

Är web scraping olagligt? Det är den miljonfråga jag hör från grundare, marknadsförare och dataentusiaster varje vecka.
Med 51 % av all internettrafik som nu kommer från bottar – första gången automatiserad trafik har gått om mänsklig aktivitet – och en stor andel av det som går till web scraping för business intelligence, försäljning och AI-träning, är det inte konstigt att alla försöker förstå var de juridiska gränserna går.
En dag ser du en rubrik om ett domstolsbeslut som säger att scraping av offentliga data är helt okej. Nästa dag varnar tillsynsmyndigheter för ”olaglig” datainsamling från sociala medier. Det är förvirrande, även för sådana som mig som tillbringar dagarna med att bygga AI-web scraping-verktyg på Thunderbit.
Så, är web scraping olagligt? Svaret är inte ett enkelt ja eller nej. Det beror på vad du samlar in, varifrån du samlar in det, hur du använder datan och vad lagen säger i ditt land.
I den här djupdykningen går jag igenom det juridiska landskapet, slår hål på några vanliga myter och delar praktiska tips (plus några krigshistorier) för att hjälpa dig hålla dig inom regelverket – oavsett om du är ensam grundare eller jobbar i ett data team på ett Fortune 500-bolag.
Web scraping och lagen: Finns det en tydlig gräns?
Om du hoppas på ett svar i en enda mening kan jag spara dig lite tid: lagen har inte dragit någon skarp, tydlig gräns för web scraping.
I stället handlar det om ett lapptäcke av överlappande regler – äganderätt till data, integritet, immaterialrätt, anti-hacking-lagar och de ökända användarvillkoren (ToS). Var och en kan spela in, och svaret beror ofta på just din situation (multilogin.com).
Låt oss dela upp det i tre stora juridiska kategorier:
- Äganderätt till data: Generellt sett är fakta och offentliga uppgifter (som priser eller telefonnummer) inte upphovsrättsskyddade. Men kreativt innehåll (artiklar, bilder) och proprietära databaser kan vara skyddade – särskilt i EU, där ”sui generis-databasskydd” är en grej (cliffordchance.com).
- Integritet: Moderna integritetslagar (tänk GDPR i Europa, PIPL i Kina) behandlar personuppgifter som en reglerad tillgång – även om de ligger offentligt. Att samla in namn, e-postadresser eller sociala profiler utan laglig grund kan få dig i trubbel (ico.org.uk).
- Avtal (användarvillkor): Många sajter förbjuder uttryckligen scraping i sina ToS. Även om ToS inte är lagar kan domstolar behandla dem som bindande avtal. Brott mot dem kan leda till stämningar och i vissa fall till och med utlösa anti-hacking-lagstiftning om du kringgår tekniska spärrar (cliffordchance.com).
Så, är web scraping olagligt? Ibland ja, ibland nej, och ofta ”det beror på”. Djävulen sitter i detaljerna.
Jämförelse av juridiska perspektiv: USA, EU, Storbritannien, Kina
Här är en snabb tabell som visar hur stora regioner ser på web scraping:
| Region | Scraping av offentliga data | Scraping av personliga/privata data | Tillämpning & viktiga punkter |
|---|---|---|---|
| USA | Generellt tillåtet för offentliga data (se hiQ v. LinkedIn). Brott mot ToS kan leda till civilrättsliga stämningar. | Begränsat/olagligt om du bryter dig förbi inloggning eller missbrukar personuppgifter. Delstatliga lagar (som CCPA) kan vara aktuella. | Varningar om upphörande, IP-blockering, stämningar. CFAA gäller om du kringgår tekniska spärrar. |
| EU | Villkorligt tillåtet för icke-personliga, offentliga data. Databasskydd kan gälla. EU AI Act (2026) lägger till krav på transparens för AI-träningsdata. | Hårt reglerat under GDPR – även offentliga personuppgifter kräver laglig grund. | Dataskyddsmyndigheter kan bötfälla överträdelser av integritetsskyddet. Upphovsrätt och databasskydd tillämpas också. EU AI Act förbjuder scraping av ansiktsbilder för AI. |
| Storbritannien | Liknar EU. Offentliga, icke-personliga data kan samlas in, men datarättigheter och avtal måste respekteras. | Strikt kring personuppgifter – UK GDPR gäller. Computer Misuse Act kriminaliserar obehörig åtkomst. | ICO kan utfärda sanktioner för överträdelser av dataskyddet. Domstolar kan verkställa ToS. |
| Kina | Starkt kontrollerat. Offentliga, icke-personliga data kan samlas in för intern användning, men miljön är försiktig. | Mycket begränsat – PIPL kräver samtycke för personuppgifter. Lagar mot illojal konkurrens kan tillämpas. | Straffrättsliga fall vid storskalig scraping. Domstolar använder lagen om illojal konkurrens för att stoppa otillåten scraping. |
Är web scraping olagligt? Viktiga juridiska faktorer att tänka på
Vad avgör egentligen om ditt scraping-projekt är lagligt eller riskabelt? Här är de viktigaste faktorerna:
- Offentliga vs. privata data: Att samla in data som vem som helst kan se på öppna webben är i regel säkrare. Att samla något bakom inloggning, betalvägg eller teknisk spärr? Det är sannolikt olagligt (thunderbit.com).
- Typ av data: Personuppgifter (namn, e-post, profiler) utlöser integritetslagar. Upphovsrättsskyddat innehåll (artiklar, bilder) får inte kopieras i sin helhet. Ren fakta (priser, väder) är oftast fritt fram (oxylabs.io).
- Avsedd användning: Intern analys eller forskning bedöms oftast mildare än att publicera eller sälja den insamlade datan. Att använda data som skrapats för att konkurrera direkt med källan? Det är en stämning som väntar på att hända (thunderbit.com).
- Efterlevnad av sajtens regler: Kontrollera alltid robots.txt och ToS. Robots.txt är inte juridiskt bindande, men det är god praxis att respektera den. Brott mot ToS kan leda till civilrättsliga mål eller värre (promptcloud.com).
- Tekniska åtgärder: Att skrapa i mänsklig takt och inte kringgå säkerhetsåtgärder är viktigt. Att bombardera en server eller ducka CAPTCHA:er kan gå över gränsen till hacking (cliffordchance.com).
Vad som förändrades 2024–2026: Viktiga domar och regleringar
Det juridiska landskapet för web scraping har förändrats dramatiskt sedan 2023. Här är utvecklingen som varje scraper behöver känna till:
Viktiga domstolsavgöranden
-
Meta v. Bright Data (2024): En amerikansk federal domstol fastslog att Metas användarvillkor inte förbjuder scraping av offentliga data av användare som inte är inloggade. Domaren ansåg att ”en besökare inte betraktas som en ’användare’ om personen inte har ett konto.” Meta drog kort därefter tillbaka övriga anspråk. Det här är en milstolpe för scraping av offentliga data.
-
X Corp v. Bright Data (2024): Twitter (numera X) förlorade ett liknande mål, vilket stärker samma princip: scraping av offentligt tillgängliga data utan inloggning bryter inte mot ToS, eftersom scrapern aldrig gick med på villkoren.
-
Reddit v. Perplexity AI (oktober 2025): Reddit stämde Perplexity AI och flera scraping-leverantörer, med hänvisning till DMCA och påstående om kringgående av anti-bot-system. Det signalerar en ny juridisk strategi: plattformar vänder sig till upphovsrätt och anti-kringgåendekrav i stället för CFAA.
-
NYT v. OpenAI (mars 2025): En federal domare lät New York Times upphovsrättsmål mot OpenAI gå vidare och avslog OpenAIs yrkande om avvisning. Det kan skapa ett viktigt prejudikat för om scraping av innehåll för att träna AI-modeller räknas som ”fair use”.
-
Anthropic-förlikning (september 2025): Anthropic gick med på att betala 1,5 miljarder dollar för att göra upp i en amerikansk grupptalan om användningen av upphovsrättsskyddade texter för att träna sin AI-modell – ett tydligt tecken på att kostnaderna för scraping för AI är högst verkliga.
Den stora trenden: Från CFAA till avtals- och upphovsrättslagar
Mönstret är tydligt: CFAA (Computer Fraud and Abuse Act) tappar kraft som vapen mot dem som skrapar offentliga data. Företag som försökte använda CFAA mot scraping av offentliga data – Meta, X, LinkedIn – har i stort sett misslyckats. I stället flyttas den juridiska striden till:
- Avtalsrätt (brott mot ToS – men domstolar säger att icke-användare inte binds av ToS)
- Upphovsrättsanspråk (särskilt för AI-träningsdata)
- Anti-kringgåendelagar (DMCA Section 1201)
För scrapers betyder det att den juridiska risken inte har försvunnit – den har bara flyttat på sig.
Regleringsförändringar
- CCPA-uppdateringar 2026: Kaliforniens reviderade CCPA-regler trädde i kraft den 1 januari 2026 och lade till nya regler för teknik för automatiserat beslutsfattande (ADMT), riskbedömningar och skyldigheter för data mäklare.
- Nya delstatliga integritetslagar i USA: Indiana, Kentucky och Rhode Island antog heltäckande integritetslagar som började gälla 2026.
- EU AI Act: Full tillämpning börjar 2 augusti 2026 – med krav på att AI-utvecklare ska redovisa källor till träningsdata, respektera avregistrering från copyright, och ett förbud mot scraping av ansiktsbilder för AI-system.
- AI Accountability for Publishers Act (februari 2026): Ett föreslaget amerikanskt lagförslag som skulle kräva att AI-bolag får tillstånd och betalar utgivare innan de skrapar deras innehåll.
Scrapingpolicyer hos stora plattformar: Det här behöver du veta
Alla webbplatser behandlar inte scraping på samma sätt. Här är en plattformsvis genomgång av vad de största sajterna tillåter, vad de blockerar och vad domstolarna har sagt:
| Plattform | ToS om scraping | Tekniskt försvar | Juridisk tillämpning | Vad som är praktiskt säkert |
|---|---|---|---|---|
| Google (Sök & Maps) | Förbjuder automatiserad åtkomst i ToS. Maps Platform har en uttrycklig ”No Scraping”-klausul. | SearchGuard JS-utmaningar, CAPTCHA:er, rate limiting. Uppdaterade robots.txt 2025 för att blockera AI-crawlers. | Stämde scrapers i december 2025 med stöd av DMCA. Blockerar aktivt AI-crawlers (Anthropic, Meta, OpenAI). | Att skrapa offentliga affärsdata från Google Maps är juridiskt försvarbart (hiQ-prejudikat), men räkna med tekniska blockeringar. Använd officiella API:er där det går. |
| Amazon | Förbjuder uttryckligen all scraping i användarvillkoren (”ingen robot, spindel, scraper eller annan automatiserad metod”). | Aggressiv bot-detektering, CAPTCHA, IP-blockering. robots.txt blockerar alla bottar utom Googlebot/Bingbot. Blockerar uttryckligen AI-crawlers sedan 2025. | Stämde Perplexity AI i november 2025. Skickar regelbundet upphörandebrev. Uppdaterade BSA i mars 2026 med regler för AI-agenter. | Offentliga produktdata (priser, listningar) är faktabaserade och kan skrapas enligt amerikansk lag, men Amazon slåss hårt. Begränsa förfrågningar och undvik personuppgifter. |
| Förbjuder scraping i ToS; kräver användaravtal för åtkomst till tjänster. | Inloggningsväggar för större delen av profildatan, anti-bot-detektering, rate limiting. | hiQ-målet bekräftade att scraping av offentliga profiler inte bryter mot CFAA, men LinkedIn vann på avtals- och illojal konkurrensanspråk när falska konton användes. | Offentliga profiler (synliga utan inloggning) är juridiskt försvarbara att skrapa. Skapa aldrig falska konton eller skrapa data bakom inloggning. | |
| Meta (Facebook & Instagram) | ToS förbjuder scraping; separata regler för inloggad respektive utloggad data. | Inloggningsväggar för det mesta innehållet, avancerad bot-detektering. | Förlorade mot Bright Data 2024 – domstolen slog fast att ToS inte gäller för scrapers som inte är inloggade. Meta drog tillbaka övriga anspråk. | Offentliga data (företagssidor, offentliga inlägg) som syns utan inloggning står på säkrare grund. Skrapa aldrig privata profiler eller data bakom inloggning. |
| X (Twitter) | Uppdaterade ToS 2023 för att förbjuda all scraping och crawling utan skriftligt samtycke. Tog bort det gamla undantaget för robots.txt. | robots.txt blockerar alla crawlers (Disallow: /). Cloudflare Turnstile-utmaningar. Strikta rate limits (300 förfrågningar/timme). IP-reputationspoäng. | Förlorade mot Bright Data kring offentliga data, men begränsar teknisk åtkomst aggressivt. | Offentliga tweets och profiler är juridiskt försvarbara att skrapa, men X:s tekniska hinder hör till de tuffaste 2026. Räkna med blockeringar utan premium-proxyinfrastruktur. |
Kort sagt: Domstolar har konsekvent slagit fast att scraping av offentligt synliga data utan inloggning inte bryter mot CFAA. Men plattformar kan fortfarande gå på dig med avtalsrätt, upphovsrätt eller anti-kringgåenderegler – och de kommer att göra livet svårt med tekniska hinder. Skrapa alltid ansvarsfullt.
AI-träningsdata och web scraping: Den nya juridiska frontlinjen
Om du följer nyheterna 2026 vet du att scraping av data för att träna AI-modeller har blivit den hetaste juridiska konfliktzonen. Här är vad som händer:
- Upphovsrättsprocesserna staplas på hög. New York Times, författare och förlag har stämt OpenAI, Anthropic och andra och hävdar att mass-scraping av upphovsrättsskyddat innehåll för att träna LLM:er inte är ”fair use”. Anthropic gjorde 2025 upp i ett stort grupprättsligt mål för 1,5 miljarder dollar – ett tydligt tecken på att kostnaderna för scraping för AI är högst verkliga.
- Försvaret ”fair use” är skakigt. Amerikanska domstolar har ännu inte kommit med ett definitivt avgörande om huruvida träning av AI på skrapad data är fair use. Tidiga beslut tyder på att det beror mycket på hur datan samlades in och vad som görs med AI-resultatet.
- Ny lagstiftning är på väg. AI Accountability for Publishers Act (presenterad i februari 2026) syftar till att kräva att AI-bolag får tillstånd och betalar utgivare innan de skrapar deras innehåll.
- EU AI Act (full tillämpning augusti 2026) kräver att AI-utvecklare redovisar källor till träningsdata, respekterar maskinläsbara avregistreringar från upphovsrättsskyddat innehåll (enligt Copyright Directive TDM-undantaget) och märker AI-genererat innehåll. Den förbjuder också AI-system som skrapar ansiktsbilder från internet.
- AI/LLM-crawlers exploderar. AI-crawlers fyrdubblade sin andel av webbtrafiken från 2,6 % till 10,1 % på bara åtta månader. OpenAIs GPTBot ensam växte med 305 %. Som svar uppdaterar stora sajter (Amazon, Reddit, NYT) robots.txt för att uttryckligen blockera AI-crawlers.
Vad det betyder för dig: Om du samlar in data för traditionella affärsändamål (leadgenerering, prisbevakning, marknadsanalys) kanske dessa AI-specifika regler inte gäller direkt. Men om du matar skrapad data in i AI-modeller ska du vara mycket försiktig – och ta juridisk rådgivning.
Web scraping-lagar runt om i världen: En snabb jämförelse
Låt oss zooma ut och se hur reglerna ser ut globalt:
- USA: Inget generellt förbud. Scraping av offentligt tillgängliga sajter är i regel lagligt (hiQ v. LinkedIn), och domarna mot Meta och X Corp 2024 har ytterligare stärkt argumentet för scraping av offentliga data. Men scraping bakom inloggning eller tekniska spärrar kan fortfarande utlösa CFAA. Trenden går nu mot att företag i stället använder avtalsrätt och upphovsrättsanspråk. Integritetslagarna expanderar snabbt: CCPA fick stora uppdateringar som trädde i kraft den 1 januari 2026, inklusive nya regler för automatiserat beslutsfattande och skyldigheter för data mäklare. Indiana, Kentucky och Rhode Island antog också heltäckande integritetslagar 2026.
- Europeiska unionen: Strikta integritetslagar. GDPR gäller även offentliga personuppgifter. Databasskydd kan stoppa storskalig scraping av strukturerad data (cliffordchance.com). NYTT: EU AI Act träder in i full tillämpning den 2 augusti 2026, vilket kräver att AI-utvecklare redovisar källor till träningsdata och respekterar avregistrering från upphovsrätt. Lagen förbjuder också scraping av ansiktsbilder från internet för AI-system.
- Storbritannien: Speglar EU:s regler efter Brexit. Offentliga data kan skrapas, men scraping av personuppgifter är hårt reglerat. Computer Misuse Act kan kriminalisera obehörig åtkomst.
- Kina: Mycket restriktivt. PIPL och Data Security Law kräver samtycke för personuppgifter. Domstolar använder lagstiftning om illojal konkurrens för att stoppa scraping som skadar företag (malwarebytes.com).
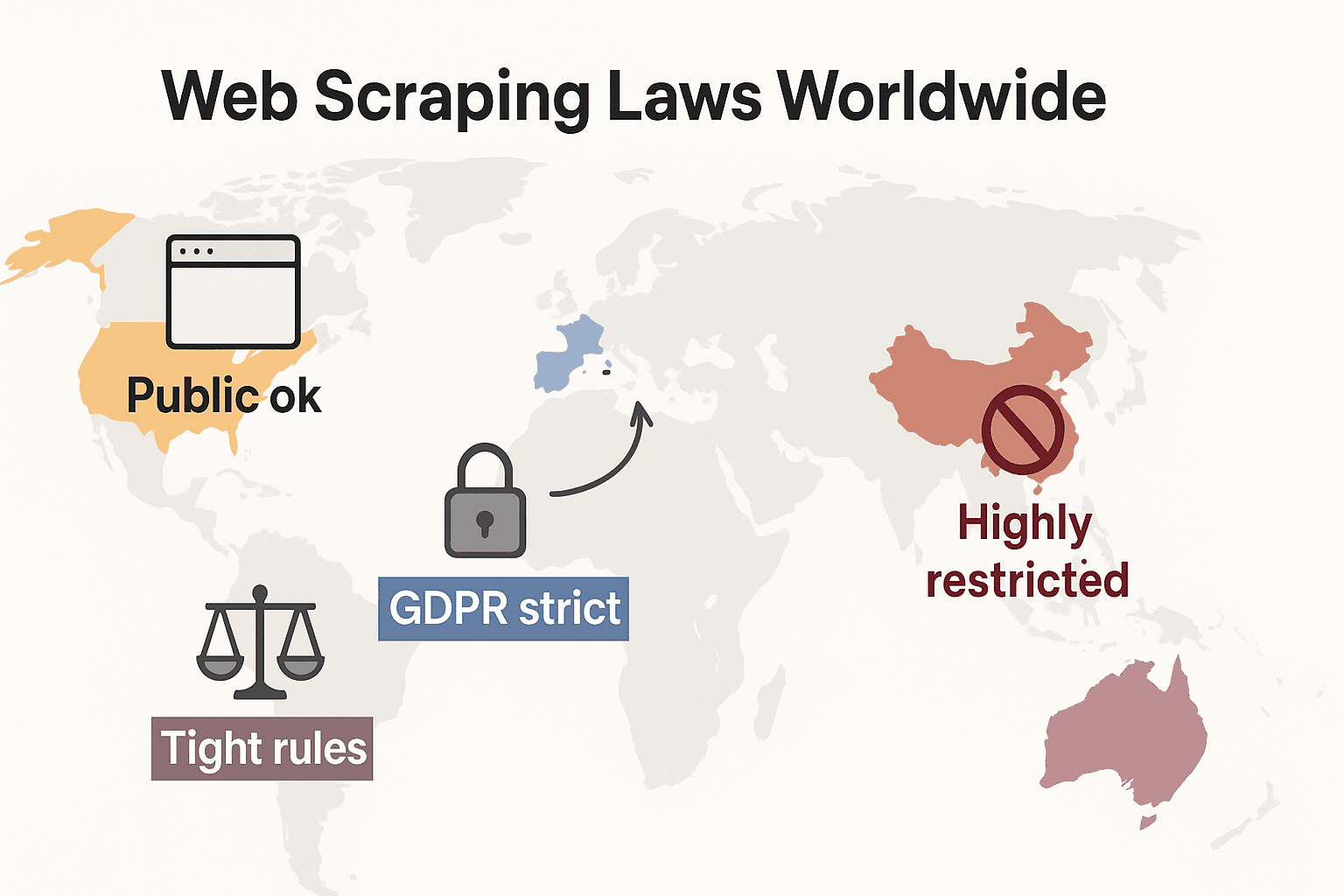
Kort sagt: att skrapa offentliga, icke-personliga data för intern användning är generellt säkrast. Allt annat? Kolla lokala lagar och gå försiktigt fram.
Vanliga myter om web scraping och laglighet
Låt oss punktera några myter jag hör hela tiden:
- Myt 1: ”Web scraping är olagligt, punkt slut.”
Fel. Det finns ingen lag som förbjuder all web scraping. Det är hur och vad du skrapar som spelar roll (oxylabs.io). - Myt 2: ”Om datan är offentlig kan jag göra vad jag vill med den.”
Inte riktigt. Offentliga data kan fortfarande skyddas av integritets- eller upphovsrättslagar, och ToS kan begränsa vissa användningar (ico.org.uk). - Myt 3: ”Web scraping är samma sak som hacking.”
Nej. Att skrapa offentliga webbsidor är inte hacking. Att kringgå inloggning eller tekniska spärrar är en annan sak (calawyers.org). - Myt 4: ”Om jag inte åker fast är det lugnt.”
Riskabelt tänkande. Många sajter använder anti-bot-teknik och kommer att märka det. Tystnad är inte samtycke. - Myt 5: ”Det är okej om jag ger kredit eller bara använder datan internt.”
Källhänvisning upphäver inte upphovsrätts- eller integritetslagar. Intern användning är säkrare, men inte ett frikort. - Myt 6: ”All web scraping bryter mot integriteten.”
Inte all scraping handlar om personuppgifter. Men att skrapa stora mängder personuppgifter utan skyddsåtgärder är nästan alltid olagligt (oxylabs.io). - Myt 7: ”Om en webbplats ToS förbjuder scraping är det alltid olagligt att skrapa.”
Inte nödvändigtvis. 2024 slog domstolarna i Meta v. Bright Data och X Corp v. Bright Data fast att ToS inte kan binda användare som aldrig har godkänt dem – alltså, om du skrapar utan att logga in eller skapa ett konto kanske sajtens ToS inte gäller för dig. Det här området utvecklas fortfarande, men det är en viktig förändring.
Så skrapar du data lagligt: Bästa praxis för efterlevnad
Här är min checklista för laglig och etisk web scraping:
- Läs och respektera sajtens användarvillkor. Om de säger ”ingen scraping”, överväg att sluta eller be om tillstånd (ql2.com).
- Håll dig till offentliga data. Om du behöver ett lösenord är det begränsat – skrapa inte det (thunderbit.com).
- Kontrollera robots.txt och crawla hänsynsfullt. Inte juridiskt bindande, men god etikett. Överbelasta inte servrar – sprid ut dina förfrågningar (promptcloud.com).
- Undvik personuppgifter om du inte har laglig grund. Om du måste samla in dem, följ GDPR/CCPA och minimera det du samlar in.
- Publicera inte skrapat innehåll i sin helhet. Lägg till värde eller analys, eller be om tillstånd (thunderbit.com).
- Mata inte in skrapat innehåll i AI-modeller utan att kontrollera upphovsrätten. Det juridiska landskapet förändras snabbt – ta rådgivning om det här är ditt användningsfall.
- Använd officiella API:er eller dataexporter när de finns. De är byggda för just det här och är oftast säkrare (thunderbit.com).
- Var transparent och ansvarstagande. Om du samlar in personuppgifter, informera berörda och för logg över dina aktiviteter.
- Minimera och säkra din data. Samla bara in det du behöver, håll den korrekt och förvara den säkert.
- Håll dig uppdaterad och sök juridisk rådgivning vid gränsfall. Lagar och domstolsbeslut förändras snabbt – särskilt EU AI Act och amerikanska delstatliga integritetslagar. Är du osäker, fråga ett proffs.
Prova Thunderbits Chrome-tillägg för efterlevnadsanpassad scraping
Att använda web scraping-verktyg lagligt: Vad företag behöver veta
Web scraping-verktyg som Thunderbit gör datainsamling tillgänglig även för den som inte kan koda, men du behöver fortfarande använda dem ansvarsfullt:
- Välj verktyg med fokus på efterlevnad. Thunderbit, till exempel, skrapar bara det du kan se i din webbläsare – inga smyghackade API:er eller obehörig åtkomst (thunderbit.com).
- Håll dig till legitima användningsfall. Intern analys, marknadsresearch och konkurrensbevakning av priser är i regel säkert. Att publicera eller sälja skrapad data? Betydligt riskablare.
- Konfigurera verktygen för efterlevnad. Ställ in fördröjningar mellan crawl, följ robots.txt och använd mallar som bara samlar in det du behöver.
- Behåll det internt. Att använda skrapad data internt är säkrare än att publicera den.
- Utbilda teamet. Se till att alla förstår reglerna och bästa praxis.
- Utnyttja inbyggda funktioner för efterlevnad. Thunderbit varnar användare för riskabla sajter, skrapar i mänsklig takt och lagrar inte din data på sina servrar.
- Tvinga inte fram det. Om ett verktyg inte kan skrapa en sajt, försök inte kringgå det. All data går inte att hämta utan risk.
Thunderbits approach: Möjliggör efterlevnadsanpassad AI-web scraping
På Thunderbit har vi lagt mycket tid på att tänka igenom efterlevnad. Så här hjälper vår AI Web Scraper användare att hålla sig på rätt sida av lagen:
- Skrapar bara det du kan se. Thunderbit arbetar i din webbläsarsession, så det kan inte komma åt data som du inte själv skulle kunna kopiera manuellt.
- Vägledning med varningar. Om du försöker skrapa en sajt med strikta anti-scraping-regler varnar Thunderbit dig.
- Skraphastighet som liknar människors. Oavsett om du skrapar lokalt eller i molnet undviker Thunderbit att överbelasta servrar.
- Anpassningsbart dataval. Vår AI föreslår relevanta kolumner så att du bara samlar in det du behöver.
- Hantera undersidor och paginering. Thunderbit navigerar sajter som en riktig användare och respekterar deras struktur.
- Sekretess och säkerhet. Din data stannar hos dig – Thunderbit lagrar eller återanvänder den inte.
- Efterlevnadsvänliga exportfunktioner. Exportera direkt till Google Sheets, Airtable, Notion eller CSV för säker intern användning.
- Schemaläggning och automatisering. Ställ in återkommande scraping till ansvarstagna intervaller.
- Stöd för flera språk. Thunderbits gränssnitt stöder 34 språk, vilket gör efterlevnad tillgänglig globalt.
- Regelbundna malluppdateringar. Våra omedelbara mallar för populära sajter hålls uppdaterade i takt med juridiska och tekniska förändringar.
Genom att bygga in efterlevnad i produkten hjälper Thunderbit team att samla in den data de behöver – utan juridiskt huvudvärk.
Håll dig steget före: Anpassa dig till juridiska och tekniska förändringar i web scraping
Utforska fler guider om web scraping Get Started Free
Web scraping är inte något du ställer in och glömmer. Lagar och webbplatsstrukturer utvecklas hela tiden. Så här ligger du steget före:
- Följ de juridiska utvecklingarna. Förändringstakten accelererade 2024–2026 – följ teknikjuridiska nyheter, tillsynsmyndigheters uppdateringar och branschbloggar (som Thunderbits). Håll ett öga på tillämpningen av EU AI Act (augusti 2026), nya amerikanska delstatliga integritetslagar och pågående upphovsrättsmål kring AI.
- Anpassa dig till tekniska förändringar. Sajter uppdaterar hela tiden sina layouter och anti-bot-försvar. Stora plattformar (Amazon, X, Google) skärpte sitt försvar kraftigt 2025–2026. Thunderbits AI och mallar är utformade för att anpassa sig automatiskt.
- Använd officiella API:er när de finns. Om en sajt går över till en betal-API-modell, överväg att byta för bättre driftsäkerhet och efterlevnad.
- Granska din scraping regelbundet. Dokumentera dina källor, kontrollera om ToS eller policyer har ändrats och justera strategin vid behov.
- Utnyttja Thunderbits malluppdateringar. Vårt team håller mallarna aktuella, så du slipper oroa dig för breaking changes eller nya efterlevnadskrav.
- Var flexibel. Om en datakälla blir för riskfylld, byt till en annan eller sök ett samarbete.
Med rätt verktyg och inställning kan du hålla din datapipeline igång – utan att trampa på juridiska minor.
Slutsats: Navigera i det juridiska landskapet för web scraping
Web scraping är inte i sig olagligt – det är ett kraftfullt verktyg för affärer, forskning och innovation. Men som alla verktyg kommer det med regler. Nyckeln är att förstå vad du samlar in, hur du samlar in det och vad du ska göra med datan. Respektera lokala lagar, följ webbplatsers policyer och använd efterlevnadsfokuserade verktyg som Thunderbit för att hålla verksamheten på rätt sida av lagen.
Domstolsavgörandena 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) har stärkt argumentet för att skrapa offentliga data, men nya risker växer fram kring AI-träningsdata, upphovsrättsanspråk och EU AI Act. Plattformsspecifika policyer varierar kraftigt – Google, Amazon, LinkedIn, Meta och X tillämpar alla sina regler på olika sätt – så lär känna landskapet innan du skrapar.
Om du någonsin är osäker, sök juridisk rådgivning – särskilt för stora eller känsliga projekt. Och kom ihåg: det juridiska landskapet förändras hela tiden, så håll dig informerad och flexibel.
Vill du lära dig mer om web scraping, efterlevnad och automatisering? Kolla in Thunderbit Blog för fler guider, eller prova Thunderbits Chrome-tillägg själv.
Börja med efterlevnadsanpassad web scraping med Thunderbit
Vanliga frågor
1. Är web scraping olagligt överallt?
Nej. Web scraping är inte i sig olagligt, men lagligheten beror på vad du skrapar, hur du skrapar det och var du befinner dig. Att skrapa offentliga, icke-personliga data för intern användning är generellt tillåtet i de flesta regioner, men att skrapa personuppgifter eller upphovsrättsskyddade data, eller att bryta mot sajtens villkor, kan vara olagligt (oxylabs.io).
2. Gör robots.txt scraping olagligt om jag ignorerar den?
Robots.txt är inte juridiskt bindande, men det är god praxis att respektera den. Att ignorera robots.txt leder inte i sig till att du blir stämd, men det kan få dig att framstå som en ”bad actor” om det uppstår en tvist (promptcloud.com).
3. Kan jag skrapa Google, Amazon eller LinkedIn?
Det är komplicerat. Alla tre förbjuder scraping i sina ToS, men domstolar har slagit fast att ToS kanske inte binder användare som inte är inloggade (se Meta v. Bright Data och X Corp v. Bright Data, båda 2024). Att skrapa offentligt synliga data (produktpriser, företagslistningar, offentliga profiler) är i regel juridiskt försvarbart i USA. Däremot tillämpar varje plattform sina regler olika: Amazon är mest aggressivt med rättsliga åtgärder (de stämde Perplexity AI i november 2025); LinkedIn lutar sig på tekniska hinder och avtalsanspråk; Google använder i allt högre grad DMCA-baserad tillämpning. Skrapa alltid ansvarsfullt och räkna med tekniska motåtgärder.
4. Kan jag skrapa Facebook eller Instagram?
Efter Meta v. Bright Data (2024) står scraping av offentliga data från Facebook och Instagram utan inloggning på starkare juridisk grund. Domstolen slog fast att Metas ToS inte gäller för icke-användare. Men skapa aldrig falska konton eller skrapa data bakom inloggningsväggar – där går gränsen.
5. Kan jag skrapa X (Twitter)?
X uppdaterade sina ToS 2023 för att förbjuda all scraping utan skriftligt samtycke och har infört aggressivt tekniskt försvar (Cloudflare Turnstile, rate limits på 300 förfrågningar/timme, IP-reputationspoäng). Bright Data vann dock i domstol på liknande grunder – offentliga data som skrapas utan konto binds inte av X:s ToS. Tekniskt sett är X en av de svåraste plattformarna att skrapa 2026.
6. Är det lagligt att skrapa data för att träna AI-modeller?
Det här är den största öppna frågan 2026. Stora mål (NYT v. OpenAI, Anthropics förlikning på 1,5 miljarder dollar) tyder på betydande juridisk risk. EU AI Act kräver att källor till träningsdata redovisas och att avregistrering från upphovsrätt respekteras. Det föreslagna AI Accountability for Publishers Act skulle kräva tillstånd och betalning. Om du skrapar för att träna AI, ta juridisk rådgivning innan du fortsätter.
7. Vad är det säkraste sättet att använda verktyg som Thunderbit?
Håll dig till att skrapa offentliga data, respektera sajtens villkor, undvik personuppgifter om du inte har laglig grund och använd datan internt. Thunderbit är byggt för att hjälpa dig hålla dig inom reglerna genom att bara skrapa det som syns i din webbläsare och varna för riskabla sajter (thunderbit.com).
8. Kan jag skrapa data för kommersiellt bruk?
Det beror på. Att använda skrapad data för intern analys eller forskning är i regel säkrare. Att publicera eller sälja skrapad data, särskilt om den är upphovsrättsskyddad eller innehåller personuppgifter, är mycket mer riskabelt och kan kräva tillstånd eller licens.
9. Hur håller jag koll på juridiska och tekniska förändringar inom web scraping?
Följ nyheter om teknikjuridik, bevaka målwebbplatsernas ToS- eller policyändringar och använd verktyg som Thunderbit som uppdaterar sina mallar och compliancefunktioner regelbundet. Viktigt att bevaka 2026: EU AI Act-tillämpning (augusti), pågående upphovsrättsmål kring AI och nya amerikanska delstatliga integritetslagar. Vid tvekan, rådfråga en jurist.
Prova AI Web Scraper Get Started Free




