W zeszłym tygodniu jeden z naszych użytkowników napisał do nas: „Potrzebuję cen, opisów i danych o wariantach z 14 konkurencyjnych sklepów Shopify — do piątku”. To około 4 000 stron produktów. Kopiuj-wklej? Nie wchodziło w grę.
Jeśli kiedykolwiek próbowałeś pobierać dane produktowe ze sklepu Shopify — ceny, obrazy, opisy, warianty, recenzje — znasz ten ból. Według danych z 2026 roku działa ponad , a żaden z nich nie ma przycisku „eksport dla osób z zewnątrz”. Tymczasem twierdzi, że aktywnie monitoruje ceny konkurencji, a dostawcy usług e-commerce podają, że ręczne dodanie nawet jednego produktu z wariantami i obrazami może zająć . Pomnóż to przez kilkaset produktów i cały tydzień znika.
Dlatego rozszerzenia Chrome do Shopify Scraper stały się standardowym elementem zestawu narzędzi e-commerce — do analizy konkurencji, wyszukiwania produktów do dropshippingu, migracji katalogów i nie tylko. Większość artykułów o „najlepszych scraperach” po prostu wylicza funkcje, ale nie pokazuje, co naprawdę dzieje się po uruchomieniu ich na prawdziwych sklepach Shopify. Ten tekst jest inny. Przetestowałem osiem rozszerzeń na rzeczywistych sklepach, natrafiłem na prawdziwe blokady anty-botowe i sprawdziłem, które narzędzia wyciągają głębokie dane produktowe, których potrzebujesz — a które kończą na powierzchni.
Dlaczego zespoły e-commerce potrzebują rozszerzenia Chrome do Shopify Scraper
Sklepy Shopify to kopalnie komercyjnie użytecznych danych produktowych. Ale jako osoba z zewnątrz nie dostajesz pliku CSV do pobrania. Dostajesz witrynę sklepu. Żeby zamienić ją w użyteczną wiedzę, potrzebujesz scrapera — a przypadki użycia wykraczają daleko poza „chcę listę nazw produktów”.
Prawdziwe pytanie brzmi: jakich danych naprawdę potrzebujesz i do jakiego procesu? Oto jak najczęstsze zastosowania w e-commerce przekładają się na konkretne pola danych:
Badanie cen konkurencji
Potrzebujesz: tytułów produktów, cen, cen porównawczych i cen na poziomie wariantów. To podstawa dynamicznej strategii cenowej — wiedzieć nie tylko, ile konkurent pobiera, ale też jak robi promocje, bundle i wyceny w zależności od rozmiaru czy koloru.
Wyszukiwanie produktów do dropshippingu
Potrzebujesz: tytułów, wszystkich obrazów (nie tylko miniaturek), pełnych opisów i dat publikacji. Sortowanie według najnowszej daty publikacji pomaga wyłapywać trendy i świeżo wprowadzone produkty, zanim rynek się nimi nasyci.
Import katalogu do własnego sklepu
Potrzebujesz: tytułów, HTML treści, wszystkich obrazów, wariantów, SKU i cen — najlepiej w pliku . Nie każde narzędzie robi to czysto.
Szacowanie dynamiki sprzedaży
Potrzebujesz: tytułów produktów i stanów magazynowych śledzonych w czasie. Zapisując poziomy zapasów według harmonogramu, możesz oszacować, jak szybko konkurent sprzedaje produkt — to przybliżony, ale użyteczny wskaźnik, gdy nie masz dostępu do danych sprzedażowych.
Pozyskiwanie leadów (znajdowanie właścicieli sklepów)
Potrzebujesz: nazwy sklepu, adresu e-mail, numeru telefonu, a czasem też informacji o aplikacjach lub stosie technologicznym sklepu. Zespoły sprzedaży używają tego do budowania list kontaktowych segmentowanych według niszy lub technologii.
Oto szybka ściągawka:
| Przypadek użycia | Najważniejsze potrzebne pola danych | Zalecany proces |
|---|---|---|
| Badanie cen konkurencji | Tytuł, cena, cena porównawcza, ceny wariantów | Scrapowanie strony listingu + wzbogacanie podstron dla wariantów |
| Wyszukiwanie produktów do dropshippingu | Tytuł, cena, obrazy (wszystkie), opis, data publikacji | Scrapowanie podstron + sortowanie po najnowszej dacie publikacji |
| Import katalogu do własnego sklepu | Tytuł, HTML treści, obrazy, warianty, SKU, cena | Pełne scrapowanie podstron → eksport jako CSV do importu do Shopify |
| Szacowanie sprzedaży | Tytuł, ilość w magazynie (w czasie) | Scrapowanie według harmonogramu → śledzenie w Google Sheets |
| Generowanie leadów (właściciele sklepów) | Nazwa sklepu, e-mail, telefon, używane aplikacje | Scrapowanie stron kontaktowych sklepu + ekstraktory e-mail/telefonu |
Jak oceniłem te 8 rozszerzeń Chrome do Shopify Scraper
Zainstalowałem wszystkie osiem rozszerzeń i uruchomiłem je na tym samym zestawie prawdziwych sklepów Shopify — w tym sklepach publicznych, chronionych przez Cloudflare oraz takich, w których wyłączono products.json. Nie sprawdzałem tylko list funkcji. Chciałem zobaczyć, co naprawdę dzieje się po kliknięciu „scrape” na aktywnej stronie kolekcji Shopify.
Oto osiem kryteriów, których użyłem, i dlaczego każde z nich ma znaczenie właśnie dla Shopify:
| Kryterium | Dlaczego ma znaczenie przy scrapowaniu Shopify |
|---|---|
| Łatwość konfiguracji | Czy osoba nietechniczna może zacząć scrapować w mniej niż 5 minut? |
| Wyciągane pola danych | Czy pobiera tytuł, cenę, obrazy, opisy, warianty ORAZ recenzje — czy tylko dane powierzchowne? |
| Wzbogacanie podstron | Czy może najpierw scrapować stronę listingu, a potem automatycznie odwiedzać każdą stronę produktu, by pobrać pełne szczegóły? |
| Obsługa paginacji | Czy może scrapować poza pierwszą stroną produktów (klikana paginacja lub nieskończone przewijanie)? |
| Odporność na boty | Czy radzi sobie z Cloudflare Turnstiles lub ochroną botową Shopify bez błędów? |
| Format eksportu | CSV, Excel, Google Sheets, Airtable, Notion, CSV gotowy do Shopify import? |
| Harmonogram/regularne scrapowanie | Czy może automatycznie monitorować zmiany cen lub stanu magazynowego w czasie? |
| Przejrzystość cen | Limity darmowego planu, system kredytów, stała opłata — i to, co naprawdę otrzymujesz |
Mając to ramy, przyjrzyjmy się, jak wypadło każde narzędzie.
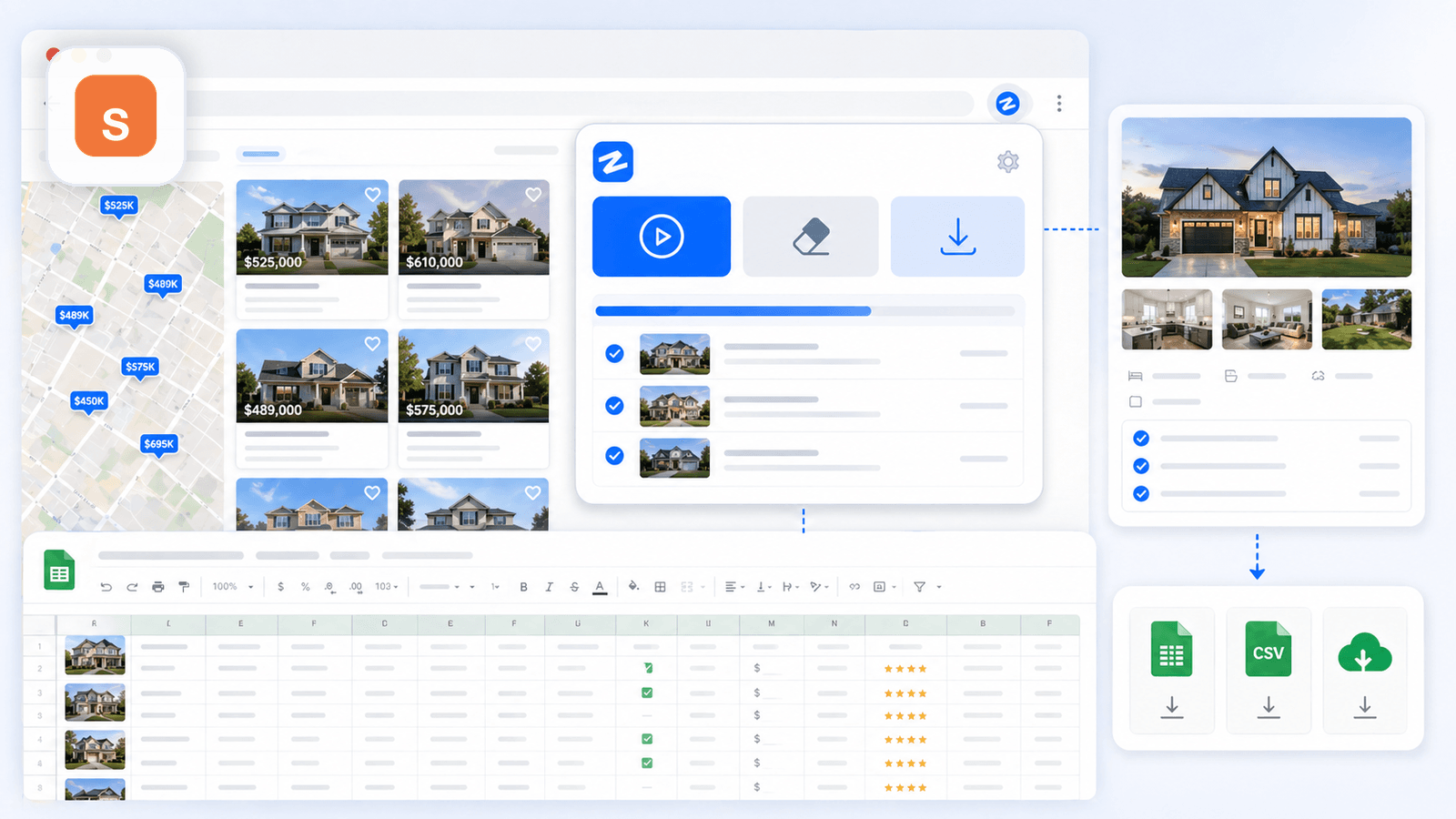
1. Thunderbit — scraper Shopify oparty na AI, stworzony dla osób bez kodowania
to narzędzie, które zbudowaliśmy w Thunderbit specjalnie dla użytkowników biznesowych, którzy chcą głębokich danych produktowych bez pisania kodu, konfigurowania selektorów CSS czy tracenia 20 minut na start. Proces w sklepie Shopify to naprawdę dwa kliknięcia: otwierasz stronę kolekcji, klikasz „AI Suggest Fields”, a AI czyta stronę i proponuje kolumny (tytuł, cena, obraz itd.). Klikasz „Scrape” i gotowe — strona listingu jest pobrana.
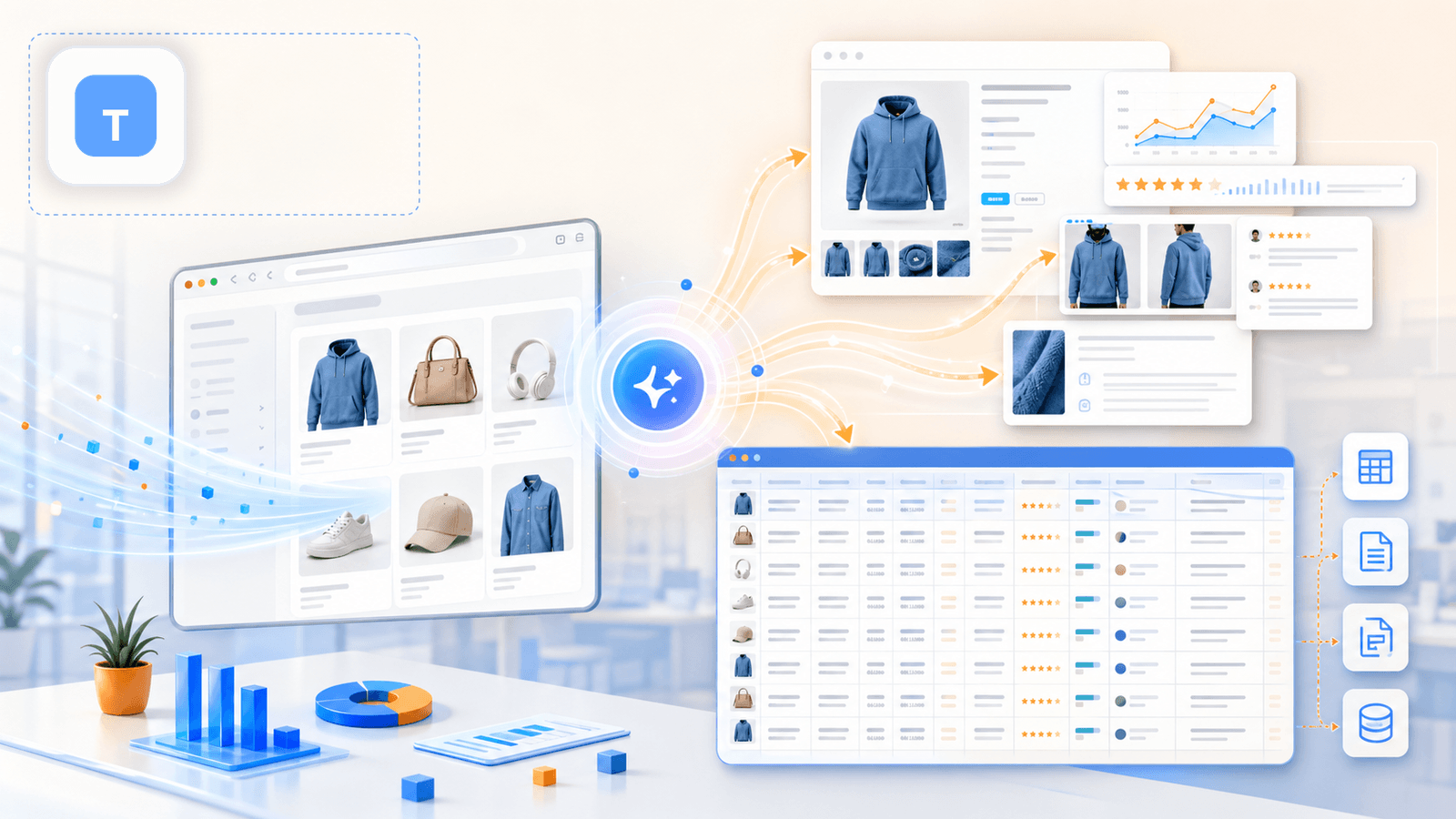
Ale prawdziwy wyróżnik — i coś, co większość konkurencyjnych artykułów pomija — dzieje się potem.
Wzbogacanie podstron: funkcja, która zmienia wszystko
Po pobraniu strony listingu klikasz „Scrape Subpages”. AI Thunderbit odwiedza każdy indywidualny adres URL produktu i dopisuje dane ze strony szczegółów do oryginalnej tabeli: pełne opisy, wszystkie obrazy galerii, opcje wariantów, SKU, liczbę recenzji i więcej. To właśnie ten krok zamienia płaski arkusz w użyteczny zbiór danych do analizy konkurencji.
W dalszej części pokażę dokładniej, dlaczego to ważne (i przedstawię porównanie przed/po).
Najważniejsze zalety dla scrapowania Shopify
- AI Suggest Fields odczytuje stronę Shopify i automatycznie tworzy właściwą strukturę kolumn — bez selektorów CSS, bez ręcznej konfiguracji
- Scrapowanie podstron uzupełnia luki w danych, których brakuje na stronach listingu (pełne opisy, opcje wariantów, galerie obrazów, recenzje)
- Tryb cloud scraping do szybkiego masowego pobierania z publicznych sklepów; tryb browser scraping dla sklepów chronionych przez Cloudflare lub wymagających logowania
- Obsługa paginacji (klikana i nieskończone przewijanie)
- Planowane scrapowanie do ciągłego monitorowania cen i stanów magazynowych — opisujesz harmonogram zwykłym językiem (np. „w każdy poniedziałek o 9:00”)
- Darmowe ekstraktory e-mail i telefonu do generowania leadów
- Eksport do Excel, Google Sheets, Airtable, Notion, CSV, JSON — także w formatach przyjaznych importowi do Shopify
- Field AI Prompt pozwala dodawać własne instrukcje do każdej kolumny (np. „skategoryzuj do 3 typów produktów” albo „przetłumacz opis na angielski”)
Gdzie ma słabsze strony
- Cennik oparty na kredytach oznacza, że bardzo duże scrapowanie (dziesiątki tysięcy produktów) wymaga płatnego planu
- Przetwarzanie AI dodaje kilka sekund na wiersz w porównaniu z scraperami opartymi na szablonach na bardzo prostych stronach
Ceny
- Darmowy plan: 6 stron (lub do 10 w ramach darmowego okresu próbnego), wszystkie eksporty bezpłatne
- Starter: , 500 kredytów/miesiąc
- Plany Professional: od 38 USD/miesiąc (3 000 kredytów) do 249 USD/miesiąc (20 000 kredytów)
- Zasady kredytów: 1 wiersz wyjściowy = 1 kredyt przy scrapowaniu webowym; 1 wiersz wyjściowy = 2 kredyty przy scrapowaniu podstron; eksporty są zawsze darmowe
Najlepsze dla: Nietechnicznych zespołów e-commerce, które potrzebują najgłębszych danych produktowych Shopify przy minimalnej konfiguracji — i chcą monitorować konkurencję w czasie.
2. Instant Data Scraper — opcja automatycznego wykrywania bez konfiguracji
Instant Data Scraper to darmowe rozszerzenie Chrome, które wykorzystuje algorytmy heurystyczne do automatycznego wykrywania danych tabelarycznych na stronach. Nie ma żadnej konfiguracji — otwierasz stronę kolekcji Shopify, klikasz ikonę rozszerzenia, a ono próbuje wykryć i wyświetlić dane produktowe w tabeli.
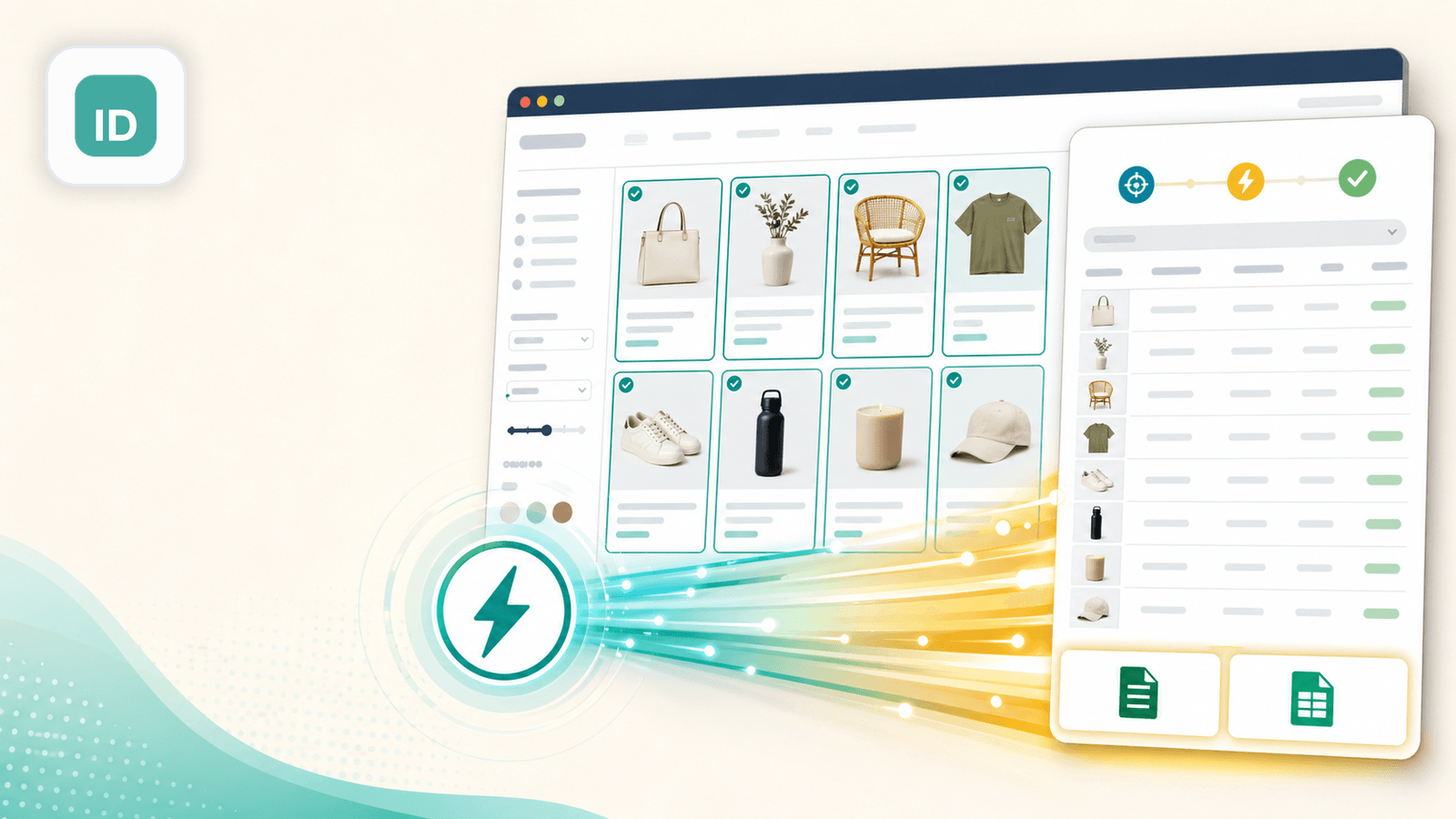
W moich testach działało dobrze na standardowych stronach kolekcji Shopify w motywie Dawn, wyciągając tytuły, ceny i URL-e miniatur w kilka sekund. Na sklepach z niestandardowym układem czasem łapało linki nawigacyjne albo treści stopki zamiast produktów — trzeba było sprawdzać wyniki wzrokiem.
Najważniejsze zalety dla scrapowania Shopify
- Całkowicie darmowe, bez limitów użycia
- Automatyczne wykrywanie oznacza zerowy czas konfiguracji — dobre do szybkich, jednorazowych eksportów
- Obsługuje paginację (może automatycznie kliknąć „next page”)
- Eksport do CSV i XLSX
Gdzie ma słabsze strony
- Automatyczne wykrywanie bywa nietrafione na sklepach Shopify z niestandardowym układem
- Brak wzbogacania podstron: dostajesz to, co jest na stronie listingu (tytuł, cena, miniatura), ale nie pełne opisy, warianty ani recenzje
- Brak AI do czyszczenia, etykietowania lub przekształcania danych
- Brak harmonogramu, brak cloud scrapingu
- Brak bezpośredniego eksportu do Google Sheets, Airtable czy Notion
Ceny
- Całkowicie darmowe
Najlepsze dla: Każdego, kto potrzebuje szybkiego, darmowego i bezkonfiguracyjnego eksportu widocznych danych ze strony listingu standardowego sklepu Shopify.
3. Web Scraper — wizualny kreator sitemap
Web Scraper (webscraper.io) to klasyczne rozszerzenie Chrome typu point-and-click do budowania „sitemap” — przepisów scrapowania, w których wybierasz elementy na stronie i definiujesz przebieg pobierania. W Shopify tworzysz sitemapę, klikając tytuły produktów, ceny, obrazy i definiując reguły paginacji oraz przechodzenia po linkach.
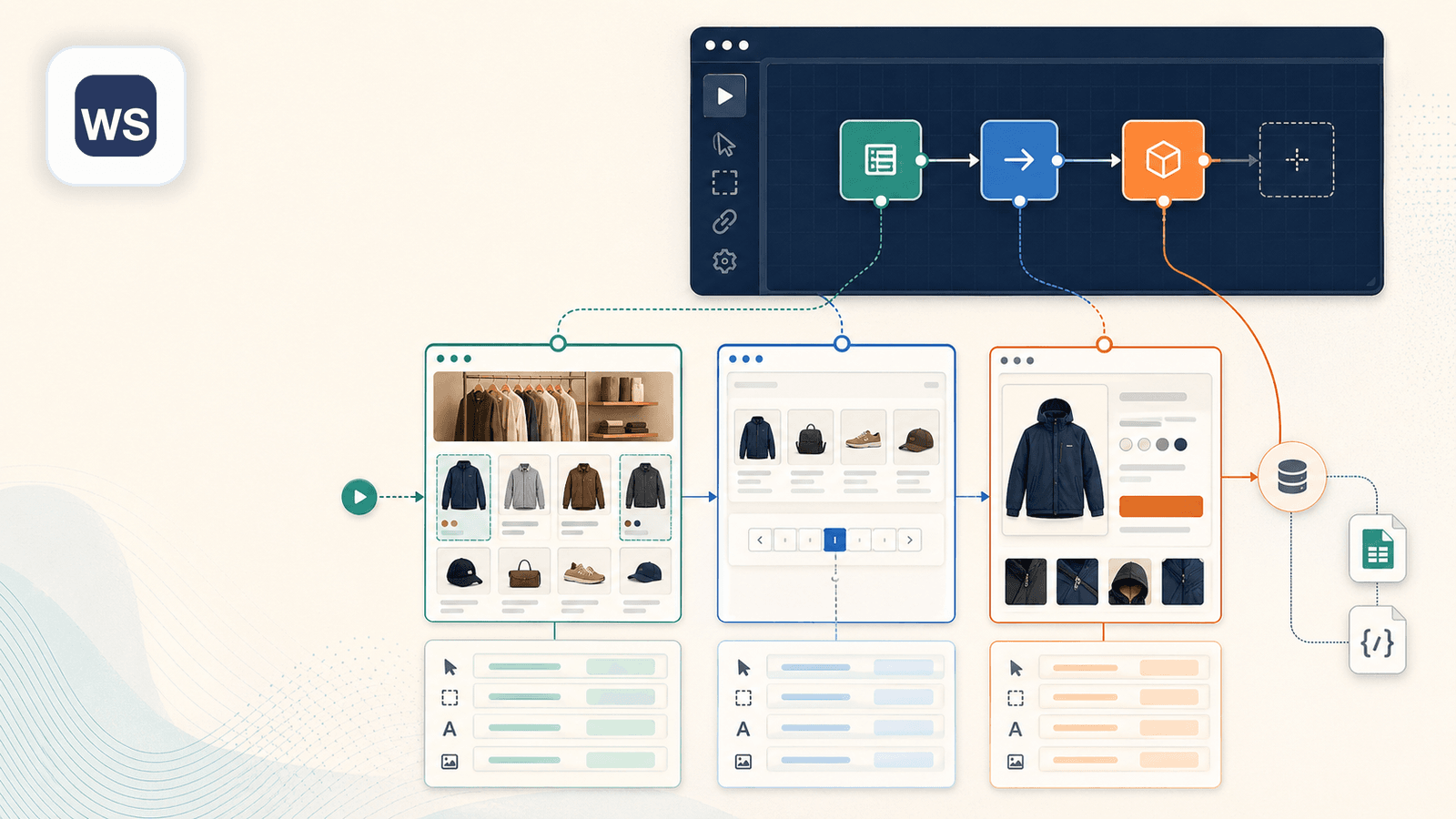
Najważniejsze zalety dla scrapowania Shopify
- Wizualny kreator selektorów daje większą kontrolę niż narzędzia automatycznie wykrywające dane
- Potrafi podążać za linkami do podstron (stron szczegółów produktu) — ale wymaga ręcznej konfiguracji selektorów nadrzędnych i podrzędnych w sitemapie
- Obsługuje paginację przy odpowiedniej konfiguracji
- Darmowe scrapowanie w przeglądarce; dostępne płatne plany cloud scraping (od 50 USD/miesiąc)
- Eksport do CSV; plany cloud obsługują Google Sheets i inne formaty
Gdzie ma słabsze strony
- Konfiguracja jest bardziej czasochłonna: stworzenie sitemap z selektorami parent-child zajęło mi około 15 minut dla nowego sklepu Shopify
- Scrapowanie podstron wymaga — to nie jest wzbogacanie jednym kliknięciem
- Sitemap przestaje działać, gdy sklep Shopify zmieni układ lub klasy CSS
- Krzywa uczenia jest bardziej stroma niż w przypadku alternatyw opartych na AI
Ceny
- Rozszerzenie do przeglądarki: darmowe
- Plany cloud: Project 50 USD/miesiąc, Professional 100 USD/miesiąc, Scale od 200 USD/miesiąc
Najlepsze dla: Użytkowników technicznych, którzy chcą precyzyjnej kontroli nad procesem scrapowania i nie mają nic przeciwko samodzielnemu budowaniu przepisu.
4. Data Miner — scraper oparty na przepisach
Data Miner (dataminer.io) opiera się na „recipes” — gotowych lub własnych szablonach scrapowania, które stosujesz do strony. Ma publiczną bibliotekę przepisów, więc możesz znaleźć szablon Shopify udostępniony przez innego użytkownika albo zbudować własny, wybierając elementy na stronie.
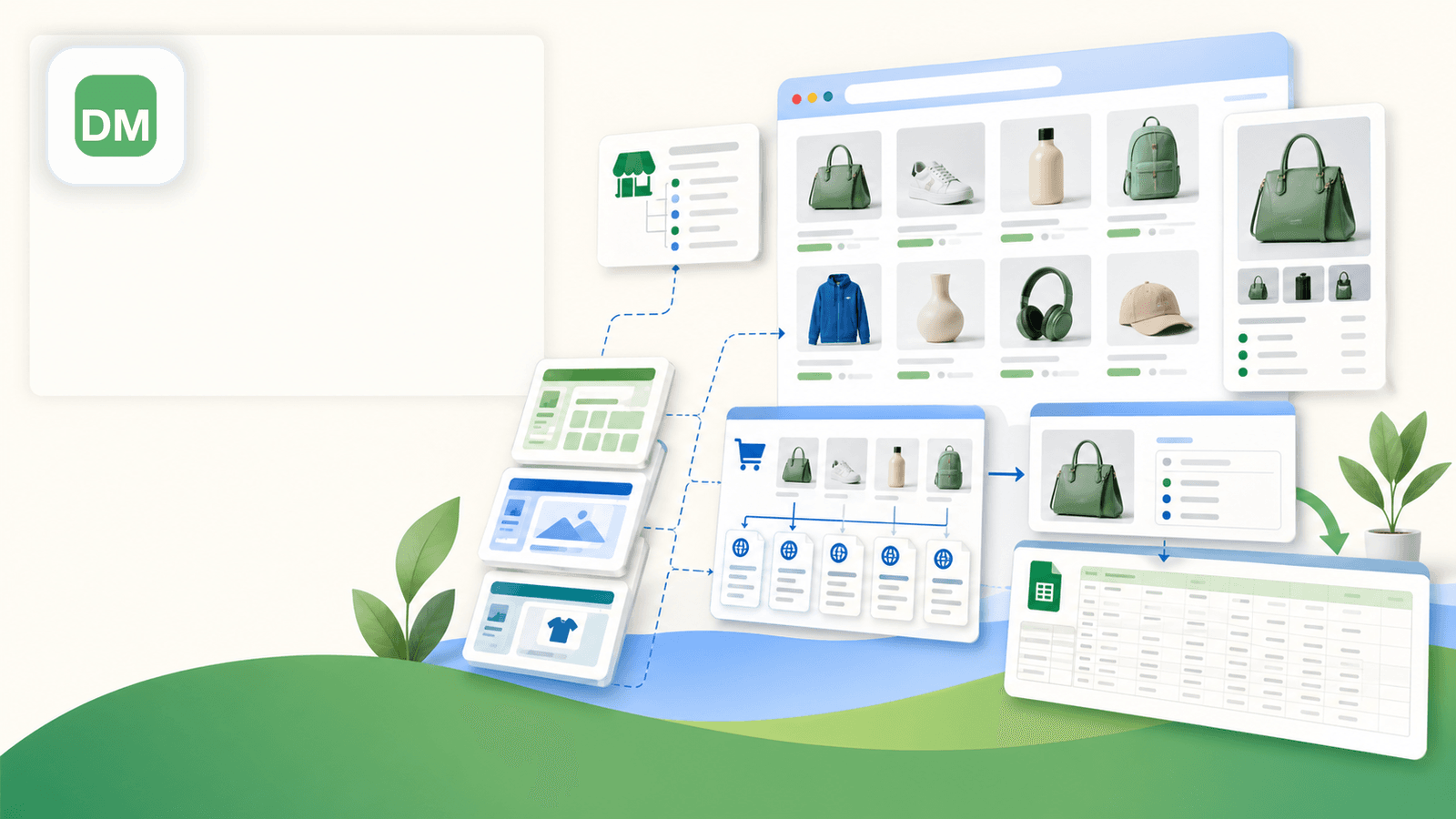
Najważniejsze zalety dla scrapowania Shopify
- Biblioteka przepisów może zawierać gotowe szablony Shopify udostępnione przez innych użytkowników
- Wizualny kreator przepisów do własnych konfiguracji scrapowania
- Obsługuje paginację przez konfigurację przepisu
- Eksport do CSV, Excel, Google Sheets i TSV
- Workflow crawl do odwiedzania stron szczegółów po stronach listingu
Gdzie ma słabsze strony
- Darmowy plan jest ograniczony do 500 stron miesięcznie
- Przepisy bazują na selektorach CSS, więc psują się, gdy zmienia się układ sklepu
- Brak sugestii pól i przekształcania danych wspieranego przez AI
- Brak wbudowanego workflow wzbogacania podstron jednym kliknięciem — wymaga osobnego przepisu crawl dla stron szczegółów
- Istnieją automatyczne crawl, ale to nie jest najprostsza historia harmonogramowania
Ceny
- Darmowy: 500 stron/miesiąc
- Solo: 19,99 USD/miesiąc
- Small Business: 49 USD/miesiąc
- Business: 99 USD/miesiąc
- Business Plus: 200 USD/miesiąc
Najlepsze dla: Użytkowników, którzy lubią pracę z szablonami i chcą biblioteki przepisów, aby przyspieszyć konfigurację na popularnych stronach.
5. Simplescraper — lekki ekstraktor
Simplescraper (simplescraper.io) to minimalistyczne rozszerzenie Chrome i scraper oparty na chmurze, który stawia na prostotę. Klikasz elementy danych na stronie Shopify, Simplescraper generuje selektory CSS i wyciąga dopasowane dane.
Najważniejsze zalety dla scrapowania Shopify
- Czysty, minimalistyczny interfejs — szybko się go uczy
- Dostępne cloud scraping do zadań planowanych i masowych
- Dostęp API dla developerów, którzy chcą włączyć dane do workflow
- Eksport do CSV, JSON, Google Sheets, Airtable i przez webhooki
- Koncepcja deep scraping do podążania za linkami do stron szczegółów
- Workflow obsługujące logowanie dla sklepów wrażliwych na sesję
Gdzie ma słabsze strony
- Ręczne podejście oparte na selektorach — brak AI do automatycznego wykrywania pól
- Scrapowanie podstron wymaga dodatkowej konfiguracji
- Mniejsza społeczność i mniej gotowych szablonów niż w Web Scraper czy Data Miner
- Darmowy plan: 100 kredytów (1 strona renderowana przez JS = 2 kredyty)
- Cennik planów płatnych jest mniej przejrzysty na oficjalnej stronie niż u większości konkurentów
Ceny
- Darmowy: 100 kredytów
- Plany płatne: źródła zewnętrzne podają Plus za ok. 39 USD/miesiąc, Pro za ok. 70 USD/miesiąc, Premium za ok. 150 USD/miesiąc (wg danych cenowych G2)
Najlepsze dla: Użytkowników, którzy chcą lekkiego, nowoczesnego scrapera cloud z dobrymi integracjami i nie potrzebują wykrywania pól przez AI.
6. Octoparse — rozszerzenie Chrome wspierane przez desktop
Octoparse (octoparse.com) to przede wszystkim aplikacja desktopowa z towarzyszącym rozszerzeniem Chrome. Oferuje zarówno wizualny kreator workflow, jak i gotowe szablony dla popularnych stron, w tym tutorial scrapowania specyficzny dla Shopify.

Najważniejsze zalety dla scrapowania Shopify
- Gotowe szablony Shopify do typowych zadań scrapowania
- Mocna aplikacja desktopowa z zaawansowanymi funkcjami: rotacja IP, planowane scrapowanie, ekstrakcja w chmurze
- Dobrze obsługuje paginację, nieskończone przewijanie i treści ładowane przez AJAX
- Najmocniejsza udokumentowana obsługa anty-bot w tym zestawieniu, w tym automatyczna obsługa CAPTCHA
- Eksport do CSV, Excel, JSON, HTML, XML, baz danych i Google Sheets
Gdzie ma słabsze strony
- Samo rozszerzenie Chrome ma ograniczenia — większość zaawansowanych funkcji wymaga aplikacji desktopowej
- Aplikacja desktopowa ma stromszą krzywą uczenia z wizualnym kreatorem workflow
- Darmowy plan jest ograniczony; sensowne użycie wymaga płatnego planu
- Cięższa konfiguracja niż w przypadku narzędzi działających wyłącznie jako rozszerzenia Chrome — nie jest to idealny wybór do szybkiego, 5-minutowego scrapowania
- Aplikacja desktopowa działa tylko na Windows/Mac (nie jest czysto przeglądarkowa)
Ceny
- Dostępny darmowy plan
- Basic: 39 USD/miesiąc
- Standard: ok. 83 USD/miesiąc (miesięcznie), ok. 75 USD/miesiąc (rocznie)
- Professional: ok. 299 USD/miesiąc (miesięcznie), ok. 208 USD/miesiąc (rocznie)
- Enterprise: indywidualnie
Najlepsze dla: Zespołów, które potrzebują scrapowania na skalę enterprise z rotacją IP, obsługą anty-bot i cyklicznymi zadaniami w chmurze — i nie mają nic przeciwko aplikacji desktopowej.
7. Bardeen — scraper stawiający na automatyzację
Bardeen (bardeen.ai) to platforma automatyzacji przeglądarkowej, która łączy web scraping z automatyzacją workflow. Użytkownicy budują „playbooks”, które mogą pobierać dane, a potem przekazywać je do innych aplikacji — można to traktować jak: „jeśli scrapuję to, to od razu wrzuć do CRM”.

Najważniejsze zalety dla scrapowania Shopify
- Automatyzacja workflow wykraczająca poza samo scrapowanie: pobierz dane Shopify → wzbogacaj → wyślij do CRM lub arkusza w jednym playbooku
- Integracje z ponad 100 aplikacjami (Google Sheets, Airtable, Notion, HubSpot, Slack itd.)
- Funkcje AI do ekstrakcji i klasyfikacji danych
- Działa w przeglądarce — nie wymaga aplikacji desktopowej
- Automatyzacje oparte na czasie i dacie do harmonogramowania
Gdzie ma słabsze strony
- To przede wszystkim narzędzie automatyzacji, a nie dedykowany scraper — funkcje scrapowania są płytsze niż w wyspecjalizowanych narzędziach
- Tworzenie playbooków może być mylące dla osób, które po prostu chcą wyciągnąć listę produktów
- Darmowy plan ograniczony do 100 kredytów
- Wzbogacanie podstron i obsługa paginacji są mniej intuicyjne niż w dedykowanych narzędziach do scrapowania
- To przesada, jeśli chcesz tylko pobierać dane bez dalszej automatyzacji
Ceny
- Darmowy: 100 kredytów
- Basic: 10 USD/miesiąc, 100 kredytów/miesiąc
- Premium: 50 USD/miesiąc, 1 000 kredytów/miesiąc (ok. 40 USD/miesiąc przy rozliczeniu rocznym)
- Enterprise: indywidualnie
- Model kredytowy: 1 kredyt za wiersz scrapera, 3 kredyty za wiersz wzbogacenia
Najlepsze dla: Zespołów, które chcą scrapować dane Shopify i natychmiast przesyłać je do aplikacji dalszego procesu (CRM, arkuszy, Slacka) w jednym zautomatyzowanym workflow.
8. Listly — konwerter list do arkusza
Listly (listly.io) został zaprojektowany specjalnie do zamieniania list i tabel ze stron WWW w dane gotowe do arkusza kalkulacyjnego. Klikasz rozszerzenie na stronie kolekcji Shopify, a Listly próbuje wykryć listę produktów i wyeksportować ją jako arkusz.

Najważniejsze zalety dla scrapowania Shopify
- Niezwykle prosty interfejs — stworzony do wyciągania list jednym kliknięciem
- Dobrze wykrywa powtarzalne struktury list (jak siatki produktów)
- Eksport bezpośrednio do Excel i Google Sheets
- Funkcja grupowego scrapowania do przetwarzania wielu URL-i naraz
- Harmonogram dostępny w planach Business
Gdzie ma słabsze strony
- Ogranicza się do tego, co automatycznie wykryje na stronie — brak własnej konfiguracji pól
- Brak wzbogacania podstron — eksportuje tylko dane na poziomie listingu
- Słabo radzi sobie z niestandardowymi motywami Shopify lub sklepami z ciężkim renderowaniem JavaScript
- Darmowy plan jest bardzo ograniczony (10 URL-i/miesiąc)
- Ograniczone opcje eksportu w porównaniu z konkurencją (głównie Excel i Sheets)
Ceny
- Darmowy: 10 URL-i/miesiąc, podstawowa ekstrakcja 1 strony, pobieranie do Excel, eksport do Google Sheets
- Light: 30 USD/miesiąc (187,20 USD/rok przy rozliczeniu rocznym)
- Business: 90 USD/miesiąc (993,60 USD/rok przy rozliczeniu rocznym) — dodaje zaawansowaną ekstrakcję, grupową ekstrakcję, harmonogram, auto-scroll/click, API beta
Najlepsze dla: Użytkowników, którzy chcą najprostszą możliwą drogę od strony kolekcji Shopify do arkusza — i nie potrzebują głębokich danych produktowych.
Porównanie wszystkich 8 rozszerzeń Chrome do Shopify Scraper
Oto pełne porównanie obok siebie. Starałem się być konkretny w każdej komórce, a nie tylko zaznaczać pola — bo „obsługuje paginację” znaczy coś zupełnie innego w zależności od narzędzia.
| Narzędzie | Łatwość konfiguracji | Pola danych | Wzbogacanie podstron | Paginacja | Obsługa anty-bot | Formaty eksportu | Harmonogram | Darmowy plan / ceny |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Bardzo łatwe (AI, 2 kliknięcia) | Najmocniejsze dla użytkowników nietechnicznych (AI sugeruje wszystkie istotne pola) | Tak — wzbogacanie jednym kliknięciem | Tak (klikana + nieskończone przewijanie) | Cloud dla publicznych, browser dla chronionych | Sheets, Airtable, Notion, CSV, JSON, Excel | Tak (harmonogram w zwykłym języku) | 6 stron za darmo; płatne od 15 USD/mies. |
| Instant Data Scraper | Ekstremalnie łatwe (bez konfiguracji) | Dobre tylko dla danych z poziomu listingu | Nie | Tak (auto-wykrywanie następnej strony) | Tylko browser, bez historii anty-bot | CSV, XLSX | Nie | Darmowe |
| Web Scraper | Średnio-trudne (ręczna sitemap) | Elastyczne, jeśli sitemap jest dobrze zbudowana | Tak, ale ręcznie przez selektory linków | Tak (przy konfiguracji sitemap) | Lokalnie w przeglądarce; rotacja proxy w planach cloud | CSV lokalnie; szersze możliwości w cloud | Tak w planach cloud | Darmowe rozszerzenie; cloud od 50 USD/mies. |
| Data Miner | Średnio (oparte na przepisach) | Dobre, jeśli przepis istnieje albo został zbudowany | Tak, ale wymaga wieloetapowego crawla | Tak (konfiguracja przepisu) | Głównie po stronie przeglądarki | CSV, Excel, Sheets, TSV | Istnieją automatyczne crawl | Darmowe 500 stron/mies.; płatne od 19,99 USD/mies. |
| Simplescraper | Łatwe-średnie (na selektorach) | Solidne do lekkiej ekstrakcji | Deep scraping istnieje, ale nie jednym kliknięciem | Tak (obsługuje nieskończone przewijanie) | Rotacja proxy i workflow przyjazne logowaniu | CSV, JSON, Sheets, Airtable, webhooki | Tak | Darmowe 100 kredytów; istnieją płatne plany |
| Octoparse | Trudniejsze (aplikacja desktopowa) | Bardzo mocne po konfiguracji | Tak, przez workflow lub szablony | Tak (AJAX, nieskończone przewijanie) | Najmocniejsza obsługa anty-bot (rotacja IP, CAPTCHA) | CSV, Excel, JSON, HTML, XML, bazy danych, Sheets | Tak w Standard+ | Darmowy; Basic 39 USD/mies.; cloud od ok. 83 USD/mies. |
| Bardeen | Średnio (kreator playbooków) | Dobre, jeśli powiązane z automatyzacją | Możliwe w logice workflow, ale nie jest nastawione na Shopify | Możliwe | Działa w przeglądarce, anty-bot nie jest głównym celem | CSV, Sheets, Airtable, Notion | Tak, przez automatyzacje oparte na czasie i dacie | Darmowe 100 kredytów; Basic 10 USD/mies.; Premium 50 USD/mies. |
| Listly | Bardzo łatwe (wykrywanie list jednym kliknięciem) | Najlepsze tylko dla widocznych wierszy list | Nie | Ograniczone do wykrytej struktury listy | Minimalna | Excel, Sheets, CSV/JSON API w planie Business | Tak w Business | Darmowe 10 URL-i/mies.; Light 30 USD/mies.; Business 90 USD/mies. |
Szybki werdykt według priorytetu
Jeśli potrzebujesz najgłębszych danych produktowych Shopify przy minimalnej konfiguracji, połączenie AI + wzbogacania podstron w Thunderbit jest najsilniejsze. Jeśli potrzebujesz całkowicie darmowego, szybkiego i prostego eksportu, Instant Data Scraper sprawdza się przy prostych stronach. Jeśli chcesz pełnej kontroli i nie przeszkadza Ci budowanie przepisów, Web Scraper lub Octoparse dadzą Ci tę moc. A jeśli Twoim prawdziwym celem jest scrape → automatyzacja → wysyłka do CRM, warto spojrzeć na Bardeen.
Scrapowanie samej strony listingu to tylko połowa pracy: workflow wzbogacania podstron
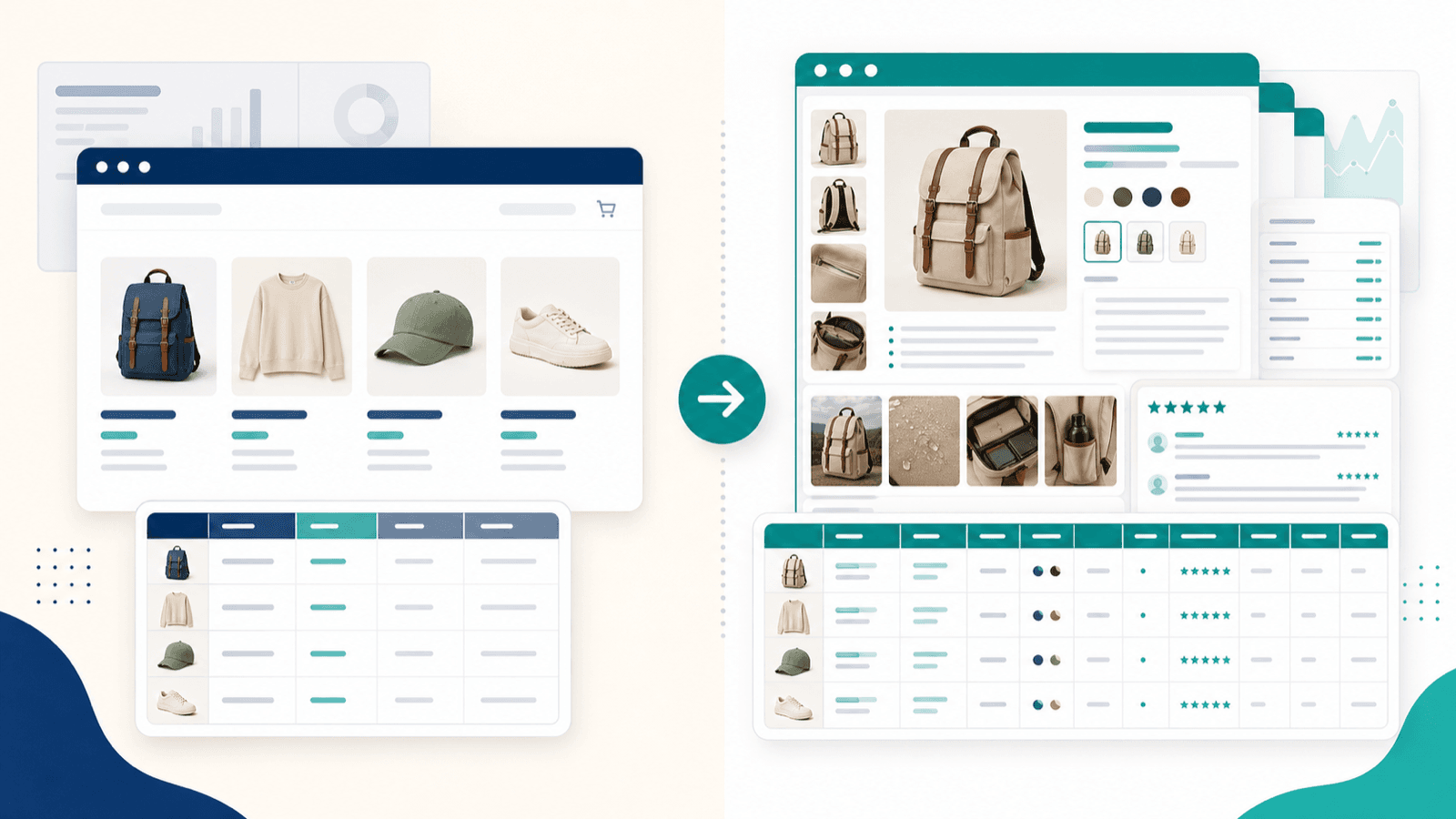
To sekcja, którą chciałbym zobaczyć w każdym innym artykule o scraperach Shopify — bo to największa luka w konkurencyjnych materiałach i jednocześnie problem nr 1, o którym słyszę od użytkowników e-commerce.
Gdy scrapujesz stronę kolekcji Shopify (stronę listingu), dostajesz dane powierzchowne: tytuły, ceny, miniatury, czasem skrócony opis. Ale pola, których naprawdę potrzebujesz do analizy konkurencji, importu katalogu czy badania dropshippingu, znajdują się na indywidualnych stronach produktów.
Co dostajesz ze strony listingu, a co po wzbogaceniu podstron
| Pole danych | Tylko ze strony listingu | Po wzbogaceniu podstron |
|---|---|---|
| Tytuł produktu | ✅ | ✅ |
| Cena | ✅ | ✅ |
| Miniatura | ✅ | ✅ + wszystkie obrazy galerii |
| Krótki opis | ⚠️ Skrócony | ✅ Pełny opis HTML |
| Warianty (rozmiar, kolor) | ❌ | ✅ |
| SKU / stan magazynowy | ❌ | ✅ |
| Recenzje / oceny | ❌ | ✅ |
To ogromna różnica.
Eksport tylko ze strony listingu daje płaski, powierzchowny arkusz. Eksport po wzbogaceniu podstron daje użyteczny zbiór danych do analizy konkurencji.
Jak działa scrapowanie podstron w Thunderbit (krok po kroku)
- Wejdź na stronę kolekcji/listingu sklepu Shopify
- Kliknij „AI Suggest Fields” — Thunderbit odczytuje stronę i proponuje kolumny (tytuł, cena, obraz, link itd.)
- Kliknij „Scrape”, aby pobrać dane ze strony listingu
- Kliknij „Scrape Subpages” — AI odwiedza każdy URL produktu i dopisuje dane ze strony szczegółów (pełny opis, wszystkie obrazy, warianty, recenzje) do oryginalnej tabeli
- Wyeksportuj wzbogaconą tabelę do Excel, Google Sheets, Airtable, Notion lub CSV
Cały proces trwa kilka minut dla typowej kolekcji, a kończysz z zestawem danych, który ręcznie zajmowałby godziny.
Które inne narzędzia obsługują wzbogacanie podstron?
- Web Scraper: Tak, ale wymaga ręcznej konfiguracji sitemap z selektorami linków i child sitemap — przygotuj się na 15–20 minut konfiguracji na sklep
- Octoparse: Tak, przez kreator workflow lub szablony — mocne, ale cięższe w konfiguracji
- Data Miner: Tak, przez wieloetapowe workflow crawl — to nie jest operacja jednym kliknięciem
- Simplescraper: Koncepcja deep scraping istnieje, ale mniej „out of the box”
- Instant Data Scraper, Listly, Bardeen: Nie ma udokumentowanego wzbogacania podstron jednym kliknięciem dla Shopify
Różnica między „technicznie potrafi podążać za linkami po 20 minutach ręcznej konfiguracji” a „wzbogacanie jednym kliknięciem” to różnica między narzędziem dla inżynierów scraperów a narzędziem dla operatorów e-commerce.
Gdy products.json Shopify zawodzi — i dlaczego rozszerzenia Chrome są Twoim planem awaryjnym
Jeśli czytałeś inne poradniki o scrapowaniu Shopify, pewnie widziałeś trik z /products.json: wystarczy dodać /products.json do adresu sklepu Shopify i dostajesz uporządkowane dane produktowe w JSON. To prawdziwy endpoint i kiedy działa, bardzo się przydaje.
Jak działa products.json
Sklepy Shopify udostępniają pod adresem /products.json, który zwraca uporządkowane dane produktowe. Możesz stronicować przez ?page=2&limit=250 (maksymalnie 250 produktów na stronę).
Zwykle zwracane pola obejmują: title, body_html, vendor, product_type, tags, published_at, variants (z price, compare_at_price, sku, available) oraz images.
Czego products.json nie obejmuje
- Brak danych o recenzjach i liczbie ocen
- Ograniczone formatowanie opisu w porównaniu z renderowaną stroną
- Niestandardowe metafields często nie są uwzględnione
- Obrazy na poziomie wariantów mogą być niespójne
- Brak renderowanych treści merchandisingowych, odznak czy social proof
Kiedy products.json przestaje działać
W dniu 27 kwietnia 2026 r. uruchomiłem bezpośrednie testy HTTP na ośmiu prawdziwych sklepach Shopify. Wyniki były wymowne:
| Sklep | Wynik |
|---|---|
| kith.com | ✅ Działa — czysty JSON |
| colourpop.com | ✅ Działa |
| allbirds.com | ✅ Działa |
| brooklinen.com | ✅ Działa |
| negativeunderwear.com | ✅ Działa |
| gymshark.com | ❌ Zablokowane — 403 HTML zamiast JSON |
| mvmt.com | ⚠️ Częściowo wyłączone — strona HTML 200, nie JSON |
| fashionnova.com | ❌ Wyłączone — 404 |
Pięć z ośmiu zwróciło czysty JSON. Trzy nie.
Użytkownicy forów raportują to samo: „Z jakiegoś powodu niektóre sklepy Shopify decydują się nie udostępniać products.json.” Sklepy chronione hasłem, z niestandardową konfiguracją API oraz domeny chronione przez Cloudflare mogą zepsuć ten schemat.
Plan awaryjny: rozszerzenie Chrome
Gdy products.json nie jest dostępne, scraper w formie rozszerzenia Chrome pobiera dane bezpośrednio z renderowanej strony (DOM). To podstawowa wartość scraperów przeglądarkowych: widzą i wyciągają to, co widzisz w swojej przeglądarce, niezależnie od dostępności API. Dzięki temu rozszerzenia Chrome są niezawodnym planem B — a często planem A, gdy potrzebujesz danych z renderowanej strony, takich jak recenzje, treści merchandisingowe czy pełne galerie obrazów.
Ochrona anty-bot: co naprawdę dzieje się podczas scrapowania sklepów Shopify
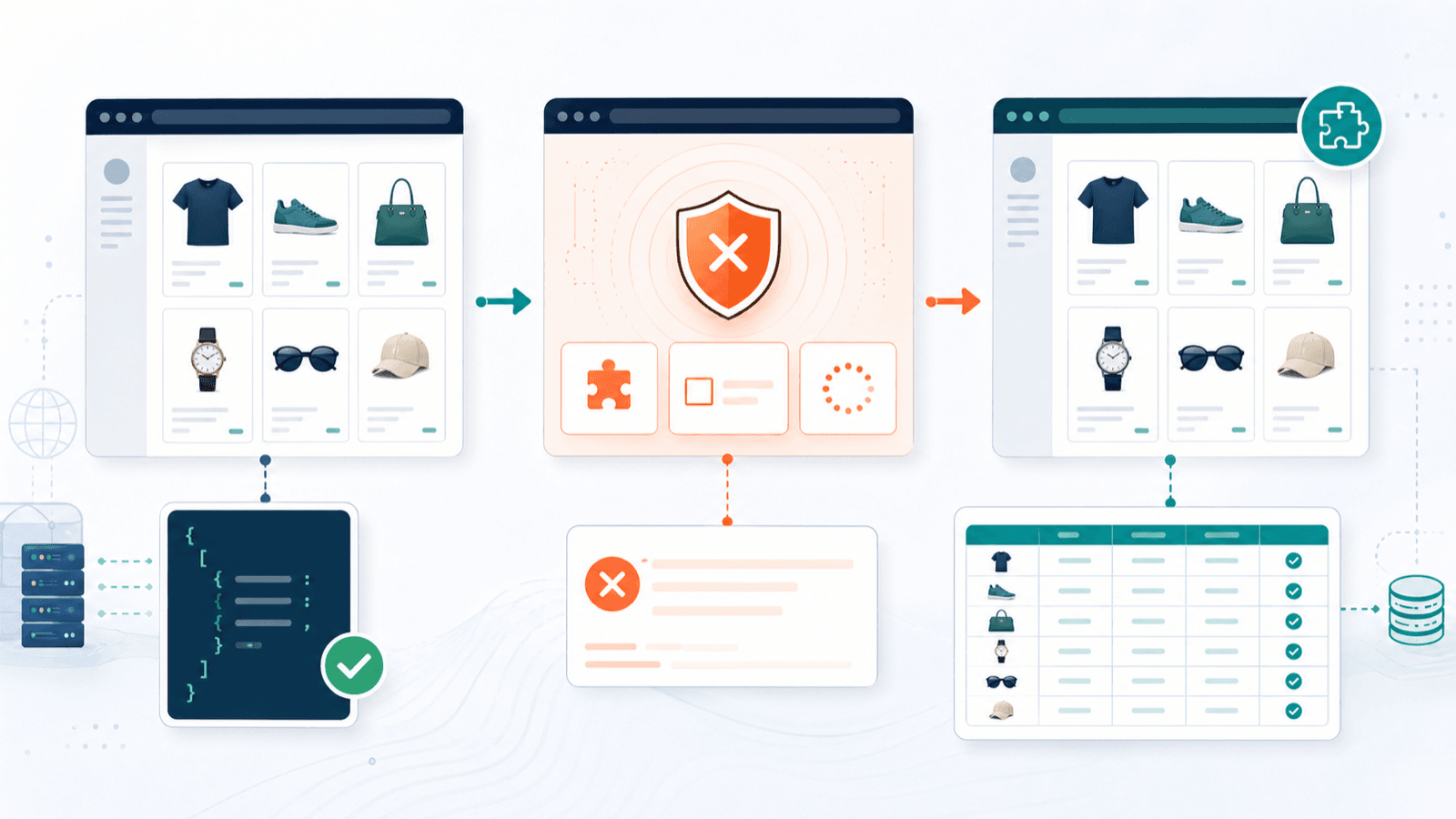
Większość artykułów o scraperach Shopify udaje, że każdy sklep jest szeroko otwarty. Nie jest. , że 99,2% sklepów Shopify korzysta z infrastruktury Cloudflare. To nie znaczy, że każdy sklep agresywnie blokuje scrapery, ale oznacza, że infrastruktura do blokowania jest wszędzie.
W praktyce wygląda to tak:
Łatwe do scrapowania
- Publiczne sklepy bez agresywnej ochrony Cloudflare
- Sklepy z włączonym
products.json - Sklepy ze standardowymi motywami Shopify (spójna struktura DOM)
Trudniejsze do scrapowania
- Sklepy chronione przez Cloudflare (wyzwania CAPTCHA, Turnstiles)
- Sklepy wymagające logowania lub chronione hasłem
- Sklepy Shopify Plus z niestandardowymi warstwami bezpieczeństwa
- Sklepy stosujące agresywne limity zapytań
Jak każde narzędzie radzi sobie z anty-bot
This paragraph contains content that cannot be parsed and has been skipped.
Dwa tryby scrapowania Thunderbit — cloud i browser — są tu naprawdę istotne. Tryb cloud jest szybki do masowego pobierania z publicznych sklepów. Tryb browser używa Twojej rzeczywistej sesji Chrome, gdy ochrona anty-bot tego wymaga. Ta elastyczność uratowała mnie na gymshark.com, gdzie żądania cloud były blokowane, ale tryb browser działał bez problemu.
Planowane scrapowanie Shopify: monitoruj ceny i stany magazynowe w czasie
Jednorazowe scrapowanie jest przydatne. Ale zespoły operacyjne e-commerce zazwyczaj potrzebują ciągłej wiedzy o konkurencji — nie tylko jednego zrzutu. Zmiany cen, wahania stanów magazynowych, nowe premiery produktów: wszystko dzieje się stale. Jeden użytkownik na forum ujął to jasno: „Bardziej pomocne byłoby widzieć ich bieżący poziom zapasów i zrzuty pokazujące, jak ten poziom spada.”
Mimo to prawie żaden konkurencyjny artykuł nie wspomina o planowanym lub cyklicznym scrapowaniu. To wyraźna luka.
Jak działa planowane monitorowanie Shopify
- Ustaw cykliczne scrapowanie strony kolekcji lub stron produktów konkurenta
- Dane przy każdym uruchomieniu eksportują się do Google Sheets (lub Airtable), tworząc szereg czasowy cen i stanów magazynowych
- Wykorzystuj dane do śledzenia: obniżek/podwyżek cen, braków towaru, nowych produktów, wzorców sezonowych
Konfiguracja planowanego scrapowania w Thunderbit
Thunderbit robi to absurdalnie prosto.
Opisujesz harmonogram zwykłym językiem (np. „w każdy poniedziałek o 9:00”), podajesz adresy URL sklepu Shopify i klikasz „Schedule”. Thunderbit uruchamia scrapowanie automatycznie i eksportuje dane do wybranego miejsca docelowego. Bez cronów, bez kodu, bez zewnętrznego harmonogramu.
Obsługa harmonogramu we wszystkich 8 narzędziach
| Narzędzie | Harmonogram? |
|---|---|
| Thunderbit | Tak — harmonogram w zwykłym języku |
| Instant Data Scraper | Nie |
| Web Scraper | Tak — w planach cloud |
| Data Miner | Istnieją automatyczne crawl, ale to nie najprostsze harmonogramowanie |
| Simplescraper | Tak |
| Octoparse | Tak — w Standard i wyżej |
| Bardeen | Tak — przez automatyzacje oparte na czasie i dacie |
| Listly | Tak — w planie Business |
Jeśli ciągłe monitorowanie konkurencji jest częścią Twojego procesu, to jest to kluczowy wyróżnik. Większość darmowych rozszerzeń Chrome w ogóle tego nie oferuje.
Które rozszerzenie Chrome do Shopify Scraper pasuje do Twojego przypadku?

Zamiast ogólnego „wybierz to, co Ci się podoba”, oto macierz decyzyjna dopasowana do konkretnych zastosowań:
| Przypadek użycia | Najlepsza rekomendacja | Dlaczego |
|---|---|---|
| Badanie cen konkurencji | Thunderbit | Listing + wzbogacanie podstron + harmonogram = pełny workflow cenowy |
| Szybki jednorazowy eksport | Instant Data Scraper | Najszybsza darmowa droga, gdy potrzebujesz tylko widocznych danych listy |
| Import katalogu do własnego sklepu Shopify | Thunderbit | Pełne dane z podstron + eksport CSV/Excel przyjazny importowi do Shopify |
| Ciągłe monitorowanie cen/stanu magazynowego | Thunderbit lub Octoparse | Najłatwiejsze harmonogramowanie bez kodu vs. najmocniejsze harmonogramowanie w stylu enterprise |
| Generowanie leadów (kontakty właścicieli sklepów) | Thunderbit | Wbudowane ekstraktory e-mail/telefonu + uporządkowany eksport |
| Złożone automatyzacje wieloetapowe | Bardeen | Scrapuj, wzbogacaj i przekazuj do aplikacji dalszego procesu w jednym workflow |
| Użytkownicy techniczni, którzy chcą pełnej kontroli | Web Scraper lub Octoparse | Najlepsza ręczna kontrola nad selektorami, przepływem i logiką ekstrakcji |
Podsumowanie
Scrapowanie Shopify w 2026 roku nie dotyczy pytania, czy da się pobrać dane produktowe — chodzi o to, jak głęboki, szybki i powtarzalny jest Twój workflow. Większość artykułów w tej przestrzeni kończy na stronie listingu. Prawdziwa wartość leży we wzbogacaniu podstron, planowanym monitoringu i radzeniu sobie z niespodziankami anty-bot, które prawdziwe sklepy Shopify rzucają na Twoją drogę.
Jeśli chcesz zobaczyć, jak to wygląda w praktyce — od strony kolekcji do w pełni wzbogaconego zbioru danych w kilka kliknięć — wypróbuj . A jeśli Thunderbit nie jest idealnym wyborem, Instant Data Scraper to solidny darmowy punkt startowy do prostych zadań, a Web Scraper i Octoparse to mocne opcje dla użytkowników technicznych, którzy chcą większej kontroli.
Miłego scrapowania — i niech Twoje dane produktowe zawsze będą kompletne, uporządkowane i bogate w warianty.
FAQ
1. Czy scrapowanie danych ze sklepów Shopify jest legalne?
Publicznie dostępne dane produktowe w sklepach Shopify są zazwyczaj dostępne dla każdego, kto odwiedza stronę. To powiedziawszy, legalność zależy od Twojej jurysdykcji, regulaminu sklepu i tego, co zrobisz z danymi. Scrapowanie publicznych cen do analizy konkurencji jest powszechną praktyką; kopiowanie treści w całości do ponownej publikacji wiąże się z większym ryzykiem. To nie jest porada prawna — w konkretnej sytuacji skonsultuj się ze specjalistą.
2. Czy mogę scrapować sklepy Shopify wymagające logowania lub hasła?
Tak, ale potrzebujesz scrapera działającego w przeglądarce, który korzysta z Twojej zalogowanej sesji Chrome. Cloud scrapery zazwyczaj nie mają dostępu do stron chronionych logowaniem. Tryb browser w Thunderbit, lokalny Web Scraper oraz workflow logowania w Simplescraper obsługują taki scenariusz.
3. Ile produktów mogę jednocześnie pobrać ze sklepu Shopify?
To zależy od narzędzia i planu. Endpoint products.json Shopify stronicuje po . Tryb cloud Thunderbit przetwarza do 50 stron naraz. W darmowych planach większości narzędzi obowiązują limity stron, wierszy lub kredytów — więc sprawdź limity swojego planu, zanim uruchomisz duże zadanie.
4. Jaka jest różnica między cloud scraping a browser scraping w Shopify?
Cloud scraping działa na zdalnych serwerach — jest szybszy i lepszy dla publicznych sklepów bez ochrony anty-bot. Browser scraping używa lokalnej sesji Chrome, więc potrafi obsłużyć sklepy chronione przez Cloudflare, wymagające logowania lub wrażliwe regionalnie. Thunderbit oferuje oba tryby, a wybór zwykle sprowadza się do tego, czy sklep blokuje zdalne żądania.
5. Czy mogę bezpośrednio eksportować pobrane dane Shopify do Google Sheets lub Airtable?
Tak, ale nie wszystkie narzędzia to obsługują. Thunderbit eksportuje do Google Sheets, Airtable, Notion, Excel, CSV i JSON — wszystko za darmo. Data Miner i Listly obsługują Google Sheets. Simplescraper obsługuje Sheets i Airtable. Octoparse obsługuje Google Sheets w wyższych planach. Bardeen integruje się z Sheets, Airtable i Notion. Instant Data Scraper eksportuje tylko do CSV i XLSX, bez bezpośredniej integracji z Sheets.
Dowiedz się więcej