

Вам когда-нибудь начальник вручал стопку PDF-файлов с задачей вытащить из них данные, которые должны быть идеально отформатированы и точны? Делать это вручную — верный способ засидеться допоздна. Извлечение данных из PDF может быть настоящей головной болью, потому что, в отличие от веб-данных, в PDF часто встречается непоследовательное форматирование. В одних PDF есть таблицы, в других — только изображения или отсканированные документы, из-за чего прямое извлечение заметно усложняется.
Извлекайте данные с любого сайта с помощью ИИ Get Started Free
Например, если вам нужно извлечь адреса электронной почты из PDF, часть из них может быть в виде изображений, а часть — скрыта в сложных символьных кодировках. Возьмем такой пример: {john.doe,jane.doe}@example.com. На самом деле это два отдельных адреса: john.doe@example.com и jane.doe@example.com. А еще бывает {first.last}@example.com, где вместо "first" и "last" нужно подставить имя и фамилию автора соответственно. Обычные инструменты распознавания текста здесь бессильны. Именно тут на помощь приходит удобный инструмент — PDF Scraper.
Что такое PDF Scraper
PDF Scraper — это удобный инструмент, который автоматически извлекает данные из PDF-файлов, преобразуя содержимое, например таблицы и текст, в нужные вам форматы, такие как Excel, CSV или JSON. Проще говоря, он превращает утомительное копирование и вставку в решение в один клик.
Представьте себе стопку счетов, контрактов, научных работ или даже отсканированных PDF, которые в ручном режиме пришлось бы перепечатывать часами. С PDF Scraper достаточно загрузить файл — и уже через несколько секунд данные будут извлечены, экономя ваше время и силы при высокой точности. Попрощайтесь с рутиной ручного ввода данных.
Если в вашем PDF есть разные типы данных — таблицы, ссылки и изображения, — поручите это AI PDF Scraper. AI PDF Scrapers используют большие языковые модели (LLM), которые могут одновременно обрабатывать текст, изображения и таблицы, показывая впечатляющие результаты.
Преимущества AI PDF Scraper не ограничиваются эффективностью и точностью: его гибкость делает работу с ним по-настоящему беззаботной. Будь то отсканированные документы, изображения или многоязычные PDF, ИИ справляется со всем легко. Существует множество отличных ИИ-инструментов, таких как Thunderbit, ChatGPT и ChatPDF, у каждого из которых свои особенности под разные задачи. Нужно ли вам быстро извлечь данные или проанализировать сложные документы, правильный инструмент сделает работу проще и эффективнее.
Попробуйте сами: извлекайте данные из PDF с помощью ИИ
Попробуйте! Вы можете нажимать, исследовать и запускать процесс прямо по ходу просмотра.
Как выбрать подходящий PDF Scraper
Выбор PDF Scraper — как покупка автомобиля: лучший вариант тот, который подходит именно вам. Вот на что стоит обратить внимание:
| Характеристика | Описание |
|---|---|
| Точность и стабильность | Проверьте, извлекает ли инструмент данные точно, особенно если речь о критически важной информации. |
| Форматы вывода | Убедитесь, что инструмент поддерживает нужные вам форматы, например Excel, CSV или JSON. |
| Интеграция с другими инструментами | Если вам нужно подключение к системам компании, проверьте, есть ли бесшовная интеграция. |
| Понятный интерфейс | Для обычных пользователей лучше подходит удобный инструмент, а более сложные решения могут быть полезны техническим командам. |
У разных инструментов свои сильные стороны, и правильный выбор может заметно повысить вашу продуктивность. Ниже — три популярных PDF Scraper, каждый со своими возможностями под разные задачи:
| Инструмент | Плюсы | Минусы |
|---|---|---|
| Thunderbit | Быстрое извлечение; удобно использовать как расширение браузера; отлично подходит для командной работы | Ограниченный масштаб обработки данных |
| ChatPDF | Прост в использовании, чат-формат вопросов и ответов по одному PDF | Нет нативного экспорта в CSV/Excel/JSON — ответы остаются в чате |
| ChatGPT | Гибко справляется со сложной семантикой, подходит для широкого круга задач | Каждый раз нужно вручную вводить запрос |
Как начать работу с AI PDF Scraper
Thunderbit
Хотите быстро извлекать данные из PDF, не тратя лишние время и силы? Thunderbit — это как раз то, что нужно. Он прост в использовании, и всего в один клик вы можете все сделать. Следуйте этим шагам, чтобы легко преобразовать сложные данные из PDF в нужный формат и заметно повысить эффективность:
-
Добавьте Thunderbit в Chrome и зарегистрируйтесь:
Перейдите на официальный сайт Thunderbit и установите расширение Thunderbit в браузер Chrome. Зарегистрируйтесь с помощью аккаунта Google или другого адреса электронной почты.

-
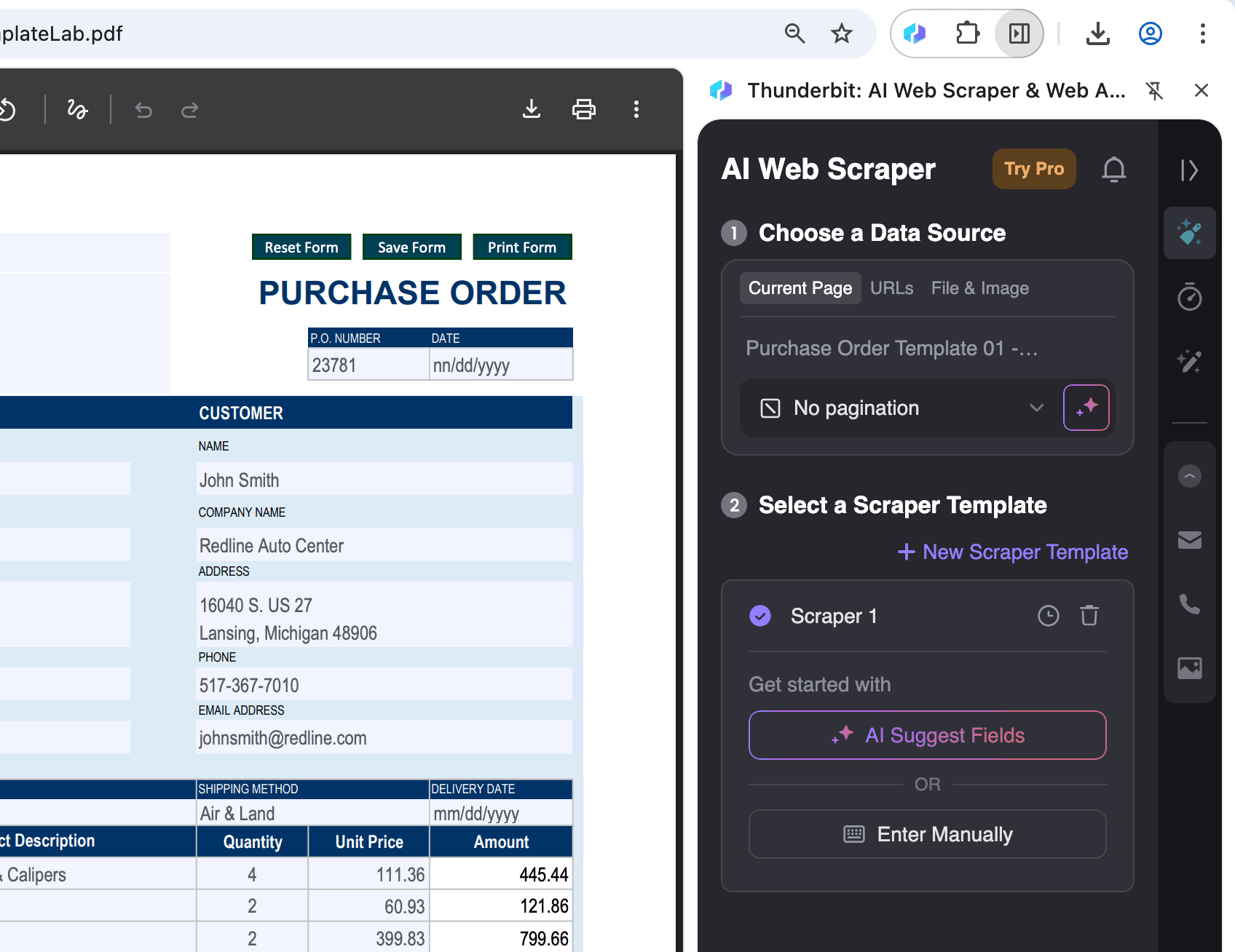
Откройте PDF в Chrome:
Откройте PDF-файл, из которого хотите извлечь данные, в Chrome и нажмите на значок Thunderbit в правом верхнем углу.
-
Выберите формат вывода и экспортируйте:
После выбора AI Suggest Columns вы можете отфильтровать или скорректировать данные по необходимости. Затем выберите нужный формат экспорта (CSV, Google Sheets, Airtable или Notion) и нажмите Scrape, чтобы экспортировать данные.
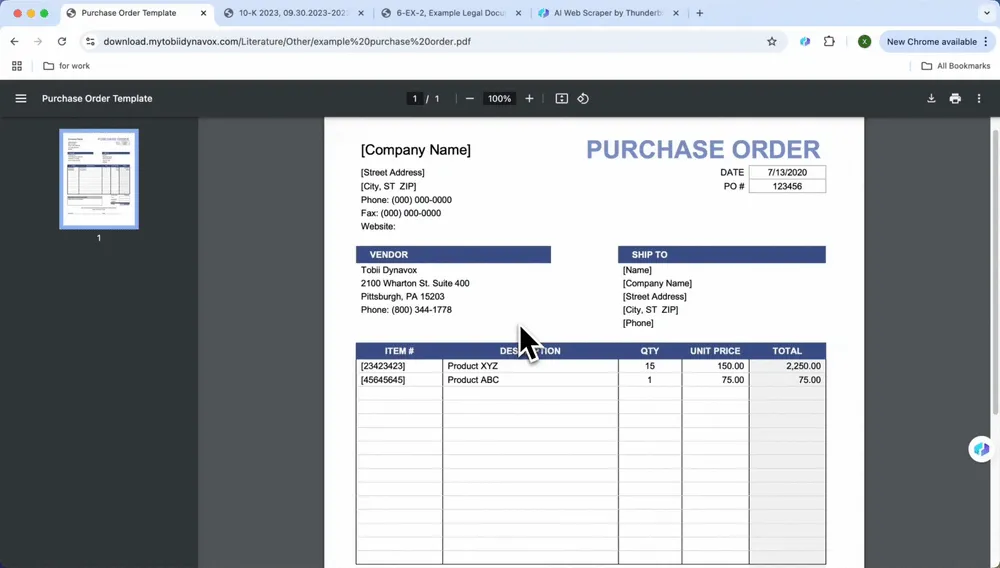 Экспортированные данные можно напрямую подключить к Notion, Airtable или Google Sheets для удобной командной работы.
Экспортированные данные можно напрямую подключить к Notion, Airtable или Google Sheets для удобной командной работы.
Thunderbit — это простой инструмент для извлечения данных из PDF, который позволяет быстро получать нужные данные из PDF-файлов и преобразовывать их в удобный для использования формат. Будь то личные задачи или командная работа, Thunderbit может значительно повысить вашу продуктивность, делая извлечение данных проще и удобнее.
ChatPDF
Если вам нужно обрабатывать PDF в больших объемах и при этом извлекать только конкретную ключевую информацию, а не все данные целиком, ChatPDF — отличный помощник. Он позволяет извлекать данные в диалоговом формате, поэтому подходит даже новичкам.
Вот как извлечь данные из PDF с помощью ChatPDF:
- Перейдите на сайт ChatPDF: Откройте сайт ChatPDF или связанную с ним страницу платформы.
- Загрузите PDF-файлы: Нажмите кнопку "Upload File", чтобы перетащить или выбрать PDF-документ для анализа. Поддерживаются разные типы файлов, например контракты, статьи или финансовые отчеты.
- Проанализируйте PDF: После загрузки ChatPDF автоматически разберет содержимое файла и сформирует структурированное резюме документа. Затем вы сможете просмотреть извлеченную ключевую информацию.
- Задайте вопрос: Используйте поле ввода, чтобы задать вопросы вроде "Какой вывод в этом отчете?" или "Какая общая сумма указана в счете?" ChatPDF извлечет релевантный контент на основе вашего запроса.
- Скопируйте ответы: ChatPDF показывает ответы прямо в окне чата. Скопируйте их в таблицу, документ или собственную таблицу — для строго структурированного вывода (чистый CSV/JSON с одинаковыми столбцами во многих файлах) лучше подойдут Thunderbit или ChatGPT с фиксированным запросом.
ChatPDF предлагает интерактивный формат работы, поэтому особенно хорошо подходит для быстрого поиска информации в документах, например для нахождения ключевых деталей или краткого пересказа содержимого.
ChatGPT
ChatGPT отлично справляется со сложными семантическими данными, например с разбором пунктов в юридических документах. Этот инструмент очень гибкий: вы можете настраивать запросы под извлечение конкретных данных или анализ содержимого. Однако для похожих задач приходится снова и снова использовать один и тот же запрос, и здесь важно уметь грамотно формулировать промпты.
Вот готовый промпт, который можно адаптировать под свои задачи (не забудьте заменить столбцы на нужную вам информацию):
Теперь вы PDF scraper. Ваша задача — при получении PDF извлечь его содержимое на основе столбцов, которые задает пользователь. Ваш результат должен быть CSV-файлом.
Вот столбцы:
1. Имя
2. Email
3. Номер телефона
4. ...
- Зарегистрируйтесь или войдите в систему: Откройте сайт ChatGPT и зарегистрируйте аккаунт. Если у вас уже есть аккаунт, просто войдите.
- Загрузите PDF и введите запрос: Прямо введите запрос в поле ввода — чем он конкретнее, тем лучше. Например: "В этом PDF-документе есть три диаграммы, экспортируй их в виде таблиц."
- Проверьте и скорректируйте результат: Убедитесь, что ответ соответствует вашим ожиданиям. Если нужно, уточните результат, задавая дополнительные вопросы или корректируя запрос.
- Экспортируйте данные в Excel или CSV: Если данные, извлеченные ChatGPT, вам подходят, введите в поле: "Экспортируй эти данные в Excel или CSV."
- Сохраните результат: Нажмите на ссылку на файл, которую предоставит ChatGPT, чтобы скачать файл.
Реальные сценарии использования AI PDF Scraper
AI PDF Scraper — это универсальный помощник в работе, будь то счета, контракты, финансовые отчеты или заказ-наряды. Вот несколько практических сценариев, где он особенно хорош:
Обработка счетов и квитанций
Пакетно обрабатывайте счета и квитанции компании, извлекая ключевую информацию, такую как суммы и даты, для классификации и архивирования.
- Запустите Thunderbit, нажмите AI Web Scraper, а затем Bulk Pages
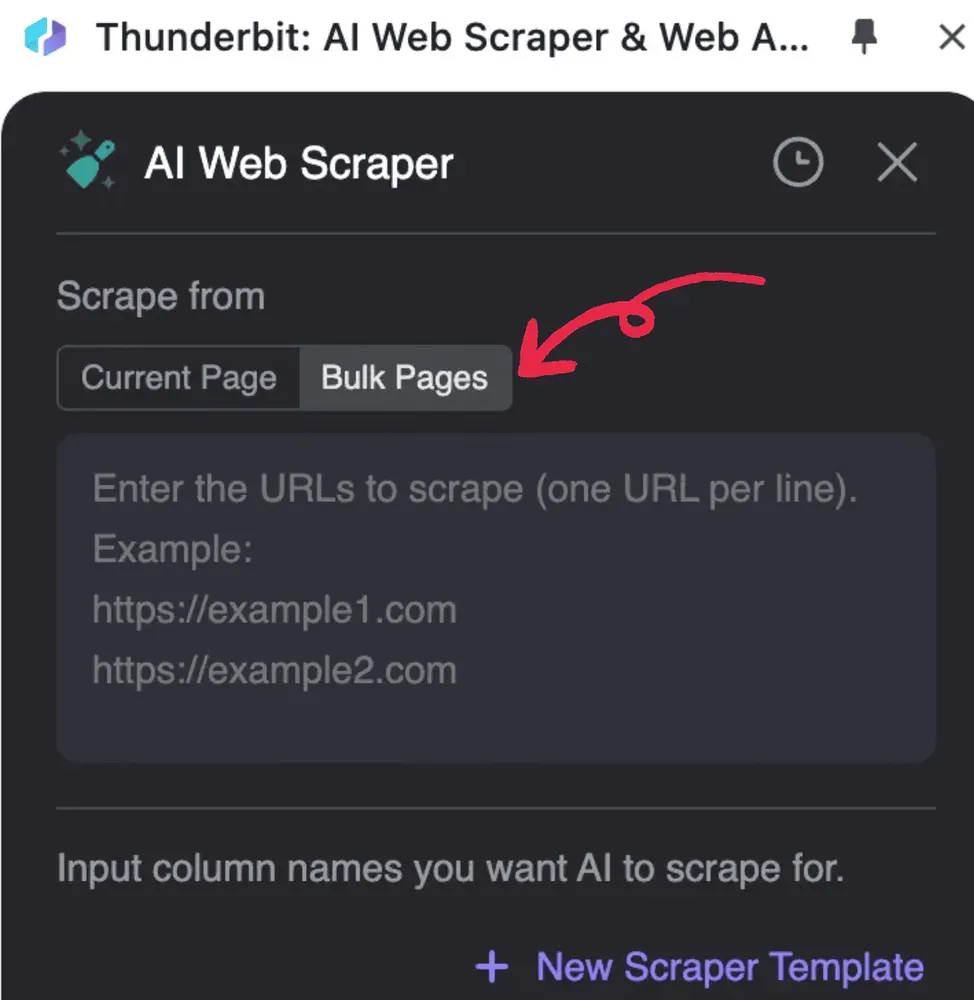 2. Введите URL PDF-файлов, которые хотите обработать, по одному URL в строке
2. Введите URL PDF-файлов, которые хотите обработать, по одному URL в строке
 3. Нажмите AI Suggest Columns (ИИ прочитает PDF и предложит, как структурировать данные)
4. Нажмите Scrape и экспортируйте данные
3. Нажмите AI Suggest Columns (ИИ прочитает PDF и предложит, как структурировать данные)
4. Нажмите Scrape и экспортируйте данные
Обработка заказ-нарядов
Автоматически определяйте позиции, количество и цены за единицу в заказ-нарядах, создавая стандартизированные записи данных и извлекая данные из PDF, чтобы сэкономить время на ручной обработке.
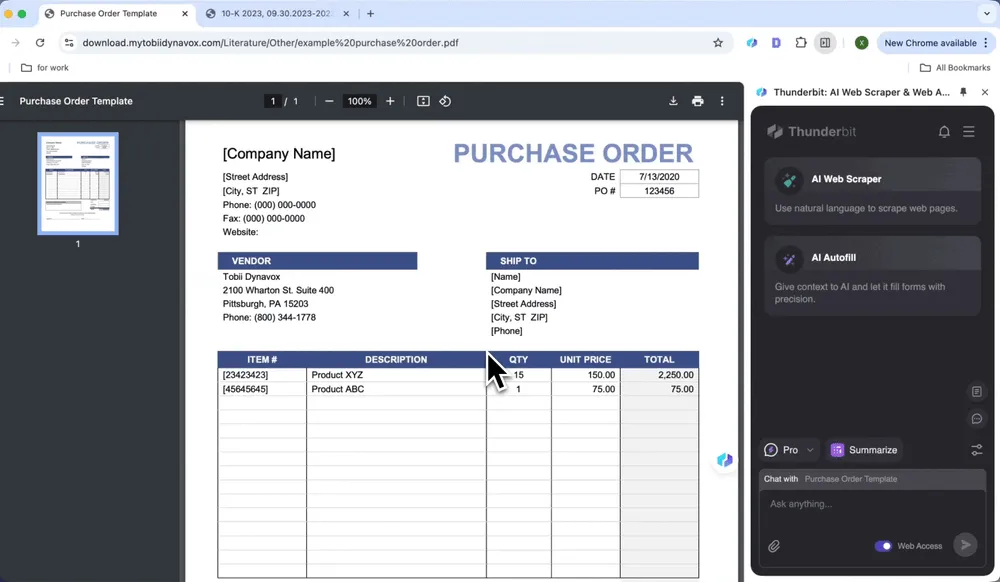
- Откройте заказ-наряд в Chrome и запустите Thunderbit
- Нажмите AI Web Scraper, затем AI Suggest Columns
- Проверьте сгенерированные названия списков и нажмите Scrape
- Нажмите Download CSV
Извлечение финансовых данных
Извлекайте данные из финансовых отчетов одним нажатием — например, показатели прибыльности и объемы продаж — и избавьтесь от утомительной ручной проверки.
- Откройте финансовый отчет в Chrome и запустите Thunderbit
- Нажмите Summarize
- Автоматически сгенерируйте сводку ключевой информации, включая текст и содержимое таблиц
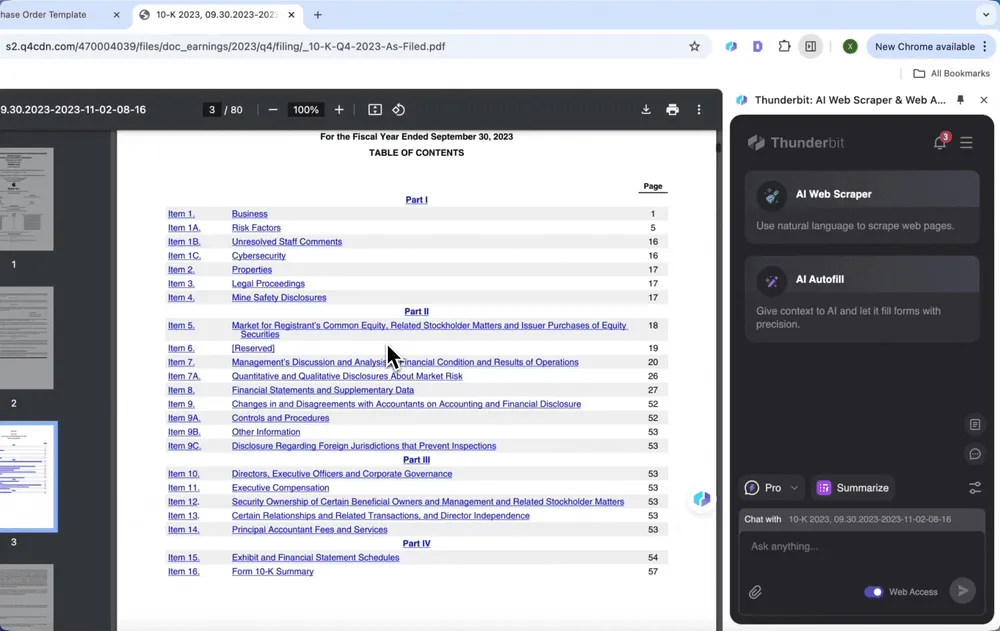
Не устраивает автоматически созданная сводка? Вы можете вручную ввести нужную вам информацию по проекту.
- Откройте финансовый отчет в Chrome и запустите Thunderbit
- Нажмите AI Web Scraper, введите нужные вам названия показателей, например Net Income, Sales и т. д.
- Нажмите Scrape, output Table
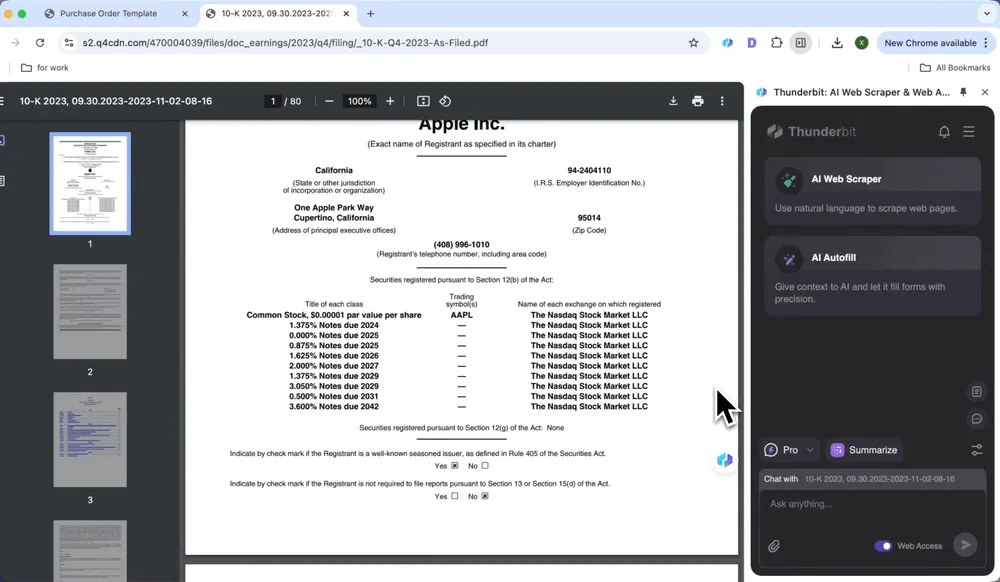
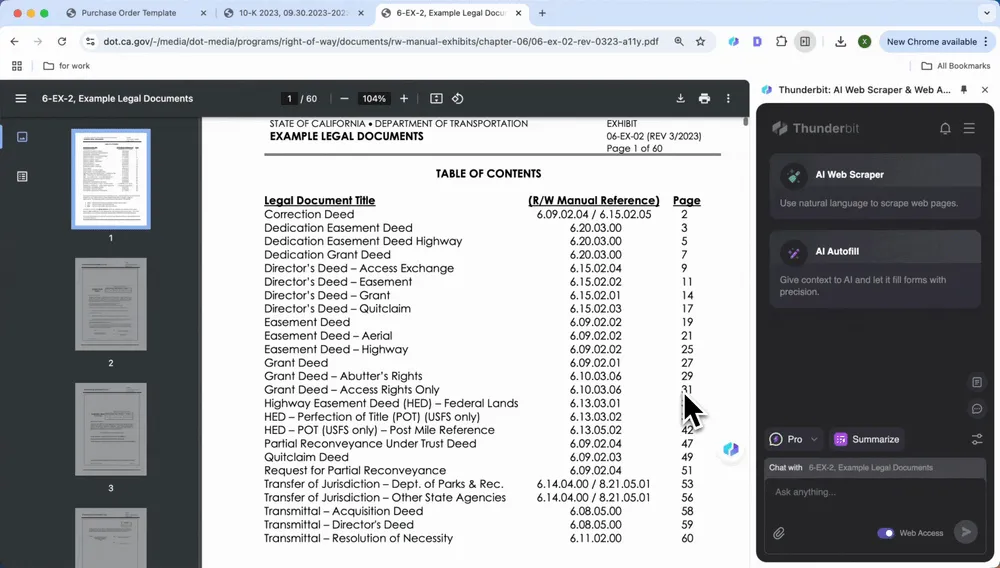
Анализ юридических документов
Трудно разобраться в пунктах договора и соглашения? Инструменты ИИ могут быстро найти условия оплаты, пункты о нарушении обязательств, сроки действия договора и другие важные моменты. Извлеките их одним кликом, чтобы получить краткое резюме или список пунктов, сэкономив время и не упустив ни одной детали.
Как и при извлечении ключевой информации из финансовых отчетов, вы можете открыть PDF и нажать Summarize, чтобы одним кликом увидеть условия оплаты, пункты о нарушении обязательств, сроки договора и другую важную информацию.
Часто задаваемые вопросы
-
Можно ли извлечь данные сразу из нескольких PDF?
Да, продвинутые инструменты PDF scraping позволяют извлекать данные сразу из нескольких PDF одновременно. Такая пакетная обработка значительно ускоряет рабочий процесс по сравнению с ручным извлечением.
-
PDF Scraper бесплатный?
Да, существует несколько бесплатных инструментов PDF scraper. Многие онлайн-сервисы, такие как Thunderbit и ChatPDF, предлагают бесплатное извлечение страниц и данных. Хотя некоторые расширенные функции могут быть платными, базовые возможности извлечения данных обычно бесплатны.
-
Нужны ли навыки программирования, чтобы пользоваться PDF scraper?
Нет, многие AI PDF scraper, такие как Thunderbit, рассчитаны на пользователей без навыков программирования. У них удобный интерфейс, который позволяет загружать файлы и извлекать данные всего в несколько кликов.
-
Какие типы документов можно обрабатывать с помощью PDF scraper?
PDF scraper может работать с разными типами документов, включая счета, контракты, финансовые отчеты, научные работы и любой другой структурированный или полуструктурированный контент в PDF-файлах.
-
Насколько безопасны мои данные при использовании PDF scraper?
Надежные инструменты PDF scraping уделяют первоочередное внимание безопасности пользователей и часто соответствуют таким требованиям, как GDPR. Обычно они хранят данные на зашифрованных серверах и не получают к ним доступ без вашего разрешения.
-
Есть ли другие способы извлечения данных из PDF?
Существует несколько способов извлечь данные из PDF-файлов помимо ручного ввода и Python-скриптов. К ним относятся PDF-конвертеры для преобразования файлов в форматы вроде Excel или CSV, специализированные инструменты извлечения данных из PDF, такие как Tabula и Excalibur, для структурированных документов, решения на базе ИИ с оптическим распознаванием символов (OCR) как для нативных, так и для отсканированных PDF, а также инструменты с открытым исходным кодом, например Extractous и PymuPDF4llm, созданные для эффективного извлечения данных. У каждого метода есть свои плюсы и минусы, поэтому выбор зависит от конкретных требований и технической подготовки пользователя.
Узнать больше
- Как извлекать данные с любого сайта с помощью ИИ
- Топ-5 инструментов с ИИ для извлечения данных из PDF
- Как использовать ChatGPT для извлечения данных из PDF
- Бесплатный онлайн-суммаризатор PDF
Попробуйте AI Web Scraper Get Started Free




