Substack scraper














Odblokuj dane Substack dzięki Thunderbit
Wysyłaj dane z Substack bezpośrednio do swoich aplikacji
Koniec z ręcznym kopiowaniem i wklejaniem szczegółów publikacji z Substack, takich jak nazwy autorów, tytuły artykułów i liczba subskrybentów. Z Thunderbit jednym kliknięciem wyślesz wyodrębnione dane prosto do Google Sheets, Notion lub Airtable — dzięki czemu możesz analizować trendy publikacji i skuteczność treści bez żmudnej pracy ręcznej.
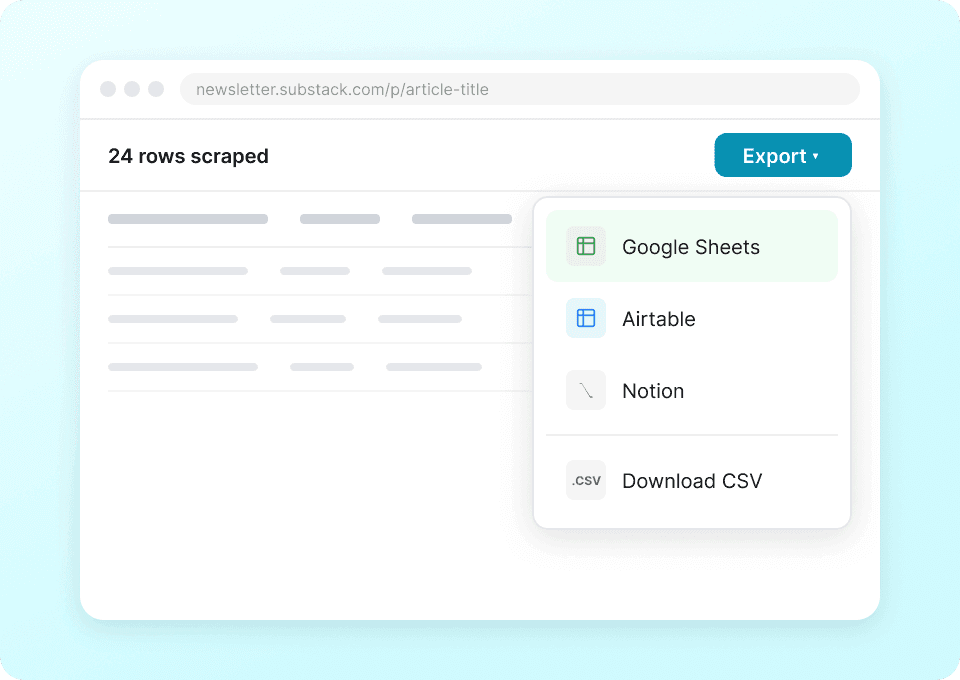
Jeden scraper do Substack i nie tylko
Nie musisz używać osobnego narzędzia dla każdej strony. Thunderbit działa na Substack od razu po instalacji i zawiera ponad 50 gotowych szablonów dla innych popularnych platform. Wyciągaj opisy publikacji, treści artykułów i więcej — a potem użyj tego samego narzędzia do pobierania danych z dowolnego innego miejsca w sieci.
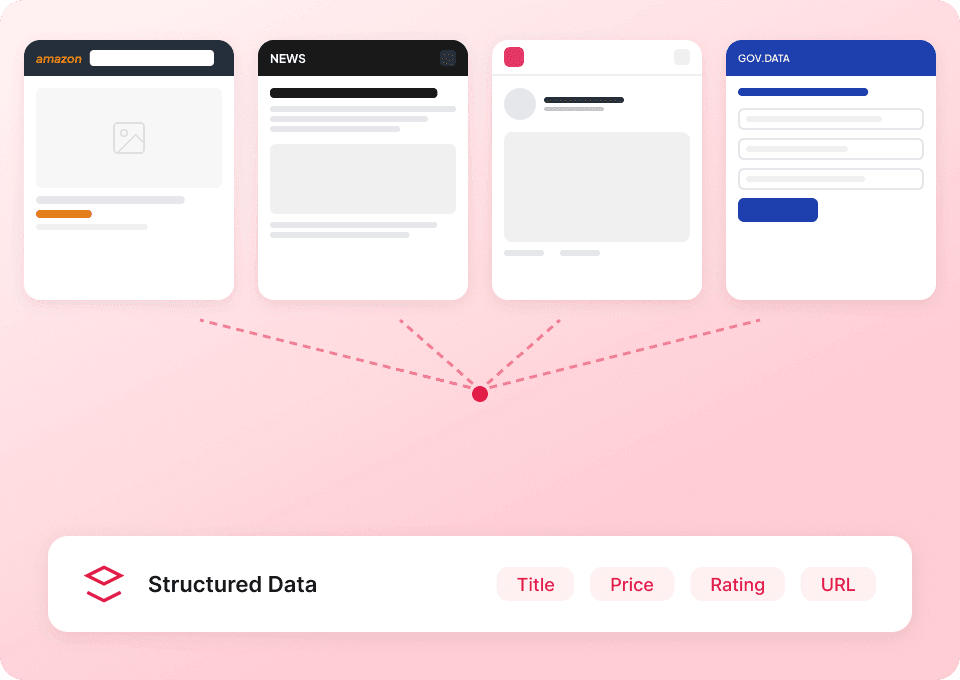
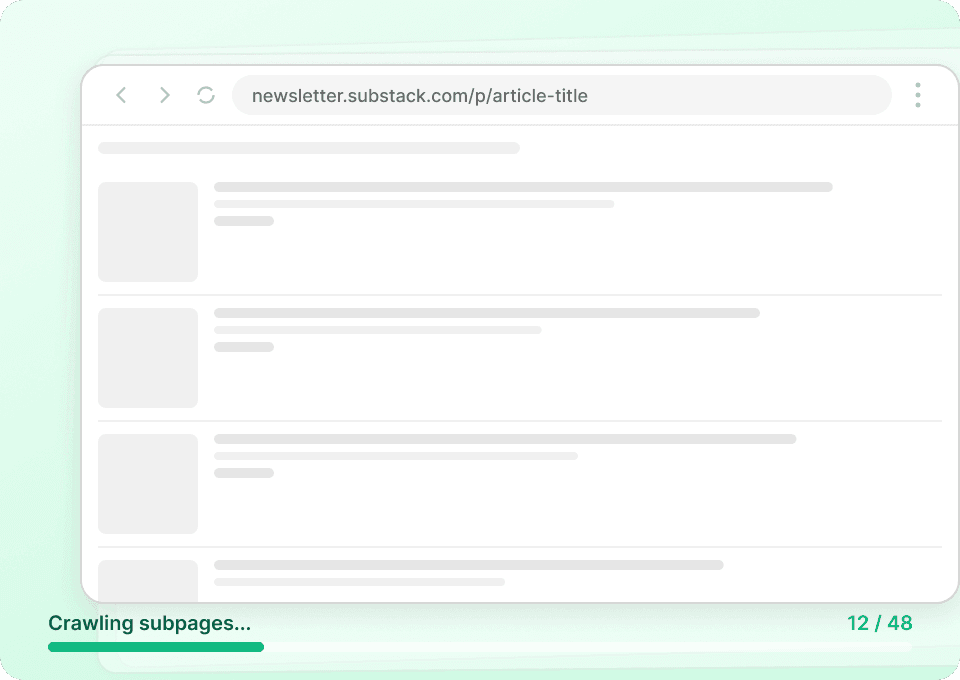
Poznaj pełny obraz Substack
Strony list publikacji w Substack pokazują tylko skróty. Thunderbit automatycznie odwiedza każdą podstronę artykułu, aby pobrać pełną treść i dostarczyć Ci kompletny zestaw danych w jednym przebiegu. Zbierz tytuły artykułów, nazwiska autorów, nazwy publikacji i pełny tekst wpisów — bez ręcznego otwierania choć jednej strony.
Masz problem z efektywnym scrapowaniem Substack?
Zobacz, dlaczego Thunderbit wypada lepiej niż tradycyjne scrapery w pracy z danymi Substack.
Tradycyjne scrapery
Stare podejście do tematuThunderbit
Sprytniejsze podejścieNie musisz wierzyć nam na słowo
Zobacz, co użytkownicy mówią o Thunderbit.




Najczęściej zadawane pytania
Powiązane zastosowania
Poznaj więcej zastosowań web scrapera Thunderbit.

Bez kodu: Spokeo Scraper
Wyciągnij pełne informacje z profilu Spokeo — imię i nazwisko, wiek, adres, numery telefonów i krewnych — w 2 kliknięciach, a potem wyeksportuj wszystko do Excela, Google Sheets lub Notion. Bez kodowania, bez kopiowania i wklejania.
Dowiedz się więcej ->
UNIQLO Scraper
Wyodrębnij nazwy produktów Uniqlo, ceny, kolory i rozmiary w 2 kliknięciach dzięki opartemu na AI rozszerzeniu Chrome od Thunderbit. Eksportuj dane bezpośrednio do Google Sheets, Excela lub Notion i zawsze miej aktualne informacje do analizy produktów.
Dowiedz się więcej ->
United Airlines scraper
W 2 kliknięcia wyciągnij numery lotów, godziny odlotu, lotniska przylotu i ceny z United Airlines — a potem od razu eksportuj dane do Excela, Arkuszy Google lub Notion. Resztą zajmie się Thunderbit AI.
Dowiedz się więcej ->PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper umożliwia wyodrębnianie danych z wyników wyszukiwania i profili PeopleWhiz dzięki sugestiom pól wspieranym przez AI. Zbieraj imiona i nazwiska, dane kontaktowe, lokalizacje i nie tylko — do badań, marketingu lub pozyskiwania leadów. Szybko i sprawnie zamieniaj dane z PeopleWhiz w uporządkowane zbiory danych.
Dowiedz się więcej ->
PlayStation Scraper
Wyodrębnij dane o grach PlayStation — tytuł, gatunek, cenę i oceny — w 2 kliknięciach, a następnie wyeksportuj je bezpośrednio do Excel, Google Sheets lub Notion. Koniec z ręcznym kopiowaniem i wklejaniem.
Dowiedz się więcej ->
Carousell scraper
Wyodrębniaj ogłoszenia z Carousell — tytuły, opisy, ceny i dane sprzedających — w 2 kliknięciach, a następnie eksportuj je bezpośrednio do Excela, Google Sheets lub Notion. Bez kodowania i bez skomplikowanej konfiguracji.
Dowiedz się więcej ->Gotowy, by przyspieszyć ekstrakcję danych?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Darmowy okres próbny daje nielimitowane kredyty dla 8 stron.



