
Iedereen praat over data-gedreven besluitvorming, maar vaak wordt vergeten hoeveel tijd en moeite dataverzameling eigenlijk kost. Als je ooit gegevens handmatig hebt verzameld, weet je hoe omslachtig dat is. Ik heb genoeg bedrijven gezien die vastliepen met hun data-gedreven strategieën door inefficiënte dataverzameling. Zit jij in hetzelfde schuitje? Dan heeft dit artikel een paar frisse oplossingen voor je.
💡 In dit artikel duiken we in de wereld van data scraping en hoe die mee-evolueert met technologie. We kijken naar de nadelen van ouderwetse methoden, leggen de voordelen van AI-gedreven data scraping uit en geven praktische tips voor gebruik in de echte wereld.
Wat is data scraping?
Data scraping, of web scraping, draait om het ophalen van gestructureerde informatie van webpagina’s met behulp van tools, vaak in de vorm van tabellen. Het is een enorm efficiënte manier om snel grote hoeveelheden data te verzamelen. Je kunt bijvoorbeeld openbare gegevens uit Google Maps halen voor leadgeneratie, e-commerce-SKU’s scrapen van Amazon voor doorverkoop of marktanalyse, of reviews van sociale media ophalen van Yelp voor klantinzichten.
De technologische verschuiving in data scraping
Vroeger leek dataverzameling iets wat alleen techneuten aankonden, of het betekende urenlang handmatig knippen en plakken. Maar inmiddels is het 2025 en speelt AI een steeds grotere rol. Data scraping is allang niet meer alleen voor programmeurs of simpele automatisering.
Traditionele methoden lopen tegen hun grenzen aan
Moderne websites brengen ook steeds meer uitdagingen met zich mee: dynamisch geladen content (bijvoorbeeld met React/Vue-frameworks), de opkomst van multimodale data (tekst, video, afbeeldingen) en niet-gestandaardiseerde datastructuren (meerdere sjablonen op dezelfde pagina). Recente onderzoeken wijzen op drie grote problemen bij traditionele webscrapingmethoden:
-
Een bodemloze put aan onderhoudskosten
Traditionele webscrapers hebben voortdurend handmatig onderhoud nodig (ongeveer 3–5 uur per maand per website). Wanneer een site wordt bijgewerkt of van front-endframework verandert, valt 60% van de XPath-selectors uit. AI-tools kunnen dankzij taalmodellen en code-inzicht tot 90% van de structurele veranderingen automatisch bijsturen, waardoor onderhoudskosten met 60–80% dalen. Bij moderne sites die met React/Vue zijn gebouwd, houdt AI data scraping stabiel via semantisch begrip, zelfs als class-namen veranderen. -
Beperkte datadimensies
Traditionele methoden halen alleen gestructureerde data op en missen waardevolle informatie zoals:- Data in afbeeldingen
- Tekstuele informatie in artikelen
- Ongestructureerde data zonder HTML-tags
-
Problemen met datakwaliteit
Traditionele methoden hebben moeite met dynamische content, wat leidt tot onvolledige of foutieve data:- Bij gepagineerde data (zoals productlijsten in e-commerce) pakken traditionele scrapers slechts 30–50% van de content op het eerste scherm mee.
- Pagina’s met oneindig scrollen (zoals social media feeds) verliezen meer dan 60% van de cruciale data.
- Hoge foutpercentages bij het koppelen van ongestructureerde data (zoals verkeerd uitgelijnde lijsten).
Hier komen AI-gedreven tools zoals Thunderbit in beeld. Hieronder leg ik de voordelen uit.
De opkomst van AI-data scraping
Data van elke website scrapen met AI Get Started Free
In 2025 hebben AI, en vooral grote taalmodellen (LLM’s), flinke sprongen gemaakt. Deze modellen begrijpen en genereren natuurlijke taal, kunnen complexe data-analyse uitvoeren en bieden efficiëntere oplossingen. Veel data scraping tools gebruiken inmiddels LLM’s om de beperkingen van traditionele methoden te omzeilen. Na het testen van 13 data scraping tools in de afgelopen maanden, raad ik Thunderbit AI Web Scraper aan.
Waarom Thunderbit eruit springt:
-
Revolutionaire interactie:
Gebruikers typen simpele opdrachten in natuurlijke taal, waarna het systeem automatisch een scrapingplan maakt. Dat scheelt 87% configuratietijd vergeleken met traditionele tools. -
Grote voordelen van lokale scraping:
Als browserextensie biedt Thunderbit:- Direct data scrapen
- Scrapen van dynamische pagina’s en pagina’s met oneindig scrollen
- Scrapen van pagina’s waarvoor je moet inloggen
-
Krachtige verwerking van multimodale data:
Thunderbit kan met allerlei datatypes overweg, zoals:- Gegevens uit tekst in artikelen extraheren
- Financiële tabellen uit pdf’s halen
- Data uit meerdere afbeeldingen herkennen en er tabellen van maken
- Videobijschriften scrapen en samenvatten
Met Thunderbit kun je allerlei dataverzamelingsscenario’s eenvoudig aanpakken. Laten we bekijken hoe je Thunderbit gebruikt.
Hoe je data scrapt met AI
Volg deze vier stappen om gebruik te maken van Thunderbit’s krachtige AI webscrapingmogelijkheden:
-
Installeer de browserextensie
Ga naar de website van Thunderbit en download de Thunderbit-extensie uit de Chrome Web Store. Zodra die is geïnstalleerd, zet je de extensie vast op je browserwerkbalk. -
Registreer je en ontvang gratis credits
Maak in de extensie een account aan om proefcredits te krijgen. Met die credits kun je kernfuncties zoals AI web scraping, formulier-autovullen en slimme samenvattingen uitproberen. Het is slim om eerst gratis in de playground te spelen voordat je credits inzet, zodat je ziet hoe goed de tool werkt. -
Start slimme scraping
Open een template vanuit de zijbalk van Thunderbit. Gebruik taalbeschrijvingen om de gewenste data en het datatype te kiezen, stel specifieke extractieformaten in of pas andere details aan. Klik daarna op scrape om het dataproces te starten.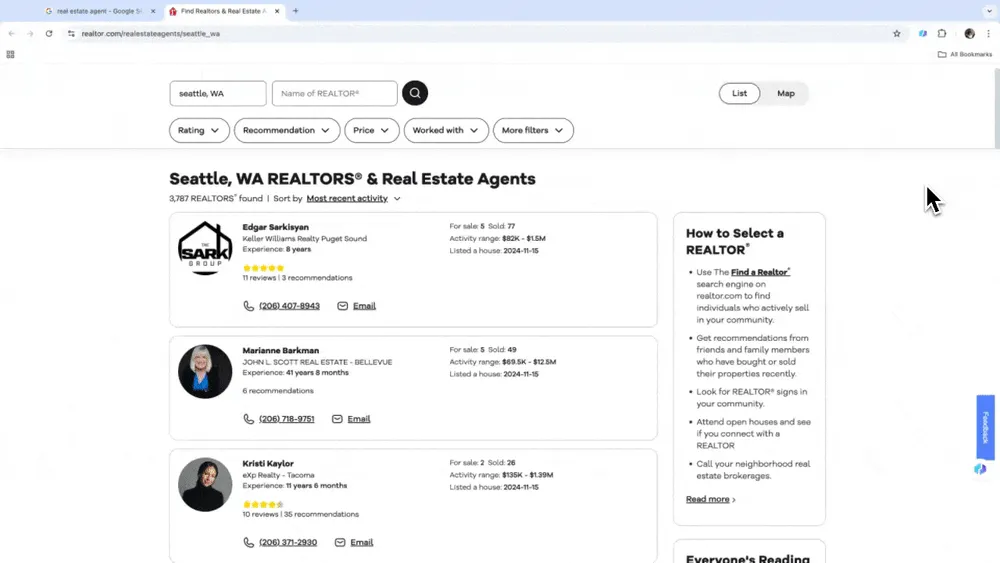
Geavanceerde scrapingfuncties (Pro Tier)
Door je te abonneren op Thunderbit’s Pro Tier (of door te starten met een gratis proefperiode), krijg je toegang tot deze functies:
-
Verwerking van multimodale data
Geschikt voor complexe scenario’s zoals het parsen van pdf-documenten (financiële rapporten/producthandleidingen), het extraheren van gegevens uit afbeeldingen (prijstags/specsheets) en het scrapen van videobijschriften. Het systeem standaardiseert ongestructureerde data automatisch. -
Diepgaande subpagescraping
Je kunt optioneel alle sublinks op een pagina meenemen (zoals productdetailpagina’s/recensiepagina’s), gerelateerde data slim herkennen en automatisch samenvoegen in de hoofddatatable. Perfect voor e-commercecatalogi, vastgoedoverzichten en meer. -
Vooraf gebouwde templatelibrary
Gebruik direct geoptimaliseerde scrapingtemplates voor meer dan 30 platforms, zoals TikTok, Amazon en Zillow. Deze passen zich automatisch aan wijzigingen in de paginastructuur aan. Nieuwe gebruikers besparen gemiddeld 83% configuratietijd. -
Bulk scrapingtaak
Voer meerdere scrapingtaken tegelijk uit, met ondersteuning voor het importeren van een lijst met URL’s voor batchscraping. -
Slim omgaan met paginering
Herkent en scrapt automatisch gepagineerde content, inclusief knoppen als ‘meer laden’ en paginanavigatie, en ondersteunt pagina’s met oneindig scrollen. Getest op volledige scraping van meer dan 200 pagina’s met e-commerceproductlijsten.
Praktische handleiding voor Thunderbit
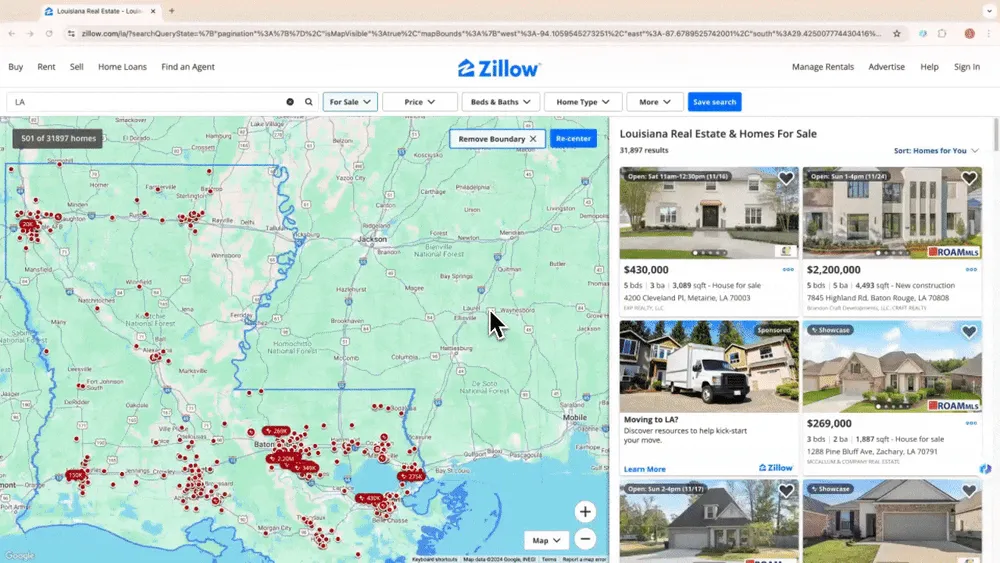
Scenario 1: Vastgoedgegevens verzamelen
Als je makelaar bent en gegevens van Zillow wilt verzamelen, of als investeerder op zoek bent naar interessante kansen, dan kan een betrouwbare webscraper je beste hulp zijn. Thunderbit’s AI web scraper laat je eenvoudig belangrijke objectinformatie uit Zillow halen, zodat je actueel en concurrerend blijft. Bekijk een instructievideo over hoe je Zillow scrapt met Thunderbit.
Scenario 2: Talent en leads vinden
Werk je in HR en zoek je talent, of ben je sales en op zoek naar nieuwe leads? Dan kan een betrouwbare webscraper een krachtige assistent zijn. Met Thunderbit kun je nuttige contact- en bedrijfsgegevens halen uit openbare websites, directories en profielpagina’s, zodat je werving en leadbeheer veel efficiënter worden. Na gebruik merk je dat tijdrovend handmatig zoeken en kopiëren en plakken verleden tijd zijn. Voor een kant-en-klare workflow kun je beginnen met de Website Contact Scraper.
Scenario 3: Marktanalyse en klanttargeting
Ben je ondernemer en verzamel je locatiegebonden data voor marktanalyse, of werk je in sales en zoek je lokale zakelijke leads? Dan kan een betrouwbare webscraper het verschil maken. Met Thunderbit haal je eenvoudig belangrijke gegevens uit Google Maps, zodat je beter onderbouwde beslissingen kunt nemen en je outreach kunt optimaliseren.
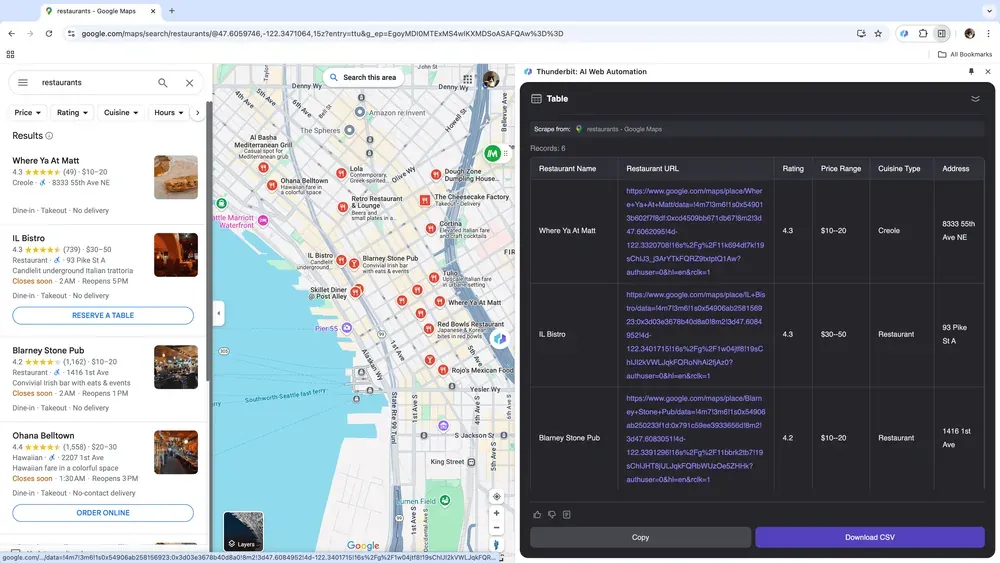
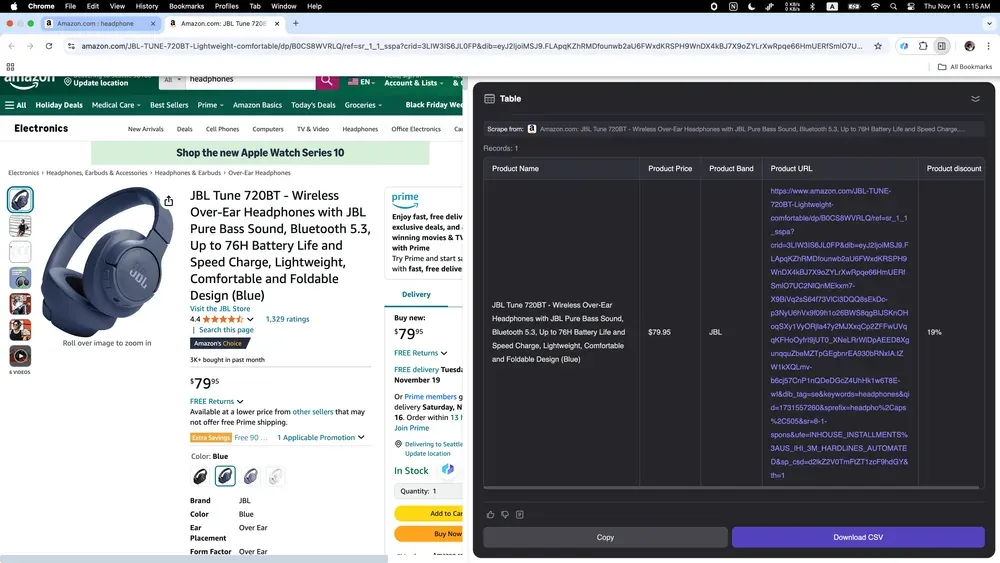
Scenario 4: E-commerce data-analyse
Ben je online verkoper en wil je concurrenten beter begrijpen, of ondernemer die markttrends volgt? Dan is Thunderbit echt iets voor jou! Het verzamelt eenvoudig allerlei productdata van Amazon, waaronder uitgebreide beschrijvingen, prijzen en gebruikersreviews.
Thunderbit AI web scraper geeft een nieuwe betekenis aan hoe zakelijke gebruikers data verzamelen: sneller, eenvoudiger en efficiënter dan ooit. Of je nu op zoek bent naar woningen in de vastgoedmarkt, potentiële klanten in de talentmarkt, of trends analyseert in e-commerce, AI webscrapers besparen je talloze uren en een hoop gedoe. Omarm de kracht van AI in webscraping en ervaar een flinke boost in productiviteit. Klaar om te beginnen? Probeer Thunderbit en zet de eerste stap naar slimmer webscrapen.
Probeer Thunderbit AI Web Scraper
Exclusieve tips voor datacleaning
Bij traditionele scrapers begint de echte uitdaging pas ná het scrapen: datacleaning. Thunderbit’s AI kan tijdens het scrapen al datacleaning uitvoeren met behulp van LLM’s, waardoor de werkdruk voor opschoning met 83% daalt dankzij deze innovatieve functies:
Tip 1: Slimme veldafstemming
Bij data uit meerdere bronnen met verschillende structuren (zoals tegelijk scrapen van LinkedIn en Zillow) maakt Thunderbit’s AI automatisch semantische mapping:
- Herkent automatisch veldovereenkomsten tussen verschillende databronnen (bijv. "price" ↔ "售价" ↔ "Price")
- Voegt vergelijkbare velden slim samen (bijv. "area" en "square feet")
- Standaardiseert data over platforms heen (bijv. LinkedIn’s "current position" en Zillow’s "property status" samen als tagdata)
Tip 2: Contextbewuste aanvulling
Met het contextbegrip van grote taalmodellen haalt Thunderbit een toonaangevende datavullingsgraad van 99%:
- Adresaanvulling: vult automatisch stad/provincie of staat in op basis van postcode (bijv. input 10001 → New York City, NY)
- Loopbaaninferentie: voorspelt mogelijke werkervaring op basis van iemands LinkedIn-opleiding
Tip 3: Data-optimalisatie
- Meertalige vertaling (ondersteunt realtime vertaling in 12 talen, waaronder Engels, Chinees en Japans)
- Slimme samenvatting (vat een productomschrijving van 500 woorden samen in drie kernverkoopargumenten)
- Eenheden uniformeren (zet automatisch square feet ↔ square meters, Fahrenheit ↔ Celsius om)
- Formaat standaardiseren (datums naar YYYY-MM-DD, valuta naar USD)
Tip 4: Kwaliteitscontrole
- Slimme foutcorrectie: herstelt automatisch formaatfouten (bijv. telefoonnummer +01 138-1234-5678 → +113812345678)
- Logische validatie: controleert of "year built" eerder ligt dan "last renovation time"
Tip 5: AI-tagging
Genereert automatisch slimme tags via natuurlijke taalverwerking:
- Sentimentanalyse-tags (labelt klantreviews automatisch als positief/neutraal/negatief)
- Zakelijke-waardetags (labelt automatisch "high-potential clients"/"properties to follow up on")
- Brancheclassificatietags (voegt automatisch labels als "tech|finance|healthcare" toe aan LinkedIn-profielen)
De nadelen van data scraping
Hoewel data scraping enorme waarde biedt, is het belangrijk om ook de uitdagingen te erkennen waar bedrijven mee te maken kunnen krijgen. Juridische aandachtspunten staan voorop: regels zoals de GDPR en CCPA stellen strikte eisen aan dataverzameling, waardoor zorgvuldige naleving van privacywetgeving noodzakelijk is. Websites zetten vaak geavanceerde verdedigingsmechanismen in, zoals Cloudflare, om scraping te detecteren en te blokkeren via IP-restricties.
De toekomst van data scraping in het AI-tijdperk
De evolutie van AI verandert webscraping in een intuïtieve oplossing voor ondernemingen. Stel je voor dat je simpelweg een domein invoert (zoals zillow.com) en je verzoek doet (bijvoorbeeld: "scrape alle woningaanbiedingen in New York City"), waarna AI automatisch alle relevante datapunten in kaart brengt — van objectdetails tot prijstrends — zonder handmatige configuratie. Deze slimme systemen integreren gescrapete data naadloos in bedrijfsprocessen, door bijvoorbeeld LinkedIn-prospectinformatie automatisch naar CRM’s te sturen of e-commercegegevens naar analyticsdashboards te pushen. Geavanceerde patroonherkenning maakt voorspellende scraping mogelijk, waarmee systemen proactief voorraadwijzigingen of opkomende markttrends monitoren. Belangrijk is ook dat AI compliance dynamisch afhandelt: scrapingparameters worden realtime aangepast aan veranderende regelgeving, terwijl transparante audittrails behouden blijven.
Deze AI-gedreven verschuiving democratiseert niet alleen de toegang tot cruciale bedrijfsinzichten, maar verandert fundamenteel hoe organisaties omgaan met webdata. Naarmate deze technologieën verder volwassen worden, zullen vroege gebruikers van AI-gestuurde scrapingoplossingen zoals Thunderbit een duidelijk concurrentievoordeel behalen in data-gedreven besluitvorming.
Veelgestelde vragen
-
Wat is Thunderbit? Thunderbit is een slimme browserextensie op basis van grote taalmodellen (LLM) die is ontwikkeld voor moderne behoeften op het gebied van dataverzameling. Het biedt niet alleen AI webscraping, maar ook multimodale gegevensverwerking, met ondersteuning voor uitgebreide data-extractie uit dynamische webpagina’s, pdf-documenten, afbeeldingen en video’s. Als lokale browseroplossing kan het direct omgaan met pagina’s waarvoor je moet inloggen (zoals LinkedIn) en zich automatisch aanpassen aan wijzigingen in moderne front-endframeworks.
-
Hoe werkt Thunderbit’s AI web scraper? Thunderbit’s AI web scraper gebruikt AI om gestructureerde data uit websites te halen. Gebruikers kunnen op "AI Suggest Columns" klikken om AI te laten voorstellen hoe de huidige site gescrapt moet worden, en daarna op "Scrape" om de data te verzamelen. Het kan data van elke website, pdf of afbeelding in slechts twee klikken verwerken.
-
Wat is het verschil tussen list scraping en subpage scraping? List scraping is geoptimaliseerd voor gepagineerde scenario’s (zoals productlijsten in e-commerce) en herkent automatisch de paginalogica om duizenden records te scrapen. Subpage scraping gebruikt een boomstructuur voor verzameling (zoals Zillow woningoverzichten → detailpagina’s → plattegronden) en legt automatisch hoofd-subtabelrelaties vast via semantische associatie.
-
Kunnen niet-programmeurs Thunderbit gebruiken? Thunderbit heeft een interactieontwerp in natuurlijke taal: gebruikers beschrijven simpelweg wat ze nodig hebben, bijvoorbeeld "naam, e-mail, telefoon", en het systeem maakt automatisch een scrapingplan. Onze testdata laat zien dat 85% van de gebruikers hun eerste dataverzameling binnen 10 minuten afrondt, zonder enige kennis van webprogrammering.
-
Met welke soorten data kan Thunderbit overweg? Thunderbit ondersteunt slimme herkenning van veel datatypen:
- Gestructureerde data: tabellen, lijsten (bijv. productspecificaties van Amazon)
- Ongestructureerde data: recenstietekst, pdf-documenten (automatische herkenning)
- Multimodale data: prijstags in afbeeldingen, extractie van videobijschriften
- Dynamische data: content met oneindig scrollen, afbeeldingen die pas later laden
- Gerelateerde data: koppeling tussen pagina’s (bijv. LinkedIn-contacten → bedrijfsinformatie)
-
Hoe begin je met Thunderbit? Lees meer over onze scrapingmogelijkheden of bekijk onze templatelibrary om direct te starten.
Meer informatie:
- De beste webscrapingtools en software in 2025
- Hoe je elke website kunt scrapen met AI
- Hoe je Thunderbit instelt
Probeer AI Web Scraper Get Started Free




