

Het internet is tegenwoordig echt een visuele jungle—waar je ook kijkt, vliegen de afbeeldingen je om de oren: van productoverzichten tot huizenaanbod, social media tot webshops van concurrenten. In mijn dagelijkse werk zie ik hoe teams in sales, e-commerce en marketing steeds meer moeite hebben om niet alleen tekst en cijfers, maar vooral de enorme stroom aan beelden bij te houden die het verschil maken voor een merk. Wist je dat artikelen met afbeeldingen 94% vaker bekeken worden dan alleen tekst? Of dat instructies met beeld de productiviteit met 15% verhogen? Visuele data is niet langer een leuke extra—het is de nieuwe standaard voor bedrijven.

Maar hier wringt het: afbeeldingen op grote schaal verzamelen is een flinke klus. Handmatig elke foto opslaan? Dan krijg je gegarandeerd last van je pols. En met steeds modernere websites—infinite scroll, pop-up galerijen, AJAX-content—lopen ouderwetse scrapers hopeloos achter. Daarom heb ik deze lijst gemaakt met de top 5 beste image crawler tools voor snelle en slimme data-extractie in 2025. Of je nu geen technische kennis hebt en gewoon snel resultaat wilt, een developer bent die alles zelf wil regelen, of een groot bedrijf met serieuze databehoefte: er zit sowieso een geschikte tool voor je tussen.
Laten we samen kijken waar een goede image crawler aan moet voldoen, hoe de tools zich tot elkaar verhouden en welke jouw workflow echt een boost kan geven.
Waarom de Juiste Image Crawler Kiezen Zo Belangrijk Is
Ontdek de Beste Webscraping Tools Get Started Free
Afbeeldingen zijn overal, maar ze uit het web halen en in je eigen systeem krijgen is allesbehalve simpel. Bedrijven gebruiken beelddata voor van alles: van marktanalyses en concurrentieonderzoek tot AI-training en contentcreatie. In retail en vastgoed kunnen goede foto’s het verschil maken tussen een verkoop of een gemiste kans—klanten willen zien, niet alleen lezen. Marketingteams volgen user-generated content om trends te spotten, onderzoekers verzamelen productfoto’s om designveranderingen te analyseren.
Maar het is niet zo makkelijk:
- Dynamische content: Veel sites laden afbeeldingen pas na scrollen of klikken—standaard scrapers missen deze vaak compleet.
- Paginering en infinite scroll: Productoverzichten beslaan soms tientallen pagina’s; de beste crawlers moeten automatisch “Volgende” knoppen of eindeloos scrollen aankunnen automatisch.
- Relevante beelden filteren: Niet elke afbeelding is bruikbaar—advertenties, iconen en decoratieve graphics vervuilen je dataset.
- Integratieproblemen: Na het scrapen wil je de afbeeldingen (of hun URL’s) direct in Excel, Sheets, Notion of je database—zonder eindeloos kopiëren en plakken.
Kies je de verkeerde tool, dan loop je kans op incomplete data, tijdverlies of zelfs blokkades door websites. De juiste image crawler bespaart je uren werk, verhoogt de nauwkeurigheid en helpt je sneller betere beslissingen te nemen.
Hoe We de Beste Image Crawler Tools Hebben Geselecteerd
Niet elke image crawler is hetzelfde. Bij het selecteren heb ik gelet op:
- Gebruiksgemak: Kunnen niet-technische gebruikers snel aan de slag? Is coderen nodig, of kun je gewoon aanwijzen en klikken?
- Schaalbaarheid: Kan de tool honderden of duizenden pagina’s aan? Is er een cloud-optie voor snelheid?
- Nauwkeurigheid & Flexibiliteit: Kan de tool afbeeldingen van dynamische, JavaScript-rijke sites halen? Kan hij subpagina’s, filters en maatwerklogica aan?
- Integratie & Export: Hoe makkelijk krijg je je data in Excel, Google Sheets, Notion, Airtable of je eigen database?
- Prijs & Waarde: Is er een gratis versie? Is de prijs geschikt voor kleine teams, of vooral voor grote bedrijven?
Ook heb ik gekeken naar verschillende gebruikersbehoeften—sommigen willen een no-code oplossing, anderen volledige controle, en grote organisaties eisen betrouwbaarheid en compliance.
Hieronder mijn selectie van de top 5 beste image crawler tools voor 2025.
1. Thunderbit
Thunderbit is mijn absolute aanrader voor iedereen die snel, slim en zonder gedoe afbeeldingen wil verzamelen. Als medeoprichter ben ik misschien een beetje bevooroordeeld, maar ik heb Thunderbit juist gebouwd omdat ik zag hoe teams vastliepen met ouderwetse, omslachtige scrapers.
Waarom Thunderbit Opvalt:
- AI-gestuurde eenvoud: Beschrijf simpelweg wat je wilt (“haal alle productafbeeldingen en prijzen op”) en Thunderbit’s AI regelt de rest. Geen selectors, geen code, geen giswerk.
- 2-Kliks Workflow: Klik op “AI Velden Voorspellen” en Thunderbit detecteert automatisch afbeeldings-URL’s, titels en meer. Klik op “Scrapen” en je bent klaar.
- Subpagina’s Scrapen: Afbeeldingen nodig van detailpagina’s? Thunderbit kan elke subpagina doorzoeken en alle beelden verzamelen—ideaal voor e-commerce, vastgoed of sites met galerijen.
- Dynamische Content & Paginering: Of het nu om infinite scroll, “Meer Laden” knoppen of JavaScript-afbeeldingen gaat, Thunderbit’s browser- en cloudmodus kunnen het aan (docs).
- Direct Exporteren: Stuur je beelddata (inclusief de daadwerkelijke bestanden, niet alleen URL’s) direct naar Excel, Google Sheets, Airtable of Notion.
- Gratis Afbeeldingen Extractie: Thunderbit’s functies voor het verzamelen en exporteren van afbeeldingen zijn gratis voor kleine klussen (6-10 pagina’s), met een betaal-per-rij systeem voor grotere projecten—geen verborgen kosten.
Belangrijkste Thunderbit Features voor Afbeeldingen:
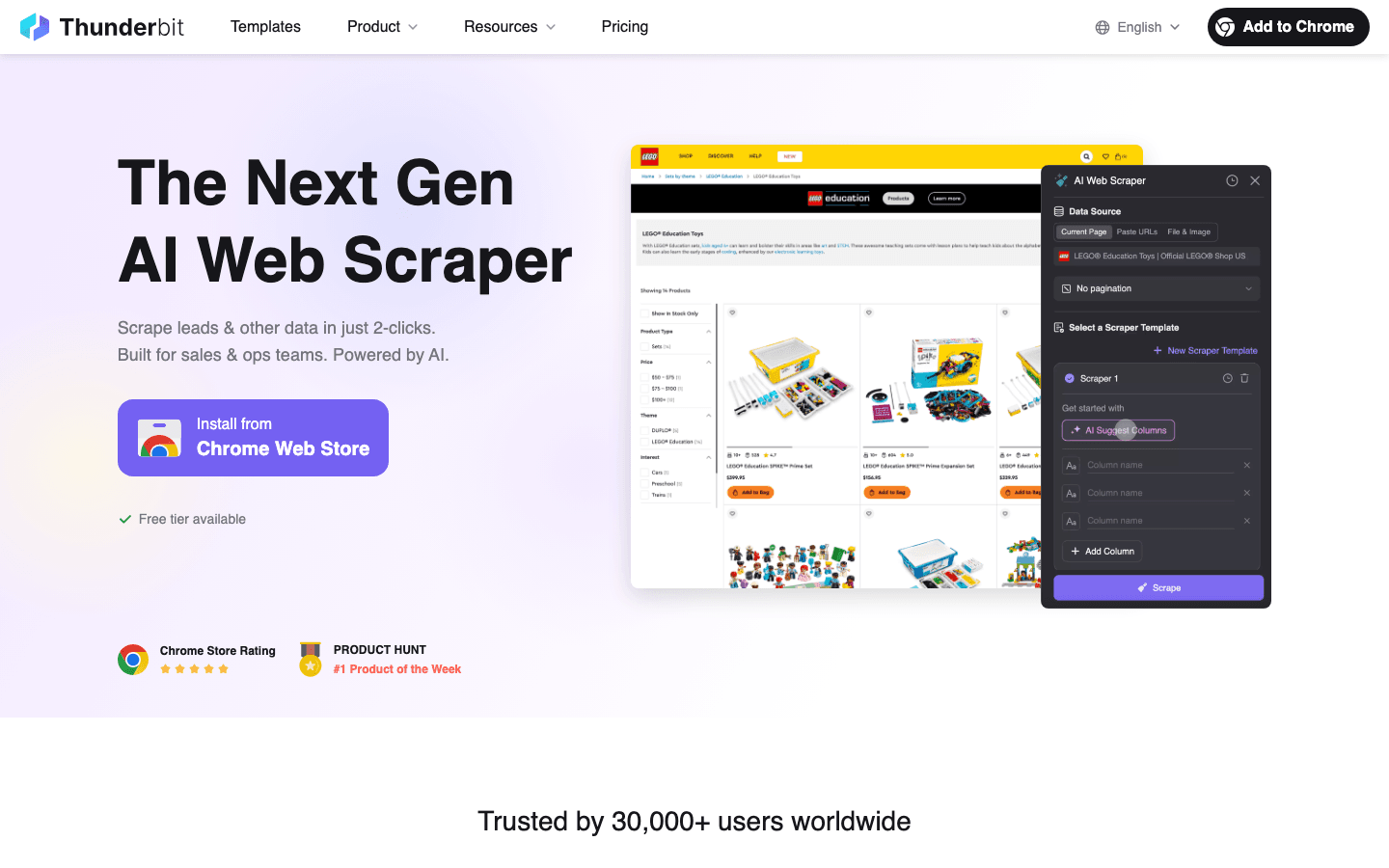
- AI Veldherkenning: Thunderbit’s AI scant de pagina en stelt afbeeldingsvelden voor, zodat je niet zelf in de HTML hoeft te zoeken (docs).
- Automatische Subpagina’s & Paginering: Verzamel beelden van overzichtspagina’s én detailpagina’s in één flow.
- Cloud vs. Browser Scraping: Gebruik cloudmodus voor snelheid (tot 50 pagina’s tegelijk), of browsermodus voor sites met login of zware JavaScript.
- Export & Integratie: Met één klik exporteren naar Excel, Sheets, Notion of Airtable. Afbeeldingen worden direct getoond in Notion/Airtable—geen extra uploads nodig (docs).
- Meertalige Ondersteuning: Thunderbit werkt in 34 talen, dus ideaal voor internationale teams.
Voor Wie?
- Sales-, marketing- en onderzoeksteams die zonder code snel resultaat willen.
- Iedereen die snel beelden van moderne, dynamische sites wil scrapen.
Prijs: Gratis tot 6-10 pagina’s. Betaalde plannen vanaf $15/maand voor 500 credits (rijen), dus betaalbaar voor kleine teams en schaalbaar voor grotere projecten.
Probeer Thunderbit Gratis voor Afbeeldingen
Zelf ervaren hoe makkelijk beeldscraping kan zijn? Download de Thunderbit Chrome-extensie en probeer het direct uit.
2. Scrapy
Scrapy is het Zwitsers zakmes voor ontwikkelaars die webdata willen scrapen. Het is open source, Python-gebaseerd en ideaal voor wie alles tot in detail wil aanpassen.
Waarom Scrapy Opvalt:
- Maximale Flexibiliteit: Schrijf je eigen “spiders” in Python om elke site te crawlen, logins te regelen, lastige HTML te parsen en precies de beelden (of data) te verzamelen die je wilt.
- Hoge Snelheid: Dankzij de asynchrone architectuur kan Scrapy duizenden pagina’s tegelijk crawlen en afbeeldingen parallel downloaden—perfect voor grote projecten.
- Images Pipeline: Scrapy heeft een ingebouwde Images Pipeline waarmee je niet alleen afbeeldings-URL’s, maar ook de bestanden zelf kunt downloaden, thumbnails kunt genereren en op formaat kunt filteren.
- Uitbreidbaar: Veel plugins voor proxies, loginbeheer en meer. Grote community.
Scrapy’s Mogelijkheden voor Afbeeldingen:
- Maatwerk Logica: Alleen beelden boven een bepaalde grootte scrapen? Duplicaten overslaan? Scrapy kan het allemaal in code.
- Integratie: Output naar je eigen database, cloudopslag of elk gewenst formaat.
- Open Source: Gratis te gebruiken—je hebt alleen Python-kennis en een server nodig.
Voor Wie?
- Ontwikkelaars, data engineers en technische teams die volledige controle willen.
- Projecten waarbij scraping onderdeel is van een grotere pipeline of grootschalige automatisering.
Prijs: Gratis (open source), maar je investeert in ontwikkeling en infrastructuur.
3. Octoparse
Octoparse is een visuele, no-code webscraper die beeldextractie voor iedereen toegankelijk maakt—zelfs als je laatste code-ervaring het aanpassen van je MySpace-profiel was.
Waarom Octoparse Opvalt:
- Aanwijs-en-Klik Interface: Klik simpelweg op de gewenste afbeeldingen en Octoparse detecteert de rest automatisch. Geen code, geen XPath, geen gedoe.
- Auto-Detectie & Templates: De auto-detect functie scant een pagina en stelt beelden, lijsten en meer voor. Templates voor populaire sites zorgen dat je in seconden kunt starten.
- Paginering & Infinite Scroll: Met de visuele workflow voeg je eenvoudig “Volgende pagina” of auto-scroll stappen toe.
- Cloud Scraping & Planning: Betaalde plannen laten je jobs in de cloud draaien, periodiek scrapen en grote volumes verwerken.
Octoparse’s Visuele Workflow voor Afbeeldingen:
- Bulk Extractie: Verzamel duizenden afbeeldings-URL’s in enkele minuten, en download de bestanden met een Chrome-extensie indien nodig.
- Exportopties: Download als CSV, Excel of stuur direct naar je database/API.
- Gratis Plan: Beperkt aantal runs voor kleine klussen; betaalde plannen vanaf ~$119/maand voor meer kracht.
Voor Wie?
- Niet-technische teams, marketeers, onderzoekers en kleine bedrijven.
- Iedereen die zonder code beelden wil scrapen.
4. ParseHub
ParseHub is ook een visuele scraper, maar blinkt vooral uit bij complexe, dynamische websites—denk aan JavaScript-rijke pagina’s, single-page apps of sites met voorwaardelijke logica.
Waarom ParseHub Opvalt:
- Dynamische Content: ParseHub kan omgaan met AJAX-content, pop-ups en meerstapsnavigatie. Verschijnen beelden pas na klikken of scrollen? ParseHub haalt ze op.
- Visuele Scripting met Logica: Voeg voorwaarden, loops en variabelen toe aan je scraping—geen code nodig, maar wel veel mogelijkheden voor gevorderden.
- Multi-Data Extractie: Verzamel beelden, tekst, links en meer in één project.
- Cloud Uitvoering & Planning: Draai jobs in de cloud, plan periodieke scrapes en koppel via API.
ParseHub’s Geavanceerde Features voor Beelddata:
- Paginering & Subpagina’s: Scrape eenvoudig beelden over meerdere pagina’s, of duik dieper in detailpagina’s.
- Export: Download als CSV, Excel of koppel aan BI-tools zoals Tableau.
- Gratis Versie: Tot 200 pagina’s per run; betaalde plannen vanaf ~$189/maand voor grotere volumes.
Voor Wie?
- Gebruikers die een no-code tool willen, maar wel met complexe of moderne sites werken.
- Data-analisten en onderzoekers die meer controle willen zonder te programmeren.
5. Content Grabber
Content Grabber (ook bekend als Sequentum Enterprise) is de krachtpatser voor grootschalige, zakelijke beeldextractie. Beheer je enorme, doorlopende scrapingprojecten met strenge compliance-eisen? Dan is dit jouw tool.
Waarom Content Grabber Opvalt:
- Enterprise Platform: On-premise Windows-software, ontworpen voor grootschalige, kritieke scraping.
- Visuele Editor + Scripting: Bouw workflows visueel, maar voeg C#/VB.NET scripts toe voor geavanceerde scenario’s.
- Multi-threaded Crawling: Download beelden van duizenden pagina’s tegelijk.
- Robuuste Foutafhandeling & Planning: Ingebouwde planner, foutafhandeling en monitoring voor betrouwbare, onbemande operaties.
- Integratie: Exporteer naar databases, API’s, cloudopslag of elk gewenst formaat.
- Team Samenwerking: Versiebeheer, gebruikersrechten en centrale aansturing voor grote teams.
Content Grabber’s Workflow Automatisering voor Beelden:
- Complexe Sites: AJAX, JavaScript, pop-ups, CAPTCHAs en meer.
- Veiligheid & Compliance: Draait op je eigen infrastructuur—geen data verlaat je servers.
- Maatwerk Prijs: Meestal een forse investering, maar gerechtvaardigd voor bedrijven met doorlopende, grootschalige behoeften.
Voor Wie?
- Grote bedrijven, dataleveranciers en iedereen die grootschalige, herhaalbare beeld- of data-extractie nodig heeft.
- Teams die maximale betrouwbaarheid, compliance en integratie eisen.
Snel Vergelijken: Beste Image Crawler Tools in Één Oogopslag
| Tool | Belangrijkste Sterktes | Ideaal Voor | Prijs (Indicatie) |
|---|---|---|---|
| Thunderbit | AI-gestuurd, 2-kliks setup, subpagina’s/paginering, direct export | Niet-technische gebruikers, snelle resultaten, MKB | Gratis tot 6-10 pagina’s, daarna per rij (vanaf $15/mnd) |
| Scrapy | Python, flexibel, schaalbaar, downloadt beelden direct | Ontwikkelaars, maatwerkprojecten, grootschalig | Gratis (open source) |
| Octoparse | No-code, visueel, auto-detectie, templates, cloud scraping | Niet-technische teams, marketing, onderzoek | Gratis plan, betaald vanaf ~$119/mnd |
| ParseHub | Visueel, dynamische sites, logica/voorwaarden, cloud planning | Complexe sites, analisten, no-code power users | Gratis versie, betaald vanaf ~$189/mnd |
| Content Grabber | Enterprise, visueel + scripting, multi-threaded, on-prem | Grote bedrijven, hoge volumes, compliance | Maatwerk/enterprise prijs |
De Beste Image Crawler Kiezen voor Jouw Bedrijf
Hoe Je Elke Website Met AI Kunt Scrapen Get Started Free
Welke tool past het beste bij jou? Mijn advies:
- Snel resultaat zonder gedoe? Kies voor Thunderbit. De makkelijkste manier om beelden te scrapen, vooral als je wilt exporteren naar Sheets, Notion of Airtable.
- Een ontwikkelaar in huis en volledige controle nodig? Scrapy is onovertroffen voor maatwerk en grootschalige projecten.
- Geen programmeerkennis, maar wel een visuele workflow? Octoparse is ideaal voor kleine tot middelgrote teams, ParseHub is beter voor complexe, dynamische sites.
- Enterprise scraping nodig? Content Grabber is gemaakt voor grote volumes, compliance en automatisering.
Kijk altijd naar de technische skills van je team, de complexiteit van je doelwebsites en hoe vaak je wilt scrapen. De meeste tools bieden gratis proefversies—dus probeer gerust uit wat het beste werkt voor jouw workflow.
Conclusie: Efficiënt Data Extractie met de Beste Image Crawler
Visuele data wordt alleen maar belangrijker. Of je nu concurrenten volgt, AI-modellen voedt of je productcatalogus up-to-date wilt houden, met de juiste image crawler verander je dagen handmatig werk in minuten automatisering. Tools als Thunderbit maken deze kracht toegankelijk voor iedereen, niet alleen voor ontwikkelaars of grote bedrijven.
Start met Afbeeldingen Scrapen via Thunderbit
Klaar om je workflow voor beeldextractie te transformeren? Probeer Thunderbit gratis of ontdek één van de andere top tools uit deze lijst. Meer weten over webscraping? Check de Thunderbit Blog voor meer handleidingen, tips en praktijkvoorbeelden.
Veelgestelde Vragen
1. Wat is een image crawler en waarom hebben bedrijven er één nodig?
Een image crawler is een tool die automatisch afbeeldingen (of hun URL’s) van websites verzamelt. Bedrijven gebruiken image crawlers om productfoto’s te verzamelen, concurrenten te monitoren, AI-modellen te trainen en contentprocessen te versnellen—dat bespaart tijd en verbetert de datakwaliteit.
2. Hoe maakt Thunderbit beeldextractie makkelijker dan andere tools?
Thunderbit gebruikt AI om automatisch afbeeldingen en andere velden te herkennen, zodat je met twee klikken een scrape opzet—zonder code of technische kennis. Het kan ook subpagina’s doorzoeken, dynamische content aan en data direct exporteren naar Excel, Sheets, Notion of Airtable.
3. Kan ik deze tools gebruiken zonder programmeerkennis?
Zeker. Thunderbit, Octoparse en ParseHub zijn allemaal ontworpen voor niet-technische gebruikers, met visuele interfaces en AI-functies. Scrapy is vooral geschikt voor wie met Python werkt, Content Grabber richt zich op enterprise IT-teams.
4. Waar moet ik op letten bij het kiezen van een image crawler?
Denk aan je technische vaardigheden, de complexiteit van je doelwebsites (dynamische content, logins, etc.), de hoeveelheid data die je nodig hebt en hoe je de resultaten wilt exporteren of integreren. Kijk ook naar de prijs—sommige tools zijn gratis, andere gericht op grote bedrijven.
5. Is het legaal om afbeeldingen van elke website te scrapen?
Controleer altijd de gebruiksvoorwaarden van de website en respecteer auteursrechten. Verzamel alleen publiek beschikbare data en vermijd het verzamelen van persoonlijke of gevoelige informatie zonder toestemming. Verantwoord en ethisch scrapen is essentieel om compliant te blijven en juridische problemen te voorkomen.
Thunderbit in actie zien? Download de Chrome-extensie en probeer het uit op je favoriete site. Vragen of meer scraping-tips? Bezoek de Thunderbit Blog voor de nieuwste gidsen en inzichten.
Meer lezen 10 Beste Gratis Website Crawlers Online voor 2025 Top 10 Geautomatiseerde Webscraping Tools in 2025 Top 12 Gratis Data Scraper Tools in 2025 Top 10 AI Webscraper Tools voor Meer Productiviteit in 2025
Probeer Thunderbit AI Image Scraper Get Started Free




