

Har du någonsin fått en bunt PDF-filer av din chef och blivit ombedd att plocka ut data som både är korrekt och snyggt formaterad? Att göra det manuellt är ett säkert sätt att bli kvar sent på jobbet. Att extrahera data från PDF-filer kan verkligen vara krångligt, eftersom PDF:er, till skillnad från webbinformation, ofta har ojämn formatering. Vissa PDF-filer innehåller tabeller, andra består bara av bilder eller skannade dokument, vilket gör direkt extrahering ganska knepig.
Extrahera data från vilken webbplats som helst med AI Get Started Free
Om du till exempel vill extrahera e-postadresser från en PDF kan vissa ligga i bildformat, medan andra gömmer sig i komplexa teckenkodningar. Ta det här exemplet: {john.doe,jane.doe}@example.com. Det här representerar faktiskt två separata e-postadresser: john.doe@example.com och jane.doe@example.com. Och sedan har vi {first.last}@example.com, där du ersätter "first" och "last" med författarens för- och efternamn. Traditionella verktyg för textigenkänning räcker helt enkelt inte till här. Det är där ett smidigt verktyg, PDF Scraper, kommer in och räddar dagen.
Vad är en PDF Scraper
En PDF Scraper är ett smart verktyg som automatiskt extraherar data från PDF-filer och konverterar innehåll som tabeller och text till de format du behöver, till exempel Excel, CSV eller JSON. Enkelt uttryckt förvandlar det tråkiga kopiera-och-klistra-in-uppgifter till en lösning med ett klick.
Föreställ dig en bunt fakturor, avtal, akademiska artiklar eller till och med skannade PDF-filer som annars skulle ta timmar att skriva av manuellt. Med en PDF Scraper laddar du bara upp filen, och inom några sekunder extraheras datan. Det sparar både tid och arbete, samtidigt som noggrannheten säkras. Säg adjö till besväret med manuell datainmatning.
Om din PDF innehåller olika datatyper som tabeller, länkar och bilder kan du låta en AI PDF Scraper hantera det. AI PDF Scrapers använder stora språkmodeller (LLM) som kan bearbeta text, bilder och tabeller samtidigt, och ger imponerande resultat.
Fördelarna med en AI PDF Scraper sträcker sig längre än effektivitet och noggrannhet; dess anpassningsförmåga gör den till ett stressfritt val. Oavsett om det gäller skannade dokument, bilder eller flerspråkiga PDF-filer hanterar AI allt utan problem. Det finns många bra AI-verktyg tillgängliga, som Thunderbit, ChatGPT och ChatPDF, med unika funktioner för olika behov. Oavsett om du snabbt behöver extrahera data eller analysera komplexa dokument kan rätt verktyg göra arbetet enklare och mer effektivt.
Testa själv: Extrahera data från PDF-filer med AI
Testa! Du kan klicka, utforska och köra arbetsflödet medan du tittar.
Hur du väljer rätt PDF Scraper
Att välja en PDF Scraper är som att köpa en bil; den bästa är den som passar dina behov. Här är några punkter att tänka på:
| Funktion | Beskrivning |
|---|---|
| Noggrannhet och stabilitet | Kontrollera om verktyget extraherar data korrekt, särskilt när informationen är kritisk. |
| Exportformat | Se till att verktyget stöder de exportformat du behöver, som Excel, CSV eller JSON. |
| Integration med andra verktyg | Om du behöver koppla ihop det med företagets system, kontrollera att smidig integration stöds. |
| Användarvänligt gränssnitt | Ett lättanvänt verktyg passar bättre för vanliga användare, medan mer avancerade verktyg kan passa teknikteam bättre. |
Olika verktyg har olika styrkor, och rätt val kan lyfta din produktivitet rejält. Här är tre populära PDF Scrapers, var och en med sina egna funktioner för olika behov:
| Verktyg | Fördelar | Nackdelar |
|---|---|---|
| Thunderbit | Snabb extrahering; enkel att använda som webbläsartillägg; bra för teamsamarbete | Begränsad skala för databehandling |
| ChatPDF | Enkel att använda, chattliknande frågor och svar på en enskild PDF | Ingen inbyggd export till CSV/Excel/JSON — svaren stannar i chatten |
| ChatGPT | Flexibel för komplex semantik, bred användning | Kräver att du matar in en ny prompt varje gång |
Kom igång med AI PDF Scraper
Thunderbit
Vill du snabbt extrahera data från PDF-filer utan att lägga för mycket tid och energi? Då är Thunderbit verktyget för dig. Det är enkelt att använda, och med bara ett klick kan du få allt gjort. Följ dessa steg för att enkelt omvandla komplex PDF-data till det format du behöver och höja din effektivitet rejält:
-
Lägg till Thunderbit i Chrome och registrera dig:
Besök Thunderbits officiella webbplats och lägg till Thunderbit i din Chrome-webbläsare. Registrera dig med ditt Google-konto eller en annan e-postadress.

-
Öppna PDF-filen i Chrome:
Öppna den PDF-fil du vill extrahera data från i Chrome och klicka på Thunderbit-ikonen uppe till höger.
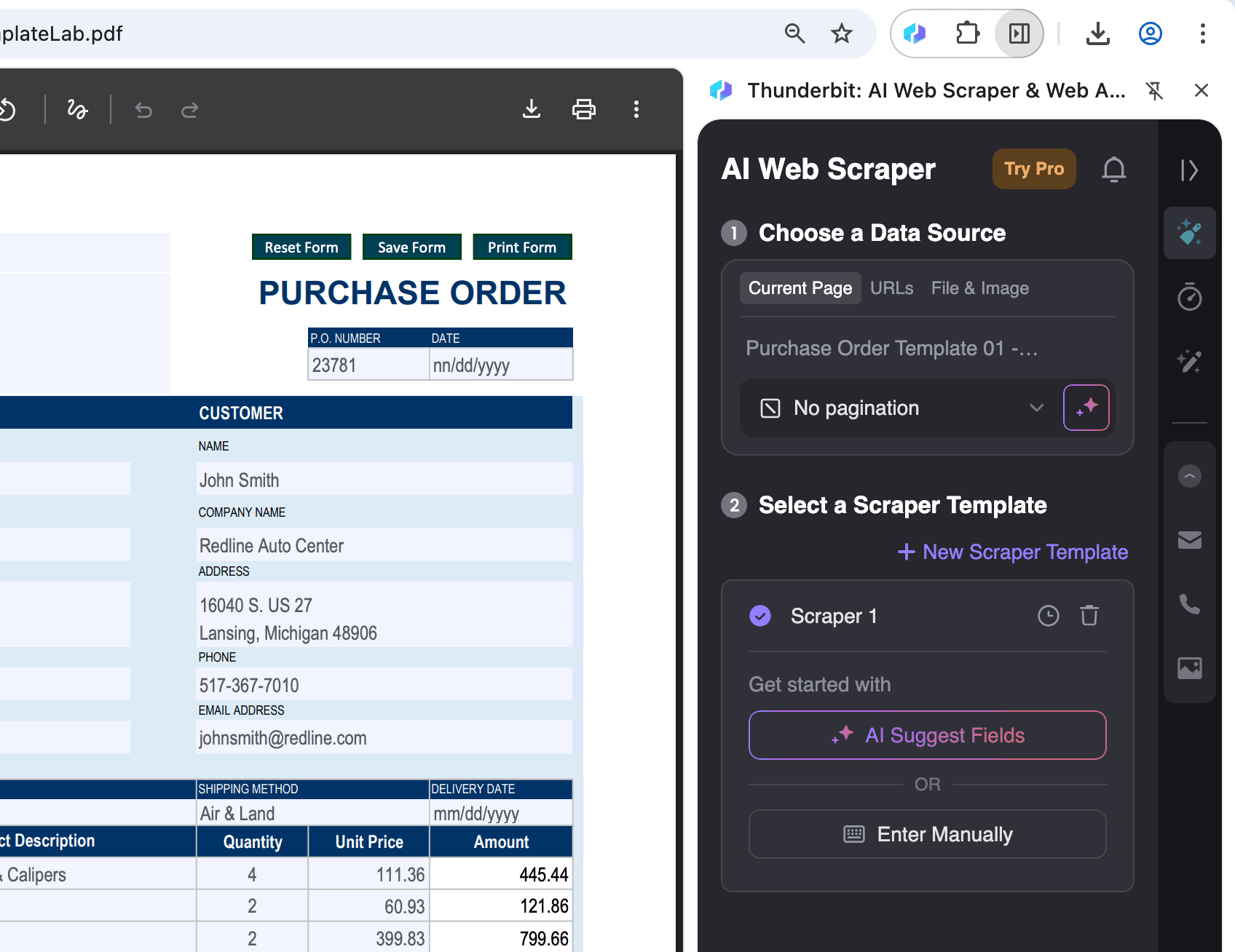
-
Välj exportformat och exportera:
När du har valt AI Suggest Columns kan du filtrera eller justera datan efter behov. Välj sedan önskat exportformat (CSV, Google Sheets, Airtable eller Notion) och klicka på Scrape för att exportera datan.
 Den exporterade datan kan direkt kopplas till Notion, Airtable eller Google Sheets för enkel teamsamverkan.
Den exporterade datan kan direkt kopplas till Notion, Airtable eller Google Sheets för enkel teamsamverkan.
Thunderbit är ett enkelt verktyg för att extrahera PDF-data som låter dig snabbt få ut den data du behöver från PDF-filer och konvertera den till ett användbart format. Oavsett om det gäller privat bruk eller teamsamarbete kan Thunderbit avsevärt förbättra din produktivitet och göra dataextrahering enklare och smidigare.
ChatPDF
Om du behöver bearbeta PDF-filer i bulk och bara vill extrahera specifik viktig information i stället för all data är ChatPDF ett bra hjälpmedel. Det låter dig extrahera data på ett konversationslikt sätt, vilket gör det lämpligt för nybörjare.
Så här extraherar du PDF-data med ChatPDF:
- Besök ChatPDF:s webbplats: Öppna ChatPDF eller motsvarande plattformssida.
- Ladda upp PDF-filer: Klicka på knappen "Upload File" för att dra och släppa eller välja den PDF-fil du vill analysera. Den stöder olika filtyper, som avtal, artiklar eller finansiella rapporter.
- Analysera PDF-filen: När filen har laddats upp parserar ChatPDF automatiskt innehållet och genererar en strukturerad sammanfattning av dokumentet. Du kan sedan granska den extraherade nyckelinformationen.
- Ställ interaktiva frågor: Använd inmatningsfältet för att fråga saker som "Vad är slutsatsen i den här rapporten?" eller "Vad är det totala beloppet som anges på fakturan?" ChatPDF extraherar relevant innehåll baserat på din fråga.
- Kopiera ut svaren: ChatPDF visar svaren direkt i chattfönstret. Kopiera svaret till ett kalkylblad, dokument eller din egen tabell — för riktigt strukturerad output (ren CSV/JSON med konsekventa kolumner över många filer) passar Thunderbit eller ChatGPT med en fast prompt bättre.
ChatPDF erbjuder en interaktiv upplevelse, vilket gör det särskilt lämpligt för att snabbt hitta information i dokument, till exempel för att hitta viktiga detaljer eller sammanfatta dokumentinnehåll.
ChatGPT
ChatGPT är utmärkt på att hantera komplex semantisk data, till exempel att tolka klausuler i juridiska dokument. Verktyget är mycket flexibelt och låter dig anpassa prompts för att extrahera specifik data eller analysera innehåll. Däremot behöver du använda samma prompt om och om igen för liknande uppgifter, och det kräver en god förståelse för promptdesign.
Här är en färdig prompt som du kan anpassa efter dina behov (kom ihåg att byta ut kolumnerna mot den information du vill extrahera):
You are now a PDF scraper, your job is when given a PDF, you need to extract its content based on the columns the user gives you. Your output should be a CSV file.
Here are the columns:
1. Name
2. Email
3. Phone Number
4. ...
- Registrera dig eller logga in: Öppna ChatGPT och skapa ett konto. Om du redan har ett konto loggar du bara in.
- Ladda upp PDF och ange din fråga: Skriv din fråga direkt i inmatningsfältet — ju mer specifik, desto bättre. Till exempel: "Det här PDF-dokumentet innehåller tre diagram, exportera dem som tabeller."
- Granska och justera resultatet: Kontrollera om svaret motsvarar dina förväntningar. Vid behov kan du förfina resultatet genom att ställa följdfrågor eller justera prompten.
- Exportera data som Excel eller CSV: Om datan som ChatGPT extraherat är det du vill ha, skriv i inmatningsfältet: "Exportera den här datan som Excel eller CSV."
- Spara resultatet: Klicka på fillänken som ChatGPT tillhandahåller för att ladda ner filen.
Verkliga användningsfall för AI PDF Scraper
AI PDF Scraper är som en mångsidig assistent i arbetet, oavsett om du hanterar fakturor, avtal, finansiella rapporter eller inköpsorder. Här är några praktiska scenarier där den verkligen kommer till sin rätt:
Hantering av fakturor och kvitton
Bearbeta företagsfakturor och kvitton i bulk och extrahera viktig information som belopp och datum för klassificering och arkivering.
- Starta Thunderbit, klicka på AI Web Scraper och sedan Bulk Pages
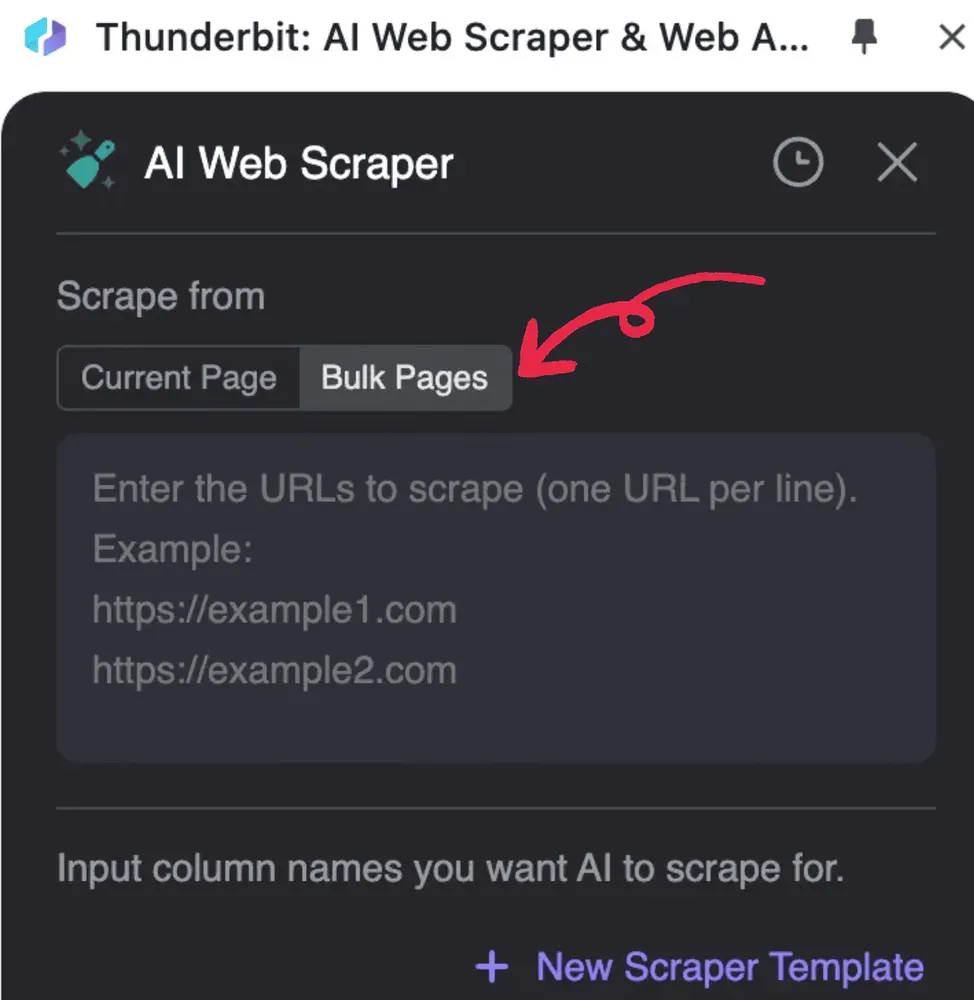 2. Ange de PDF-URL:er du vill bearbeta, en URL per rad
2. Ange de PDF-URL:er du vill bearbeta, en URL per rad
 3. Klicka på AI Suggest Columns (AI läser PDF-filen och föreslår hur datan ska struktureras)
4. Klicka på Scrape och exportera datan
3. Klicka på AI Suggest Columns (AI läser PDF-filen och föreslår hur datan ska struktureras)
4. Klicka på Scrape och exportera datan
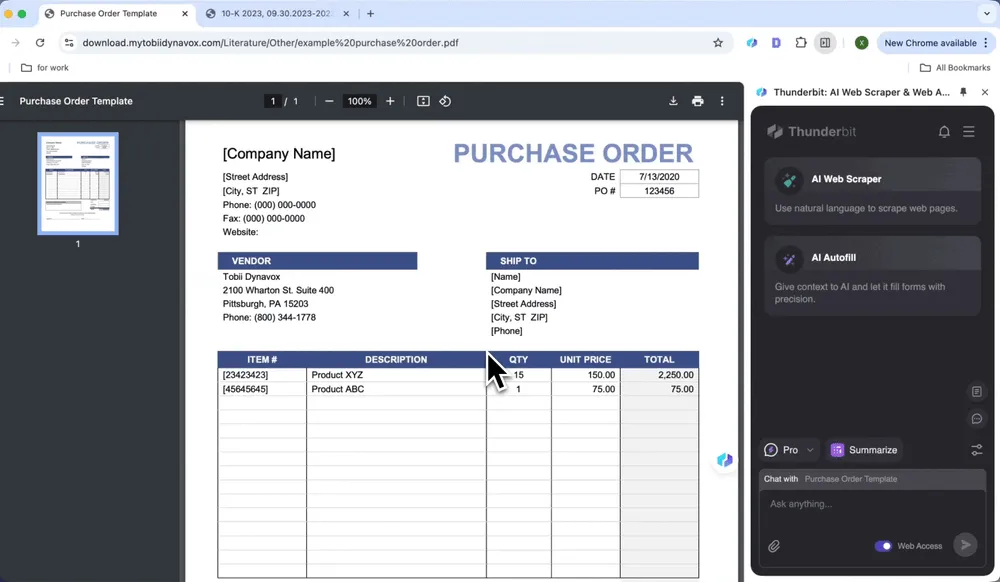
Bearbetning av inköpsorder
Identifiera automatiskt artiklar, kvantiteter och enhetspriser i inköpsorder, skapa standardiserade dataposter och extrahera data från PDF-filer, vilket sparar tid vid manuell bearbetning.
- Öppna inköpsordern i Chrome och starta Thunderbit
- Klicka på AI Web Scraper och sedan AI Suggest Columns
- Granska de genererade listnamnen och klicka på Scrape
- Klicka på Download CSV
Extrahering av finansiella data
Extrahera data från finansiella rapporter med ett enda klick, till exempel vinstmarginaler och försäljningssiffror, och slipp den tråkiga manuella granskningen.
- Öppna den finansiella rapporten i Chrome och starta Thunderbit
- Klicka på Summarize
- Generera automatiskt en sammanfattning av viktig information, inklusive text och tabellinnehåll
Inte nöjd med den automatiskt genererade sammanfattningen? Du kan manuellt ange den projektinformation du vill ha.
- Öppna den finansiella rapporten i Chrome och starta Thunderbit
- Klicka på AI Web Scraper, ange de projektnamn du vill ha, till exempel Net Income, Sales osv.
- Klicka på Scrape, exportera som tabell
Analys av juridiska dokument
Har du problem med klausuler i avtal och överenskommelser? AI-verktyg kan snabbt hitta betalningsvillkor, avtalsbrottsklausuler, avtalstid och andra viktiga punkter. Extrahera dem med ett klick för att skapa en kortfattad sammanfattning eller en lista över klausuler, spara tid och se till att inga detaljer missas.
På samma sätt som när du extraherar viktig information från finansiella rapporter kan du öppna PDF-filen och klicka på Summarize för att med ett enda klick se betalningsvillkor, avtalsbrottsklausuler, avtalstid och annan viktig information.
FAQ
-
Kan jag extrahera data från flera PDF-filer samtidigt?
Ja, avancerade verktyg för PDF-extrahering låter användare extrahera data från flera PDF-filer samtidigt. Den här batchbearbetningsfunktionen snabbar upp arbetsflödet avsevärt jämfört med manuella metoder.
-
Är PDF Scraper gratis?
Ja, det finns flera gratisverktyg för PDF-extrahering att använda. Många onlineverktyg, som Thunderbit och ChatPDF, erbjuder gratis funktioner för sidextrahering och dataextrahering. Även om vissa avancerade funktioner kan kräva betalning är de grundläggande extraheringsmöjligheterna vanligtvis gratis.
-
Krävs programmeringskunskaper för att använda en PDF Scraper?
Nej, många AI PDF scrapers, som Thunderbit, är utformade för användare utan programmeringskunskaper. De har användarvänliga gränssnitt som låter dig ladda upp filer och extrahera data med bara några få klick.
-
Vilka typer av dokument kan bearbetas med en PDF Scraper?
PDF scrapers kan hantera olika typer av dokument, inklusive fakturor, avtal, finansiella rapporter, akademiska artiklar och annat strukturerat eller semistrukturerat innehåll som finns i PDF-filer.
-
Är min data säker när jag använder en PDF Scraper?
Ansedda verktyg för PDF-extrahering prioriterar användarsäkerhet och följer ofta regler som GDPR. De lagrar vanligtvis din data på krypterade servrar och får inte åtkomst till den utan ditt tillstånd.
-
Finns det andra sätt att extrahera data från PDF?
Det finns flera metoder för att extrahera data från PDF-filer utöver manuell inmatning och Python-skript. Dit hör att använda PDF-konverterare för att omvandla filer till format som Excel eller CSV, specialiserade verktyg för PDF-dataextrahering som Tabula och Excalibur för strukturerade dokument, AI-drivna lösningar med optisk teckenigenkänning (OCR) för både inbyggda och skannade PDF-filer, samt öppen källkod-verktyg som Extractous och PymuPDF4llm som är utformade för effektiv dataextrahering. Varje metod har sina för- och nackdelar, så valet beror på användarens specifika krav och tekniska kunskaper.
Läs mer
- Hur du extraherar data från vilken webbplats som helst med AI
- De 5 bästa verktygen med AI för att extrahera data från PDF-filer
- Så använder du ChatGPT för att extrahera från PDF-filer
- Gratis PDF-sammanfattare online
Testa AI Web Scraper Get Started Free




