На прошлой неделе один из наших пользователей написал нам: «Мне нужны цены, описания и данные по вариантам из 14 магазинов-конкурентов на Shopify — к пятнице». Это примерно 4 000 страниц товаров. Копипастой? Даже не обсуждается.
Если вы когда-нибудь пытались выгрузить данные о товарах из магазина на Shopify — цены, изображения, описания, варианты, отзывы — вы знаете, насколько это мучительно. По состоянию на 2026 год в сети работает более , и ни у одного из них нет кнопки «экспорт для посторонних». При этом говорят, что активно отслеживают цены конкурентов, а провайдеры e-commerce-услуг сообщают, что ручная загрузка даже одного товара с вариантами и изображениями может занимать . Умножьте это на несколько сотен товаров — и вся ваша неделя исчезла.
Именно поэтому расширения Chrome для Shopify scraping стали стандартной частью набора инструментов в e-commerce — для анализа конкурентов, поиска товаров для дропшиппинга, миграции каталогов и не только. Но большинство материалов о «лучших scraper» просто перечисляют функции, не показывая, что реально происходит, когда вы запускаете их на настоящих магазинах Shopify. Эта статья другая. Я протестировал восемь расширений на реальных витринах, наткнулся на настоящие антибот-барьеры и выяснил, какие инструменты действительно вытягивают глубокие данные о товарах, а какие останавливаются на поверхности.
Почему e-commerce-командам нужен Chrome-расширение Shopify Scraper
Магазины Shopify — это кладезь коммерчески полезных данных о товарах. Но как внешний пользователь вы не получаете CSV-файл. Вы видите витрину магазина. Чтобы превратить эту витрину в полезную аналитику, нужен scraper — и сценарии использования далеко не ограничиваются «хочу список названий товаров».
Главный вопрос: какие именно данные вам нужны и для какого процесса? Вот как самые распространённые e-commerce-сценарии соотносятся с конкретными полями данных:
Исследование цен конкурентов
Вам нужны: названия товаров, цены, зачёркнутые цены и цены по вариантам. Это основа динамического ценообразования — важно понимать не только, сколько конкурент берёт за товар, но и как он делает скидки, комплектует и назначает цены для разных размеров или цветов.
Поиск товаров для дропшиппинга
Вам нужны: названия, все изображения (а не только миниатюры), полные описания и даты публикации. Сортировка по самой свежей дате публикации помогает заметить трендовые или недавно запущенные товары до того, как рынок ими перенасытится.
Импорт каталога в свой магазин
Вам нужны: названия, body HTML, все изображения, варианты, SKU и цены — в идеале в формате . Не каждый инструмент делает это аккуратно.
Оценка скорости продаж
Вам нужны: названия товаров и остатки на складе, отслеживаемые во времени. Фиксируя уровни запасов по расписанию, можно оценить, насколько быстро конкурент продаёт товар — грубый, но полезный показатель, когда прямые данные о продажах недоступны.
Генерация лидов (поиск владельцев магазинов)
Вам нужны: название магазина, контактный email, номер телефона и иногда приложения или технологический стек, который использует магазин. Команды продаж используют это для формирования списков для outreach, сегментированных по нише или технологии.
Краткая шпаргалка:
| Сценарий | Ключевые нужные поля данных | Рекомендуемый рабочий процесс |
|---|---|---|
| Исследование цен конкурентов | Название, цена, зачёркнутая цена, цены по вариантам | Сбор данных со страницы списка + обогащение через подстраницы для вариантов |
| Поиск товаров для дропшиппинга | Название, цена, изображения (все), описание, дата публикации | Сбор со страницы товара + сортировка по самой свежей дате публикации |
| Импорт каталога в свой магазин | Название, body HTML, изображения, варианты, SKU, цена | Полный сбор с подстраниц → экспорт в CSV для Shopify |
| Оценка продаж | Название, количество на складе (во времени) | Планируемый сбор → отслеживание в Google Sheets |
| Генерация лидов (владельцы магазинов) | Название магазина, email, телефон, используемые приложения | Сбор с контактных страниц магазина + извлечение email/телефонов |
Как я оценивал эти 8 расширений Chrome для Shopify Scraper
Я установил все восемь расширений и прогнал их по одному и тому же набору реальных магазинов Shopify — включая публичные магазины, магазины под защитой Cloudflare и магазины, где products.json отключён. Я не просто смотрел на списки функций. Я хотел увидеть, что реально происходит, когда вы нажимаете «scrape» на живой странице коллекции Shopify.
Вот восемь критериев, которые я использовал, и почему каждый из них особенно важен именно для Shopify:
| Критерий | Почему это важно для Shopify scraping |
|---|---|
| Простота настройки | Сможет ли нетехнический пользователь начать сбор данных менее чем за 5 минут? |
| Извлекаемые поля данных | Получает ли инструмент название, цену, изображения, описания, варианты И отзывы — или только поверхностные данные? |
| Обогащение через подстраницы | Может ли он сначала собрать страницу списка, а затем автоматически зайти на каждую карточку товара за полными деталями? |
| Обработка пагинации | Может ли он собирать данные дальше первой страницы товаров (клики по пагинации или бесконечная прокрутка)? |
| Устойчивость к антибот-защите | Справляется ли он с Cloudflare Turnstile или защитой Shopify от ботов без сбоев? |
| Форматы экспорта | CSV, Excel, Google Sheets, Airtable, Notion, CSV для импорта в Shopify? |
| Планируемый/повторяющийся сбор | Может ли он автоматически отслеживать цены или изменения запасов со временем? |
| Прозрачность цен | Лимиты бесплатного тарифа, система кредитов, фиксированная плата — и что вы реально получаете |
С этой рамкой в голове посмотрим, как показал себя каждый инструмент.
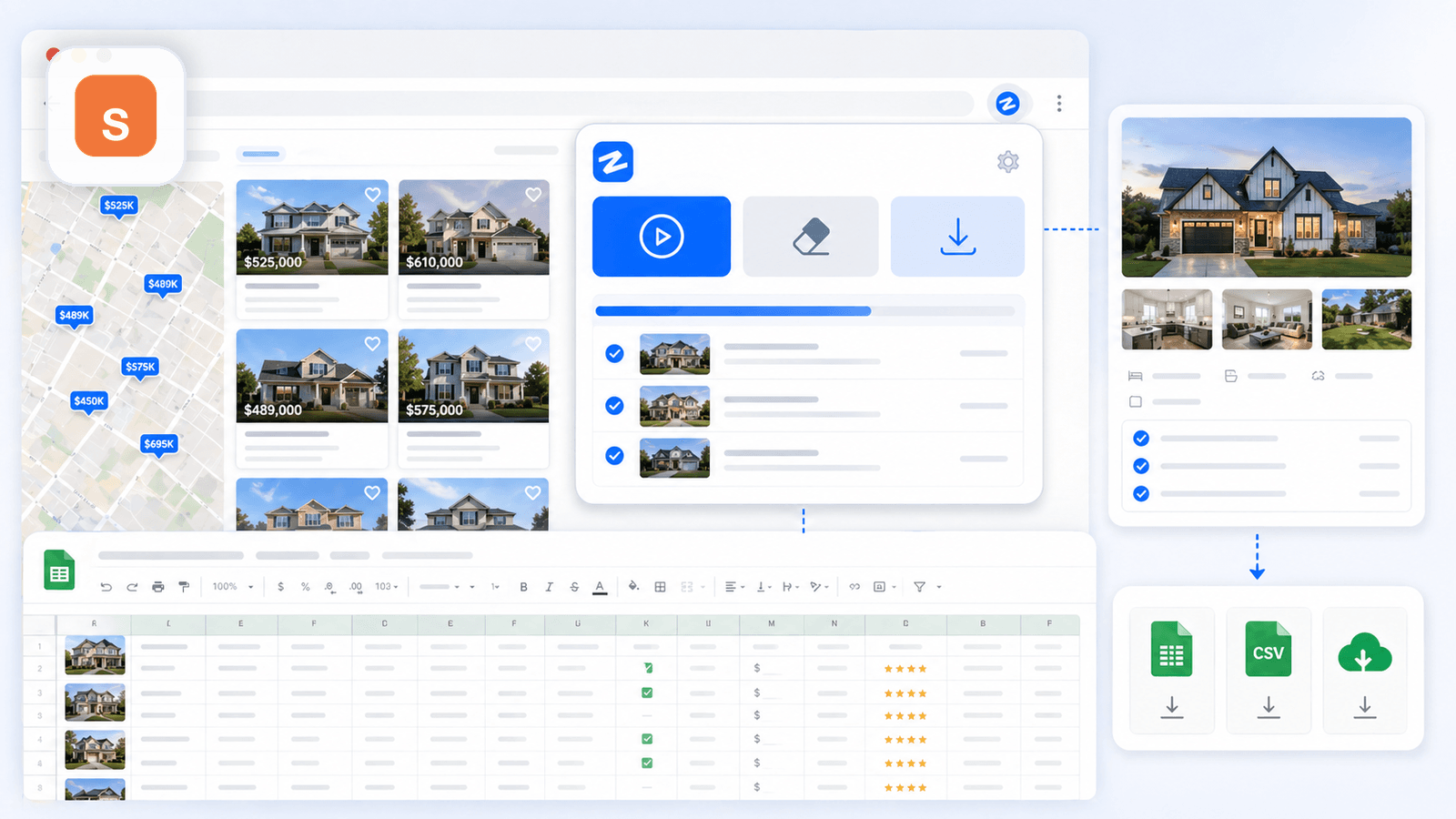
1. Thunderbit — AI-скрейпер для Shopify, созданный для тех, кто не пишет код
— это инструмент, который мы сделали в Thunderbit специально для бизнес-пользователей, которым нужны глубокие данные о товарах без кода, без настройки CSS-селекторов и без 20 минут на подготовку. Рабочий процесс для магазина Shopify действительно состоит из двух кликов: открыть страницу коллекции, нажать «AI Suggest Fields», и AI прочитает страницу и предложит столбцы (название, цена, изображение и т. д.). Нажимаете «Scrape» — и с листингом всё.
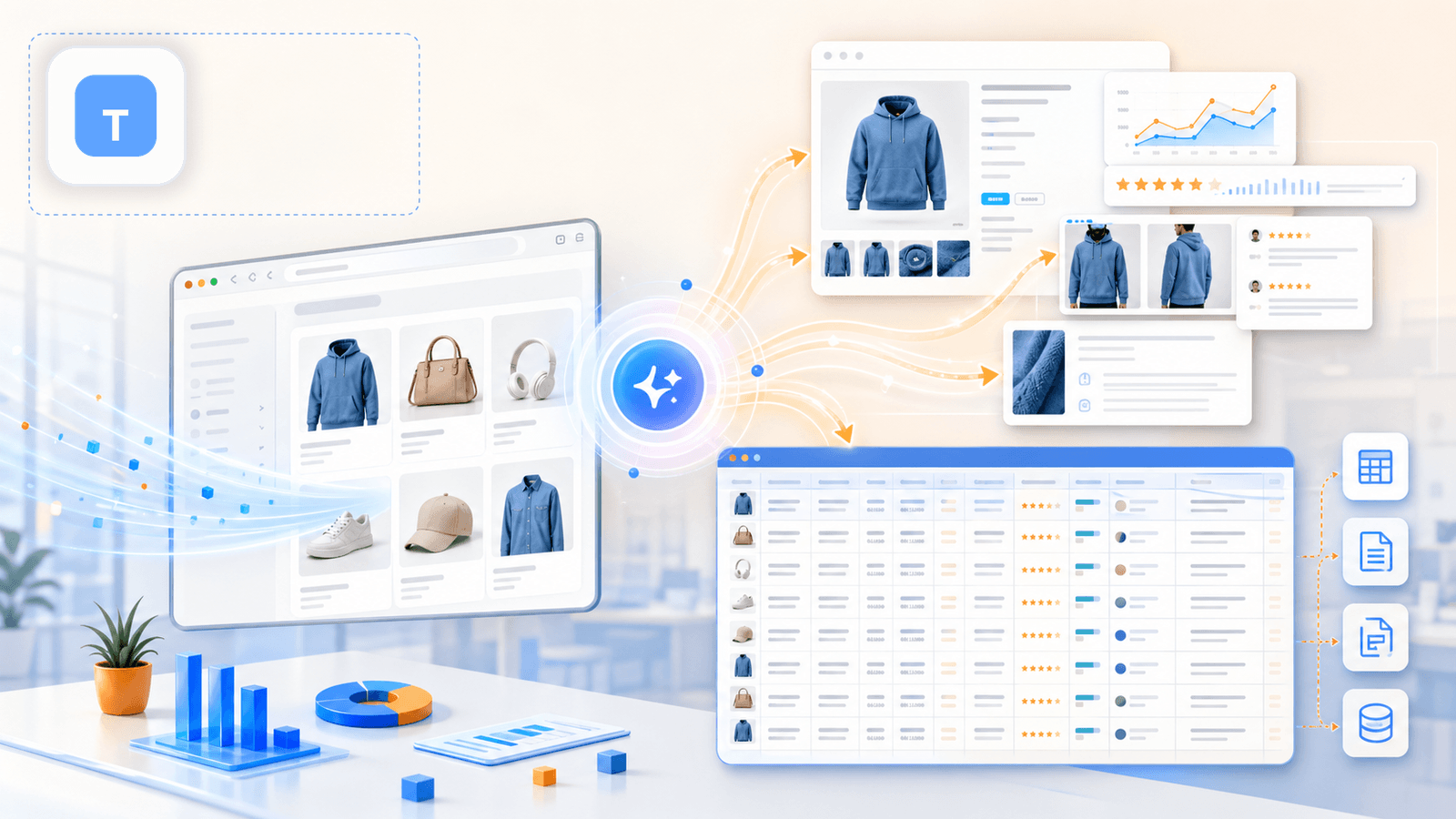
Но главное отличие — и то, что чаще всего упускают конкурирующие статьи, — это то, что происходит дальше.
Обогащение подстраниц: функция, которая меняет всё
После сбора страницы списка нажимаете «Scrape Subpages». AI Thunderbit заходит на каждую отдельную страницу товара и дополняет вашу исходную таблицу данными со страницы товара: полные описания, все изображения галереи, варианты, SKU, количество отзывов и многое другое. Именно этот шаг превращает поверхностную таблицу в пригодный для работы набор данных для конкурентного анализа.
Ниже я подробнее объясню, почему это важно, и покажу сравнение до/после в отдельном разделе.
Ключевые сильные стороны для Shopify scraping
- AI Suggest Fields читает страницу Shopify и автоматически формирует правильную структуру столбцов — без CSS-селекторов и ручной настройки
- Сбор подстраниц заполняет пробелы в данных, которые не попадают на страницу списка (полные описания, варианты, галереи изображений, отзывы)
- Cloud scraping mode для быстрого массового сбора на публичных магазинах; browser scraping mode для магазинов под Cloudflare или с требованием входа в систему
- Обработка пагинации (по клику и бесконечная прокрутка)
- Планируемый сбор для постоянного мониторинга цен и запасов — просто опишите расписание обычным языком (например, «каждый понедельник в 9:00»)
- Бесплатные извлекатели email и телефона для сценариев лидогенерации
- Экспорт в Excel, Google Sheets, Airtable, Notion, CSV, JSON — включая форматы, удобные для импорта в Shopify
- Field AI Prompt позволяет задавать собственные инструкции для каждого столбца (например, «разделить на 3 типа товаров» или «перевести описание на английский»)
Где он уступает
- Ценообразование на основе кредитов означает, что для очень больших объёмов (десятки тысяч товаров) нужен платный тариф
- Обработка AI добавляет несколько секунд на строку по сравнению с шаблонными скрейперами на очень простых страницах
Цены
- Бесплатный тариф: 6 страниц (или до 10 с бесплатным пробным периодом), все экспорты бесплатны
- Starter: , 500 кредитов/месяц
- Professional: от $38/месяц (3 000 кредитов) до $249/месяц (20 000 кредитов)
- Правила кредитов: 1 выходная строка = 1 кредит для web scraping; 1 выходная строка = 2 кредита для scraping подстраниц; экспорт всегда бесплатен
Лучше всего подходит для: Нетехнических e-commerce-команд, которым нужны самые глубокие данные о товарах Shopify с минимальной настройкой — и которые хотят отслеживать конкурентов со временем.
2. Instant Data Scraper — вариант с автоматическим определением и без настройки
Instant Data Scraper — это бесплатное расширение Chrome, которое использует эвристические алгоритмы для автоматического распознавания табличных данных на веб-страницах. Настройка вообще не нужна — откройте страницу коллекции Shopify, нажмите на иконку расширения, и оно попытается определить и показать данные о товарах в таблице.
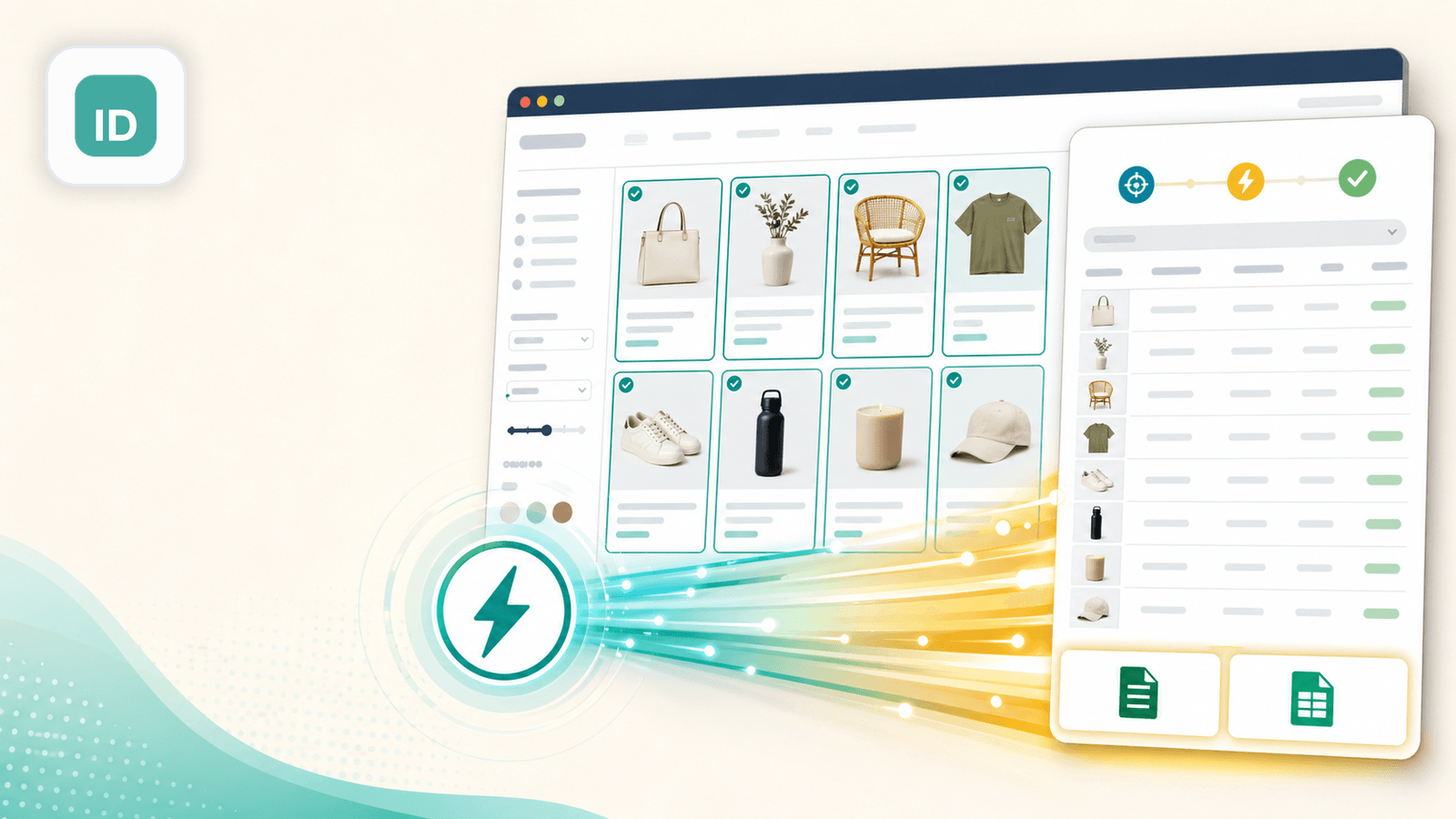
В моём тестировании оно хорошо работало на стандартных страницах коллекций Shopify с темой Dawn, за считанные секунды подхватывая названия, цены и URL миниатюр. На магазинах с нестандартной версткой оно иногда хватало ссылки навигации или содержимое футера вместо товаров — результат нужно проверять глазами.
Ключевые сильные стороны для Shopify scraping
- Полностью бесплатно, без лимитов по использованию
- Автоопределение означает нулевое время на настройку — отлично для быстрых разовых выгрузок
- Поддерживает пагинацию (может автоматически нажимать «next page»)
- Экспорт в CSV и XLSX
Где он уступает
- Автоопределение работает не всегда на магазинах Shopify с нестандартной версткой
- Нет обогащения подстраниц: вы получаете данные со страницы списка (название, цена, миниатюра), но не полные описания, варианты или отзывы
- Нет AI для очистки, разметки или преобразования данных
- Нет планирования, нет cloud scraping
- Нет прямого экспорта в Google Sheets, Airtable или Notion
Цены
- Полностью бесплатно
Лучше всего подходит для: Всем, кому нужен быстрый, бесплатный и не требующий настройки экспорт видимых данных со страницы списка в обычном магазине Shopify.
3. Web Scraper — визуальный конструктор sitemap
Web Scraper (webscraper.io) — классическое расширение Chrome по принципу point-and-click для создания «sitemap» — рецептов scraping, где вы выбираете элементы на странице и задаёте логику сбора. В Shopify вы бы создавали sitemap, кликая по названиям товаров, ценам, изображениям и задавая правила пагинации и переходов по ссылкам.
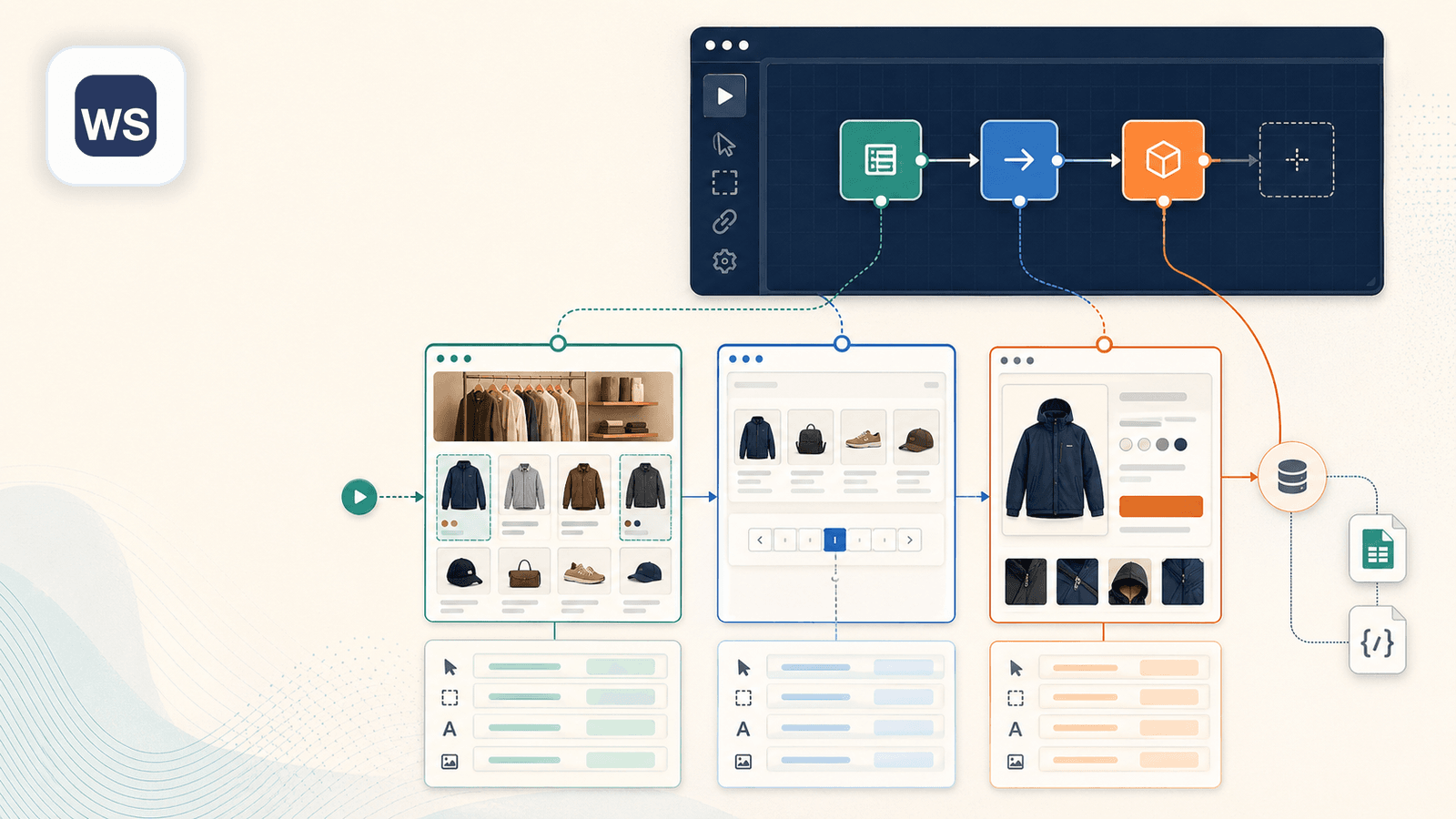
Ключевые сильные стороны для Shopify scraping
- Визуальный конструктор селекторов даёт больше контроля, чем инструменты автоопределения
- Может переходить по ссылкам на подстраницы (страницы товара), но требует ручной настройки родительско-дочерних селекторов в sitemap
- Обрабатывает пагинацию при правильной настройке
- Бесплатный браузерный сбор; доступны платные облачные планы (от $50/месяц)
- Экспорт в CSV; облачные планы поддерживают Google Sheets и другие форматы
Где он уступает
- Настройка занимает больше времени: создание sitemap с родительско-дочерними селекторами у меня заняло около 15 минут для нового магазина Shopify
- Для сбора подстраниц нужна — это не обогащение в один клик
- Sitemap ломаются, когда магазин Shopify меняет верстку или CSS-классы
- Порог входа выше, чем у AI-альтернатив
Цены
- Расширение для браузера: бесплатно
- Cloud-планы: Project $50/месяц, Professional $100/месяц, Scale от $200/месяц
Лучше всего подходит для: Технических пользователей, которым нужен тонкий контроль над процессом сбора и не мешает самостоятельно собирать рецепт.
4. Data Miner — scraper на основе рецептов
Data Miner (dataminer.io) построен вокруг «рецептов» — готовых или собственных шаблонов scraping, которые вы применяете к странице. Есть публичная библиотека рецептов, так что вы можете найти шаблон Shopify, которым поделился другой пользователь, или создать свой, выбрав элементы на странице.
Ключевые сильные стороны для Shopify scraping
- В библиотеке рецептов могут быть готовые шаблоны Shopify, которыми поделились другие пользователи
- Визуальный конструктор рецептов для пользовательских конфигураций scraping
- Обрабатывает пагинацию через настройку рецепта
- Экспорт в CSV, Excel, Google Sheets и TSV
- Workflows для обхода страниц товара после страниц списка
Где он уступает
- Бесплатный тариф ограничен 500 страницами в месяц
- Рецепты основаны на CSS-селекторах, поэтому ломаются при изменении верстки магазина
- Нет AI-подсказок по полям и преобразованию данных
- Нет встроенного one-click-процесса обогащения подстраниц — для страниц товара нужен отдельный crawl-рецепт
- Плановые обходы есть, но это не самый простой сценарий настройки расписания
Цены
- Бесплатно: 500 страниц/месяц
- Solo: $19.99/месяц
- Small Business: $49/месяц
- Business: $99/месяц
- Business Plus: $200/месяц
Лучше всего подходит для: Пользователей, которым нравится работать с шаблонами и нужна библиотека рецептов, чтобы ускорить настройку на распространённых сайтах.
5. Simplescraper — лёгкий extractor
Simplescraper (simplescraper.io) — это минималистичное расширение Chrome и облачный scraper, в котором сделан упор на простоту. Вы кликаете по элементам данных на странице Shopify, Simplescraper генерирует CSS-селекторы и извлекает совпадающие данные.
Ключевые сильные стороны для Shopify scraping
- Чистый, минималистичный интерфейс — быстро осваивается
- Доступен cloud scraping для плановых и массовых задач
- API-доступ для разработчиков, которые хотят встроить данные в рабочие процессы
- Экспорт в CSV, JSON, Google Sheets, Airtable и через webhooks
- Концепция deep scraping для перехода по ссылкам на страницы товара
- Поддержка логина для магазинов, чувствительных к сессии
Где он уступает
- Ручной подход на основе селекторов — нет AI для автоматического определения полей
- Для сбора подстраниц нужна дополнительная настройка
- Сообщество меньше, а готовых шаблонов меньше, чем у Web Scraper или Data Miner
- Бесплатный тариф: 100 кредитов (1 страница с JS-рендерингом = 2 кредита)
- Цены платных тарифов на официальном сайте описаны менее прозрачно, чем у большинства конкурентов
Цены
- Бесплатно: 100 кредитов
- Платные тарифы: сторонние источники указывают Plus примерно за ~$39/месяц, Pro — примерно за ~$70/месяц, Premium — примерно за ~$150/месяц (по данным G2)
Лучше всего подходит для: Пользователей, которым нужен лёгкий современный облачный scraper с хорошими интеграциями и не требуется AI-распознавание полей.
6. Octoparse — Chrome-расширение с упором на desktop
Octoparse (octoparse.com) — это в первую очередь desktop-приложение с сопутствующим расширением Chrome. Оно предлагает и визуальный конструктор рабочих процессов, и готовые шаблоны для популярных сайтов, включая обучающий сценарий scraping для Shopify.

Ключевые сильные стороны для Shopify scraping
- Готовые шаблоны Shopify для типовых задач scraping
- Мощное desktop-приложение с расширенными функциями: ротация IP, планируемый сбор, облачное извлечение
- Хорошо обрабатывает пагинацию, бесконечную прокрутку и контент, загружаемый через AJAX
- Самая сильная документированная антибот-обработка в этом списке, включая автоматическую работу с CAPTCHA
- Экспорт в CSV, Excel, JSON, HTML, XML, базы данных и Google Sheets
Где он уступает
- Одного Chrome-расширения мало — большая часть мощных функций требует desktop-приложения
- У desktop-приложения более высокий порог входа из-за визуального конструктора workflow
- Бесплатный тариф сильно ограничен; для реальной работы нужен платный план
- Более тяжёлая настройка по сравнению с чисто Chrome-инструментами — не лучший вариант для быстрого 5-минутного scrape
- Desktop-приложение доступно только для Windows/Mac (не полностью браузерное решение)
Цены
- Бесплатный план доступен
- Basic: $39/месяц
- Standard: примерно $83/месяц (помесячно), примерно $75/месяц (при годовой оплате)
- Professional: примерно $299/месяц (помесячно), примерно $208/месяц (при годовой оплате)
- Enterprise: индивидуально
Лучше всего подходит для: Команд, которым нужен scraping уровня enterprise с ротацией IP, антибот-защитой и повторяющимися облачными задачами — и которые не против desktop-приложения.
7. Bardeen — scraper, ориентированный прежде всего на автоматизацию
Bardeen (bardeen.ai) — это платформа для автоматизации браузера, которая объединяет web scraping и автоматизацию рабочих процессов. Пользователи создают «playbooks», которые могут собирать данные, а затем отправлять их в другие приложения — представьте это как «если я собрал эти данные, то отправь их в мою CRM».

Ключевые сильные стороны для Shopify scraping
- Автоматизация рабочих процессов поверх самого сбора: собрать данные Shopify → обогатить → отправить в CRM или таблицу в одном playbook
- Интеграции с 100+ приложениями (Google Sheets, Airtable, Notion, HubSpot, Slack и др.)
- AI-функции для извлечения и классификации данных
- Работает в браузере — desktop-приложение не нужно
- Автоматизации по времени и дате для планирования
Где он уступает
- Прежде всего это инструмент автоматизации, а не специализированный scraper — функции scraping менее глубокие, чем у профильных инструментов
- Создание playbook может запутать пользователей, которым просто нужно выгрузить список товаров
- Бесплатный тариф ограничен 100 кредитами
- Обогащение подстраниц и обработка пагинации менее интуитивны, чем у специализированных инструментов scraping
- Избыточен, если вам нужно только собрать данные без дальнейшей автоматизации
Цены
- Бесплатно: 100 кредитов
- Basic: $10/месяц, 100 кредитов/месяц
- Premium: $50/месяц, 1 000 кредитов/месяц (около $40/месяц при годовой оплате)
- Enterprise: индивидуально
- Модель кредитов: 1 кредит за строку скрейпера, 3 кредита за строку обогащения
Лучше всего подходит для: Команд, которым нужно собрать данные Shopify и сразу отправить их в downstream-приложения (CRM, таблицы, Slack) в одном автоматизированном процессе.
8. Listly — конвертер списков в таблицы
Listly (listly.io) специально создан для преобразования списков и таблиц на веб-страницах в данные, готовые для таблицы. Нажимаете расширение на странице коллекции Shopify, и Listly пытается распознать список товаров и экспортировать его как таблицу.

Ключевые сильные стороны для Shopify scraping
- Очень простой интерфейс — рассчитан на извлечение списков в один клик
- Хорошо распознаёт повторяющиеся структуры списков (например, сетки товаров)
- Прямой экспорт в Excel и Google Sheets
- Функция group scraping для обработки нескольких URL сразу
- Планирование доступно на тарифах Business
Где он уступает
- Ограничен тем, что автоопределяется на странице — без пользовательской настройки полей
- Нет обогащения подстраниц — экспортируются только данные уровня страницы списка
- Плохо справляется с нестандартными темами Shopify или магазинами с тяжёлым JavaScript-rendering
- Бесплатный тариф очень ограничен (10 URL в месяц)
- Меньше вариантов экспорта по сравнению с конкурентами (в основном Excel и Sheets)
Цены
- Бесплатно: 10 URL/месяц, базовое извлечение с 1 страницы, скачивание Excel, экспорт в Google Sheet
- Light: $30/месяц ($187.20/год при годовой оплате)
- Business: $90/месяц ($993.60/год при годовой оплате) — добавляет продвинутое извлечение, групповое извлечение, планирование, авто-прокрутку/клик, beta API
Лучше всего подходит для: Пользователей, которым нужен максимально простой путь от страницы коллекции Shopify к таблице — и не нужны глубокие данные о товарах.
Сравнение всех 8 расширений Chrome для Shopify Scraper
Вот полное сравнение по всем параметрам. Я старался быть конкретным в каждой ячейке, а не просто ставить галочки — потому что «поддерживает пагинацию» означает очень разное в зависимости от инструмента.
| Инструмент | Простота настройки | Поля данных | Обогащение подстраниц | Пагинация | Обработка антибот-защиты | Форматы экспорта | Планирование | Бесплатный тариф / цены |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Очень просто (AI, 2 клика) | Лучшая для нетехнических пользователей (AI предлагает все нужные поля) | Да — обогащение в один клик | Да (клик + бесконечная прокрутка) | Cloud для публичных, browser для защищённых | Sheets, Airtable, Notion, CSV, JSON, Excel | Да (планирование простым языком) | Бесплатно 6 страниц; платно от $15/мес |
| Instant Data Scraper | Крайне просто (без настройки) | Хорошо только для данных уровня листинга | Нет | Да (автоопределение следующей страницы) | Только браузер, без отдельной истории с антиботом | CSV, XLSX | Нет | Бесплатно |
| Web Scraper | Средне-сложно (ручной sitemap) | Гибко, если sitemap собран грамотно | Да, но вручную через селекторы ссылок | Да (при настройке sitemap) | Локально в браузере; ротация прокси на cloud-планах | Локально CSV; больше форматов в облаке | Да, на cloud-планах | Бесплатное расширение; cloud от $50/мес |
| Data Miner | Средне (на основе рецептов) | Хорошо, если рецепт уже есть или создан | Да, но через многошаговую настройку crawl | Да (через настройку рецепта) | В основном на стороне браузера | CSV, Excel, Sheets, TSV | Автоматические обходы есть | Бесплатно 500 страниц/мес; платно от $19.99/мес |
| Simplescraper | Просто-средне (на основе селекторов) | Надёжно для лёгкого извлечения | Deep scraping есть, но не в один клик | Да (поддерживается бесконечная прокрутка) | Ротация прокси и удобен для логина | CSV, JSON, Sheets, Airtable, webhooks | Да | Бесплатно 100 кредитов; есть платные тарифы |
| Octoparse | Сложнее (desktop-приложение) | Очень сильный, если настроен | Да, через workflows или шаблоны | Да (AJAX, бесконечная прокрутка) | Самая сильная антибот-защита (ротация IP, CAPTCHA) | CSV, Excel, JSON, HTML, XML, DB, Sheets | Да, на Standard+ | Бесплатно; Basic $39/мес; cloud от ~$83/мес |
| Bardeen | Средне (конструктор playbook) | Хорош, когда связан с автоматизацией | Возможно через логику workflow, но не ориентирован на Shopify | Возможно | Работает в браузере, антибот — не основная функция | CSV, Sheets, Airtable, Notion | Да, через автоматизации | Бесплатно 100 кредитов; Basic $10/мес; Premium $50/мес |
| Listly | Очень просто (распознавание списка в один клик) | Лучше всего для видимых строк списка | Нет | Ограничено распознанной структурой списка | Минимальная | Excel, Sheets, CSV/JSON API на Business | Да, на Business | Бесплатно 10 URL/мес; Light $30/мес; Business $90/мес |
Краткий вывод по приоритетам
Если вам нужны самые глубокие данные о товарах Shopify при минимальной настройке, связка AI + обогащение подстраниц у Thunderbit — сильнейший вариант. Если нужен полностью бесплатный, быстрый и простой экспорт, Instant Data Scraper подойдёт для простых страниц. Если вы хотите полный контроль и не против собирать рецепты вручную, Web Scraper или Octoparse дадут такую возможность. А если ваша реальная цель — собрать данные → автоматизировать → отправить в CRM, на Bardeen стоит посмотреть как на платформу для workflow.
Сбор страницы списка — это только половина работы: workflow обогащения подстраниц
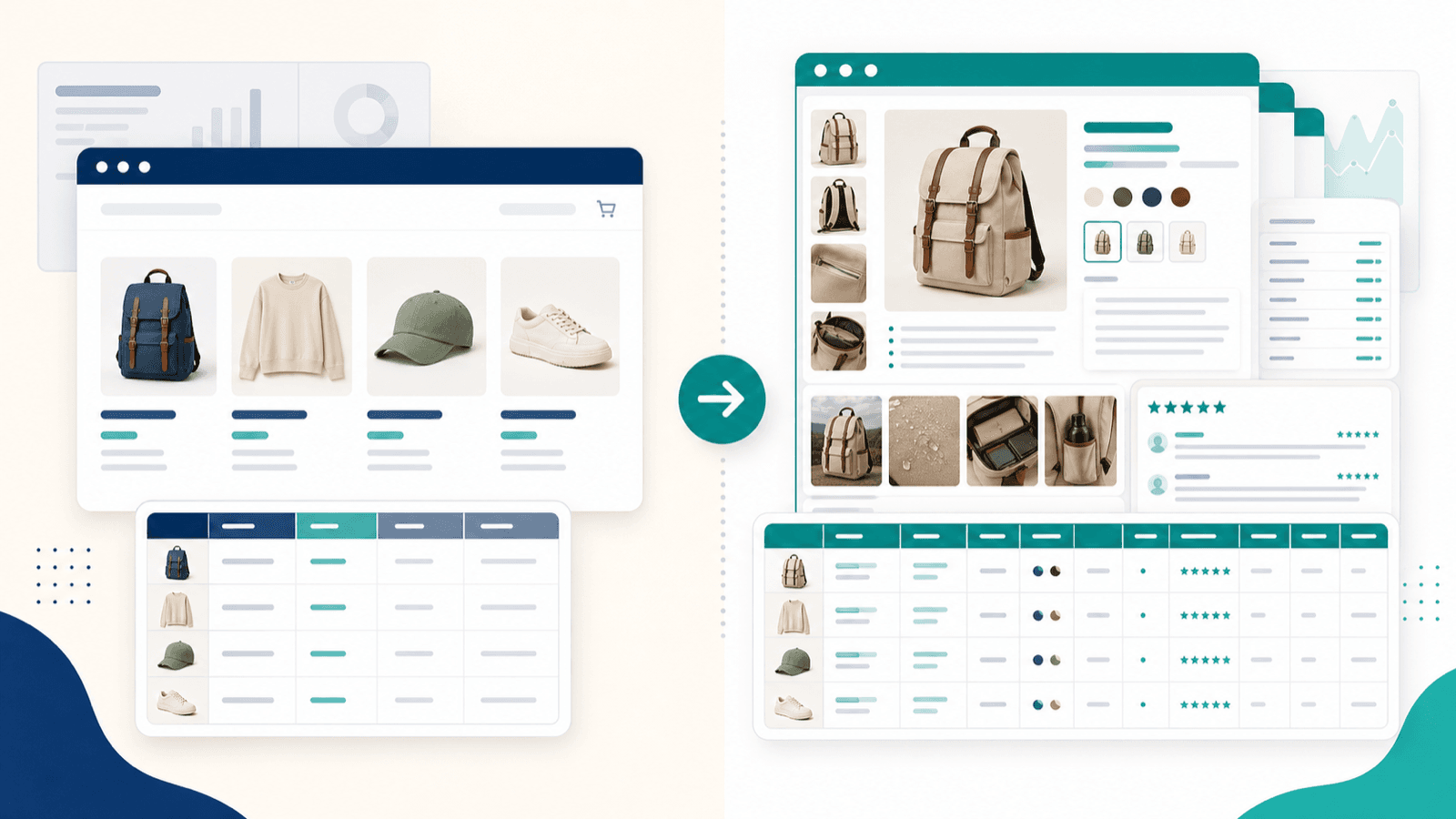
Это тот раздел, который я хотел бы видеть в каждой статье о Shopify scraper, потому что именно здесь самый большой пробел в контенте конкурентов и главная боль, которую я слышу от пользователей e-commerce.
Когда вы собираете страницу коллекции Shopify (страницу списка), вы получаете данные верхнего уровня: названия, цены, миниатюры, иногда укороченное описание. Но поля, которые вам действительно нужны для анализа конкурентов, импорта каталога или исследования товаров для дропшиппинга, находятся на отдельных страницах товара.
Что даёт только страница списка и что меняется после обогащения подстраниц
| Поле данных | Только со страницы списка | После обогащения подстраниц |
|---|---|---|
| Название товара | ✅ | ✅ |
| Цена | ✅ | ✅ |
| Миниатюра | ✅ | ✅ + все изображения галереи |
| Краткое описание | ⚠️ Урезано | ✅ Полное HTML-описание |
| Варианты (размер, цвет) | ❌ | ✅ |
| SKU / остатки | ❌ | ✅ |
| Отзывы / рейтинги | ❌ | ✅ |
Это огромная разница.
Экспорт только со страницы списка даёт вам поверхностную таблицу. Экспорт с обогащением подстраниц даёт пригодный для работы набор данных для конкурентного анализа.
Как работает сбор подстраниц в Thunderbit (шаг за шагом)
- Перейдите на страницу коллекции/списка магазина Shopify
- Нажмите «AI Suggest Fields» — Thunderbit читает страницу и предлагает столбцы (название, цена, изображение, ссылка и т. д.)
- Нажмите «Scrape», чтобы извлечь данные со страницы списка
- Нажмите «Scrape Subpages» — AI посещает каждый URL товара и добавляет данные со страницы товара (полное описание, все изображения, варианты, отзывы) в исходную таблицу
- Экспортируйте обогащённую таблицу в Excel, Google Sheets, Airtable, Notion или CSV
Весь процесс занимает несколько минут для типичной коллекции, а на выходе вы получаете набор данных, на сбор которого вручную ушли бы часы.
Какие ещё инструменты поддерживают обогащение подстраниц?
- Web Scraper: Да, но нужна ручная настройка sitemap с селекторами ссылок и дочерними sitemap — на один магазин закладывайте 15–20 минут настройки
- Octoparse: Да, через конструктор workflow или шаблоны — мощно, но настройка тяжелее
- Data Miner: Да, через многошаговые crawl-workflows — это не операция в один клик
- Simplescraper: Концепция deep scraping есть, но меньше готовых сценариев
- Instant Data Scraper, Listly, Bardeen: Нет документированного обогащения подстраниц Shopify в один клик
Разница между «может технически переходить по ссылкам при 20 минутах ручной настройки» и «обогащение в один клик» — это разница между инструментом для scraper-инженеров и инструментом для e-commerce-операторов.
Когда products.json Shopify не работает — и почему Chrome-расширения остаются вашим планом Б
Если вы читали другие руководства по scraping Shopify, вы наверняка видели трюк с /products.json: достаточно добавить /products.json к URL магазина Shopify, и вы получите структурированные данные о товарах в формате JSON. Это реальный endpoint, и когда он работает, это очень удобно.
Как работает products.json
Магазины Shopify предоставляют по адресу /products.json, который возвращает структурированные данные о товарах. Пагинацию можно делать через ?page=2&limit=250 (максимум 250 товаров на страницу).
Обычно возвращаются поля: title, body_html, vendor, product_type, tags, published_at, variants (с price, compare_at_price, sku, available) и images.
Чего не хватает в products.json
- Нет данных об отзывах и количестве рейтингов
- Форматирование описания ограничено по сравнению с отрисованными страницами
- Пользовательские metafields часто не включены
- Изображения на уровне вариантов могут быть непоследовательными
- Нет отрисованного merchandising-контента, бейджей или social proof
Когда products.json ломается
27 апреля 2026 года я провёл прямые HTTP-проверки на восьми реальных витринах Shopify. Результаты показательные:
| Магазин | Результат |
|---|---|
| kith.com | ✅ Работает — чистый JSON |
| colourpop.com | ✅ Работает |
| allbirds.com | ✅ Работает |
| brooklinen.com | ✅ Работает |
| negativeunderwear.com | ✅ Работает |
| gymshark.com | ❌ Заблокировано — 403 HTML вместо JSON |
| mvmt.com | ⚠️ Частично отключено — HTML-страница 200, не JSON |
| fashionnova.com | ❌ Отключено — 404 |
Пять из восьми вернули чистый JSON. Три — нет.
Пользователи форумов сообщают о том же: «По какой-то причине некоторые магазины Shopify решают не открывать products.json». Магазины с паролем, магазины с собственной API-архитектурой и домены под Cloudflare могут ломать этот сценарий.
Запасной вариант — Chrome-расширение
Когда products.json недоступен, scraper в виде расширения Chrome извлекает данные напрямую с отрисованной страницы (DOM). В этом и состоит основная ценность браузерных scraper: они видят и извлекают то, что видите вы в браузере, независимо от доступности API. Поэтому Chrome-расширения — надёжный план Б, а часто и план А, когда вам нужны данные с отрисованной страницы, например отзывы, merchandising-контент или полные галереи изображений.
Антибот-защита: что реально происходит, когда вы скрейпите магазины Shopify
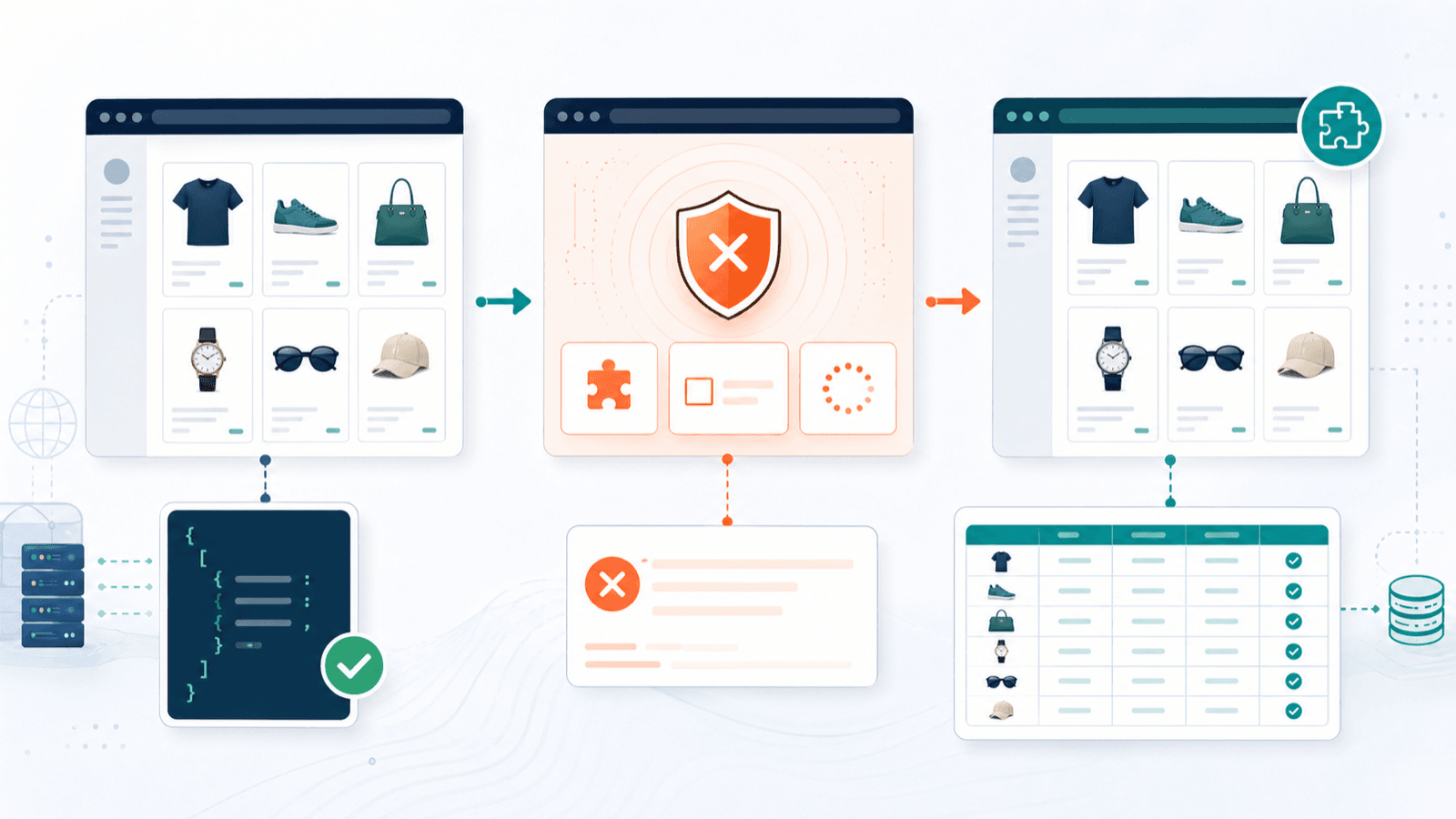
Большинство статей о Shopify scraper делает вид, что каждый магазин открыт настежь. Это не так. По данным , 99,2% магазинов Shopify используют инфраструктуру Cloudflare. Это не значит, что каждый магазин агрессивно блокирует scraper, но это значит, что инфраструктура для блокировки есть почти везде.
На практике диапазон такой:
Легко скрейпить
- Публичные магазины без агрессивной защиты Cloudflare
- Магазины, где products.json включён
- Магазины со стандартными темами Shopify (одинаковая структура DOM)
Сложнее скрейпить
- Магазины под Cloudflare (CAPTCHA, Turnstile)
- Магазины с обязательным входом или доступом по паролю
- Магазины Shopify Plus с пользовательскими слоями безопасности
- Магазины с агрессивным rate limiting
Как каждый инструмент справляется с антибот-сценариями
| Сценарий | Лучший подход | Инструменты, которые справляются |
|---|---|---|
| Публичный магазин без антибота | Cloud scraping (быстро) | Thunderbit (cloud mode), Instant Data Scraper, большинство остальных |
| Магазин под Cloudflare | Browser-based scraping (использует вашу сессию) | Thunderbit (browser mode), Web Scraper, Octoparse |
| Магазин с обязательным входом / приватный | Browser scraping с вашей авторизованной сессией | Thunderbit (browser mode), Web Scraper, Simplescraper |
| products.json отключён | Извлечение из отрисованной страницы через DOM | Все Chrome-расширения (в этом их сила) |
Два режима Thunderbit — cloud и browser scraping — здесь действительно важны. Cloud mode быстро подходит для массового сбора с публичных магазинов. Browser mode использует вашу реальную сессию Chrome, когда антибот-защита требует этого. Эта гибкость выручила меня на gymshark.com, где cloud-запросы блокировались, а browser mode работал нормально.
Планируемый Shopify scraping: отслеживайте цены и остатки во времени
Разовый сбор данных полезен. Но e-commerce-командам обычно нужна постоянная конкурентная аналитика — не просто один снимок. Изменения цен, колебания запасов, запуск новых товаров: всё это происходит непрерывно. Один пользователь на форуме выразился просто: «Полезнее видеть текущий уровень запасов и снимки того, как он снижается».
Однако почти ни одна статья-конкурент не упоминает планируемый или повторяющийся сбор. Это очевидный пробел.
Как работает планируемый мониторинг Shopify
- Настраиваете повторяющийся сбор страниц коллекций или товаров конкурента
- Данные при каждом запуске экспортируются в Google Sheets (или Airtable), формируя временной ряд цен и запасов
- Используете данные для отслеживания: снижения/повышения цен, out of stock, добавления новых товаров, сезонных паттернов
Настройка планируемого сбора в Thunderbit
Thunderbit делает это до смешного просто.
Вы описываете расписание обычным языком (например, «каждый понедельник в 9:00»), вводите URL магазинов Shopify и нажимаете «Schedule». Thunderbit запускает сбор автоматически и экспортирует его в выбранное вами место. Никаких cron jobs, никакого кода, никаких сторонних планировщиков.
Поддержка планирования во всех 8 инструментах
| Инструмент | Планирование? |
|---|---|
| Thunderbit | Да — планирование простым языком |
| Instant Data Scraper | Нет |
| Web Scraper | Да — на cloud-планах |
| Data Miner | Автоматические обходы есть, но это не самый простой сценарий |
| Simplescraper | Да |
| Octoparse | Да — на Standard и выше |
| Bardeen | Да — через автоматизации по времени и дате |
| Listly | Да — на тарифе Business |
Если постоянный мониторинг конкурентов входит в ваш процесс, это ключевое отличие. Большинство бесплатных Chrome-расширений этого вообще не предлагают.
Какое расширение Chrome для Shopify Scraper подходит именно вам?

Вместо общего вывода в стиле «выберите то, что вам нравится» вот матрица решений, привязанная к конкретным сценариям:
| Сценарий | Лучшая рекомендация | Почему |
|---|---|---|
| Исследование цен конкурентов | Thunderbit | Листинг + обогащение подстраниц + планирование = полный workflow по ценам |
| Быстрый разовый экспорт | Instant Data Scraper | Самый быстрый бесплатный путь, если нужны только видимые данные списка |
| Импорт каталога в свой Shopify-магазин | Thunderbit | Полные данные подстраниц + экспорт в CSV/Excel, удобный для Shopify |
| Постоянный мониторинг цен/запасов | Thunderbit или Octoparse | Самое простое no-code планирование против сильнейшего enterprise-уровня |
| Лидогенерация (контакты владельцев магазинов) | Thunderbit | Встроенные извлекатели email/телефона + структурированный экспорт |
| Сложные многошаговые автоматизации | Bardeen | Собрать, обогатить и отправить данные в downstream-приложения в одном workflow |
| Технические пользователи, которым нужен полный контроль | Web Scraper или Octoparse | Лучший ручной контроль над селекторами, логикой и процессом извлечения |
Итоги
Shopify scraping в 2026 году — это не вопрос, можно ли получить данные о товарах. Вопрос в том, насколько глубоко, насколько быстро и насколько воспроизводимо работает ваш процесс. Большинство материалов в этой теме останавливаются на странице списка. Реальная ценность — в обогащении подстраниц, планируемом мониторинге и работе с антибот-сюрпризами, которые реальные магазины Shopify подбрасывают вам на каждом шагу.
Если хотите увидеть, как это выглядит на практике — от страницы коллекции до полностью обогащённого набора данных за несколько кликов — попробуйте . А если Thunderbit не идеален для вашего случая, Instant Data Scraper — хороший бесплатный старт для простых задач, а Web Scraper и Octoparse — сильные варианты для технических пользователей, которым нужен больший контроль.
Удачного scraping — и пусть ваши данные о товарах всегда будут полными, структурированными и богатыми вариантами.
Часто задаваемые вопросы
1. Законно ли скрейпить данные из магазинов Shopify?
Общедоступные данные о товарах в магазинах Shopify, как правило, доступны любому посетителю сайта. Но законность зависит от вашей юрисдикции, условий использования магазина и того, что именно вы делаете с данными. Сбор публичных цен для анализа конкурентов — обычная практика; полное копирование контента для повторной публикации несёт больше рисков. Это не юридическая консультация — в вашей конкретной ситуации лучше обратиться к специалисту.
2. Можно ли скрейпить магазины Shopify, где нужен логин или пароль?
Да, но вам нужен браузерный scraper, который использует вашу авторизованную сессию Chrome. Cloud-scraper обычно не могут получить доступ к страницам за логином. Browser mode в Thunderbit, локальный Web Scraper и login-воркфлоу в Simplescraper поддерживают такой сценарий.
3. Сколько товаров можно собрать из магазина Shopify за один раз?
Это зависит от инструмента и тарифа. Endpoint products.json в Shopify поддерживает пагинацию по . Cloud mode в Thunderbit обрабатывает до 50 страниц за раз. Бесплатные тарифы у большинства инструментов ограничивают страницы, строки или кредиты — поэтому перед крупной задачей проверьте лимиты вашего плана.
4. В чём разница между cloud scraping и browser scraping для Shopify?
Cloud scraping выполняется на удалённых серверах — он быстрее и лучше подходит для публичных магазинов без антибот-защиты. Browser scraping использует вашу локальную сессию Chrome, а значит может работать с магазинами под Cloudflare, с обязательным входом или с региональными ограничениями. Thunderbit предлагает оба режима, и выбор обычно сводится к тому, блокирует ли магазин удалённые запросы.
5. Можно ли экспортировать собранные данные Shopify напрямую в Google Sheets или Airtable?
Да, но не все инструменты это поддерживают. Thunderbit экспортирует в Google Sheets, Airtable, Notion, Excel, CSV и JSON — и всё это бесплатно. Data Miner и Listly поддерживают Google Sheets. Simplescraper поддерживает Sheets и Airtable. Octoparse поддерживает Google Sheets на премиальных тарифах. Bardeen интегрируется с Sheets, Airtable и Notion. Instant Data Scraper экспортирует только в CSV и XLSX без прямой интеграции с Sheets.
Узнать больше