Substack 스크래퍼

유수 기업의 전문가들이 신뢰합니다











Thunderbit로 Substack 데이터를 활용하세요
Substack 데이터를 앱으로 바로 전송
작성자 이름, 글 제목, 구독자 수 같은 Substack 발행물 세부 정보를 일일이 복사해 붙여 넣는 일을 멈추세요. Thunderbit를 사용하면 한 번의 클릭으로 추출한 데이터를 Google Sheets, Notion, Airtable로 바로 보낼 수 있습니다. 번거로운 수작업 없이 발행물 추세와 콘텐츠 성과를 분석해 보세요.
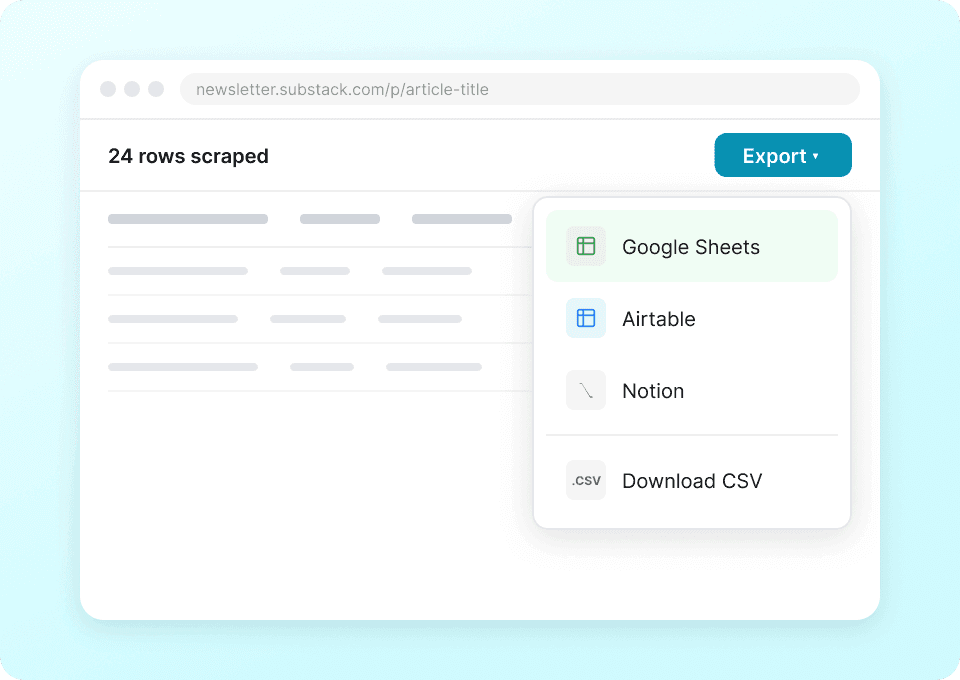
Substack부터 그 이상까지, 하나의 스크래퍼로
웹사이트마다 다른 스크래퍼를 쓰느라 멈춰 서지 마세요. Thunderbit는 Substack에서 바로 사용할 수 있고, 다른 인기 플랫폼용 사전 구축 템플릿도 50개 이상 제공합니다. 발행물 설명, 글 콘텐츠 등을 추출한 다음, 같은 도구로 다른 어디서든 데이터를 수집할 수 있어요.
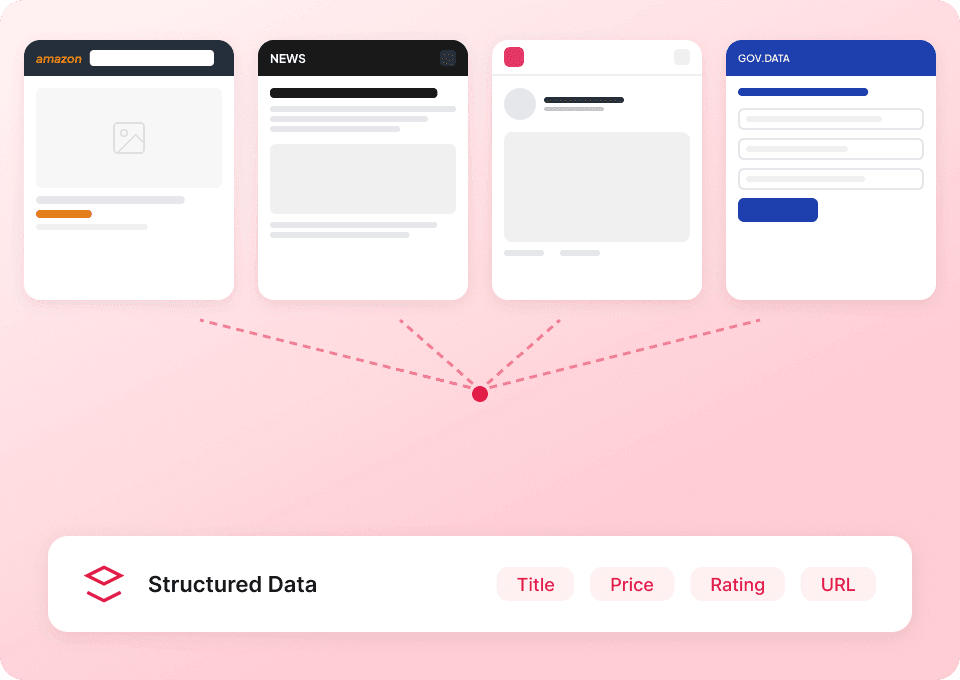
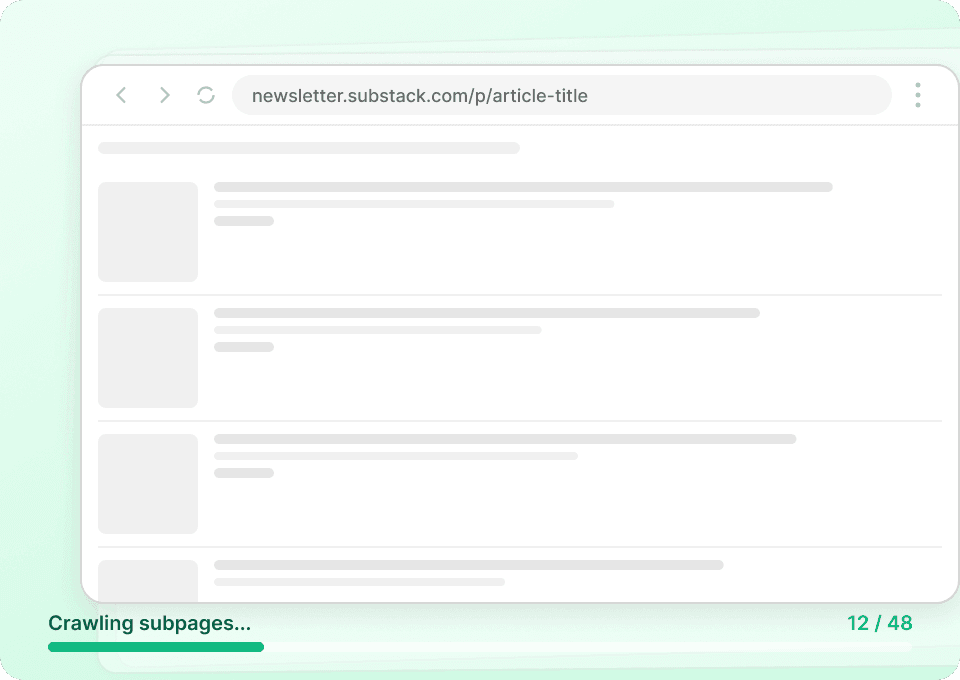
Substack의 전체 내용을 확인하세요
Substack 발행물 목록 페이지에는 요약만 표시됩니다. Thunderbit는 각 글의 하위 페이지를 자동으로 방문해 전체 콘텐츠를 추출하므로, 완전한 데이터셋을 얻을 수 있어요. 글 제목, 작성자 이름, 발행물 이름, 글 내용을 한 번에 모두 가져오세요.
Substack 스크래핑, 제대로 하고 계신가요?
Substack 데이터에서 Thunderbit가 기존 스크래퍼보다 뛰어난 이유를 확인해 보세요.
기존 스크래퍼
예전 방식Thunderbit
더 똑똑한 접근 방식말만 믿지 마세요
Thunderbit에 대한 사용자들의 후기를 확인해 보세요.




자주 묻는 질문
관련 활용 사례
Thunderbit 웹 스크래퍼의 더 많은 활용 사례를 살펴보세요.

Trustpilot 스크래퍼
Trustpilot 페이지를 리뷰, 평점, 작성자 이름이 정리된 깔끔한 스프레드시트로 바꿔보세요. 저희가 각 페이지를 대신 읽어드리기 때문에 코드도, 복붙도 필요 없습니다.
자세히 보기 ->
Tieba 스크래퍼
Thunderbit Tieba 웹 스크래퍼를 사용하면 Baidu Tieba에서 인기 토픽과 포럼 카테고리 데이터를 손쉽게 추출할 수 있습니다. AI 기반 필드 추천 기능으로 토픽명, URL, 게시글 수, 사용자 활동 정보를 빠르게 수집할 수 있어, 연구, 마케팅, 콘텐츠 제작에 유용합니다. Tieba 내 소셜 트렌드와 토론 분석에 최적화된 도구입니다.
자세히 보기 ->
UpCity 스크래퍼
Thunderbit UpCity 스크래퍼를 사용하면 UpCity의 광고 에이전시 목록과 제공업체 리뷰 데이터를 손쉽게 추출할 수 있습니다. AI 기반 필드 추천 기능으로 에이전시 이름, 위치, 평점, 연락처, 상세 리뷰 내용까지 빠르게 수집할 수 있어 분석이나 리서치에 유용합니다. 체계적인 UpCity 데이터를 원하는 마케터, 연구자, 비즈니스 오너에게 최적의 도구입니다.
자세히 보기 ->PeopleWhiz 스크래퍼
Thunderbit PeopleWhiz 스크래퍼를 사용하면 AI 기반 필드 추천으로 PeopleWhiz 검색 결과와 프로필에서 데이터를 추출할 수 있어요. 이름, 연락처, 위치 등 리서치, 마케팅, 리드 생성에 필요한 정보를 수집해 보세요. PeopleWhiz 데이터를 구조화된 데이터셋으로 빠르고 효율적으로 변환할 수 있어요.
자세히 보기 ->
유나이티드 항공 스크래퍼
포인트 앤 클릭 방식으로 United Airlines 항공편 데이터—항공편 번호, 도착 시간, 출발 공항 등—를 손쉽게 수집하세요. 나머지는 Thunderbit AI가 알아서 처리합니다.
자세히 보기 ->
Amarillas.com 스크래퍼
Thunderbit Amarillas.com 스크래퍼를 사용하면 Amarillas.com에서 모텔, 레스토랑 등 다양한 업종의 구조화된 데이터를 손쉽게 추출할 수 있습니다. AI 기반 필드 추천 기능으로 비즈니스 이름, 위치, 연락처, 평점, 리뷰 등 필요한 정보를 빠르게 수집해 리서치, 마케팅, 리드 발굴에 활용해보세요.
자세히 보기 ->데이터 추출 효율을 한 단계 높일 준비가 되셨나요?
이미 Thunderbit로 웹 스크래핑 워크플로를 자동화하는 100,000명 이상의 전문가들과 함께하세요.
무료 체험에서는 8개 웹페이지에 대해 무제한 크레딧을 제공합니다.