
Vorige week vertelde een gebruiker me dat hij een hele middag had zitten handmatig kopiëren van loodgietersvermeldingen van SuperPages naar een spreadsheet — 47 regels in drie uur. Zijn polsen deden pijn, zijn data stond vol tikfouten en e-mailadressen had hij nog steeds niet. Dat raakte me, want ik heb hetzelfde meegemaakt. Juist voor dit soort gedoe hebben we gebouwd.
SuperPages is een van de langst bestaande Amerikaanse lokale bedrijvengidsen, beheerd door Thryv, met een brede dekking van grote steden en categorieën — loodgieters, tandartsen, advocaten, HVAC-technici, noem maar op. Oudere technische documentatie omschreef het als een nationale Yellow Pages-database met meer dan 11 miljoen vermeldingen, en ook vandaag laat de site nog steeds enorm uitgebreide lokale categorieën zien. Het probleem is niet om vermeldingen te vinden. Het probleem is om er een nette, verrijkte leadlijst van te maken zonder je hoofd — of je middag — te verliezen.
Volgens HubSpot’s 2024 Sales Trends-rapport besteden verkopers slechts zo’n 2 uur per dag echt aan verkopen — de rest gaat op aan taken zoals gegevensinvoer en onderzoek. En 81% van de salesprofessionals zegt dat AI hen kan helpen om minder tijd kwijt te zijn aan handmatig werk. In deze gids laat ik drie manieren zien om SuperPages te scrapen voor leads — van no-code AI tot Python — zodat je de methode kunt kiezen die bij je niveau past en weer kunt doen waar het echt om draait.
Wat is SuperPages (en waarom sales teams er graag leads uit halen)
SuperPages is een online bedrijvengids voor de VS waarin lokale bedrijven worden vermeld met contactgegevens, categorieën, beoordelingen en meer. Zie het als de digitale opvolger van het oude telefoonboek — alleen kun je nu zoeken op categorie en locatie, met rijkere gegevens per vermelding.
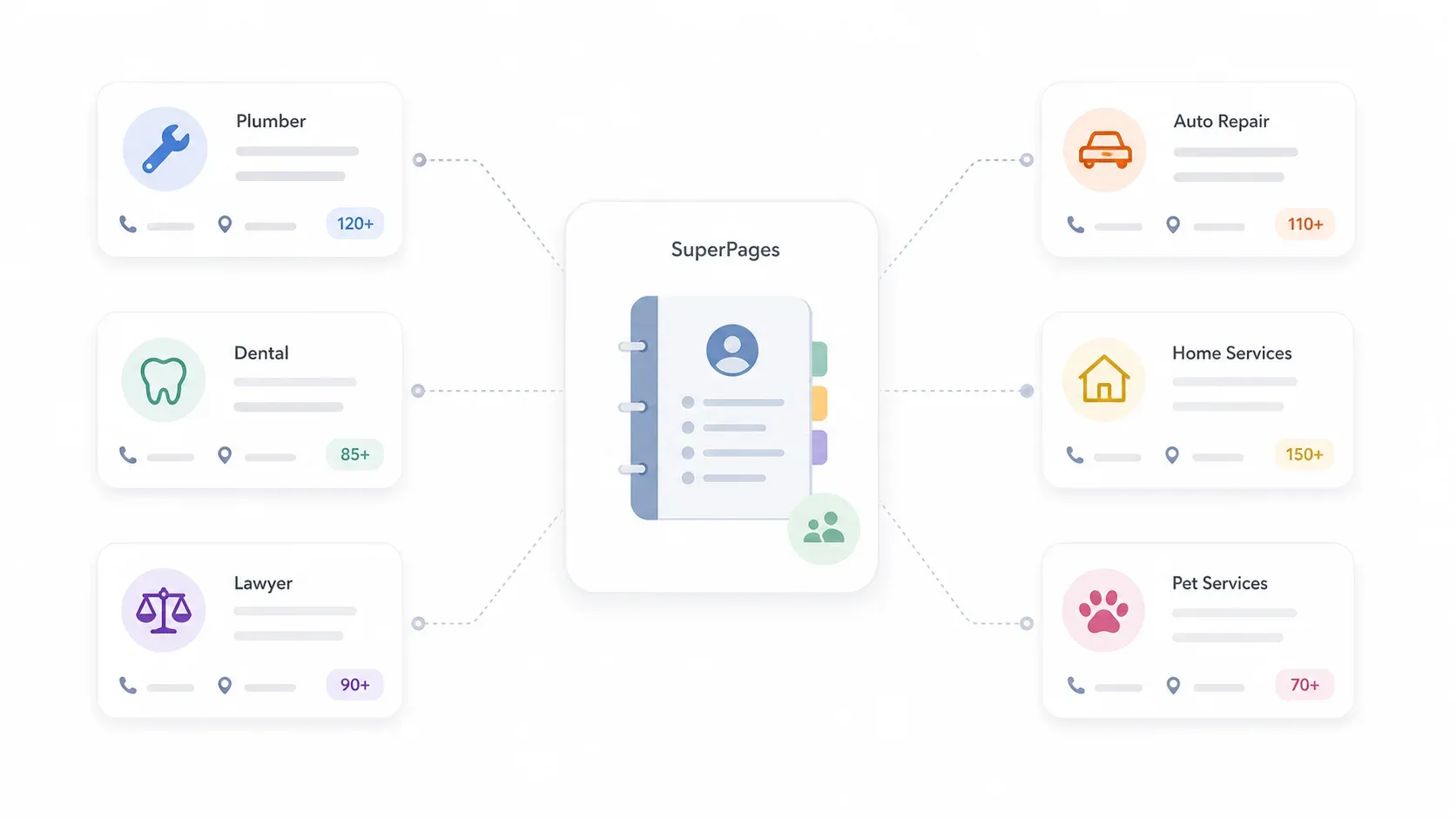
Een typische SuperPages-vermelding kan het volgende bevatten:
- Bedrijfsnaam
- Telefoonnummer
- Straatadres
- Website-URL (indien beschikbaar)
- Categorie (bijv. loodgieter, familierecht, HVAC)
- Beoordelingen en reviews
- Openingstijden (meestal op de detailpagina)
- Beschrijving (detailpagina)
Op de homepage van SuperPages worden populaire categorieën uitgelicht zoals Home Services, Plumbers, Electricians, Dentists, Legal Services, Auto Repair, Restaurants en Pet Services — precies de sectoren waar sales teams, bureaus en lokale dienstverleners op mikken voor outbound outreach.
Kort gezegd: SuperPages is een goudmijn voor iedereen die lokale bedrijven in de VS benadert. De data is gestructureerd, de dekking is breed en de categorieën sluiten goed aan op echte outbound campagnes.
Waarom SuperPages scrapen voor leads? (Belangrijkste use cases)
Handmatig door SuperPages bladeren en data naar een spreadsheet kopiëren is een zwart gat voor je productiviteit. Scraping automatiseert dat proces en levert je binnen enkele minuten een gerichte, gestructureerde lijst op in plaats van uren werk. En omdat jij de zoekopdracht bepaalt (categorie + stad + keyword), is de output vaak relevanter dan een generieke gekochte leadlijst.
Dit zijn de meest voorkomende use cases die ik van onze gebruikers zie:
| Use case | Wie profiteert | Voorbeeld |
|---|---|---|
| Lokale leadgeneratie | Sales teams, bureaus | Maak een lijst van loodgieters in Dallas voor cold outreach |
| Concurrentieonderzoek | Operations, marketing | Vergelijk beoordelingen en diensten van concurrenten in een markt |
| Marktin kaart brengen | Business development | Vind alle tandartsen in een postcodegebied voor een productlancering |
| Leveranciers vinden | Inkoop, operations | Zoek leveranciers in een regio met telefoon + website-info |
| Lokale SEO-prospecting | Bureaus | Vind bedrijven zonder website of met zwakke vermelding |
| Territoriumplanning | Field sales | Groepeer aannemers per stad, postcode of servicegebied |
De Amerikaanse B2B-markt voor leadgeneratie werd in 2024 geschat op 8,5 miljard dollar en zal naar verwachting groeien naar 18,2 miljard dollar in 2034 — de vraag naar dit soort data neemt dus zeker niet af. Een vers gescrapete lijst, toegespitst op categorie en locatie, kan gerichter zijn dan een algemene aangekochte lijst, maar moet nog steeds gecontroleerd en gededupliceerd worden voordat je gaat benaderen (daarover later meer).
Hoe de eindoutput eruitziet: voorbeeld van gescrapete data uit SuperPages
Voordat we ingaan op hoe je het doet, wil ik je laten zien wat je uiteindelijk in handen hebt. Dit is vaak het deel dat veel gidsen overslaan — maar als je er tijd in steekt, wil je ook weten wat het oplevert.
Hier is een voorbeeld van de output in tabelvorm (fictieve data, realistische structuur):
| Bedrijfsnaam | Telefoon | Adres | Website | Categorie | Beoordeling | Openingstijden | E-mail (verrijkt) |
|---|---|---|---|---|---|---|---|
| Sunset Pipe & Drain Co. | +1 213-555-0148 | 1842 W 7th St, Los Angeles, CA 90057 | sunsetpipe.example | Loodgieter | 4.6 | ma-vr 7:00-18:00 | service@sunsetpipe.example |
| Arroyo HVAC Pros | +1 626-555-0182 | 72 N Fair Oaks Ave, Pasadena, CA 91103 | arroyohvac.example | HVAC | 4.8 | ma-za 8:00-19:00 | hello@arroyohvac.example |
| Wilshire Family Dental | +1 323-555-0119 | 4100 Wilshire Blvd, Los Angeles, CA 90010 | wilshiredental.example | Tandartsen | 4.4 | ma-do 9:00-17:00 | appointments@wilshiredental.example |
| Pacific Legal Aid Group | +1 310-555-0173 | 11845 W Olympic Blvd, Los Angeles, CA 90064 | Juridische diensten | 4.2 | ma-vr 8:30-17:30 | intake@pacificlegal.example | |
| Valley Auto Repair Center | +1 818-555-0198 | 14422 Ventura Blvd, Sherman Oaks, CA 91423 | valleyautorepair.example | Autoreparatie | 4.7 | ma-za 8:00-18:00 | info@valleyautorepair.example |
| Echo Park Pet Grooming | +1 213-555-0166 | 1511 Sunset Blvd, Los Angeles, CA 90026 | echoparkpets.example | Huisdierverzorging | 4.9 | di-zo 9:00-17:00 | booking@echoparkpets.example |
Een paar dingen om op te letten:
- Van de zoekresultatenpagina: bedrijfsnaam, telefoon, gedeeltelijk adres, categorie, beoordeling, listing-URL.
- Van de detailpagina van het bedrijf (subpagina): volledig adres, openingstijden, beschrijving, reviews, soms website.
- Uit verrijking: e-mail (vaak alleen te vinden op de eigen website van het bedrijf of via verrijkingstools).
- Uit opschoning: telefoon in E.164-formaat, genormaliseerde staat/postcode, dedupe-sleutels, bron-URL en scrape-datum.
Dit is het soort output dat je direct in een CRM, een Google Sheet of een Airtable-base kunt zetten en meteen kunt gebruiken.
3 manieren om SuperPages te scrapen voor leads: snelle vergelijking

Niet iedereen heeft hetzelfde technische niveau — of hetzelfde geduld. Daarom staan hier drie methoden naast elkaar, zodat je kunt kiezen wat het beste past:
| Criteria | Thunderbit (AI no-code) | Visuele scraper (bijv. Octoparse) | Python (Requests + BS4) |
|---|---|---|---|
| Opstarttijd | ~2 min (extensie installeren) | ~15 min (workflow bouwen) | ~30 min (libraries installeren, code schrijven) |
| Coderen nodig | Nee | Nee | Ja (Python) |
| Omgaan met paginering | Ingebouwd (klik of scroll) | Configuratie vereist | Handmatige code |
| Verrijking van subpagina’s | 1-klik subpage scraping | Aparte workflow/loop nodig | Aparte script nodig |
| Anti-blokkering | Cloud Scraping regelt dit | Hangt af van plan/proxy-add-on | Zelf doen (proxies, headers, rate limits) |
| Exportopties | Excel, Google Sheets, Airtable, Notion, CSV, JSON | CSV, Excel, database | Wat je zelf programmeert |
| Beste voor | Sales teams, bureaus, niet-ontwikkelaars | Halftechnische gebruikers | Ontwikkelaars die volledige controle willen |
Mijn advies: als je binnen 2 minuten wilt beginnen met scrapen, ga dan naar Methode 1. Als je liever visuele workflows gebruikt en wat configuratie niet erg vindt, probeer Methode 2. Als je volledige controle wilt en Python kent, ga dan naar Methode 3.
Methode 1: SuperPages scrapen met Thunderbit (AI, zonder code)
Dit is de snelste weg van “ik heb een SuperPages-zoekresultaat” naar “ik heb een leadlijst.” Geen code, geen workflow builders, geen proxy-configuratie. Ik ben bevooroordeeld — we hebben Thunderbit zelf gebouwd — maar ik leg precies uit wat er gebeurt, zodat je zelf kunt beoordelen.
Moeilijkheidsgraad: Beginner
Benodigde tijd: ~5 minuten voor een volledige categorie-/stadsscrape
Wat je nodig hebt: Chrome-browser, Thunderbit Chrome-extensie (gratis versie werkt)
Stap 1: Installeer Thunderbit en open SuperPages
Ga naar de en installeer de Thunderbit-extensie. Dat kost ongeveer een minuut. Zodra die is geïnstalleerd, ga je naar een SuperPages-resultatenpagina — zoek bijvoorbeeld op “Plumbers in Los Angeles, CA” op superpages.com.
Je zou nu het Thunderbit-icoon in je browserwerkbalk moeten zien en een zijpaneel dat klaarstaat.
Stap 2: Klik op “AI Suggest Fields” om automatisch datavelden te detecteren
Open de Thunderbit-zijbalk en klik op “AI Suggest Fields.” De AI van Thunderbit leest de pagina en stelt automatisch kolommen voor op basis van wat het vindt — meestal bedrijfsnaam, telefoon, adres, website, categorie, beoordeling en listing-URL.
Je kunt kolommen aanpassen, toevoegen of verwijderen vóór het scrapen. Wil je een aangepaste kolom zoals “Heeft website?” of “Servicegebied?” toevoegen? Beschrijf het gewoon in gewone taal via de Field AI Prompt. Je kunt een kolom bijvoorbeeld opdracht geven om “telefoon te formatteren als +1XXXXXXXXXX” of “te classificeren als residentieel of commercieel.”
Je zou nu een tabelvoorbeeld moeten zien met de ingestelde kolommen in het Thunderbit-paneel.
Stap 3: Klik op “Scrape” en kijk hoe de data wordt ingevuld
Klik op de blauwe knop “Scrape”. Thunderbit haalt alle vermeldingen van de huidige pagina op en vult je tabel regel voor regel. Voor een typische SuperPages-resultatenpagina duurt dit ongeveer 30–45 seconden.
Thunderbit handelt paginering automatisch af — het herkent “Next”-knoppen of oneindig scrollen en gaat door totdat de pagina’s op zijn of je limiet is bereikt. Als je een grote result set scrapt (bijvoorbeeld alle loodgieters in een grootstedelijk gebied), schakel dan over naar Cloud Scraping, waarmee tot 50 pagina’s tegelijk verwerkt kunnen worden zonder je browser te blokkeren.
Stap 4: Gebruik subpage scraping om elke vermelding te verrijken
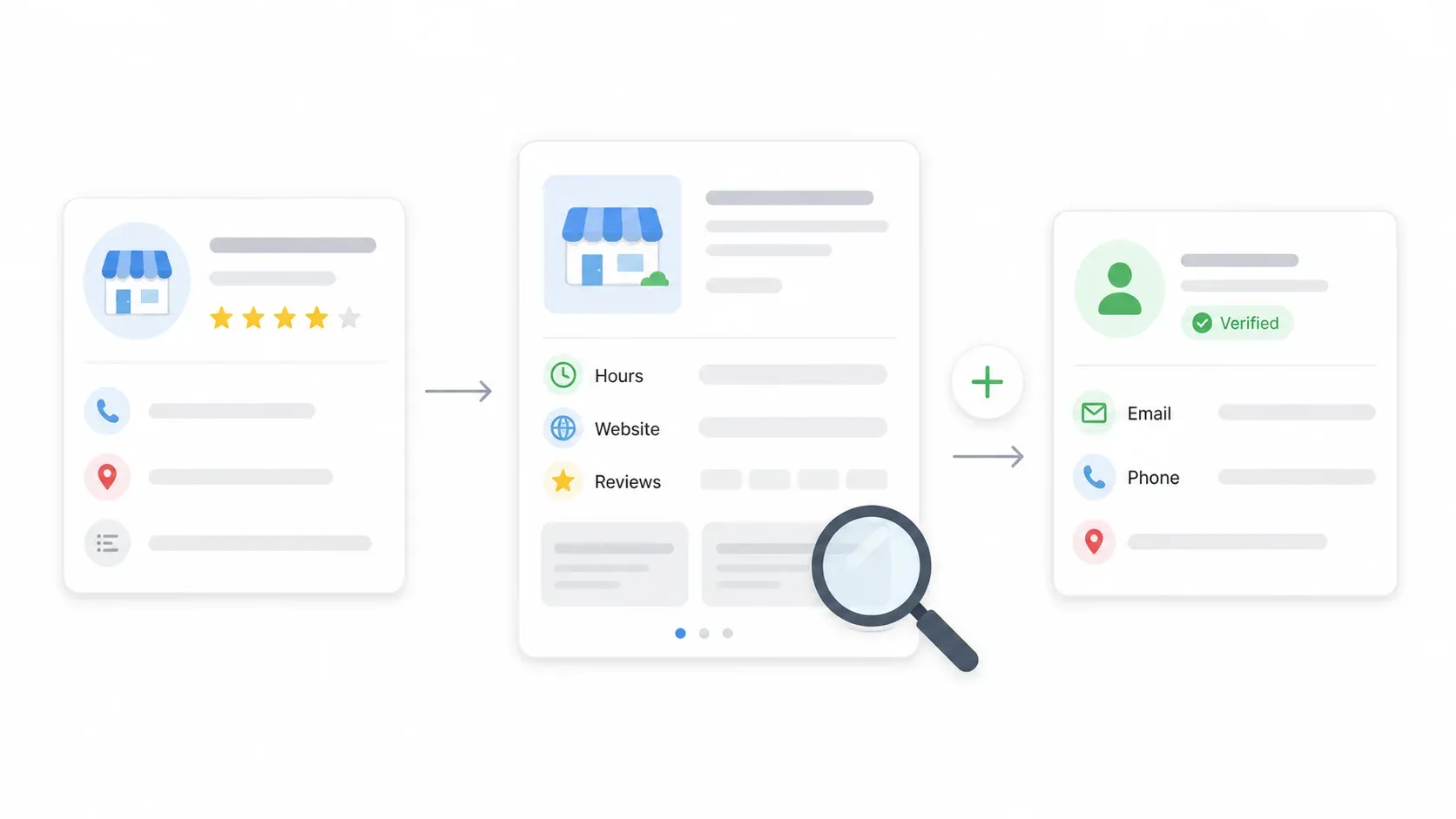
De zoekresultatenpagina geeft je de basis, maar de echte waarde — openingstijden, volledige beschrijvingen, reviews, soms e-mail — staat op de detailpagina van elk bedrijf. Klik op “Scrape Subpages” en Thunderbit bezoekt de detailpagina van elke vermelding om verrijkte kolommen op te halen, zoals openingstijden, beschrijving, website-URL en alle zichtbare contactgegevens.
Dit is een proces met één klik. Geen aparte workflow, geen configuratie. De verrijkte data wordt direct aan je bestaande tabel toegevoegd.
Stap 5: Exporteer je leads naar Excel, Google Sheets, Airtable of Notion
Als je tevreden bent met de data, klik dan op Export. Thunderbit laat je je leads direct sturen naar:
- Google Sheets (handig voor CRM-voorbereiding en delen)
- Airtable (lichte pipeline-tabellen)
- Notion (onderzoeksdatabases)
- Excel / CSV (CRM-import)
- JSON (voor developers)
Alle exportopties zijn gratis. Als je leads in HubSpot of Salesforce wilt laden, is exporteren naar CSV of Google Sheets meestal de snelste route.
Tip: scrape per categorie + stad in plaats van brede zoekopdrachten op staatsniveau. “Emergency plumbers Dallas TX” levert een veel gerichtere, actievere lijst op dan “plumbers Texas.” Voeg een kolom “Source URL” en “Scraped At” toe voor traceerbaarheid.
Methode 2: SuperPages scrapen met een visuele scrapingtool (voorbeeld: Octoparse)
Visuele scrapingtools zoals Octoparse zitten in het midden: geen code, maar wel meer setup en configuratie dan Thunderbit. Octoparse heeft zelfs een kant-en-klare SuperPages-template voor eenvoudigere use cases.
Moeilijkheidsgraad: Intermediate
Benodigde tijd: ~20–30 minuten voor setup + scrape
Wat je nodig hebt: Octoparse-account (gratis plan beschikbaar, met beperkingen)
Stap 1: Maak een nieuwe taak aan en laad de SuperPages-URL
Open Octoparse, klik op “New Task” en plak je SuperPages-zoek-URL (bijv. “https://www.superpages.com/los-angeles-ca/plumbers”). De ingebouwde browser laadt de pagina.
Stap 2: Auto-detect of selecteer handmatig datavelden
Klik op “Auto-detect” — Octoparse scant de pagina en markeert velden die volgens hem relevant zijn. Controleer het Data Preview-paneel. In mijn ervaring pakt auto-detect meestal de meeste velden, maar hij kan extra’s meenemen (zoals advertentielabels of navigatietekst) of iets missen. Waarschijnlijk moet je dus handmatig een paar velden toevoegen of verwijderen.
Volgens de helpdocs van Octoparse maakt auto-detect een basisworkflow met paginering en data-extractiestappen, maar gebruikers moeten soms ontbrekende data handmatig toevoegen.
Stap 3: Bouw de workflow en configureer paginering
Klik op “Create workflow”. Octoparse genereert een stapsgewijze actiereeks. Controleer de pagineringsstap — zorg dat hij correct op “Next” klikt of meer resultaten laadt. Als je data van elke detailpagina van een bedrijf wilt (openingstijden, e-mail, beschrijving), moet je een loop voor detailpagina’s of een subpage-actie toevoegen binnen de workflow. Dat maakt het complexer dan Thunderbit’s one-click subpage-aanpak.
Stap 4: Draai de taak en exporteer de data
Voer de taak lokaal uit (voor kleine jobs) of in de cloud van Octoparse (voor geplande of grotere jobs — cloud is een betaalde functie). Als het klaar is, exporteer je als CSV, Excel of JSON.
Beperkingen om te weten: het gratis plan van Octoparse bevat 10 taken, tot 50.000 rijen per maand en alleen lokale extractie. Cloud-runs, IP-rotatie, CAPTCHA-oplossing en sommige exportintegraties vereisen een betaald plan (vanaf ongeveer $69/maand bij jaarlijkse betaling).
Methode 3: SuperPages scrapen met Python (Requests + BeautifulSoup)
Dit is de route voor developers. Volledige controle, volledige verantwoordelijkheid. Als je comfortabel bent met het schrijven en onderhouden van Python-scripts, heb je hiermee de meeste flexibiliteit — maar ook de meeste frustratie.
Moeilijkheidsgraad: Geavanceerd
Benodigde tijd: ~30–60 minuten (setup + coderen + debuggen)
Wat je nodig hebt: Python 3.x, pip, requests, beautifulsoup4, lxml, een code-editor
Stap 1: Stel je Python-omgeving in
1python -m venv .venv
2source .venv/bin/activate
3pip install requests beautifulsoup4 lxml pandasStap 2: Inspecteer de HTML-structuur van SuperPages
Open Developer Tools (F12) op een SuperPages-resultatenpagina. Zoek CSS-selectors voor bedrijfsnaam, adres, telefoon, website en de link naar de detailpagina. Houd er rekening mee dat de HTML-structuur zonder waarschuwing kan veranderen, waardoor je selectors op elk moment kunnen breken.
Stap 3: Schrijf de listings-scraper en verwerk paginering
Hier is een vereenvoudigd voorbeeld. Belangrijke kanttekening: in mijn tests gaf een directe request naar SuperPages een Cloudflare-pagina “Attention Required” terug. Een naïef Requests-script kan op schaal falen — je hebt mogelijk browser-sessiecontext, rate limiting, retries of geautoriseerde alternatieven nodig.
1import csv, time
2from urllib.parse import urljoin
3import requests
4from bs4 import BeautifulSoup
5BASE_URL = "https://www.superpages.com"
6HEADERS = {
7 "User-Agent": (
8 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
9 "AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/125.0 Safari/537.36"
11 )
12}
13def fetch(url):
14 resp = requests.get(url, headers=HEADERS, timeout=20)
15 resp.raise_for_status()
16 if "Attention Required" in resp.text or "Cloudflare" in resp.text:
17 raise RuntimeError("Geblokkeerd. Vertraag of schakel over op browser/cloud scraping.")
18 return BeautifulSoup(resp.text, "lxml")
19def parse_listing(card):
20 name_el = card.select_one(".business-name, a.business-name, h2 a, h3 a")
21 phone_el = card.select_one(".phones, .phone, [class*=phone]")
22 address_el = card.select_one(".street-address, .adr, [class*=address]")
23 website_el = card.select_one("a.track-visit-website, a[href*='http']")
24 rating_el = card.select_one(".rating, [class*=rating]")
25 detail_url = urljoin(BASE_URL, name_el.get("href")) if name_el and name_el.get("href") else ""
26 return {
27 "business_name": name_el.get_text(" ", strip=True) if name_el else "",
28 "phone": phone_el.get_text(" ", strip=True) if phone_el else "",
29 "address": address_el.get_text(" ", strip=True) if address_el else "",
30 "website": website_el.get("href", "") if website_el else "",
31 "rating": rating_el.get_text(" ", strip=True) if rating_el else "",
32 "detail_url": detail_url,
33 }
34def scrape_search(search_url, pages=3):
35 all_rows = []
36 for page in range(1, pages + 1):
37 page_url = f"\{search_url\}?page=\{page\}"
38 soup = fetch(page_url)
39 cards = soup.select(".result, .organic, [class*=result]")
40 if not cards:
41 break
42 for card in cards:
43 all_rows.append(parse_listing(card))
44 time.sleep(5)
45 return all_rows
46if __name__ == "__main__":
47 rows = scrape_search("https://www.superpages.com/los-angeles-ca/plumbers", pages=2)
48 with open("superpages_leads.csv", "w", newline="", encoding="utf-8") as f:
49 writer = csv.DictWriter(f, fieldnames=sorted({k for row in rows for k in row}))
50 writer.writeheader()
51 writer.writerows(rows)Stap 4: Scrape detailpagina’s voor verrijking
Schrijf een aparte functie om elke detailpagina-URL te bezoeken en openingstijden, e-mail, beschrijving en reviews uit te lezen. Dat betekent dat je zelf rate limits, foutafhandeling en mogelijk proxies moet beheren.
Stap 5: Sla data op als CSV of JSON
Gebruik de csv- of json-modules van Python. Je moet ook zelf deduplicatie, opschoning en exportlogica schrijven.
Veelvoorkomende valkuilen:
- SuperPages kan requests blokkeren met Cloudflare of vergelijkbare anti-bot systemen (bevestigd in mijn tests).
- Selectors zijn hier bewust ruim gekozen, omdat de markup van SuperPages kan veranderen.
- Ga er niet vanuit dat zoekresultaten e-mailadressen bevatten. Dat is bijna nooit zo.
- Een production scraper heeft een robots-/TOS-check, rate limiting, retry/backoff, gestructureerde logging en foutregistratie nodig.
Als je dieper wilt ingaan op Python scraping, bekijk dan onze gids over web scraping met Python of de BeautifulSoup-tutorial.
Van ruwe data naar echte leads: de volledige pipeline (scrape → clean → verify → CRM)
Hier stopt de meeste scraping-content — en hier begint de echte waarde. Scraping levert je grondstoffen op. Er een bruikbare leadlijst van maken vraagt nog een paar stappen.
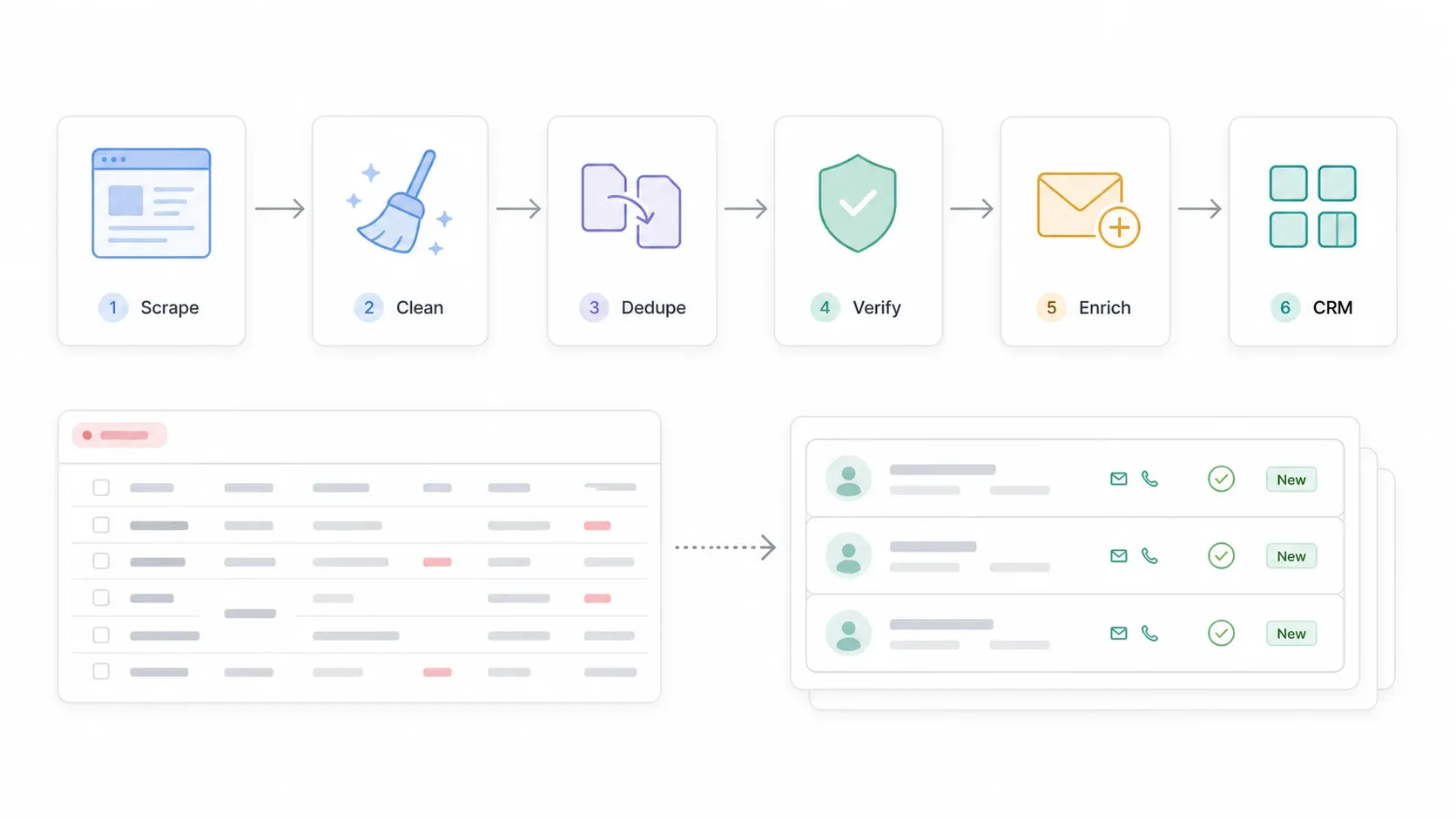
De pipeline ziet er zo uit:
SuperPages zoeken → Listings scrapen → Detailpagina’s/websites scrapen → Exporteren naar Google Sheets of CSV → Telefoons, adressen en categorieën opschonen → Duplicaten verwijderen → E-mails/telefoons verifiëren → Ontbrekende contactgegevens verrijken → Importeren in CRM → Outreach volgens de regels
Deduplicatie: dubbele vermeldingen verwijderen
SuperPages toont vaak hetzelfde bedrijf in meerdere categorieën. Als je “plumbers” en “drain cleaning” in dezelfde stad hebt gescrapet, krijg je overlap.
- Primair dedupe-key: Genormaliseerd telefoonnummer + genormaliseerd straatadres.
- Secundair: Domein + stad.
- Terugvaloptie: Bedrijfsnaam + postcode (handmatig controleren bij franchises).
In Google Sheets gebruik je =UNIQUE(A:H) voor exacte rij-overeenkomsten, of maak een hulpkolom zoals =LOWER(REGEXREPLACE(B2&C2,"[^a-zA-Z0-9]","")) om bijna-duplicaten te vinden. In Excel gebruik je Gegevens > Duplicaten verwijderen.
Data cleaning: telefoons, adressen en opmaak standaardiseren
- Formatteer telefoonnummers in E.164 (voor de VS: +1 gevolgd door 10 cijfers). Dat is het formaat dat de meeste CRM’s en dialers verwachten. Je kunt in Thunderbit een Field AI Prompt gebruiken om dit tijdens het scrapen automatisch te laten formatteren.
- Normaliseer adressen: schrijf afkortingen voluit, vul ontbrekende postcodes aan, splits indien nodig op in straat/stad/staat/postcode.
- Verwijder HTML-resten, extra spaties en trackingparameters uit URL’s.
- Voeg kolommen
source_directory,source_urlenscraped_attoe voor traceerbaarheid.
E-mail- en telefoonverificatie vóór outreach
Stuur niet zomaar een cold email naar elk adres dat je hebt gescrapet. Verificatie beschermt je sender reputation en houdt je bounce rate laag.
- E-mailverificatie: ZeroBounce (vanaf ongeveer $39 voor 2.000 credits, plus 100 gratis credits per maand) of Bouncer ($8 voor 1.000 credits, credits verlopen nooit) zijn sterke opties.
- Telefoonvalidatie: Twilio Lookup biedt gratis formatting en validatie; caller ID kost $0,01 per verzoek.
- Thunderbit’s gratis Email Extractor en Phone Number Extractor kunnen contactgegevens ophalen die op vermeldingpagina’s ontbreken.
Verrijking: contactpersonen vinden als SuperPages geen e-mails toont
Veel SuperPages-vermeldingen tonen helemaal geen e-mailadres — zeker niet op de zoekresultatenpagina. Dit kun je doen:
- Scrape de Contact-, About- of footerpagina’s van de bedrijfswebsite. Thunderbit’s Subpage Scraping of Email Extractor kan dit in bulk doen.
- Gebruik verrijkingstools zoals Apollo, BetterContact, Icypeas of Prospeo. Let wel: voor kleine lokale bedrijven (een loodgietersbedrijf met twee mensen, een zelfstandige tandarts) leveren grote B2B-databases vaak weinig op. Website-first extractie werkt voor dit soort bedrijven meestal beter.
- Combineer meerdere directories. Scrape SuperPages, Yellow Pages en Google Maps voor dezelfde categorie/stad en merge daarna de resultaten met deduplicatie. De overlap zorgt voor completere records.
Als je ooit een lokale SMB-lijst door Apollo hebt gehaald en vooral lege velden kreeg, ben je niet de enige. Daarom is de website-first aanpak voor deze doelgroep zo belangrijk.
CRM-import: leads in HubSpot, Salesforce of Google Sheets krijgen
- HubSpot: ga naar Data Management > Data Integration > Import data > Quick import (contacts only). Upload je
.csvof.xlsx. De importgids van HubSpot legt de field mapping uit. - Salesforce: gebruik de Data Import Wizard. Maak een CSV klaar, koppel bronvelden aan Salesforce-velden en start de import.
- Google Sheets / Airtable / Notion: Thunderbit exporteert direct naar alle drie — zonder CSV-tussenstap.
Tip: map je gescrapete kolommen vóór het importeren aan CRM-velden. Een paar minuten mapping bespaart je later uren handmatig opschonen.
SuperPages versus andere lokale bedrijvengidsen: waar vind je de beste leads?
SuperPages is een sterk startpunt, maar het is niet de enige directory die het waard is om te scrapen. Zo verhoudt het zich tot andere opties:
| Directory | Lead volume | Beschikbare datavelden | Actualiteit van data | Moeilijkheid anti-scraping | Beste voor |
|---|---|---|---|---|---|
| SuperPages | Groot (focus op VS) | Naam, telefoon, adres, website, categorieën, beoordelingen | Gemiddeld | Gemiddeld | Home services, aannemers, SMB’s |
| Yellow Pages | Groot (focus op VS) | Vergelijkbaar met SuperPages | Gemiddeld | Gemiddeld | Algemene lokale outreach |
| Google Maps | Zeer groot (wereldwijd) | Naam, telefoon, adres, website, reviews, openingstijden, foto’s | Hoog (door eigenaar bijgewerkt) | Hoog (strenge anti-bot) | Meest actuele lokale data |
| Yelp | Groot (focus op VS) | Naam, telefoon, adres, reviews, prijsklasse | Hoog | Hoog | Restaurants, retail, dienstverleners |
| Manta | Middelgroot | Naam, telefoon, adres, omzetindicaties, aantal medewerkers | Gemiddeld | Laag | B2B-prospecting (omzet-/medewerkgegevens) |
| BBB | Middelgroot | Naam, telefoon, adres, accreditatie, klachten | Gemiddeld | Laag | Betrouwbare/gecontroleerde bedrijven |
Bronnen: SuperPages homepage, VLDB SuperPages-paper, Google Places API-documentatie, Yelp Places API-documentatie, Manta homepage, BBB-gids.
Thunderbit werkt voor al deze bronnen — inclusief Instant Templates voor populaire sites zoals Google Maps en SuperPages — zodat je dezelfde workflow op meerdere bronnen kunt toepassen en je leadlijsten kunt samenvoegen. In mijn ervaring is de beste aanpak vaak om twee of drie directories voor dezelfde categorie/stad te scrapen en daarna te dedupliceren. De overlap vult gaten op en geeft je een completer beeld.
Voor meer informatie over het scrapen van andere directories, bekijk onze gidsen over , en .
Juridische en ethische tips voor het scrapen van SuperPages-leads
Ik ben geen advocaat, en dit is geen juridisch advies — maar ik heb lang genoeg in deze wereld gezeten om te weten dat compliance negeren een snelle manier is om problemen te krijgen. Hier is de praktische samenvatting.
Openbare bedrijfsdata vs. persoonsgegevens
Bedrijfsvermeldingen — bedrijfsnaam, bedrijfsnummer, bedrijfsadres, bedrijfswebsite — worden in het algemeen gezien als openbare commerciële data. Dat is iets anders dan persoonlijke consumentendata onder GDPR of CCPA. Maar “publiek” betekent niet “zonder regels”. Controleer altijd de Terms of Service van de site.
De Terms of Use van SuperPages (bijgewerkt in juli 2019) bevatten een clausule “Data Mining Prohibited”: gebruikers mogen geen bots, crawlers, spiders of vergelijkbare tools gebruiken om data te verzamelen of te extraheren zonder voorafgaande toestemming van Thryv. Dit artikel bespreekt methoden en workflows, maar je moet deze voorwaarden zelf beoordelen en waar nodig toestemming vragen vóór je op grote schaal scrape’t.
Outreach-compliance: basis van CAN-SPAM en TCPA
Als je gescrapete e-mails gebruikt voor cold outreach, zegt de FTC CAN-SPAM-gids dat je:
- Geen valse of misleidende headers mag gebruiken
- Geen bedrieglijke onderwerpregels mag gebruiken
- De boodschap als advertentie moet markeren wanneer dat verplicht is
- Een geldig fysiek postadres moet opnemen
- Een duidelijke opt-out moet aanbieden en die snel moet respecteren
Als je gescrapete telefoonnummers gebruikt voor cold calling, controleer dan het National Do Not Call Registry en houd je aan de TCPA-regels — vooral rond geautomatiseerde oproepen, opgenomen berichten en sms. De FTC kondigde in 2024 wijzigingen aan om bescherming tegen misleidende B2B-telemarketing en AI-gestuurde scam calls te versterken.
Snelle compliance-checklist
- ✅ Scrape alleen openbaar vermelde bedrijfsgegevens
- ✅ Bekijk de Terms of Use van SuperPages en vraag waar nodig toestemming
- ✅ Verifieer contactgegevens vóór outreach
- ✅ Voeg een opt-out toe aan e-mails
- ✅ Respecteer robots.txt en rate limits
- ✅ Houd DNC- en e-mail-suppressionlijsten bij
- ⚠️ Vermijd het scrapen van persoonlijke/consumentendata
- ⚠️ Verkoop ruwe gescrapete data niet opnieuw zonder juridische review
Kies je methode en begin met het bouwen van je leadlijst
SuperPages scrapen voor leads gaat niet alleen over rijen uit een webpagina halen. De echte waarde zit in de volledige pipeline: scrapen, opschonen, dedupliceren, verifiëren, verrijken, importeren en compliant outreach doen.
Hier is de korte samenvatting:
- Thunderbit is de snelste route voor sales teams, bureaus en niet-ontwikkelaars. Twee klikken om te scrapen, één klik om te verrijken met subpagina’s, gratis export naar Google Sheets, Airtable, Notion of Excel. Probeer het gratis.
- Octoparse is een sterke visuele workflowtool voor halftechnische gebruikers die meer controle over configuratie willen.
- Python geeft developers volledige flexibiliteit — maar brengt onderhoud, anti-blokkering-frustratie en geen ingebouwde verrijking met zich mee.
- En vergeet niet: dezelfde workflow geldt voor Yellow Pages, Google Maps, Yelp, Manta en BBB. Scrape meerdere bronnen, merge, dedupliceer en je hebt de meest complete lokale leadlijst die je kunt maken.
Als je Thunderbit in actie wilt zien, bekijk dan ons voor walkthroughs, of bekijk om te zien wat bij je team past.
Ga nu die directorypagina’s omzetten in pipeline — en moge je telefoonnummers altijd correct geformatteerd zijn en je e-mails altijd geverifieerd.
FAQ’s
Is het legaal om SuperPages te scrapen voor leads?
Het scrapen van publiek beschikbare gegevens uit bedrijvengidsen voor B2B-onderzoek komt vaak voor, maar de Terms of Use van SuperPages verbieden data mining zonder voorafgaande toestemming van Thryv. Controleer altijd de voorwaarden van de site, vraag waar nodig toestemming en houd je aan regels voor outreach zoals CAN-SPAM en TCPA. Dit artikel behandelt methoden en workflows uitsluitend voor educatieve doeleinden — het is jouw verantwoordelijkheid om ze volgens de regels te gebruiken.
Welke data kan ik uit SuperPages halen?
Een typische scrape levert bedrijfsnaam, telefoon, adres, website, categorie, beoordelingen, openingstijden en beschrijvingen op. E-mailadressen zijn zelden zichtbaar op de zoekresultatenpagina — meestal moet je de detailpagina van het bedrijf of de eigen website van het bedrijf bezoeken (met subpage scraping of een email extractor) om ze te vinden.
Kan ik SuperPages scrapen zonder te coderen?
Ja. Tools zoals Thunderbit (AI Chrome-extensie) en Octoparse (visuele scraper) laten je SuperPages scrapen zonder één regel code te schrijven. Thunderbit is de snelste optie — installeer de extensie, open een SuperPages-zoekopdracht, klik op “AI Suggest Fields” en daarna op “Scrape.”
Hoe ga ik om met paginering bij het scrapen van SuperPages?
Thunderbit handelt paginering automatisch af — het herkent “Next”-knoppen of oneindig scrollen en gaat gewoon door. Octoparse vereist dat je in de workflow een pagineringsstap configureert. In Python moet je handmatig een lus over pagina’s schrijven (pagina-nummers verhogen, laatste pagina detecteren).
Hoe krijg ik e-mailadressen uit SuperPages-vermeldingen?
De meeste SuperPages-vermeldingen tonen geen e-mailadressen op de zoekresultatenpagina. Gebruik Thunderbit’s Subpage Scraping om elke detailpagina te bezoeken, of gebruik de gratis Email Extractor op de website van het bedrijf. Voor resterende gaten kun je verrijkingstools zoals Apollo, BetterContact of Prospeo proberen — maar voor kleine lokale bedrijven werkt website-first extractie vaak beter dan grote B2B-databases.
Meer informatie