

Sieć w 2026 roku to dziki świat — połowa całego ruchu internetowego to dziś boty, a otwartoźródłowe web crawlery są cichymi bohaterami działającymi w tle, napędzając wszystko od monitorowania cen po trening AI. Od lat pracuję w SaaS i automatyzacji i jeśli nauczyłem się jednej rzeczy, to tego, że dobór odpowiedniego samodzielnie hostowanego crawlера może oszczędzić zespołowi miesiące problemów (i może kilka nocnych sesji debugowania). Niezależnie od tego, czy wyciągasz dane z kilku stron produktowych, czy indeksujesz miliony adresów URL na potrzeby badań, otwartoźródłowe alternatywy dla Firecrawl z tej listy zapewnią Ci wsparcie — bez względu na skalę, stos technologiczny czy gotowość na złożoność.
Jest jednak haczyk: nie ma rozwiązania uniwersalnego. Niektóre zespoły potrzebują surowej mocy Scrapy albo archiwizacyjnej siły Heritrix, a inne uznają utrzymanie bibliotek open-source za zbyt kosztowne. Rozłóżmy więc na czynniki pierwsze 9 najlepszych otwartoźródłowych alternatyw dla Firecrawl na 2026 rok, pokażmy, w czym każda z nich błyszczy, i pomóżmy dopasować właściwe narzędzie do potrzeb Twojej firmy — bez bólu metodą prób i błędów.
Jak wybrać najlepszą otwartoźródłową alternatywę dla Firecrawl dla Twojej firmy
Zanim wejdziesz w listę, porozmawiajmy o strategii. Rynek otwartoźródłowego web crawlingu jest dziś bardziej zróżnicowany niż kiedykolwiek, a wybór powinien zależeć od kilku kluczowych czynników:
- Łatwość użycia: Wolisz interfejs typu point-and-click, czy czujesz się swobodnie, pisząc w Pythonie, Go albo JavaScript?
- Skalowalność: Indeksujesz jedną stronę czy musisz przeszukiwać miliony stron w setkach domen?
- Typ treści: Czy Twoja strona docelowa to statyczny HTML, czy opiera się na ciężkim JavaScript i dynamicznym ładowaniu?
- Potrzeby integracyjne: Jak chcesz wykorzystać dane — wyeksportować do Excela, wysłać do bazy danych czy podać je do pipeline’u analitycznego?
- Utrzymanie: Masz zasoby, by utrzymywać własny kod, czy wolisz narzędzie, które samo dostosowuje się do zmian na stronie?
Oto krótka ściągawka, która pomoże Ci zdecydować:
| Scenariusz | Najlepsze narzędzie(a) |
|---|---|
| Bez kodu, przeglądanie offline | HTTrack |
| Duża skala, crawl wielu domen | Scrapy, Apache Nutch, StormCrawler |
| Strony dynamiczne / mocno oparte na JS | Puppeteer |
| Automatyzacja formularzy / wymagane logowanie | MechanicalSoup |
| Pobieranie / archiwizacja statycznych stron | Wget, HTTrack, Heritrix |
| Programista Go, wysoka wydajność | Colly |
Przejdźmy teraz do 9 najlepszych otwartoźródłowych alternatyw dla Firecrawl na 2026 rok.
1. Scrapy: najlepszy wybór do dużych projektów crawlingu w Pythonie

Scrapy to prawdziwy gigant otwartoźródłowego web crawlingu. Zbudowany w Pythonie, jest frameworkiem z wyboru dla deweloperów, którzy potrzebują działania na dużą skalę — miliony stron, częste aktualizacje i złożona logika witryny.
Dlaczego Scrapy?
- Ogromna skala: Scrapy radzi sobie z tysiącami żądań na sekundę i jest używany przez firmy przetwarzające miliardy stron miesięcznie (Zyte).
- Rozszerzalny i modułowy: Piszesz własne spidery, dodajesz middleware do proxy, obsługujesz logowania i eksportujesz do JSON, CSV albo baz danych.
- Aktywna społeczność: Mnóstwo wtyczek, dokumentacji i odpowiedzi na Stack Overflow.
- Sprawdzony w boju: Używany produkcyjnie przez zespoły e-commerce, media i badawcze na całym świecie.
Ograniczenia: Stroma krzywa nauki dla osób nietechnicznych i konieczność utrzymywania spiderów, gdy strony się zmieniają. Ale jeśli zależy Ci na pełnej kontroli i skalowalności, Scrapy trudno przebić.
2. Apache Nutch: najlepszy wybór do firmowych wyszukiwarek
Apache Nutch to prawdziwy nestor otwartoźródłowych crawlerów, zaprojektowany z myślą o crawlingu klasy enterprise i na skalę internetu. Jeśli marzysz o zbudowaniu własnej wyszukiwarki albo indeksowaniu milionów domen, Nutch jest dla Ciebie.
Dlaczego Apache Nutch?
- Skala napędzana Hadoopem: Zbudowany na Hadoopie, Nutch może indeksować miliardy stron w klastrach serwerów (Common Crawl używa go do indeksowania publicznej sieci).
- Crawling wsadowy: Podajesz listę seed URL-i i pozwalasz mu działać — świetne do cyklicznych zadań na dużą skalę.
- Integracje: Działa z Solr, Elasticsearch i pipeline’ami big data.
Ograniczenia: Złożona konfiguracja (pomyśl o klastrach Hadoop, plikach konfiguracyjnych Java), i bardziej chodzi w nim o surowe crawlowanie niż o wydobywanie ustrukturyzowanych danych. Przesada dla małych projektów, ale bezkonkurencyjny w crawlowaniu na skalę internetu.
3. Heritrix: najlepszy do archiwizacji WWW i zgodności z regulacjami
Heritrix to własny crawler Internet Archive, stworzony specjalnie do archiwizacji stron i cyfrowej preservacji.
Dlaczego Heritrix?
- Kompletność na poziomie archiwalnym: Zapisuje każdą stronę, zasób i link — idealne rozwiązanie do zgodności prawnej albo historycznych migawek.
- Wyjście WARC: Przechowuje wszystko w standardowych plikach Web ARChive, gotowych do odtwarzania lub analizy.
- Panel administracyjny w przeglądarce: Konfigurujesz i monitorujesz crawl przez interfejs WWW.
Ograniczenia: Ciężki (wymaga dużo miejsca na dysku i pamięci), nie wykonuje JavaScriptu i zwraca surowe archiwa zamiast ustrukturyzowanych tabel danych. Najlepszy dla bibliotek, archiwów i branż regulowanych.
4. Colly: najlepszy dla programistów Go nastawionych na wydajność
Colly to ulubieniec programistów Go — szybki, lekki i bardzo równoległy web scraper.
Dlaczego Colly?
- Błyskawiczny: Współbieżność Go pozwala Colly skrobać tysiące stron przy minimalnym użyciu CPU/RAM (Oxylabs).
- Proste API: Definiujesz callbacki dla elementów HTML, a obsługa cookies i robots.txt działa automatycznie.
- Świetny do stron statycznych: Idealny do stron renderowanych po stronie serwera, API albo wtedy, gdy chcesz włączyć scraping do backendu w Go.
Ograniczenia: Brak wbudowanego renderowania JavaScriptu (do stron dynamicznych trzeba go połączyć np. z Chromedp) i trzeba znać Go.
5. MechanicalSoup: najlepszy do prostych automatyzacji formularzy

MechanicalSoup to biblioteka Pythona, która łączy proste żądania HTTP z pełną automatyzacją przeglądarki.
Dlaczego MechanicalSoup?
- Automatyzacja formularzy: Łatwo się loguje, wypełnia formularze i utrzymuje sesje — świetne do scrapingu za logowaniem.
- Lekki: W tle korzysta z Requests i BeautifulSoup, więc jest szybki i prosty w uruchomieniu.
- Idealny do stron interaktywnych: Jeśli musisz wysłać formularz wyszukiwania albo pobierać dane po zalogowaniu, MechanicalSoup to bardzo dobry wybór (Apify Blog).
Ograniczenia: Nie wykonuje JavaScriptu, więc nie poradzi sobie na stronach mocno opartych na JS. Najlepszy do stron statycznych lub renderowanych po stronie serwera z prostymi interakcjami.
6. Puppeteer: najlepszy do stron dynamicznych i mocno opartych na JavaScript
Puppeteer to szwajcarski scyzoryk do scrapingu nowoczesnych stron internetowych, mocno opartych na JavaScript. To biblioteka Node.js, która daje pełną kontrolę nad przeglądarką Chrome w trybie headless.
Dlaczego Puppeteer?
- Obsługa dynamicznej treści: Scraping aplikacji SPA, infinite scroll i stron ładujących dane przez AJAX (Browserless Guide).
- Symulacja użytkownika: Klika przyciski, wypełnia formularze, robi zrzuty ekranu, a nawet rozwiązuje CAPTCHA (z pomocą wtyczek).
- Mocna automatyzacja: Świetny do testów, monitoringu i scrapingu wszystkiego, co widzi prawdziwy użytkownik.
Ograniczenia: Duże zużycie zasobów (uruchamia pełne instancje Chrome), wolniejszy od scraperów opartych wyłącznie na HTTP, a skalowanie wymaga solidnego sprzętu albo orkiestracji w chmurze.
7. Wget: najlepszy do szybkich pobrań z linii poleceń

Wget to klasyczne narzędzie wiersza poleceń do pobierania statycznych stron i plików.
Dlaczego Wget?
- Prostota: Pobierasz całe strony albo katalogi jedną komendą — bez kodowania.
- Szybkość: Napisany w C, więc jest szybki i wydajny.
- Świetny do treści statycznych: Idealny do stron dokumentacji, blogów albo masowego pobierania plików (HuggingFace Guide).
Ograniczenia: Nie wykonuje JavaScriptu ani nie obsługuje formularzy, a pobiera surowe strony, nie ustrukturyzowane dane. Traktuj go jak cyfrowy odkurzacz do stron statycznych.
8. HTTrack: najlepszy do przeglądania offline (bez kodu)
HTTrack to przyjazny użytkownikowi kuzyn Wget, oferujący graficzny interfejs do mirroringu stron.
Dlaczego HTTrack?
- Wygoda GUI: Kreator krok po kroku sprawia, że narzędzie jest dostępne także dla osób nietechnicznych.
- Przeglądanie offline: Dostosowuje linki, dzięki czemu możesz lokalnie przeglądać zmirrorowane strony.
- Świetny do archiwizacji: Idealny dla badaczy, marketerów albo każdego, kto chce mieć migawkę strony bez kodowania (Reddit DataHoarder).
Ograniczenia: Nie obsługuje treści dynamicznych, może działać wolno na dużych stronach i nie jest zaprojektowany do wydobywania ustrukturyzowanych danych.
9. StormCrawler: najlepszy do rozproszonego crawlowania w czasie rzeczywistym

StormCrawler to nowoczesny, rozproszony crawler dla zespołów, które potrzebują ciągłych danych webowych w czasie rzeczywistym i na dużą skalę.
Dlaczego StormCrawler?
- Crawling w czasie rzeczywistym: Zbudowany na Apache Storm, przetwarza dane strumieniowo — świetne do monitoringu newsów albo wyszukiwarek (Wikipedia).
- Modułowy i skalowalny: W razie potrzeby dodajesz parsowanie, indeksowanie i własne bolty przetwarzające.
- Używany przez Common Crawl: Napędza zbiór danych newsowych dla jednego z największych otwartych archiwów sieci.
Ograniczenia: Wymaga programowania w Javie i klastra Storm, więc najlepiej sprawdza się w zespołach z doświadczeniem w systemach rozproszonych. Przesada dla małych projektów.
Porównanie otwartoźródłowych alternatyw dla Firecrawl: która darmowa konkurencja pasuje do Twoich potrzeb?
Oto zestawienie wszystkich 9 narzędzi obok siebie:
| Narzędzie | Najlepsze zastosowanie | Główne zalety | Wady | Język / konfiguracja |
|---|---|---|---|---|
| Scrapy | Crawling na dużą skalę, częsty crawl | Potężny, skalowalny, ogromna społeczność | Stroma krzywa nauki, wymaga Pythona | Framework Python |
| Apache Nutch | Crawling enterprise, na skalę internetu | Napędzany Hadoopem, sprawdzony w skali | Złożona konfiguracja, wsadowy charakter | Java/Hadoop |
| Heritrix | Archiwizacja, crawling zgodnościowy | Pełne przechwytywanie witryny, wyjście WARC | Ciężki, bez JS, surowe archiwa | Aplikacja Java, interfejs webowy |
| Colly | Deweloperzy Go, scraping wysokiej wydajności | Szybki, proste API, współbieżność | Brak JS, wymaga Go | Biblioteka Go |
| MechanicalSoup | Automatyzacja formularzy, scraping po logowaniu | Lekki, obsługa sesji | Brak JS, ograniczona skala | Biblioteka Python |
| Puppeteer | Strony dynamiczne / mocno oparte na JS | Pełna kontrola nad przeglądarką, automatyzacja | Duże zużycie zasobów, wymaga Node.js | Biblioteka Node.js |
| Wget | Pobieranie statycznych stron, dostęp offline | Prosty, szybki, CLI | Brak JS, surowe strony | Narzędzie wiersza poleceń |
| HTTrack | Użytkownicy nietechniczni, archiwizacja witryn | GUI, łatwe przeglądanie offline | Brak JS, wolny na dużych stronach | Aplikacja desktopowa (GUI) |
| StormCrawler | Crawling rozproszony w czasie rzeczywistym | Skalowalny, modułowy, real-time | Wymagana znajomość Java/Storm | Klaster Java/Storm |
Czy budować własne rozwiązanie, czy skorzystać z istniejącej otwartoźródłowej alternatywy dla Firecrawl?
Oto szczera prawda: budowanie własnego crawlера brzmi świetnie — aż do momentu, gdy grzęźniesz po uszy w utrzymaniu, proxy i problemach z antybotami. Otwartoźródłowe narzędzia z tej listy zamykają w sobie lata ciężko zdobywanego doświadczenia i mądrości społeczności. Według raportów branżowych korzystanie z gotowych rozwiązań to najszybszy i najbardziej niezawodny sposób, by osiągnąć rezultat i nie wymyślać koła na nowo (IveerData).
- Wybierz open-source, jeśli: Twoje potrzeby pokrywają się z tym, co już istnieje, chcesz skrócić czas rozwoju i cenisz wsparcie społeczności.
- Buduj własne rozwiązanie, jeśli: Masz naprawdę unikalne wymagania, głęboką wiedzę wewnątrz firmy i scraping jest kluczowy dla Twojego biznesu.
Pamiętaj jednak, że open-source nie jest „darmowy”, jeśli policzysz koszt czasu inżynierów, utrzymania serwerów i ciągłych aktualizacji potrzebnych do walki z zabezpieczeniami anty-scrapingowymi. Jeśli chcesz korzyści płynące z mocnego crawlера bez pisania kodu, jest jeszcze jedna opcja.
Bonus: gdy open-source jest zbyt złożony, wypróbuj Thunderbit
Choć narzędzia wymienione powyżej są świetne dla deweloperów, wszystkie mają wspólne ograniczenia: wymagają umiejętności kodowania, gorzej radzą sobie z dynamicznymi systemami anty-bot opartymi na AI i potrzebują ciągłego utrzymania.
Thunderbit to moja rekomendacja numer jeden dla każdego, kto chce ominąć te ograniczenia. Łączy moc scrapingu z łatwością użycia.
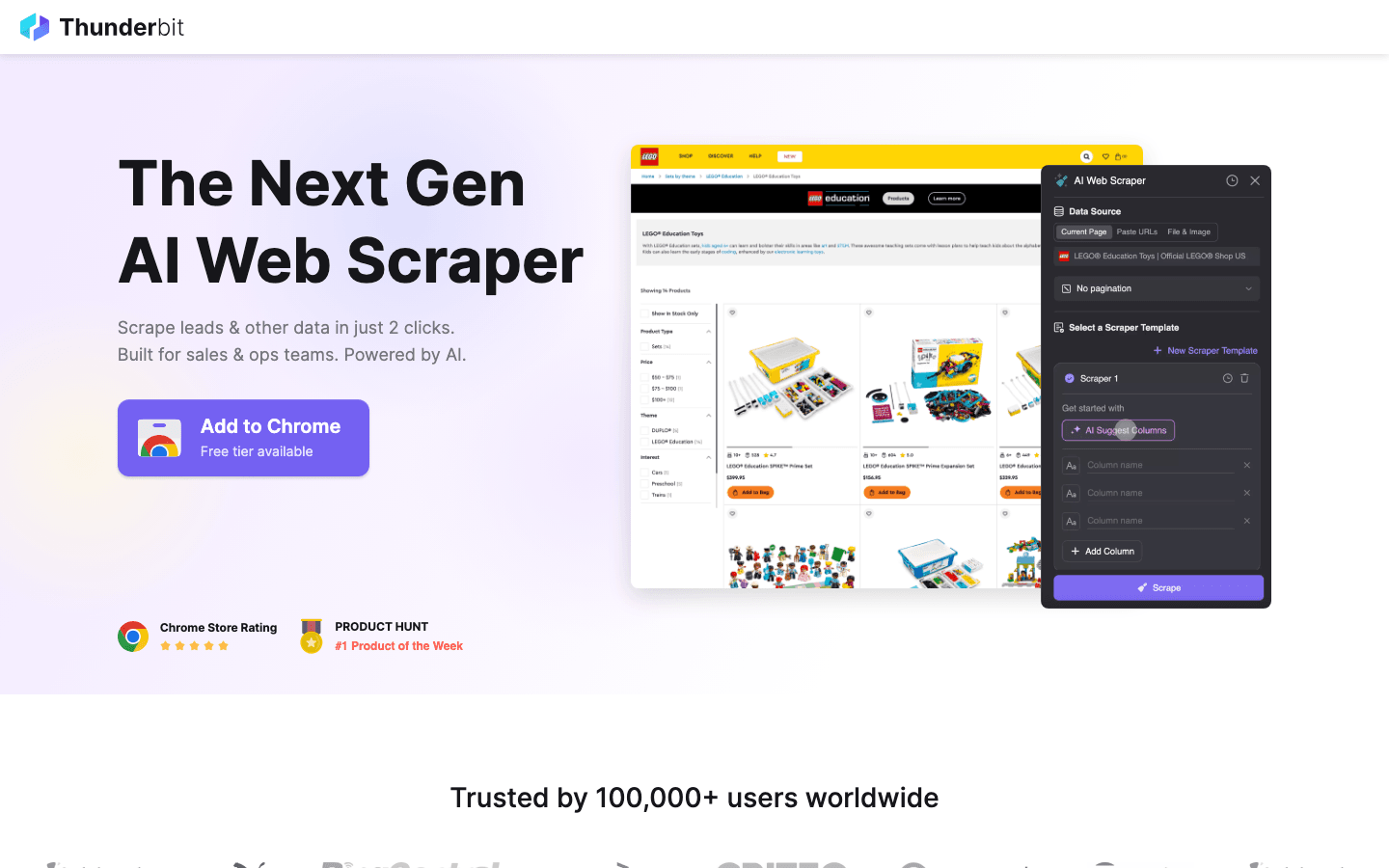
Dlaczego rozważyć Thunderbit zamiast open-source?
- Zero kodowania: W przeciwieństwie do Scrapy czy Puppeteer, Thunderbit to rozszerzenie do Chrome oparte na AI. Klikasz „AI Suggest Fields”, a ono buduje scraper za Ciebie.
- Radzi sobie z trudnymi rzeczami: Dynamiczna treść, nieskończone przewijanie i paginacja są obsługiwane automatycznie przez AI, co oszczędza godziny pisania własnych skryptów.
- Natychmiastowy eksport: Przechodzisz ze strony internetowej do Excela, Google Sheets albo Notion w dwa kliknięcia.
- Brak utrzymania: Nie musisz aktualizować kodu, gdy strona zmienia układ — AI Thunderbit dostosowuje się za Ciebie.
Jeśli jesteś handlowcem, marketerem albo badaczem i chcesz danych teraz, bez nauki Pythona czy Go, Thunderbit jest idealnym uzupełnieniem otwartoźródłowych narzędzi z tej listy.
Chcesz zobaczyć to w akcji? Pobierz rozszerzenie do Chrome i wypróbuj je sam.
Wypróbuj AI Web Scraper Thunderbit
Podsumowanie: jak znaleźć odpowiedni samodzielnie hostowany web crawler na 2026 rok
Przeczytaj więcej poradników o web scrapingu Get Started Free
Świat otwartoźródłowych alternatyw dla Firecrawl jest dziś bogatszy niż kiedykolwiek. Niezależnie od tego, czy potrzebujesz surowej skali Scrapy lub Nutch, czy archiwalnej wierności Heritrix, istnieje rozwiązanie dla każdego scenariusza biznesowego. Klucz polega na dopasowaniu narzędzia do potrzeb — nie przewymiarowuj rozwiązania, jeśli potrzebujesz tylko szybkiego pobrania danych, i nie oszczędzaj zbyt mocno, jeśli crawlujesz na skalę internetu.
I pamiętaj: jeśli droga open-source okaże się zbyt techniczna albo czasochłonna, narzędzia AI, takie jak Thunderbit, są gotowe przejąć część pracy.
Gotowy, by zacząć? Uruchom Scrapy przy swoim następnym dużym projekcie danych albo wypróbuj Thunderbit do prostego scrapingu wspieranego przez AI. Jeśli chcesz więcej wskazówek o web scrapingu, zajrzyj na blog Thunderbit, gdzie znajdziesz analizy i poradniki.
Wypróbuj Thunderbit do scrapingu webowego z AI
FAQ
1. Jaka jest główna zaleta korzystania z otwartoźródłowych alternatyw dla Firecrawl? Otwartoźródłowe alternatywy oferują elastyczność, oszczędność kosztów oraz możliwość samodzielnego hostowania i dostosowywania crawlера. Unikasz uzależnienia od jednego dostawcy i korzystasz z aktywnego wsparcia społeczności oraz aktualizacji.
2. Które narzędzie jest najlepsze dla osób nietechnicznych, które potrzebują szybkich rezultatów? HTTrack to solidny otwartoźródłowy wybór do przeglądania offline. Jednak do wydobywania ustrukturyzowanych danych (na przykład tabel do Excela) polecamy bonusowe narzędzie Thunderbit dzięki jego możliwościom AI.
3. Jak obsługiwać dynamiczne strony internetowe mocno oparte na JavaScript? Puppeteer to najlepszy wybór — steruje prawdziwą przeglądarką, więc może pobierać wszystko, co widzi użytkownik, w tym aplikacje SPA i treści ładowane przez AJAX.
4. Kiedy powinienem używać ciężkiego crawlера, takiego jak Apache Nutch lub StormCrawler? Jeśli musisz indeksować miliony stron w wielu domenach albo potrzebujesz rozproszonego crawlowania w czasie rzeczywistym (np. do wyszukiwarek lub monitoringu newsów), te narzędzia są stworzone do pracy na dużą skalę i z wysoką niezawodnością.
5. Czy lepiej zbudować własny crawler, czy użyć istniejącego rozwiązania open-source? Dla większości zespołów korzystanie z istniejącego otwartoźródłowego narzędzia i jego dostosowanie jest szybsze, tańsze i bardziej niezawodne. Własne rozwiązanie warto budować tylko wtedy, gdy masz bardzo wyspecjalizowane potrzeby i zasoby na długoterminowe utrzymanie.
Udanych crawlingów — niech Twoje dane zawsze będą świeże, ustrukturyzowane i gotowe do działania.
Wypróbuj Thunderbit AI Web Scraper za darmo Get Started Free
Dowiedz się więcej
- Top 5 najlepszych narzędzi do scrapingu danych webowych w 2026 roku
- 15 najlepszych AI web crawlerów, które warto znać w 2025 roku
- Top 5 najlepszych narzędzi do scrapingu danych webowych w 2026 roku
- 7 najpopularniejszych narzędzi do web scrapingu w 2026 roku
- 6 niezbędnych narzędzi do web scrapingu, które pomogą osiągnąć sukces w 2025 roku




