

A internet está transbordando de dados — tanta coisa que isso virou o coração dos negócios modernos. Seja em vendas, e-commerce, imóveis ou simplesmente para acompanhar a concorrência, ter os dados certos à mão faz toda a diferença. Mas vamos falar a verdade: ninguém quer passar horas a copiar e colar informações de sites para folhas de cálculo. É aqui que entra a raspagem de dados da web, e pode acreditar: é muito menos intimidante do que parece.
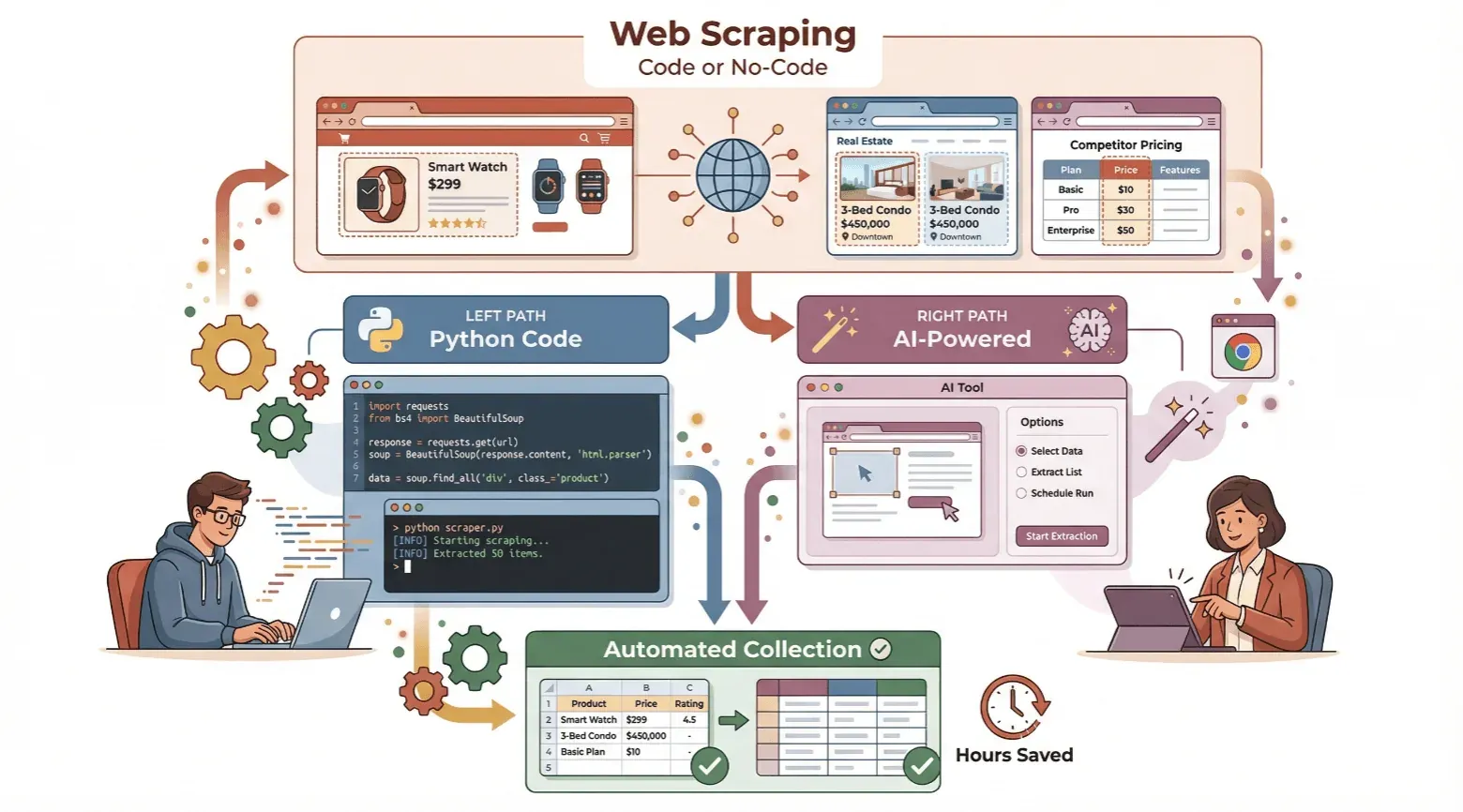
Neste guia, vou mostrar como criar um raspador web — quer seja iniciante e queira experimentar programar em Python, quer prefira saltar o código e usar uma ferramenta no-code com IA como a Thunderbit. Vou explicar o básico, mostrar as duas abordagens passo a passo e ajudar você a decidir qual caminho faz mais sentido para o seu caso. Pronto para poupar tempo e desbloquear o poder da recolha automatizada de dados? Vamos lá.
O que é um Raspador Web? Entendendo o Básico
Um raspador web é simplesmente uma ferramenta — software ou serviço — que extrai automaticamente informações de sites. Imagine que precisa de uma lista de todas as cafeterias da sua cidade, com moradas e números de telefone. Podia passar horas a clicar em páginas e a copiar cada detalhe manualmente (olá, cansaço de Ctrl+C), ou deixar um raspador web fazer o trabalho pesado por si.
Pense num raspador web como um assistente digital que lê páginas da web, encontra os dados de que você precisa (como preços, nomes de produtos ou contactos) e organiza tudo de forma limpa numa folha de cálculo ou base de dados. Em vez de andar a alternar manualmente entre separadores do navegador e Excel, o raspador automatiza o processo — procura, analisa e guarda os dados numa fração do tempo.
Veja como isso funciona nos bastidores:
- Pedido: o raspador envia um pedido a uma página e descarrega o HTML bruto.
- Análise: ele examina o HTML para encontrar os dados específicos que você procura (como o preço dentro de uma tag
<span>). - Extração: recolhe esses dados e guarda-os num formato estruturado (CSV, Excel, Google Sheets etc.).
Copiar e colar à mão é como cavar um buraco com uma colher. A raspagem de dados da web é chamar uma escavadora.
Por que Criar um Raspador Web é Importante para os Negócios
A raspagem de dados da web não é só para gente de tecnologia ou cientistas de dados — tornou-se uma ferramenta indispensável para qualquer pessoa que precise de informação fiável e atualizada. Quase 97% das grandes organizações já investem em decisões orientadas por dados, e a cobertura de analistas sobre o mercado de raspagem de dados da web projeta, de forma consistente, crescimento contínuo por vários anos até ao fim da década.
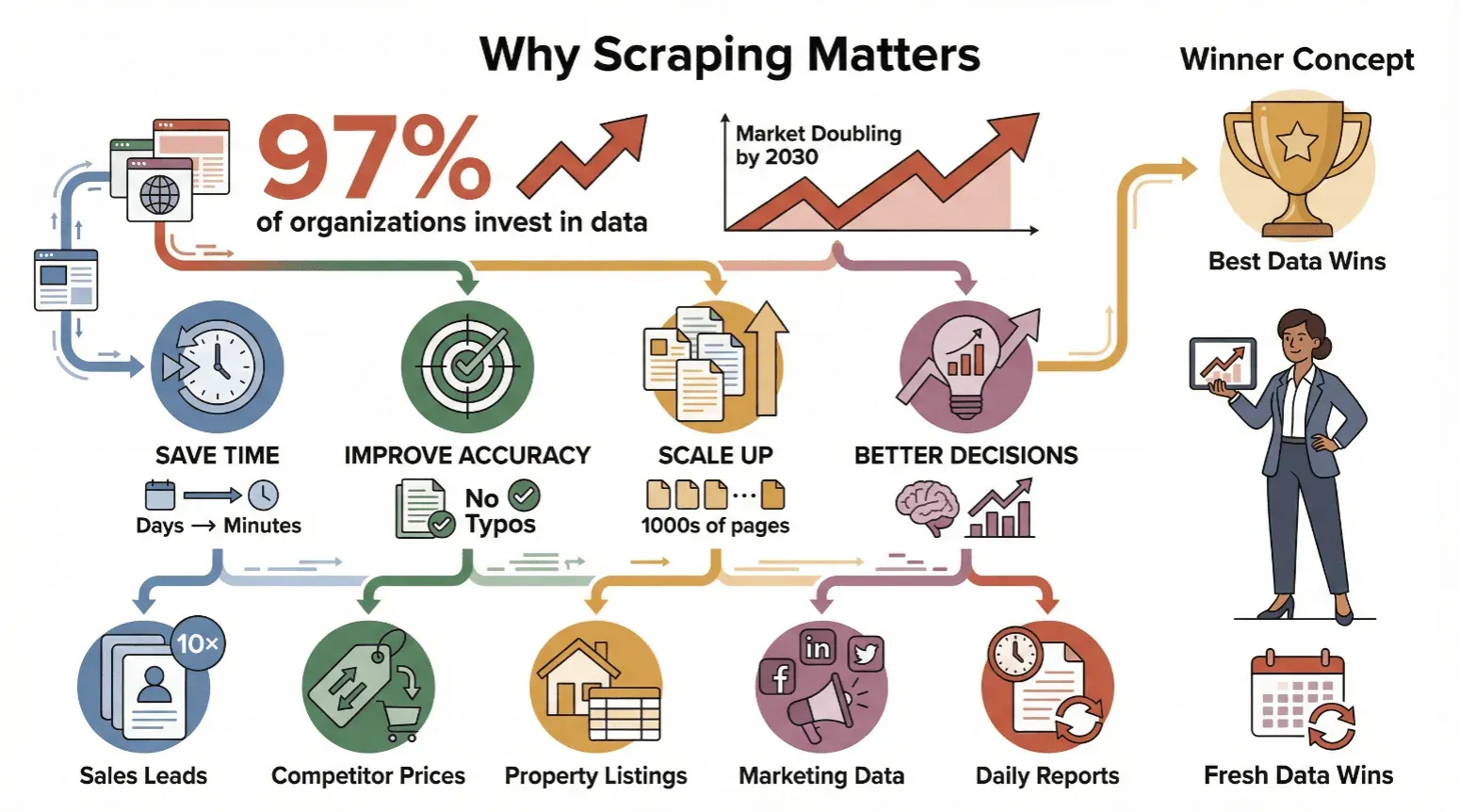
Veja por que empresas de todos os tamanhos estão a adotar a raspagem de dados da web:
- Poupe tempo: a raspagem automatizada transforma dias de trabalho manual em minutos.
- Aumente a precisão: o software não se cansa nem comete erros de digitação.
- Escale: raspe milhares de páginas, não apenas algumas.
- Tome melhores decisões: dados atualizados significam ações mais inteligentes — seja a ajustar preços, encontrar leads ou acompanhar tendências.
Vejamos alguns casos de uso reais:
| Caso de uso | Quem beneficia | Resultado típico |
|---|---|---|
| Extrair leads de vendas de diretórios | Equipas de vendas | 10× mais leads, horas poupadas na prospeção |
| Monitorizar preços da concorrência em e-commerce | Gestores de e-commerce | Ajustes de preço em tempo real, proteção da margem |
| Agregar anúncios de imóveis do setor imobiliário | Imobiliárias | Descoberta mais rápida de oportunidades, dados de mercado atualizados |
| Recolher dados de marketing da web/redes sociais | Equipas de marketing | Campanhas mais segmentadas, melhor acompanhamento do desempenho |
| Automatizar relatórios diários de dados da web | Operações, analistas | Menores custos de trabalho, menos erros, relatórios consistentes e pontuais |
Em resumo: quem tem os melhores dados, e os mais atualizados, sai na frente.
Guia para Iniciantes: Como Criar um Raspador Web Simples com Python
Se tem curiosidade sobre como a raspagem de dados da web funciona “nos bastidores”, Python é um excelente ponto de partida. Mesmo que esteja a começar agora a programar, dá para criar um raspador básico em apenas alguns passos. Veja como:
Configurando o Ambiente
Primeiro, precisa de ter o Python instalado no computador. Descarregue a versão mais recente em python.org e siga as instruções do seu sistema operativo (Windows ou Mac). Não se esqueça de assinalar “Add Python to PATH” durante a instalação.
Depois, abra o terminal ou prompt de comando e instale as bibliotecas de que vai precisar:
pip install requests
pip install bs4
pip install pandas
requestspermite pedir páginas da web.bs4(Beautiful Soup) ajuda a analisar o HTML.pandasé ótimo para guardar dados em CSV ou Excel.
Inspecionando a Estrutura do Site
Antes de escrever qualquer código, precisa de saber onde os dados estão no HTML. Abra o site-alvo no Chrome, clique com o botão direito no dado que quer (como um título de vaga) e selecione “Inspecionar”. Vai ver o elemento HTML destacado — talvez uma tag <a> com uma classe como jobtitle. Repare nessas tags e classes; vai usá-las para dizer ao seu raspador o que procurar.
Escrevendo e Executando o Raspador
Digamos que quer raspar títulos de vagas e nomes de empresas de uma página de anúncios de emprego. Aqui está um script simples:
import requests
from bs4 import BeautifulSoup
import pandas as pd
URL = "https://example.com/jobs" # Substitua pela sua URL-alvo
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# Encontre todos os títulos de vagas e nomes de empresas (ajuste os seletores conforme necessário)
titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
# Guardar em CSV
df = pd.DataFrame({'Título da vaga': titles, 'Empresa': companies})
df.to_csv('jobs.csv', index=False)
print("Raspagem concluída! Dados guardados em jobs.csv")
- Ajuste a URL e os nomes das classes para corresponder ao site-alvo.
- Execute o script no terminal:
python yourscript.py - Abra
jobs.csvpara ver os resultados.
Dica profissional: para sites mais complexos (com paginação ou conteúdo dinâmico), vai precisar de adicionar loops ou usar ferramentas como Selenium. Mas, para muitas páginas estáticas, esta abordagem funciona muito bem.
Simplicidade No-Code: Como Criar um Raspador Web com a Thunderbit
E se não quiser mexer em código nenhum? É aí que entra a Thunderbit — um raspador web no-code com IA, criado para utilizadores de negócio. Para páginas simples e bem estruturadas, a Thunderbit pode levá-lo de “preciso destes dados” até uma folha de cálculo utilizável em poucos cliques — sites mais pesados, com login, proteções anti-bot ou layouts incomuns ainda exigem algum ajuste, mas a barreira inicial é muito menor do que escrever um parser à mão.
Extraia dados de qualquer site usando IA Get Started Free
Veja como funciona:
Etapa 1: Instale a Extensão Thunderbit para Chrome
Aceda à Página de Download da Extensão Thunderbit para Chrome e adicione-a ao navegador. Crie uma conta gratuita (o plano gratuito permite raspar algumas páginas para você testar).
Etapa 2: Acesse o Site-Alvo
Abra no Chrome a página que quer raspar. Faça login, se necessário, e desça a página para carregar qualquer conteúdo dinâmico.
Etapa 3: Descreva o que Você Precisa Extrair
Clique no ícone da Thunderbit para abrir a barra lateral. Pode:
- Clicar em “AI Suggest Fields” e deixar a IA da Thunderbit analisar a página e sugerir colunas (como “Nome do produto”, “Preço”, “Imagem”).
- Ou escrever um prompt em linguagem natural (por exemplo, “Extraia todos os títulos e autores de livros desta página”).
A IA da Thunderbit vai recomendar os campos e os tipos de dados automaticamente. Pode renomear, adicionar ou eliminar campos conforme necessário.
Etapa 4: Execute Sua Primeira Raspagem
Depois de os campos estarem definidos, basta clicar em “Scrape”. A Thunderbit vai extrair os dados, tratar da paginação se necessário e mostrar tudo numa tabela organizada. Se quiser mais detalhes de subpáginas (como páginas individuais de produtos), clique em “Scrape Subpages” — a Thunderbit vai visitar cada link e recolher informações extra.
Etapa 5: Revise e Exporte os Resultados
Verifique os dados na tabela da Thunderbit. Quando estiver satisfeito, clique em “Export” e escolha o formato: Excel, CSV, Google Sheets, Airtable, Notion ou JSON. As exportações são gratuitas e ilimitadas.
É isso. Sem código, sem modelos, sem dor de cabeça.
Experimente o Raspador Web IA da Thunderbit gratuitamente
Comparando Soluções Tradicionais e No-Code de Raspador Web
Vamos ver como as duas abordagens se comparam:
| Solução | Tempo de configuração | Competências necessárias | Manutenção | Flexibilidade | Opções de exportação |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Horas/dias | Programação, noções de HTML | Alta (quebra facilmente) | Muito alta | CSV, Excel, JSON (via código) |
| Ferramentas No-Code mais antigas | 30–60 min | Algum conhecimento técnico | Média (correção manual) | Boa para páginas estáticas | CSV, Excel |
| Thunderbit (No-Code com IA) | Minutos | Nenhuma (linguagem natural) | Baixa (a IA adapta-se) | Alta (sites dinâmicos) | Excel, CSV, Sheets, Notion... |
A abordagem orientada por IA da Thunderbit significa que você passa menos tempo a configurar e corrigir raspadores, e mais tempo a usar de facto os seus dados.
Superando os Desafios Tradicionais do Raspador Web
Os raspadores tradicionais têm alguns problemas bem conhecidos:
- Mudanças no site: se um site atualiza o layout, o seu código pode quebrar. A IA da Thunderbit adapta-se automaticamente à maioria das mudanças, por isso você não precisa de reescrever nada.
- Medidas anti-bot: muitos sites bloqueiam scripts automatizados. A Thunderbit pode correr no seu navegador (usando o seu login/sessão) ou na cloud para ganhar velocidade.
- Conteúdo dinâmico: páginas com scroll infinito ou botões “Carregar mais” podem travar raspadores básicos. A IA da Thunderbit trata da rolagem automática e de elementos interativos por defeito.
- Dados que exigem login: com o modo navegador da Thunderbit, se você consegue ver no Chrome, você consegue raspar.
Em resumo, a Thunderbit foi feita para lidar com a confusão da web moderna — para que você não tenha de lidar.
Aumentando a Eficiência: Recursos Avançados de Raspagem da Thunderbit
A Thunderbit não serve só para obter dados — serve para obtê-los rápido, limpos e prontos a usar. Aqui estão alguns recursos que eu adoro:
Paginação Automática e Raspagem de Subpáginas
Precisa de raspar centenas de produtos em várias páginas? A Thunderbit deteta paginação (botões Próximo, scroll infinito) e recolhe tudo de uma vez. Quer mais detalhes nas subpáginas? Clique em “Scrape Subpages” e a Thunderbit vai visitar cada link, puxando campos extra (como informações do vendedor ou especificações do produto).
Sugestões de Campos com IA e Estruturação de Dados
A IA da Thunderbit não se limita a adivinhar colunas — entende o contexto. Pode nomear colunas, atribuir tipos de dados (texto, número, imagem, email) e até aplicar instruções personalizadas (como “apenas preços acima de US$ 100” ou “traduzir as descrições para inglês”). Pode adicionar prompts para categorizar, resumir ou reformular os dados enquanto estão a ser raspados.
Modelos e Raspagem Instantânea
Para sites populares (Amazon, Zillow, Google Maps, Instagram), a Thunderbit oferece modelos instantâneos — basta escolher o site e todos os campos já vêm pré-configurados. Sem necessidade de configuração.
Agendamento e Automação
Precisa de dados novos todos os dias? Configure um agendamento (“todas as segundas-feiras às 9h”) e a Thunderbit fará a raspagem automaticamente, atualizando a sua folha de Google ou base de dados sem que você precise de mexer um dedo.
Raspagem na Nuvem vs. Local
Escolha entre executar as raspagens no navegador (ótimo para sites com login ou interativos) ou na cloud (mais rápido para dados públicos — até 50 páginas por vez).
O que é raspagem de dados e como fazer isso em 2025 Get Started Free
Os recursos avançados da Thunderbit fazem dela uma das melhores opções para utilizadores de negócio que precisam de uma solução de raspagem de dados da web fiável, escalável e fácil de usar.
Guia Passo a Passo: Como Criar um Raspador Web com a Thunderbit
Aqui está a sua checklist de arranque rápido:
- Instale a Thunderbit: Adicione a extensão do Chrome e crie a sua conta.
- Abra o site-alvo: faça login, se necessário, e desça para carregar o conteúdo.
- Abra a barra lateral da Thunderbit: clique no ícone da extensão.
- Descreva os seus dados: clique em “AI Suggest Fields” ou escreva o seu prompt.
- Revise os campos: renomeie, adicione ou elimine colunas conforme necessário.
- Clique em “Scrape”: deixe a Thunderbit fazer o trabalho.
- (Opcional) Raspe subpáginas: para dados mais detalhados, clique em “Scrape Subpages”.
- Revise os resultados: verifique a precisão na tabela.
- Exporte os dados: escolha Excel, CSV, Google Sheets, Notion, Airtable ou JSON.
- Guarde/modele/agende: guarde a sua configuração para a próxima vez ou agende raspagens recorrentes.
Dicas de resolução de problemas:
- Se faltarem dados, tente reformular o seu prompt ou usar instruções personalizadas.
- Para conteúdo dinâmico, certifique-se de estar no modo navegador.
- Se atingir o limite do plano gratuito, considere fazer upgrade para raspar mais páginas.
Veja os preços e planos da Thunderbit
Conclusão e Principais Aprendizagens
Criar um raspador web já não é coisa só de programador. Seja para arregaçar as mangas e escrever em Python, seja para deixar a IA fazer o trabalho pesado, as ferramentas estão mais acessíveis do que nunca.
O que lembrar:
- A raspagem de dados da web poupa tempo, aumenta a precisão e permite decisões orientadas por dados.
- Python é ótimo para aprendizagem e projetos personalizados, mas exige programação e manutenção.
- A Thunderbit oferece uma solução rápida e no-code — basta descrever o que quer e clicar em “Scrape”.
- Recursos avançados como paginação automática, raspagem de subpáginas e sugestões de campos com IA tornam a Thunderbit uma potência para utilizadores de negócio.
- Pode testar a Thunderbit gratuitamente e ver resultados em minutos.
Pronto para deixar de copiar e colar e começar a automatizar? Descarregue a Thunderbit e veja como a raspagem de dados da web pode ser fácil. E, se quiser aprofundar, confira o Blog da Thunderbit para mais tutoriais e dicas.
Experimente o Raspador Web IA da Thunderbit gratuitamente Get Started Free
Perguntas frequentes
1. Preciso saber programar para criar um raspador web?
Não! Embora programar (como com Python + Beautiful Soup) dê controlo total, ferramentas no-code como a Thunderbit permitem que qualquer pessoa crie raspadores web poderosos usando prompts em linguagem natural e alguns cliques.
2. Que tipo de dados posso raspar com a Thunderbit?
A Thunderbit pode extrair texto, números, imagens, emails, números de telefone e muito mais de כמעט qualquer site — inclusive listas paginadas e subpáginas. Também pode usar modelos para sites populares.
3. Como a Thunderbit lida com sites que mudam o layout?
A IA da Thunderbit adapta-se automaticamente à maioria das mudanças de layout. Ao contrário dos raspadores tradicionais, que quebram quando um site é atualizado, a Thunderbit usa compreensão semântica para continuar a funcionar com o mínimo de ajuste.
4. A raspagem de dados da web é legal e segura?
A raspagem de dados da web é legal quando recolhe dados publicamente disponíveis e respeita os termos de serviço do site. A Thunderbit incentiva o uso responsável e oferece recursos para ajudar você a manter-se em conformidade.
5. Posso agendar raspagens recorrentes ou automatizar exportações?
Sim! A Thunderbit permite agendar raspagens em qualquer intervalo (diário, semanal etc.) e exportar resultados diretamente para Google Sheets, Notion, Airtable, Excel ou CSV — sem trabalho manual.
Pronto para automatizar a recolha dos seus dados? Experimente a Thunderbit gratuitamente e veja como a raspagem de dados da web pode ser fácil para toda a gente.
Saiba mais




