

Bijna de helft van al het internetverkeer bestaat inmiddels uit bots. De meeste daarvan scrapen op grote schaal links, data en URL’s. Doe je dat nog handmatig, dan loop je al snel achter de feiten aan.
Ik heb 12 linkextractors getest — van AI-gestuurde Chrome-extensies tot Python-bibliotheken — om te zien welke tools echt leveren wanneer je snel duizenden URL’s moet scrapen.
Dit is wat ik heb ontdekt.
Waarom linkextractors belangrijk zijn
Laten we eerlijk zijn: het web barst van de data, en bedrijven proberen die chaos om te zetten in bruikbare inzichten. Linkextractors en URL-extractors zijn inmiddels onmisbaar voor teams die willen:
- Leads genereren: salesteams halen in een paar minuten bedrijfsprofielen of LinkedIn-links uit directories of LinkedIn, en gebruiken die URL’s vervolgens om contactgegevens te extraheren. Eindeloos klikken is verleden tijd.
- Content bundelen en SEO versterken: marketeers kunnen alle artikel-URL’s uit een blog verzamelen, backlinks van concurrenten monitoren of de sitestructuur controleren op kapotte links.
- Concurrenten volgen en marktonderzoek doen: operationele teams kunnen automatisch links verzamelen naar nieuwe producten, prijspagina’s of persberichten — zonder er veel werk aan te hebben.
- Workflows automatiseren en tijd besparen: moderne linkscrapers verwerken bulk-URL’s, crawlen subpagina’s en exporteren data in gestructureerde formaten (CSV, Excel, Google Sheets, Notion — noem maar op). Geen eindeloze copy-paste-werkzaamheden of rommelige tekstbestanden meer.
Aangezien er dagelijks tientallen miljarden webpagina’s worden gecrawld, is dit handmatig doen simpelweg geen optie. De juiste linkextractor voelt als een superassistente die nooit moe wordt, nooit een link mist en nooit om koffie vraagt.
Hoe we de beste linkextractors hebben gekozen
Met zoveel tools op de markt kan het kiezen van de juiste linkextractor voelen als speed-daten op een techconferentie: iedereen beweert "de ware" te zijn, maar slechts een paar maken het echt waar. Zo heb ik de top 12 geselecteerd:
- Gebruiksgemak: kunnen niet-coders ermee werken zonder een PhD in regex? No-code en low-code oplossingen kregen extra punten.
- Bulk- en meerlaagse scraping: kan de tool honderden URL’s tegelijk verwerken? Crawlt hij subpagina’s en volgt hij automatisch links?
- Export en integraties: exporteert hij naar CSV, Excel, Google Sheets, Notion, Airtable of via API? Hoe minder handwerk, hoe beter.
- Type gebruiker en flexibiliteit: is het voor business users, analisten of ontwikkelaars? Sommige tools zijn voor iedereen, andere zijn juist niche.
- Geavanceerde functies: AI-gestuurde herkenning, planning, cloud-schaalbaarheid, datacleaning en sjablonen voor veelgebruikte sites.
- Prijs en schaalbaarheid: gratis tiers, pay-as-you-go of enterprise? Ik heb gekeken wat je krijgt voor je geld.
Ik heb alles meegenomen: van browserextensies tot enterprise-platforms. Dus of je nu solo ondernemer bent of deel uitmaakt van een Fortune 500-datateam, je vindt hier iets dat past.
Thunderbit: de slimste linkextractor voor zakelijke gebruikers
Laten we bovenaan beginnen. Thunderbit is mijn eerste keuze voor linkextractie, en niet alleen omdat ik eraan heb meegewerkt. Thunderbit is een AI-gestuurde webscraper Chrome-extensie voor zakelijke gebruikers die snel resultaat willen.
Wat maakt Thunderbit zo bijzonder? Het is alsof je een AI-stagiair hebt die echt luistert. Je beschrijft in gewone taal wat je nodig hebt (“Haal alle productlinks en prijzen van deze pagina”), en de AI van Thunderbit doet de rest. Geen gedoe met selectors of scripts.
Maar daar houdt het niet op:
- Ondersteuning voor bulk-URL’s: plak één URL of een lijst van honderden — Thunderbit verwerkt ze in één keer.
- Navigatie door subpagina’s: moet je links scrapen van een overzichtspagina en daarna elke detailpagina bezoeken voor meer URL’s? De meerlaagse scrapinglogica van Thunderbit regelt het.
- Gestructureerde export: zodra je links zijn geëxtraheerd, kun je velden hernoemen, categoriseren en direct exporteren naar Google Sheets, Notion, Airtable, Excel of CSV. Geen nabewerking meer nodig.
Scrape links van elke website met AI Get Started Free
Thunderbit wordt vertrouwd door meer dan 30.000 gebruikers wereldwijd, van salesteams tot makelaars en kleine e-commercebedrijven. En ja, er is een gratis versie (tot 6 pagina’s scrapen, of 10 met een proefboost), zodat je het zonder risico kunt uitproberen.
Probeer Thunderbit Link Extractor gratis
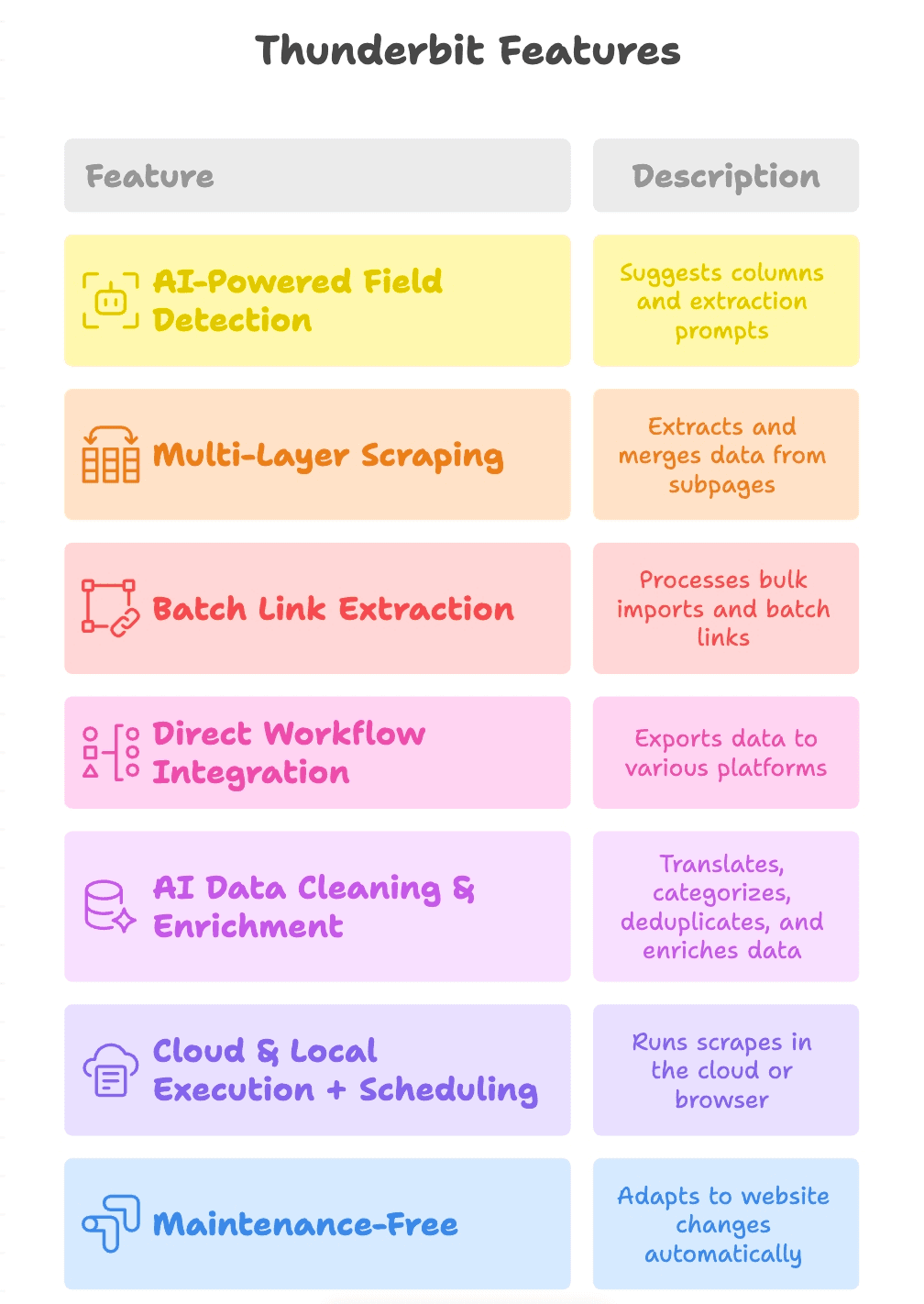
Uitblinkende functies van Thunderbit
Laten we dieper ingaan op wat Thunderbit echt onderscheidt:
- AI-gestuurde veldherkenning: klik op “AI Suggest Fields”, en Thunderbit leest de pagina, stelt kolommen voor (zoals “Productlink”, “PDF-URL”, “Contact-e-mail”) en maakt zelfs extractieprompts per veld aan.
- Meerlaagse scraping: Thunderbit kan links volgen van een hoofdpagina naar subpagina’s (zoals productdetailpagina’s of PDF-downloads), daar extra links uit halen en alles samenvoegen in één tabel.
- Batch linkextractie: of je nu één pagina of duizend pagina’s scrapt, Thunderbit verwerkt bulk-imports en batch-linkextractie moeiteloos.
- Directe workflow-integratie: exporteer resultaten naar Google Sheets, Notion, Airtable of download als CSV/Excel. Je data komt precies daar terecht waar je team het nodig heeft.
- AI-datacleaning en verrijking: Thunderbit kan tijdens het scrapen vertalen, categoriseren, dedupliceren en zelfs data verrijken — zodat je output direct bruikbaar is in plaats van een ruwe dump.
- Cloud- en lokale uitvoering + planning: voer scrapes uit in de cloud voor snelheid, of in je browser voor sites waarvoor je moet inloggen. Plan terugkerende jobs om je data actueel te houden.
- Onderhoudsvrij: de AI van Thunderbit past zich aan aan wijzigingen op websites, zodat je minder tijd kwijt bent aan het repareren van kapotte scrapers en meer tijd overhoudt voor resultaten.
Octoparse: no-code linkscraper voor iedereen
Octoparse is een klassieker in de no-code scrapingwereld. Het is een desktopapp voor Windows/Mac met een visuele point-and-click-interface. Je laadt een webpagina, klikt op de links die je wilt, en Octoparse doet de rest.
- Geschikt voor beginners: geen code nodig. Gewoon klikken, extraheren en klaar.
- Ondersteunt paginering en dynamische content: Octoparse kan op “Volgende”-knoppen klikken, scrollen en zelfs inloggen op sites.
- Cloud scraping en planning: met betaalde plannen kun je jobs in de cloud uitvoeren en terugkerende taken inplannen.
- Exportopties: download data als CSV, Excel, JSON of stuur het door naar databases.
Het gratis plan is royaal voor kleine taken (tot 10 taken en 50.000 rijen per maand), maar intensievere gebruikers hebben een betaald plan nodig (vanaf ongeveer $75 per maand).
Apify: flexibele URL-extractor voor aangepaste workflows
Apify is het Zwitserse zakmes onder de webscrapingtools. Het biedt een marktplaats met kant-en-klare “actors” (scrapingtools), maar je kunt ook zelf scripts schrijven in JavaScript of Python.
- Kant-en-klaar én aanpasbaar: gebruik community-actors voor veelvoorkomende taken, of bouw zelf iets voor specifieke workflows.
- Bulk- en geplande scraping: zet URL’s in de wachtrij, voer taken parallel uit en plan terugkerende scrapes.
- API-first: exporteer naar JSON, CSV, Excel of Google Sheets en koppel het aan je datapipeline.
- Pay-as-you-go: elke maand gratis credits, daarna betalen op basis van gebruik.
Apify is ideaal voor semi-technische teams en ontwikkelaars die flexibiliteit en schaalbaarheid willen.
Bright Data URL Scraper: linkscraping op enterprise-niveau
Bright Data is gebouwd voor bedrijven die op grote schaal willen scrapen. Hun Data Collector biedt een vooraf ingestelde URL Scraper voor jobs met hoog volume.
- Kan enorm schalen: scrape duizenden of miljoenen pagina’s, met robuuste proxy-infrastructuur om blokkades te vermijden.
- Vooraf ingestelde sjablonen: kant-en-klare scrapers voor e-commerce, social, vastgoed en meer.
- Enterprise-functies: compliance-tools, deskundige support en geavanceerde anti-blocking.
- Prijs: vanaf ongeveer $350 voor 100.000 page loads — duidelijk gericht op grotere organisaties.
Ben je een startup, dan is dit waarschijnlijk te veel van het goede. Maar voor bedrijfskritische scraping op hoge volumes is Bright Data een krachtpatser.
WebHarvy: visuele linkextractor met point-and-click eenvoud
WebHarvy is een desktopapp voor Windows waarmee je links kunt scrapen door er simpelweg op te klikken in de ingebouwde browser.
- Super eenvoudig: klik op een link, en WebHarvy markeert automatisch vergelijkbare elementen voor extractie.
- Ondersteuning voor reguliere expressies: ingebouwde patronen voor veelvoorkomende taken, zonder te coderen.
- Export naar Excel, CSV, JSON, XML, SQL: ideaal voor zakelijke gebruikers die data in bekende formaten willen.
- Eenmalige licentie: één keer betalen, voor altijd gebruiken.
Perfect voor kleine bedrijven, onderzoekers of iedereen die snel en zonder gedoe links wil ophalen zonder code.
Web Scraper (Chrome-extensie): snel links scrapen in je browser
De Web Scraper Chrome-extensie is een gratis open-source tool die van je browser een scraper maakt.
- Sitemaps definiëren: geef aan hoe de tool moet navigeren en wat hij moet extraheren.
- Ondersteunt paginering en crawlen op meerdere niveaus: crawl categorieën, subcategorieën en detailpagina’s.
- Export naar CSV/XLSX: download data direct vanuit je browser.
- Community-sjablonen: veel gedeelde sitemaps voor populaire websites.
Ideaal voor snelle eenmalige klussen of voor studenten en kleine teams met een beperkt budget.
ScraperAPI: schaalbare linkscraper voor ontwikkelaars
ScraperAPI is voor ontwikkelaars die webpagina’s op schaal willen ophalen zonder zich zorgen te maken over proxies, blokkades of CAPTCHA’s.
- API-gedreven: stuur een URL en krijg HTML of gescrapete data terug.
- Schaalbaarheid en anti-botmaatregelen: proxyrotatie, JS-rendering en CAPTCHA-oplossing ingebouwd.
- Integreert met je code: te gebruiken met Python, Node.js of vrijwel elke andere taal.
- Prijs: gratis tier (~1000 API-calls), daarna betalen per verzoek.
Geweldig voor custom crawlers of wanneer je betrouwbaarheid en snelheid op schaal nodig hebt.
ParseHub: visuele linkscraper met geavanceerde selectie
ParseHub is een desktopapp voor Windows, Mac en Linux waarmee je scrapingprojecten visueel bouwt.
- Geavanceerde selectie en navigatie: klik, loop en extraheer links conditioneel — zelfs uit dynamische of verborgen elementen.
- Ondersteunt geneste pagina’s: crawl categorieën, daarna detailpagina’s en haal daar weer extra links uit.
- Export naar CSV, Excel, JSON: cloud-runs en API-toegang zitten in betaalde plannen.
- Gratis plan: 5 projecten, tot 200 pagina’s per run.
ParseHub is favoriet bij marketeers en onderzoekers die power willen zonder te coderen.
Scrapy: Python-linkextractor voor ontwikkelaars
Scrapy is de gouden standaard voor Python-ontwikkelaars die volledige controle willen.
- Code-first: bouw eigen spiders om links op elke schaal te crawlen en extraheren.
- Ondersteunt gedistribueerd crawlen: efficiënt, asynchroon en sterk aanpasbaar.
- Export naar CSV, JSON, XML of database: jij bepaalt de output.
- Open-source en gratis: maar je moet wel je eigen omgeving beheren.
Als je comfortabel bent met Python, is Scrapy extreem krachtig.
Diffbot: AI-gestuurde linkscraper voor gestructureerde data
Diffbot is het "AI-brein" van webscraping. De tool analyseert pagina’s en levert gestructureerde data terug — inclusief links — zonder handmatige inrichting.
- Automatische inhoudsherkenning: geef een URL op en ontvang gestructureerde data terug (artikelen, producten, links, enz.).
- Crawlbot en Knowledge Graph: crawl complete websites of query hun enorme webindex.
- API-gedreven: integreer met je BI-tools of datapipeline.
- Enterprise-prijzen: vanaf ongeveer $299 per maand, maar je krijgt er ook veel voor terug.
Het beste voor enterprises die schone, gestructureerde data willen zonder scrapers te hoeven beheren.
Cheerio: lichte linkextractor voor Node.js
Cheerio is een snelle HTML-parser voor Node.js, met een jQuery-achtige syntax.
- Zeer snel: parseert HTML in milliseconden.
- Bekende syntax: als je jQuery kent, begrijp je Cheerio meteen.
- Ideaal voor statische pagina’s: rendert geen JS, maar is perfect voor server-side gegenereerde content.
- Open-source en gratis: combineer met axios of fetch voor verzoeken.
Ideaal voor ontwikkelaars die eigen scripts bouwen en snelheid en eenvoud willen.
Puppeteer: browserautomatisering voor geavanceerde linkscraping
Puppeteer is een Node.js-bibliotheek waarmee je Chrome in headless mode aanstuurt.
- Volledige browserautomatisering: laad pagina’s, klik, scroll en interageer als een echte gebruiker.
- Werkt met dynamische content en logins: perfect voor JavaScript-zware sites of complexe workflows.
- Fijne controle: wacht op elementen, maak screenshots en onderschep netwerkverzoeken.
- Open-source en gratis: wel zwaarder qua resources en trager dan lichtere tools.
Gebruik Puppeteer wanneer je links moet scrapen van sites die zich niet makkelijk laten aanpakken met basis scrapers.
In één oogopslag: welke linkextractor past bij jou?
Hier is een snelle vergelijking van alle 12 tools:
| Tool | Het beste voor | Ondersteuning voor bulk & subpagina’s | Exportopties | Prijs |
|---|---|---|---|---|
| Thunderbit | Niet-coders, business users | Ja (AI, meerlaags) | Excel, CSV, Sheets, Notion, Airtable | Gratis proef, vanaf ~$9/maand |
| Octoparse | No-code gebruikers, analisten | Ja | CSV, Excel, JSON, cloudopslag | Gratis tier, ~$75/maand |
| Apify | Semi-technisch, developers | Ja | CSV, JSON, Sheets via API | Gratis credits, gebruiksafhankelijk |
| Bright Data | Enterprise | Ja (hoog volume) | CSV, JSON, NDJSON via API | ~$350/100k pagina’s |
| WebHarvy | Niet-coders, desktop | Ja | Excel, CSV, JSON, XML, SQL | Betaalde licentie |
| Web Scraper Extension | Iedereen, snel/gratis | Ja | CSV, XLSX | Gratis, open-source |
| ScraperAPI | Developers, API-gebruikers | Ja | JSON (HTML via API) | Gratis 1k requests, betaalde tiers |
| ParseHub | Niet-coders, gevorderd | Ja | CSV, Excel, JSON, API | Gratis 5 projecten, betaald |
| Scrapy | Developers, Python | Ja | CSV, JSON, XML, DB | Gratis, open-source |
| Diffbot | Enterprise, AI | Ja (AI-crawl) | JSON (gestructureerde data via API) | ~$299/maand+ |
| Cheerio | Developers, Node.js | Ja (custom code) | Aangepast (JSON, enz.) | Gratis, open-source |
| Puppeteer | Developers, complexe sites | Ja (volledige automatisering) | Aangepast (via script) | Gratis, open-source |
De juiste linkscraper kiezen voor jouw bedrijf
Dus, hoe kies je? Dit is mijn korte beslisgids:
- Geen programmeerkennis? Begin met Thunderbit, Octoparse, ParseHub, WebHarvy of de Web Scraper-extensie.
- Aangepaste workflows nodig? Apify, ScraperAPI of Cheerio zijn sterk voor developers.
- Enterprise-schaal? Bright Data of Diffbot zijn hiervoor gebouwd.
- Python- of Node.js-ontwikkelaar? Scrapy (Python) of Cheerio/Puppeteer (Node.js) geven je volledige controle.
- Direct exporteren naar Sheets/Notion? Thunderbit is dan je beste keuze.
Kies de tool die past bij je technische niveau, datavolume en integratiebehoeften. De meeste bieden gratis proefperiodes, dus probeer gerust wat uit.
Ontdek meer handleidingen over webscraping Get Started Free
Thunderbit’s unieke waarde voor linkextractie in 2026
Laten we nog even terugkomen op wat Thunderbit echt anders maakt:
- AI-gestuurde eenvoud: beschrijf in gewone taal wat je wilt — de AI van Thunderbit regelt de rest.
- Meerlaagse scraping: extraheer links van hoofdpagina’s, ga door naar subpagina’s en verzamel daar weer extra URL’s — allemaal in één workflow.
- Bulk-import en batchverwerking: plak honderden URL’s, extraheer links in bulk en exporteer direct gestructureerde data.
- Workflow-integratie: exporteer direct naar Google Sheets, Notion, Airtable of download als CSV/Excel.
- Geen onderhoud: de AI van Thunderbit past zich aan aan wijzigingen op websites, zodat je niet steeds kapotte scrapers hoeft te repareren.
Thunderbit overbrugt de kloof tussen “gewoon data scrapen” en “data krijgen die je echt kunt gebruiken”. Het is de tool die ik jaren geleden had willen hebben, toen ik werd overspoeld door handmatige datataken.
Begin gratis met linkextractie via Thunderbit
Conclusie: scrape links slimmer en versterk je workflow
Webdata is de brandstof voor bedrijfsgroei — en de juiste linkextractor is je motor. Of je nu leadlijsten opbouwt, concurrenten volgt of onderzoek automatiseert, hier zit een tool tussen die past bij jouw behoeften en vaardigheden.
Wil je zien hoe moderne linkextractie eruitziet? Probeer dan de gratis versie van Thunderbit. Ik denk dat je verrast zult zijn hoeveel je in slechts een paar klikken voor elkaar krijgt. En als Thunderbit niet perfect past, probeer dan een paar andere tools uit deze lijst — er was nog nooit een beter moment om het saaie werk te automatiseren en je te richten op wat echt telt.
Veel scrape-plezier — en moge je links altijd schoon, gestructureerd en direct inzetbaar zijn. Wil je je verder verdiepen in webscraping? Bekijk dan de Thunderbit Blog voor meer handleidingen en tips.
Probeer Thunderbit Link Extractor gratis Get Started Free
Veelgestelde vragen
1. Waarom zijn linkextractors onmisbaar?
Omdat bijna de helft van al het internetverkeer van bots komt en bedrijven massaal data scrapen, zijn linkextractors essentieel om webchaos om te zetten in bruikbare inzichten. Ze helpen taken zoals leadgeneratie, contentbundeling, SEO-audits en concurrentiemonitoring te automatiseren, wat enorm veel tijd en moeite bespaart.
2. Waarin onderscheidt Thunderbit zich van andere linkextractors?
Thunderbit gebruikt AI om scraping eenvoudig te maken — beschrijf gewoon in normale taal wat je wilt bereiken, en de tool doet de rest. Het ondersteunt bulk-URL-invoer, meerlaagse scraping, slimme veldherkenning en naadloze export naar platforms zoals Google Sheets en Notion. Ideaal voor niet-coders en zakelijke gebruikers die krachtige resultaten willen zonder technische rompslomp.
3. Zijn er linkextractors die geschikt zijn voor developers en aangepaste workflows?
Ja. Tools zoals Apify, ScraperAPI, Cheerio, Puppeteer en Scrapy zijn gemaakt voor developers. Ze bieden scripting, API-integraties en de flexibiliteit om complexe scrapingtaken, grootschalige jobs en geavanceerde automatisering aan te kunnen.
4. Welke tools zijn het beste voor gebruikers zonder programmeerervaring?
Thunderbit, Octoparse, ParseHub, WebHarvy en de Web Scraper Chrome-extensie zijn topkeuzes voor niet-technische gebruikers. Deze tools bieden visuele interfaces, kant-en-klare sjablonen en AI-gestuurde functies die linkextractie voor iedereen toegankelijk maken.
5. Hoe kies ik de juiste linkextractor voor mijn situatie?
Kijk naar je technische vaardigheden, datavolume en exportbehoeften. Niet-coders doen er goed aan tools zoals Thunderbit of Octoparse te kiezen, terwijl developers misschien liever Scrapy of Puppeteer gebruiken. Enterprises kunnen voor grootschalige operaties beter kijken naar Bright Data of Diffbot. Begin altijd met een gratis proefperiode om te zien wat het best past.




