

2024년 5월 1일, 네덜란드 개인정보보호청이 유럽 전역의 데이터 팀을 긴장시킨 한 문장을 발표했어요. “스크래핑은 거의 항상 불법이다.” 영업, 이커머스, 부동산처럼 웹 데이터로 먹고사는 일이라면 이 한 줄에 가슴이 철렁했을 거예요.
저도 그 마음 잘 알아요. Thunderbit에서는 가격 모니터링, 리드 확보, 시장 조사 때문에 웹 데이터가 필요한 팀들과 매일 대화해요. 답답한 지점도 항상 똑같아요. “유럽에서 웹 스크래핑 합법인가요?”라고 검색하면 돌아오는 답은 늘 “상황에 따라 다릅니다”의 변주뿐이거든요. 마감은 코앞이고 긁어야 할 URL 목록은 손에 쥐어져 있는데, 그런 답은 아무 도움이 안 되죠.
그래서 몇 주에 걸쳐 실제 법령, 개인정보보호청 가이드, 집행 사례, 판례를 직접 파봤어요. 결과물이 이 글이에요. 의사결정 체크리스트, 안전장치 통합표, 실제 과징금 사례, 그리고 규제기관 표적이 되지 않으면서 유럽 사이트를 긁는 단계별 가이드까지 담았어요. 아마존 가격을 긁든 디렉터리에서 B2B 연락처를 모으든, 어디까지 가능한지와 어떻게 안전하게 갈지 판단하는 데 쓸모가 있을 거예요.
웹 스크래핑이 뭐고, 유럽 기업이 왜 신경 써야 할까요?
웹 스크래핑은 사이트 데이터를 스프레드시트, 데이터베이스, CRM 같은 구조화된 형태로 자동 추출하는 작업이에요. 200개 페이지에서 상품명과 가격을 일일이 복붙하는 대신, 스크래퍼가 각 페이지를 돌며 필요한 항목만 깔끔한 열로 뽑아 와요.
비기술 팀에게 이게 왜 중요할까요? 웹 데이터가 실제 비즈니스 판단을 좌우하니까요. 영업팀은 디렉터리에서 리드를 긁고, 이커머스 팀은 경쟁사 가격을 매일 들여다봐요. 부동산 분석가는 포털 전반의 매물 흐름을 추적하고, 시장 조사팀은 공개 리뷰와 평점을 대규모로 모으죠. 전 세계 웹 스크래핑 시장은 빠르게 커지는 중이고, 기업들은 매일 수백만 개의 데이터 포인트를 긁어요.
문제는 유럽의 규제 환경이 미국과 다르다는 점이에요. GDPR, 데이터베이스 지침, 계속 바뀌는 개인정보보호청 가이드를 보면 “공개돼 있다”가 곧 “마음대로 써도 된다”는 뜻은 아니에요. 네덜란드 개인정보보호청장 Aleid Wolfsen도 짚었듯, “공개”가 자동으로 스크래핑 허가가 되지는 않아요. 시작 전에 규칙을 아는 건 선택이 아니에요. 깨끗한 데이터셋과 6자리 과징금을 가르는 갈림길이니까요.
규정을 고려한 웹 스크래핑을 위해 Thunderbit 사용해 보기
유럽에서 웹 스크래핑은 합법일까요? 짧은 답
유럽에서 웹 스크래핑이 본질적으로 불법인 건 아니에요. 다만 합법 여부가 세 가지에 달려 있어요. 무엇을 긁는지, 어떻게 긁는지, 그리고 왜 긁는지예요.
EU에서 스크래핑을 다스리는 법적 층위는 세 가지가 겹쳐요.
- GDPR — 개인정보(이름, 이메일, 전화번호, IP 주소, 가명 처리된 식별자까지)를 긁을 때 적용돼요.
- EU 데이터베이스 지침 — 데이터를 모으는 데 “상당한 투자”를 한 데이터베이스 제작자를 보호해요.
- 계약/이용약관법 — 많은 사이트가 약관에서 스크래핑을 콕 집어 금지하고, EU 법원은 그 약관을 실제로 인정해 왔어요.
핵심은 이거예요. “공개”라고 해서 “규제 밖”인 건 아니에요. 비개인 데이터조차 데이터베이스 권리나 계약법의 보호를 받을 수 있어요. 모든 스크래핑 프로젝트는 이 세 층위를 함께 따져야 해요.
웹 스크래핑을 다스리는 핵심 EU 법규
GDPR: 개인정보를 긁을 때
특정 개인과 연결되는 데이터는 전부 GDPR 의무를 일으켜요. 이름, 이메일, 전화번호, IP 주소, 사진은 물론 재식별이 가능한 가명 데이터도 포함돼요. 개인정보를 긁는 순간 GDPR상 ‘데이터 컨트롤러’가 되고, 다음 의무를 지게 돼요.
- 적법한 근거(제6조): 데이터를 처리할 법적 이유가 있어야 해요. 대규모 스크래핑에서 동의를 받는 건 사실상 불가능해요. 공개 게시물 하나하나에 대해 수백만 명에게 허락을 구할 순 없으니까요. 가장 흔히 쓰는 근거는 정당한 이익(제6조 1항 f호)인데, 문서화된 3단계 테스트가 필요해요. (1) 이익이 정당한가, (2) 그 이익을 위해 처리가 꼭 필요한가, (3) 정보주체의 합리적 기대를 고려할 때 권리를 과하게 침해하진 않는가.
- 투명성(제14조): 개인에게 직접 받은 게 아니니, 보통 한 달 안에 무엇을 왜 모았고 권리를 어떻게 행사하는지 알려야 해요. 개별 통지가 너무 버거우면, 제14조 내용을 다 담은 일반 고지를 게시해야 해요.
- 데이터 최소화: 정말 필요한 것만 모으세요. 상품 가격이 필요하다면 판매자 이메일까지 가져올 이유는 없어요.
- 보관 제한과 권리 관리: 보관 기간을 정하고, 삭제 요청을 받아주고, 출처 정보 접근을 보장해야 해요.
EDPB ChatGPT 태스크포스 보고서(2024년 5월 채택)는 한 발 더 나갔어요. 수집, 전처리, 학습, 프롬프트, 출력처럼 처리 단계마다 적법한 근거 분석을 따로 해야 한다고 못 박았거든요. EDPB가 스크래핑에서 정당한 이익을 아예 배제한 건 아니지만, 제대로 된 안전장치를 갖춘 완전한 3단계 평가를 요구했어요.
EU 데이터베이스 지침: 데이터 구성 방식을 지키는 법
데이터베이스 지침은 데이터를 모으고 검증하고 보여주는 데 “상당한 투자”를 한 제작자에게 독자적(sui generis) 권리를 줘요. 스크래핑이 그런 데이터베이스의 “상당한 부분”을 빼내면 이 권리를 침해할 수 있어요.
실무 기준은 꽤 높은 편이에요. 대형 리테일러 상품 가격 몇백 개를 긁는 정도는 침해로 보기 어려워요. 하지만 경쟁사 카탈로그 전체, 수만 건 상품 목록을 통째로 받아 가는 건 선을 넘을 수 있어요. 제작자가 투자비를 회수할 능력을 위협하면 더더욱요. EU 사법재판소도 여러 사건에서 이 기준을 다뤘는데, 핵심 질문은 늘 비례성이에요.
대부분의 비즈니스 스크래핑은 — 상품 페이지에서 특정 필드만 가져오거나, 카테고리 전반 목록을 비교하는 정도는 — 데이터베이스 지침 리스크가 상대적으로 낮아요. 그래도 위험이 0은 아니니, 긁는 범위를 짤 때 머리 한구석에 넣어두는 게 좋아요.
이용약관: 계약법이라는 변수
여기서 많은 사람이 발이 걸려 넘어져요. 적잖은 사이트가 약관에서 스크래핑을 금지하거든요. 유럽에서는 약관 위반이 형사가 아니라 민사 문제예요. 그래도 금지명령, 계약 소송, 실제 금전 손실로 번질 수 있어요.
알아둘 유형이 둘이에요. 브라우즈랩(browsewrap) 은 페이지 하단에 묻힌 링크처럼 수동적으로 걸어두는 약관이라, 사용자가 명시적으로 동의한 게 아니어서 인정받기 어려워요. 클릭랩(clickwrap) 은 체크박스를 누르거나 “동의합니다”를 클릭하는 방식이라, 훨씬 강하게 인정돼요.
EU의 대표 사례가 Ryanair v. PR Aviation이에요. 법원은 데이터베이스 권리가 안 걸리더라도, 스크래퍼가 약관에 동의한 이상 Ryanair 약관을 그대로 인정했어요. 그러니 긁기 전에 사이트 약관을 꼭 확인하세요. 스크래핑을 콕 집어 금지하는 클릭랩 계약이라면, 조심해서 진행하거나 API 접근을 알아보는 편이 나아요.
DSM 지침과 AI Act: 연구·텍스트·데이터 마이닝 예외
모든 스크래핑이 같은 제약을 받는 건 아니에요. 디지털 단일시장(DSM) 지침(2019)은 텍스트·데이터 마이닝(TDM) 예외 두 가지를 들여왔어요.
- 제3조: 연구기관과 문화유산 기관은 적법하게 접근한 콘텐츠에 TDM을 할 수 있어요.
- 제4조: 권리자가 robots.txt, ai.txt, TDMRep 헤더 등으로 명시적으로 거부(opt-out)하지 않았다면, 상업적 주체를 포함해 누구나 TDM을 할 수 있어요.
EU AI Act(제53조) 는 AI 모델 제공자에게 의무를 더 얹어요. TDM 옵트아웃 메커니즘을 지키고, 학습 데이터 출처를 문서로 남겨야 해요.
조심할 점도 있어요. 이 예외는 저작권과 데이터베이스 권리에 관한 거지 GDPR이 아니에요. TDM에 개인정보가 섞이면, GDPR 적법한 근거는 여전히 따로 필요해요.

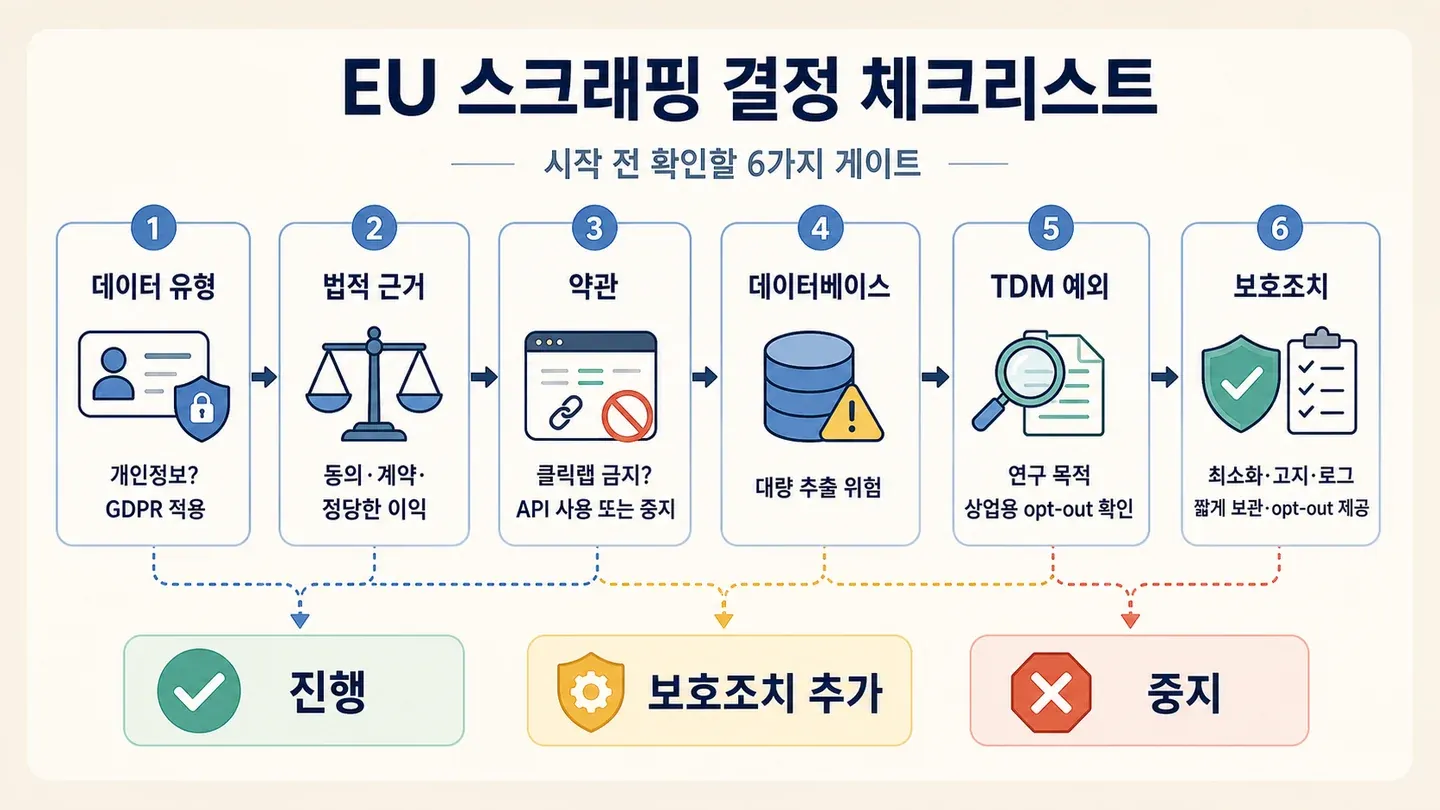
“이거 긁어도 될까?” 유럽 데이터 의사결정 체크리스트
이 섹션이야말로 제가 처음 이 주제를 팔 때 가장 갖고 싶던 부분이에요. 모든 법률 글이 “상황에 따라 다르다”고만 하는데, 실제 판단 흐름은 어떻게 생겼을까요? 명확한 관문이 있는 단계별 준수 체크리스트로 정리했어요. 각 단계는 ✅ 진행, ⚠️ 안전장치 추가, 🛑 중단으로 이어져요.
1단계: 데이터가 개인정보인가, 비개인정보인가?
비개인정보(상품 가격, SKU 번호, 개인과 연결되지 않은 사업장 주소): 규제 부담이 더 가벼워요. 데이터베이스 지침과 이용약관은 봐야 하지만, GDPR은 안 걸려요. ✅ 3단계로 가세요.
개인정보(이름, 이메일, 전화번호, 사진, 사람과 연결된 식별자): GDPR이 적용돼요. ⚠️ 2단계로 가세요.
2단계: 어떤 GDPR 적법한 근거가 적용되나요?
- 동의: 대규모 스크래핑에선 사실상 불가능해요. 🛑 아주 좁고 구체적인 경우가 아니라면요.
- 정당한 이익(제6조 1항 f호): 가장 흔한 근거예요. 다만 문서화된 3단계 테스트가 필요해요.
- 이익이 정당해야 해요. (상업적 이익도 CJEU의 2024년 C-621/22 판결에 따르면 해당될 수 있어요.)
- 그 이익을 위해 처리가 꼭 필요해야 해요.
- 정보주체의 합리적 기대를 고려할 때, 내 이익이 그들의 권리를 압도하면 안 돼요.
- 긁기 전에 균형 테스트를 문서로 남기세요. 긁히는 당사자가 이런 사용을 합리적으로 예상할 수 있는지 설명하지 못하겠다면, 그건 위험 신호예요. ⚠️ 문서화된 정당한 이익으로 진행하세요.
3단계: 사이트 이용약관이 스크래핑을 막나요?
- 스크래핑을 금지하는 클릭랩 계약: 🛑 위험도가 높아요. 다른 데이터 출처나 공식 API 접근을 알아보세요.
- 브라우즈랩이거나 제한이 없음: ⚠️ 위험은 낮지만, robots.txt와 기술적 차단 신호는 여전히 존중하세요.
4단계: 데이터베이스 지침이 적용되나요?
- 대상이 데이터 구성에 상당한 투자가 들어간 데이터베이스인가요?
- 스크래핑이 그 데이터베이스의 “상당한 부분”을 빼내게 되나요?
- 둘 다 그렇다면: ⚠️ 독자적 권리 침해 위험이 있어요. 추출 범위를 줄이세요.
5단계: 연구나 TDM 예외에 해당하나요?
- 등록된 연구기관이나 문화유산 기관인가요? DSM 지침 제3조가 적용될 수 있어요. ✅
- 상업적 TDM인가요? 제4조 옵트아웃 신호(robots.txt, ai.txt, TDMRep)를 확인하세요. 사이트가 거부했다면, 🛑 그 출처는 포기하세요.
6단계: 개인정보보호청이 권고한 안전장치를 적용했나요?
위 관문을 다 통과했다면, 마지막은 CNIL, 네덜란드 개인정보보호청, EDPB가 권고하는 안전장치를 적용하는 거예요. 자세한 건 다음 섹션에서 다뤄요. ✅ 안전장치를 갖추고 진행하세요.
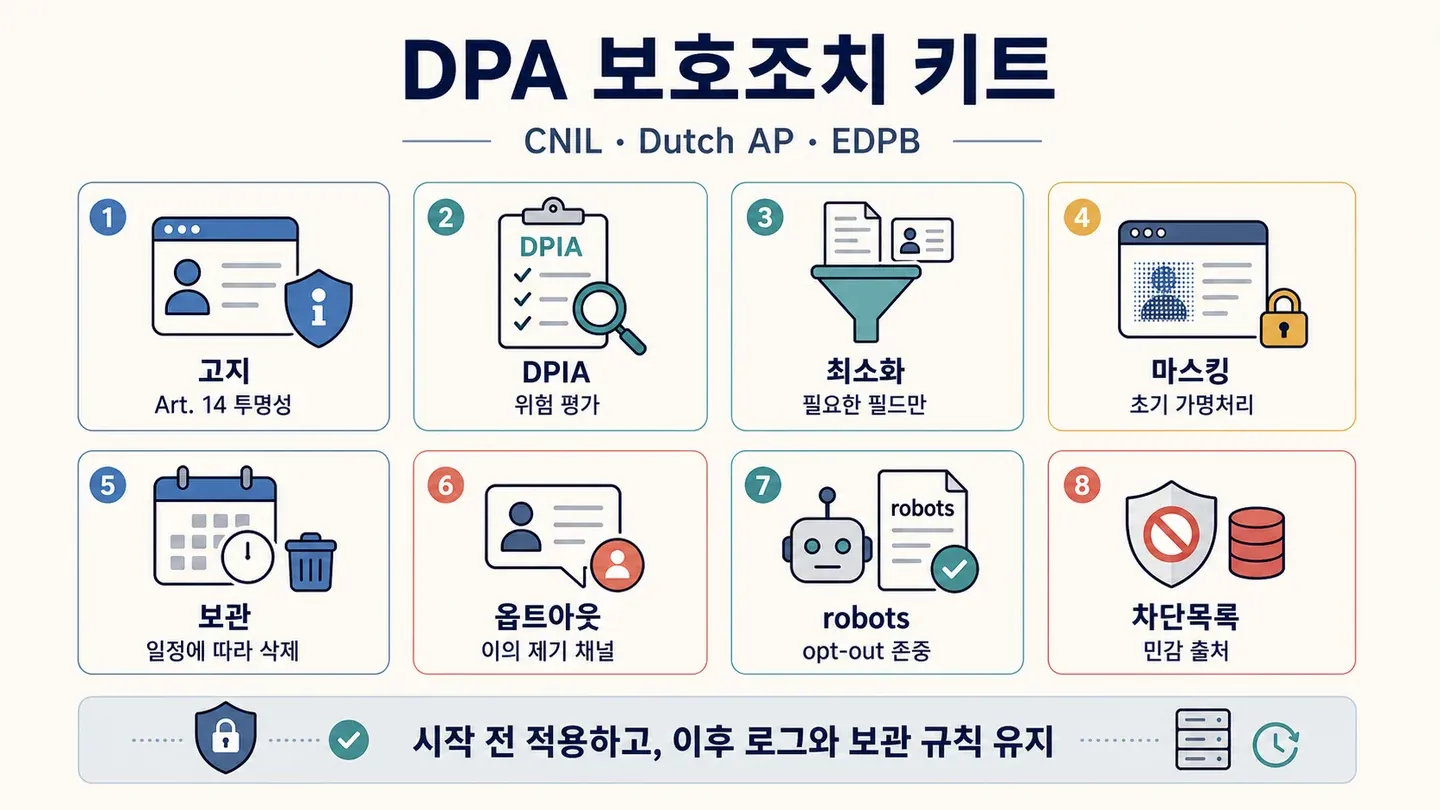
개인정보보호청 준수 안전장치: CNIL, 네덜란드 AP, EDPB의 권고
제가 찾아본 어떤 경쟁 기사도 유럽에서 가장 활발한 세 규제기관이 권고하는 스크래핑 안전장치를 한자리에 모아 정리하진 않았어요. 그래서 CNIL 가이드, 네덜란드 AP 가이드, EDPB ChatGPT 태스크포스 보고서를 교차 검토해 아래 표를 만들었어요.
| 안전장치 | CNIL | 네덜란드 개인정보보호청(AP) | EDPB 태스크포스 | 구현 팁 |
|---|---|---|---|---|
| 제14조 투명성 고지 | ✅ 필수 | ✅ 필수 | ✅ 필수 | 출처 범주, 목적, 적법한 근거, 보관 기간, 권리 행사 채널, DPO 연락처를 담은 공개 고지를 게시하세요 |
| 스크래핑 전 DPIA | ✅ 권장(고위험이면 의무) | ✅ 필수 | ✅ 필수 | 출시 전에 균형 테스트, 데이터 범주, 위험, 완화 조치를 문서화하세요 |
| 데이터 최소화 | ✅ 필수(정확한 수집 기준 정의) | ✅ 필수 | ✅ 필수 | 필요한 필드만 추출하도록 스크래퍼를 설정하고, 불필요한 데이터는 즉시 삭제하세요 |
| 속도 제한 / robots.txt 준수 | ✅ 필수(robots.txt/CAPTCHA로 거부하는 사이트 제외) | — | — | robots.txt를 파싱하고, 요청 간 지연을 넣고, 사용자 에이전트를 식별하세요 |
| 가명화 / 익명화 | ⚠️ 권장(수집 직후) | ✅ 강력 권고 | ✅ 권장 | ID를 해시 처리하거나 무작위화하고, 프로필 URL을 제거하며, 신원 식별이 불필요하면 얼굴을 흐리세요 |
| 보관 기간 | ✅ 명확한 제한 | ✅ 가능한 한 짧게 | ✅ 명확한 제한 | 삭제 일정을 자동화하고, 원본 캐시와 추출된 사실을 분리하세요 |
| 옵트아웃 / 블랙리스트 메커니즘 | ✅ 권장(사전 이의 제기 가능) | ✅ 필수(제21조 이의 제기) | ✅ 필수 | 옵트아웃 양식, 도메인 블랙리스트, 개인 단위 차단 기능을 제공하세요 |
| 민감한 출처 제외 | ✅ 필수(건강 포럼, 미성년자 사이트, 음란 사이트, 족보 사이트) | ✅ 필수 | ✅ 필수 | 건강, 종교, 정치, 생체정보, 미성년자 관련 기본 차단 목록을 유지하세요 |
실무에서 참고할 점도 있어요. Thunderbit의 “AI Suggest Fields” 기능은 가격, SKU, 상품명처럼 어떤 열을 뽑을지 정확히 정의하게 해줘요. 스크래퍼가 페이지 전체를 무작정 받아 가는 게 아니라, 목적 제한과 데이터 최소화 원칙에 맞는 구조화된 필드만 모으는 거예요. 다만 어떤 도구도 규정 어긴 스크래핑을 합법으로 바꿔주진 않아요. 법적 검토가 늘 먼저예요.
내 경우엔 유럽 웹 스크래핑이 합법일까? 업종별 가이드
포럼에서 가장 자주 보는 질문은 “스크래핑이 합법인가요?”가 아니라 “내 스크래핑이 합법인가요?”예요. 추상적인 GDPR 이론만으론 답이 안 나오죠. 그래서 흔한 비즈니스 사용 사례별로 쪼개봤어요.
| 사용 사례 | 데이터 유형 | 핵심 법적 리스크 | 예상 결과 |
|---|---|---|---|
| 이커머스 가격 모니터링(공개 상품 목록) | 비개인정보(가격, SKU, 상품명) | 데이터베이스 지침의 독자적 권리; 이용약관 위반 | 개인정보가 없고 데이터베이스의 “상당한 부분”을 체계적으로 추출하지 않는다면 일반적으로 낮은 리스크 |
| B2B 리드 생성(디렉터리의 연락처 정보) | 개인정보(이름, 이메일, 전화번호) | GDPR 제6조 적법한 근거; 제14조 통지; 전자적 연락에 대한 ePrivacy | 리스크가 더 높음 — 문서화된 정당한 이익 균형 테스트와 통지 의무가 필요 |
| 부동산 매물 정보(포털의 부동산 데이터) | 혼합형(주소는 비개인정보일 수 있고, 소유자 이름은 개인정보) | 데이터베이스 지침; 이용약관; 소유자와 연결되면 GDPR | 중간 리스크 — 소유자 데이터를 익명화하고, 이용약관을 확인하고, robots.txt를 존중하세요 |
| AI 학습 데이터(대규모 웹 콘텐츠 스크래핑) | 필터링하지 않으면 개인정보일 수 있음 | GDPR + EU AI Act 제53조 TDM 의무 | 높은 리스크 — GDPR과 AI Act를 모두 준수해야 하며, 옵트아웃 메커니즘과 강력한 필터링이 필요 |
공개 이커머스 데이터처럼 상대적으로 낮은 리스크라면, Thunderbit의 Amazon·Shopify용 즉시 템플릿 같은 구조화된 도구가 도움이 돼요. 쓸데없는 콘텐츠를 안 모으고 구체적인 비개인 필드만 뽑으니 노출이 줄거든요. 반대로 개인정보가 끼는 리드 생성 같은 고위험 시나리오에선 법적 검토가 먼저예요. 아무리 똑똑한 스크래퍼라도 규정 안 지킨 수집을 지킨 수집으로 둔갑시키진 못해요.
EU vs 미국 vs 영국: 웹 스크래핑 법은 어떻게 다를까?
사업이 국경을 넘나든다면, 각 규칙의 차이를 알아야 해요. 한눈에 스캔되는 나란한 표로 정리한 경쟁 기사가 잘 안 보여서, 여기 직접 만들었어요.
| 구분 | EU | 미국 | 영국(브렉시트 이후) |
|---|---|---|---|
| 주요 법률 | GDPR + 데이터베이스 지침 + ePrivacy | CFAA + 주법(제한적 연방 개인정보법) | UK GDPR + 2018년 데이터보호법 |
| 공개 데이터 스크래핑 | 개인정보가 있으면 여전히 GDPR 적법한 근거 필요 | hiQ v. LinkedIn 이후 일반적으로 합법(공개 데이터) | EU와 유사; ICO 가이드 적용 |
| 이용약관 집행 | 민사 문제; Ryanair v. PR Aviation에서 독자적 권리 집행 | Van Buren이 CFAA 범위를 축소; ToS 위반 ≠ 형사 범죄 | 민사 문제, EU와 유사 |
| 데이터베이스 보호 | 독자적 권리(강함) | 대응되는 연방법 없음 | 유지된 독자적 권리 |
| AI/TDM 예외 | DSM 지침 제3~4조; AI Act 제53조 | 연방 TDM 예외 없음(공정 이용 원칙) | 영국은 TDM 예외 검토 중(2026년 기준 정체) |
| 주요 집행기관 | 국가별 DPA(CNIL, 네덜란드 AP 등) | FTC + 주 법무장관 | ICO |
| 최근 경향 | 더 엄격해짐(네덜란드 AP: 개인정보는 “거의 항상 불법”) | hiQ 이후 더 관대 | 중간 수준; 대체로 EU 방향을 따름 |
유럽 사이트나 유럽 거주자 관련 데이터를 긁는다면, 회사가 미국이나 영국에 있어도 EU 규칙이 적용돼요.
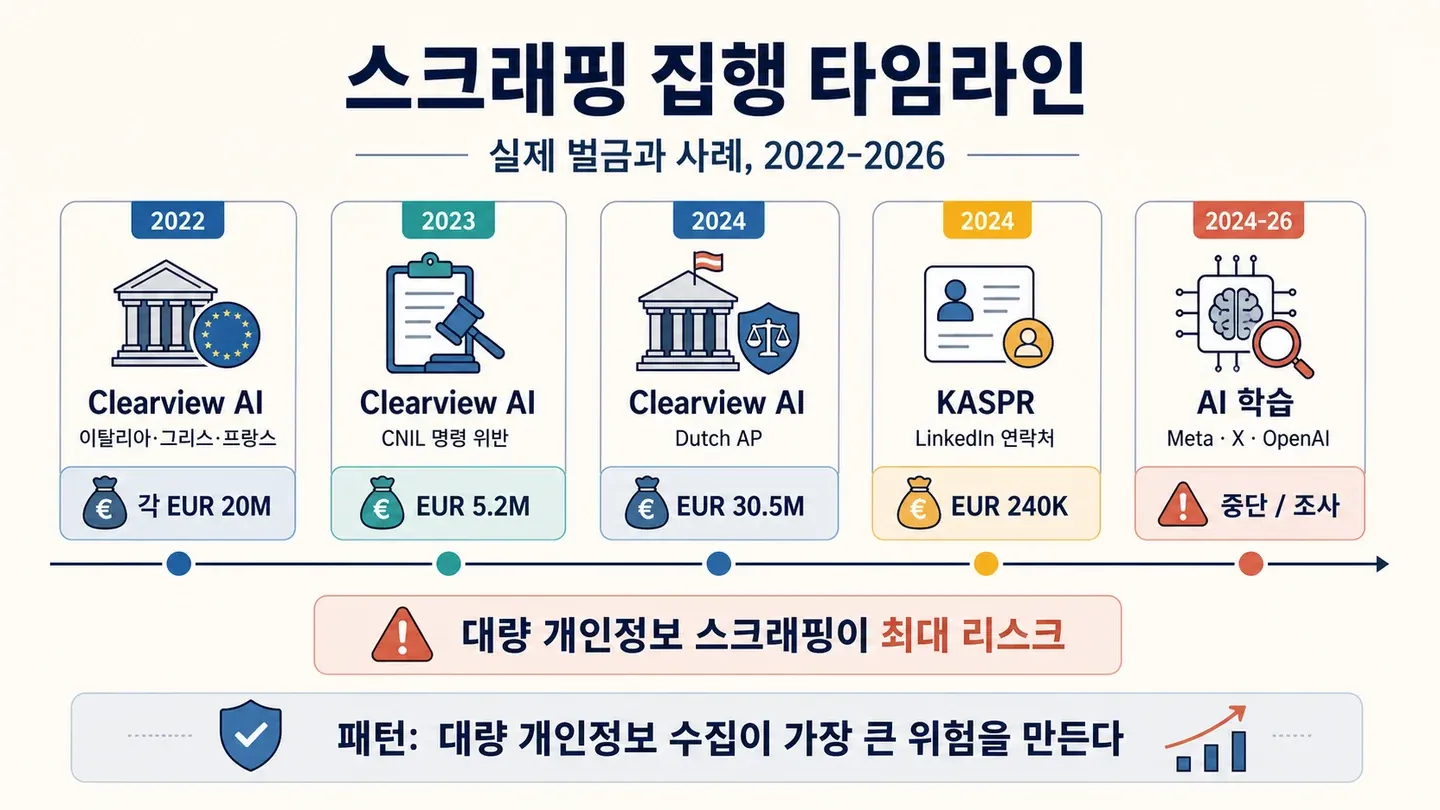
실제 과징금과 사례: 2022~2026년에 걸리면 무슨 일이 벌어질까?
이건 질문 뒤에 숨은 진짜 질문에 답하는 섹션이에요. “실제 위험이 얼마나 큰가?” 2022년부터 2026년 4월까지 웹 스크래핑이나 스크래핑된 개인정보와 얽힌 공개 DPA 집행 조치를 다 모았어요.
| 연도 | 집행기관 | 대상 | 위반 내용 | 과징금/결과 |
|---|---|---|---|---|
| 2022 | 이탈리아 Garante | Clearview AI | 법적 근거 없이 얼굴 이미지를 스크래핑 | 2,000만 유로 과징금 + 금지 + 삭제 명령 |
| 2022 | 그리스 Hellenic DPA | Clearview AI | 동일 — 얼굴 인식 스크래핑 | 2,000만 유로 과징금 + 금지 + 삭제 |
| 2022 | CNIL(프랑스) | Clearview AI | 얼굴 인식 데이터베이스 | 2,000만 유로 과징금 + 하루 10만 유로 추가 과징금 가능 |
| 2023 | CNIL(프랑스) | Clearview AI | 2022년 명령 미이행 | 520만 유로 벌금 지급 명령 |
| 2023 | 오스트리아 DSB | Clearview AI | 공개 웹의 300억 건 이상 얼굴 이미지 | 삭제 + EU 대리인 지정 명령(공개된 벌금 없음) |
| 2024 | 네덜란드 AP | Clearview AI | 불법 얼굴 인식 데이터 수집 | 3,050만 유로 과징금 + 준수 명령 |
| 2024 | CNIL(프랑스) | KASPR | 리드 생성용 LinkedIn 연락처 데이터 스크래핑 | 24만 유로 과징금 — 1억 6천만 건 연락처, 제한 공개 데이터, 5년 보관 |
| 2024 | 아일랜드 DPC | X / Grok | AI 학습에 사용된 공개 게시물 | 중단 합의; 2025년에 법정 조사 개시 |
| 2024 | 아일랜드 DPC | Meta | 공개 Facebook/Instagram 콘텐츠로 LLM 학습 예정 | Meta가 EU AI 학습 계획을 중단 |
| 2024 | 이탈리아 Garante | OpenAI | ChatGPT 학습 데이터 + 투명성 | 1,500만 유로 과징금 부과, 2026년 3월 로마 법원에서 취소 |
스크래핑/오픈웹 범주에서 EU/EEA의 총 금전 제재액은 9,500만 유로 이상이에요(취소된 OpenAI 과징금 제외).
이 큰 과징금들은 전부 법적 근거 없이 생체정보나 개인정보를 대량으로 긁은 사례를 겨눴어요. Clearview는 수십억 장의 얼굴 이미지를 긁었고, KASPR는 제한 공개 LinkedIn 프로필 데이터를 포함한 1억 6천만 건 연락처를 긁어 5년간 끼고 있었어요.
반대로 상품 가격이나 SKU 번호처럼 공공 비개인 데이터를 비례적으로, 목적에 맞게 긁은 행위는 집행 대상이 된 적이 없어요. 그렇다고 안전하다는 뜻은 아니지만, 위험 수준을 가늠하는 데는 도움이 돼요.
유럽 사이트를 안전하게 긁는 법: 단계별 가이드
- 난이도: 초급
- 소요 시간: 약 15분(준수 검토 포함)
- 준비물: Chrome 브라우저, Thunderbit 확장 프로그램(무료 플랜 가능), 대상 URL, 그리고 위 체크리스트의 간단한 검토
1단계: 목적과 필요한 데이터를 정의하세요
도구를 열기 전에, 왜 그 데이터가 필요한지와 정확히 어떤 필드가 필요한지 적어두세요. 좋은 습관일 뿐 아니라 GDPR의 목적 제한·데이터 최소화 원칙의 토대예요.
예를 들어 “경쟁 가격표를 갱신하려고 아마존 상품 페이지 50개에서 상품명, 가격, 재고 상태가 필요하다”는 구체적이에요. “아마존의 모든 걸 긁고 싶다”와 비교해 보세요. 앞쪽은 최소화 테스트를 통과하지만, 뒤쪽은 못 해요.
2단계: 준수 체크리스트를 돌리세요
위 6단계 “이거 긁어도 될까?” 체크리스트를 따라가세요. 어느 관문에서든 🛑가 나오면, 진행 전에 법률 자문을 받으세요.
아마존 가격 예시를 관문에 넣으면 이래요. 데이터는 비개인정보예요(가격, SKU, 상품명) ✅, GDPR 개인정보 이슈 없음 ✅, 아마존 약관은 검토 필요(스크래핑을 제한하니, 가능하면 공식 상품 데이터 API를 고려) ⚠️, 50개 상품 기준 데이터베이스 지침 리스크 낮음 ✅.
3단계: 맞는 스크래핑 방식을 고르세요
| 방법 | 사용 편의성 | 준수 지원 | 유지보수 | 정확도 |
|---|---|---|---|---|
| 수동 복사-붙여넣기 | 낮음 | 해당 없음(무엇을 복사할지 직접 통제) | 높음(시간 많이 소요) | 오류 발생 가능 |
| 코드 기반 스크래퍼(Python, Scrapy) | 낮음(코딩 필요) | 내장 기능 없음 | 높음(사이트 변경 시 깨짐) | 유지하면 높음 |
| Thunderbit(AI 기반) | 매우 높음 | 필드 수준 최소화 내장 | 낮음(AI가 페이지 변경에 적응) | 높음 |
| 공식 API | 중간 | 가장 높음(구조화되고 승인된 접근) | 낮음 | 가장 높음 |
개발팀이 없는 비즈니스 사용자라면 Thunderbit이 가장 빠른 길이에요. 공식 API가 있는 사이트(예: Amazon Product Advertising API)는 API가 늘 가장 안전한 선택이지만, 데이터 양과 필드에 제한이 따르는 경우가 많아요.
4단계: 준수를 고려해 스크래퍼를 설정하세요
Thunderbit에서:
- 대상 페이지로 이동하세요(예: 아마존 상품 목록 페이지).
- Chrome 도구 모음에서 Thunderbit 아이콘을 누르고 “AI Suggest Fields”를 선택하세요. AI가 페이지를 스캔해 “상품명”, “가격”, “평점”, “재고 상태” 같은 열을 제안해요.
- 필요 없는 필드는 빼세요. AI가 “판매자 이름”이나 “판매자 이메일”을 제안했는데 가격 데이터만 필요하다면 그 열을 지우세요. 이게 실무에서의 데이터 최소화예요.
- Field AI Prompt로 “개인 식별자 제외”나 “공개 가격 데이터만 추출” 같은 지시를 더하세요.
- 공개 이커머스 사이트엔 Cloud Scraping을(더 빠르고 로그인 불필요), 인증이 필요한 사이트엔 Browser Scraping을 고르세요.
- “Scrape”를 누르기 전에 robots.txt가 해당 사용 사례를 막지 않는지 확인하세요. 브라우저에서
[도메인]/robots.txt를 열면 돼요.
이제 설정한 필드만 든 테이블 미리보기가 보여야 해요. 불필요한 개인정보도, 쓸데없는 메타데이터도 없어야 하고요.
5단계: 데이터를 책임감 있게 내보내고 저장하고 관리하세요
스크래핑 후엔 데이터를 Excel, Google Sheets, Airtable, Notion으로 내보내세요. Thunderbit는 이들 모두로 무료 내보내기를 지원해요.
그다음은:
- 보관 기간을 정하세요. 스크래핑 데이터를 무기한 쟁여두지 마세요. 주간 가격 모니터링이라면 지난달 원본 데이터는 거의 필요 없어요.
- 개인정보를 모았다면(예: 리드 생성), 법적 근거를 문서화하고, 제14조 투명성 고지를 게시하고, 옵트아웃·삭제 요청을 처리할 절차를 마련하세요.
- 가능하면 삭제 일정을 자동화하세요. Thunderbit의 Scheduled Scraper는 같은 필드 설정을 유지한 채 정해진 간격으로 반복 스크래핑을 자동화해, 매 실행이 준수 범위 안에 머물도록 도와요.
유럽에서 긁으면서 준수 상태를 유지하는 팁
이 주제를 파고들고 준수에 민감한 팀들과 이야기하며 배운 것들이에요.
- 새 사이트를 긁기 전에 항상 약관을 확인하세요. 2분이면 되고, 수개월짜리 법적 골칫거리를 막아줘요.
- 가능하면 API를 쓰세요. 구조화돼 있고, 승인된 접근이며, 가장 안전한 길이에요. 스크래핑은 기본값이 아니라 대안이어야 해요.
- 대규모 개인정보 프로젝트엔 DPIA를 하세요. CNIL은 AI 학습 데이터셋이 고위험을 만들 수 있다고 봐요. DPIA는 책임성을 입증하는 증거가 돼요. 규모가 작아도 분석을 문서로 남기는 게 현명해요.
- 스크래핑 로그를 남기세요. 무엇을, 언제, 어디서, 어떤 법적 근거로, 얼마나 보관할지 적어두세요. DPA가 나중에 물으면 그 기록이 크게 도와줘요.
- 규제 업데이트를 주시하세요. DPA 가이드는 빠르게 바뀌어요. CNIL은 2026년 1월에 새 AI 스크래핑 가이드를 냈고, EDPB도 추가 의견을 낼 걸로 보여요. 오늘의 규칙이 내일 더 빡빡해질 수 있어요.
- 제한되거나 민감한 출처는 긁지 마세요. CNIL의 의무 제외 목록엔 건강 포럼, 주로 미성년자가 쓰는 사이트, 음란 사이트, 족보 사이트, 고도로 구조화된 개인정보 사이트가 들어가요. 스크래핑 프로젝트를 만든다면 기본 차단 목록을 유지하세요.
- 자동화 트래픽은 운영상 정말 중요해요. Akamai는 2024년 봇이 전체 웹 트래픽의 42%였다고 보고했고, Thales/Imperva는 자동화 봇 트래픽이 처음으로 인간을 넘어 2024년 51%에 달했다고 밝혔어요. 규제기관은 봇의 행동, 속도, 우회 시도를 점점 위험성과 불공정성의 증거로 봐요. 책임감 있는 스크래퍼처럼 굴어야 해요 — 사용자 에이전트를 식별하고, 속도를 제한하고, 차단 신호를 존중하기. 이건 단순한 예의가 아니라 법적으로도 중요해요.
결론
웹 스크래핑은 유럽에서 불법이 아니에요. 다만 규제 대상이에요. 개인정보가 얽히면 더더욱요.
법적 결과는 무엇을 긁는지(개인정보 vs 비개인정보), 어떻게 긁는지(이용약관, robots.txt, 속도 제한, 필드 수준 최소화), 왜 긁는지(문서화된 목적과 적법한 근거)에 달려 있어요. 집행 사례는 분명해요. 법적 근거 없이 개인정보를 대량·무차별 스크래핑하면 7자리, 8자리 과징금으로 이어져요. 반대로, 안전장치를 갖춘 채 공공 비개인 데이터를 비례적으로 표적 스크래핑하는 건 완전히 다른 위험 범주예요.
실무 프레임워크는 이래요.
- 모든 스크래핑 프로젝트 전에 의사결정 체크리스트를 쓰세요.
- 개인정보보호청이 권고한 안전장치(투명성, 최소화, 보관 제한, 옵트아웃 메커니즘)를 적용하세요.
- 설계 단계부터 준수를 지원하는 도구를 고르세요. Thunderbit의 AI 기반 필드 선택, 구조화된 추출, 그리고 Google Sheets, Excel, Airtable, Notion으로의 무료 내보내기는 필요한 데이터만 — 더도 덜도 말고 — 긁기 쉽게 해줘요.
- 모든 걸 문서로 남기세요. 균형 테스트, 출처 목록, 보관 일정, DPIA. 규제기관이 물으면, 그 파일이 방어선이 돼요.
의무 면책 조항: 이 글은 법률 자문이 아니라 정보 제공용이에요. 개인정보를 대규모로 다루는 고위험 시나리오라면, 자격 있는 개인정보 변호사와 상담하세요. 규정은 계속 바뀌고, 잘못 판단했을 때의 비용은 실제로 커요.
직접 규정을 고려한 표적 웹 스크래핑을 시도해 보고 싶으세요? Thunderbit의 무료 플랜으로 소규모 구조화 추출을 시험해 볼 수 있어요. 필드를 정의하고, 필요한 것만 긁고, 클릭 몇 번으로 내보내세요. 단계별 안내가 담긴 YouTube 채널도 확인해 보세요.
규정 준수 데이터 추출을 위한 AI 웹 스크래퍼 사용해 보기 Get Started Free
자주 묻는 질문
1. 데이터가 공개돼 있으면 유럽에서 웹 스크래핑은 합법인가요?
공개돼 있다고 해서 개인정보가 든 경우 GDPR 적용이 면제되진 않아요. 네덜란드 개인정보보호청이 짚었듯, “공개”가 자동으로 스크래핑 허가가 되진 않아요. 비개인 공개 데이터(상품 가격, SKU)는 보통 리스크가 낮지만, 데이터베이스 지침과 사이트 약관은 여전히 확인해야 해요.
2. 유럽 사이트에서 이메일과 전화번호를 긁어도 되나요?
이메일과 전화번호는 GDPR상 개인정보예요. 적법한 근거가 필요하고 — 보통은 문서화된 균형 테스트를 포함한 정당한 이익이 해당돼요 — 제14조에 따라 개인에게 통지해야 해요. CNIL은 2024년에 적절한 투명성이나 법적 근거 없이 LinkedIn 연락처 데이터를 긁은 KASPR에 24만 유로를 부과했어요. 집행이 활발한 영역이라는 뜻이에요.
3. 유럽에서 불법 웹 스크래핑으로 가장 큰 과징금은 얼마인가요?
네덜란드 개인정보보호청은 2024년에 공개 웹에서 불법으로 얼굴 인식 데이터를 모은 Clearview AI에 3,050만 유로를 부과했어요. 다른 여러 EU DPA도 Clearview에 각각 2,000만 유로를 부과했고요. 2022~2026년 EU/EEA의 스크래핑 관련 총 과징금은 9,500만 유로를 넘어요.
4. robots.txt를 지키면 유럽에서 웹 스크래핑이 합법이 되나요?
robots.txt 준수는 모범 사례이고 CNIL의 의무 안전장치와도 맞지만, 그것만으로 합법성이 보장되진 않아요. 개인정보가 끼면 GDPR, 데이터베이스 지침, 사이트 약관도 함께 지켜야 해요. robots.txt 준수는 다층 준수 체계의 한 층으로 보세요.
5. 유럽과 미국의 웹 스크래핑 법은 어떻게 다른가요?
EU가 훨씬 더 빡빡해요. GDPR은 공개 데이터라도 개인정보에 적용되고, 데이터베이스 지침은 정리된 데이터셋에 강한 보호를 줘요. 미국엔 이 두 법에 상응하는 연방법이 없고, hiQ v. LinkedIn 이후 공개 데이터 스크래핑은 보통 허용돼요. 브렉시트 이후 영국은 UK GDPR과 유지된 데이터베이스 권리로 EU와 대체로 비슷하지만, ICO 집행이 적용돼요. 국경 간 비즈니스라면 EU 규칙이 가장 높은 기준이고, EU 거주자 데이터를 긁는다면 회사 소재지와 무관하게 그 규칙이 적용돼요.
더 알아보기




