Imagine só: você coloca seu site no ar, esperando aquela avalanche de visitantes, mas logo percebe que metade do seu tráfego vem de... robôs. Não são aqueles androides de filme, mas sim rastreadores digitais — mecanismos de busca, bots de IA, spiders de análise — todos fuçando suas páginas, 24 horas por dia, como uma multidão invisível que nunca para. Em 2026, isso já virou o novo normal. Entender quem (ou o quê) está rastreando seu site, com que frequência e por qual motivo, virou questão de sobrevivência para qualquer negócio online.
Com minha bagagem em SaaS, automação e IA, vi o web crawling sair do porão técnico para virar pauta estratégica de negócio. Os números assustam: bots já são quase metade do tráfego da internet e, em alguns lugares, já superam os humanos. Com a explosão dos rastreadores de IA, que coletam conteúdo para treinar grandes modelos de linguagem, o impacto nunca foi tão pesado — seja na infraestrutura, no bolso ou na reputação da sua marca. Bora mergulhar nas estatísticas mais quentes, benchmarks do mercado e o que tudo isso significa para o seu negócio em 2026.
Web Crawling em 2026: O Retrato Atual
O web crawling chegou num nível de escala e complexidade que nunca vimos. Todos os dias, bilhões de requisições automatizadas cruzam a internet, feitas por uma variedade cada vez maior de rastreadores. Antes, os bots de busca como Googlebot e Bingbot eram os astros, indexando páginas para facilitar as buscas. Agora, eles dividem espaço com uma nova geração: rastreadores de IA, scrapers de redes sociais, bots de análise e muito mais.
O dado que mais chama atenção: , e em algumas regiões, o tráfego de bots passa o de humanos. Na rede da Cloudflare, . E o mais curioso? Esse crescimento não vem só dos buscadores — é cada vez mais puxado por rastreadores de IA famintos por dados para alimentar chatbots e ferramentas generativas.
O cenário nunca foi tão variado:
- Bots “do bem”: Indexadores de busca, monitores de uptime, raspadores de dados autorizados.
- Bots “do mal”: Spam, tentativas de invasão, scraping não autorizado.
- Rastreadores de IA: Os novatos, coletando conteúdo para treinar IA e responder perguntas em tempo real.
Rastreadores de IA têm um comportamento diferente dos bots tradicionais. Eles podem baixar páginas inteiras para análise semântica, não só indexar palavras-chave, e operam em volumes absurdos — às vezes, milhões de requisições em poucos dias. O resultado? , misturando indexação clássica com a fome insaciável de dados da IA.
Estatísticas de Web Crawling que Todo Negócio Precisa Saber
Vamos aos números que estão mudando a web em 2026. Não são só curiosidades — são referências para sua infraestrutura, estratégia de conteúdo e até para o caixa.
Bots vs. Humanos: Quem Manda no Tráfego?
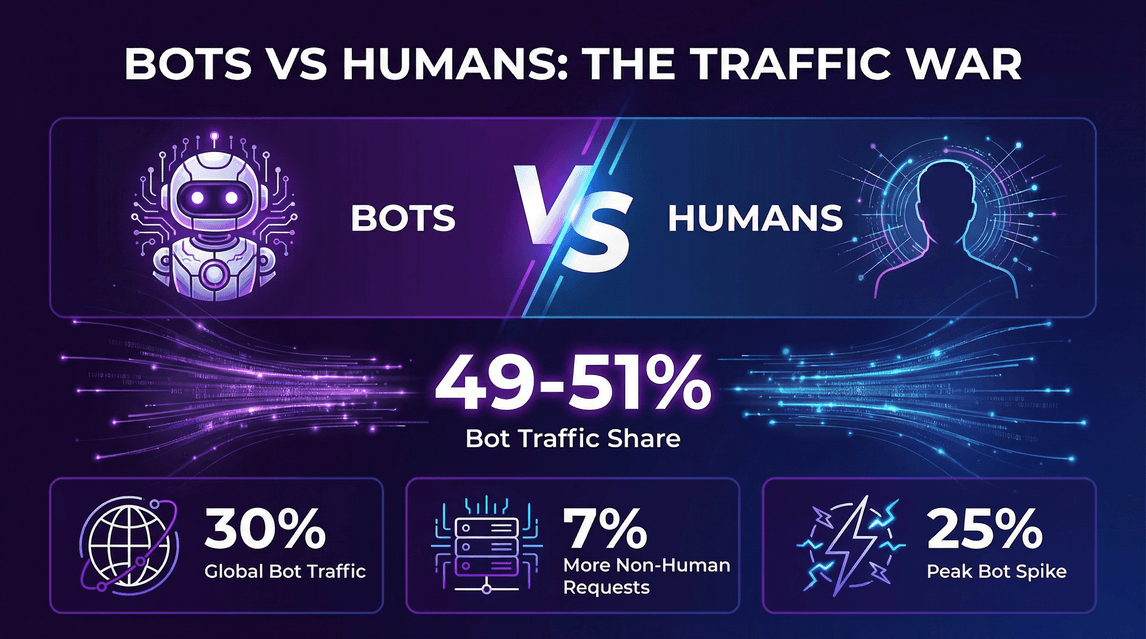
- Entre 49% e 51% de todo o tráfego da internet já é gerado por bots, com requisições automatizadas empatando ou superando as visitas humanas ().
- Dados da Cloudflare: .
- Requisições não humanas para páginas HTML foram cerca de 7% maiores que as humanas ().
- Em certos picos, o tráfego de bots .
O Boom dos Rastreadores de IA

- Bots de IA representaram 4,2% de todas as requisições de páginas HTML em 2025 ().
- GPTBot da OpenAI: Saiu do zero para , crescendo 305% em um ano.
- Bot da Perplexity.ai: .
- Googlebot: , respondendo por cerca de 50% de todas as requisições de rastreadores de busca/IA.
Tráfego de Rastreadores na Prática
Olha só um exemplo real dos logs de um servidor de :
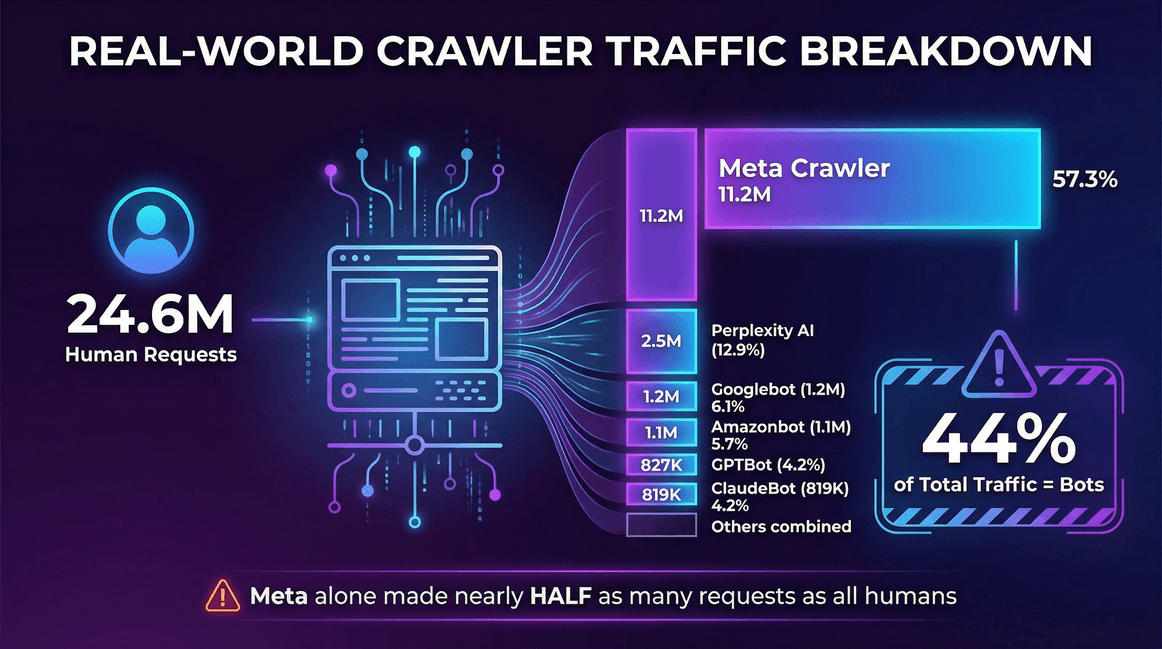
| Fonte de Tráfego | Requisições (Mensal) | Participação dos Rastreadores |
|---|---|---|
| Usuários reais (humanos) | 24.647.904 | -- |
| Meta Crawler (Facebook) | 11.175.701 | 57,3% |
| Perplexity AI | 2.512.747 | 12,9% |
| Googlebot | 1.180.737 | 6,1% |
| Amazonbot | 1.120.382 | 5,7% |
| OpenAI GPTBot | 827.204 | 4,2% |
| ClaudeBot (Anthropic) | 819.256 | 4,2% |
| Bingbot | 599.752 | 3,1% |
| ChatGPT-User (OpenAI) | 557.511 | 2,9% |
| Ahrefs Crawler | 449.161 | 2,3% |
| ByteDance Spider | 267.393 | 1,4% |
Nesse site, bots foram 44% do tráfego total — e só o rastreador da Meta fez quase metade das requisições dos usuários reais.
O Panorama Geral
- O tráfego de rastreadores (busca + IA) cresceu 18% entre maio de 2024 e maio de 2025 em um grupo estável de sites ().
- Bots de treinamento de LLM chegaram a ser quase 80% de todo o tráfego de “bots” em grandes CDNs ().
- A rede da Cloudflare registrou cerca de 50 bilhões de requisições diárias de rastreadores de IA no fim de 2025 ().
A Ascensão dos Rastreadores de IA: Como a Inteligência Artificial Está Mudando o Web Crawling
Vamos falar do “robô” na sala: os rastreadores de IA. Eles não estão só indexando seu site para buscas — estão devorando conteúdo para treinar grandes modelos de linguagem ou entregar respostas instantâneas com IA. E fazem isso numa escala que deixa qualquer buscador tradicional no chinelo.
O Que Está Por Trás do Crescimento dos Rastreadores de IA?
- Modelos de IA famintos por dados: Os LLMs modernos precisam de volumes gigantescos e variados de dados. A web é o banquete, e seu conteúdo está no cardápio.
- Treinamento vs. Respostas em tempo real: , não só para responder perguntas ao vivo.
- Novos padrões de rastreamento: Bots de IA podem acessar sites em grandes rajadas, às vezes rastreando milhões de páginas em poucos dias, especialmente durante re-treinamentos ou atualizações de modelos.
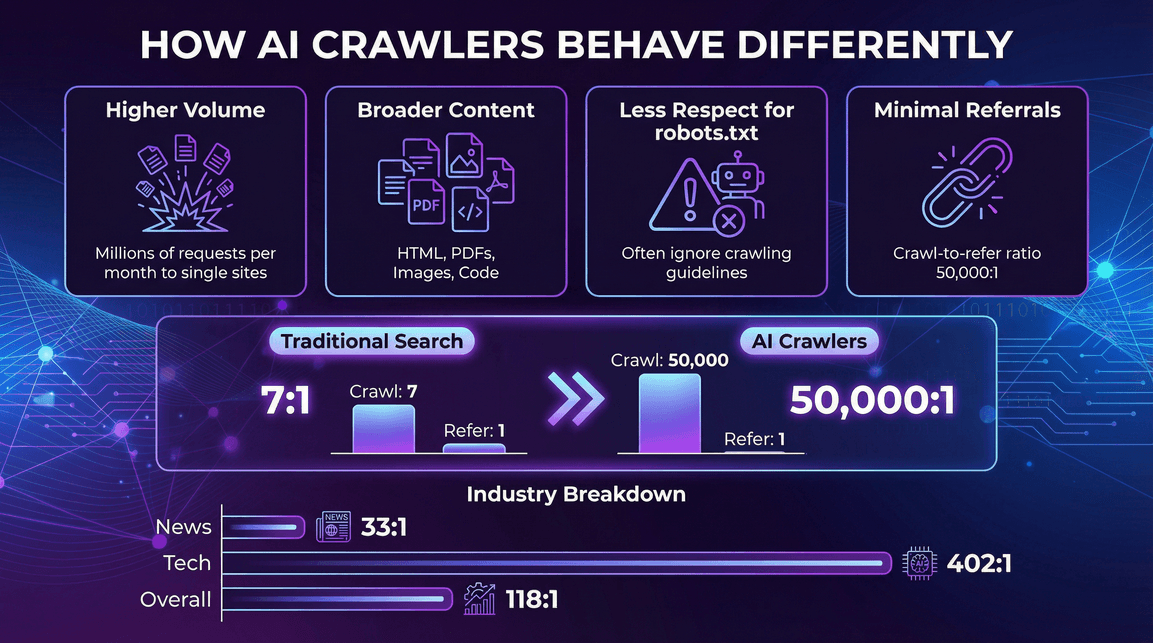
Como os Rastreadores de IA se Comportam Diferente
- Volume muito maior por bot: Um único bot de IA pode gerar milhões de requisições mensais para um site ().
- Tipos de conteúdo mais variados: Não só HTML — PDFs, imagens, códigos, o que estiver disponível.
- Menos respeito ao robots.txt: Muitos rastreadores de IA ignoram ou só seguem parcialmente as regras de crawling ().
- Quase nenhum tráfego de referência: Diferente dos buscadores, rastreadores de IA raramente trazem visitantes de volta ao seu site. .
Tráfego de Rastreadores de IA por Setor
Nem todo setor é rastreado igual. Por exemplo:
- Notícias e Publicações: Forte atividade de rastreadores de IA, mas com taxas de referência um pouco melhores (ex: Perplexity tem relação crawl-to-refer de 33:1 em sites de notícias, contra 118:1 no geral) ().
- Tecnologia e Eletrônicos: GPTBot e Amazonbot dominam, com relações de referência ainda altas (ex: OpenAI tem relação de 402:1 em tecnologia) ().
- Finanças, Academia e outros: Cada setor tem sua mistura de bots e taxas de referência, mas a tendência é clara: rastreadores de IA estão em todo lugar, e a maioria não gera tráfego de volta.
Principais Rastreadores da Web em 2026: Quem Mais Vasculha a Internet?
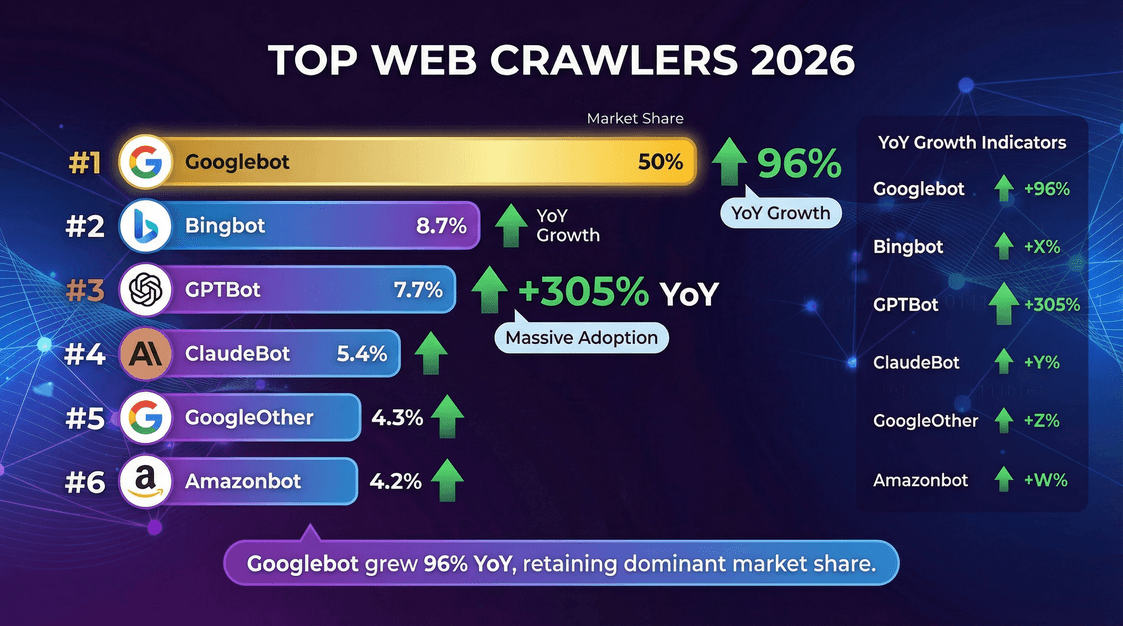
Quem são os grandes nomes desse universo de rastreamento? Veja o ranking, segundo :
| Rastreador (Proprietário) | % dos Rastreamentos (Mai/2025) | Crescimento YoY de Requisições |
|---|---|---|
| Googlebot (Google) | 50,0% | +96% |
| Bingbot (Microsoft) | 8,7% | +2% |
| GPTBot (OpenAI) | 7,7% | +305% |
| ClaudeBot (Anthropic) | 5,4% | –46% |
| GoogleOther (Google) | 4,3% | +14% |
| Amazonbot (Amazon) | 4,2% | –35% |
| Googlebot-Image (Google) | 3,3% | –13% |
| Bytespider (ByteDance) | 2,9% | –85% |
| YandexBot (Yandex) | 2,2% | –10% |
| ChatGPT-User (OpenAI) | 1,3% | +2825% |
| Applebot (Apple) | 1,2% | –26% |
| PerplexityBot | 0,2% | +157.490% |
Destaques:
- Googlebot segue absoluto, responsável por metade de toda a atividade de rastreamento.
- GPTBot e o rastreador da Meta são os que mais crescem, com o GPTBot triplicando sua fatia em um ano.
- PerplexityBot e ChatGPT-User ainda têm participação pequena, mas estão crescendo feito foguete.
Benchmarks de Web Crawling: Taxas, Desempenho e Eficiência
 Web crawling não é só volume — é também velocidade e eficiência. Veja o que importa sobre taxas de rastreamento e benchmarks de desempenho em 2026.
Web crawling não é só volume — é também velocidade e eficiência. Veja o que importa sobre taxas de rastreamento e benchmarks de desempenho em 2026.
Taxa de Rastreamento: Com Que Rapidez os Bots Vasculham Páginas?
- Taxa de rastreamento normalmente é medida em páginas por segundo (ou requisições por segundo) ().
- Threads/conexões paralelas: Mais threads = mais velocidade. Por exemplo, 200 threads com 2 segundos de atraso por site podem render cerca de 100 páginas por segundo ().
- Benchmarks reais: 100–200 páginas por segundo é comum para um rastreador bem ajustado em um cluster decente.
- Google e Bing: Provavelmente buscam milhares de páginas por segundo no mundo todo, espalhados por milhões de sites.
O Que Afeta a Taxa de Rastreamento
- Número de threads/fetchers paralelos: Mais threads, mais velocidade (até bater em outros limites).
- Número de sites ativos: Rastrear vários domínios ao mesmo tempo multiplica o throughput.
- Delay/tempo de espera: Delays maiores = rastreamento mais lento.
- Limites de recursos: Banda, CPU, velocidade do banco de dados podem ser gargalos.
- Desempenho do site alvo: Sites lentos ou com limitação de taxa derrubam a velocidade do rastreamento.
Por exemplo, se seu rastreador tem 100 threads e 1 segundo de delay por site, pode buscar cerca de 100 páginas por segundo — a não ser que o banco de dados não aguente, aí o gargalo é o armazenamento, não a rede.
O Impacto do Web Crawling nos Negócios: Custos, Oportunidades e Riscos
Web crawling não é só papo técnico — é assunto de negócio, com custos e oportunidades reais.
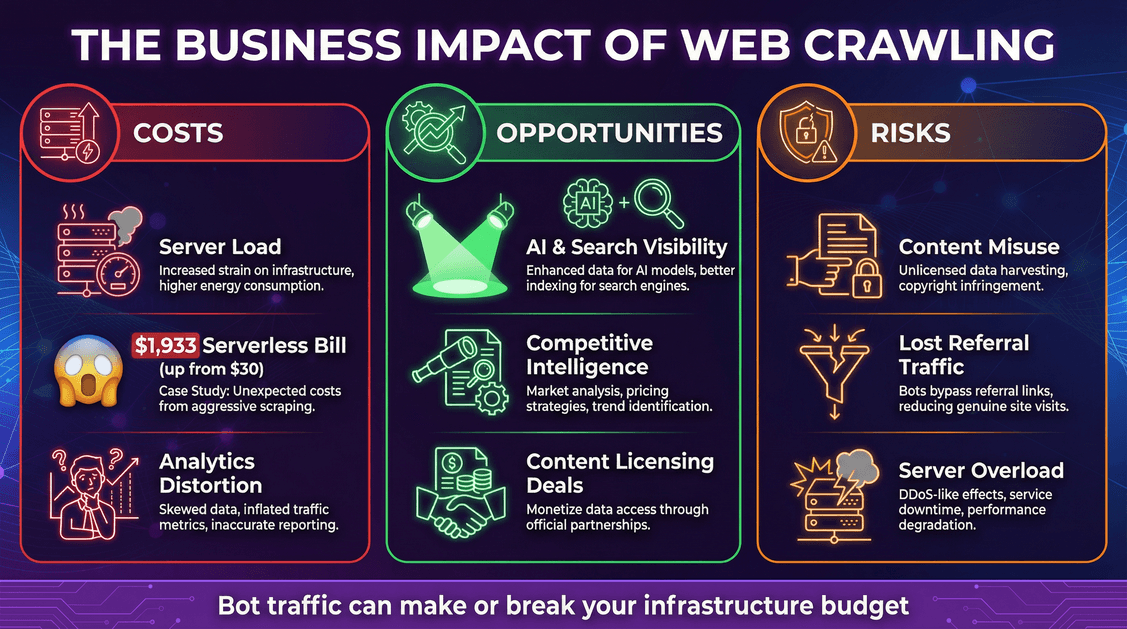
Custos: Infraestrutura e Surpresas na Fatura
- Carga nos servidores: Cada requisição de bot consome CPU, memória e banda.
- Contas na nuvem: Se você usa modelo de cobrança por uso (tipo serverless), bots podem inflar sua conta. Um dev viu .
- Distorção de análises: Bots podem bagunçar seus dados de analytics, dificultando entender o comportamento real dos usuários.
Oportunidades: Visibilidade e Inteligência de Dados
- Visibilidade em IA e buscas: Estar presente em dados de treinamento de IA ou em índices de busca pode ampliar o alcance da sua marca ().
- Inteligência competitiva: Empresas usam rastreadores para pesquisa de mercado, monitoramento de preços e mais.
- Monetização: Alguns publishers já .
Riscos: Uso Indevido de Conteúdo e Perda de Tráfego
- Uso indevido de conteúdo: Rastreadores de IA podem absorver seu conteúdo em seus modelos, às vezes sem permissão ou compensação.
- Perda de tráfego de referência: Respostas de IA podem satisfazer o usuário sem levá-lo ao seu site, causando “desintermediação”.
- Segurança e indisponibilidade: Rastreadores agressivos podem sobrecarregar seus servidores, causando lentidão ou até quedas.
Como Gerenciar o Tráfego de Rastreadores: Boas Práticas
Como evitar que os bots detonem seu orçamento (ou sua infraestrutura)?
1. Capriche no robots.txt
- Use o
robots.txtpara permitir ou bloquear bots específicos. A maioria dos rastreadores confiáveis (como o Googlebot) respeita, mas muitos bots de IA podem ignorar (). - Em meados de 2025, cerca de 14% dos principais sites já tinham regras explícitas para bots de IA ().
2. Use Ferramentas de Gerenciamento de Bots
- Firewalls de Aplicação Web (WAFs) e serviços de gerenciamento de bots podem bloquear ou limitar tráfego suspeito.
- Cloudflare e outros provedores oferecem recursos de mitigação de bots e até ferramentas de “Auditoria de IA” para criadores de conteúdo ().
3. Implemente Limites de Taxa e Cache
- Limite requisições em alta frequência de um mesmo bot.
- Sempre que possível, sirva conteúdo em cache para bots — evite que eles acionem funções serverless ou consultas caras ao banco de dados ().
4. Monitore e Analise o Tráfego de Bots
- Fique de olho nos logs do servidor. Saiba quais bots estão acessando, com que frequência e quando.
- Configure alertas para picos de tráfego fora do comum.
5. Fique de Olho nas Novidades do Setor
- Preste atenção em novas meta tags ou cabeçalhos HTTP para permissões de uso por IA (ex:
<meta name="ai:allow" content="no">). - Acompanhe iniciativas como ) e protocolos de pagamento como .
Tendências de Web Crawling para Ficar de Olho em 2026 e Além
O universo do web crawling está mudando rápido. Veja o que estou acompanhando (e você também deveria):
- Crawling movido por IA só vai crescer: Prepare-se para ainda mais bots de IA, rastreando todo tipo de conteúdo (texto, imagens, vídeos).
- Licenciamento de conteúdo e padrões de pagamento: O “Velho Oeste” está dando lugar a e .
- Regulação chegando: Espere mais clareza legal sobre o que bots podem ou não fazer, principalmente para dados de treinamento de IA ().
- Novos padrões técnicos para uso de conteúdo: Novas meta tags, extensões do robots.txt e declarações de bots legíveis por máquina estão vindo aí.
- Colaboração entre publishers e IA: Em vez de só serem alvos, mais publishers vão negociar feeds estruturados ou APIs para empresas de IA.
Conclusão: O Que Essas Estatísticas de Web Crawling Significam para Seu Negócio
Resumindo: o web crawling é uma força dominante em 2026 — e só vai crescer. Bots automatizados, especialmente rastreadores de IA, já são responsáveis por uma fatia enorme do seu tráfego, e o impacto na infraestrutura, orçamento e estratégia de conteúdo só aumenta.
O que fazer?
- Prepare-se para muito tráfego de bots: Planeje infraestrutura, orçamento e monitoramento pensando nisso.
- Conheça seus rastreadores: Nem todo bot é igual — adapte sua estratégia para cada um.
- Monitore seus indicadores: Acompanhe o tráfego de bots como faz com visitantes humanos.
- Proteja seu conteúdo e seu bolso: Use controles técnicos, acordos legais e novos padrões.
- Aproveite o lado bom: Estar em índices de IA e busca pode impulsionar sua marca — só garanta que você está recebendo valor em troca.
- Mantenha-se atualizado e adapte-se: O cenário está mudando rápido. Fique de olho em novos padrões, regulações e modelos de negócio.
Com anos desenvolvendo ferramentas de automação e IA (e agora no ), posso garantir: as empresas que prosperam nessa nova era são as que tratam o web crawling como prioridade estratégica — não só como um incômodo técnico. Seja em vendas, ecommerce, marketing ou imóveis, entender as estatísticas e benchmarks do setor virou pré-requisito.
Então, da próxima vez que olhar seus logs e ver uma multidão de bots, não só ignore. Use os dados. Compare seu site. Ajuste suas táticas. E lembre-se: na era da IA, os bots não estão chegando — eles já estão aqui. Faça-os trabalhar a seu favor, não o contrário.
Fique ligado, mantenha a curiosidade e que seus logs estejam sempre a seu favor.
Quer saber mais sobre web scraping, automação e produtividade com IA? Dá uma olhada no para conteúdos aprofundados, tutoriais e as últimas tendências. E se quiser assumir o controle dos seus dados, experimente a para raspagem de dados com IA — sem código, sem dor de cabeça, só resultado.
Fontes e Leituras Complementares: