Stel je het volgende scenario voor: je hebt net je website gelanceerd, helemaal klaar om een golf aan nieuwe klanten te ontvangen, maar tot je verbazing blijkt de helft van je bezoekers... geen mensen te zijn. Geen sciencefictionrobots, maar digitale crawlers—denk aan zoekmachines, AI-bots en analysetools—die dag en nacht je site afspeuren als een onzichtbare parade. In 2026 is dit de dagelijkse realiteit. Weten wie (of wat) je site bezoekt, hoe vaak en met welk doel, is inmiddels onmisbaar voor elk online bedrijf.
Na jaren ervaring in SaaS, automatisering en AI heb ik web crawling zien uitgroeien van een technisch detail tot een strategisch speerpunt voor bedrijven. De cijfers liegen er niet om: bots zijn tegenwoordig verantwoordelijk voor bijna de helft van al het internetverkeer, en in sommige regio’s zijn ze zelfs in de meerderheid. Door de opkomst van AI-gedreven crawlers die massaal content verzamelen voor het trainen van grote taalmodellen, zijn de gevolgen voor je infrastructuur, kosten en merk groter dan ooit. Laten we samen de nieuwste web crawling statistieken, branchebenchmarks en de impact voor jouw organisatie in 2026 induiken.
Web Crawling in 2026: Het Nieuwe Speelveld
Web crawling is tegenwoordig groter en complexer dan ooit. Elke dag razen er miljarden geautomatiseerde verzoeken over het internet, afkomstig van een steeds breder scala aan crawlers. Waar vroeger vooral zoekmachinebots als Googlebot en Bingbot de dienst uitmaakten, zijn er nu veel meer spelers bijgekomen: AI-datacrawlers, social media scrapers, analysetools en meer.
Het belangrijkste nieuws: , en in sommige regio’s is het botverkeer zelfs groter dan het menselijke verkeer. Op het netwerk van Cloudflare waren . En het opvallende? Deze groei komt niet alleen door zoekmachines, maar vooral door AI-crawlers die data verzamelen voor de nieuwste chatbots en generatieve AI-tools.
Het landschap is diverser dan ooit:
- Goede bots: Zoekindexers, uptime monitors, legitieme datascrapers.
- Slechte bots: Spam, hacking, ongeoorloofd scrapen.
- AI-crawlers: De nieuwkomers, die content verzamelen voor AI-training en realtime antwoorden.
AI-crawlers pakken het vaak anders aan dan traditionele zoekmachinebots. Ze halen soms complete pagina’s op voor semantische analyse, niet alleen voor het indexeren van trefwoorden, en ze werken vaak op grote schaal—soms miljoenen verzoeken in een paar dagen. Het resultaat? , waarbij klassieke indexering wordt gecombineerd met de onstilbare honger van AI naar data.
Belangrijkste Web Crawling Statistieken die je Moet Weten
Tijd voor de cijfers die het web in 2026 vormgeven. Deze statistieken zijn niet alleen leuk om te weten, maar vormen de basis voor je infrastructuur, contentstrategie en bedrijfsvoering.
Bots versus Mensen: Wie Bepaalt het Verkeer?
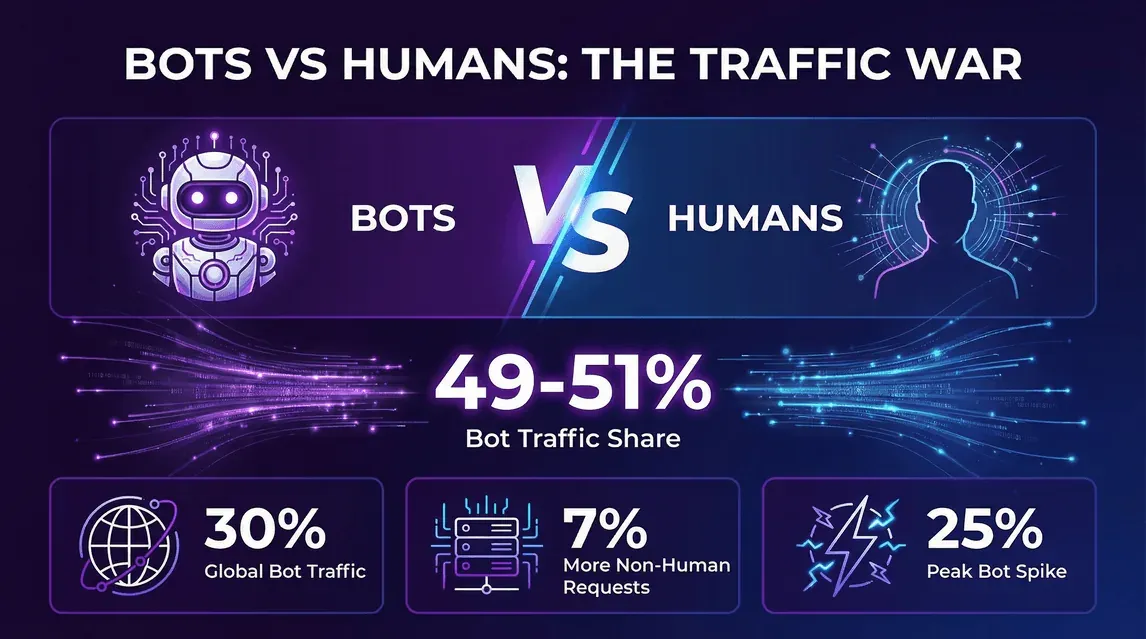
- 49–51% van al het internetverkeer wordt nu veroorzaakt door bots, waarbij geautomatiseerde verzoeken gelijk zijn aan of zelfs hoger liggen dan het aantal menselijke bezoekers ().
- Cloudflare-data: .
- Niet-menselijke verzoeken naar HTML-pagina’s waren ~7% hoger dan menselijke verzoeken ().
- Op sommige momenten .
De Opkomst van AI-Crawlers
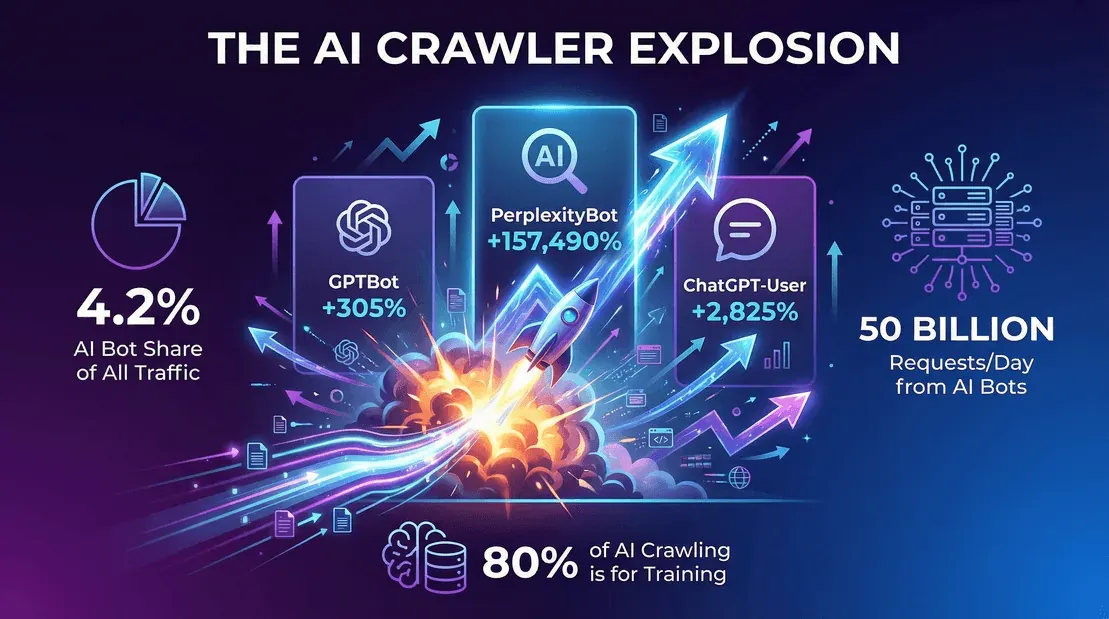
- AI-gerichte bots waren in 2025 goed voor 4,2% van alle HTML-paginaverzoeken ().
- OpenAI’s GPTBot: Ging van nul naar , een groei van 305% in één jaar.
- Perplexity.ai’s bot: .
- Googlebot: , en was goed voor ongeveer 50% van alle zoek-/AI-crawlerverzoeken.
Crawlerverkeer in de Praktijk
Een praktijkvoorbeeld uit de :
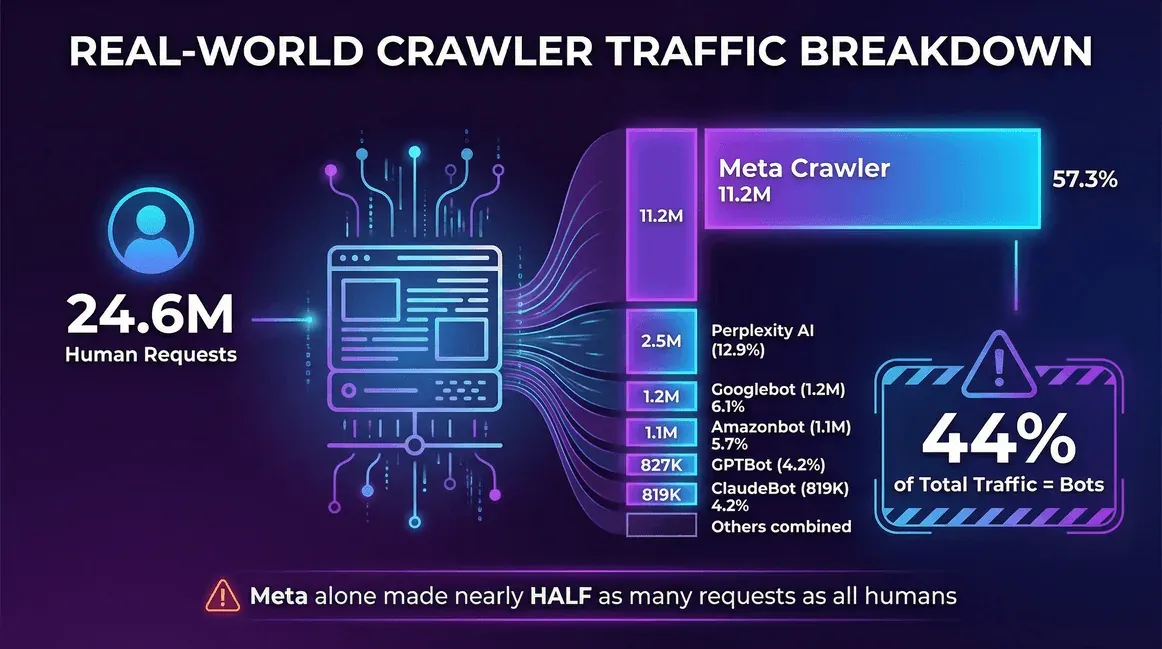
| Verkeersbron | Verzoeken (per maand) | Aandeel crawlers |
|---|---|---|
| Echte gebruikers (mens) | 24.647.904 | -- |
| Meta Crawler (Facebook) | 11.175.701 | 57,3% |
| Perplexity AI | 2.512.747 | 12,9% |
| Googlebot | 1.180.737 | 6,1% |
| Amazonbot | 1.120.382 | 5,7% |
| OpenAI GPTBot | 827.204 | 4,2% |
| ClaudeBot (Anthropic) | 819.256 | 4,2% |
| Bingbot | 599.752 | 3,1% |
| ChatGPT-User (OpenAI) | 557.511 | 2,9% |
| Ahrefs Crawler | 449.161 | 2,3% |
| ByteDance Spider | 267.393 | 1,4% |
Op deze site bestond 44% van het totale verkeer uit bots—en alleen al de crawler van Meta was goed voor bijna de helft van het aantal verzoeken van alle echte gebruikers samen.
Het Grote Plaatje
- Crawlerverkeer (zoek- + AI-bots) groeide met 18% tussen mei 2024 en mei 2025 bij een vaste groep sites ().
- Bots voor LLM-training waren op sommige grote CDNs goed voor bijna 80% van al het botverkeer ().
- Alleen al op het Cloudflare-netwerk werden eind 2025 dagelijks zo’n 50 miljard crawlerverzoeken van AI-bots geregistreerd ().
De Opkomst van AI-Crawlers: Hoe AI Web Crawling Alles Verandert
Laten we het hebben over de olifant (of beter gezegd: de robot) in de kamer: AI-crawlers. Deze bots indexeren je site niet alleen voor zoekmachines, maar verzamelen ook content om grote taalmodellen te trainen of directe AI-antwoorden te geven. En dat doen ze op een schaal waar zelfs de grootste zoekmachines van opkijken.
Waarom Exploderen AI-Crawlers?
- Datahongerige AI-modellen: Moderne LLM’s hebben enorme, diverse datasets nodig. Het web is hun buffet, en jouw content staat op het menu.
- Training versus realtime antwoorden: , niet alleen voor het beantwoorden van live vragen.
- Nieuwe crawlpatronen: AI-bots kunnen sites in korte tijd massaal bezoeken, vooral bij het updaten of opnieuw trainen van modellen.
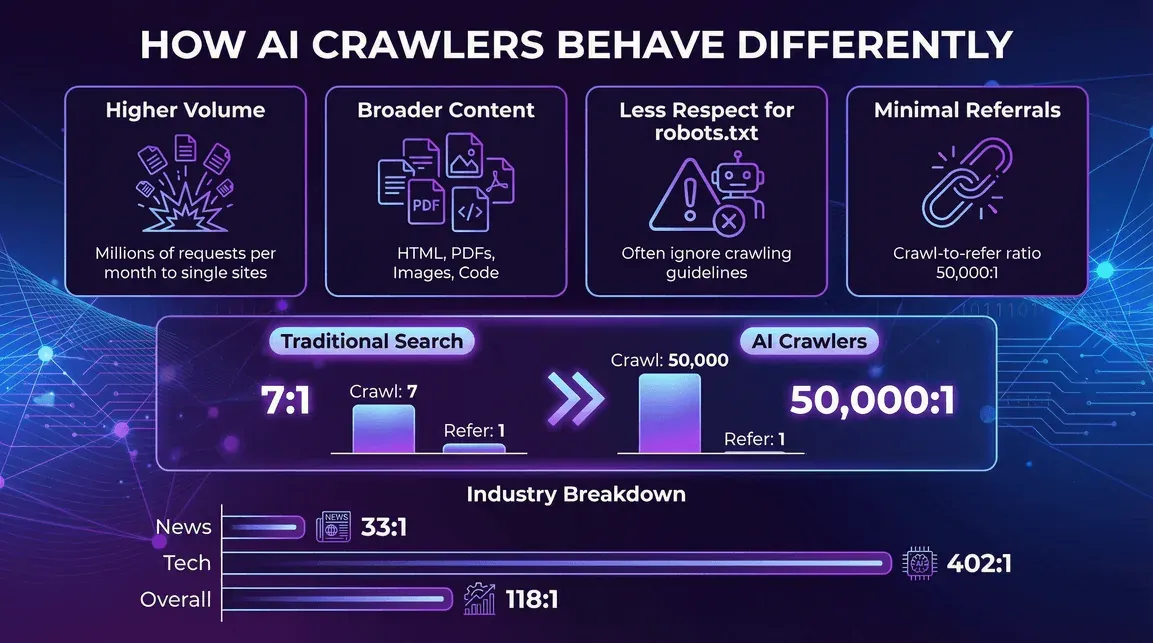
Hoe Gedragen AI-Crawlers Zich Anders?
- Veel hogere volumes per crawler: Eén AI-bot kan miljoenen verzoeken per maand naar een enkele site sturen ().
- Breder scala aan contenttypes: Niet alleen HTML, maar ook PDF’s, afbeeldingen, code, enzovoort.
- Minder respect voor robots.txt: Sommige AI-crawlers negeren of volgen crawlrichtlijnen slechts gedeeltelijk ().
- Nauwelijks verwijzingsverkeer: In tegenstelling tot zoekmachines sturen AI-crawlers zelden bezoekers terug naar je site. .
AI-Crawlerverkeer per Sector
Niet elke branche wordt evenveel gecrawld. Bijvoorbeeld:
- Nieuws & Publicaties: Veel AI-crawleractiviteit, maar iets betere verwijzingsratio’s (bijvoorbeeld Perplexity’s crawl-to-refer ratio is 33:1 op nieuwssites, tegenover 118:1 gemiddeld) ().
- Technologie & Elektronica: GPTBot en Amazonbot zijn hier dominant, met nog steeds hoge crawl-to-refer ratio’s (bijvoorbeeld OpenAI’s ratio is 402:1 in tech) ().
- Financiën, Onderwijs en Overige: Elke sector heeft zijn eigen mix van bots en verwijzingsratio’s, maar de trend is duidelijk: AI-crawlers zijn overal, en de meeste sturen nauwelijks verkeer terug.
De Belangrijkste Web Crawlers in 2026: Wie is de Grootste?
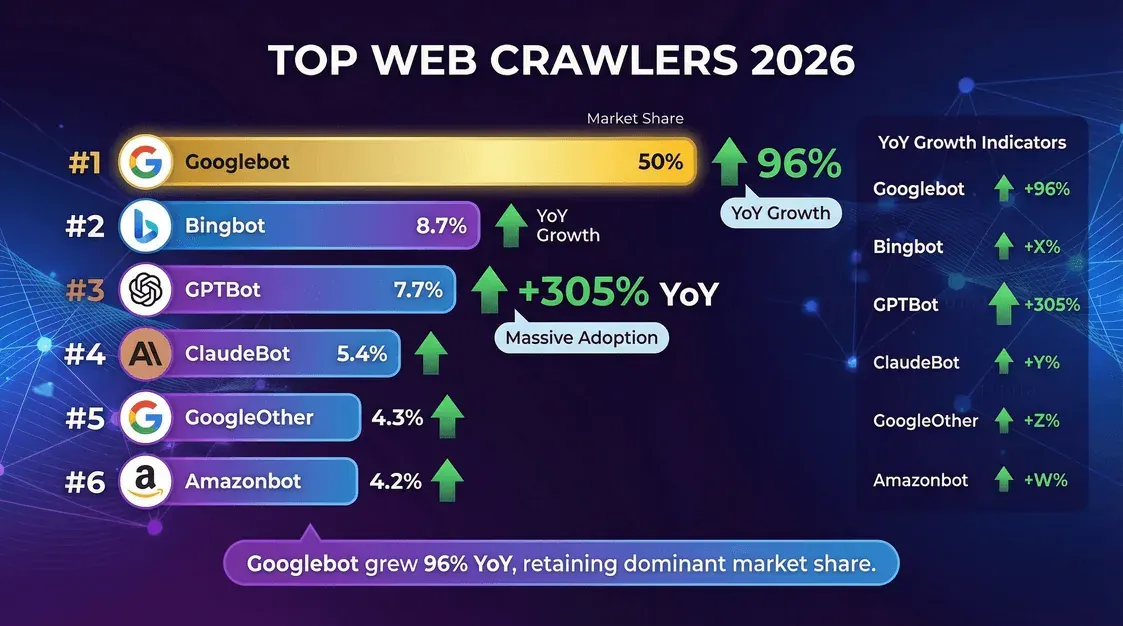
Wie zijn de hoofdrolspelers in deze crawling-wereld? Hier is de ranglijst op basis van :
| Crawler (Eigenaar) | % van Crawls (mei 2025) | Jaar-op-jaar groei |
|---|---|---|
| Googlebot (Google) | 50,0% | +96% |
| Bingbot (Microsoft) | 8,7% | +2% |
| GPTBot (OpenAI) | 7,7% | +305% |
| ClaudeBot (Anthropic) | 5,4% | –46% |
| GoogleOther (Google) | 4,3% | +14% |
| Amazonbot (Amazon) | 4,2% | –35% |
| Googlebot-Image (Google) | 3,3% | –13% |
| Bytespider (ByteDance) | 2,9% | –85% |
| YandexBot (Yandex) | 2,2% | –10% |
| ChatGPT-User (OpenAI) | 1,3% | +2825% |
| Applebot (Apple) | 1,2% | –26% |
| PerplexityBot | 0,2% | +157.490% |
Belangrijke inzichten:
- Googlebot blijft de absolute koploper en is verantwoordelijk voor de helft van alle crawling-activiteiten.
- GPTBot en Meta’s crawler zijn de snelste stijgers, waarbij GPTBot zijn aandeel in een jaar tijd heeft verdrievoudigd.
- PerplexityBot en ChatGPT-User zijn nog klein qua aandeel, maar groeien razendsnel.
Web Crawling Benchmarks: Snelheid, Doorvoer en Prestaties
 Web crawling draait niet alleen om volume, maar ook om snelheid en efficiëntie. Dit zijn de belangrijkste benchmarks voor crawlsnelheid en prestaties in 2026.
Web crawling draait niet alleen om volume, maar ook om snelheid en efficiëntie. Dit zijn de belangrijkste benchmarks voor crawlsnelheid en prestaties in 2026.
Crawlsnelheid: Hoe Snel Halen Crawlers Pagina’s Op?
- Crawlsnelheid wordt meestal uitgedrukt in pagina’s per seconde (of verzoeken per seconde) ().
- Threads/parallelle verbindingen: Meer threads betekent een hogere potentiële crawlsnelheid. Bijvoorbeeld, 200 threads met 2 seconden vertraging per site leveren ongeveer 100 pagina’s per seconde op ().
- Praktijkbenchmarks: 100–200 pagina’s per seconde is gebruikelijk voor een goed geoptimaliseerde crawler op een degelijk servercluster.
- Google en Bing: Halen wereldwijd waarschijnlijk duizenden pagina’s per seconde op, verspreid over miljoenen sites.
Factoren die de Crawlsnelheid Beïnvloeden
- Aantal threads/parallelle fetchers: Meer threads betekent meer snelheid (totdat je andere knelpunten bereikt).
- Aantal actieve sites: Meerdere domeinen tegelijk crawlen verhoogt de doorvoer.
- Crawlpauze/wachttijd: Langere pauzes zorgen voor een lagere crawlsnelheid.
- Resource-limieten: Bandbreedte, CPU en databasesnelheid kunnen beperkend zijn.
- Prestaties van de doelsite: Trage of gelimiteerde sites vertragen de crawl.
Bijvoorbeeld: als je crawler 100 threads heeft en 1 seconde wachttijd per site, kun je ongeveer 100 pagina’s per seconde ophalen—tenzij je database het niet bijhoudt, dan wordt opslag de bottleneck in plaats van het netwerk.
De Zakelijke Impact van Web Crawling: Kosten, Kansen en Risico’s
Web crawling is niet alleen een technisch fenomeen, maar heeft directe gevolgen voor je bedrijfsvoering.
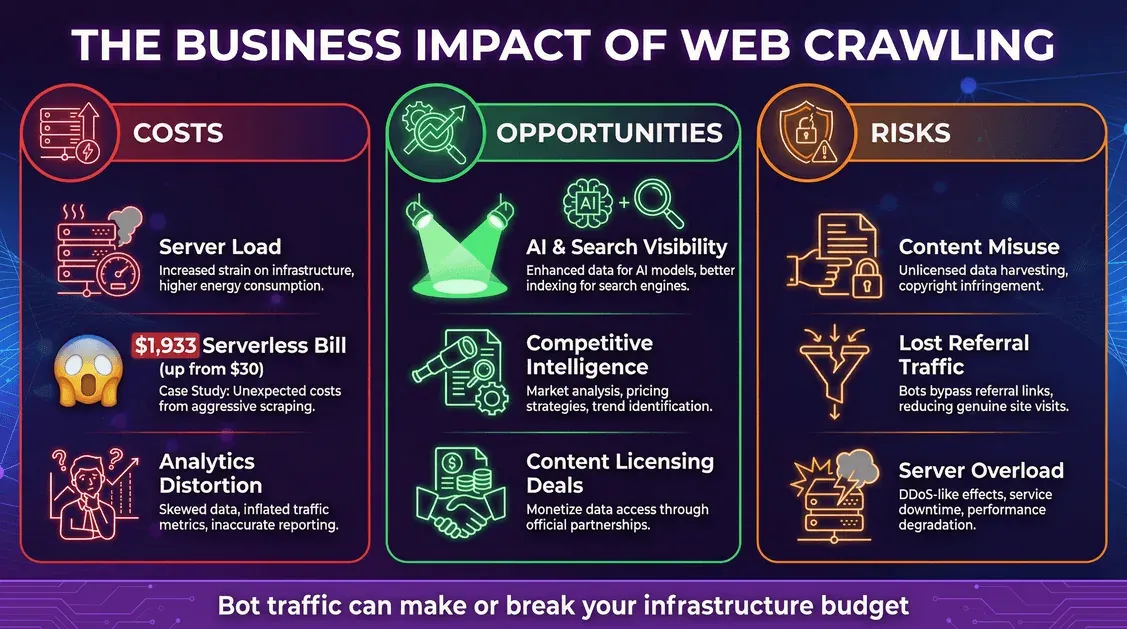
Kosten: Infrastructuur en Onverwachte Rekening
- Serverbelasting: Elke botverzoek gebruikt CPU, geheugen en bandbreedte.
- Cloudkosten: Bij een pay-per-use model (zoals serverless) kunnen bots flinke kosten veroorzaken. Een ontwikkelaar zag .
- Vertekende analytics: Bots kunnen je webstatistieken verstoren, waardoor het lastiger wordt om echt gebruikersgedrag te analyseren.
Kansen: Zichtbaarheid en Datawaarde
- AI- en zoekzichtbaarheid: Opgenomen worden in AI-trainingsdata of zoekindexen kan je merkbereik vergroten ().
- Concurrentieanalyse: Bedrijven gebruiken crawlers voor marktonderzoek, prijsmonitoring en meer.
- Monetarisering: Sommige uitgevers .
Risico’s: Contentmisbruik en Verloren Verkeer
- Contentmisbruik: AI-crawlers kunnen je content opnemen in hun modellen, soms zonder toestemming of vergoeding.
- Verloren verwijzingsverkeer: AI-antwoorden kunnen gebruikers tevredenstellen zonder ze naar je site te sturen, wat leidt tot minder direct verkeer.
- Beveiliging en downtime: Agressieve crawlers kunnen je servers overbelasten, met vertragingen of uitval tot gevolg.
Web Crawler Verkeer Beheren: Best Practices
Hoe voorkom je dat bots je cloudbudget opslokken?
1. Optimaliseer je robots.txt
- Gebruik
robots.txtom specifieke bots toe te staan of te blokkeren. De meeste betrouwbare crawlers (zoals Googlebot) respecteren dit, maar veel AI-bots niet (). - Halverwege 2025 had ongeveer 14% van de topwebsites expliciete regels toegevoegd voor AI-bots ().
2. Gebruik Bot Management Tools
- Web Application Firewalls (WAF’s) en botmanagementdiensten kunnen verdacht verkeer blokkeren of beperken.
- Cloudflare en andere aanbieders bieden botmitigatie en zelfs “AI Audit”-tools voor contentmakers ().
3. Implementeer Rate Limiting en Caching
- Beperk het aantal snelle verzoeken van één bot.
- Lever waar mogelijk gecachte content aan bots—laat ze geen dure serverless functies of databasequeries triggeren ().
4. Monitor en Analyseer Botverkeer
- Houd je serverlogs goed in de gaten. Weet welke bots je site bezoeken, hoe vaak en wanneer.
- Stel meldingen in voor ongebruikelijke verkeerspieken.
5. Blijf op de Hoogte van Nieuwe Standaarden
- Let op nieuwe metatags of HTTP-headers voor AI-gebruik (bijvoorbeeld
<meta name="ai:allow" content="no">). - Volg initiatieven als ) en betalingsprotocollen als .
Web Crawling Trends om in 2026 en Verder in de Gaten te Houden
Het web crawling-landschap verandert razendsnel. Dit zijn de ontwikkelingen om op te letten:
- AI-gedreven crawling blijft groeien: Verwacht nog meer AI-bots die steeds meer soorten content (tekst, beeld, video) verzamelen.
- Contentlicenties en betaalstandaarden: De “Wilde Westen”-periode maakt plaats voor en .
- Regulering op komst: Verwacht meer juridische duidelijkheid over wat bots wel en niet mogen, vooral rond AI-trainingsdata ().
- Technische standaarden voor contentgebruik: Let op nieuwe metatags, robots.txt-uitbreidingen en machineleesbare botdeclaraties.
- Samenwerking tussen uitgevers en AI: Steeds meer uitgevers zullen actief onderhandelen over gestructureerde datafeeds of API’s voor AI-bedrijven.
Conclusie: Wat Betekenen Deze Web Crawling Statistieken voor Jouw Bedrijf?
De kern: web crawling is in 2026 een bepalende factor en de groei is nog lang niet voorbij. Geautomatiseerde bots—vooral AI-crawlers—zijn nu verantwoordelijk voor een groot deel van je verkeer, en hun invloed op je infrastructuur, kosten en contentstrategie neemt alleen maar toe.
Wat kun je doen?
- Reken op veel botverkeer: Stem je infrastructuur, budget en monitoring hierop af.
- Ken je crawlers: Niet elke bot is hetzelfde—pas je aanpak aan per type.
- Houd je statistieken bij: Volg botverkeer net zo nauwkeurig als menselijk verkeer.
- Bescherm je content en je portemonnee: Gebruik technische maatregelen, juridische afspraken en nieuwe standaarden.
- Profiteer van de voordelen: Opgenomen worden in AI- en zoekindexen kan je merk versterken—zorg dat je er waarde voor terugkrijgt.
- Blijf op de hoogte en flexibel: Het crawling-landschap verandert snel. Volg nieuwe standaarden, regelgeving en businessmodellen.
Na jaren bouwen aan automatisering en AI-tools (en nu bij ), weet ik: bedrijven die web crawling als strategisch speerpunt zien, zijn de winnaars van morgen. Of je nu actief bent in sales, e-commerce, marketing of vastgoed—inzicht in web crawling statistieken en branchebenchmarks is onmisbaar geworden.
Dus de volgende keer dat je je serverlogs bekijkt en een stoet bots ziet langskomen, zucht dan niet, maar doe er je voordeel mee. Gebruik de data. Vergelijk je site met de benchmarks. Pas je strategie aan. En onthoud: in het AI-tijdperk zijn de bots niet onderweg—ze zijn er al. Laat ze voor jou werken, niet andersom.
Blijf scherp, blijf nieuwsgierig, en moge je serverlogs altijd in jouw voordeel zijn.
Meer weten over webscraping, automatisering en AI-gedreven productiviteit? Check de voor diepgaande artikelen, praktische tips en de nieuwste trends. Wil je zelf aan de slag met data? Probeer dan de voor AI-webscraping—geen code, geen gedoe, direct resultaat.
Bronnen en Verder Lezen: