

В 2026 году веб — это дикий мир: половина всего интернет-трафика теперь приходится на ботов, а краулеры с открытым исходным кодом — это тихие герои, которые работают за кулисами и обеспечивают всё: от мониторинга цен до обучения ИИ. Я много лет работаю в SaaS и автоматизации, и если я усвоил что-то одно, так это то, что правильный самостоятельно размещаемый веб-краулер может сэкономить вашей команде месяцы нервотрёпки (и, возможно, пару ночных отладок). Неважно, нужно ли вам собрать несколько карточек товаров или обойти миллионы URL ради исследований — в этом списке есть альтернатива Firecrawl с открытым исходным кодом на любой масштаб, стек технологий и уровень терпимости к сложности.
Но вот в чём загвоздка: универсального решения не существует. Одним командам нужна сырая мощь Scrapy или архивная надёжность Heritrix, а другим open-source-библиотеки могут обойтись слишком дорого. Поэтому давайте разберём топ-9 альтернатив Firecrawl с открытым исходным кодом в 2026 году, посмотрим, в чём сильна каждая из них, и поможем подобрать правильный инструмент под задачи вашего бизнеса — без боли проб и ошибок.
Как выбрать лучшую альтернативу Firecrawl с открытым исходным кодом для вашего бизнеса
Прежде чем перейти к списку, давайте поговорим о стратегии. Ландшафт веб-краулинга с открытым исходным кодом сегодня разнообразнее, чем когда-либо, и ваш выбор должен зависеть от нескольких ключевых факторов:
- Простота использования: вам нужен интерфейс с кликами мышью или вы спокойно пишете на Python, Go или JavaScript?
- Масштабируемость: вы скрейпите один сайт или нужно обойти миллионы страниц на сотнях доменов?
- Тип контента: ваш целевой сайт статический HTML или он сильно зависит от JavaScript и динамической загрузки?
- Потребности в интеграции: как вы хотите использовать данные — выгрузить в Excel, отправить в базу данных или передать в аналитический пайплайн?
- Поддержка: есть ли у вас ресурсы поддерживать собственный код или вы хотите инструмент, который автоматически адаптируется к изменениям сайта?
Вот краткая шпаргалка, которая поможет определиться:
| Сценарий | Лучший инструмент(ы) |
|---|---|
| Без кода, офлайн-просмотр | HTTrack |
| Крупномасштабный обход нескольких доменов | Scrapy, Apache Nutch, StormCrawler |
| Сайты с динамикой / сильной зависимостью от JS | Puppeteer |
| Автоматизация форм / требуется вход | MechanicalSoup |
| Скачивание/архивирование статических сайтов | Wget, HTTrack, Heritrix |
| Разработчик на Go, высокая производительность | Colly |
А теперь перейдём к топ-9 альтернатив Firecrawl с открытым исходным кодом в 2026 году.
1. Scrapy: лучший выбор для масштабного краулинга на Python

Scrapy — тяжеловесный чемпион среди краулеров с открытым исходным кодом. Это фреймворк на Python, который выбирают разработчики, когда нужно работать в масштабе — миллионы страниц, частые обновления и сложная логика сайта.
Почему Scrapy?
- Огромный масштаб: Scrapy обрабатывает тысячи запросов в секунду и используется компаниями, которые скрейпят миллиарды страниц в месяц (Zyte).
- Расширяемый и модульный: можно писать собственных пауков, подключать middleware для прокси, обрабатывать логины и выгружать данные в JSON, CSV или базы данных.
- Активное сообщество: масса плагинов, документации и ответов на Stack Overflow.
- Проверен в бою: используется в продакшене командами электронной коммерции, новостей и исследований по всему миру.
Ограничения: крутая кривая обучения для тех, кто не занимается разработкой, и вам придётся поддерживать пауков по мере изменений на сайтах. Но если вам нужен полный контроль и масштабируемость, Scrapy трудно превзойти.
2. Apache Nutch: лучший выбор для корпоративных поисковых систем
Apache Nutch — дедушка open-source-краулеров, созданный для корпоративного обхода на масштабе интернета. Если вы мечтаете построить собственную поисковую систему или обходить миллионы доменов, Nutch — ваш вариант.
Почему Apache Nutch?
- Масштаб на базе Hadoop: благодаря Hadoop Nutch может обходить миллиарды страниц в кластерах серверов (Common Crawl использует его для обхода публичного веба).
- Пакетный краулинг: достаточно передать список стартовых URL и запустить — отлично подходит для плановых крупных задач.
- Интеграция: работает с Solr, Elasticsearch и большими data-пайплайнами.
Ограничения: сложная настройка (Hadoop-кластеры, Java-конфиги), и он больше про сам обход, чем про извлечение структурированных данных. Для небольших проектов это перебор, но для веб-масштаба ему нет равных.
3. Heritrix: лучший выбор для веб-архивации и соответствия требованиям
Heritrix — собственный краулер Internet Archive, специально созданный для веб-архивации и цифрового сохранения.
Почему Heritrix?
- Архивная полнота: захватывает каждую страницу, ресурс и ссылку — идеально для юридического соответствия или исторических снимков сайта.
- Вывод в WARC: сохраняет всё в стандартизованных файлах Web ARChive, готовых к воспроизведению или анализу.
- Веб-администрирование: настраивать и контролировать обход можно через браузерный интерфейс.
Ограничения: тяжёлый инструмент (требует много диска и памяти), не выполняет JavaScript и выдаёт сырые архивы, а не структурированные таблицы данных. Лучше всего подходит для библиотек, архивов или регулируемых отраслей.
4. Colly: лучший выбор для высокопроизводительных разработчиков на Go
Colly — любимец разработчиков на Go: быстрый, лёгкий и очень конкурентный веб-скрейпер.
Почему Colly?
- Молниеносная скорость: конкурентность Go позволяет Colly скрейпить тысячи страниц с минимальной нагрузкой на CPU и RAM (Oxylabs).
- Простой API: можно задавать callback-функции для HTML-элементов, а cookies и robots.txt он обрабатывает автоматически.
- Отлично подходит для статических сайтов: идеален для серверно отрисованных страниц, API или когда нужно встроить скрейпинг в Go-бэкенд.
Ограничения: нет встроенного рендеринга JavaScript (для динамических сайтов его нужно сочетать с чем-то вроде Chromedp), и вам нужно знать Go.
5. MechanicalSoup: лучший выбор для простой автоматизации форм

MechanicalSoup — это Python-библиотека, которая соединяет простые HTTP-запросы и полноценную браузерную автоматизацию.
Почему MechanicalSoup?
- Автоматизация форм: легко входить в аккаунт, заполнять формы и сохранять сессии — отлично для скрейпинга за авторизацией.
- Лёгкость: под капотом Requests и BeautifulSoup, поэтому инструмент быстрый и простой в настройке.
- Идеален для интерактивных сайтов: если нужно отправлять поисковые формы или собирать данные после входа, MechanicalSoup — отличный выбор (Apify Blog).
Ограничения: не выполняет JavaScript, так что на сайтах с тяжёлым JS он не сработает. Лучше всего подходит для статических или серверно отрисованных страниц с простыми взаимодействиями.
6. Puppeteer: лучший выбор для динамических сайтов и сайтов с тяжёлым JavaScript
Puppeteer — швейцарский нож для скрейпинга современных сайтов, насыщенных JavaScript. Это библиотека для Node.js, которая даёт полный контроль над браузером Chrome в headless-режиме.
Почему Puppeteer?
- Работает с динамическим контентом: скрейпит SPA, бесконечную прокрутку и страницы, которые подгружают данные через AJAX (Browserless Guide).
- Имитирует пользователя: нажимает кнопки, заполняет формы, делает скриншоты и даже решает CAPTCHA (с плагинами).
- Мощная автоматизация: отлично подходит для тестирования, мониторинга и скрейпинга всего, что видит реальный пользователь.
Ограничения: требует много ресурсов (запускает полноценные экземпляры Chrome), работает медленнее, чем HTTP-only скрейперы, а масштабирование требует серьёзного железа или облачной оркестрации.
7. Wget: лучший выбор для быстрых загрузок из командной строки

Wget — классический командный инструмент для скачивания статических сайтов и файлов.
Почему Wget?
- Простота: скачайте целый сайт или каталог одной командой — без программирования.
- Скорость: написан на C, поэтому быстрый и эффективный.
- Отлично подходит для статического контента: идеально для документации, блогов или массовой загрузки файлов (HuggingFace Guide).
Ограничения: не выполняет JavaScript и не обрабатывает формы, а также скачивает сырые страницы, а не структурированные данные. Можно считать его цифровым пылесосом для статических сайтов.
8. HTTrack: лучший выбор для офлайн-просмотра без кода
HTTrack — более дружелюбный родственник Wget с графическим интерфейсом для зеркалирования сайтов.
Почему HTTrack?
- Простота GUI: пошаговый мастер делает инструмент доступным даже для нетехнических пользователей.
- Офлайн-просмотр: он переписывает ссылки так, чтобы вы могли просматривать зеркалированные сайты локально.
- Отлично подходит для архивирования: идеален для исследователей, маркетологов и всех, кому нужен снимок сайта без программирования (Reddit DataHoarder).
Ограничения: не поддерживает динамический контент, может быть медленным на больших сайтах и не предназначен для извлечения структурированных данных.
9. StormCrawler: лучший выбор для распределённого краулинга в реальном времени

StormCrawler — современный распределённый краулер для команд, которым нужны веб-данные в реальном времени и в масштабе.
Почему StormCrawler?
- Краулинг в реальном времени: построен на Apache Storm и обрабатывает данные потоками — отлично для мониторинга новостей или поисковых систем (Wikipedia).
- Модульность и масштабируемость: при необходимости добавляйте парсинг, индексацию и собственные processing bolts.
- Используется Common Crawl: обеспечивает работу новостного датасета одного из крупнейших открытых веб-архивов.
Ограничения: требует разработки на Java и кластера Storm, поэтому лучше всего подходит командам с опытом в распределённых системах. Для небольших проектов это чрезмерно.
Сравнение альтернатив Firecrawl с открытым исходным кодом: какой бесплатный конкурент подойдёт вам?
Вот сравнение всех 9 инструментов бок о бок:
| Инструмент | Лучший сценарий использования | Ключевые преимущества | Недостатки | Язык / настройка |
|---|---|---|---|---|
| Scrapy | Крупномасштабный, частый краулинг | Мощный, масштабируемый, огромное сообщество | Крутая кривая обучения, нужен Python | Фреймворк Python |
| Apache Nutch | Корпоративный краулинг на масштабе веба | На базе Hadoop, проверен в масштабе | Сложная настройка, ориентирован на пакетную обработку | Java/Hadoop |
| Heritrix | Архивный краулинг, соответствие требованиям | Полный захват сайта, вывод в WARC | Тяжёлый, без JS, сырые архивы | Java-приложение, веб-интерфейс |
| Colly | Разработчики Go, высокопроизводительный скрейпинг | Быстрый, простой API, конкурентность | Нет JS, нужен Go | Библиотека Go |
| MechanicalSoup | Автоматизация форм, скрейпинг после входа | Лёгкий, работа с сессиями | Нет JS, ограниченный масштаб | Python-библиотека |
| Puppeteer | Сайты с динамикой / тяжёлым JS | Полный контроль над браузером, автоматизация | Требует много ресурсов, нужен Node.js | Библиотека Node.js |
| Wget | Скачивание статических сайтов, офлайн-доступ | Простой, быстрый, CLI | Нет JS, сырые страницы | Командная утилита |
| HTTrack | Нетехнические пользователи, архивирование сайта | GUI, простое офлайн-использование | Нет JS, медленно на больших сайтах | Настольное приложение (GUI) |
| StormCrawler | Распределённый краулинг в реальном времени | Масштабируемый, модульный, в реальном времени | Нужен опыт Java/Storm | Java/Storm-кластер |
Стоит ли строить свой краулер или использовать уже существующую альтернативу Firecrawl с открытым исходным кодом?
Вот честная правда: писать собственный краулер звучит здорово — пока вы не увязнете по колено в поддержке, прокси и борьбе с антибот-защитой. Open-source-инструменты выше аккумулируют годы тяжело добытого опыта и мудрости сообщества. Согласно отраслевым отчётам, использование уже существующих решений — самый быстрый и надёжный способ получить результат и не изобретать велосипед (IveerData).
- Выбирайте open source, если: ваши задачи совпадают с тем, что уже есть на рынке, вы хотите сократить время разработки и цените поддержку сообщества.
- Стройте свой инструмент, если: у вас действительно уникальные требования, глубокая внутренняя экспертиза и скрейпинг — ядро вашего бизнеса.
Однако open source — не «бесплатно», если посчитать стоимость инженерного времени, обслуживания серверов и постоянных обновлений ради борьбы с антискрейпинг-защитой. Если вам нужны преимущества мощного краулера без кода, есть ещё один вариант.
Бонус: если open source слишком сложен, попробуйте Thunderbit
Хотя инструменты выше невероятно полезны для разработчиков, у них есть общие ограничения: они требуют знания кода, плохо справляются с динамическими AI-антиботами и нуждаются в постоянной поддержке.
Thunderbit — мой основной совет всем, кому нужно обойти эти ограничения. Он закрывает разрыв между мощным скрейпингом и простотой использования.
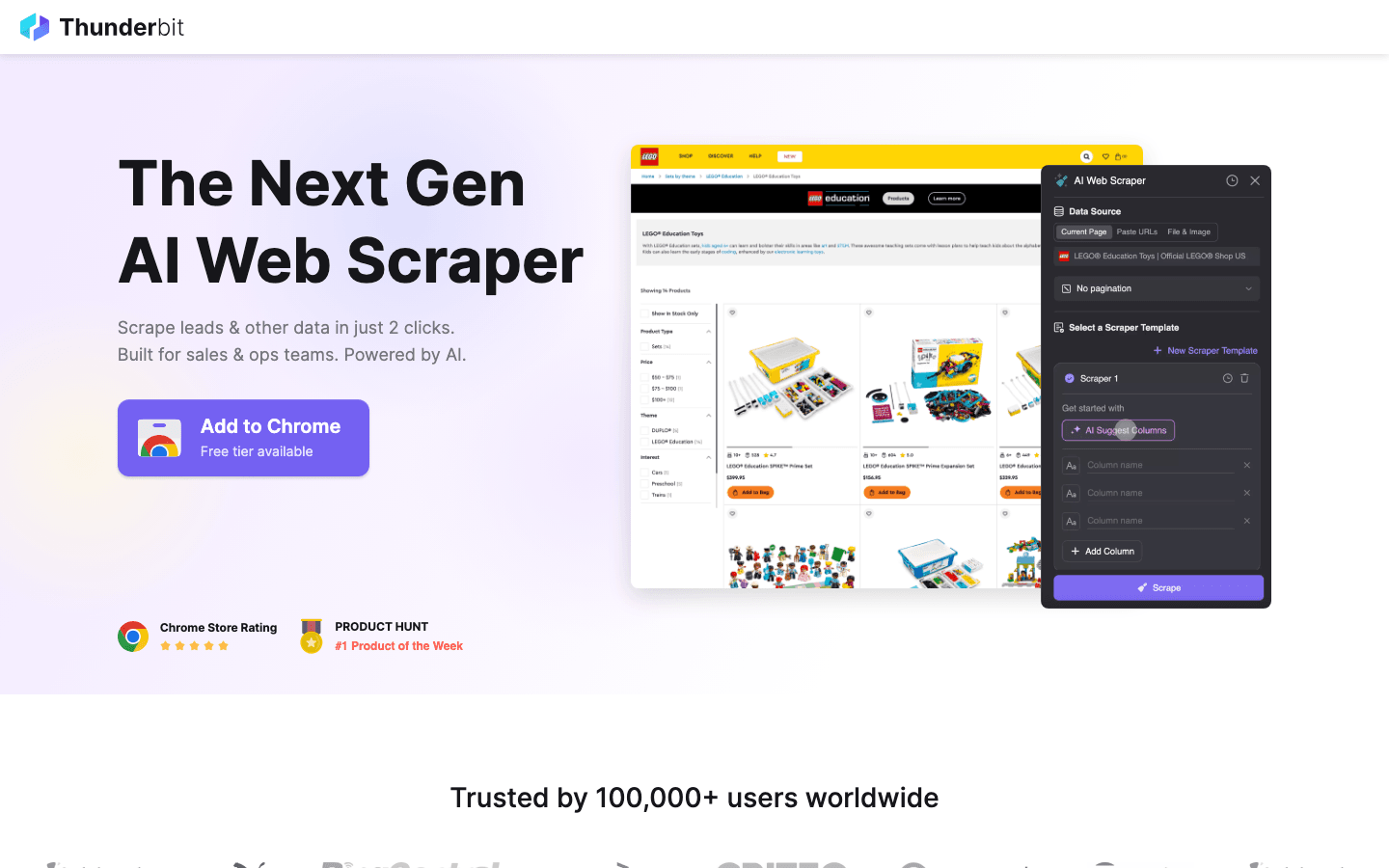
Почему Thunderbit стоит рассмотреть вместо open source?
- Никакого кодинга: в отличие от Scrapy или Puppeteer, Thunderbit — это расширение для Chrome на базе ИИ. Вы нажимаете «AI Suggest Fields», и он сам строит скрейпер.
- Справляется со сложным: динамический контент, бесконечная прокрутка и пагинация обрабатываются ИИ автоматически, экономя вам часы на написание собственных скриптов.
- Мгновенный экспорт: от сайта до Excel, Google Sheets или Notion — в два клика.
- Без поддержки кода: не нужно обновлять скрипты каждый раз, когда сайт меняет дизайн — ИИ Thunderbit адаптируется за вас.
Если вы менеджер по продажам, маркетолог или исследователь, которому нужны данные прямо сейчас без изучения Python или Go, Thunderbit — идеальное дополнение к open-source-инструментам из этого списка.
Хотите увидеть это в деле? Скачайте расширение Chrome и попробуйте сами.
Попробовать Thunderbit AI Web Scraper
Заключение: как найти подходящий самостоятельно размещаемый веб-краулер в 2026 году
Читать больше руководств по веб-скрейпингу Get Started Free
Мир альтернатив Firecrawl с открытым исходным кодом никогда ещё не был таким богатым. Нужен ли вам масштаб Scrapy или Nutch, либо архивная точность Heritrix, для любого бизнес-сценария найдётся решение. Главное — подбирать инструмент под задачу: не усложняйте, если вам нужен просто быстрый сбор данных, и не экономьте на возможностях, если вы работаете в масштабе всего интернета.
И помните: если open-source-путь окажется слишком техническим или затратным по времени, ИИ-инструменты вроде Thunderbit готовы подхватить эстафету.
Готовы начать? Запустите Scrapy для следующего большого data-проекта или попробуйте Thunderbit для простого ИИ-скрейпинга. Если хотите ещё больше советов по веб-скрейпингу, загляните в блог Thunderbit за глубокими разбором и туториалами.
Попробовать Thunderbit для ИИ-скрейпинга веба
Часто задаваемые вопросы
1. В чём главное преимущество альтернатив Firecrawl с открытым исходным кодом?
Open-source-альтернативы дают гибкость, экономию и возможность самостоятельно размещать и настраивать краулер. Вы избегаете зависимости от вендора и получаете поддержку активного сообщества и регулярные обновления.
2. Какой инструмент лучше всего подойдёт нетехническим пользователям, которым нужен быстрый результат?
HTTrack — хороший open-source-вариант для офлайн-просмотра. Но для извлечения структурированных данных, например таблиц в Excel, мы рекомендуем бонусный инструмент Thunderbit благодаря его возможностям ИИ.
3. Как работать с динамическими сайтами, сильно завязанными на JavaScript?
Puppeteer — ваш лучший выбор: он управляет реальным браузером, поэтому может скрейпить всё, что видит пользователь, включая SPA и контент, загружаемый через AJAX.
4. Когда стоит использовать тяжеловесный краулер вроде Apache Nutch или StormCrawler?
Если вам нужно обходить миллионы страниц на множестве доменов или требуется распределённый краулинг в реальном времени, например для поисковиков или мониторинга новостей, эти инструменты созданы именно для такого масштаба и надёжности.
5. Что лучше: написать свой краулер или использовать существующее open-source-решение?
Для большинства команд быстрее, дешевле и надёжнее взять существующий open-source-инструмент и доработать его под себя. Свой краулер имеет смысл писать только при очень специфических требованиях и наличии ресурсов на долгосрочную поддержку.
Удачного краулинга — и пусть ваши данные всегда будут свежими, структурированными и готовыми к работе.
Попробовать Thunderbit AI Web Scraper бесплатно Get Started Free
Узнать больше
- Топ-5 лучших программ для веб-скрейпинга данных в 2026 году
- Топ-15 AI Web Crawlers, которые стоит знать в 2025 году
- Топ-5 лучших программ для веб-скрейпинга данных в 2026 году
- 7 самых популярных инструментов для веб-скрейпинга в 2026 году
- Топ-6 незаменимых инструментов Web Scraper для успеха в 2025 году




