
CRM을 동기화하거나, 배송 업데이트를 가져오거나, 두 개의 SaaS 도구를 연결할 때마다 뒤에서 묵묵히 일을 처리하는 건 REST API예요. 대부분은 뭔가 고장 나기 전까지는 그 존재조차 의식하지 않죠.
재미있는 건, 개발자들 사이에서도 어떤 API를 기준으로 "RESTful"하다고 볼 수 있는지 꽤 헷갈려한다는 점이에요. 이 용어가 너무 느슨하게 쓰이다 보니, 한 Reddit 스레드에서는 누군가 이렇게 단정적으로 말했죠. "Roy Fielding의 정의를 기준으로 보면, 내가 진짜 RESTful API를 하나라도 만들어 봤는지 모르겠다." 이 말은 일반 비즈니스 사용자가 아니라 개발자의 발언입니다. 이 개념은 UC Irvine에서 Roy Fielding이 쓴 에서 시작됐고, 그는 REST를 아키텍처 스타일—즉, 설계 제약의 집합—로 설명했어요. 프로토콜도 아니고, 제품도 아니고, 다운로드해서 쓰는 명세도 아닙니다.
그런데도 에 따르면 API 전문가의 93%가 REST를 사용하고 있어요. 거의 모두가 쓰고 있지만, 실제로 무엇이 필요한지는 의외로 많은 팀이 오해하고 있는 셈이죠. 이 글에서는 REST API의 6가지 핵심 특성을 쉬운 말로 풀어 설명하고, 어떤 특성을 가장 많이 잘못 이해하는지 보여드린 뒤, 스스로 점검할 수 있는 성숙도 모델을 소개하고, REST를 SOAP, GraphQL, gRPC와 비교해볼게요.
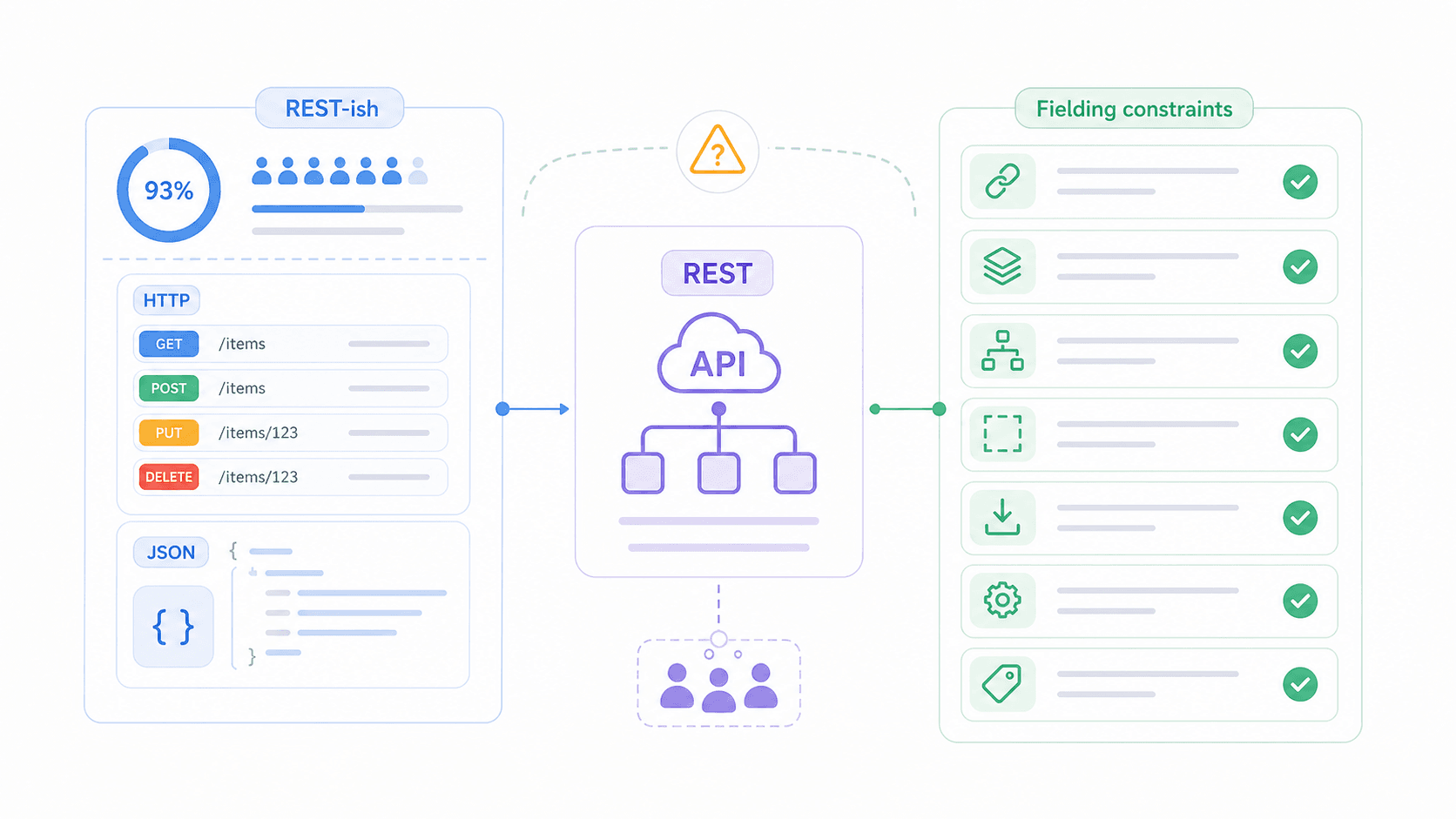
REST API란 무엇인가요? (쉽게 풀어쓴 정의)
REST(Representational State Transfer)는 소프트웨어 시스템이 네트워크를 통해 어떻게 통신해야 하는지에 대한 설계 규칙의 집합이에요.
좀 더 정확히 말하면, REST는 무상태성, 캐시 가능성, 통일된 인터페이스 같은 제약을 정의하는 아키텍처 스타일입니다. 이 제약들은 클라이언트(브라우저, 모바일 앱, 자동화 도구)가 서버(데이터가 저장된 곳)와 상호작용하는 방식을 안내해요. REST는 보통 HTTP 위에서 동작하고 JSON을 반환하는 경우가 많지만, REST 자체가 특정 프로토콜이나 데이터 형식에 묶여 있는 건 아닙니다.
저녁 식사 자리의 에티켓 규칙이라고 생각해보면 쉬워요. REST는 어떤 음식을 내야 하는지, 어떤 언어를 써야 하는지는 정하지 않아요. 대신 어떻게 음식을 건네고, 어떻게 더 달라고 하고, 어떻게 식사가 끝났음을 알리는지를 정합니다. 같은 에티켓을 따르는 두 시스템은 서로 처음 만나도 예측 가능하게 대화할 수 있어요.
REST가 아닌 것: REST는 설치하는 제품이 아니에요. HTTP나 SOAP 같은 프로토콜도 아닙니다. 그리고 API를 "RESTful"하다고 부른다고 해서 Fielding의 원래 제약을 전부 충족한다는 뜻도 아니에요. 보통은 리소스 URL과 HTTP 메서드를 사용한다는 정도를 의미하죠. "REST 비슷한 것"과 "진짜 RESTful" 사이의 간극은 업계에서 가장 큰 혼란 요인 중 하나이고, 잠시 뒤에 더 자세히 살펴볼게요.
한눈에 보는 REST API의 6가지 특성
본격적으로 들어가기 전에 먼저 요약표부터 볼게요. Fielding은 API가 RESTful하다고 간주되려면 따라야 할 6가지 제약을 정의했습니다. 그중 5개는 필수이고, 1개는 선택 사항이에요.
| 제약 | 핵심 개념 | 주요 이점 | 구체적 예시 |
|---|---|---|---|
| 클라이언트-서버 | UI와 데이터 저장소를 분리 | 프런트엔드와 백엔드가 독립적으로 발전 가능 | React SPA가 REST API를 호출 |
| 무상태성 | 각 요청이 필요한 모든 맥락을 포함 | 수평 확장성, 세션 종속성 없음 | 모든 요청 헤더에 인증 토큰 전송 |
| 캐시 가능성 | 응답이 캐시 가능한지 명시 | 지연 시간과 서버 부하 감소 | GET 응답에 Cache-Control: max-age=3600 |
| 통일된 인터페이스 | 표준화된 리소스 상호작용 | 예측 가능하고 배우기 쉬운 API 표면 | GET /users/42, DELETE /users/42 |
| 계층화 시스템 | 클라이언트는 서버에 직접 말하는지 알 수 없음 | CDN, 게이트웨이, 로드 밸런서 삽입 가능 | 클라이언트 → CDN → API 게이트웨이 → 앱 서버 |
| 코드 온 디맨드(선택) | 서버가 실행 코드를 보내 클라이언트를 확장 | 필요할 때 클라이언트 기능 확장 | JavaScript 위젯 조각을 반환하는 API |
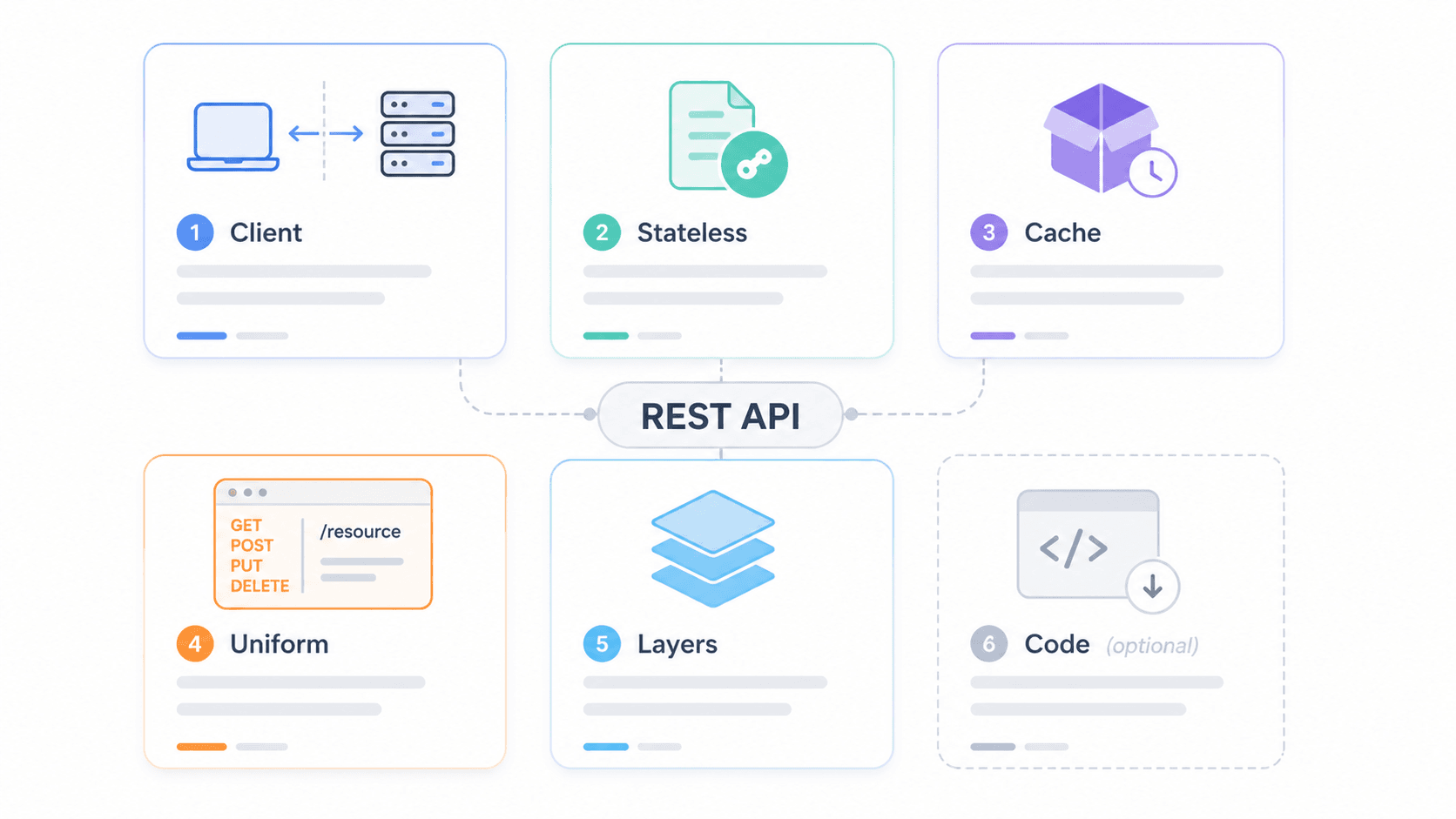
이 제약들이 실제 시스템에서 어떻게 함께 작동하는지 보려면, 아래와 같은 계층형 아키텍처를 떠올려보세요.
1클라이언트 / 모바일 앱
2 ↓
3CDN / 엣지 캐시 (예: Cloudflare)
4 ↓
5API 게이트웨이 (속도 제한, 인증, CORS)
6 ↓
7로드 밸런서
8 ↓
9애플리케이션 서버
10 ↓
11데이터베이스 / 내부 서비스클라이언트는 오직 CDN 계층과만 통신해요. 뒤에 몇 개의 계층이 있는지는 알지 못하죠. 이게 바로 계층화 시스템 제약이 실제로 작동하는 방식이고, 보안, 캐싱, 확장이 클라이언트가 알 필요 없이 이뤄지는 지점이기도 합니다.
이제 세부적으로 하나씩 살펴볼게요.
REST API 특성, 하나씩 풀어서 보기
클라이언트-서버 분리
Fielding의 첫 번째 제약은 클라이언트(사용자가 직접 상호작용하는 부분)와 서버(데이터와 로직이 있는 부분)는 반드시 분리되어야 한다는 거예요. 그는 이를 관심사의 분리라고 불렀습니다.
실무에서 왜 중요할까요? 모바일 뱅킹 앱이 완전히 새로운 화면으로 바뀌더라도, 은행이 계좌 데이터베이스나 거래 엔진을 건드릴 필요가 없다는 뜻이기 때문이에요. 예를 들어 는 연락처, 캠페인, 여정, 푸시 알림을 리소스 엔드포인트로 제공해요. 맞춤형 대시보드를 만들든, 모바일 앱을 만들든, 외부 도구를 연결하든 백엔드는 그대로 유지됩니다.
비즈니스 팀 입장에서는 이것이 더 빠른 반복 작업으로 이어져요. 프런트엔드 디자이너와 백엔드 엔지니어가 같은 릴리스 주기에 묶일 필요가 없거든요. API 계약만 안정적이라면 양쪽은 독립적으로 움직일 수 있습니다.
무상태성
요청 사이에 기억이 없다는 뜻이에요. 클라이언트가 서버로 보내는 모든 호출에는 그 요청을 처리하는 데 필요한 정보가 전부 포함되어 있어야 하고, 서버는 이전 상호작용의 흔적을 저장하지 않습니다.
저는 이걸 고객센터에 전화를 걸 때마다 같은 문제를 처음부터 다시 설명해야 하는 상황이라고 생각해요. 답답하죠? 물론이에요. 하지만 장점은 엄청납니다. 사용 가능한 어떤 상담원이든 도와줄 수 있고, 콜센터는 구조를 바꾸지 않고도 상담원 500명을 더 늘릴 수 있어요. 이것이 바로 수평 확장이에요.
기술적으로 말하면, 무상태성이란 sticky session이 없다는 뜻입니다. 로드 밸런서는 다음 요청을 정상 상태의 아무 서버로든 보낼 수 있어요. 한 서버가 다운돼도 다른 서버가 자연스럽게 이어받습니다. Fielding의 논문은 무상태성이 가시성(모니터링 도구가 각 요청을 독립적으로 이해할 수 있음), 신뢰성(장애가 공유 세션 상태를 망가뜨리지 않음), 확장성(서버가 요청 사이에 자원을 비울 수 있음)을 높인다고 설명합니다.
현실적인 주의점도 있어요. 실제 시스템에는 인증 토큰, 장바구니, OAuth 흐름이 존재하죠. 핵심은 어떤 상태도 어디에도 존재하지 않는다는 뜻이 아니에요. 서버가 자신의 메모리 안에 클라이언트 세션 상태를 요청 사이에 저장하지 않는다는 뜻입니다. 대신 토큰, 데이터베이스, 공유 캐시가 그 역할을 맡아요.
캐시 가능성
이 응답을 다시 쓸 수 있을까? 이 질문에 답하는 것이 캐시 가능성입니다. 응답은 캐시 가능한지 명시해야 하고, 가능하다면 클라이언트와 중간 계층(CDN 같은 것)이 이후의 같은 요청에 재사용해 서버 부하를 줄이고 속도를 높여요.
HTTP 메커니즘은 간단합니다. Cache-Control, ETag, Last-Modified, Expires 같은 헤더가 응답이 얼마나 오래 유효한지, 언제 다시 확인해야 하는지를 알려줘요. 비즈니스 관점에서는 응답에 "이 답변은 다음 1시간 동안 유효합니다" 또는 "항상 새로 확인하세요"라고 적힌 라벨이 붙어 있다고 생각하면 됩니다.
성능 효과도 확실해요. 실험에서는 꼬리 지연 구간의 캐시 적중 응답 시간이 50~100ms 개선됐다고 보고했습니다. 그리고 Fielding의 논문은 웹 트래픽이 1994년 하루 10만 요청에서 1999년 하루 6억 요청으로 커지는 과정을 기록하면서, 캐싱이 핵심 설계 요소였다고 설명해요.
보통 캐시 가능한 것: 제품 카탈로그, 공개 블로그 콘텐츠, 국가/통화 목록, API 문서
보통 캐시하지 않는 것: 개인 대시보드, 결제 총액, 은행 잔액, 관리자 보고서
통일된 인터페이스
Fielding 자신이 REST를 다른 아키텍처 스타일과 구분하는 핵심 특징이라고 부른 제약입니다. 클라이언트가 리소스와 상호작용하는 방식을 표준화해서 API를 예측 가능하게 만들어요.
이 범주 아래에는 네 가지 하위 제약이 있습니다.
- 리소스 식별: 모든 리소스는 안정적인 URI를 가져야 해요.
/customers/123은 고객이고,/orders/456은 주문입니다. - 표현을 통한 조작: 클라이언트는 서버 내부 객체가 아니라 리소스의 표현(JSON, XML, HTML)을 다룹니다.
- 자기 서술적 메시지: 요청과 응답에는 메서드, 상태 코드, 콘텐츠 타입, 오류 세부 정보 같은 메타데이터가 충분히 포함되어 있어서 중간자나 클라이언트가 내용을 이해할 수 있어야 해요.
- HATEOAS(Hypermedia as the Engine of Application State): 응답에 관련 작업과 리소스로 연결되는 링크가 포함되어, 클라이언트가 모든 엔드포인트를 하드코딩하지 않고도 다음 행동을 발견할 수 있어야 합니다.
HTTP 메서드 매핑은 통일된 인터페이스의 가장 눈에 띄는 부분이에요.
| HTTP 메서드 | CRUD 의미 | 안전한가? | 멱등성 있는가? | 예시 |
|---|---|---|---|---|
| GET | 읽기 | 예 | 예 | GET /products/42 |
| POST | 생성 / 동작 | 아니요 | 아니요 | POST /orders |
| PUT | 전체 리소스 교체 | 아니요 | 예 | PUT /users/42 |
| PATCH | 부분 업데이트 | 아니요 | 보장되지 않음 | PATCH /users/42 |
| DELETE | 삭제 | 아니요 | 예 | DELETE /sessions/abc |
은 GET은 안전해야 하고, GET·PUT·DELETE는 멱등적이어야 한다고 명시해요. GitHub, Stripe, Spotify처럼 잘 알려진 API들도 이런 패턴을 따르기 때문에, 하나를 배우면 다른 것도 빠르게 익힐 수 있습니다.
계층화 시스템
클라이언트는 자신이 원본 서버와 이야기하는지, CDN 캐시와 이야기하는지, API 게이트웨이와 이야기하는지, 아니면 로드 밸런서와 이야기하는지 알 수 없어요. 바로 그게 핵심입니다. 각 구성 요소는 자기와 인접한 계층만 보게 되거든요.
이 구조가 가능하게 해주는 것은 다음과 같아요.
- CDN: Cloudflare처럼 API 앞단에 위치해 응답을 캐시하고 가속
- API 게이트웨이: AWS API Gateway, Kong, Apigee 같은 도구가 인증, 속도 제한, 할당량 처리
- 로드 밸런서: 무상태 요청을 여러 앱 서버에 분산
에 따르면 가 AWS API Gateway를 사용하고, 26%는 Azure의 게이트웨이를, 31%는 여러 게이트웨이를 동시에 사용합니다. 계층화 아키텍처는 이론이 아니라 실제 운영 시스템이 움직이는 방식이에요.
대신 각 계층은 약간의 지연 시간을 더합니다. 하지만 Fielding은 대부분의 현실 시스템에서 중간 계층의 공유 캐싱이 이 오버헤드를 충분히 상쇄한다고 주장했어요.
코드 온 디맨드(선택 사항)
이건 조금 특이한 제약입니다. 코드 온 디맨드는 REST에서 유일한 선택 항목으로, 서버가 JavaScript 같은 실행 코드를 보내 클라이언트 기능을 즉석에서 확장할 수 있어요.
현실에서 가장 흔한 예는 웹 페이지가 서버에서 JavaScript를 불러오는 형태입니다. 하지만 모바일 앱, 백엔드 작업, 자동화 도구가 소비하는 일반적인 JSON REST API에서는 코드 온 디맨드가 거의 사용되지 않아요. API 클라이언트는 원격 서버에서 온 임의의 코드를 실행하고 싶어 하지 않거든요.
대부분의 독자에게는 이 제약이 각주 정도로 보일 거예요. Fielding의 모델에 완전성을 위해 들어가 있지만, 일상적인 API 평가에서 중요한 비중을 차지하진 않습니다.
많은 사람이 잘못 이해하는 것: 대부분의 REST API는 정말 RESTful할까요?
아무도 크게 말하고 싶어 하지 않는 부분이 있어요. 스스로를 "RESTful"하다고 부르는 실무 API 대부분은 사실 REST 스타일의 관행을 따르는 HTTP JSON API에 가깝습니다. 리소스 URL, HTTP 메서드, 상태 코드를 사용하긴 하지만 그 정도예요. r/softwarearchitecture의 한 Reddit 스레드에서는 개발자들이 Fielding 기준을 완전히 충족하는 진짜 REST API를 만들어 본 적이 없다고 인정하기도 했습니다. 또 다른 r/learnprogramming 토론에서는 "RESTful"이 정확히 무슨 뜻인지조차 합의할 수 있는지 논쟁이 벌어졌죠.
2026년 한 연구에서 REST API 전문가 16명을 인터뷰한 결과, 가이드라인은 사용성을 높이지만 개발자들은 엄격한 REST 규칙에 상당한 저항을 보였어요. 이유로는 가이드라인의 방대함과 조직별 상황에 잘 맞지 않는다는 점이 지적됐습니다.
그렇다면 실제 현장에서는 제약들이 어디까지 지켜질까요?
| 제약 | 실무 적용 수준 | 이유 |
|---|---|---|
| 클라이언트-서버 | ✅ 거의 보편적 | 웹 아키텍처의 기본이므로 피하기 어려움 |
| 무상태성 | ✅ 거의 보편적 | 수평 확장에 필요하고, 표준 관행임 |
| 통일된 인터페이스(기본) | ✅ 흔함 | 리소스 URI + HTTP 동사는 기본 패턴 |
| 캐시 가능성 | ⚠️ 일관되지 않음 | 많은 팀이 Cache-Control 헤더를 아예 생략함 |
| 계층화 시스템 | ⚠️ 암묵적 | CDN과 게이트웨이는 존재하지만 의도적으로 설계되지 않는 경우도 많음 |
| HATEOAS | ❌ 드묾 | 대부분의 클라이언트는 엔드포인트를 하드코딩하며, 링크 기반 탐색은 복잡성을 더함 |
| 코드 온 디맨드 | ❌ 매우 드묾 | 정의상 선택 사항이고, JSON API에서는 거의 구현되지 않음 |
팀들이 HATEOAS를 건너뛰는 이유: 클라이언트 개발자들은 런타임에 링크를 따라가는 것보다 OpenAPI 문서를 읽고 SDK를 사용하는 것을 선호해요. HATEOAS를 구현하려면 안정적인 미디어 타입, 링크 관계 정의, 워크플로 모델링이 필요합니다. 단기 비용은 크고, 대부분의 팀에겐 기대 효과가 불분명하죠.
실용적인 결론은 이렇습니다. API가 100% Fielding 규격을 완벽히 따르지 않아도 충분히 유용할 수 있어요. 하지만 어떤 제약을 생략했고, 그로 인해 무엇을 포기했는지 아는 것은 더 나은 설계와 통합 결정을 내리는 데 도움이 됩니다.
Richardson 성숙도 모델: 내 API는 실제로 얼마나 RESTful할까?
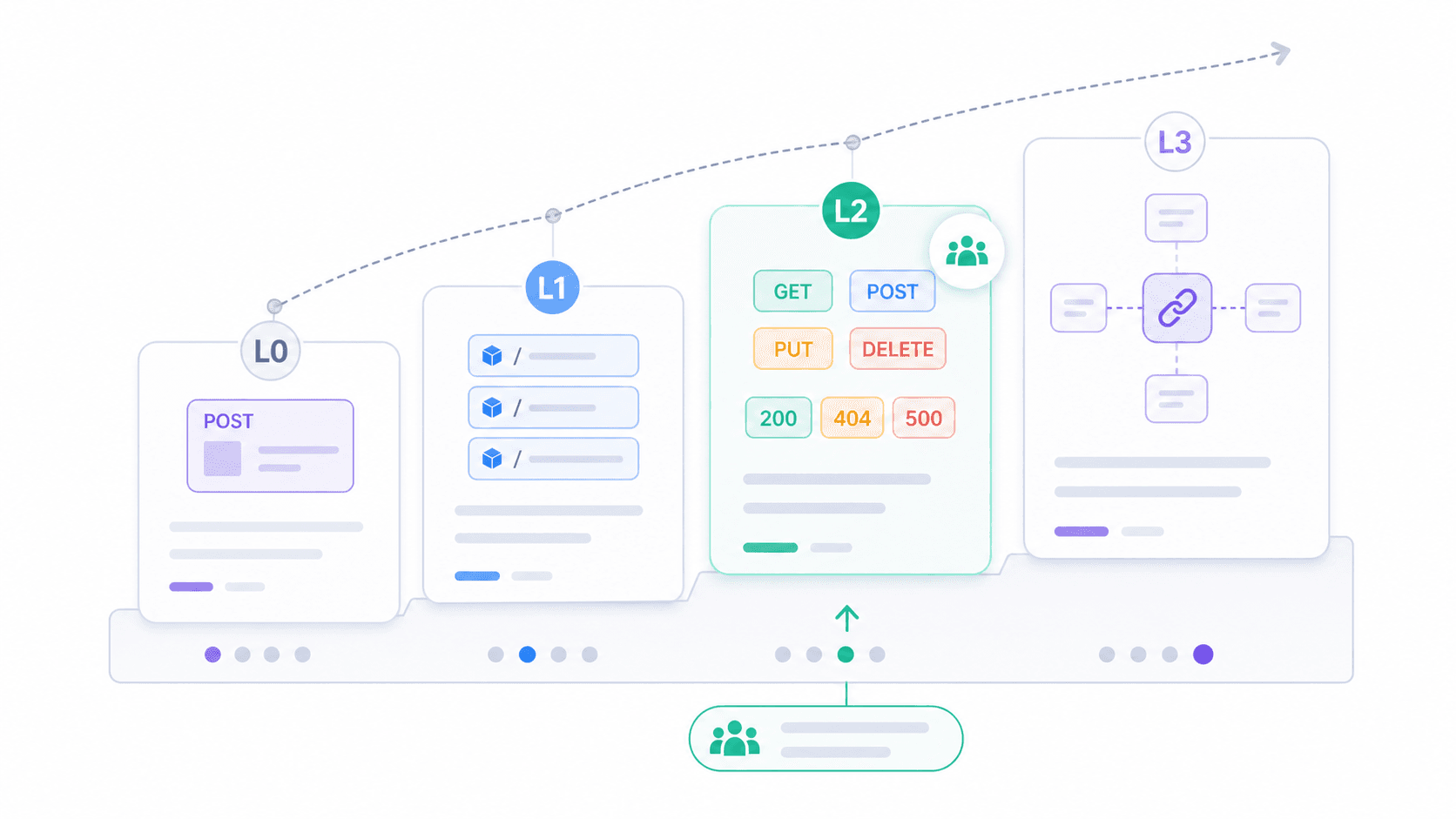
"REST인가, 아닌가?"라는 이분법이 별 도움이 되지 않는다면, Richardson 성숙도 모델이 더 실용적인 틀을 제공합니다. Leonard Richardson이 제안하고 이 모델은 REST 채택 수준을 네 단계로 나눠요.
| 단계 | 이름 | 설명 | 실제 예시 |
|---|---|---|---|
| 0 | POX의 늪 | 단일 URI, 단일 HTTP 동사(보통 POST) | 레거시 SOAP-over-HTTP 엔드포인트; POST /api에 { "action": "getUser" } |
| 1 | 리소스 | 여러 URI(리소스별 1개)는 있지만 여전히 주로 POST 사용 | POST /users/123/getProfile, POST /orders/456/cancel |
| 2 | HTTP 동사 | GET, POST, PUT, DELETE를 올바르게 사용 + 적절한 상태 코드 | 오늘날 대부분의 실무 "REST" API |
| 3 | 하이퍼미디어(HATEOAS) | 응답에 관련 작업/리소스로 연결되는 링크 포함 | Spring Data REST, HAL 기반 API; 실제 공개 API에서는 매우 드묾 |
실무에서 접하게 되는 API 대부분은 2단계에 있어요. 리소스, 동사, 상태 코드를 올바르게 사용하죠. 이것만으로도 충분히 실용적이고, 상호운용 가능하며, 도구 지원도 잘 받습니다. 3단계는 Fielding이 그린 완전한 비전이지만, 실제 채택은 여전히 적어요.
내 API는 어디쯤일까요? 스스로에게 이렇게 물어보세요.
- 모든 것을 위한 단일 엔드포인트가 있나요? (0단계)
- 각 비즈니스 객체마다 고유 URI가 있나요? (1단계 이상)
- HTTP 메서드와 상태 코드를 올바르게 사용하나요? (2단계)
- 응답이 외부 문서에 의존하지 않고 다음에 할 수 있는 일을 알려주나요? (3단계)
이 모델은 "REST냐 아니냐" 논쟁을 정리하는 데 제가 찾은 도구 중 가장 유용합니다. 이분법을 스펙트럼으로 바꿔주거든요.
흔한 REST API 실수와 피하는 방법
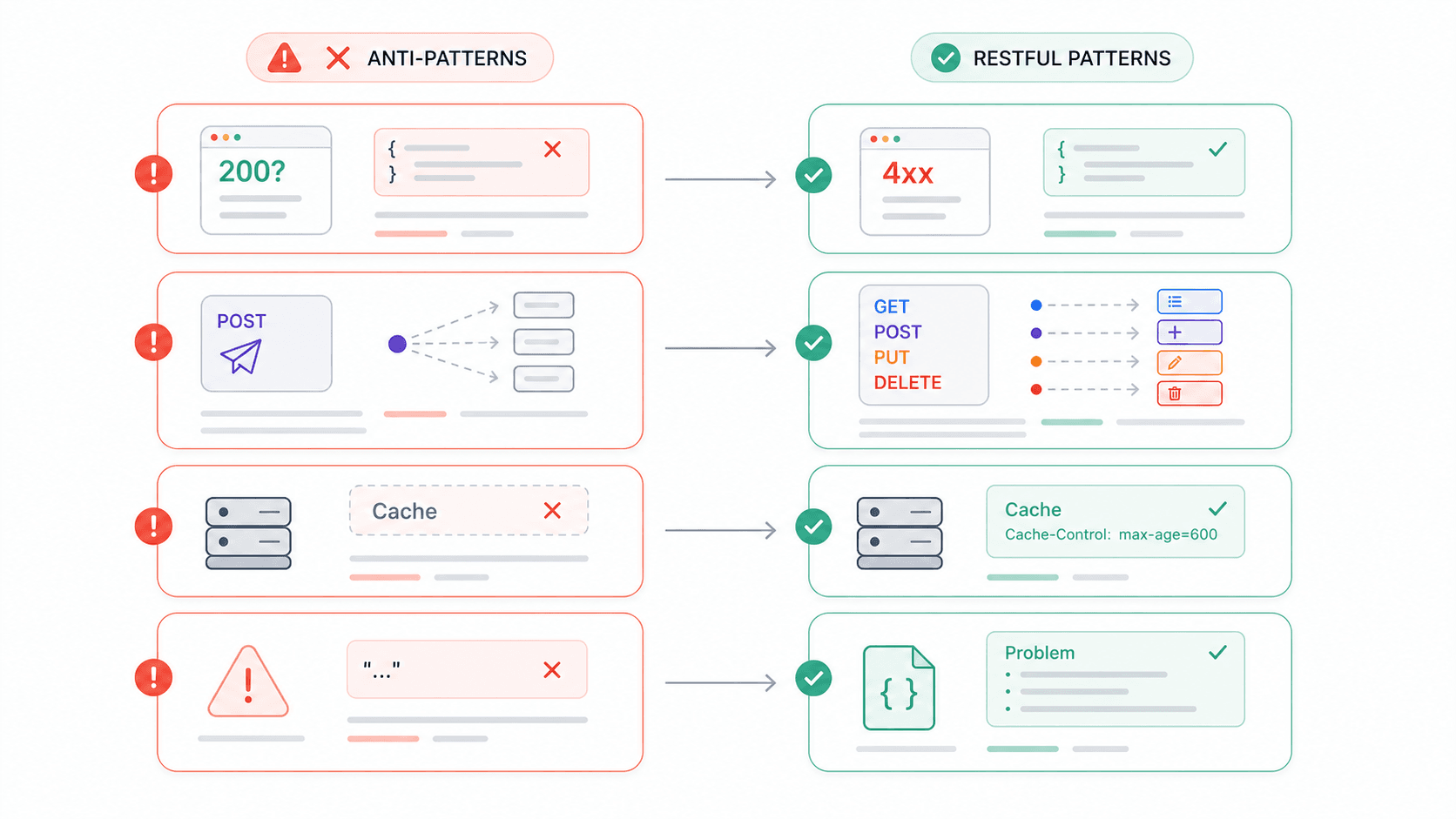
저는 서드파티 API를 통합하면서 충분히 많은 시간을 써서, 이제는 반복적으로 마주치는 불만 목록이 생겼어요. 개발자 포럼을 보면 저만 그런 것도 아니고요. 여기 가장 자주 보이는 안티패턴들을 정리했는데, 각각은 REST 제약 위반과 직접 연결됩니다.
This paragraph contains content that cannot be parsed and has been skipped.
는 공식 HTTP 상태 코드를 요구하고, 오류 응답에는 Problem JSON 사용을 권장합니다. 는 Problem Detail은 4xx/5xx에만 사용하고 2xx와 섞지 말라고 명시해요. 이런 것들은 학술적 취향이 아니라, 규모 있게 API를 운영하는 팀들의 실무 기준입니다.
r/learnprogramming의 한 Reddit 스레드에서는 한 개발자가 오류에도 항상 HTTP 200을 반환해도 되는지 진지하게 묻고 있었어요. 2026년에도 이런 질문이 계속 나온다는 사실만 봐도, 이런 안티패턴이 얼마나 끈질긴지 알 수 있습니다.
REST vs SOAP vs GraphQL vs gRPC: REST API 특성 비교하기
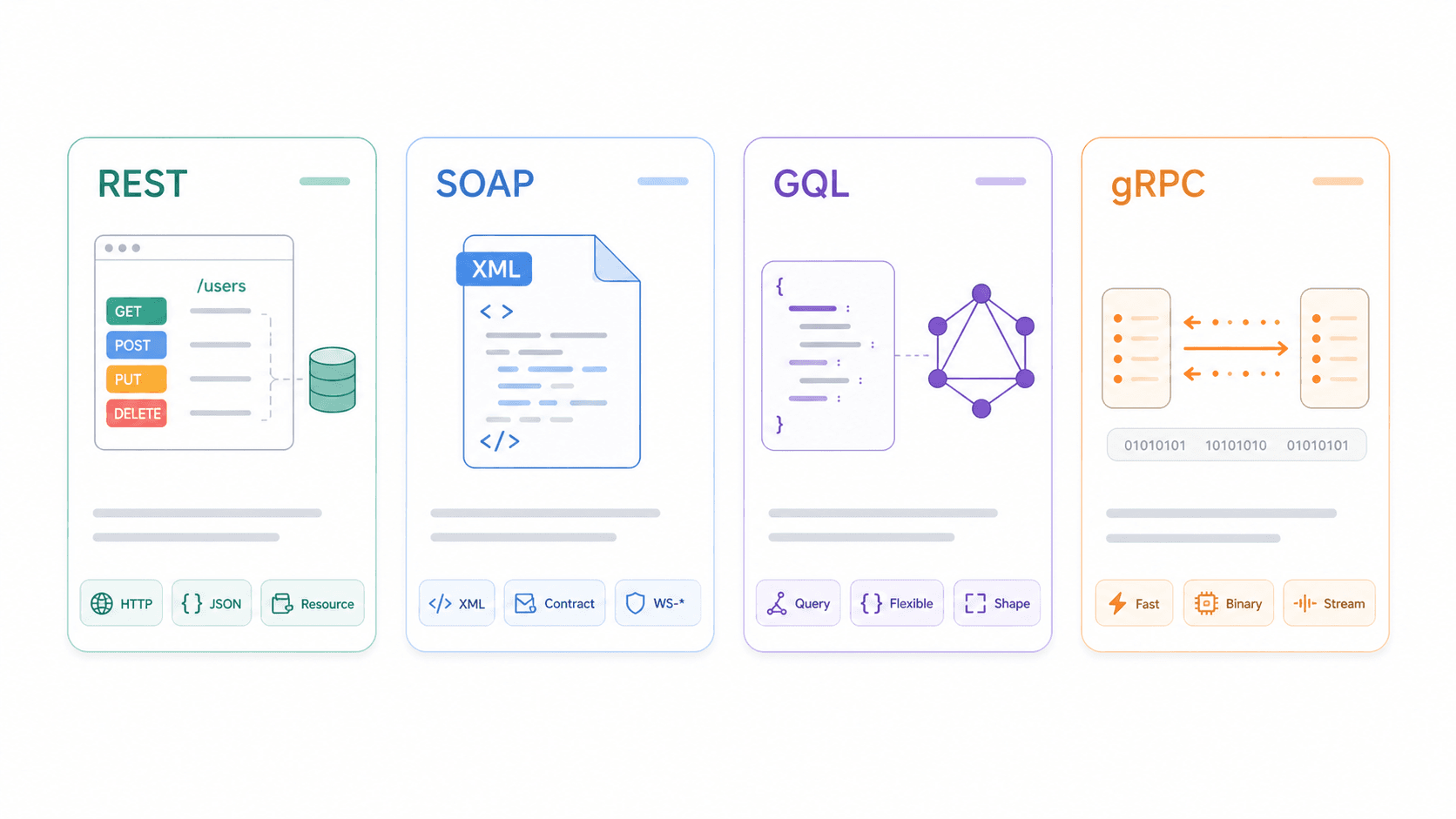
REST를 단독으로 이해하는 것도 유용하지만, 대안과 비교해서 이해하면 더 좋습니다.
| 비교 항목 | REST | SOAP | GraphQL | gRPC |
|---|---|---|---|---|
| 프로토콜 / 전송 방식 | 아키텍처 스타일, 보통 HTTP 사용 | XML 기반 메시징 프로토콜; HTTP, SMTP 등 | 쿼리 언어/런타임, 보통 HTTP 위에서 동작 | HTTP/2 기반 RPC 프레임워크 |
| 데이터 형식 | 보통 JSON, 그 외 XML/HTML도 가능 | XML만 사용(WSDL 계약) | 쿼리 모양에 맞는 JSON | Protocol Buffers(이진) |
| 캐싱 | ✅ 잘 설계하면 HTTP 네이티브 캐싱 가능 | ❌ 복잡함; HTTP 캐시 친화적이지 않음 | ⚠️ 더 어려움(POST + 단일 엔드포인트 + 쿼리 변화) | ❌ HTTP 캐싱 중심이 아님 |
| 실시간 지원 | ❌ 폴링/웹훅 | ❌ 엔터프라이즈 메시징 패턴 | ✅ 구독(Subscriptions) | ✅ 스트리밍, 낮은 지연 시간 |
| 학습 곡선 | 낮음~중간 | 높음 | 중간 | 중간~높음 |
| 적합한 용도 | 공개 API, CRUD, 웹/모바일 연동 | 엔터프라이즈/레거시, 엄격한 계약, 규정 준수 | 복잡한 쿼리, 유연한 프런트엔드, 모바일 앱 | 마이크로서비스 간 통신, 내부 고성능 처리 |
는 호환성, 데이터 형태, 작업 방식, 사용자 도구를 기준으로 선택하라고 권장합니다.
언제 무엇을 선택할까:
- REST는 넓은 호환성, 단순한 CRUD 작업, HTTP 캐싱이 필요할 때 강합니다. 공개 API와 웹/모바일 연동의 기본값에 가깝습니다.
- SOAP는 엄격한 계약, WS-Security 요구사항, 쉽게 교체되지 않는 레거시 통합이 있는 엔터프라이즈 시스템에서 여전히 의미가 있습니다.
- GraphQL은 프런트엔드가 유연한 중첩 쿼리를 필요로 하고, 과도한 조회나 부족한 조회를 피하고 싶을 때 빛을 발해요. 복잡한 모바일 앱에서 특히 흔합니다.
- gRPC는 낮은 지연 시간과 이진 직렬화가 브라우저 호환성보다 중요한 내부 마이크로서비스 통신에 적합합니다.
실제 REST 예시로는 가 있어요. 이 API는 단순한 POST 엔드포인트(/distill과 /extract), JSON 요청/응답 본문, 베어러 토큰 인증, 그리고 표준 HTTP 상태 코드(400, 401, 402, 408, 422, 429, 500, 502, 503, 504)를 사용합니다. SOAP 계약이나 gRPC의 복잡성 없이도 실무 AI 제품에서 REST 특성이 어떻게 적용되는지 잘 보여줘요. HATEOAS를 뽐내는 예시는 아니지만, 비즈니스 팀과 개발자가 쉽게 통합할 수 있는 실용적인 2단계 API입니다.
REST API 특성이 비즈니스 팀에 중요한 이유
영업, 운영, 이커머스 같은 팀은 API 코드를 직접 작성하지 않죠. 하지만 벤더를 고르고, 도구를 연결하고, 자동화 워크플로를 만들 때 REST API의 품질이 그 통합을 얼마나 고통스럽게 또는 수월하게 만드는지는 직접 영향을 줍니다.
도구 통합: CRM이 마케팅 자동화 플랫폼과 동기화될 때, REST API 설계가 그 동기를 안정적으로 만들지 아니면 불안정하게 만들지를 결정합니다. 는 예측 가능한 리소스 엔드포인트를 통해 연락처, 캠페인, 여정, 푸시 알림을 관리해요. 이런 엔드포인트가 REST 관례를 잘 따르면 RevOps 팀은 별도 우회 작업 없이 자동화를 구축할 수 있습니다.
이커머스 운영: 는 이행 주문, 추적 번호, 배송 상태를 관리합니다. 배송 앱과 이행 도구는 이 계층에 의존해요. API가 제대로 설계되어 있으면—적절한 상태 코드, 캐시 가능한 카탈로그 데이터, 명확한 오류 메시지—물류 파이프라인이 매끄럽게 돌아갑니다. 그렇지 않으면 새벽 2시에 이유를 알 수 없는 장애를 맞게 되죠.
벤더 평가: 6가지 제약을 알고 있으면 실용적인 체크리스트가 생깁니다.
- API가 표준 상태 코드를 쓰나요, 아니면 실패가 모두 200 OK처럼 보이나요?
- 오류가 자동화 도구가 복구할 수 있을 만큼 구체적인가요?
- 속도 제한, 페이지네이션, 인증에 대한 문서가 명확한가요?
- 일반 응답을 캐시해서 부하를 줄일 수 있나요?
데이터 추출과 자동화: 같은 도구는 REST 기반 아키텍처를 사용해 비즈니스 사용자가 웹사이트, PDF, 이미지에서 구조화된 데이터를 추출하고, 이를 Google Sheets, Airtable, Notion, Excel로 내보낼 수 있게 해줘요. Thunderbit의 은 2번 클릭으로 끝나는 인터페이스 뒤에서 복잡한 처리를 맡지만, 그 아래에서는 무상태 요청, JSON 응답, 표준 오류 같은 REST 원칙이 통합 계층의 안정성을 만들어 줍니다.
한 가지 더 짚고 갈 데이터가 있어요. Postman 2025 보고서에 따르면 개발자의 AI 에이전트를 염두에 두고 API를 설계하고 있으며, 51%는 AI 에이전트의 무단 또는 과도한 API 호출을 우려하고 있습니다. 자동화와 AI 기반 워크플로가 비즈니스 팀의 표준이 되면서, 예측 가능한 REST 패턴, 최소 권한 API 키, 속도 제한은 더 이상 개발자만의 문제가 아니라 운영 리스크 요인이 되고 있어요.
Thunderbit가 비즈니스 사용자를 위해 REST 원칙을 적용하는 방식
우리는 를 만들 때 대부분의 사용자가 REST 명세를 읽어본 적이 없고, 그럴 필요도 없다고 가정했어요. 하지만 Thunderbit를 쉽게 쓰게 만드는 설계 선택들은 이 글에서 다루는 REST 특성에 뿌리를 두고 있습니다.
실제 사용 흐름을 간단히 보면 이렇습니다.
- 에서 Chrome 확장 프로그램을 설치하고, 데이터를 추출하려는 웹사이트, PDF, 이미지를 엽니다.
- **"AI 필드 제안"**을 클릭하면 Thunderbit의 AI가 페이지를 읽고 열 구조를 제안해요. 상품명, 가격, 이메일 등 페이지에 있는 어떤 내용이든 포함될 수 있습니다.
- 필요한 경우 열을 조정한 뒤 **"스크랩"**을 클릭하세요. Thunderbit가 페이지네이션, 하위 페이지, 동적 콘텐츠를 자동으로 처리합니다.
- 데이터를 Google Sheets, Airtable, Notion, CSV, Excel로 내보내세요. 무료이고, 유료 장벽도 없습니다.
개발자와 자동화 워크플로를 위해 Thunderbit의 는 /distill(정제된 Markdown 추출)과 /extract(구조화된 데이터 추출)를 JSON 본문을 가진 REST 스타일 POST 엔드포인트와 표준 HTTP 오류 코드로 제공합니다. Richardson 성숙도 모델로 보면 이는 2단계에 해당해요. 리소스, 올바른 메서드, 의미 있는 상태 코드가 갖춰져 있습니다.
웹 스크래핑이나 데이터 추출을 더 폭넓게 살펴보고 있다면, , , 에 대한 더 깊은 가이드도 준비되어 있어요.
핵심 요약
- REST는 프로토콜이 아니라 아키텍처 스타일입니다. 클라이언트-서버, 무상태성, 캐시 가능성, 통일된 인터페이스, 계층화 시스템, 선택적 코드 온 디맨드라는 6가지 제약이 API 설계를 안내해요.
- 대부분의 "RESTful" API는 완전한 RESTful이 아닙니다. 대다수는 Richardson 2단계(리소스 + HTTP 동사 + 상태 코드)에 머뭅니다. HATEOAS와 코드 온 디맨드는 거의 구현되지 않아요.
- Richardson 성숙도 모델은 가장 좋은 자체 점검 도구입니다. "REST냐 아니냐"라는 이분법을 실용적인 스펙트럼(0~3단계)으로 바꿔줍니다.
- 200 OK로 오류를 돌려주기, 모든 것에 POST 사용하기, 캐시 헤더 누락하기 같은 실수는 여전히 만연합니다. 제약을 이해하면 이런 안티패턴을 찾아내고 고칠 수 있어요.
- REST vs SOAP vs GraphQL vs gRPC는 '무엇이 최고냐'의 문제가 아니라 '무엇에 맞느냐'의 문제입니다. REST는 공개 API와 CRUD 연동에서 강세를 보이고, GraphQL은 복잡한 프런트엔드에 적합하며, gRPC는 내부 마이크로서비스에 뛰어나고, SOAP는 엔터프라이즈/레거시 환경에서 여전히 사용됩니다.
- 비즈니스 팀도 벤더를 평가하고, 도구를 연결하고, 자동화 워크플로를 만들 때 REST 특성을 이해하면 이득을 봅니다. 같은 도구는 REST 원칙을 적용해 기술 지식 없이도 데이터 추출을 쉽게 만들어 줍니다.
자주 묻는 질문
REST API의 6가지 특성은 무엇인가요?
REST의 6가지 제약은 (1) 클라이언트-서버 분리, (2) 무상태성, (3) 캐시 가능성, (4) 통일된 인터페이스, (5) 계층화 시스템, (6) 코드 온 디맨드(선택)입니다. Fielding의 원래 정의에 따르면 앞의 5가지는 RESTful API로 간주되기 위한 필수 조건이에요.
REST와 RESTful의 차이는 무엇인가요?
REST는 Roy Fielding이 정의한 설계 제약의 집합, 즉 아키텍처 스타일이에요. "RESTful"은 그 제약을 따르는 API를 뜻합니다. 실제로는 "RESTful"이라고 불리는 많은 API가 리소스, HTTP 메서드, 상태 코드만 구현하고 HATEOAS와 코드 온 디맨드는 생략하는 식으로 부분적으로만 따르고 있어요.
모든 REST API가 모든 REST 제약을 따르나요?
아니요. 대부분의 실무 API는 클라이언트-서버 분리, 무상태성, 기본적인 통일된 인터페이스(리소스 + HTTP 동사)를 따릅니다. 캐시 가능성과 계층화 시스템 설계는 일관되지 않게 구현돼요. HATEOAS는 드물고, 코드 온 디맨드는 JSON API에서 거의 사용되지 않습니다.
REST와 GraphQL의 차이는 무엇인가요?
REST는 여러 엔드포인트를 통해 리소스를 노출하고, 표준 HTTP 메서드(GET, POST, PUT, DELETE)를 사용합니다. GraphQL은 보통 단일 엔드포인트를 사용하며, 클라이언트가 쿼리에서 원하는 필드를 정확히 지정해요. REST는 HTTP 네이티브 캐싱이 더 강하고, GraphQL은 복잡하고 중첩된 데이터 요구에 더 유연하며 과도한 조회를 줄여줍니다.
HATEOAS는 무엇이고, 실제로 쓰는 사람이 있나요?
HATEOAS(Hypermedia as the Engine of Application State)는 API 응답에 다음에 가능한 작업을 알려주는 링크가 포함되어 있어 클라이언트가 모든 엔드포인트를 하드코딩하지 않고도 API를 탐색할 수 있다는 뜻입니다. 이는 Fielding이 그린 REST의 핵심( Richardson 3단계 )이지만, 실제로는 이를 구현한 공개 API가 매우 드뭅니다. 대부분의 팀은 2단계에서 멈추고 문서와 SDK에 의존해요.
더 알아보기