Sephora scraper

Zaufali nam profesjonaliści z czołowych firm














Odblokuj dane Sephora w dwóch kliknięciach
Bezproblemowe pobieranie danych z Sephora w dwóch kliknięciach
Masz dość skomplikowanych narzędzi do pobierania danych? Thunderbit pozwala pobierać dane o produktach Sephora bez napisania ani jednej linijki kodu. Po prostu wskaż nazwę produktu, markę, cenę, ocenę, liczbę recenzji i typ skóry, których potrzebujesz, a następnie kliknij, aby wyodrębnić dane. To naprawdę takie proste.
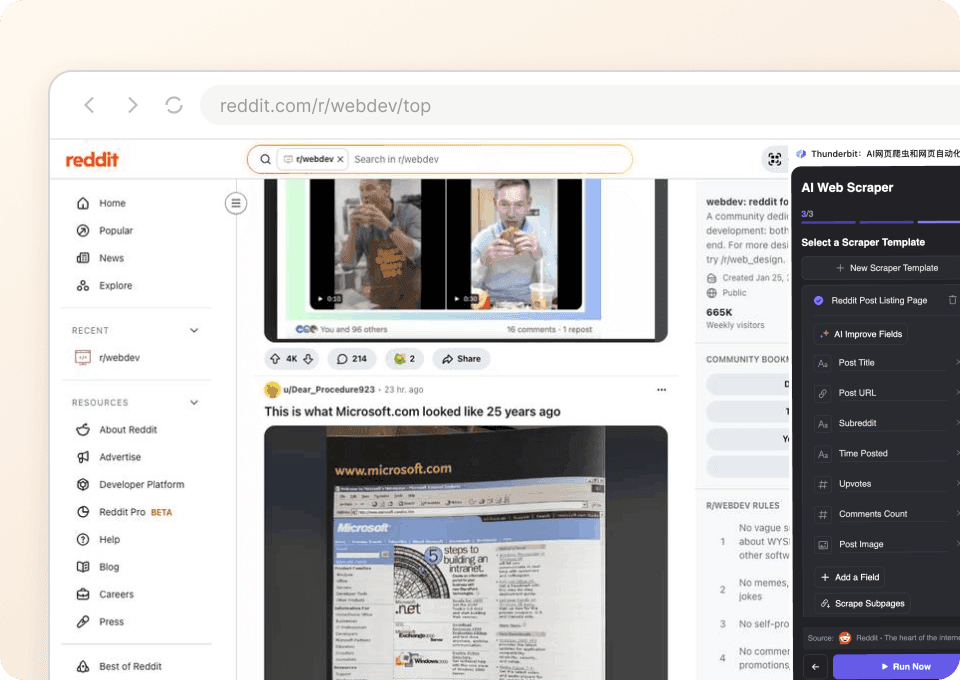
Automatycznie otrzymuj czyste dane z Sephora
Dane z Sephora bywają chaotyczne, ale ich porządkowanie nie musi takie być. Thunderbit automatycznie strukturyzuje i formatuje dane w trakcie ekstrakcji, więc nie musisz spędzać godzin na ich czyszczeniu. Eksportuj bezpośrednio do Google Sheets, Notion lub Airtable i od razu zaczynaj analizę.
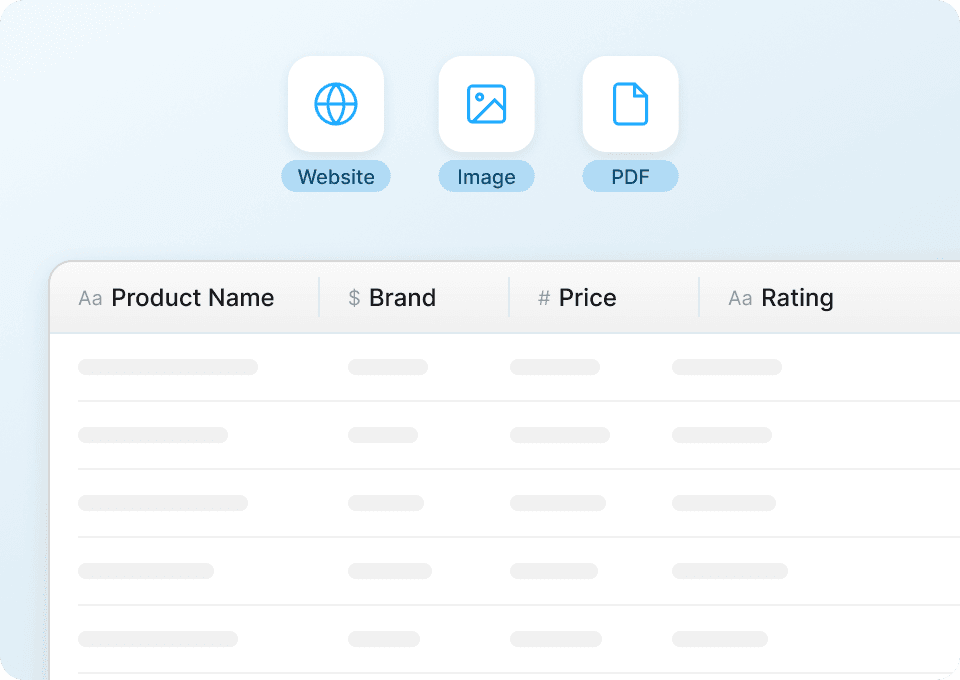
Skaluj pobieranie danych z Sephora bez wysiłku
Ręczne pobieranie szczegółów produktu z każdej strony Sephora to uciążliwa praca. Z Thunderbit możesz pobrać jednocześnie setki stron produktów. Wystarczy, że podasz Thunderbit listę adresów URL z Sephora, a narzędzie automatycznie wyodrębni z każdej strony dane, takie jak nazwa produktu, cena i oceny.
Masz problem z pobieraniem danych produktów z Sephora?
Zobacz, jak Thunderbit wypada na tle tradycyjnych metod pobierania danych.
Tradycyjne scrapery
Stary sposób działaniaThunderbit
Inteligentniejsze podejścieNie wierz tylko nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.







Najczęściej zadawane pytania
Powiązane przypadki użycia
Poznaj więcej zastosowań web scrapera Thunderbit.

HKTVmall Scraper
Zbieraj nazwy produktów, ceny, a nawet oceny klientów z ofert HKTVmall kilkoma kliknięciami — bez żadnej skomplikowanej konfiguracji.
Dowiedz się więcej ->Video Scraper
Video Scraper od Thunderbit pozwala w kilka kliknięć wyciągać z TikToka dane o filmach i twórcach z pomocą AI. Zbieraj listy filmów, metryki wyników i szczegóły profili, a następnie eksportuj do Excel, Google Sheets, Airtable lub Notion, aby prowadzić monitoring i research influencerów.
Dowiedz się więcej ->
Wikipedia scraper
Pobieraj dane z infoboksów, przypisy i treść artykułów z Wikipedii do przejrzystego arkusza — bez kodu, AI zrobi strukturę za Ciebie.
Dowiedz się więcej ->
PubMed Scraper
PubMed Scraper od Thunderbit pozwala z pomocą AI wyciągać uporządkowane dane z wyników wyszukiwania PubMed oraz stron artykułów. Zbieraj popularne publikacje medyczne, dowody z badań klinicznych, streszczenia, autorów, afiliacje, daty publikacji i linki, a następnie eksportuj do Excel, Google Sheets, Airtable lub Notion.
Dowiedz się więcej ->Substack scraper
Pobierz liczbę subskrybentów Substack, tytuły artykułów i opisy publikacji do przejrzystego arkusza — bez kodu, AI zajmie się strukturą danych.
Dowiedz się więcej ->PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper umożliwia wyodrębnianie danych z wyników wyszukiwania i profili PeopleWhiz dzięki sugestiom pól wspieranym przez AI. Zbieraj imiona i nazwiska, dane kontaktowe, lokalizacje i nie tylko — do badań, marketingu lub pozyskiwania leadów. Szybko i sprawnie zamieniaj dane z PeopleWhiz w uporządkowane zbiory danych.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Dołącz do ponad 100 000 profesjonalistów, którzy już używają Thunderbit do automatyzacji procesów web scrapingu.
Bezpłatny okres próbny daje nielimitowane kredyty na 8 stron.