IDCrawl 스크래퍼
유수 기업의 전문가들이 신뢰합니다











계속 활용할 수 있는 Idcrawl 데이터
Thunderbit로 idcrawl 데이터를 더 빠르고, 더 깔끔하게, 더 대규모로 추출해 보세요.
Idcrawl이 바뀌어도 유연하게 대응
사이트가 업데이트될 때마다 깨지는 스크래퍼는 쓸모가 없어요. 특히 idcrawl에서 성명, 직함, 회사명, 이메일 주소, 전화번호, LinkedIn 프로필을 뽑아야 할 때는 더 그렇습니다. Thunderbit는 고정 셀렉터가 아니라 페이지의 의미를 읽기 때문에, 레이아웃이 바뀌어도 적응할 수 있어요. 스크래퍼를 고치는 시간은 줄이고, 필요한 데이터를 얻는 데 더 많은 시간을 쓸 수 있습니다.
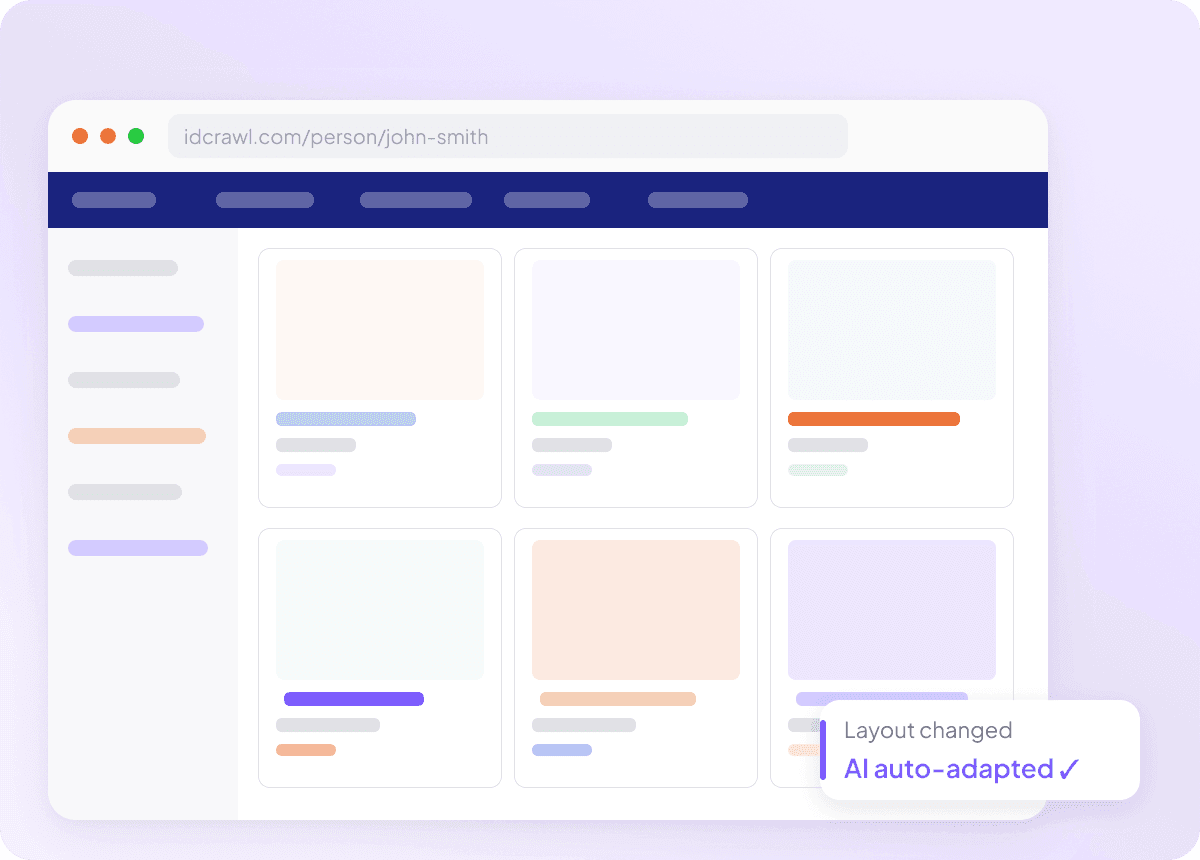
처음부터 깔끔한 데이터
원시 데이터는 실제 작업의 시작일 뿐이고, idcrawl 결과는 보통 활용하기 전에 정리가 필요해요. Thunderbit는 추출하는 동안 데이터를 구조화하고 형식을 맞춰 주기 때문에, 내보낸 결과가 이미 깔끔하고 바로 사용할 수 있는 상태입니다. 즉, 정리 작업은 줄고, 재작업도 줄며, 팀에 넘기는 과정도 훨씬 매끄러워져요.
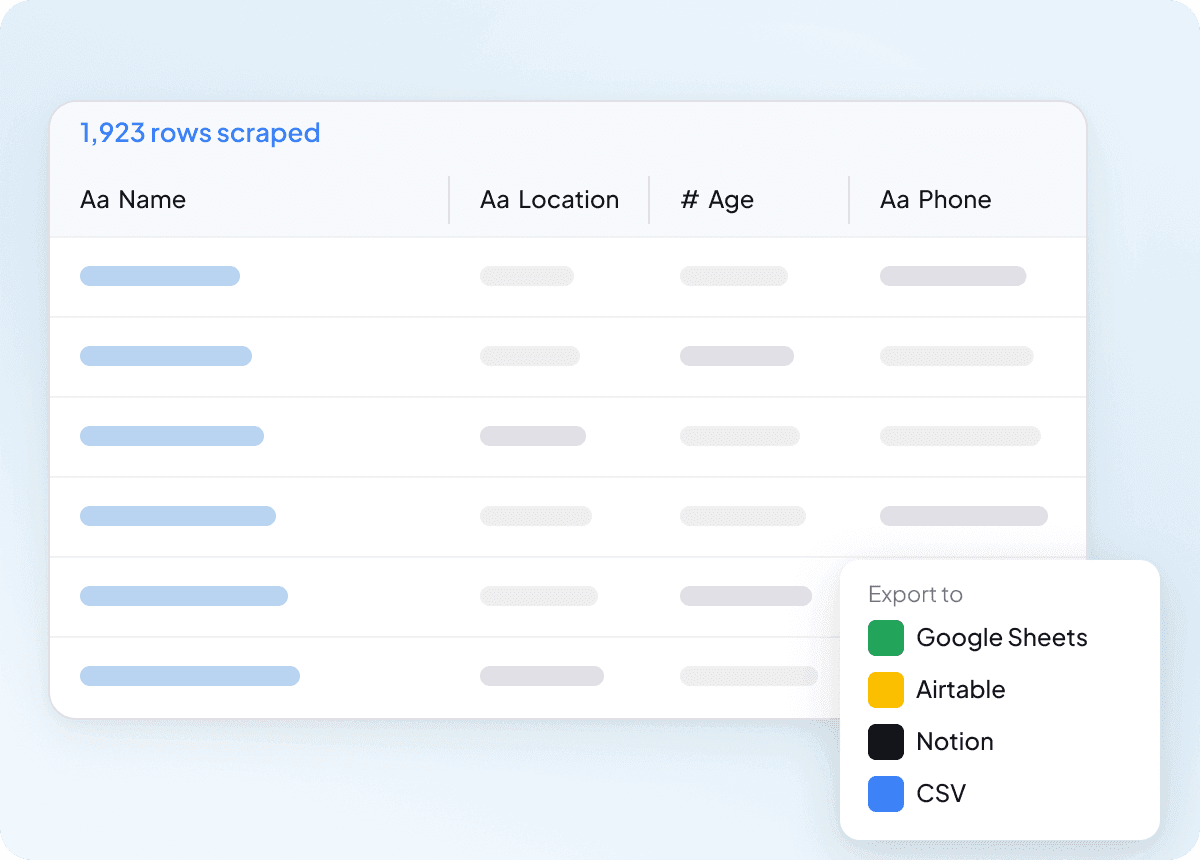
한 번에 Idcrawl 대량 수집
연락처 목록이 길어질수록 idcrawl 페이지를 하나씩 수집하는 방식은 확장성이 떨어집니다. Thunderbit는 수백 개의 페이지를 한 번에 대량 수집할 수 있어서, URL 목록을 넣고 성명, 직함, 회사명, 이메일 주소, 전화번호, LinkedIn 프로필을 전부 추출할 수 있어요. 큰 목록을 바로 쓸 수 있는 데이터로 바꾸는 훨씬 쉬운 방법입니다.

Thunderbit가 기존 idcrawl 스크래퍼와 다른 이유는 무엇인가요?
계속 수정할 필요 없이 idcrawl 데이터를 더 쉽게 추출하는 방법입니다.
기존 스크래퍼
예전 방식Thunderbit AI
더 스마트한 접근 방식말만 믿지 마세요
사용자들이 Thunderbit에 대해 뭐라고 하는지 확인해 보세요.






자주 묻는 질문
관련 활용 사례
Thunderbit 웹 스크래퍼의 더 많은 활용 사례를 살펴보세요.

사람 검색 스크래퍼
Thunderbit People-Search 웹 스크래퍼는 People-Search 프로필과 역전화번호 조회 페이지에서 구조화된 데이터를 추출할 수 있도록 도와줍니다. AI 기반 필드 추천 기능을 활용해 이름, 위치, 전화번호, 이메일 등 다양한 정보를 빠르게 수집할 수 있어, 리서치, 마케팅, 리드 발굴에 적합합니다. 공개 기록과 연락처 정보가 필요한 마케터, 연구자, 기업에게 이상적인 도구입니다.
자세히 보기 ->
HKTVmall 웹 스크래퍼
복잡한 설정 없이 단 몇 번의 클릭만으로 HKTVmall 상품 목록에서 상품명, 가격, 고객 평점까지 손쉽게 수집하세요.
자세히 보기 ->Substack 스크래퍼
Substack 구독자 수, 글 제목, 발행물 설명을 깔끔한 스프레드시트로 가져오세요. 코드는 필요 없고, AI가 구조화를 처리합니다.
자세히 보기 ->
ReverseAustralia 스크래퍼
Thunderbit ReverseAustralia 웹 스크래퍼를 사용하면 ReverseAustralia의 불만 및 댓글 페이지에서 데이터를 손쉽게 추출할 수 있습니다. AI 기반 필드 추천 기능으로 전화번호, 불만 설명, 댓글 내용, 사용자 이름 등 다양한 정보를 빠르게 수집하여 분석이나 리서치에 활용할 수 있습니다. 마케터, 연구자, 피드백 데이터를 체계적으로 수집하려는 기업에 최적화된 도구입니다.
자세히 보기 ->
화이트 페이지 스크래퍼
Thunderbit White Pages 웹 스크래퍼는 AI 기반 필드 추천 기능으로 White Pages의 전화번호 및 비즈니스 목록에서 데이터를 손쉽게 추출할 수 있도록 도와줍니다. 몇 번의 클릭만으로 리드 발굴, 마케팅, 리서치에 필요한 이름, 전화번호, 주소, 웹사이트 URL을 빠르게 수집하세요.
자세히 보기 ->
UpCity 스크래퍼
Thunderbit UpCity 스크래퍼를 사용하면 UpCity의 광고 에이전시 목록과 제공업체 리뷰 데이터를 손쉽게 추출할 수 있습니다. AI 기반 필드 추천 기능으로 에이전시 이름, 위치, 평점, 연락처, 상세 리뷰 내용까지 빠르게 수집할 수 있어 분석이나 리서치에 유용합니다. 체계적인 UpCity 데이터를 원하는 마케터, 연구자, 비즈니스 오너에게 최적의 도구입니다.
자세히 보기 ->데이터 추출을 한 단계 끌어올릴 준비가 됐어?
이미 10만 명 이상의 전문가가 Thunderbit으로 웹 스크래핑 워크플로를 자동화하고 있습니다.
무료 체험으로 8개 웹페이지까지 무제한 크레딧을 제공합니다.