

Czy web scraping jest nielegalny? To pytanie za milion dolarów, które co tydzień słyszę od founderów, marketerów i fanów danych.
Gdy 51% całego ruchu internetowego pochodzi dziś od botów — po raz pierwszy w historii ruch automatyczny wyprzedził aktywność ludzi — a ogromna jego część służy do web scrapingu na potrzeby analityki biznesowej, sprzedaży i trenowania AI, nic dziwnego, że wszyscy próbują ustalić, gdzie przebiegają granice prawa.
Jednego dnia widzisz nagłówek o wyroku, z którego wynika, że pobieranie publicznych danych jest dozwolone. Następnego regulatorzy ostrzegają przed „nielegalnym” pozyskiwaniem danych z mediów społecznościowych. To mylące nawet dla osób takich jak ja, które codziennie pracują nad narzędziami do AI web scrapingu w Thunderbit.
Więc czy web scraping jest nielegalny? Odpowiedź nie brzmi po prostu tak albo nie. Zależy od tego, co scrapujesz, skąd pobierasz dane, jak ich używasz i co mówi prawo w Twoim kraju.
W tym pogłębionym omówieniu rozłożę na czynniki pierwsze krajobraz prawny, obalę kilka popularnych mitów i podzielę się praktycznymi wskazówkami (oraz kilkoma historiami z pola walki), które pomogą działać zgodnie z przepisami — niezależnie od tego, czy jesteś solo founderem, czy częścią zespołu danych w Fortune 500.
Web scraping a prawo: czy istnieje wyraźna granica?
Jeśli liczysz na odpowiedź w jednym zdaniu, zaoszczędzę Ci czasu: prawo nie wyznaczyło dla web scrapingu ostrej, jednoznacznej granicy.
Zamiast tego mamy mozaikę nakładających się reguł — własność danych, prywatność, własność intelektualna, przepisy antyhakerskie i słynne Warunki korzystania z usługi (ToS). Każdy z tych obszarów może mieć znaczenie, a odpowiedź często zależy od konkretnej sytuacji (multilogin.com).
Rozbijmy to na trzy główne koszyki prawne:
- Własność danych: Zasadniczo fakty i publiczne informacje (np. ceny czy numery telefonów) nie podlegają prawu autorskiemu. Ale treści kreatywne (artykuły, obrazy) oraz zastrzeżone bazy danych mogą być chronione — zwłaszcza w UE, gdzie istnieją prawa do baz danych (cliffordchance.com).
- Prywatność: Nowoczesne przepisy o prywatności (np. RODO w Europie, PIPL w Chinach) traktują dane osobowe jako regulowany zasób — nawet jeśli zostały opublikowane publicznie. Scrapowanie imion, e-maili czy profili społecznościowych bez podstawy prawnej może skończyć się kłopotami (ico.org.uk).
- Umowy (Warunki korzystania z usługi): Wiele serwisów wprost zabrania scrapingu w swoich ToS. Choć ToS nie są ustawą, sąd może traktować je jak wiążącą umowę. Ich naruszenie może oznaczać pozwy, a w niektórych przypadkach nawet uruchomić przepisy antyhakerskie, jeśli ominiesz zabezpieczenia techniczne (cliffordchance.com).
Więc czy web scraping jest nielegalny? Czasem tak, czasem nie, a najczęściej: „to zależy”. Diabeł tkwi w szczegółach.
Porównanie podejścia prawnego: USA, UE, Wielka Brytania, Chiny
Oto krótka tabela pokazująca, jak główne regiony podchodzą do web scrapingu:
| Region | Scraping danych publicznych | Scraping danych osobowych/prywatnych | Egzekwowanie i ważne uwagi |
|---|---|---|---|
| USA | Zasadniczo dozwolone w przypadku danych publicznych (zob. hiQ v. LinkedIn). Naruszenie ToS może prowadzić do pozwów cywilnych. | Ograniczone/nielegalne, jeśli omijasz logowanie lub niewłaściwie używasz danych osobowych. Mogą mieć zastosowanie przepisy stanowe (np. CCPA). | Wezwania do zaprzestania, blokady IP, pozwy. CFAA ma zastosowanie przy omijaniu barier technicznych. |
| UE | Warunkowo dozwolone dla publicznych danych nieosobowych. Mogą mieć zastosowanie prawa do baz danych. Akt UE o AI (2026) dodaje wymogi przejrzystości dla danych treningowych AI. | Silnie regulowane przez RODO — nawet publiczne dane osobowe wymagają podstawy prawnej. | Organy ochrony danych mogą nakładać kary za naruszenia prywatności. Egzekwowane są też prawa autorskie i prawa do baz danych. Akt UE o AI zakazuje scrapingu zdjęć twarzy do AI. |
| Wielka Brytania | Podobnie jak w UE. Publiczne, nieosobowe dane można scrapować, ale trzeba respektować prawa do danych i umowy. | Surowe podejście do danych osobowych — obowiązuje UK GDPR. Computer Misuse Act kryminalizuje nieautoryzowany dostęp. | ICO może nakładać kary za naruszenia ochrony danych. Sądy mogą egzekwować ToS. |
| Chiny | Ściśle kontrolowane. Publiczne, nieosobowe dane mogą być scrapowane do użytku wewnętrznego, ale otoczenie prawne jest ostrożne. | Bardzo ograniczone — PIPL wymaga zgody na dane osobowe. Obowiązują przepisy o nieuczciwej konkurencji. | Sprawy karne przy scrapingu na dużą skalę. Sądy używają prawa o nieuczciwej konkurencji, by zatrzymać nieautoryzowany scraping. |
Czy web scraping jest nielegalny? Najważniejsze czynniki prawne
Co więc tak naprawdę decyduje o tym, czy Twój projekt scrapingu jest legalny czy ryzykowny? Oto najważniejsze czynniki:
- Dane publiczne vs. prywatne: Pobieranie danych, które każdy może zobaczyć w otwartej sieci, jest zazwyczaj bezpieczniejsze. A co z danymi za logowaniem, paywallem albo barierą techniczną? To najpewniej nielegalne (thunderbit.com).
- Rodzaj danych: Dane osobowe (imiona, e-maile, profile) uruchamiają przepisy o prywatności. Treści chronione prawem autorskim (artykuły, obrazy) nie mogą być kopiowane w całości. Czyste fakty (ceny, pogoda) zwykle są do wzięcia (oxylabs.io).
- Planowane użycie: Analiza wewnętrzna albo badania są traktowane łagodniej niż ponowne publikowanie lub sprzedaż zebranych danych. Wykorzystanie scrapowanych danych do bezpośredniej konkurencji wobec źródła? To proszenie się o pozew (thunderbit.com).
- Zgodność z zasadami serwisu: Zawsze sprawdzaj robots.txt i ToS. Robots.txt nie jest prawnie wiążący, ale najlepiej go respektować. Naruszenie ToS może prowadzić do pozwów cywilnych lub czegoś gorszego (promptcloud.com).
- Środki techniczne: Kluczowe jest scrapowanie z prędkością zbliżoną do ludzkiej i nieomijanie zabezpieczeń. Zasypywanie serwera żądaniami albo obchodzenie CAPTCHA może wejść w obszar hackingu (cliffordchance.com).
Co zmieniło się w latach 2024–2026: kluczowe wyroki i regulacje
Krajobraz prawny web scrapingu zmienił się znacząco od 2023 roku. Oto najważniejsze wydarzenia, które każdy scraper powinien znać:
Najważniejsze wyroki sądowe
-
Meta v. Bright Data (2024): Sąd federalny w USA orzekł, że Warunki korzystania z usługi Meta nie zakazują scrapingu danych publicznych przez użytkowników niezalogowanych. Sędzia uznał, że „odwiedzający nie jest uznawany za »użytkownika«, dopóki nie ma konta”. Meta wkrótce potem wycofała pozostałe roszczenia. To przełomowe zwycięstwo dla scrapingu danych publicznych.
-
X Corp v. Bright Data (2024): Twitter (obecnie X) przegrał podobną sprawę, co potwierdziło tę samą zasadę: scraping publicznie dostępnych danych bez logowania nie narusza ToS, ponieważ scraper nigdy nie zaakceptował tych warunków.
-
Reddit v. Perplexity AI (październik 2025): Reddit pozwał Perplexity AI i kilku dostawców scrapingu, powołując się na DMCA i zarzucając obchodzenie systemów antybotowych. To sygnał nowej strategii prawnej: platformy coraz częściej sięgają po roszczenia z prawa autorskiego i zakazu obchodzenia zabezpieczeń zamiast CFAA.
-
NYT v. OpenAI (marzec 2025): Sędzia federalny pozwolił sprawie The New York Times przeciwko OpenAI o prawa autorskie toczyć się dalej, odrzucając wniosek OpenAI o oddalenie pozwu. Może to ustanowić ważny precedens dotyczący tego, czy scrapowanie treści do trenowania modeli AI mieści się w ramach „dozwolonego użytku”.
-
Ugoda Anthropic (wrzesień 2025): Anthropic zgodziło się zapłacić 1,5 mld USD, by zakończyć w USA pozew zbiorowy dotyczący użycia chronionych prawem autorskim tekstów do trenowania swojego modelu AI — to pokazuje, że koszty scrapingu dla AI są bardzo realne.
Główny trend: od CFAA do prawa umów i prawa autorskiego
Wzór jest wyraźny: CFAA (Computer Fraud and Abuse Act) traci skuteczność jako broń przeciwko scraperom danych publicznych. Firmy, które próbowały używać CFAA przeciwko scrapingowi danych publicznych — Meta, X, LinkedIn — w dużej mierze przegrywały. Pole prawnej walki przesuwa się więc na:
- prawo umów (naruszenia ToS — choć sądy mówią, że osoby niebędące użytkownikami nie są związane ToS)
- roszczenia z prawa autorskiego (zwłaszcza przy danych do trenowania AI)
- przepisy zakazujące obchodzenia zabezpieczeń (DMCA Section 1201)
Dla scraperów oznacza to, że ryzyko prawne nie zniknęło — po prostu zmieniło miejsce.
Zmiany regulacyjne
- Aktualizacje CCPA 2026: Zmienione przepisy CCPA w Kalifornii weszły w życie 1 stycznia 2026, wprowadzając nowe zasady dotyczące technologii automatycznego podejmowania decyzji (ADMT), ocen ryzyka i obowiązków brokerów danych.
- Nowe stanowe przepisy o prywatności w USA: Indiana, Kentucky i Rhode Island uchwaliły kompleksowe ustawy o prywatności obowiązujące od 2026 roku.
- Akt UE o AI: Pełne egzekwowanie zaczyna się 2 sierpnia 2026 — wymagając ujawniania źródeł danych treningowych, respektowania rezygnacji z wykorzystania utworów chronionych prawem autorskim oraz zakazując scrapingu zdjęć twarzy do systemów AI.
- AI Accountability for Publishers Act (luty 2026): Proponowana ustawa USA, która wymagałaby od firm AI uzyskania zgody i zapłaty wydawcom przed scrapowaniem ich treści.
Polityki scrapingu na największych platformach: co warto wiedzieć
Nie wszystkie serwisy traktują scraping tak samo. Oto przegląd platform po platformie: co największe witryny dopuszczają, co blokują i co mówią o tym sądy:
| Platforma | ToS o scrapingu | Zabezpieczenia techniczne | Egzekwowanie prawne | Co jest praktycznie bezpieczne |
|---|---|---|---|---|
| Google (Search i Maps) | Zakazuje automatycznego dostępu w ToS. Platforma Maps ma wprost zapis „No Scraping”. | Wyzwania SearchGuard JS, CAPTCHA, ograniczanie liczby żądań. W 2025 zaktualizowano robots.txt, aby blokować crawlery AI. | W grudniu 2025 pozwał scraperów, powołując się na DMCA. Aktywnie blokuje crawlery AI (Anthropic, Meta, OpenAI). | Scraping publicznych danych firmowych z Google Maps da się obronić prawnie (precedens hiQ), ale należy spodziewać się blokad technicznych. Tam, gdzie to możliwe, używaj oficjalnych API. |
| Amazon | W Conditions of Use wprost zakazuje wszelkiego scrapingu („no robot, spider, scraper, or other automated means”). | Agresywne wykrywanie botów, CAPTCHA, blokady IP. robots.txt blokuje wszystkie boty poza Googlebot/Bingbot. Od 2025 wprost blokuje crawlery AI. | W listopadzie 2025 pozwał Perplexity AI. Regularnie wysyła wezwania do zaprzestania. W marcu 2026 zaktualizował BSA o zasady dla agentów AI. | Publiczne dane produktowe (ceny, oferty) są faktami i można je scrapować według prawa USA, ale Amazon bardzo ostro reaguje. Ograniczaj tempo żądań i unikaj danych osobowych. |
| Zakazuje scrapingu w ToS; do korzystania z usług wymaga akceptacji użytkownika. | Ściany logowania dla większości danych profilu, wykrywanie botów, ograniczanie liczby żądań. | Sprawa hiQ potwierdziła, że scrapowanie publicznych profili nie narusza CFAA, ale LinkedIn wygrał w kwestii roszczeń umownych i nieuczciwej konkurencji, gdy używano fałszywych kont. | Publiczne profile (widoczne bez logowania) są prawnie najbezpieczniejsze do scrapowania. Nigdy nie twórz fałszywych kont ani nie scrapuj danych po zalogowaniu. | |
| Meta (Facebook i Instagram) | ToS zakazują scrapingu; osobne reguły dla danych zalogowanych i wylogowanych. | Ściany logowania dla większości treści, zaawansowane wykrywanie botów. | W 2024 przegrała z Bright Data — sąd uznał, że ToS nie dotyczą scraperów niezalogowanych. Meta wycofała pozostałe roszczenia. | Publiczne dane (strony firmowe, publiczne posty) widoczne bez logowania są na bezpieczniejszym gruncie. Nigdy nie scrapuj prywatnych profili ani danych za logowaniem. |
| X (Twitter) | W 2023 zaktualizowano ToS, aby zakazać całego scrapingu i crawlowania bez pisemnej zgody. Usunięto dawny wyjątek dla robots.txt. | robots.txt blokuje wszystkie crawlery (Disallow: /). Wyzwania Cloudflare Turnstile. Surowe limity (300 żądań/godz.). Ocena reputacji IP. | Przegrał z Bright Data w sprawie danych publicznych, ale agresywnie ogranicza dostęp techniczny. | Publiczne tweety i profile są prawnie obronne, ale techniczne bariery X należą do najtrudniejszych w 2026. Bez premiumowej infrastruktury proxy trzeba liczyć się z blokadami. |
Wniosek: Sądy konsekwentnie uznają, że scraping publicznie widocznych danych bez logowania nie narusza CFAA. Ale platformy nadal mogą dochodzić swoich praw na gruncie prawa umów, prawa autorskiego albo przepisów o obchodzeniu zabezpieczeń — i dodatkowo skutecznie utrudniają życie barierami technicznymi. Zawsze scrapuj odpowiedzialnie.
Dane treningowe AI i web scraping: nowa granica prawna
Jeśli śledzisz wiadomości w 2026 roku, wiesz, że scraping danych do trenowania modeli AI stał się najgorętszym polem sporu prawnego. Oto, co się dzieje:
- Pozwy o prawa autorskie się mnożą. The New York Times, autorzy i wydawcy pozwali OpenAI, Anthropic i innych, twierdząc, że masowe scrapowanie treści chronionych prawem autorskim do trenowania LLM-ów nie jest „fair use”. Anthropic zawarło w 2025 roku ugodę w dużym pozwie zbiorowym na 1,5 mld USD — co pokazuje, że koszty scrapingu dla AI są bardzo realne.
- Obrona „fair use” jest chwiejna. Sądy w USA nie wydały jeszcze ostatecznego rozstrzygnięcia, czy trenowanie AI na scrapowanych danych mieści się w fair use. Wstępne orzeczenia sugerują, że wiele zależy od tego, jak dane zostały pozyskane i co robi się z wynikiem działania AI.
- Nadchodzą nowe przepisy. AI Accountability for Publishers Act (wniesiony w lutym 2026) ma wymagać od firm AI uzyskania zgody i zapłaty wydawcom przed scrapowaniem ich treści.
- Akt UE o AI (pełne egzekwowanie w sierpniu 2026) wymaga od twórców AI ujawniania źródeł danych treningowych, respektowania czytelnych maszynowo rezygnacji z wykorzystania utworów chronionych prawem autorskim (w ramach wyjątku TDM z dyrektywy o prawie autorskim) oraz oznaczania treści generowanych przez AI. Zakazuje też systemów AI, które scrapują z internetu zdjęcia twarzy.
- Crawlery AI/LLM eksplodują. Udział crawlerów AI w ruchu webowym wzrósł czterokrotnie — z 2,6% do 10,1% — w zaledwie osiem miesięcy. Sam GPTBot OpenAI urósł o 305%. W odpowiedzi duże serwisy (Amazon, Reddit, NYT) aktualizują robots.txt, by wprost blokować crawlery AI.
Co to oznacza dla Ciebie: Jeśli scrapujesz dane do tradycyjnych celów biznesowych (generowanie leadów, monitoring cen, badania rynku), te zasady specyficzne dla AI mogą nie mieć bezpośredniego zastosowania. Ale jeśli przepuszczasz scrapowane dane przez modele AI, zachowaj szczególną ostrożność — i skonsultuj się z prawnikiem.
Prawo web scrapingu na świecie: szybkie porównanie
Spójrzmy szerzej i zobaczmy, jak wygląda to globalnie:
- Stany Zjednoczone: Brak całkowitego zakazu. Scrapowanie stron publicznych jest zasadniczo legalne (hiQ v. LinkedIn), a wyroki z 2024 roku w sprawach Meta i X Corp dodatkowo wzmocniły pozycję scrapingu danych publicznych. Ale scrapowanie za logowaniem lub barierami technicznymi może nadal uruchamiać CFAA. Trend przesuwa się dziś w stronę używania przez firmy prawa umów i roszczeń z prawa autorskiego. Przepisy o prywatności szybko się rozszerzają: CCPA otrzymała ważne aktualizacje obowiązujące od 1 stycznia 2026, w tym nowe zasady dotyczące automatycznego podejmowania decyzji i obowiązków brokerów danych. Indiana, Kentucky i Rhode Island uchwaliły też kompleksowe ustawy o prywatności w 2026 roku.
- Unia Europejska: Surowe przepisy o prywatności. RODO dotyczy nawet publicznych danych osobowych. Prawa do baz danych mogą blokować masowy scraping danych uporządkowanych (cliffordchance.com). NOWOŚĆ: Akt UE o AI wchodzi w pełne egzekwowanie 2 sierpnia 2026, wymagając ujawniania źródeł danych treningowych i respektowania rezygnacji z wykorzystania utworów chronionych prawem autorskim. Ustawa zakazuje też scrapowania zdjęć twarzy z internetu do systemów AI.
- Wielka Brytania: Odtwarza reguły UE po Brexicie. Publiczne dane można scrapować, ale scraping danych osobowych jest ściśle regulowany. Computer Misuse Act może kryminalizować nieautoryzowany dostęp.
- Chiny: Bardzo restrykcyjne. PIPL i Data Security Law wymagają zgody na dane osobowe. Sądy używają prawa o nieuczciwej konkurencji, by blokować scraping szkodzący firmom (malwarebytes.com).
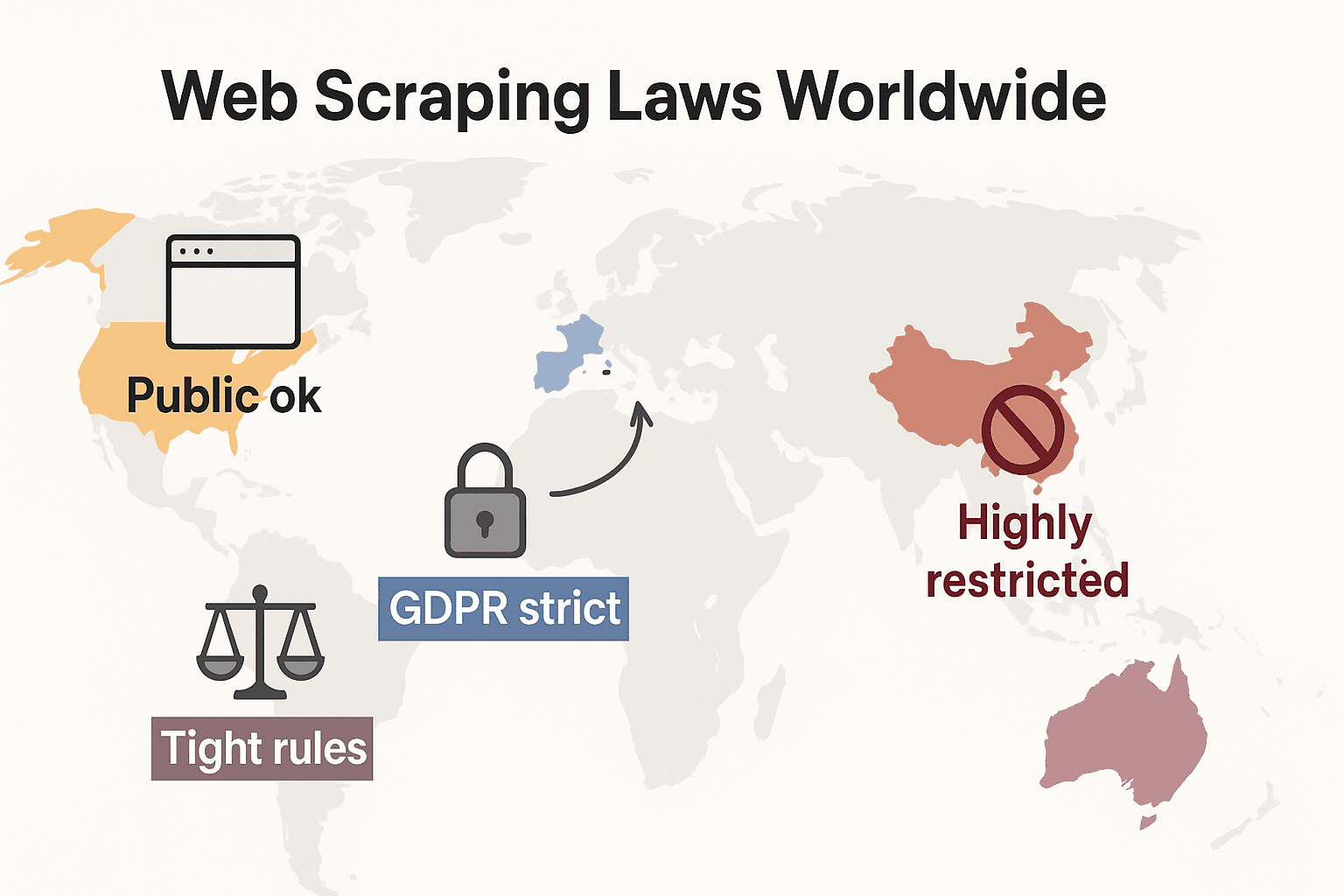
Najkrócej: scrapowanie publicznych, nieosobowych danych do użytku wewnętrznego jest zazwyczaj najbezpieczniejsze. Coś innego? Sprawdź lokalne prawo i działaj ostrożnie.
Popularne mity o legalności web scrapingu
Obalmy kilka mitów, które słyszę bez przerwy:
- Mit 1: „Web scraping jest nielegalny, kropka.”
Fałsz. Nie istnieje prawo, które zakazuje całego web scrapingu. Liczy się to, jakich danych używasz i co dokładnie scrapujesz (oxylabs.io). - Mit 2: „Jeśli dane są publiczne, mogę z nimi robić, co chcę.”
Niekoniecznie. Dane publiczne nadal mogą być chronione przepisami o prywatności lub prawem autorskim, a ToS mogą ograniczać określone użycia (ico.org.uk). - Mit 3: „Web scraping to to samo co hacking.”
Nie. Scrapowanie publicznych stron internetowych nie jest hackingiem. Omijanie logowania lub barier technicznych to zupełnie inna historia (calawyers.org). - Mit 4: „Jeśli mnie nie złapią, wszystko jest w porządku.”
Ryzykowne myślenie. Wiele serwisów używa technologii antybotowych i zauważy Twoją aktywność. Cisza nie oznacza zgody. - Mit 5: „Jeśli podam źródło albo użyję danych wewnętrznie, to wszystko jest okej.”
Atrybucja nie unieważnia prawa autorskiego ani prawa do prywatności. Użycie wewnętrzne jest bezpieczniejsze, ale nie daje wolnej ręki. - Mit 6: „Każdy web scraping narusza prywatność.”
Nie każdy scraping dotyczy danych osobowych. Ale pobieranie dużych ilości danych osobowych bez zabezpieczeń jest niemal zawsze nielegalne (oxylabs.io). - Mit 7: „Jeśli ToS strony zabrania scrapingu, to scraping zawsze jest nielegalny.”
Niekoniecznie. W 2024 roku sądy w sprawach Meta v. Bright Data i X Corp v. Bright Data uznały, że ToS nie wiążą użytkowników, którzy nigdy ich nie zaakceptowali — czyli jeśli scrapujesz bez logowania i bez tworzenia konta, ToS strony może Cię nie dotyczyć. To wciąż rozwijający się obszar, ale to duża zmiana.
Jak legalnie scrapować dane: najlepsze praktyki zgodności
Oto moja sprawdzona lista kontrolna dla legalnego i etycznego web scrapingu:
- Przeczytaj i respektuj Warunki korzystania z usługi. Jeśli piszą „no scraping”, rozważ rezygnację albo poproś o zgodę (ql2.com).
- Trzymaj się danych publicznych. Jeśli potrzebne jest hasło, dane są ograniczone — nie scrapuj ich (thunderbit.com).
- Sprawdzaj robots.txt i crawluj uprzejmie. To nie jest prawnie wiążące, ale to dobra etykieta. Nie zasypuj serwerów — rozłóż żądania w czasie (promptcloud.com).
- Unikaj danych osobowych, chyba że masz podstawę prawną. Jeśli musisz je zbierać, stosuj się do RODO/CCPA i ograniczaj zakres zbieranych danych.
- Nie publikuj ponownie całych scrapowanych treści. Dodaj wartość lub analizę albo poproś o zgodę (thunderbit.com).
- Nie karm modeli AI scrapowaną treścią bez sprawdzenia praw autorskich. Krajobraz prawny zmienia się szybko — jeśli to Twój przypadek, zasięgnij porady.
- Korzystaj z oficjalnych API lub eksportów danych, gdy są dostępne. Są do tego stworzone i zwykle bezpieczniejsze (thunderbit.com).
- Bądź transparentny i rozliczalny. Jeśli zbierasz dane osobowe, informuj ludzi i prowadź rejestr działań.
- Minimalizuj i zabezpieczaj dane. Zbieraj tylko to, czego potrzebujesz, dbaj o poprawność i przechowuj bezpiecznie.
- Bądź na bieżąco i w trudnych przypadkach konsultuj prawnika. Prawo i wyroki zmieniają się szybko — szczególnie Akt UE o AI i stanowe przepisy o prywatności w USA. Gdy masz wątpliwości, zapytaj specjalistę.
Wypróbuj rozszerzenie Thunderbit Chrome do zgodnego scrapingu
Legalne korzystanie z narzędzi do web scrapingu: co firmy muszą wiedzieć
Narzędzia do web scrapingu, takie jak Thunderbit, sprawiają, że zbieranie danych staje się dostępne także dla osób bez programowania. Nadal jednak trzeba używać ich odpowiedzialnie:
- Wybieraj narzędzia nastawione na zgodność. Thunderbit na przykład pobiera tylko to, co widzisz w przeglądarce — bez podstępnych obejść API i bez nieautoryzowanego dostępu (thunderbit.com).
- Trzymaj się legalnych zastosowań. Analityka wewnętrzna, badania rynku i monitoring cen konkurencji są zazwyczaj bezpieczne. Republikanie lub sprzedaż scrapowanych danych? Znacznie większe ryzyko.
- Konfiguruj narzędzia pod kątem zgodności. Ustaw opóźnienia między żądaniami, respektuj robots.txt i używaj szablonów, które zbierają tylko potrzebne dane.
- Trzymaj dane w firmie. Wykorzystanie danych wewnętrznie jest bezpieczniejsze niż ich ponowne publikowanie.
- Edukuj zespół. Upewnij się, że wszyscy rozumieją zasady i najlepsze praktyki.
- Korzystaj z wbudowanych funkcji zgodności. Thunderbit ostrzega użytkowników przed ryzykownymi stronami, scrapuje z prędkością zbliżoną do ludzkiej i nie przechowuje Twoich danych na swoich serwerach.
- Nie wymuszaj na siłę. Jeśli narzędzie nie potrafi scrapować strony, nie próbuj tego obchodzić. Nie wszystkie dane da się pozyskać bez ryzyka.
Podejście Thunderbit: umożliwianie zgodnego z prawem AI web scrapingu
W Thunderbit sporo czasu poświęciliśmy myśleniu o zgodności z przepisami. Oto jak nasz AI Web Scraper pomaga użytkownikom działać po właściwej stronie prawa:
- Pobiera tylko to, co widzisz. Thunderbit działa w Twojej sesji przeglądarki, więc nie ma dostępu do danych, których nie mógłbyś skopiować ręcznie.
- Prowadzi użytkownika ostrzeżeniami. Jeśli spróbujesz scrapować stronę z surową polityką antyscrapingową, Thunderbit Cię ostrzeże.
- Prędkości podobne do ludzkich. Niezależnie od tego, czy scrapujesz lokalnie, czy w chmurze, Thunderbit nie zasypuje serwerów żądaniami.
- Konfigurowalny dobór danych. Nasza AI sugeruje odpowiednie kolumny, pomagając zbierać tylko to, czego potrzebujesz.
- Obsługa podstron i paginacji. Thunderbit porusza się po witrynach jak prawdziwy użytkownik, respektując ich strukturę.
- Prywatność i bezpieczeństwo. Twoje dane zostają u Ciebie — Thunderbit ich nie przechowuje ani nie wykorzystuje ponownie.
- Eksporty przyjazne zgodności. Eksportuj bezpośrednio do Google Sheets, Airtable, Notion lub CSV do bezpiecznego użytku wewnętrznego.
- Planowanie i automatyzacja. Ustaw cykliczny scraping w odpowiednich odstępach.
- Wsparcie wielu języków. Interfejs Thunderbit obsługuje 34 języki, dzięki czemu zgodność jest dostępna globalnie.
- Regularne aktualizacje szablonów. Nasze natychmiastowe szablony dla popularnych stron są na bieżąco dostosowywane do zmian prawnych i technicznych.
Wbudowując zgodność w produkt, Thunderbit pomaga zespołom zbierać potrzebne dane — bez prawnych bólów głowy.
Być o krok przed zmianami: dostosowywanie się do zmian prawnych i technicznych w web scrapingu
Poznaj więcej poradników o web scrapingu Get Started Free
Web scraping to nie jest gra typu ustaw i zapomnij. Prawo i struktury stron cały czas się zmieniają. Oto jak utrzymać przewagę:
- Śledź zmiany prawne. Tempo zmian przyspieszyło w latach 2024–2026 — obserwuj wiadomości z obszaru prawa technologicznego, aktualizacje regulatorów i blogi branżowe (takie jak blog Thunderbit). Miej oko na egzekwowanie Aktu UE o AI (sierpień 2026), nowe stanowe ustawy o prywatności w USA i trwające sprawy o prawa autorskie związane z AI.
- Dostosowuj się do zmian technicznych. Serwisy stale aktualizują układy stron i zabezpieczenia antybotowe. Główne platformy (Amazon, X, Google) znacząco wzmocniły obronę w latach 2025–2026. AI i szablony Thunderbit zostały zaprojektowane tak, by dostosowywać się automatycznie.
- Korzystaj z oficjalnych API, gdy są dostępne. Jeśli serwis przechodzi na płatny model API, rozważ zmianę ze względu na niezawodność i zgodność.
- Regularnie audytuj scraping. Dokumentuj źródła, sprawdzaj zmiany ToS i polityk oraz dostosowuj strategię, gdy trzeba.
- Wykorzystuj aktualizacje szablonów Thunderbit. Nasz zespół dba o aktualność szablonów, więc nie musisz martwić się breaking changes ani nowymi wymaganiami zgodności.
- Zachowaj elastyczność. Jeśli źródło danych stanie się zbyt ryzykowne, przejdź na inne albo poszukaj partnerstwa.
Przy odpowiednich narzędziach i nastawieniu możesz utrzymać płynność swojego pipeline’u danych — bez wchodzenia na prawne miny.
Podsumowanie: poruszanie się po prawnym krajobrazie web scrapingu
Web scraping nie jest z natury nielegalny — to potężne narzędzie dla biznesu, badań i innowacji. Ale jak każde narzędzie, wiąże się z zasadami. Kluczowe jest zrozumienie, co scrapujesz, jak to robisz i co zamierzasz zrobić z danymi. Respektuj lokalne prawo, przestrzegaj zasad serwisów i korzystaj z narzędzi nastawionych na zgodność, takich jak Thunderbit, aby działać zgodnie z przepisami.
Wyroki z lat 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) wzmocniły pozycję scrapingu danych publicznych, ale pojawiają się nowe ryzyka związane z danymi treningowymi AI, roszczeniami z prawa autorskiego i Aktem UE o AI. Polityki poszczególnych platform bardzo się różnią — Google, Amazon, LinkedIn, Meta i X egzekwują swoje zasady na różne sposoby — więc zanim zaczniesz scrapować, poznaj teren.
Jeśli kiedykolwiek masz wątpliwości, skonsultuj się z prawnikiem — zwłaszcza przy dużych lub wrażliwych projektach. I pamiętaj: krajobraz prawny cały czas się zmienia, więc bądź na bieżąco i działaj elastycznie.
Chcesz dowiedzieć się więcej o web scrapingu, zgodności i automatyzacji? Zajrzyj na blog Thunderbit, gdzie znajdziesz więcej poradników, albo wypróbuj samodzielnie rozszerzenie Thunderbit do Chrome.
Rozpocznij zgodny web scraping z Thunderbit
FAQ
1. Czy web scraping jest nielegalny wszędzie?
Nie. Web scraping sam w sobie nie jest nielegalny, ale jego legalność zależy od tego, co scrapujesz, jak to robisz i gdzie się znajdujesz. Scraping publicznych, nieosobowych danych do użytku wewnętrznego jest zazwyczaj dozwolony w większości regionów, ale scrapowanie danych osobowych lub chronionych prawem autorskim albo łamanie zasad serwisu może być nielegalne (oxylabs.io).
2. Czy robots.txt sprawia, że scraping staje się nielegalny, jeśli go zignoruję?
Robots.txt nie jest prawnie wiążący, ale najlepiej go respektować. Zignorowanie robots.txt samo w sobie nie doprowadzi Cię do pozwu, ale w sporze może sprawić, że będziesz wyglądać jak „zły aktor” (promptcloud.com).
3. Czy mogę scrapować Google, Amazon albo LinkedIn?
To skomplikowane. Wszystkie trzy platformy zabraniają scrapingu w swoich ToS, ale sądy uznały, że ToS mogą nie wiązać użytkowników niezalogowanych (zob. Meta v. Bright Data i X Corp v. Bright Data, obie sprawy z 2024 roku). Scrapowanie publicznie widocznych danych (cen produktów, ofert firmowych, publicznych profili) jest w USA zazwyczaj możliwe do obrony prawnej. Każda z tych platform egzekwuje jednak zasady inaczej: Amazon reaguje najsurowiej na drodze prawnej (pozwał Perplexity AI w listopadzie 2025), LinkedIn opiera się na barierach technicznych i roszczeniach umownych, a Google coraz częściej korzysta z egzekwowania opartego na DMCA. Zawsze scrapuj odpowiedzialnie i licz się z technicznymi kontrposunięciami.
4. Czy mogę scrapować Facebooka albo Instagrama?
Po Meta v. Bright Data (2024) scrapowanie publicznych danych z Facebooka i Instagrama bez logowania ma mocniejsze podstawy prawne. Sąd uznał, że ToS Meta nie dotyczą osób, które nie są zalogowane. Ale nigdy nie twórz fałszywych kont ani nie scrapuj danych za ścianą logowania — to już przekroczenie granicy.
5. Czy mogę scrapować X (Twitter)?
X zaktualizował ToS w 2023 roku, zakazując całego scrapingu bez pisemnej zgody, i wdrożył agresywne zabezpieczenia techniczne (Cloudflare Turnstile, limity 300 żądań/godz., ocena reputacji IP). Jednak Bright Data wygrało w sądzie w podobnym zakresie — dane publiczne scrapowane bez konta nie są objęte ToS X. Technicznie X jest jedną z najtrudniejszych platform do scrapowania w 2026 roku.
6. Czy scraping danych do trenowania modeli AI jest legalny?
To największe otwarte pytanie w 2026 roku. Duże pozwy (NYT v. OpenAI, ugoda Anthropic na 1,5 mld USD) sugerują znaczące ryzyko prawne. Akt UE o AI wymaga ujawniania źródeł danych treningowych i respektowania rezygnacji z wykorzystania utworów chronionych prawem autorskim. Proponowany AI Accountability for Publishers Act wymagałby zgody i płatności. Jeśli scrapujesz dane do trenowania AI, skonsultuj się z prawnikiem przed działaniem.
7. Jaki jest najbezpieczniejszy sposób korzystania z narzędzi do web scrapingu, takich jak Thunderbit?
Trzymaj się scrapowania danych publicznych, respektuj warunki serwisu, unikaj danych osobowych, chyba że masz podstawę prawną, i używaj danych wewnętrznie. Thunderbit został zaprojektowany tak, by pomagać Ci zachować zgodność: pobiera tylko to, co widać w przeglądarce, i ostrzega przed ryzykownymi stronami (thunderbit.com).
8. Czy mogę scrapować dane do celów komercyjnych?
To zależy. Wykorzystanie scrapowanych danych do analiz wewnętrznych lub badań jest zazwyczaj bezpieczniejsze. Republikanie lub sprzedaż scrapowanych danych, zwłaszcza jeśli są chronione prawem autorskim albo dotyczą osób prywatnych, jest znacznie bardziej ryzykowna i może wymagać zgody lub licencji.
9. Jak nadążać za zmianami prawnymi i technicznymi w web scrapingu?
Śledź wiadomości z obszaru prawa technologicznego, monitoruj docelowe serwisy pod kątem zmian ToS lub polityk i korzystaj z narzędzi takich jak Thunderbit, które regularnie aktualizują szablony i funkcje zgodności. Najważniejsze rzeczy do obserwacji w 2026 roku: egzekwowanie Aktu UE o AI (sierpień), trwające sprawy o prawa autorskie związane z AI oraz nowe stanowe przepisy o prywatności w USA. Gdy masz wątpliwości, skonsultuj się z prawnikiem.
Wypróbuj AI Web Scraper Get Started Free




