Pixiv 스크래퍼
유수 기업의 전문가들이 신뢰합니다











Pixiv 데이터 스크래핑을 더 쉽게
수동 복사-붙여넣기 없이 headline, author, section 같은 Pixiv 데이터를 추출하세요.
대량으로 Pixiv 데이터 스크래핑
Pixiv 데이터를 페이지별로 직접 모으는 방식은 금방 느려져요. 특히 수십 개, 수백 개의 제목, 기사 요약, 작성자, 게시일, 뉴스 출처, 섹션이 필요할 때 더 그렇죠. Thunderbit은 URL 목록을 한 번에 스크래핑할 수 있어서, 반복 작업에 시간을 낭비하지 않고 몇 페이지에서 대규모 Pixiv 기록으로 바로 확장할 수 있어요.

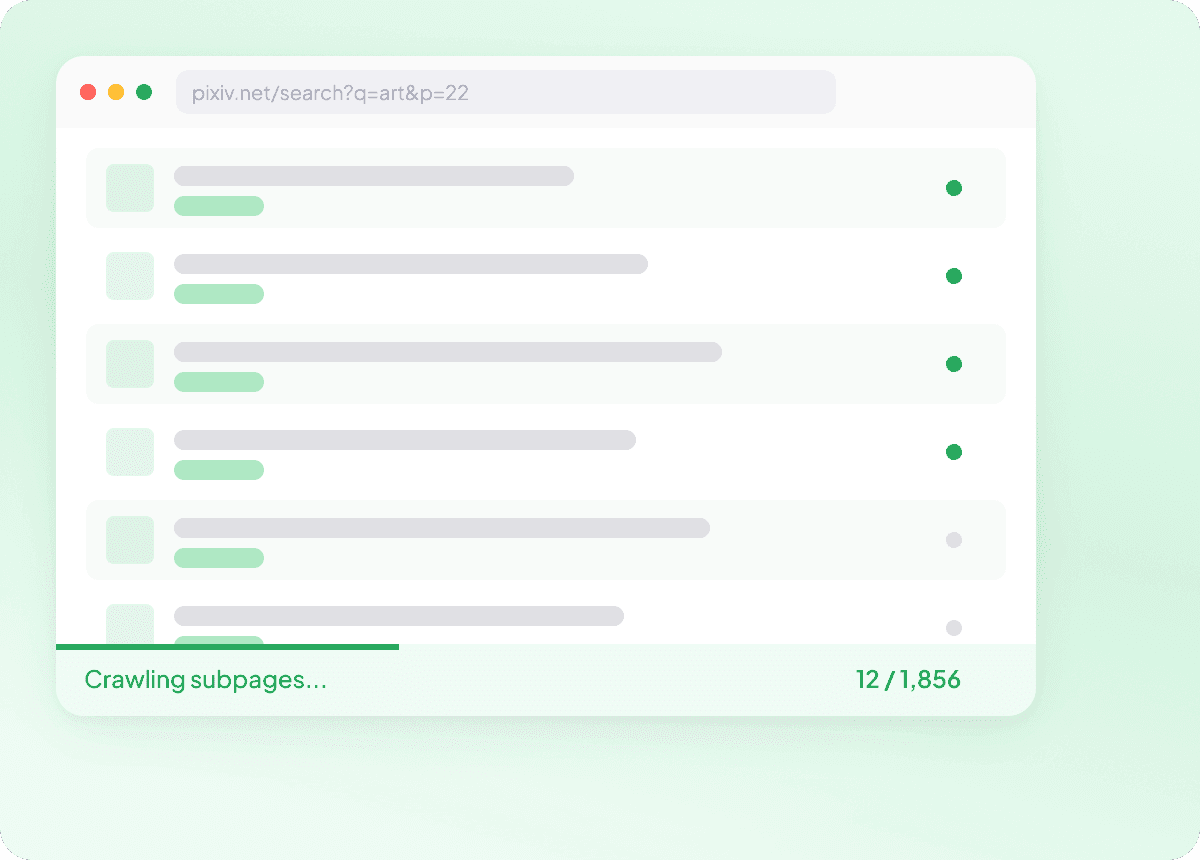
Pixiv 하위 페이지의 전체 세부 정보 캡처
Pixiv의 목록 페이지에는 보통 기본 정보만 표시되고, 실제 세부 정보는 각 기사나 게시물의 하위 페이지에 들어 있어요. Thunderbit은 연결된 모든 하위 페이지를 방문해 전체 정보를 가져오며, 기사 요약, 작성자, 게시일, 뉴스 출처, 섹션 같은 더 풍부한 데이터를 깔끔한 구조로 제공해요.
Pixiv 데이터를 자동으로 최신 상태로 유지
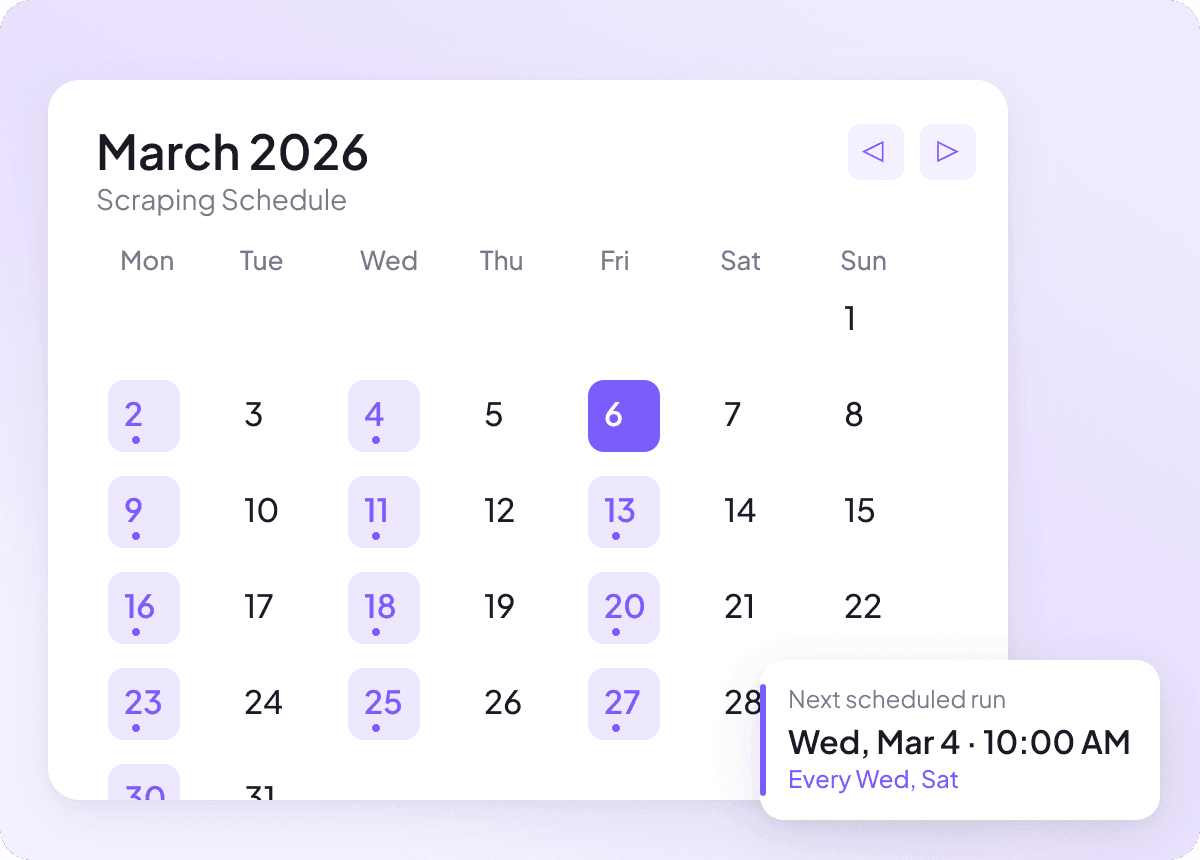
Pixiv 콘텐츠는 매일 바뀔 수 있고, 수동으로 따라가려면 같은 페이지를 계속 확인해야 해요. 예약 스크래핑을 사용하면 Thunderbit이 자동으로 실행되어 정기적으로 최신 Pixiv 데이터를 스프레드시트에 전달해 주므로, 제목, 작성자, 섹션 추적을 손대지 않고도 최신 상태로 유지할 수 있어요.
Thunderbit이 기존 pixiv 스크래퍼와 다른 이유는 무엇인가요?
취약한 셀렉터나 정리 작업 없이 Pixiv를 더 쉽게 스크래핑하는 방법이에요.
기존 스크래퍼
예전 방식Thunderbit AI
더 똑똑한 접근 방식말만 믿지 마세요
사용자들이 Thunderbit에 대해 뭐라고 하는지 확인해 보세요.




자주 묻는 질문
관련 활용 사례
Thunderbit 웹 스크래퍼의 더 많은 활용 사례를 살펴보세요.
PeopleWhiz 스크래퍼
Thunderbit PeopleWhiz 스크래퍼를 사용하면 AI 기반 필드 추천으로 PeopleWhiz 검색 결과와 프로필에서 데이터를 추출할 수 있어요. 이름, 연락처, 위치 등 리서치, 마케팅, 리드 생성에 필요한 정보를 수집해 보세요. PeopleWhiz 데이터를 구조화된 데이터셋으로 빠르고 효율적으로 변환할 수 있어요.
자세히 보기 ->
ReverseAustralia 스크래퍼
Thunderbit ReverseAustralia 웹 스크래퍼를 사용하면 ReverseAustralia의 불만 및 댓글 페이지에서 데이터를 손쉽게 추출할 수 있습니다. AI 기반 필드 추천 기능으로 전화번호, 불만 설명, 댓글 내용, 사용자 이름 등 다양한 정보를 빠르게 수집하여 분석이나 리서치에 활용할 수 있습니다. 마케터, 연구자, 피드백 데이터를 체계적으로 수집하려는 기업에 최적화된 도구입니다.
자세히 보기 ->
Tieba 스크래퍼
Thunderbit Tieba 웹 스크래퍼를 사용하면 Baidu Tieba에서 인기 토픽과 포럼 카테고리 데이터를 손쉽게 추출할 수 있습니다. AI 기반 필드 추천 기능으로 토픽명, URL, 게시글 수, 사용자 활동 정보를 빠르게 수집할 수 있어, 연구, 마케팅, 콘텐츠 제작에 유용합니다. Tieba 내 소셜 트렌드와 토론 분석에 최적화된 도구입니다.
자세히 보기 ->
iBegin 스크래퍼
Thunderbit iBegin 스크래퍼를 사용하면 iBegin 웹사이트에서 비즈니스 검색 결과와 상세 정보를 손쉽게 추출할 수 있습니다. AI 기반 필드 추천 기능을 통해 비즈니스 이름, 연락처, 주소, 평점 등 다양한 정보를 빠르게 수집하여 리드 발굴, 시장 조사, 마케팅 분석 등에 활용해 보세요.
자세히 보기 ->
화이트 페이지 스크래퍼
Thunderbit White Pages 웹 스크래퍼는 AI 기반 필드 추천 기능으로 White Pages의 전화번호 및 비즈니스 목록에서 데이터를 손쉽게 추출할 수 있도록 도와줍니다. 몇 번의 클릭만으로 리드 발굴, 마케팅, 리서치에 필요한 이름, 전화번호, 주소, 웹사이트 URL을 빠르게 수집하세요.
자세히 보기 ->
사람 검색 스크래퍼
Thunderbit People-Search 웹 스크래퍼는 People-Search 프로필과 역전화번호 조회 페이지에서 구조화된 데이터를 추출할 수 있도록 도와줍니다. AI 기반 필드 추천 기능을 활용해 이름, 위치, 전화번호, 이메일 등 다양한 정보를 빠르게 수집할 수 있어, 리서치, 마케팅, 리드 발굴에 적합합니다. 공개 기록과 연락처 정보가 필요한 마케터, 연구자, 기업에게 이상적인 도구입니다.
자세히 보기 ->데이터 추출을 한 단계 끌어올릴 준비가 됐어?
이미 10만 명 이상의 전문가가 Thunderbit으로 웹 스크래핑 워크플로를 자동화하고 있습니다.
무료 체험으로 8개 웹페이지까지 무제한 크레딧을 제공합니다.