Se você já tentou montar uma lista de leads, monitorar preços de produtos ou analisar avaliações de concorrentes na internet, sabe bem como é: clicar, copiar, colar, repetir — até acabar o café ou a paciência. Hoje em dia, o tutorial de extração de dados da web virou um verdadeiro trunfo para equipes de vendas, operações e marketing. Não é só questão de economizar tempo (embora economize, e muito). É sobre enxergar oportunidades, automatizar tarefas chatas e tomar decisões mais espertas — antes que a concorrência perceba.
Já vi de perto como um bom fluxo de extração de dados pode transformar uma semana inteira de pesquisa manual em só cinco minutinhos de trabalho. Seja você iniciante ou já querendo dar um passo além, este tutorial de extração de dados da web vai te mostrar o essencial, os desafios e o passo a passo prático — tanto com métodos tradicionais quanto com ferramentas de IA, como o . Bora transformar a web na sua fonte de dados valiosa.
O que é Extração de Dados da Web? O Básico que Você Precisa Saber
No fim das contas, extração de dados da web (ou web scraping) é o processo de coletar informações de sites de forma automática e organizar tudo em um formato estruturado — tipo uma planilha ou banco de dados — para análise ou uso nos negócios. Em vez de perder horas copiando e colando, um 웹 스크래퍼 funciona como um assistente digital: navega pelas páginas, encontra os dados que você precisa (preços, nomes de produtos, e-mails, avaliações) e organiza tudo para você ().
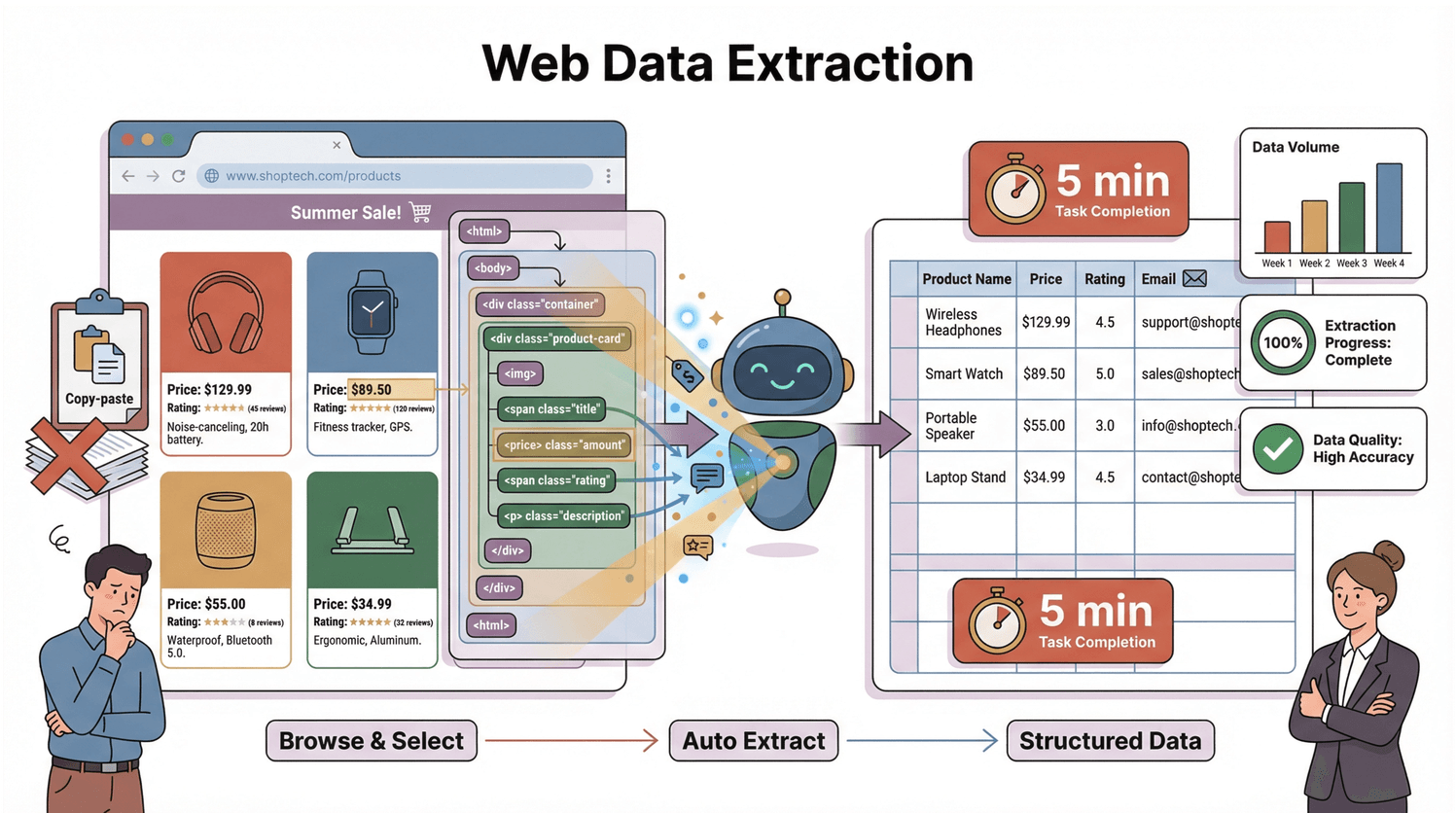
Mas como isso rola na prática? Toda página web é construída em cima de uma estrutura chamada DOM (Modelo de Objeto de Documento) — pense nela como um mapa que mostra ao navegador (e ao 웹 스크래퍼) onde está cada pedacinho de conteúdo. O 웹 스크래퍼 lê esse mapa, acha os elementos que interessam e extrai tudo em linhas e colunas. É como ter um assistente superorganizado que nunca se cansa nem se distrai com vídeos de gatos.
Por que a Extração de Dados da Web é Essencial para Vendas e Operações
Vamos falar a real: tutorial de extração de dados da web não é só coisa de nerd — é um superpoder para negócios. Olha só por que times de vendas, operações e marketing estão apostando nisso:
| Caso de Uso | Benefício para o Negócio | Impacto Real |
|---|---|---|
| Geração de Leads | Encha seu funil com leads qualificados rapidamente | 70% de ROI em 6 meses; 40% mais leads de qualidade; centenas de horas economizadas (Grepsr) |
| Monitoramento de Preços | Preços dinâmicos, proteção de margem | 65% de ROI em meio ano; aumento de 12% nas vendas; 75% menos trabalho manual (Grepsr) |
| Benchmarking de Concorrentes | Inteligência de mercado em tempo real | 55% de ROI para companhias aéreas; 68% de ROI em e-commerce (Grepsr) |
| Monitoramento Operacional | Evite rupturas, otimize a cadeia de suprimentos | 62% de ROI para varejista global; sem mais surpresas de estoque (Grepsr) |
E não é só sobre retorno financeiro. Automatizar a coleta de dados libera sua equipe para focar em estratégia, não em planilhas. Tem empresa que já cortou 40% dos custos de coleta de dados (), e o mercado global de web scraping deve saltar de US$ 5 bilhões em 2023 para mais de US$ 140 bilhões até 2032 (). É dado demais — e oportunidade de sobra.
Como Funciona a Extração de Dados da Web: Do DOM à Tabela
Vamos simplificar o que rola nos bastidores:
- Requisição: O 웹 스크래퍼 manda um pedido pro site e recebe o HTML bruto.
- Análise: Ele lê o DOM da página — aquela estrutura em árvore que organiza tudo.
- Extração: Acha os dados que você quer (preços, nomes, e-mails) e joga tudo numa tabela organizada (CSV, Excel, Google Sheets, etc.) ().
Entendendo o DOM: O Mapa da Extração de Dados
Pensa no DOM como a árvore genealógica de uma página web. No topo está o documento, que se divide em <html>, depois <head> e <body>, e assim vai — até cada <div>, <span> e texto (). Cada nó dessa árvore é um elemento que você pode capturar.
Por exemplo, para pegar o preço de um produto, o 웹 스크래퍼 pode buscar um <span class="price"> dentro de um <div> no <body>. É tipo pedir pro assistente: “Vai até a cozinha, abre a geladeira, acha o leite.” O DOM é o mapa; o 웹 스크래퍼 é o explorador.
Mas tem um detalhe: muitos sites modernos usam JavaScript pra carregar conteúdo na hora. Ou seja, o dado que você quer pode não estar no HTML inicial — só aparece depois que a página termina de carregar e os scripts rodam. Por isso, o 웹 스크래퍼 precisa enxergar o DOM renderizado, não só o HTML cru (). É aí que muitos métodos antigos falham (e onde as ferramentas modernas brilham).
Armadilhas Comuns na Extração de Dados da Web (e Como Driblar)
Fazer scraping nem sempre é moleza. Olha os principais desafios — e como sair por cima:
- Conteúdo Dinâmico & Rolagem Infinita: Muitos sites carregam dados conforme você navega ou rola a página. Se o 웹 스크래퍼 só pega o HTML inicial, vai perder muita coisa. Solução: use ferramentas que renderizam JavaScript ou simulam rolagem (Thunderbit faz isso sozinho) ().
- Paginação & Subpáginas: Dados espalhados em várias páginas ou escondidos em detalhes? Garanta que sua ferramenta segue botões “Próximo” e acessa subpáginas. O recurso “Raspar Subpáginas” do Thunderbit resolve isso ().
- Mudanças no Layout do Site: Pequenas alterações podem quebrar métodos antigos. Ferramentas com IA, como Thunderbit, se adaptam automaticamente, evitando dor de cabeça ().
- Barreiras Anti-Scraping: CAPTCHAs, bloqueios de IP e limites de acesso podem travar seu trabalho. Sempre raspe com cautela (vá devagar, varie os acessos), use ferramentas baseadas em navegador e respeite as regras do site ().
- Dados Bagunçados ou Inconsistentes: Nem todo site é bem estruturado. Às vezes, vai precisar usar prompts de IA ou regras personalizadas pra extrair o que interessa (o Field AI Prompt do Thunderbit é ótimo pra isso).
Lidando com Páginas Dinâmicas e JavaScript
Algumas páginas só mostram tudo depois de rolar ou clicar — usando JavaScript pra carregar mais conteúdo. Métodos antigos não capturam isso, mas extensões de navegador (como Thunderbit) veem o que você vê e conseguem extrair tudo, até de rolagens infinitas ou pop-ups ().
Como Driblar Barreiras Anti-Scraping
Se você está sendo bloqueado ou vendo CAPTCHAs, diminua a frequência dos acessos, alterne IPs e use ferramentas que simulam o comportamento de usuários reais. E sempre confira as regras do site e o robots.txt ().
Comparando Ferramentas de Extração de Dados: Thunderbit vs. Soluções Tradicionais
Existem várias formas de extrair dados — algumas mais trabalhosas que outras. Veja como as principais opções se comparam:
| Solução | Tempo de Configuração | Habilidade Necessária | Manutenção | Recursos & Opções de Exportação |
|---|---|---|---|---|
| Copiar e Colar Manualmente | Nenhum | Nenhuma | Sempre manual | Sem automação; sujeito a erros |
| Código Personalizado (Python, etc.) | Horas–Dias | Programação + HTML | Alta | Flexível; exporta para qualquer lugar; curva de aprendizado alta |
| Ferramentas No-Code Tradicionais | ~1 hora/site | Algum conhecimento técnico | Média | Configuração visual; suporta paginação; curva de aprendizado moderada |
| Thunderbit (IA No-Code) | Minutos | Nenhuma (português claro) | Baixa (IA adapta) | Detecção de campos por IA; subpáginas; agendamento; exporta para Sheets/Excel/Notion |
O Thunderbit se destaca pra quem trabalha com negócios porque foi feito pra ser simples. Não precisa saber programar — só descrever o que você quer e a IA faz o resto ().
Por que o Thunderbit é Diferente para Negócios
- Simplicidade em Dois Cliques: “IA Sugere Campos” e depois “Raspar”. Pronto.
- Reconhecimento de Campos por IA: A IA lê a página e sugere as melhores colunas — sem chute.
- Sem Código, Linguagem Natural: Só digitar o que deseja (“Pegue todos os nomes e preços dos produtos”) e o Thunderbit entende.
- Automação de Subpáginas e Paginação: Raspe todas as páginas e links de detalhes com um clique.
- Exportação Rápida: Envie os dados direto para Excel, Google Sheets, Notion ou Airtable — sem custo extra.
- Modo Nuvem ou Navegador: Raspe na nuvem pra mais velocidade ou no navegador pra páginas logadas.
O Thunderbit foi criado pro mundo real — onde os sites mudam, os dados são bagunçados e quem trabalha com negócios precisa de resultado, não de dor de cabeça.
Tutorial Passo a Passo: Extraindo Dados da Web com Thunderbit
Pronto pra colocar a mão na massa (sem complicação)? Veja como extrair dados de qualquer site usando o :
Passo 1: Instale a Extensão Thunderbit no Chrome
Acesse a e adicione o Thunderbit. Crie uma conta gratuita — o plano grátis já permite testar a ferramenta em algumas páginas.
Passo 2: Acesse o Site que Você Quer Extrair Dados
Abra o site desejado. Faça login se precisar e navegue até que todos os dados que você quer estejam visíveis.
Passo 3: Abra o Thunderbit e Descreva o que Precisa
Clique no ícone do Thunderbit. Você pode:
- Clicar em “IA Sugere Campos” pra IA analisar e sugerir colunas.
- Ou digitar um prompt personalizado: “Extrair nome do produto, preço e avaliações.”
O Thunderbit mostra uma prévia dos campos encontrados. Você pode renomear, excluir ou adicionar colunas como quiser.
Passo 4: Execute a Extração
Clique em “Raspar”. O Thunderbit vai extrair os dados pra uma tabela. Se tiver várias páginas ou subpáginas, ele pergunta se você quer raspar tudo — só confirmar.
Passo 5: Revise e Exporte
Confira os resultados. Se faltar algo, tente reformular o prompt ou garantir que todo o conteúdo esteja carregado. Quando estiver satisfeito, clique em “Exportar” pra baixar em CSV ou enviar direto pro Google Sheets, Excel, Notion ou Airtable.
Exemplo Prático: Extraindo Avaliações de Produtos da Amazon com Thunderbit
Suponha que você queira analisar avaliações de um produto concorrente na Amazon. Veja como o Thunderbit facilita:
- Acesse a página do produto na Amazon e clique em “Ver todas as avaliações”.
- Ative o Thunderbit. Se aparecer o template Amazon Reviews Scraper, use — ele já está configurado com os campos certos ().
- Clique em “Raspar”. O Thunderbit coleta nomes dos avaliadores, notas, textos, datas e mais — em todas as páginas.
- Exporte. Agora você tem uma planilha pronta pra análise de sentimento, benchmarking ou um relatório rápido sobre o que os clientes realmente valorizam.
Quer personalizar? Só usar um prompt em linguagem natural: “Extrair nome do avaliador, nota, data e texto da avaliação.” A IA do Thunderbit faz o resto — mesmo que a Amazon mude o layout.
Dicas Avançadas: Personalize e Automatize sua Extração de Dados
Depois de dominar o básico, os recursos avançados do Thunderbit podem turbinar seu fluxo de trabalho:
- Field AI Prompts: Adicione instruções específicas pra cada campo (ex: “Extrair só avaliações com 1 ou 2 estrelas” ou “Traduzir o texto para português”).
- Raspador Agendado: Programe extrações recorrentes (diárias, semanais, etc.) pra manter os dados sempre atualizados — ótimo pra monitorar preços ou gerar leads ().
- AI Autofill: Automatize preenchimento de formulários ou fluxos multi-etapas (perfeito pra sites que exigem buscas ou login).
- Raspagem na Nuvem: Pra grandes volumes, execute as extrações na nuvem pra mais velocidade e estabilidade.
- Templates Instantâneos: Use modelos prontos pra sites populares como Amazon, Zillow, Yelp, LinkedIn e outros ().
Você ainda pode integrar o Thunderbit ao fluxo do seu time — exportando pra Google Sheets, compartilhando resultados ou conectando a outras ferramentas pra automação.
O Futuro da Extração de Dados da Web: IA e o Impacto nos Negócios
A IA está mudando o jogo da extração de dados da web:
- Resiliência: 웹 스크래퍼 com IA se adaptam automaticamente a mudanças nos sites, reduzindo manutenção e paradas ().
- Scraping Agente: Bots já conseguem navegar, clicar e interagir como humanos — abrindo novas fontes e fluxos de dados.
- Dados em Tempo Real: Empresas estão migrando de extrações pontuais pra pipelines contínuos e automáticos.
- Acessibilidade: Ferramentas no-code e prompts em linguagem natural, como o Thunderbit, democratizam a extração de dados — não é mais só pra desenvolvedor.
- Insights Imediatos: O próximo passo é unir scraping com análise por IA — imagine extrair avaliações de concorrentes e já receber um resumo dos principais pontos críticos.
Resumindo? Tutorial de extração de dados da web com IA está virando tão essencial quanto planilhas ou CRMs. Quem dominar essa habilidade vai sair na frente — enquanto os outros ainda estão presos no copiar e colar.
Conclusão & Principais Aprendizados
- Extração de dados da web transforma a internet no seu banco de dados pessoal — automatizando a coleta de leads, preços, avaliações e muito mais.
- O DOM é o mapa de toda página web; entender isso é chave pra extrair dados com eficiência.
- Principais desafios (conteúdo dinâmico, barreiras anti-bot, dados bagunçados) podem ser superados com as ferramentas certas e um pouco de conhecimento.
- Thunderbit deixa a extração de dados acessível pra todo mundo: dois cliques, detecção de campos por IA, raspagem de subpáginas e exportação instantânea pra suas ferramentas favoritas.
- A IA é o futuro — tornando o scraping mais rápido, inteligente e confiável pra negócios.
Quer experimentar? e veja como a extração de dados pode ser simples. Pra mais dicas, tutoriais e casos reais, acesse o .
Perguntas Frequentes
1. O que é extração de dados da web e como funciona?
Extração de dados da web (web scraping) é o processo automatizado de coletar informações de sites e transformar em dados estruturados, tipo uma planilha. Funciona lendo o DOM do site, identificando os dados desejados e exportando pra análise ().
2. Quais os maiores desafios na extração de dados da web?
Os principais obstáculos são conteúdo dinâmico (dados carregados por JavaScript), barreiras anti-scraping (CAPTCHAs, bloqueios de IP) e dados desorganizados. Ferramentas modernas como Thunderbit usam IA e scraping via navegador pra superar esses desafios ().
3. O que diferencia o Thunderbit de outras ferramentas de web scraping?
Thunderbit é um 웹 스크래퍼 com IA e sem código, pensado pra negócios. Tem configuração em dois cliques (“IA Sugere Campos” e “Raspar”), prompts em linguagem natural, raspagem de subpáginas e exportação instantânea pra Excel, Google Sheets, Notion e Airtable ().
4. Posso usar o Thunderbit para extrair dados de sites dinâmicos ou com várias páginas?
Com certeza. O Thunderbit lida automaticamente com conteúdo dinâmico (rolagem infinita, dados carregados por JavaScript) e pode raspar várias páginas ou subpáginas com um clique ().
5. A extração de dados da web é legal?
Raspar dados públicos geralmente é permitido, especialmente pra inteligência de negócios, mas sempre confira os termos de uso do site e o robots.txt. Evite coletar dados pessoais ou privados e raspe com responsabilidade — sem sobrecarregar sites ou violar políticas ().
Boas extrações — que suas planilhas estejam sempre cheias, seus dados sempre atualizados e o copiar e colar fique no passado.
Saiba Mais