
Every AI web scraper looks brilliant in its product tour. Then you point it at a real site with Cloudflare protection, and it returns a challenge page while confidently telling you it found 47 product listings.
I've spent the last several months evaluating scraping tools for our team at Thunderbit. The gap between demo performance and production reliability is consistently the biggest source of frustration I see in communities. One Reddit user summed it up perfectly: With in the web scraping category alone, plus dozens more Chrome extensions, API vendors, and actor marketplaces, the paradox of choice is real. So I tested 12 of them.
This article evaluates 12 AI web scraper tools against production criteria: anti-bot handling, scalability, structured output quality, cost efficiency, dynamic site support, and developer flexibility. No feature checklists. No marketing screenshots. Just what actually works once the demo is over.
Why Most AI Web Scrapers Fail Past the Demo
The pattern is predictable. A tool's marketing site shows it extracting clean columns from a simple product listing page. You install it, try it on a defended e-commerce site, and get one of these:
- A
200 OKresponse containing a Cloudflare challenge page instead of actual data - Clean results for the first 5 pages, then silent failures or hallucinated rows
- Perfect extraction today, broken selectors next week after a minor layout update
These are not edge cases. They are the norm.
As one practitioner : "The scraper returns a 200 with a Cloudflare challenge page, your agent tries to reason over it, hallucinates, and you have no idea why."
The root issue is architectural. Most demos showcase the parsing layer on clean public pages, while real work fails in the fetching layer. Production sites add bot protection, dynamic rendering, nested detail pages, infinite scroll, login state, locale variance, and changing layouts.
A tool can look great on a product tour and still collapse within the first serious customer workflow.
That is why this article evaluates every tool through a production-readiness lens rather than a feature checklist. The six criteria I used:
| Criterion | Why It Matters |
|---|---|
| Anti-bot/CAPTCHA handling | Protected sites fail before extraction quality even matters |
| Scalability past demo | Batch jobs and parallel runs reveal operational limits |
| Structured output quality | Users need clean JSON/CSV, not raw HTML requiring manual cleanup |
| Token/cost efficiency | AI extraction can become more expensive than the scraping itself |
| Dynamic/JS-heavy site support | Modern pages require rendered DOMs, not static HTML |
| No-code vs. API flexibility | Sales teams and data engineers have different needs |
If you want a quick market-level overview of how web scraping changed in the last two years, this Browserless talk is a good scene-setter before you compare tools one by one.
Where AI Actually Helps in a Scraping Pipeline (and Where It Doesn't)
A persistent myth in this market is that "AI web scraper" means AI handles everything end to end. Community consensus is remarkably clear: . One user's blunt take: "You use AI to read a screenshot of a web page. You don't use AI to code the scraper itself."
The scraping pipeline has three distinct layers, and AI's value varies dramatically across them:
Crawling and Fetching: The Infrastructure Layer
This is where requests happen: proxies, headless browsers, session management, CAPTCHA solving, retries. AI does almost nothing useful here. You still need proxy pools, browser fingerprinting, and unblocking infrastructure. This is where most tools fail first in production.
Parsing and Extraction: Where AI Shines
Once you have clean page content, AI excels at turning unstructured HTML into structured fields. Schema-based extraction, adaptive field detection, and handling layout variations without brittle XPath selectors are AI's sweet spot in scraping.
Post-Processing: Labeling, Translating, Categorizing
After extraction, AI adds value by categorizing products, translating text, normalizing phone numbers, or summarizing descriptions. Strong fit, but only if the extracted data is already correct.
Here is how the 12 tools map across these layers:
| Tool | Crawling/Fetching | Parsing/Extraction | Post-Processing | Best Description |
|---|---|---|---|---|
| Thunderbit | Strong | Strong | Strong | Full-stack no-code AI scraper |
| Octoparse | Strong | Medium | Low | Rule-based visual scraper with cloud infra |
| Browse AI | Medium | Medium | Medium | Monitoring-first cloud robot platform |
| Firecrawl | Medium | Strong | Low-Medium | Developer extraction API |
| Apify | Strong | Medium-Strong | Medium | Actor marketplace and orchestration |
| Gumloop | Medium | Medium | Strong | Workflow automation with scraper nodes |
| Bright Data | Very Strong | Medium | Low-Medium | Enterprise infra stack |
| Bardeen | Medium | Medium | Strong | Browser automation for GTM workflows |
| Diffbot | Low-Medium | Very Strong | Medium | Pretrained extraction plus knowledge graph |
| ScrapingBee | Strong | Low-Medium | Low | Fetching and unblocking API |
| Instant Data Scraper | Low | Medium (simple pages) | Low | Heuristic browser-side quick scraper |
| ParseHub | Medium | Medium | Low | Desktop visual scraper for complex interactions |
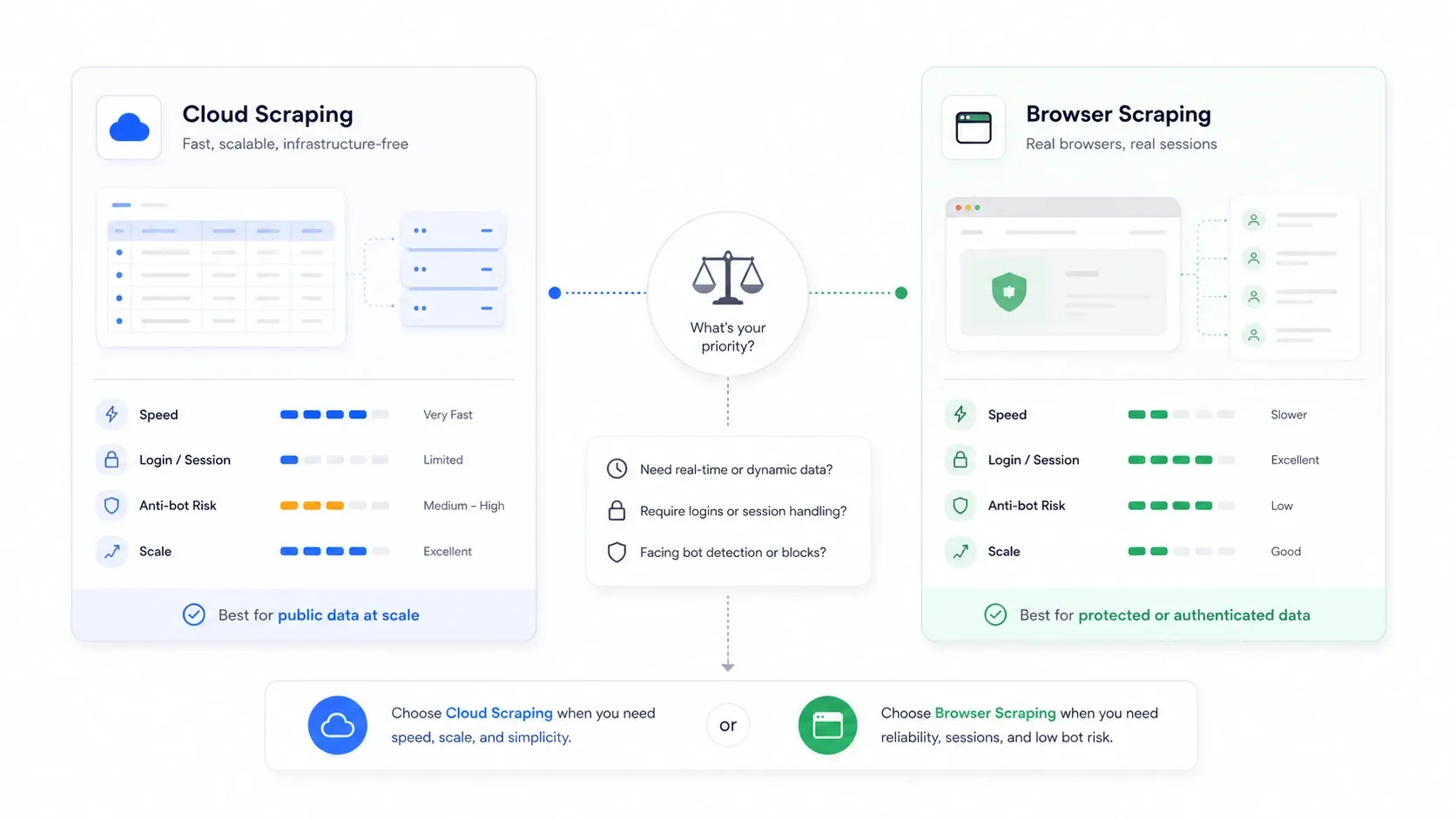
Cloud Scraping vs. Browser Scraping: The Choice No One Explains
This is the architectural decision that most roundup articles completely ignore, and it is often more important than which tool you pick.
Cloud scraping means remote servers fetch pages on your behalf. Browser scraping means extraction happens in your own browser session, using your cookies, your IP, and your authenticated state.
| Scenario | Better Mode | Why |
|---|---|---|
| Public e-commerce and listing sites at volume | Cloud | Faster parallelism and no local-machine bottleneck |
| Sites requiring login or authentication | Browser | Reuses your real session cookies |
| Sites that punish datacenter IPs | Browser | Appears as normal user traffic |
| Large recurring monitoring jobs | Cloud | Easier scheduling and continuity |
| One-off, fragile, anti-bot-sensitive jobs | Browser | Easier to inspect what the site actually rendered |
This matters economically too. Apify's 2026 State of Web Scraping report found that year over year, and reported higher infrastructure spend. Anti-bot is not just a technical issue. It is a budget issue.
Most tools only offer one mode. Here is the breakdown:
| Tool | Cloud | Browser | Both |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (local) | ✅ |
| Browse AI | ✅ | Setup only | — |
| Firecrawl | ✅ | API for interactive | — |
| Apify | ✅ | ✅ (via actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Limited (public pages) | ✅ | Partial |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (paid) | ✅ (desktop) | ✅ |
The 12 AI Web Scrapers at a Glance
Here is the master comparison across all 12 tools:
| Tool | Best For | Free Tier | Cloud/Browser | API Access | Scheduled Scraping | Anti-Bot Handling |
|---|---|---|---|---|---|---|
| Thunderbit | Non-technical teams | ✅ (6 pages) | Both | ✅ | ✅ | Strong |
| Octoparse | Template-heavy scraping | ✅ (limited) | Both | ✅ | ✅ | Moderate-Strong |
| Browse AI | Monitoring changes | ✅ (limited) | Primarily cloud | ✅ | ✅ | Moderate |
| Firecrawl | Dev extraction pipelines | ✅ (1,000 credits/mo) | Cloud plus browser API | ✅ | No | Moderate |
| Apify | Dev teams plus marketplace | ✅ ($5 free usage) | Both | ✅ | ✅ | Strong with add-ons |
| Gumloop | Workflow automation | ✅ (5,000 credits/mo) | Both | ✅ | ✅ | Medium |
| Bright Data | Enterprise data access | Trial / credits | Both | ✅ | External | Very Strong |
| Bardeen | Sales and ops browser automation | ✅ (100 credits) | Browser-first | Limited | ✅ | Medium-Low |
| Diffbot | Structured extraction APIs | ✅ (10,000 credits) | Cloud | ✅ | No | Low on fetching / high on extraction |
| ScrapingBee | Dev fetching and unblocking | ✅ (1,000 credits) | Cloud | ✅ | No | Strong |
| Instant Data Scraper | Free one-off scrapes | ✅ (fully free) | Browser only | No | No | Low |
| ParseHub | Complex visual workflows | ✅ (5 projects) | Desktop plus cloud | ✅ | ✅ (paid) | Medium |
1. Thunderbit
is the AI web scraper we built specifically for non-technical teams who need production-quality data without writing code or managing infrastructure. The core workflow is genuinely two clicks: AI Suggest Fields reads the page and proposes columns, then Scrape runs extraction in cloud or browser mode.
What makes it different from other no-code scrapers is the architecture. Thunderbit separates crawling concerns such as cloud infrastructure, proxy rotation, anti-bot handling, and JavaScript rendering from AI extraction that reads HTML and outputs structured columns. This matches the expert-recommended "scraper first, LLM second" pattern, but packaged in a Chrome extension workflow that sales reps and ops managers can actually use.
Key Strengths
- Both cloud and browser scraping in one interface. Toggle between modes depending on whether the target site is public or requires your authenticated session. Cloud mode handles up to 50 pages in parallel.
- AI re-reads page structure every time. No XPath maintenance. When a site updates its layout, Thunderbit adapts automatically on the next run.
- Subpage scraping. AI visits linked detail pages and enriches the main data table without manual configuration.
- Field AI Prompts. Custom labeling, translation, and categorization during extraction instead of as a separate post-processing step.
- Free exports to Google Sheets, Excel, Airtable, and Notion.
- Instant scraper templates for popular sites such as Amazon, Zillow, and LinkedIn.
- Natural-language scheduling. Tell it "scrape every Monday at 9am" and it converts to a recurring schedule.
- Open API with Distill and Extract endpoints, batch processing up to 100 URLs, and published concurrency from 2 on free to 50 on Pro 1.
Where It Could Improve
- Free tier is intentionally small.
- Chrome-extension-centric for the no-code experience. Developers who want API-only workflows need to use the Open API separately.
- Not the right tool if your primary need is raw proxy infrastructure without extraction.
Pricing
Free tier available. No-code plans start from $9/month billed yearly or $15/month monthly for Starter. API pricing is separate: free one-time 600 units, then $16/month yearly for Starter API and $40/month yearly for Pro 1 API. See and .
Best for: Sales, e-commerce, and operations teams who need structured web data without engineering support.
2. Octoparse
is a visual workflow builder for web scraping with a large library of pre-built templates. It has been around long enough to have mature cloud infrastructure, and it handles pagination well on structured, predictable websites.
Key Strengths
- Extensive pre-built scraping templates for popular sites
- Cloud extraction with scheduled runs
- IP rotation and CAPTCHA solving as paid add-ons
- API access on higher plans
Where It Could Improve
- AI capabilities are lighter than LLM-native tools. Field suggestion still relies more on templates than adaptive reading.
- Complex or unusual layouts require significant manual tuning in the visual editor.
- The learning curve gets steeper once you need conditional logic or anti-blocking workarounds.
Pricing
Free forever plan available. Official help-center pricing currently points to Standard from $75/month annually and Professional from $208/month annually, while some localized pages and upgrade paths show higher monthly equivalents. The important point is that Octoparse pricing now mixes subscription tiers with paid add-ons such as residential proxies and CAPTCHA solving.
Best for: Analysts and ops teams scraping structured, template-friendly sites at moderate scale.
3. Browse AI
is a cloud-based no-code platform built primarily for monitoring website changes over time, such as competitor pricing, stock availability, and content updates. Scraping is part of the product, but the real differentiator is the recurring monitoring and alerting system.
Key Strengths
- Built-in change detection and alerts
- No-code robot recorder with point-and-click setup
- Pre-built robots for popular sites
- Premium proxy support on higher plans
Where It Could Improve
- Credit-based pricing gets expensive fast when monitoring detail pages at scale
- Less compelling for large-scale one-shot extraction than API-first tools
- Moderate anti-bot handling; some sites still require premium proxies or workarounds
Pricing
Free account available. Paid plans start around $19/month billed yearly for Starter, with higher credit and monitoring tiers above that.
Best for: Teams that need ongoing monitoring of competitor prices, content changes, or stock levels rather than one-time bulk extraction.
4. Firecrawl
is a developer-first API that converts web pages into clean Markdown or structured JSON. It sits primarily in the extraction layer and is excellent for teams building RAG pipelines or feeding web content into LLMs.
Key Strengths
- Excellent Markdown output quality for downstream LLM workflows
- Clean API with scrape, crawl, map, search, extract, and browser actions
- Batch processing support
- Concurrency from 2 on free to 100 on Growth
Where It Could Improve
- No no-code interface and requires developer skills
- Built-in proxy and anti-bot help exists, but Firecrawl is not positioned like a dedicated unblocking vendor
- No first-party scheduler for recurring jobs
- Not cost-effective for non-developers who just want a spreadsheet of data
Pricing
Free plan includes 1,000 credits per month. Paid plans start at $16/month yearly for Hobby and scale up with more credits, concurrency, and browser usage. Browser sessions are billed separately in credits.
Best for: Developers building LLM pipelines, RAG systems, or custom extraction workflows who need clean Markdown or JSON from web pages.
5. Apify
is a platform with a marketplace of pre-built scraping actors plus tools to build custom ones. Think of it as an orchestration layer where you pick or build specialized scrapers for specific sites, then schedule and manage them through a unified API.
Key Strengths
- Massive actor marketplace with community-built scrapers for hundreds of sites
- Strong API and SDK for developers
- Built-in proxy management and scheduling
- Integrates with many downstream tools
Where It Could Improve
- "No-code" is only partly true once you leave the marketplace and need custom logic
- Actor reliability depends on community maintenance
- Pricing can escalate because compute, actor costs, and proxies stack
Pricing
Free tier includes $5 in monthly platform credits. Paid plans start at $39/month for Starter, with scale-oriented tiers above that.
Best for: Developer teams who want reusable, schedulable scraping workflows with a large ecosystem of pre-built solutions.
6. Gumloop
is a no-code workflow automation platform that includes a web scraping node. The real value is not scraping alone. It is connecting extraction to LLMs, Google Sheets, CRMs, and other tools in a single visual canvas.
Key Strengths
- Visual drag-and-drop workflow builder
- Integrates scraping with LLMs and downstream business tools in one flow
- Free plan currently advertised at 5,000 credits/month
- Time-based scheduling for recurring workflows
- Basic scraping and interactive Web Agent modes cover both simple and richer flows
Where It Could Improve
- Scraping engine is less robust than dedicated AI web scraper tools
- Limited anti-bot and proxy depth compared with specialist vendors
- Concurrency and trigger limits are tighter on free plans
- Not ideal for large-scale, high-volume scraping as the primary use case
Pricing
Free plan available. Gumloop combined its old Solo and Team structure into a Pro plan in late 2025, and the public messaging since then focuses on more generous free credits plus consolidated paid tiers rather than scraper-first pricing.
Best for: Teams that want scraping as one step in a broader automated workflow: scrape, analyze, and push into business tools.
If you want to see how an AI-native extraction workflow feels in practice before reading the rest of the list, this Thunderbit walkthrough is the most relevant product demo for non-technical teams.
7. Bright Data
is the enterprise-grade infrastructure stack on this list. If your problem is "I cannot get past the bot protection on this site no matter what I try," Bright Data is probably the answer, but it comes with enterprise complexity and pricing to match.
Key Strengths
- Industry-leading proxy network across residential, datacenter, and mobile IPs
- Web Unlocker for anti-bot and CAPTCHA bypass
- Scraping Browser with built-in unblocking
- Pre-collected datasets available for purchase
- Full programmatic control via API and SDK
Where It Could Improve
- Not designed for non-technical users
- Pricing reflects enterprise positioning
- AI extraction is not the primary reason to buy the platform
Pricing
Browser API starts at $8/GB pay as you go, with lower per-GB rates on larger monthly commitments. Other Bright Data products such as Unlocker, Scraper APIs, datasets, and proxy pools use different pricing units.
Best for: Enterprise data teams that need to scrape heavily defended sites at scale and have the technical staff to manage the infrastructure.
8. Bardeen
is a browser automation tool focused on clicks, form fills, and scraping with AI-powered data extraction layered on top. It is best understood as a GTM workflow tool that happens to scrape, not a scraping tool that happens to do GTM.
Key Strengths
- Intuitive playbook-style automation with scraping as one step
- Official scrapers maintained by Bardeen's team for popular sites
- Strong integrations with CRM, Google Sheets, Slack, and other business tools
- Good for lead scraping, enrichment, and CRM export workflows
Where It Could Improve
- Browser-first architecture limits high-volume unattended scraping
- Cloud scraping works only on public pages, not gated ones
- Anti-bot handling is mostly whatever your browser session already provides
- AI extraction can struggle with complex or non-standard page layouts
Pricing
Free plan includes 100 monthly credits. Public support documentation references legacy $15/month Pro pricing for existing users, while current Bardeen commercial packaging is more enterprise and workflow-oriented than classic low-end scraper pricing.
Best for: Sales and ops teams who need scraping as part of a broader browser automation workflow.
9. Diffbot
uses computer vision and NLP to read web pages like a human, outputting structured data for articles, products, discussions, and organizations. It is one of the highest-quality extraction APIs available if your pages fit its pre-trained models.
Key Strengths
- Pre-trained extraction models for articles, products, discussions, and more
- Knowledge Graph with billions of entities for data enrichment
- Strong structured output quality on supported page types
- Clear developer API with published rate limits
Where It Could Improve
- No no-code interface
- No built-in crawling, proxy management, or anti-bot handling
- Expensive for small teams
- Less flexible on non-standard page types than schema-prompt extractors
Pricing
Free plan includes 10,000 credits. Startup is $299/month for 250,000 credits, and Plus is $899/month for 1,000,000 credits.
Best for: Developer teams that need high-accuracy structured extraction from standard page types and are willing to handle fetching separately.
10. ScrapingBee
is a web scraping API focused on the fetching and unblocking layer. You send it a URL, it handles proxies, headless browser rendering, and anti-bot defenses, and it returns HTML or optionally extracted data.
Key Strengths
- Built-in proxy rotation and anti-bot handling
- JavaScript rendering support
- Simple REST API
- Google Search scraping endpoint
- Published concurrency by plan
Where It Could Improve
- AI extraction features are limited
- No no-code interface
- No scheduling or monitoring built in
- A
200response with a block page can still count as a successful request
Pricing
Free plan includes 1,000 API credits. Paid plans start at $49/month and scale up with higher concurrency and request volume.
Best for: Developers who primarily need reliable page fetching past anti-bot defenses and will handle extraction with their own code or a separate tool.
11. Instant Data Scraper
is a free Chrome extension with over 1,000,000 users that automatically detects data patterns on a page and lets you export to CSV or Excel. There is no AI field suggestion in the LLM sense. It uses heuristic pattern detection.
Key Strengths
- Completely free, no account required
- One-click data detection on many listing and table pages
- Handles pagination on some sites
- Extremely low barrier to entry
- Still maintained, with Chrome Web Store updates in 2026
Where It Could Improve
- No AI-powered field suggestion or data labeling
- No cloud scraping, scheduling, or API
- Struggles with complex layouts, dynamic content, and JS-heavy sites
- No anti-bot handling beyond what your browser can already load
- Export limited to CSV and Excel
Pricing
Free. Forever.
Best for: Anyone who needs a quick, one-off scrape of a simple listing page and does not want to create an account or pay anything.
12. ParseHub
is a desktop application with a visual, point-and-click interface for building scraping projects. It can handle complex nested data, AJAX-loaded content, infinite scroll, and dropdown interactions that simpler extensions often miss.
Key Strengths
- Visual selector interface for defining extraction rules
- Handles nested data, dropdowns, infinite scroll, and AJAX content
- Free tier with up to 5 projects
- Exports to JSON, CSV, and Excel
- Cloud scheduling and IP rotation on paid plans
Where It Could Improve
- Desktop-only workflow, no browser-extension convenience
- Slower execution speed compared with cloud-native tools
- Projects break when site layouts change because there is no AI re-reading layer
- Limited AI capabilities and a more legacy visual-scraper feel
Pricing
Free plan available with 5 projects and 200 pages per run. Paid plans start at $189/month with scheduling, IP rotation, and higher limits.
Best for: Non-technical users who need to scrape complex interactive sites and are willing to invest time in visual workflow setup.
How to Get Started with an AI Web Scraper in 5 Steps
Every tool in this list has a different onboarding flow. I will use Thunderbit as the concrete example because it best matches the "I just need this to work on a real page" search intent.
Step 1: Install and Navigate
Install the and navigate to the page you want to scrape: a product listing, a directory, or a real estate portal.
Step 2: Let AI Suggest Your Data Fields
Click AI Suggest Fields. The AI reads the current page and proposes column names and data types. On a product page, it might suggest Product Name, Price, Rating, Image URL, and Description.
Step 3: Customize Fields with AI Prompts
Adjust columns if the defaults are not quite right. Add Field AI Prompts for custom transformations such as "translate description to Spanish," "categorize as Electronics, Home, or Fashion," or "extract only the numeric price."
Step 4: Choose Cloud or Browser Mode and Scrape
Select cloud scraping for public sites or browser scraping for authenticated or heavily defended targets. Then click Scrape.
Step 5: Export Your Data Anywhere
Export results to Google Sheets, Excel, Airtable, or Notion. Exports are free.
What If the Site Layout Changes?
This is the key production advantage of AI-native extractors over rule-based tools. Traditional scrapers such as ParseHub and older Octoparse workflows rely on XPath selectors or CSS paths. When a site updates its HTML structure, those selectors break and you are back to manual reconfiguration.
AI-powered extractors like Thunderbit re-read the page structure each time. That means no XPath maintenance and no brittle selectors. The AI adapts to layout changes automatically on the next run.
Scheduled Scraping and API Access: The Power User Features Nobody Reviews
One-time scrapes are fine for research. Production use cases such as price monitoring, lead list refreshes, and stock tracking require recurring extraction and programmatic access. These features separate toys from tools.
Scheduling Support
| Tool | Native Scheduling | Notes |
|---|---|---|
| Thunderbit | ✅ | Natural-language setup |
| Octoparse | ✅ | Cloud scheduled runs |
| Browse AI | ✅ | Core product feature |
| Firecrawl | ❌ | Use external cron |
| Apify | ✅ | Full cron expressions |
| Gumloop | ✅ | Time-based workflow triggers |
| Bright Data | External | Usually orchestrated through customer systems |
| Bardeen | ✅ | Playbook scheduling |
| Diffbot | ❌ | API-first, external orchestration |
| ScrapingBee | ❌ | API-only |
| Instant Data Scraper | ❌ | Manual browser tool |
| ParseHub | ✅ (paid) | Premium feature |
Developer API Comparison
| Tool | Concurrency or Rate Signal | Pricing Model |
|---|---|---|
| Thunderbit | 2 → 50 concurrent | Credit-based |
| Firecrawl | 2 → 100 concurrent | Credit-based |
| Apify | Plan-dependent | Compute units |
| Gumloop | Plan-limited workflow concurrency | Credit-based |
| Diffbot | 5 calls/min → 25 calls/sec | Credit-based |
| ScrapingBee | 10 → 200 concurrent | API credit-based |
| Bright Data | Browser API advertises unlimited concurrent requests | GB-based |
If your use case is more technical and you are trying to decide how much infrastructure you want to own, this Firecrawl walkthrough is a useful execution-oriented complement to the product comparisons above.
How to Choose the Right AI Web Scraper
After testing all 12 tools, here is how I would decide:
- Non-technical team that needs data fast: Start with Thunderbit. The two-click workflow, free exports, and browser-cloud toggle cover most business scraping needs without engineering support.
- Need ongoing monitoring and alerts: Browse AI is purpose-built for this. It is not the strongest one-shot extractor, but its change detection is a first-class feature.
- Developer building an LLM pipeline: Firecrawl for Markdown or JSON extraction, or Diffbot for pre-trained structured extraction. Pair either with ScrapingBee or Bright Data if you need serious anti-bot handling on the fetching layer.
- Need a marketplace of pre-built scrapers: Apify has the largest actor ecosystem. Just be prepared for maintenance when actors break.
- Enterprise-scale, heavily defended targets: Bright Data. Nothing else matches its proxy infrastructure, but budget and technical staff accordingly.
- Want scraping as part of a larger automation: Gumloop or Bardeen, depending on whether you are automating workflows or browser-based GTM tasks.
- Just need a quick free scrape: Instant Data Scraper. Zero setup, zero cost, zero complexity, but also zero scheduling, zero AI, and zero cloud.
- Complex interactive sites with dropdowns and AJAX: ParseHub still handles these better than most extensions, though the maintenance burden is real.
Conclusion
The AI web scraper market in 2026 is crowded with tools that look impressive in demos and disappoint in production. The gap between "works on a marketing screenshot" and "works on a defended e-commerce site at 3 a.m. on a schedule" is where most buyers waste time and money.
The key insight from evaluating all 12 tools is simple: the fetching layer is still the hard part. AI excels at extraction and post-processing, but it does not replace proxy infrastructure, anti-bot handling, or session management. The best tools either solve both layers, like Thunderbit and Bright Data, or are honest about which layer they cover, like Firecrawl for extraction and ScrapingBee for fetching.
If you want to see what a production-ready AI web scraper looks like without writing code, . The free tier is enough to test the full workflow on real pages. If your needs are more developer-oriented, pair an extraction API with a dedicated fetching service and save yourself the frustration of expecting one tool to do everything.
FAQs
Why do most AI web scrapers fail on real websites after working fine in demos?
Demos typically showcase extraction on clean, undefended pages. Real sites add Cloudflare protection, dynamic JavaScript rendering, pagination, login requirements, and frequently changing layouts. Most tools handle the parsing and extraction layer well but lack robust infrastructure for the fetching layer.
What's the difference between cloud scraping and browser scraping, and when should I use each?
Cloud scraping uses remote servers to fetch pages, which is faster, parallel, and scalable. Browser scraping runs in your own browser session and is better for authenticated sites or those with aggressive bot detection. Thunderbit is one of the few tools that offers both modes in the same interface.
Can I use an AI web scraper for recurring tasks like price monitoring?
Yes, but only if the tool supports scheduled scraping. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen, and ParseHub on paid plans all offer scheduling.
Which AI web scraper is best if I have no coding skills?
Thunderbit offers the fastest path to usable data for non-technical users. Instant Data Scraper is completely free but limited to simple pages. Browse AI and Octoparse offer visual interfaces with more setup. ParseHub is powerful for complex interactive sites but has a steeper learning curve.
How much does production-grade AI web scraping actually cost?
The range is wide. Instant Data Scraper is free. Thunderbit, Firecrawl, and Browse AI offer free entry points with low-cost paid plans. Mid-range tools such as Octoparse, ParseHub, and ScrapingBee can run from around $49 to $189 per month. Enterprise solutions such as Bright Data and Diffbot start far higher.