A web está crescendo num ritmo que, sinceramente, é até difícil de imaginar. Todo santo dia, bilhões de novas páginas, produtos, avaliações e conjuntos de dados entram no ar — alimentando desde pesquisas de mercado até o treinamento de IA e a sua próxima compra na Amazon. Como alguém que passou anos em SaaS e automação, vi de perto como os dados certos podem decidir o sucesso ou o fracasso de uma decisão de negócio. Mas aqui está o problema: coletar, atualizar e transformar esse mar de dados da web em algo realmente útil está ficando mais difícil, não mais fácil. Os scrapers tradicionais não estão dando conta do recado, e as empresas precisam de uma forma mais inteligente e rápida de transformar a internet em insights acionáveis. É aí que entra o cloud crawler — uma ferramenta que vem mudando, de forma quase silenciosa, a maneira como as organizações descobrem e usam dados da web em grande escala.
Então, afinal, o que é um cloud crawler? Em que ele se diferencia dos web scrapers que você talvez já conheça? E por que times de vendas até operações estão apostando nessa tecnologia para sair na frente num mundo orientado por dados? Vamos entrar no assunto, descomplicar os termos e ver como os cloud crawlers — especialmente a solução da Thunderbit — estão virando o jogo para empresas modernas.
O que é um cloud crawler? O próximo passo na descoberta de dados
Vamos simplificar: um cloud crawler não é só um web scraper rodando na nuvem. Ele funciona mais como um mecanismo de descoberta de dados — um sistema inteligente baseado em nuvem, feito para encontrar, extrair e analisar automaticamente grandes volumes de dados espalhados pela internet. Enquanto um web scraper tradicional busca informações em algumas poucas páginas (muitas vezes uma por vez, normalmente a partir de um único dispositivo), um cloud crawler atua num outro patamar. Ele roda em data centers potentes na nuvem, rastreando milhares — ou até milhões — de páginas ao mesmo tempo, e consegue processar tudo, de texto a imagens e PDFs, não importa o quão complexo ou extenso seja o site-alvo.
Pense assim: se um web scraper é como um único bibliotecário copiando trechos de um livro, um cloud crawler é uma equipe de supercomputadores escaneando todos os livros da biblioteca ao mesmo tempo, marcando, organizando e analisando o conteúdo enquanto avança. O resultado? As empresas recebem dados mais ricos, mais atualizados e mais úteis — sem os gargalos do hardware local ou do trabalho manual (, ).
Cloud crawler vs. web scraper tradicional: qual é a diferença real?
Se você já usou um web scraper, conhece a lógica básica: aponta para uma página, define o que quer e deixa a ferramenta coletar os dados. Mas, conforme a web cresce e fica mais complexa, essa abordagem antiga começa a mostrar seus limites. Veja como cloud crawlers e web scrapers tradicionais se comparam:
| Recurso/Aspecto | Web Scraper Tradicional | Cloud Crawler |
|---|---|---|
| Implantação | Roda no seu dispositivo ou servidor local | Roda na nuvem (data centers remotos) |
| Escala | Limitado pela capacidade do seu computador | Execução massivamente paralela — milhares de páginas ao mesmo tempo |
| Velocidade | Mais lento, especialmente em tarefas grandes | Processamento em lote de alta velocidade |
| Manutenção | Exige atualizações frequentes e quebra com mudanças no site | Baseado na nuvem, com atualização automática e menos frágil |
| Tipos de dados | Normalmente texto, às vezes imagens | Texto, imagens, PDFs, layouts complexos |
| Acesso | Preso ao seu dispositivo/rede | Acessível de qualquer lugar, em qualquer dispositivo |
| Agendamento | Manual ou automação básica | Agendamento avançado, tarefas recorrentes |
| Ideal para | Projetos pequenos, sites simples | Necessidades de dados em grande escala, frequentes ou complexas |
Os cloud crawlers foram feitos para a web moderna — onde os dados estão por toda parte, e velocidade e escala não são negociáveis (, ).
Como os cloud crawlers turbinaram a eficiência da coleta de dados
É aqui que a coisa fica realmente interessante. Cloud crawlers usam o poder da computação em nuvem para processar milhares de páginas da web em paralelo. Isso significa que você pode extrair um catálogo inteiro de ecommerce, monitorar preços da concorrência em dezenas de sites ou consolidar listagens imobiliárias de todos os grandes portais — tudo em uma fração do tempo que um scraper tradicional levaria.
Por que isso importa? Porque em áreas como ecommerce, finanças e mercado imobiliário, a atualização dos dados é tudo. Preços, estoque e tendências de mercado podem mudar a cada minuto. Esperar horas — ou dias — para um scraper local terminar simplesmente não é uma opção. Cloud crawlers não ficam presos à RAM do seu notebook nem ao Wi‑Fi do escritório — eles escalam conforme a necessidade, para você encarar tarefas enormes sem sofrimento (, ).
Os setores que mais se beneficiam dessa eficiência incluem:
- Ecommerce: monitoramento de preços, consolidação de catálogos de produtos, análise de avaliações
- Imobiliário: consolidação de anúncios, acompanhamento de tendências do mercado, comparação de imóveis
- Finanças: análise de notícias e sentimento, monitoramento de ações/cripto, acompanhamento regulatório
- Vendas e Marketing: geração de leads, pesquisa de concorrência, identificação de tendências
E, sinceramente, isso é só a ponta do iceberg. Se você precisa de dados da web em escala, um cloud crawler é seu novo melhor amigo.
A solução de cloud crawler da Thunderbit: rápida, flexível e poderosa
Deixe-me vestir meu chapéu de Thunderbit por um segundo (tá, eu nunca tiro ele de verdade). O modo de scraping na nuvem da é a nossa resposta ao desafio moderno dos dados — um cloud crawler criado para usuários de negócio que querem resultado, não dor de cabeça.
O que faz o cloud crawler da Thunderbit se destacar:
- Scraping em lote de alta velocidade: extraia até 50 páginas por vez, com servidores na nuvem nos EUA, UE e Ásia para alcance global. Nada de ficar vendo seu computador sofrer para processar uma lista enorme.
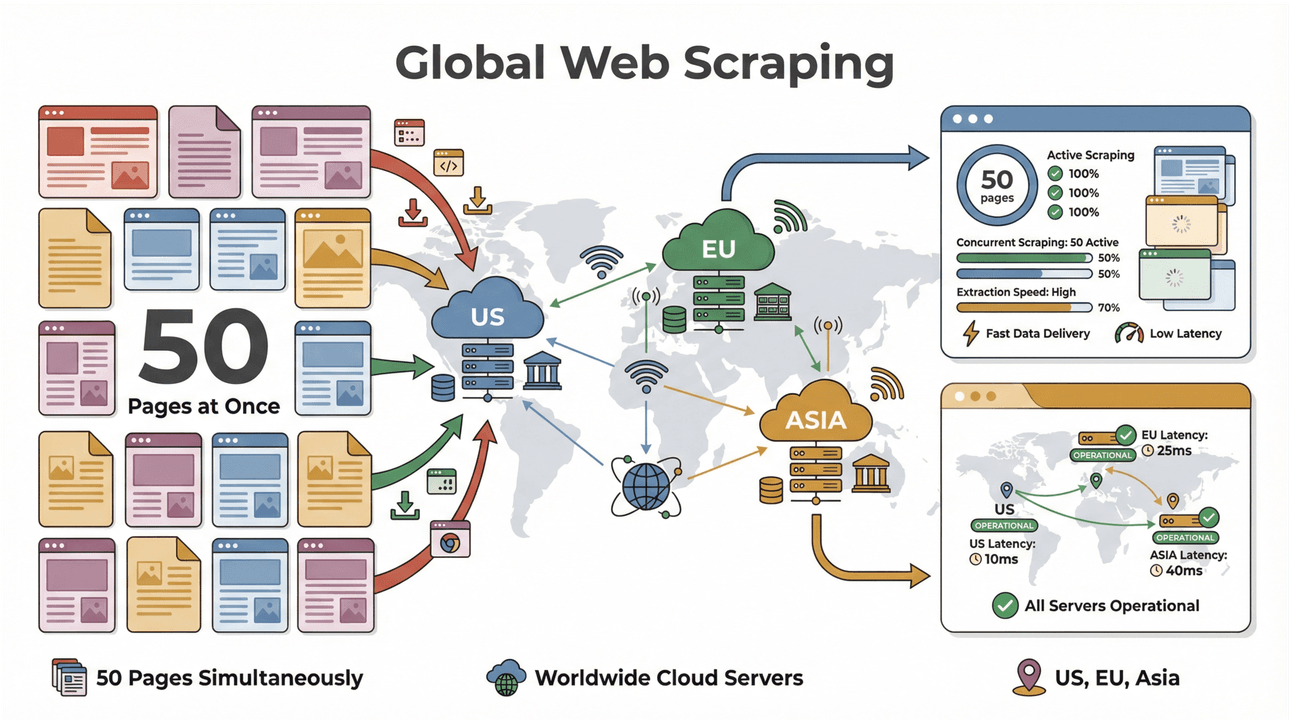
- Suporte a páginas complexas: a IA da Thunderbit dá conta de tudo, de sites dinâmicos de ecommerce a PDFs complicados e até extração de imagens. Se está na web, a Thunderbit provavelmente consegue extrair ().
- Rastreamento de subpáginas: precisa enriquecer seus dados com detalhes de subpáginas, como especificações de produtos ou biografias de autores? A IA da Thunderbit pode visitar cada subpágina e juntar os resultados ao seu conjunto principal de dados ().
- Estruturação inteligente de dados: use “AI Suggest Fields” para deixar a Thunderbit ler o site e recomendar as melhores colunas — sem código e sem criar template.
- Exportação para qualquer lugar: envie seus dados direto para Excel, Google Sheets, Airtable ou Notion. Ou baixe em CSV/JSON — do jeito que fizer mais sentido no seu fluxo de trabalho ().
- Sem manutenção: a IA da Thunderbit se adapta a mudanças no site, então você não fica o tempo todo corrigindo scrapers quebrados ().
E sim, você pode testar tudo isso com uma — então não precisa acreditar só na minha palavra.
Implantação de cloud crawler: nuvem vs. local — qual faz mais sentido para você?
Uma das maiores vantagens dos cloud crawlers é a flexibilidade de implantação. Com um crawler tradicional (local), você fica preso a um dispositivo específico, a uma rede específica e, muitas vezes, a uma série de dores de cabeça de configuração. Se o seu computador entra em suspensão ou a internet cai, a coleta para. Escalar significa comprar mais hardware ou rodar vários scripts.
Os cloud crawlers viram esse jogo:
- Sem necessidade de hardware especial: todo o processamento pesado acontece na nuvem. Você pode iniciar grandes extrações a partir de um Chromebook, de um Mac ou até do celular.
- Acesso de qualquer lugar: viajando? Trabalhando remotamente? Sem problema — seu cloud crawler está sempre disponível.
- Escala fácil: precisa extrair 10.000 páginas em vez de 100? Basta aumentar o tamanho da tarefa — sem depender do time de TI.
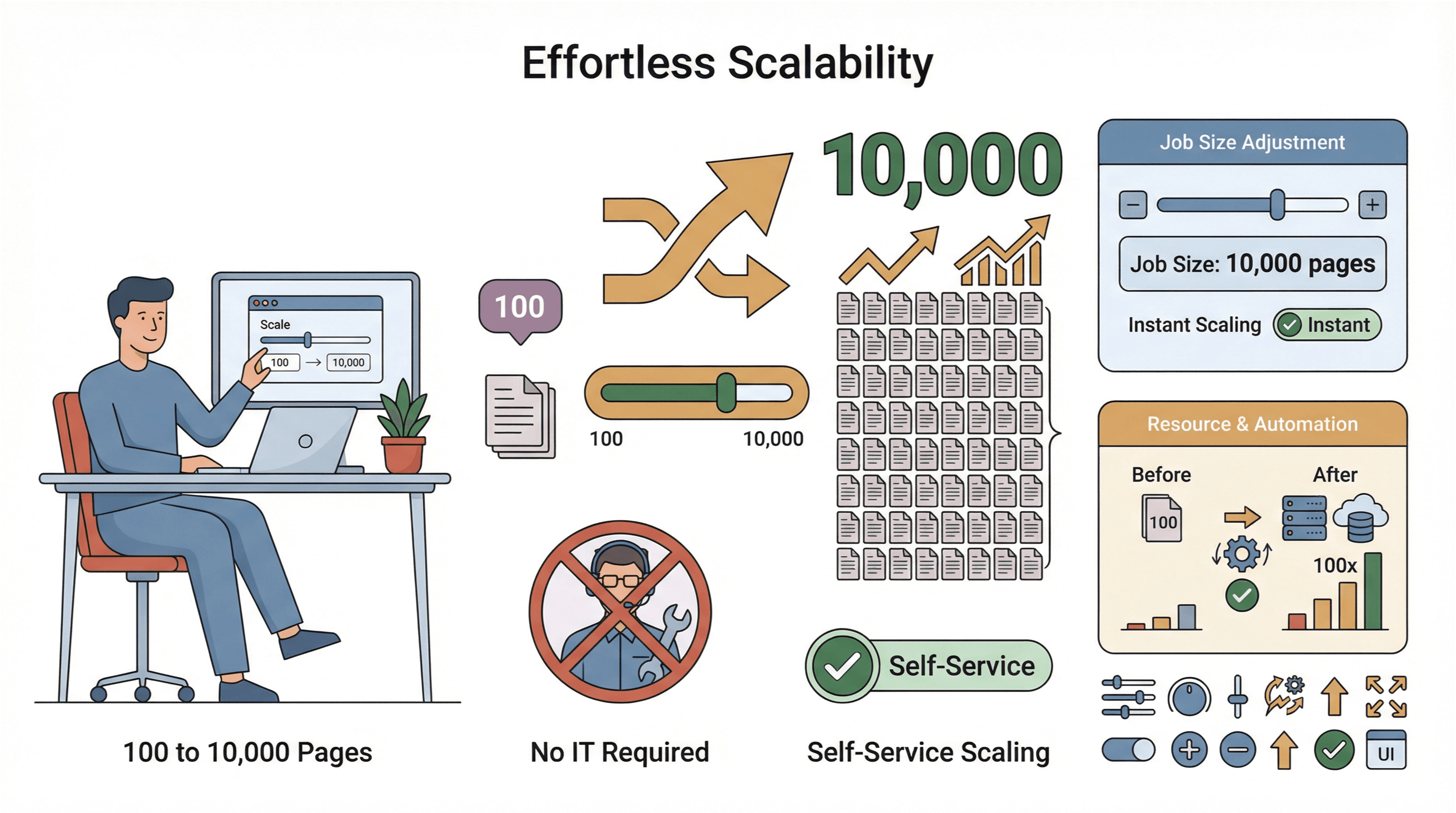
- Coleta global de dados: com servidores em várias regiões, você pode acessar conteúdo com restrição geográfica e gerenciar conformidade com mais facilidade ().
Claro, segurança e conformidade sempre são prioridades. Os melhores cloud crawlers (incluindo a Thunderbit) usam conexões criptografadas, respeitam os termos dos sites e oferecem recursos para ajudar você a lidar com dados sensíveis de forma responsável.
Impacto no mundo real: como cloud crawlers estão transformando estratégias orientadas por dados
Vamos ao que interessa. Por que as empresas estão migrando para cloud crawlers? Porque estão vendo impacto real e mensurável:
- Análise de mercado em tempo real: varejistas usam cloud crawlers para monitorar preços e estoque da concorrência em tempo real, permitindo precificação dinâmica e respostas mais rápidas às mudanças do mercado ().
- Previsão de tendências do consumidor: marcas consolidam avaliações, publicações em redes sociais e discussões em fóruns para identificar tendências emergentes e ajustar campanhas rapidamente.
- Vendas e geração de leads: equipes comerciais montam listas de leads atualizadas a partir de diretórios, sites de eventos e até PDFs — alimentando CRMs com contatos novos e qualificados ().
- Operações e compliance: empresas financeiras usam cloud crawlers para monitorar atualizações regulatórias, notícias e documentos em várias jurisdições — reduzindo riscos e se antecipando às mudanças.
O ponto em comum? Cloud crawlers permitem que as equipes andem mais rápido, tomem decisões melhores e deixem para trás concorrentes que ainda estão no ritmo lento.
Principais recursos para procurar em um cloud crawler
Nem todo cloud crawler é igual. Se você estiver avaliando opções, estes são os recursos que mais importam (e onde a Thunderbit se destaca):
- Escalabilidade: ele consegue lidar com milhares de páginas ao mesmo tempo? Fica mais lento conforme as tarefas crescem?
- Facilidade de uso: a interface é amigável para quem não é técnico? Dá para configurar uma extração em poucos cliques?
- Suporte a múltiplos tipos de dados: texto, imagens, PDFs, subpáginas — ele lida com tudo?
- Integração: exporta para as ferramentas que você já usa (Excel, Sheets, Notion, Airtable)?
- Agendamento: dá para configurar tarefas recorrentes e manter os dados sempre atualizados?
- Assistência de IA: oferece sugestões inteligentes de campos, enriquecimento de dados e adaptação automática às mudanças do site?
- Segurança e conformidade: seus dados e credenciais ficam protegidos? A ferramenta ajuda você a cumprir as leis de privacidade?
A Thunderbit marca todos esses pontos, o que a torna uma excelente escolha para equipes que querem potência sem complicação.
Começando: como usar um cloud crawler no seu negócio
Pronto para começar? Veja como um usuário de negócio pode dar os primeiros passos com um cloud crawler como a Thunderbit:
- Instale a : configuração rápida, sem necessidade de TI.
- Escolha seu alvo: abra o site, a lista ou o documento que você quer extrair.
- Clique em “AI Suggest Fields”: deixe a IA da Thunderbit analisar a página e recomendar as melhores colunas para extração.
- Personalize conforme necessário: adicione, remova ou renomeie campos para atender às suas necessidades.
- Selecione o modo de scraping na nuvem: para tarefas grandes ou sites complexos, mude para o modo cloud e tenha máxima velocidade.
- Inicie a extração: a Thunderbit processará até 50 páginas por vez na nuvem.
- Revise e exporte: confira os resultados e depois exporte para Excel, Google Sheets, Notion ou Airtable.
- Agende tarefas recorrentes: para demandas contínuas, configure extrações agendadas — seus dados serão atualizados automaticamente ().
Dica: comece com uma tarefa pequena para pegar o jeito e, depois, aumente conforme ganhar confiança. E não hesite em usar o suporte ou a documentação da Thunderbit — eles estão lá para ajudar.
O futuro da coleta de dados: o que vem por aí para os cloud crawlers?
A revolução dos cloud crawlers está só começando. Aqui vai o que eu espero ver nos próximos anos:
- Extração de IA mais inteligente: os cloud crawlers estão ficando melhores em entender contexto, relações e até sentimento — o que torna os dados coletados muito mais valiosos ().
- Suporte a novos tipos de dados: espere melhor tratamento de vídeo, áudio e conteúdo interativo — não só texto e imagens estáticas.
- Automação mais profunda: de agendamento automático a alertas em tempo real, os cloud crawlers vão exigir cada vez menos intervenção do usuário.
- Conformidade aprimorada: à medida que as leis de privacidade evoluem, os cloud crawlers vão incorporar mais ferramentas para ajudar as equipes a seguir as regras.
- Integração com BI e ferramentas de IA: pipelines diretos dos cloud crawlers para plataformas de analytics, dashboards e machine learning.
Em resumo, os cloud crawlers estão prestes a virar a base da estratégia digital das empresas — alimentando tudo, de lançamentos de produtos a previsões com IA ().
Conclusão: por que cloud crawlers são essenciais para empresas modernas
Resumindo: a web está transbordando de dados, e os métodos antigos de coleta já não conseguem acompanhar. Cloud crawlers são a próxima evolução — oferecendo velocidade, escala e inteligência que os scrapers tradicionais simplesmente não conseguem igualar. Ferramentas como a tornam possível que qualquer equipe, técnica ou não, aproveite todo o potencial dos dados da web — impulsionando decisões mais inteligentes, respostas mais rápidas e uma vantagem competitiva de verdade.
Se você está pronto para deixar o scraping manual e os dados lentos para trás, agora é a hora de explorar o que um cloud crawler pode fazer pelo seu negócio. Experimente o modo de scraping na nuvem da Thunderbit e veja como a descoberta de dados moderna pode ser fácil — e poderosa. E, se quiser se aprofundar, confira o para mais guias, dicas e exemplos do mundo real.
Perguntas frequentes
1. O que é um cloud crawler em termos simples?
Um cloud crawler é uma ferramenta baseada na nuvem que descobre, extrai e analisa automaticamente grandes volumes de dados da web. Diferente dos scrapers tradicionais, que rodam no seu dispositivo local, os cloud crawlers operam em data centers potentes, permitindo escala e velocidade muito maiores.
2. Qual é a diferença entre um cloud crawler e um web scraper comum?
Cloud crawlers rodam na nuvem, lidam com milhares de páginas ao mesmo tempo, suportam tipos de dados complexos (como imagens e PDFs) e não exigem manutenção nem hardware local. Scrapers tradicionais são limitados pela capacidade do seu dispositivo e funcionam melhor em tarefas menores e mais simples.
3. Quais são os principais benefícios de usar um cloud crawler?
Cloud crawlers oferecem coleta de dados em alta velocidade e grande escala, suporte a sites complexos, acesso fácil de qualquer lugar e recursos avançados como agendamento e extração com IA. Eles são ideais para empresas que precisam de dados novos e acionáveis com rapidez.
4. Como o cloud crawler da Thunderbit funciona para usuários de negócios?
O cloud crawler da Thunderbit permite configurar uma extração em poucos cliques — sem precisar programar. Você pode extrair dados de sites, PDFs e imagens, enriquecê-los com IA e exportar diretamente para Excel, Google Sheets, Notion ou Airtable. Ele foi feito para usuários não técnicos que querem resultado, não complexidade.
5. Cloud crawling é seguro e compatível com leis de privacidade?
Sim, os principais cloud crawlers, como a Thunderbit, usam conexões criptografadas e boas práticas de segurança de dados. Sempre certifique-se de extrair apenas dados publicamente disponíveis e respeite os termos de uso dos sites e as regras de privacidade.
Pronto para ver o que um cloud crawler pode fazer? e comece hoje mesmo a explorar o universo da coleta de dados em grande escala, com a nuvem.
Saiba mais