lägg till, ta bort eller döp om fält så att de passar dina behov.
- Välj molnskrapningsläge: För stora jobb eller komplexa webbplatser, byt till molnläge för maximal hastighet.
- Starta skrapningen: Thunderbit bearbetar upp till 50 sidor åt gången i molnet.
- Granska och exportera: Förhandsgranska resultatet och exportera sedan till Excel, Google Sheets, Notion eller Airtable.
- Schemalägg återkommande jobb: För löpande behov kan du skapa schemalagda scrapingkörningar – då uppdateras datan automatiskt (Thunderbit Docs).
Tips: Börja med ett litet jobb för att lära dig hur det fungerar och skala sedan upp när du känner dig trygg. Och tveka inte att använda Thunderbits support eller dokumentation – de finns där för att hjälpa till.
Börja crawla i molnet med Thunderbit
Framtiden för datainsamling: vad väntar molncrawlers härnäst?
Revolutionen kring molncrawlers har bara börjat. Det här håller jag ögonen på de kommande åren:
- Smartare AI-extraktion: Molncrawlers blir bättre på att förstå sammanhang, relationer och till och med känsloläge – vilket gör datan de samlar in ännu mer värdefull (GPTBots).
- Stöd för nya datatyper: Förvänta dig bättre hantering av video, ljud och interaktivt innehåll – inte bara statisk text och bilder.
- Djupare automatisering: Från automatisk schemaläggning till realtidslarm kommer molncrawlers att bli ännu mer självgående för affärsanvändare.
- Starkare regelefterlevnad: När integritetslagar utvecklas kommer molncrawlers att bygga in fler verktyg som hjälper team att hålla sig på rätt sida av reglerna.
- Integration med BI- och AI-verktyg: Direkta datapipelines från molncrawlers till analysverktyg, dashboards och maskininlärningsplattformar.
Kort sagt är molncrawlers på väg att bli ryggraden i digital affärsstrategi – och driva allt från produktlanseringar till AI-baserade prognoser (Thunderbit Blog).
Slutsats: varför molncrawlers är avgörande för moderna företag
Sammanfattningsvis: webben svämmar över av data, och de gamla sätten att samla in den hinner helt enkelt inte med. Molncrawlers är nästa utvecklingssteg – med fart, skala och intelligens som traditionella scrapers inte kan matcha. Verktyg som Thunderbit gör det möjligt för vilket team som helst, tekniskt eller inte, att utnyttja webbdatans fulla potential – och därmed fatta smartare beslut, reagera snabbare och få ett verkligt konkurrensövertag.
Om du är redo att lämna manuellt skrapande och långsam data bakom dig är det nu dags att utforska vad en molncrawler kan göra för ditt företag. Testa Thunderbits molnskrapningsläge och se hur enkel – och kraftfull – modern datainsamling kan vara. Och vill du fördjupa dig ytterligare, ta en titt på Thunderbit Blog för fler guider, tips och verkliga exempel.
Vanliga frågor
1. Vad är en molncrawler i enkla ord?
En molncrawler är ett molnbaserat verktyg som automatiskt hittar, extraherar och analyserar stora mängder data från webben. Till skillnad från traditionella scrapers som körs på din lokala enhet arbetar molncrawlers i kraftfulla datacenter, vilket möjliggör enorm skala och hastighet.
2. Hur skiljer sig en molncrawler från en vanlig webscraper?
Molncrawlers körs i molnet, hanterar tusentals sidor samtidigt, stöder komplexa datatyper som bilder och PDF:er och kräver varken underhåll eller lokal hårdvara. Traditionella scrapers begränsas av enhetens kapacitet och passar bäst för mindre och enklare jobb.
3. Vilka är de största fördelarna med att använda en molncrawler?
Molncrawlers erbjuder snabb datainsamling i stor skala, stöd för komplexa webbplatser, enkel åtkomst var som helst och avancerade funktioner som schemaläggning och AI-driven extrahering. De är perfekta för företag som snabbt behöver färsk och användbar data.
4. Hur fungerar Thunderbits molncrawler för affärsanvändare?
Thunderbits molncrawler låter dig sätta upp en scraping med bara några klick – ingen kod krävs. Du kan extrahera data från webbplatser, PDF:er och bilder, berika den med AI och exportera direkt till Excel, Google Sheets, Notion eller Airtable. Den är utformad för icke-tekniska användare som vill ha resultat, inte komplexitet.
5. Är molncrawling säkert och förenligt med dataskyddslagar?
Ja, ledande molncrawlers som Thunderbit använder krypterade anslutningar och beprövade metoder för datasäkerhet. Se alltid till att bara skrapa offentligt tillgänglig data och att följa webbplatsens villkor och gällande integritetsregler.
Redo att se vad en molncrawler kan göra? Ladda ner Thunderbit och börja utforska världen av storskalig, molndriven datainsamling redan idag.
Testa Thunderbit Cloud Crawler idag Get Started Free
Läs mer




