
솔직히 말하면, 인터넷은 끝없이 뻗어 나가는 거대한 정글 같아요. 하루에도 25만 개가 넘는 새 웹사이트가 생겨나고, 구글 검색 인덱스에는 300억 개가 넘는 웹페이지가 쌓여 있거든요. 그러면 이 엄청난 정보를 검색 엔진은 대체 어떻게 따라잡고, 기업들은 이 디지털 미로에서 필요한 정보를 어떻게 찾아낼까요? SaaS와 자동화 업계에서 오래 일해 온 저도 아직까지 자주 듣는 질문이 있어요. "웹 크롤링이랑 웹 스크래핑, 뭐가 달라요? 그냥 같은 거 아니에요?" 결론부터 말씀드리면, 둘은 아주 다르거든요. 이걸 헷갈리면 프로젝트 방향이 한참 엇나갈 수도 있어요.
영업 리드를 찾고 있든, 이커머스 가격을 모니터링하든, 아니면 그냥 회의에서 좀 똑똑해 보이고 싶든, 지금부터 웹 크롤러가 실제로 어떤 일을 하는지, 스크래퍼와는 어떻게 다른지, 그리고 Thunderbit 같은 제대로 된 도구가 왜 필요한지를 차근차근 풀어 볼게요.
웹 크롤러란? 기본부터 차근차근

세상에서 제일 꼼꼼한 사서를 한번 떠올려 보세요. 이 사서는 단순히 책을 정리만 하는 게 아니라, 매일 도서관 서가를 돌면서 새 책이 들어왔는지 직접 확인해요. 웹 크롤러도 이런 느낌이에요. 다만 책 대신 수십억 개의 웹페이지를 돌아다닌다는 점이 다르죠. 웹 크롤러(스파이더, 봇이라고도 불러요)는 자동화된 프로그램으로, 웹사이트의 링크를 따라가면서 페이지를 탐색하고 그 내용을 차곡차곡 모아요. 구글이나 Bing 같은 검색 엔진이 거대한 인덱스를 만들 수 있는 것도 다 이 덕분이고요.
"Googlebot"이나 "Bingbot" 같은 이름, 한 번쯤 들어 보셨을 거예요. 바로 이런 유명한 크롤러들이 백그라운드에서 부지런히 일하고 있는 거예요. 최근에는 Firecrawl처럼 개발자나 기업이 사이트 전체를 크롤링해 AI나 데이터 분석에 쓸 구조화된 데이터를 만들어 주는 도구도 등장했어요.
여기서 짚고 가야 할 포인트가 하나 있어요. 크롤링은 어디까지나 발견이 목적이에요. 페이지를 찾아내고 인덱싱하는 데 초점이 있지, 특정 데이터를 뽑아내는 작업은 아니거든요. 이 부분이 웹 스크래핑과 가장 크게 갈리는 지점이에요(아래에서 더 자세히 다뤄 볼게요).
웹 크롤러는 어떻게 돌아갈까?
웹 크롤러의 하루를 한번 따라가 볼까요? 크롤러는 "시드 URL"이라고 부르는 출발점 목록을 들고 디지털 탐험을 시작해요. 큰 흐름을 보면 이렇게 돼요.
- 시드 URL: 크롤러는 미리 정해 둔 웹 주소 목록에서 출발해요.
- 가져오기 & 파싱: 각 URL을 방문해 페이지를 불러오고, 안에 있는 링크를 분석해요.
- 링크 따라가기: 새로 찾은 링크들을 "다음에 방문할 목록"에 추가해요.
- 인덱싱: 페이지 전체 내용이나 메타데이터를 저장해요.
- 예의 지키기: 사이트마다 robots.txt 파일을 확인해 크롤링이 허용된 영역인지 보고, 서버에 부담을 주지 않도록 요청 사이에 적당한 간격을 둬요.
- 지속적 업데이트: 웹은 늘 변하니까, 크롤러도 주기적으로 페이지를 다시 방문해서 최신 상태를 유지해요.
도시의 골목과 가게를 직접 걸어다니면서 지도를 그리고, 변화가 생길 때마다 그 자리를 업데이트하는 일과 비슷한 셈이에요.
웹 크롤러의 핵심 구성 요소
비전문가라도 기본 구조만 잡아 두면 훨씬 이해가 쉬워져요.
- URL 프론티어(큐): 다음에 방문할 URL 목록을 관리해요.
- 페처/다운로더: 실제로 웹페이지를 불러오는 역할이에요.
- 파서: 페이지에서 링크나 필요한 정보를 뽑아내요.
- 중복 제거 & URL 필터: 같은 페이지를 반복해서 방문하거나 무한 루프에 빠지는 걸 막아 줘요.
- 데이터 저장/인덱스: 모은 정보를 차곡차곡 쌓아 두는 공간이에요.
신문사를 예로 들면, 한 명은 신문을 가져오고, 다른 한 명은 주요 기사에 형광펜을 긋고, 또 다른 사람은 스크랩을 정리하고, 마지막으로 누군가는 다음에 읽을 신문 목록을 관리하는 식이에요.
웹사이트 크롤링: 도구와 접근법
비즈니스 사용자라면 직접 크롤러를 만들어 보고 싶을 수도 있을 거예요. 다만 제 경험상으로는 직접 개발하는 길은 잘 권하지 않아요. 구글 같은 검색 엔진을 만들 게 아니라면, 이미 검증된 도구가 충분히 많거든요.
대표적인 웹 크롤링 도구는 이런 게 있어요.
- Scrapy: 오픈소스, 개발자 중심, 대규모 프로젝트에 잘 맞아요.
- Apache Nutch: 빅데이터 인덱싱과 연구용으로 자주 쓰여요.
- Heritrix: 인터넷 아카이브의 웹 아카이빙 도구예요.
- Screaming Frog SEO Spider: SEO 전문가들이 사이트 크롤링과 진단에 자주 활용해요.
- Firecrawl: 최신 API 기반으로, 사이트 전체에서 구조화된 데이터를 뽑아낼 수 있어요.
참고로, 대부분의 도구는 어느 정도 기술적인 설정이 필요해요. "노코드"라고 하는 도구도 HTML 요소 선택이나 사이트 구조 변화, 동적 콘텐츠 처리 같은 부분에서 학습 곡선이 있을 수 있고요. 단순히 페이지 몇 개에서 데이터만 뽑으면 되는 상황이라면, 굳이 크롤러까지 동원할 필요는 없어요.
웹 크롤링 vs. 웹 스크래핑: 뭐가 다를까?
이 둘을 헷갈려하시는 분들이 정말 많은데요, 크롤링과 스크래핑은 서로 연결돼 있긴 해도 목적과 방식이 달라요.
| 항목 | 웹 크롤링 | 웹 스크래핑 |
|---|---|---|
| 목적 | 웹페이지 발견 및 인덱싱 | 웹페이지에서 특정 데이터 추출 |
| 비유 | 모든 책을 분류하는 사서 | 일부 페이지에서 핵심 정보만 복사 |
| 결과물 | URL 목록, 페이지 내용, 사이트맵 | 구조화된 데이터(CSV, Excel, JSON 등) |
| 주요 사용자 | 검색 엔진, SEO 도구, 아카이브 | 영업, 이커머스, 데이터 분석, 리서치 |
| 규모 | 수십억 페이지(광범위) | 수십~수천 페이지(타겟팅) |
한 줄로 정리하면, 크롤링은 페이지를 찾는 일이고, 스크래핑은 원하는 데이터를 뽑아내는 일이에요. (nimbleway.com)
웹 크롤링/스크래핑의 주요 과제와 실전 팁
주요 어려움
- 웹사이트 구조 변경: 디자인이 살짝만 바뀌어도 도구가 제대로 동작하지 않을 수 있어요. (octoparse.com)
- 동적 콘텐츠: 많은 사이트가 JavaScript로 데이터를 불러와서, 기본 크롤러로는 잘 안 보일 때도 있어요.
- 봇 차단: CAPTCHA, IP 차단, 로그인 요구 같은 장벽 때문에 접근이 막힐 수 있어요.
- 규모 문제: 수천 페이지 단위로 크롤링하면 컴퓨터가 버거워하거나 IP가 차단되기도 해요.
- 법적/윤리적 이슈: 공개 데이터 스크래핑은 대체로 괜찮지만, 사이트 이용약관과 개인정보 보호법은 꼭 확인해 두는 게 좋아요. (web.instantapi.ai)
실전 팁
- 상황에 맞는 도구 고르기: 코딩이 부담스럽다면 노코드 스크래퍼부터 시작해 보세요.
- 데이터 목표 명확히 잡기: 어떤 데이터를 왜 모을지 먼저 정해 두면 좋아요.
- 사이트 정책 지키기: 늘 robots.txt와 이용약관을 먼저 확인해 보세요.
- 서버 과부하 막기: 요청 사이에 딜레이를 두고, 서버에 무리가 가지 않게 신경 써 주세요.
- 유지보수 계획 세우기: 사이트 구조는 바뀌게 마련이라, 설정도 주기적으로 점검해 줘야 해요.
- 데이터 정제와 보안: 결과를 안전하게 저장하고, 중복이나 오류가 없는지도 확인해 보세요.
실제 활용 사례: 크롤링 vs. 스크래핑
웹 크롤링
- 검색 엔진 인덱싱: Googlebot, Bingbot이 웹을 크롤링하면서 최신 검색 결과를 만들어 줘요. (en.wikipedia.org)
- 웹 아카이빙: 인터넷 아카이브가 Wayback Machine을 위해 사이트를 크롤링하는 식이에요.
- SEO 진단: 사이트의 깨진 링크나 누락된 태그 같은 걸 찾기 위해 크롤링을 돌려요.
웹 스크래핑
- 가격 모니터링: 소매업체가 경쟁사 상품 페이지에서 가격 정보를 모아요. (nextgeninvent.com)
- 리드 발굴: 영업팀이 디렉터리에서 연락처 정보를 추출해요.
- 콘텐츠 집계: 뉴스나 채용 사이트가 여러 소스에서 목록을 모아 와요.
- 시장 조사: 분석가들이 리뷰나 소셜 미디어 데이터를 모아 감성 분석에 활용해요.
참고로 82%가 넘는 이커머스 기업이 외부 데이터 수집에 웹 스크래핑을 쓰고 있어요. 경쟁사도 이미 활용하고 있을 가능성이 꽤 높은 거죠.
언제 웹 크롤링, 언제 웹 스크래핑을 써야 할까?
빠르게 판단할 수 있는 기준을 정리해 봤어요.
-
새로운 페이지를 발견하거나 사이트 전체를 인덱싱해야 하나요?
→ 웹 크롤링을 써요.
-
데이터가 어디에 있는지(특정 페이지/섹션) 이미 알고 있나요?
→ 웹 스크래핑이 맞아요.
-
검색 엔진 구축이나 웹 아카이빙이 목적인가요?
→ 크롤링이 잘 맞아요.
-
영업, 가격, 리서치처럼 실질적인 데이터 수집이 목적인가요?
→ 스크래핑이 정답이에요.
-
잘 모르겠다면요?
→ 대부분의 비즈니스에는 스크래핑만으로도 충분해요.
비즈니스 사용자 대다수에게 필요한 건 결국 스크래핑, 그러니까 곧바로 쓸 수 있는 구조화된 데이터일 거예요.
비즈니스 사용자를 위한 웹 스크래핑: Thunderbit의 강점
이제 비전문가를 포함한 대부분의 비즈니스 사용자에게 왜 스크래핑이 더 잘 맞는지, 그리고 Thunderbit는 어떤 점이 다른지 살펴볼게요.
"쉽다"는 스크래핑 도구를 썼다가 오히려 며칠, 몇 주를 고생하는 팀을 정말 많이 봤어요. 그래서 Thunderbit는 웹 데이터 추출을 클릭 두 번이면 끝낼 수 있도록 설계됐어요.
Thunderbit의 주요 강점은 이런 거예요.
- 2번 클릭 워크플로: "AI 필드 추천" 한 번, "스크래핑" 한 번. 코딩이나 복잡한 설정은 필요 없어요.
- 대량 URL & PDF 지원: 여러 URL이나 PDF에서도 데이터를 한꺼번에 뽑아낼 수 있어요.
- 다양한 내보내기: 추출한 데이터를 Google Sheets, Airtable, Notion으로 바로 보내거나 CSV/JSON으로 내려받을 수 있어요. 추가 비용도 없고요.
- 하위 페이지 자동 추출: 상품 상세처럼 하위 페이지도 자동으로 들어가서 데이터 테이블을 풍성하게 채워 줘요.
- AI 자동입력: 반복적인 폼 입력이나 웹 작업도 자동화할 수 있어요. 지루한 업무를 대신해 주는 디지털 비서 같은 느낌이에요.
- 무료 이메일 & 전화번호 추출: 클릭 한 번이면 페이지에 있는 연락처 정보를 한꺼번에 모아 줘요.
- 클라우드/브라우저 스크래핑: 클라우드(초고속) 또는 브라우저(로그인 페이지 등) 중에서 상황에 맞게 고를 수 있어요.
- 학습 곡선 거의 없음: 영업, 이커머스, 마케팅팀 누구나 곧바로 쓸 수 있게 설계돼 있어요.
더 다양한 활용 사례가 궁금하다면 아마존 상품 스크래핑, 구글 검색 결과 스크래핑, 엑셀로 데이터 추출 가이드를 한번 살펴보세요.
Thunderbit vs. 기존 웹 스크래퍼 비교
비즈니스 사용자 입장에서 두 방식을 나란히 두면 이렇게 정리돼요.
| 기능/필요성 | Thunderbit | 기존 웹 스크래퍼(예: Scrapy, Nutch) |
|---|---|---|
| 설정 | 2번 클릭, 코딩 불필요 | 기술적 설정, 스크립트 필요 |
| 학습 곡선 | 거의 없음 | 비전문가에겐 진입장벽 높음 |
| 하위 페이지 처리 | AI 기반 자동화 | 수동 스크립팅 또는 고급 설정 필요 |
| 대량 URL/PDF | 기본 지원 | 기본 미지원, 별도 개발 필요 |
| 결과 포맷 | Google Sheets, Airtable, Notion, CSV | CSV, JSON(연동은 수동) |
| 적응력 | AI가 사이트 변화에 자동 대응 | 사이트 변경 시 수동 수정 필요 |
| 비즈니스 활용 | 영업, 이커머스, SEO, 운영 | 검색엔진 인덱싱, 연구, 아카이빙 |
| 스케줄링 | 자연어로 예약 가능 | 크론잡 등 외부 스케줄러 필요 |
| 가격 | 월 $15부터, 무료 플랜 제공 | 무료/오픈소스지만 설정·유지비용 높음 |
| 지원 | 사용자 중심, 현대적 UI | 커뮤니티 중심, 개발자 위주 |
Thunderbit는 "이 데이터가 필요해"에서 "엑셀 파일 완성!"까지 가장 빠른 길을 만들어 줘요. IT팀에 따로 요청할 필요도 없고요.
마무리: 내 비즈니스에 맞는 접근법 고르기
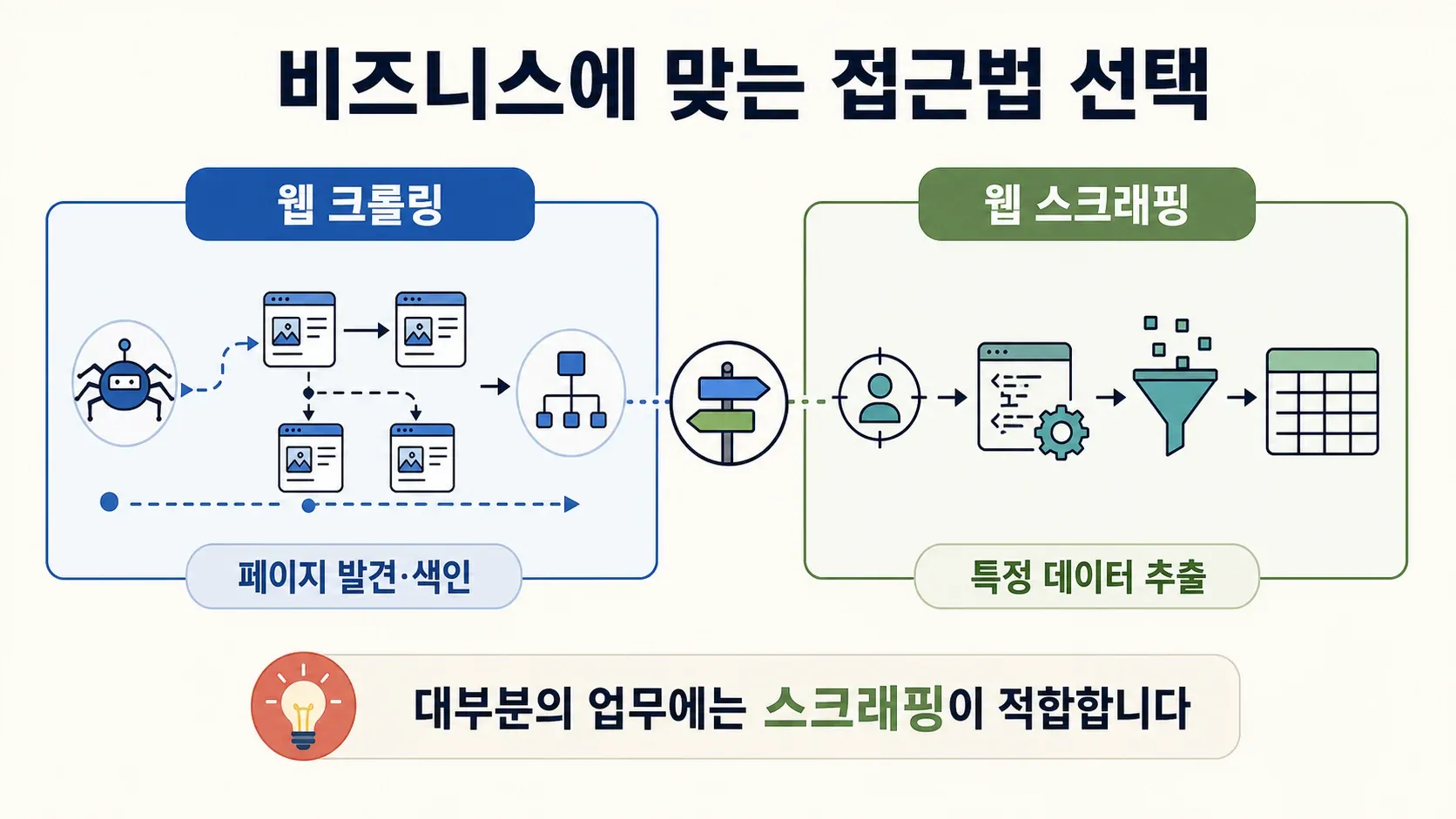
정리하면 이렇게 돼요.
- 웹 크롤링은 페이지를 발견하고 인덱싱하는 데 쓰는 방식이에요. 검색 엔진이나 사이트 진단 같은 작업에 잘 맞아요.
- 웹 스크래핑은 원하는 데이터를 뽑아내는 데 쓰는 방식이에요. 영업 리드, 가격 모니터링, 콘텐츠 집계 등에 활용돼요.
- 비즈니스 사용자 대부분에게 필요한 건 스크래핑이에요. 코딩 지식이 없어도 충분히 다룰 수 있고요.
웹은 갈수록 더 방대하고 복잡해지고 있어요. 그래도 맞는 접근법과 도구만 갖추면, 이 혼돈 속에서도 명확한 인사이트를 끌어낼 수 있어요. 복잡한 스크래퍼에 지치셨거나 IT팀의 지원을 마냥 기다리기 싫다면, Thunderbit를 한번 직접 써 보세요. 클릭 두 번만으로도 꽤 놀라운 결과를 얻을 수 있을 거예요(주말도 챙길 수 있고요).
Thunderbit가 실제로 어떻게 동작하는지 보고 싶다면 Chrome 확장 프로그램을 설치해 보시거나, Thunderbit 블로그에서 더 많은 팁과 가이드를 확인해 보세요.
스크래핑, 즐겁게 해 보세요! (크롤링은… 구글 만들 때만 고민하면 돼요)
자주 묻는 질문(FAQ)
1. 내 비즈니스에 웹 크롤러와 스크래퍼 둘 다 필요할까요?
꼭 그렇지는 않아요. 필요한 데이터가 있는 페이지를 이미 알고 있다면 Thunderbit 같은 웹 스크래퍼 하나로도 충분해요. 크롤러는 사이트 전체를 훑어보거나 SEO 진단처럼 새 페이지를 발견해야 하는 상황에서 더 빛을 발해요.
2. 웹 스크래핑은 합법인가요?
일반적으로 공개된 데이터의 스크래핑은 합법이에요. 다만 로그인 우회나 서비스 약관 위반, 민감 정보 수집 같은 경우는 문제가 될 수 있으니, 상업적으로 활용하기 전에는 robots.txt와 개인정보처리방침을 꼭 확인해 보세요.
3. Thunderbit는 다른 웹 스크래핑 도구와 무엇이 다른가요?
Thunderbit는 코딩이 부담스러운 비즈니스 사용자를 위해 만들어졌어요. 기존 스크래퍼는 HTML 지식이나 수동 설정이 필요한 경우가 많지만, Thunderbit는 AI가 필드를 자동으로 인식하고 하위 페이지까지 따라가서, 원하는 포맷으로 클릭 두 번이면 데이터를 건네줘요.
4. Thunderbit는 동적 웹사이트나 로그인 페이지도 지원하나요?
네, 지원해요. Thunderbit는 브라우저 기반 스크래핑으로 로그인 세션이나 동적 콘텐츠도 추출할 수 있고, 클라우드 기반 스크래핑으로 빠른 대규모 작업도 받쳐 줘요. 데이터 유형에 따라 가장 잘 맞는 방식을 골라 쓰면 돼요.
더 읽어보기
AI 웹 스크래퍼 무료 체험하기 Get Started Free




