

Pięć japońskich ustaw reguluje web scraping. Żadna z nich nie używa jednak dosłownie tego zwrotu.
Jeśli kiedykolwiek próbowałeś ustalić, czy Twój projekt scrapingowy jest legalny w Japonii, pewnie trafiłeś na ścianę niejasnych wpisów na forach, artykułów o trenowaniu AI i wzajemnie sprzecznych porad. Spędziłem tygodnie, przekopując się przez oficjalne japońskie ustawy, wytyczne rządowe, dane dotyczące egzekwowania prawa i komentarze prawne, żeby przygotować możliwie najjaśniejszy przewodnik po angielsku.
Niezależnie od tego, czy monitorujesz ceny konkurencji na Rakuten, pobierasz dane o nieruchomościach do analizy rynku, czy budujesz listę leadów B2B, ten artykuł przeprowadzi Cię przez wszystkie istotne przepisy — z praktycznymi tabelami, przykładami z życia i 10-punktową checklistą zgodności, z której możesz skorzystać, zanim zaczniesz pobierać dane.
Co właściwie oznacza pytanie „Czy web scraping jest legalny w Japonii”?
Web scraping — czyli używanie oprogramowania do automatycznego pobierania danych ze stron internetowych — nie jest ujęty w jednej konkretnej japońskiej ustawie. Żaden przepis nie mówi wprost: „scraping jest legalny” albo „scraping jest nielegalny”. To, czy Twój projekt jest zgodny z prawem, zależy od trzech rzeczy: co pobierasz, w jaki sposób uzyskujesz dostęp i co później robisz z danymi.
Pięć ustaw tworzy ten prawny układ:
| Ustawa | Co oznacza dla scraperów |
|---|---|
| Ustawa o prawie autorskim (Act No. 48 of 1970) | Chroni utwory twórcze, obrazy, teksty i struktury baz danych. Artykuł 30-4 przewiduje szerokie wyłączenie dla analizy danych. |
| APPI (Act on the Protection of Personal Information, Act No. 57 of 2003) | Reguluje zbieranie, używanie, udostępnianie i transgraniczne przekazywanie danych osobowych żyjących osób. |
| UCAL (Act on Prohibition of Unauthorized Computer Access, Act No. 128 of 1999) | Penalizuje obchodzenie uwierzytelniania i kontroli dostępu — japońskie prawo antyhakerskie. |
| UCPA (Unfair Competition Prevention Act, Act No. 47 of 1993) | Chroni tajemnice handlowe i „współdzielone dane o ograniczonym dostępie” przed bezprawnym pozyskaniem. |
| Kodeks karny (Act No. 45 of 1907) | Artykuły 233, 234 i 234-2 mogą mieć zastosowanie, gdy scraping zakłóca działanie strony internetowej. |
Dalsza część artykułu omawia każdą z tych ustaw z praktycznymi przykładami i oceną ryzyka. Chcesz od razu przejść do działań? Przeskocz do 10-punktowej checklisty zgodności.
Japońska ustawa o prawie autorskim i artykuł 30-4: wyłączenie dla analizy informacji
Japońska ustawa o prawie autorskim chroni utwory twórcze: artykuły, zdjęcia, opisy produktów, struktury baz danych o twórczym układzie. Gdy scraper pobiera stronę internetową, technicznie „reprodukuje” ten materiał na podstawie art. 21 — wyłącznego prawa autora do zwielokrotniania.
Ale właśnie tutaj Japonia się wyróżnia.
W 2018 roku Japonia wprowadziła szeroką nowelizację (weszła w życie 1 stycznia 2019 r.), dodając art. 30-4 — elastyczne wyłączenie z praw autorskich, które sprawia, że większość analitycznego web scrapingu jest legalna. Agency for Cultural Affairs określa to jako jeden z najbardziej liberalnych modeli na świecie dla analizy danych i rozwoju AI.
Większość anglojęzycznych artykułów przedstawia art. 30-4 tak, jakby dotyczył wyłącznie trenowania AI. To zbyt wąskie spojrzenie. Przepis wprost obejmuje „analizę informacji” — ekstrakcję, porównywanie, klasyfikację i inną analizę statystyczną danych. Innymi słowy: dokładnie to, co firmy scrapingowe robią na co dzień.
Co naprawdę mówi art. 30-4 (prostym językiem)
Art. 30-4 zezwala na korzystanie z utworu chronionego prawem autorskim „jeżeli celem nie jest osobiste czerpanie przyjemności ani umożliwianie innej osobie czerpania przyjemności z myśli lub uczuć wyrażonych w utworze”. W praktyce muszą być spełnione dwa warunki:
-
Test „czerpania przyjemności”. Jeśli wyciągasz dane faktograficzne — ceny, daty, metraż, stany magazynowe — zamiast konsumować lub ponownie publikować treści twórcze, jesteś po bezpiecznej stronie. Wytyczne ACA z 2024 r. dotyczące AI i praw autorskich potwierdzają, że zastosowania niepolegające na „czerpaniu przyjemności” obejmują analizę danych, klasyfikację i indeksowanie.
-
Test „niesłusznej szkody”. Twój scraping nie powinien zastępować oryginalnego utworu ani podcinać rynku właścicielowi praw autorskich. Na przykład pobieranie płatnego, gotowego do analizy zbioru danych tylko po to, by nie płacić za niego, może nie przejść tego testu, nawet jeśli cel jest analityczny.

Rzeczywiste scenariusze scrapingu w świetle art. 30-4
Tu teoria spotyka się z praktyką. Przepis ma zastosowanie znacznie szerzej niż tylko do trenowania AI:
| Przypadek użycia | Czy art. 30-4 ma zastosowanie? | Dlaczego |
|---|---|---|
| Scraping ofert nieruchomości do analizy cen rynkowych | ✅ Tak | Cena ofertowa, metraż i wiek budynku to dane faktograficzne służące analizie informacji, a nie czerpaniu przyjemności z ekspresji |
| Scraping danych giełdowych ze stron giełdy | ✅ Tak | Cel analizy statystycznej |
| Scraping obrazów produktów dla konkurencyjnego sklepu ecommerce | ❌ Nie | Wykorzystuje samą treść ekspresyjną |
| Scraping artykułów prasowych do ponownej publikacji | ❌ Nie | Zastępuje oryginalny utwór |
| Scraping opisów produktów do monitorowania cen | ✅ Najpewniej tak | Pobieranie danych faktograficznych, a nie czerpanie przyjemności z ekspresji |
| Budowa systemu RAG na podstawie zeskrobanych dokumentów | ⚠️ Mieszane | Wektoryzacja może nie służyć czerpaniu przyjemności, ale wyświetlanie chronionych fragmentów wymaga dalszej analizy |
Jeszcze jedna kwestia: art. 47-5 zapewnia węższą ochronę dla „drobnej eksploatacji” incydentalnej wobec komputerowego przetwarzania informacji — na przykład małych fragmentów lub miniaturek w wynikach wyszukiwania. Nie jest to główna bezpieczna przystań dla scrapingu, ale może wspierać kopie przygotowawcze potrzebne do usług wyszukiwania lub analizy. Komentarz ACA z 2019 r. ocenia „drobność” według proporcji, ilości i dokładności wyświetlania.
Wniosek: jeśli wyciągasz fakty do analizy, a nie ponownie publikujesz treści twórcze, japońskie ramy prawa autorskiego są po Twojej stronie.
Japońska ustawa o zakazie nieuprawnionego dostępu do komputerów (UCAL): kiedy scraping przekracza granicę
Prawie żaden anglojęzyczny artykuł o scrapingu nie wyjaśnia tej ustawy. To być może najważniejsza wyraźna granica w japońskim prawie.
Ustawa o zakazie nieuprawnionego dostępu do komputerów (不正アクセス禁止法, Act No. 128 of 1999) jest funkcjonalnym odpowiednikiem amerykańskiej CFAA. Kryminalizuje nieuprawniony dostęp do komputerów chronionych mechanizmami uwierzytelniania. Kary na podstawie art. 11 mogą sięgać do 3 lat pozbawienia wolności lub grzywny do ¥1,000,000.
UCAL nie zakazuje scrapingu publicznych stron internetowych. Ustawa wchodzi w grę dopiero wtedy, gdy obchodzisz uwierzytelnianie — panele logowania, hasła, tokeny dostępu lub podobne zabezpieczenia. Ta różnica jest kluczowa.
Poziomy ryzyka UCAL w typowych scenariuszach scrapingu
| Scenariusz | Poziom ryzyka UCAL | Wyjaśnienie |
|---|---|---|
| Scraping publicznych ofert produktów | ✅ Niskie | Brak obchodzenia uwierzytelniania |
| Scraping za logowaniem przy użyciu własnych danych | ⚠️ Średnie — zależy od ToS | UCAL może nie mieć zastosowania, jeśli dane logowania należą do Ciebie, ale ryzyko związane z ToS i umową pozostaje |
| Obchodzenie uwierzytelniania lub CAPTCHA w celu dostępu do danych | ❌ Wysokie — prawdopodobne naruszenie | Art. 2(4)(ii) obejmuje obchodzenie ograniczeń dostępu |
| Dostęp do ograniczonych API bez autoryzacji | ❌ Wysokie — prawdopodobne naruszenie | API z uwierzytelnianiem lub dostępne wyłącznie dla partnerów zdecydowanie podlegają UCAL |
| Używanie cudzych danych logowania lub tokenów sesji | ❌ Wysokie — prawdopodobne naruszenie | Art. 2(4)(i) bezpośrednio odnosi się do użycia cudzego kodu identyfikacyjnego |
Japońska Krajowa Agencja Policji podała 563 zakończone sprawy naruszeń UCAL w 2024 roku, co oznacza wzrost o 8,1% rok do roku. Z tego 511 spraw (90,8%) dotyczyło nieuprawnionego użycia cudzego kodu identyfikacyjnego. Egzekwowanie prawa koncentruje się głównie na nadużywaniu danych uwierzytelniających, a nie na zwykłym publicznym scrapingu.
Czym UCAL różni się od amerykańskiej CFAA
UCAL jest w istotny sposób węższa niż CFAA. Koncentruje się konkretnie na obchodzeniu uwierzytelniania, podczas gdy sformułowanie CFAA o „przekroczeniu autoryzowanego dostępu” było przez dziesięciolecia przedmiotem sporów w amerykańskich sądach. Po decyzji amerykańskiego Sądu Najwyższego w sprawie Van Buren samo naruszenie ToS strony internetowej rzadziej prowadzi do odpowiedzialności karnej na gruncie CFAA. Japonia dochodzi do podobnego praktycznego rezultatu: naruszenie ToS to kwestia umowna, a nie karna na gruncie UCAL, chyba że występuje niezależny element kontroli dostępu.
Nowelizacje APPI z 2022 roku: co scraperzy muszą wiedzieć o danych osobowych
Japońska Act on the Protection of Personal Information (APPI) jest podstawową ustawą o ochronie danych w kraju — a nowelizacje z 2022 roku znacząco zaostrzyły zasady. Jeśli scrapujesz imiona i nazwiska, e-maile, numery telefonów albo jakiekolwiek dane identyfikujące żyjącą osobę z japońskich stron internetowych, APPI ma zastosowanie.
Praktyczne pytanie brzmi: kiedy scraping uruchamia obowiązki zgodności z APPI?
Co jest „danymi osobowymi” w rozumieniu APPI
APPI art. 2 definiuje dane osobowe jako dane, które pozwalają zidentyfikować konkretną żyjącą osobę — także poprzez łatwe zestawienie z innymi informacjami. Wytyczne Q&A PPC potwierdzają, że służbowy adres e-mail w stylu firstname.lastname@company.jp może być danymi osobowymi, jeśli identyfikuje konkretną osobę, a identyfikatory cookie stają się danymi osobowymi, gdy zostaną połączone z innymi danymi umożliwiającymi identyfikację.
Nowelizacje z 2022 roku wprowadziły nową kategorię: „informacje związane z jednostką” — dane, które nie identyfikują bezpośrednio osoby, ale mogą to zrobić po połączeniu z innymi danymi (identyfikatory cookie, historia przeglądania, historia zakupów). Dlaczego ma to znaczenie przy scrapingu: dane, które dla scrapera wyglądają na anonimowe, mogą stać się identyfikowalne po połączeniu z CRM lub danymi adtech po stronie odbiorcy.
Ograniczenia dotyczące przekazywania danych za granicę
Jeśli scrapujesz japońskie strony spoza Japonii i zbierasz dane osobowe, APPI art. 28 wymaga analizy przed przekazaniem tych danych za granicę. Wytyczne PPC dotyczące transferu zagranicznego opisują trzy typowe ścieżki: odbiorca znajduje się w kraju uznanym przez PPC za równorzędny, odbiorca wdrożył równoważne środki ochrony albo ma zastosowanie wyjątek z art. 27 ust. 1.
Jeśli firma z USA, UE lub Singapuru scrapuje dane osobowe z japońskich stron i przechowuje je poza Japonią, potrzebna jest analiza transferu zagranicznego na gruncie APPI. To często zaskakuje zespoły międzynarodowe.
Wyłączenie opt-out przy udostępnianiu stronom trzecim (art. 27)
Najczęstsze pytanie na forum: „Co się stanie, jeśli udostępnię lub sprzedam zeskrobane dane z japońskich stron?”
APPI art. 27 zasadniczo wymaga uprzedniej zgody na przekazanie danych osobowych stronom trzecim. Istnieje formalny mechanizm opt-out — ale wymaga złożenia zgłoszenia do Personal Information Protection Commission, poinformowania osób, których dane dotyczą, oraz zapewnienia im sposobu zablokowania przekazywania stronom trzecim. Nowelizacje z 2022 roku jeszcze to zawęziły: z mechanizmu opt-out nie można korzystać w przypadku danych osobowych pozyskanych w sposób bezprawny ani otrzymanych od innego przedsiębiorcy w ramach opt-out.
Roczny raport PPC za rok fiskalny 2024 pokazuje 405 łącznie zaakceptowanych zgłoszeń opt-out od października 2021 r., w tym 93 w FY2024. System istnieje, ale jest formalny, nie swobodny.
Kiedy scraping nie uruchamia APPI
APPI nie ma zastosowania do danych, które nie pozwalają zidentyfikować żyjącej osoby. Pola o niższym ryzyku APPI obejmują:
- Ceny produktów, SKU, stany magazynowe i koszty wysyłki
- Godziny otwarcia sklepów i ogólne dane kontaktowe firmy (info@company.jp)
- Ceny ofert nieruchomości, metraż, wiek budynku i odległość od stacji — jeśli nie są powiązane z imiennie wskazanymi właścicielami lub agentami
- Zagregowane statystyki rynkowe, z których usunięto identyfikację pojedynczych osób
Warto wspomnieć o praktycznym wyborze projektowym: funkcja Thunderbit AI Suggest Fields pozwala użytkownikom dokładnie zdefiniować, które kolumny danych mają zostać pobrane. Możesz świadomie wykluczyć pola z danymi osobowymi i skupić się wyłącznie na potrzebnych danych biznesowych — ograniczając ekspozycję na APPI z założenia, a nie przez przypadek.
Ustawa o zwalczaniu nieuczciwej konkurencji (UCPA): scraping danych konkurencji
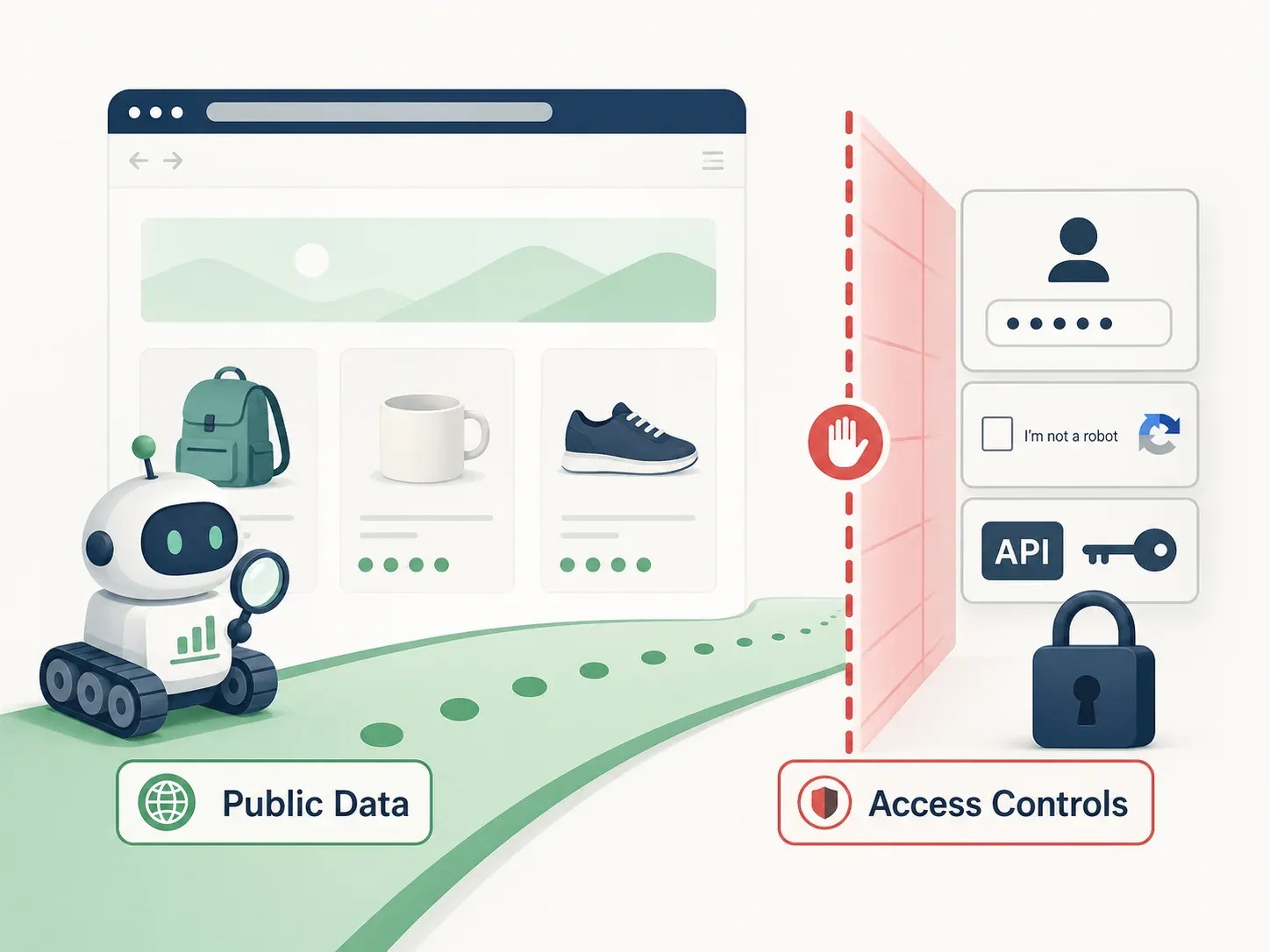
Ustawa o zwalczaniu nieuczciwej konkurencji wkracza do gry, gdy scraping wychodzi poza publiczne fakty i wchodzi w obszar poufnych informacji biznesowych lub chronionych zbiorów danych.
UCPA definiuje tajemnicę handlową jako informację, która (1) jest zarządzana jako tajna, (2) jest przydatna biznesowo i (3) nie jest powszechnie znana. METI podsumowuje to jako trzy wymagania dla ochrony tajemnicy handlowej.
Fakty z publicznych stron internetowych — ceny produktów, lokalizacje sklepów, ogłoszenia o pracę, katalogi produktów — zazwyczaj nie są tajemnicą handlową, ponieważ nie są tajne i są publicznie znane. Ich scraping zwykle nie narusza UCPA.
Kiedy UCPA może mieć zastosowanie do scrapingu
| Scenariusz | Ryzyko UCPA | Dlaczego |
|---|---|---|
| Scraping publicznego katalogu produktów konkurenta do monitorowania cen | Zwykle niskie | Fakty z publicznego katalogu zasadniczo nie są tajne |
| Scraping wewnętrznych danych cenowych poprzez wykorzystanie luki w API | Wysokie | Niepubliczne, przydatne biznesowo informacje pozyskane w bezprawny sposób |
| Scraping płatnej bazy tylko dla partnerów lub licencjonowanego API poza zakresem | Wysokie | Nowelizacje UCPA z 2018 roku chronią „współdzielone dane o ograniczonym dostępie” |
| Wykorzystanie zeskrobanych danych do stworzenia konkurencyjnego produktu, który jedzie na kosztownej bazie danych | Szara strefa | Sądy mogą oceniać ograniczenia dostępu, inwestycje i substytucję |
Nowelizacja UCPA z 2018 roku dodała ochronę dla „współdzielonych danych o ograniczonym dostępie” — informacji technicznych lub biznesowych zgromadzonych w istotnym stopniu, zarządzanych elektronicznie i regularnie udostępnianych określonym osobom. Jednak UCPA art. 19 wyłącza dane, które są zasadniczo takie same jak informacje udostępnione publicznie bez wynagrodzenia. Zatem darmowa publiczna oferta produktu to coś innego niż komercyjny zbiór danych dostępny tylko dla członków.
Przeciążenie serwera i japoński kodeks karny: nie doprowadzaj do awarii strony
Same dane mogą być całkowicie legalne do zbierania. Ale sposób, w jaki je pobierasz, może stworzyć ryzyko karne. Japoński kodeks karny zawiera przepisy o zakłócaniu działalności gospodarczej, które uruchamiają się, gdy automatyczny dostęp zakłóca działanie strony internetowej lub systemu biznesowego.
| Artykuł kodeksu karnego | Zachowanie | Kara |
|---|---|---|
| Artykuł 233 | Zakłócanie działalności poprzez oszustwo | Do 3 lat lub ¥500,000 |
| Artykuł 234 | Przymusowe zakłócanie działalności | Taka sama jak w art. 233 |
| Artykuł 234-2 | Zakłócanie przez uszkodzenie / ingerencję w komputer | Do 5 lat lub ¥1,000,000 |
Każda japońska dyskusja o scrapingu ostatecznie trafia na incydent w Centralnej Bibliotece Miejskiej Okazaki (ok. 2010 r.). Inżynier oprogramowania stworzył crawler do zbierania informacji o nowych książkach ze strony biblioteki, generując około 33 000 automatycznych wejść w ciągu dwóch tygodni. Serwer biblioteki stał się trudny w użyciu, a policja aresztowała użytkownika pod zarzutem zakłócania działalności. Sprawa zakończyła się bez merytorycznego wyroku, ale nadal jest mocnym przypomnieniem, że wpływ na serwer ma znaczenie — nawet wtedy, gdy same dane są publiczne.
Dla kontekstu, dlaczego operatorzy stron eskalują takie sprawy: Thales/Imperva podał, że zautomatyzowane boty stanowiły 51% ruchu internetowego w 2024 roku, a zły ruch botów — 37%. Akamai ustalił, że boty odpowiadały za 42% całego ruchu webowego, szczególnie mocno dotykając ecommerce.
Jak unikać problemów z przeciążeniem serwera
- Przestrzegaj robots.txt (nawet jeśli to nie ustawa, jest to dowód intencji operatora)
- Dodawaj opóźnienia między żądaniami i ograniczaj współbieżność
- Unikaj godzin szczytu dla docelowej witryny
- Zatrzymuj lub ograniczaj ruch, gdy widzisz błędy, blokady lub odpowiedzi o limitach
- Buforuj wcześniej pobrane strony zamiast wielokrotnie uderzać w te same adresy URL
Funkcja cloud scraping w Thunderbit rozdziela żądania między wiele serwerów, co naturalnie rozkłada obciążenie i zmniejsza ryzyko przeciążenia pojedynczego serwera docelowego. To nie jest tarcza prawna, ale praktyczny wybór projektowy zgodny z odpowiedzialnym scrapingiem.
Naruszenia warunków korzystania: ryzyko umowne, nie karne
Wiele japońskich stron internetowych zawiera Warunki korzystania, które zakazują scrapingu lub automatycznego zbierania danych. Zgodnie z japońskim prawem naruszenie ToS to kwestia umowna — nie przestępstwo.
Wytyczne interpretacyjne METI dotyczące handlu elektronicznego wyjaśniają, że warunki strony są wiążące, gdy zostały prawidłowo włączone do umowy transakcyjnej. Najmocniejsze są umowy click-wrap, gdzie trzeba kliknąć „Zgadzam się”. Warunki ukryte w trudno zauważalnych linkach w stopce są słabsze.
| Konstrukcja ToS | Sygnał egzekwowalności |
|---|---|
| Jasny click-wrap z wymaganym przyciskiem „Zgadzam się” | Najmocniejszy |
| Warunki podlinkowane w pobliżu transakcji, ale bez kliknięcia zgody | Bardziej niepewne |
| Warunki ukryte w stopce lub trudno dostępne | Słabszy |
| Brak relacji umownej z operatorem | Roszczenie umowne może być słabe |
Nie znaleziono wiarygodnego źródła potwierdzającego, że samo naruszenie ToS, bez dodatkowych okoliczności, staje się w Japonii zarzutem karnym. Praktyczne stanowisko brzmi: naruszenie ToS może tworzyć cywilne ryzyko umowne (odszkodowanie, nakaz sądowy), ale odpowiedzialność karna zwykle wymaga niezależnego elementu — obejścia kontroli dostępu na gruncie UCAL, zakłócania działalności na gruncie kodeksu karnego albo naruszenia praw autorskich.
Moja rada: przeczytaj ToS przed scrapingiem jakiejkolwiek japońskiej strony. Jeśli wyraźnie zakazuje scrapingu, poszukaj alternatyw — API, partnerstwa danych albo innego źródła tych samych informacji.
Japonia vs. USA vs. UE: jak wypadają przepisy o web scrapingu
Jeśli masz doświadczenie prawne z USA lub UE, ta tabela pomoże Ci się zorientować. Japońskie ramy są w niektórych obszarach bardziej liberalne, a w innych bardziej restrykcyjne.
| Wymiar prawny | Japonia | Stany Zjednoczone | UE |
|---|---|---|---|
| Główna ustawa o scrapingu | Brak jednej ustawy; patchwork: ustawa o prawie autorskim, APPI, UCPA, UCAL, kodeks karny | CFAA, prawo stanowe | RODO, dyrektywa bazodanowa, dyrektywa DSM |
| Wyjątek prawnoautorski dla analizy danych | Art. 30-4 (szeroki) | Fair use (indywidualnie) | Wyjątek TDM (art. 3-4 dyrektywy DSM) — z opt-out dla komercyjnego TDM |
| Scraping danych osobowych | APPI — opt-out przy udostępnianiu stronom trzecim (art. 27) | Zależy od stanu (CCPA itd.) | RODO — ścisła zgoda / uzasadniony interes |
| Obejście kontroli dostępu | UCAL — czyn karalny | CFAA — odpowiedzialność karna i cywilna | Zależy od państwa członkowskiego |
| Naruszenie ToS = nielegalne? | Tylko prawo umowne; nie znaleziono odpowiedzialności karnej | CFAA po Van Buren: prawdopodobnie nie | Zależy; RODO może nadal mieć zastosowanie |
| Ryzyko przeciążenia serwera | Kodeks karny art. 233, 234-2 (zakłócanie działalności) | CFAA + tortious interference | Zależy |
Najważniejsze wnioski z porównania
Artykuł 30-4 w Japonii jest szerszy niż amerykański fair use czy wyjątki TDM w UE — co czyni Japonię jednym z bardziej przyjaznych krajów dla analitycznego scrapingu z perspektywy prawa autorskiego. UCAL jest węższa niż CFAA, ponieważ koncentruje się wyłącznie na obchodzeniu uwierzytelniania. Zasady APPI dotyczące transferu danych za granicę są bardziej restrykcyjne niż rozdrobnione amerykańskie ramy prywatności, ale w niektórych operacyjnych detalach mniej szczegółowe niż RODO.
Dla zespołów międzynarodowych: możesz mieć większą swobodę scrapowania publicznych danych japońskich do analizy, niż Ci się wydaje. To właśnie przetwarzanie danych osobowych stanowi największe wyzwanie — zwłaszcza przy transferach transgranicznych i udostępnianiu stronom trzecim.
Twoja 10-punktowa checklista zgodności dla scrapingu japońskich stron internetowych
Zanim zaczniesz scrapować jakąkolwiek japońską stronę, przejdź przez te dziesięć pytań tak/nie. Każde z nich odnosi się do jednej z pięciu ustaw powyżej.
- Czy dane są publicznie dostępne? (Brak logowania, brak paywalla, brak obchodzenia kontroli dostępu) → Jeśli tak, ryzyko UCAL jest niskie.
- Czy ToS strony zabrania scrapingu? → Jeśli tak, oceń ryzyko umowne; rozważ alternatywne źródła danych.
- Czy zbierasz dane osobowe zdefiniowane przez APPI? (Imiona, e-maile, numery telefonów, identyfikatory) → Jeśli tak, zapewnij zgodność z APPI.
- Czy planujesz przekazać zeskrobane dane osobowe poza Japonię? → Jeśli tak, przestrzegaj zasad transgranicznego transferu z art. 28 APPI.
- Czy planujesz udostępniać lub sprzedawać zeskrobane dane stronom trzecim? → Jeśli tak, zastosuj procedury opt-out z art. 27 APPI albo uzyskaj zgodę.
- Czy dane są chronione prawem autorskim? → Jeśli scraping służy analizie informacji (a nie ponownej publikacji treści twórczych), art. 30-4 prawdopodobnie ma zastosowanie.
- Czy Twoje działania scrapingowe zastąpią oryginalny utwór? → Jeśli tak, ochrona z art. 30-4 prawdopodobnie nie ma zastosowania.
- Czy obchodzisz jakiekolwiek uwierzytelnianie, CAPTCHA lub kontrolę dostępu? → Jeśli tak, wysokie ryzyko UCAL — nie działaj bez porady prawnej.
- Czy skala scrapingu grozi przeciążeniem serwera? → Jeśli tak, ograniczaj żądania, dodawaj opóźnienia, używaj scrapingu rozproszonego.
- Czy docelowe dane są zarządzane przez firmę jako tajemnica handlowa? → Jeśli to niepubliczne, zastrzeżone dane, UCPA może mieć zastosowanie.
Jeśli każda odpowiedź wskazuje na publiczne, faktograficzne, nieosobowe, ograniczone i niepowielające treści do analizy — jesteś w dobrej sytuacji. Każdy sygnał ostrzegawczy powinien uruchomić przegląd prawny, zanim zaczniesz.

Jak Thunderbit pomaga zgodnie scrapować japońskie strony
Chcę być szczery: Thunderbit to narzędzie, a nie porada prawna. Ale zostało zaprojektowane w sposób, który wspiera zasady zgodności opisane powyżej.
- AI Suggest Fields: AI w Thunderbit czyta stronę i podpowiada dokładnie, które kolumny danych pobrać. Pomaga to świadomie definiować wyłącznie potrzebne nieosobowe pola danych — ograniczając zbieranie niepotrzebnych danych osobowych z założenia, a nie przez przypadek.
- Cloud Scraping: Rozdziela żądania między wiele serwerów, naturalnie rozkładając obciążenie i zmniejszając ryzyko przeciążenia pojedynczego japońskiego serwera. (Potraktuj to jako wbudowaną przyjazność dla limitów zapytań.)
- Darmowe ekstraktory e-maili i numerów telefonów: Kiedy naprawdę musisz zebrać dane kontaktowe z japońskich stron, ekstraktor e-maili Thunderbit i ekstraktor numerów telefonów zapewniają ekstrakcję jednym kliknięciem. Ale połącz to z wytycznymi APPI powyżej — zbieranie danych osobowych wymaga zrozumienia obowiązków zgodności.
- Eksport do Excela, Google Sheets, Airtable lub Notion: Zeskrobane dane można od razu uporządkować i wyeksportować do analizy, wspierając cel „analizy informacji”, który chroni art. 30-4.
- Brak konieczności utrzymania: AI Thunderbit odczytuje witrynę na nowo za każdym razem, dostosowując się do zmian układu. Oznacza to brak uszkodzonych scraperów, które wielokrotnie bombardują serwer nieudanymi żądaniami — praktyczny sposób na uniknięcie problemów z obciążeniem serwera, które doprowadziły do incydentu w bibliotece Okazaki.
Aby zobaczyć, jak korzystać z Thunderbit w praktyce, sprawdź nasz kanał YouTube lub przewodnik szybkiego startu. Możesz wypróbować za darmo przez rozszerzenie Chrome.
Wypróbuj Thunderbit do scrapingu japońskich stron
Praktyczne przykłady zastosowań
| Przypadek użycia | Polecane pola do pobrania | Uzasadnienie prawne |
|---|---|---|
| Monitorowanie cen w japońskim ecommerce | Nazwa produktu, cena ofertowa, dostępność, sprzedawca, SKU, URL, znacznik czasu | Faktograficzne dane biznesowe; analiza informacji na gruncie art. 30-4; unikaj kopiowania obrazów produktów lub recenzji do ponownej publikacji |
| Analiza japońskiego rynku nieruchomości | Cena ofertowa, lokalizacja, metraż, wiek budynku, typ nieruchomości, najbliższa stacja, URL, znacznik czasu | Wspiera zbiorczą analizę rynku; wyklucz nazwiska agentów, numery telefonów i nazwiska właścicieli, chyba że zapewniona jest zgodność z APPI |
| Monitorowanie operacji B2B | Nazwa firmy, adres oddziału, ogólny adres e-mail firmy, godziny otwarcia, kategoria usług | Niższe ryzyko APPI, jeśli nie identyfikuje się żyjącej osoby; sprawdź ToS i limity zapytań |
Najważniejsze wnioski dotyczące legalności scrapingu w Japonii
Web scraping jest w Japonii legalny w większości przypadków — zwłaszcza gdy pobierasz publicznie dostępne, nieosobowe, faktograficzne dane do celów analitycznych. Ale „w większości przypadków” nie znaczy „we wszystkich”.
- Ustawa o prawie autorskim (art. 30-4): analityczny scraping danych publicznych jest dozwolony; ponowna publikacja treści twórczych — nie.
- UCAL: nie obchodź uwierzytelniania ani kontroli dostępu.
- APPI: ostrożnie traktuj dane osobowe, zwłaszcza przy transferach transgranicznych i udostępnianiu stronom trzecim.
- UCPA: dane publiczne zwykle nie są tajemnicą handlową; dane chronione lub płatne są bardziej ryzykowne.
- Kodeks karny: nie doprowadzaj do awarii serwera.
Przed rozpoczęciem każdego projektu scrapingowego skorzystaj z 10-punktowej listy kontrolnej. W razie wątpliwości skonsultuj się z prawnikiem — zwłaszcza przy projektach obejmujących dane osobowe lub treści z ograniczonym dostępem.
Jeśli chcesz zacząć scrapować japońskie strony zgodnie z prawem, Thunderbit został stworzony po to, by uprościć ten proces osobom nietechnicznym. Zdefiniuj pola, pobierz dane, wyeksportuj je do ulubionego narzędzia i skup się na analizie.
Wypróbuj AI Web Scraper do japońskich stron Get Started Free
FAQ
Czy scraping publicznych stron internetowych w Japonii jest legalny?
Zasadniczo tak. Scraping publicznie dostępnych danych do analizy informacji jest zwykle legalny na gruncie art. 30-4 japońskiej ustawy o prawie autorskim, pod warunkiem że nie przeciążasz serwera, nie obchodzisz kontroli dostępu, nie zbierasz danych osobowych bez zgodności z APPI ani nie publikujesz ponownie chronionej ekspresji. Decydujący jest cel: analiza, a nie ponowna publikacja.
Czy mogę scrapować dane osobowe (e-maile, numery telefonów) z japońskich stron?
Możesz, ale wtedy ma zastosowanie APPI. Potrzebujesz zgodnego z prawem celu, musisz ujawnić, jak zamierzasz używać danych, i podlegasz ograniczeniom dotyczącym transferów zagranicznych oraz udostępniania stronom trzecim. Nowelizacje z 2022 roku znacząco zaostrzyły te zasady — zwłaszcza w przypadku danych opuszczających Japonię lub udostępnianych innym firmom.
Co się stanie, jeśli ToS japońskiej strony zabrania scrapingu?
Naruszenie ToS to kwestia umowna (potencjalna odpowiedzialność cywilna za odszkodowanie lub nakaz sądowy), a nie przestępstwo. Może jednak wspierać szersze roszczenia prawne i zaostrzać egzekwowanie. Zawsze czytaj ToS przed scrapingiem i rozważ, czy dane są dostępne w inny sposób.
Czy scraping za loginem jest legalny w Japonii?
Korzystanie z własnych danych logowania to szara strefa — UCAL może nie mieć bezpośredniego zastosowania, ale ryzyko naruszenia ToS i ryzyko umowne pozostają. Obejście uwierzytelniania, użycie cudzych danych logowania lub obchodzenie kontroli dostępu to najpewniej przestępstwo na gruncie ustawy o zakazie nieuprawnionego dostępu do komputerów, z karą do 3 lat więzienia lub ¥1,000,000.
Czy mogę sprzedać dane zeskrobane z japońskich stron?
Jeśli dane zawierają informacje osobowe, musisz stosować system opt-out przy udostępnianiu stronom trzecim z art. 27 APPI — co wymaga formalnego zgłoszenia do PPC, powiadomienia osób fizycznych i mechanizmów opt-out. Sprzedaż danych osobowych bez właściwych procedur to naruszenie zgodności. W przypadku nieosobowych, faktograficznych agregatów ryzyko APPI jest mniejsze, ale nadal mają zastosowanie prawa autorskie, UCPA, ToS i prawne implikacje web scrapingu.
Dowiedz się więcej




