

Links quebrados. Páginas órfãs. Uma página de “teste” de 2019 que, vai saber como, o Google indexou. Se você administra um site, conhece bem essa dor.
Um bom crawler encontra tudo isso — e ainda mapeia seu site inteiro para que você consiga corrigir os problemas de verdade. Mas muita gente confunde “web crawler” com “web scraper”. Não é a mesma coisa.
Testei 10 crawlers gratuitos em sites reais. Alguns são ótimos para auditorias de SEO. Outros funcionam melhor para extração de dados. Aqui está o que deu certo — e o que não deu.
O que é um Website Crawler? Entendendo o básico
Vamos começar pelo começo: um website crawler não é a mesma coisa que um web scraper. Eu sei, esses termos vivem sendo usados como se fossem sinônimos, mas são bem diferentes. Pense no crawler como o cartógrafo do seu site — ele explora cada canto, segue cada link e monta um mapa de todas as páginas. A missão dele é descobrir: encontrar URLs, mapear a estrutura do site e indexar o conteúdo. É isso que mecanismos de busca como o Google fazem com seus bots, e também o que ferramentas de SEO usam para auditar a saúde do seu site (Thunderbit Blog: What Is a Web Crawler?).
Já um web scraper é o minerador de dados. Ele não quer o mapa inteiro — só quer extrair o ouro: preços de produtos, nomes de empresas, avaliações, e-mails, o que for. Scrapers capturam campos específicos das páginas que os crawlers encontram (Thunderbit Blog: How to Web Crawl a Site?).
Comparação rápida:
- Crawler: a pessoa que percorre todos os corredores de um supermercado e faz um inventário de todos os produtos.
- Scraper: a pessoa que vai direto à prateleira de café e anota o preço de cada blend orgânico.
Por que isso importa? Porque, se você só quer encontrar todas as páginas do seu site (para uma auditoria de SEO, por exemplo), precisa de um crawler. Se quer extrair todos os preços de produtos do site do concorrente, precisa de um scraper — ou, de preferência, de uma ferramenta que faça os dois.
Por que usar um Web Crawler online? Principais benefícios para o negócio
Então, por que se dar ao trabalho de usar um web crawler? Bem, a web não para de crescer. Na verdade, mais de 54% das marcas enterprise usam plataformas dedicadas de crawling para otimizar seus sites, e algumas ferramentas de SEO rastreiam 7 bilhões de páginas por dia.
Veja o que os crawlers podem fazer por você:
- Auditorias de SEO: encontre links quebrados, títulos ausentes, conteúdo duplicado, páginas órfãs e muito mais (SEO.ai).
- Verificação de links e QA: identifique erros 404 e loops de redirecionamento antes dos seus usuários (Screaming Frog).
- Geração de sitemap: crie automaticamente sitemaps XML para mecanismos de busca e planejamento (PowerMapper).
- Inventário de conteúdo: monte uma lista de todas as páginas, sua hierarquia e metadados.
- Conformidade e acessibilidade: verifique cada página em relação a WCAG, SEO e exigências legais (SiteOne Crawler).
- Performance e segurança: sinalize páginas lentas, imagens pesadas ou problemas de segurança (SiteOne Crawler).
- Dados para IA e análise: leve os dados rastreados para ferramentas de analytics ou IA (Thunderbit Blog: Crawl4AI Review).
Aqui vai uma tabela rápida relacionando casos de uso e perfis profissionais:
| Caso de uso | Ideal para | Benefício / resultado |
|---|---|---|
| SEO e auditoria do site | Marketing, SEO, donos de pequenas empresas | Encontrar problemas técnicos, otimizar a estrutura, melhorar rankings |
| Inventário de conteúdo e QA | Gestores de conteúdo, webmasters | Auditar ou migrar conteúdo, detectar links/imagens quebrados |
| Geração de leads (scraping) | Vendas, desenvolvimento de negócios | Automatizar prospecção, alimentar o CRM com leads atualizados |
| Inteligência competitiva | E-commerce, product managers | Monitorar preços, novos produtos e mudanças de estoque da concorrência |
| Clonagem de sitemap e estrutura | Desenvolvedores, DevOps, consultores | Reproduzir a estrutura do site para redesigns ou backups |
| Agregação de conteúdo | Pesquisadores, mídia, analistas | Coletar dados de vários sites para análise ou monitoramento de tendências |
| Pesquisa de mercado | Analistas, times de treinamento de IA | Reunir grandes volumes de dados para análise ou treino de modelos de IA |
(Thunderbit Blog: How to Web Crawl a Site?)
Como escolhemos as melhores ferramentas gratuitas de Website Crawler
Passei muitas madrugadas (e bebi café demais para contar) analisando ferramentas de crawling, lendo documentação e rodando testes. Foi isso que considerei:
- Capacidade técnica: lida com sites modernos (JavaScript, logins, conteúdo dinâmico)?
- Facilidade de uso: é amigável para quem não é técnico ou exige dominar linha de comando?
- Limites do plano grátis: é realmente gratuito ou só uma isca?
- Acesso online: é uma ferramenta em nuvem, app desktop ou biblioteca de código?
- Recursos exclusivos: faz algo especial — como extração com IA, sitemaps visuais ou crawling orientado por eventos?
Testei cada ferramenta, analisei feedback de usuários e comparei os recursos lado a lado. Se uma ferramenta me dava vontade de jogar o laptop pela janela, ela não entrou na lista.
Tabela comparativa rápida: 10 melhores Website Crawlers gratuitos em um olhar
| Ferramenta e tipo | Recursos principais | Melhor caso de uso | Necessidade técnica | Detalhes do plano grátis |
|---|---|---|---|---|
| BrightData (Cloud/API) | Crawling enterprise, proxies, renderização JS, resolução de CAPTCHA | Coleta de dados em grande escala | Alguma habilidade técnica ajuda | Teste grátis: 3 scrapers, 100 registros cada (cerca de 300 registros no total) |
| Crawlbase (Cloud/API) | Crawling via API, anti-bot, proxies, renderização JS | Devs que precisam de infraestrutura de crawling no backend | Integração via API | Grátis: ~5.000 chamadas de API por 7 dias, depois 1.000/mês |
| ScraperAPI (Cloud/API) | Rotação de proxies, renderização JS, crawl assíncrono, endpoints prontos | Devs, monitoramento de preços, dados de SEO | Configuração mínima | Grátis: 5.000 chamadas de API por 7 dias, depois 1.000/mês |
| Diffbot Crawlbot (Cloud) | Crawling + extração com IA, grafo de conhecimento, renderização JS | Dados estruturados em escala, IA/ML | Integração via API | Grátis: 10.000 créditos/mês (cerca de 10 mil páginas) |
| Screaming Frog (Desktop) | Auditoria de SEO, análise de links/metadados, sitemap, extração personalizada | Auditorias de SEO, gestão de sites | App desktop, interface gráfica | Grátis: 500 URLs por rastreamento, apenas recursos essenciais |
| SiteOne Crawler (Desktop) | SEO, performance, acessibilidade, segurança, exportação offline, Markdown | Devs, QA, migração, documentação | Desktop/CLI, GUI | Grátis e open-source, relatório na GUI com 1.000 URLs (configurável) |
| Crawljax (Java, OpenSrc) | Crawling orientado por eventos para sites pesados em JS, exportação estática | Devs, QA para apps web dinâmicos | Java, CLI/configuração | Grátis e open-source, sem limites |
| Apache Nutch (Java, OpenSrc) | Distribuído, baseado em plugins, integração com Hadoop, busca personalizada | Motores de busca próprios, crawling em larga escala | Java, linha de comando | Grátis e open-source, custo só da infraestrutura |
| YaCy (Java, OpenSrc) | Crawling e busca peer-to-peer, privacidade, indexação web/intranet | Busca privada, descentralização | Java, interface no navegador | Grátis e open-source, sem limites |
| PowerMapper (Desktop/SaaS) | Sitemaps visuais, acessibilidade, QA, compatibilidade com navegadores | Agências, QA, mapeamento visual | GUI, fácil de usar | Teste grátis: 30 dias, 100 páginas (desktop) ou 10 páginas (online) por varredura |
BrightData: Website Crawler em nuvem para nível enterprise

BrightData é o “peso-pesado” do crawling. É uma plataforma em nuvem com uma enorme rede de proxies, renderização JavaScript, resolução de CAPTCHA e um IDE para crawls personalizados. Se você faz coleta de dados em grande escala — como monitorar centenas de sites de e-commerce para preços — a infraestrutura da BrightData é difícil de superar (aimultiple.com).
Pontos fortes:
- Lida com sites difíceis e com barreiras anti-bot
- Escala bem para necessidades enterprise
- Templates prontos para sites comuns
Limitações:
- Não tem plano grátis permanente (apenas teste: 3 scrapers, 100 registros cada)
- Pode ser exagero para auditorias simples
- Há uma curva de aprendizado para usuários não técnicos
Se você precisa rastrear a web em grande escala, a BrightData é como alugar um carro de Fórmula 1. Só não espere que seja grátis depois do test drive (BrightData Pricing).
Crawlbase: Web Crawler gratuito orientado por API para desenvolvedores

A Crawlbase (antes ProxyCrawl) é focada em crawling programático. Você chama a API com uma URL e recebe o HTML — enquanto proxies, geotargeting e CAPTCHAs são tratados em segundo plano (Capterra).
Pontos fortes:
- Alta taxa de sucesso (99%+)
- Lida bem com sites pesados em JavaScript
- Ótimo para integrar em seus próprios apps ou fluxos
Limitações:
- Exige integração com API ou SDK
- Plano grátis: ~5.000 chamadas de API por 7 dias, depois 1.000/mês
Se você é desenvolvedor e quer fazer crawling (e talvez scraping) em escala sem administrar proxies, a Crawlbase é uma ótima opção (Crawlbase Pricing).
ScraperAPI: simplificando o crawling de sites dinâmicos

A ScraperAPI é a API do “só busca isso para mim”. Você fornece uma URL, ela cuida de proxies, navegadores headless e bloqueios anti-bot, e devolve o HTML (ou dados estruturados em alguns sites). É especialmente boa para páginas dinâmicas e oferece um plano grátis generoso (ScraperAPI Pricing).
Pontos fortes:
- Muito simples para desenvolvedores (basta uma chamada de API)
- Lida com CAPTCHAs, bloqueios de IP e JavaScript
- Grátis: 5.000 chamadas de API por 7 dias, depois 1.000/mês
Limitações:
- Não oferece relatórios visuais de crawl
- Você precisará programar a lógica de crawling se quiser seguir links
Se a ideia é encaixar crawling na sua base de código em minutos, a ScraperAPI é uma escolha óbvia.
Diffbot Crawlbot: descoberta automatizada da estrutura do site

O Diffbot Crawlbot é onde as coisas ficam realmente inteligentes. Ele não só rastreia — usa IA para classificar páginas e extrair dados estruturados (artigos, produtos, eventos etc.) em JSON. É como ter um estagiário robô que realmente entende o que está lendo (Diffbot Free Plan).
Pontos fortes:
- Extração com IA, não apenas crawling
- Lida com JavaScript e conteúdo dinâmico
- Grátis: 10.000 créditos/mês (cerca de 10 mil páginas)
Limitações:
- Voltado para desenvolvedores (integração via API)
- Não é uma ferramenta visual de SEO — serve mais para projetos de dados
Se você precisa de dados estruturados em escala, especialmente para IA ou analytics, o Diffbot é uma potência.
Screaming Frog: crawler desktop gratuito para SEO

O Screaming Frog é o clássico crawler desktop para auditorias de SEO. Ele rastreia até 500 URLs por varredura na versão gratuita e entrega praticamente tudo: links quebrados, meta tags, conteúdo duplicado, sitemaps e muito mais (Screaming Frog User Guide).
Pontos fortes:
- Rápido, completo e confiável no universo de SEO
- Não exige código — basta inserir uma URL e começar
- Grátis para até 500 URLs por rastreamento
Limitações:
- Apenas desktop (sem versão em nuvem)
- Recursos avançados (renderização JS, agendamento) exigem licença paga
Se SEO é prioridade, o Screaming Frog é indispensável — só não espere rastrear um site com 10 mil páginas de graça.
SiteOne Crawler: exportação estática e documentação de sites

O SiteOne Crawler é uma espécie de canivete suíço para auditorias técnicas. É open-source, multiplataforma e consegue rastrear, auditar e até exportar seu site para Markdown para documentação ou uso offline (SiteOne Crawler).
Pontos fortes:
- Cobre SEO, performance, acessibilidade e segurança
- Exporta sites para arquivamento ou migração
- Grátis e open-source, sem limites de uso
Limitações:
- Mais técnico que algumas ferramentas com interface gráfica
- Relatório na GUI limitado a 1.000 URLs por padrão (configurável)
Se você é desenvolvedor, QA ou consultor e quer uma análise profunda (e curte open source), o SiteOne é uma joia escondida.
Crawljax: crawler Java open source para páginas dinâmicas
O Crawljax é especializado: foi criado para rastrear apps web modernos e pesados em JavaScript, simulando interações de usuário (cliques, preenchimento de formulários etc.). Ele é orientado por eventos e ainda pode gerar uma versão estática de um site dinâmico (Wikipedia: Crawljax).
Pontos fortes:
- Imbatível para rastrear SPAs e sites com muito AJAX
- Open-source e extensível
- Sem limites de uso
Limitações:
- Exige Java e alguma programação/configuração
- Não é para usuários não técnicos
Se você precisa rastrear um app em React ou Angular como um usuário real, o Crawljax é seu aliado.
Apache Nutch: crawler distribuído e escalável para websites

O Apache Nutch é o avô dos crawlers open source. Ele foi pensado para rastreamentos massivos e distribuídos — como construir seu próprio mecanismo de busca ou indexar milhões de páginas (Martechvibe).
Pontos fortes:
- Escala para bilhões de páginas com Hadoop
- Altamente configurável e extensível
- Grátis e open-source
Limitações:
- Curva de aprendizado bem íngreme (Java, linha de comando, configurações)
- Não é ideal para sites pequenos ou usuários ocasionais
Se você quer rastrear a web em escala e não tem medo de mexer com terminal, o Nutch é para você.
YaCy: crawler e mecanismo de busca peer-to-peer
YaCy é um crawler e mecanismo de busca descentralizado, bem diferente dos demais. Cada instância rastreia e indexa sites, e você pode entrar em uma rede peer-to-peer para compartilhar índices com outras pessoas (TechRadar: YaCy).
Pontos fortes:
- Focado em privacidade, sem servidor central
- Ótimo para criar buscas privadas ou para intranet
- Grátis e open-source
Limitações:
- Os resultados dependem da cobertura da rede
- Exige alguma configuração (Java, interface no navegador)
Se você gosta de descentralização ou quer criar seu próprio mecanismo de busca, o YaCy é uma opção fascinante.
PowerMapper: gerador visual de sitemap para UX e QA

O PowerMapper é todo voltado a visualizar a estrutura do seu site. Ele rastreia seu site e gera sitemaps interativos, além de verificar acessibilidade, compatibilidade com navegadores e noções básicas de SEO (Slickplan Review).
Pontos fortes:
- Sitemaps visuais são ótimos para agências e designers
- Verifica acessibilidade e conformidade
- Interface simples, sem necessidade de habilidades técnicas
Limitações:
- Apenas teste grátis (30 dias, 100 páginas no desktop/10 páginas online por varredura)
- Versão completa é paga
Se você precisa apresentar um mapa do site para clientes ou verificar conformidade, o PowerMapper é muito útil.
Como escolher o Web Crawler gratuito ideal para sua necessidade
Com tantas opções, como decidir? Aqui vai meu guia rápido:
- Para auditorias de SEO: Screaming Frog (sites pequenos), PowerMapper (visual), SiteOne (auditorias profundas)
- Para apps web dinâmicos: Crawljax
- Para escala grande ou busca personalizada: Apache Nutch, YaCy
- Para desenvolvedores que precisam de API: Crawlbase, ScraperAPI, Diffbot
- Para documentação ou arquivamento: SiteOne Crawler
- Para uso enterprise com teste: BrightData, Diffbot
Fatores importantes a considerar:
- Escalabilidade: qual é o tamanho do seu site ou do trabalho de crawl?
- Facilidade de uso: você prefere código ou cliques?
- Exportação de dados: precisa de CSV, JSON ou integração com outras ferramentas?
- Suporte: existe comunidade ou documentação para ajudar se você travar?
Quando o Web Crawling encontra o Web Scraping: por que Thunderbit é uma escolha mais inteligente
Extraia dados de qualquer site usando IA Get Started Free
A real é a seguinte: a maioria das pessoas não rastreia sites só para fazer mapas bonitos. O objetivo mesmo costuma ser obter dados estruturados — seja lista de produtos, informações de contato ou inventário de conteúdo. É aí que o Thunderbit entra.
O Thunderbit não é apenas um crawler ou um scraper — é uma extensão Chrome com IA que combina os dois. Veja como funciona:
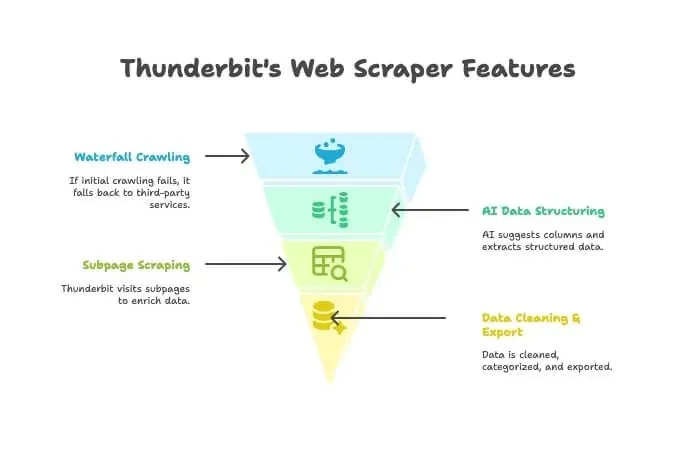
- AI Crawler: o Thunderbit explora o site como um crawler tradicional.
- Waterfall Crawling: se o mecanismo próprio do Thunderbit não conseguir acessar a página (talvez por uma proteção anti-bot mais forte), ele faz fallback automático para serviços de crawling de terceiros — sem nenhuma configuração manual.
- Estruturação de dados com IA: assim que obtém o HTML, a IA do Thunderbit sugere as colunas certas e extrai os dados estruturados (nomes, preços, e-mails etc.) sem que você precise escrever um único seletor.
- Scraping de subpáginas: precisa de detalhes de cada página de produto? O Thunderbit pode visitar automaticamente cada subpágina e enriquecer sua tabela.
- Limpeza e exportação de dados: ele pode resumir, categorizar, traduzir e exportar seus dados para Excel, Google Sheets, Airtable ou Notion com um clique.
- Simplicidade sem código: se você sabe usar um navegador, sabe usar o Thunderbit. Sem programação, sem proxies, sem dor de cabeça.
Quando vale usar o Thunderbit em vez de um crawler tradicional?
- Quando o objetivo final é uma planilha limpa e útil — não apenas uma lista de URLs.
- Quando você quer automatizar o processo inteiro (crawling, extração, limpeza e exportação) em um só lugar.
- Quando você valoriza seu tempo e sua sanidade.
Você pode baixar a extensão Chrome do Thunderbit aqui e ver por si mesmo por que tantos usuários de negócios estão migrando.
Experimente o Thunderbit grátis – AI Web Scraper
Conclusão: como aproveitar ao máximo os Website Crawlers gratuitos
O que é Data Scraping e como fazer Get Started Free
Os crawlers de sites evoluíram muito. Seja você um profissional de marketing, desenvolvedor ou só alguém querendo manter o site saudável, existe uma ferramenta gratuita — ou pelo menos com teste gratuito — para o seu caso. De plataformas enterprise como BrightData e Diffbot, passando por soluções open source como SiteOne e Crawljax, até mapeadores visuais como PowerMapper, as opções nunca foram tão diversas.
Mas se você procura um jeito mais inteligente e integrado de sair do “preciso desses dados” para “aqui está minha planilha”, vale testar o Thunderbit. Ele foi feito para usuários de negócio que querem resultado, não apenas relatórios.
Pronto para começar a rastrear? Baixe uma ferramenta, rode uma varredura e descubra o que estava perdendo. E, se quiser ir do crawling a dados acionáveis em dois cliques, conheça o Thunderbit.
Para mais análises aprofundadas e guias práticos, visite o Thunderbit Blog.
Extraia dados de sites com IA em 2 cliques
Experimente o AI Web Scraper Get Started Free
FAQ
Qual é a diferença entre um website crawler e um web scraper?
Um crawler descobre e mapeia todas as páginas de um site (pense: criar um sumário). Um scraper extrai campos específicos de dados (como preços, e-mails ou avaliações) dessas páginas. Crawlers encontram; scrapers extraem (Thunderbit Blog: What Is a Web Crawler?).
Qual crawler gratuito é melhor para usuários não técnicos?
Para sites pequenos e auditorias de SEO, o Screaming Frog é fácil de usar. Para mapeamento visual, o PowerMapper é excelente durante o teste. O Thunderbit é o mais simples se o seu objetivo for obter dados estruturados com uma experiência sem código e baseada no navegador.
Existem sites que bloqueiam crawlers?
Sim — alguns usam arquivos robots.txt ou mecanismos anti-bot, como CAPTCHAs e bloqueios de IP, para impedir crawlers. Ferramentas como ScraperAPI, Crawlbase e Thunderbit (com waterfall crawling) muitas vezes conseguem contornar isso, mas sempre faça crawling de forma responsável e respeite as regras do site (BrightData Pricing).
Crawlers gratuitos têm limites de páginas ou de recursos?
A maioria sim. Por exemplo, a versão gratuita do Screaming Frog é limitada a 500 URLs por rastreamento; o teste do PowerMapper limita a 100 páginas. Ferramentas baseadas em API geralmente têm limites mensais de créditos. Ferramentas open source como SiteOne ou Crawljax normalmente não têm limites rígidos, mas você fica limitado pelo hardware.
Usar um web crawler é legal e compatível com privacidade?
Em geral, rastrear páginas públicas é legal, mas sempre verifique os termos de uso do site e o robots.txt. Nunca rastreie dados privados ou protegidos por senha sem permissão e tenha atenção às leis de privacidade se estiver extraindo dados pessoais (Crawlbase Guide).




