상상해보세요. 2025년 어느 아침, 커피 한 잔 들고 Walmart에서 눈여겨보던 65인치 TV 가격이 떨어졌는지 확인하고 싶거나, 이커머스 사업을 하면서 Walmart의 가격, 재고, 고객 반응을 실시간으로 모니터링해야 한다면 어떨까요? 매일 모든 상품을 일일이 확인하는 건 사실상 불가능에 가깝죠. 하지만 Python과 웹 스크래핑 기술만 있으면, 반복적인 작업을 자동화해서 방대한 데이터를 손쉽게 모을 수 있습니다.
저는 오랜 시간 비즈니스 자동화와 AI 도구를 개발해왔는데, walmart 데이터 수집은 몇 시간씩 걸리던 리서치를 단 몇 줄의 코드로 바꿔주는 ‘비밀 무기’와도 같아요. 이 글에서는 walmart 데이터 수집이 뭔지, 2025년 비즈니스에 왜 중요한지, 그리고 Python으로 강력한 walmart 웹 스크래퍼를 만드는 방법을 실제 코드와 함께 단계별로 안내합니다. 커피(혹은 디버깅 간식) 챙기고 바로 시작해볼까요?
Walmart 데이터 수집이란? 2025년 기준 기본 개념
간단히 말해, walmart 데이터 수집은 소프트웨어(주로 초고속 웹 브라우저처럼 동작하는 스크립트)를 이용해 Walmart 웹사이트에서 상품, 가격, 리뷰 데이터를 자동으로 추출하는 걸 의미합니다. 일일이 복사-붙여넣기 할 필요 없이, Python 스크립트가 Walmart 페이지를 불러와 원하는 정보를 뽑아내고, 분석을 위해 저장하는 거죠.
왜 Python이냐고요? Python은 웹 스크래핑에 정말 잘 맞는 언어입니다. 코드가 읽기 쉽고, Requests, BeautifulSoup, pandas 등 강력한 라이브러리가 많고, 커뮤니티도 활발하죠. 혼자 리서치하든, 팀 단위로 일하든, Python만 있으면 walmart 데이터 수집이 어렵지 않습니다.
몇 개 상품 가격만 추적하는 것과, 비즈니스 목적으로 수천 개 SKU를 모니터링하는 건 규모와 난이도가 완전히 다릅니다. 특히 Walmart는 2025년 기준 공식 상품 API를 제공하지 않으니(), 기술적 난관도 함께 커집니다.
왜 Walmart 데이터를 수집해야 할까? 비즈니스 가치
Walmart는 미국 최대 오프라인 유통업체이자, 온라인 매출도 를 돌파하며 디지털 강자로 자리잡았습니다. 이커머스 매출이 전체의 **18%**에 달할 정도죠(). 즉, 분석할 만한 상품, 가격, 리뷰, 트렌드 데이터가 넘쳐난다는 뜻입니다.
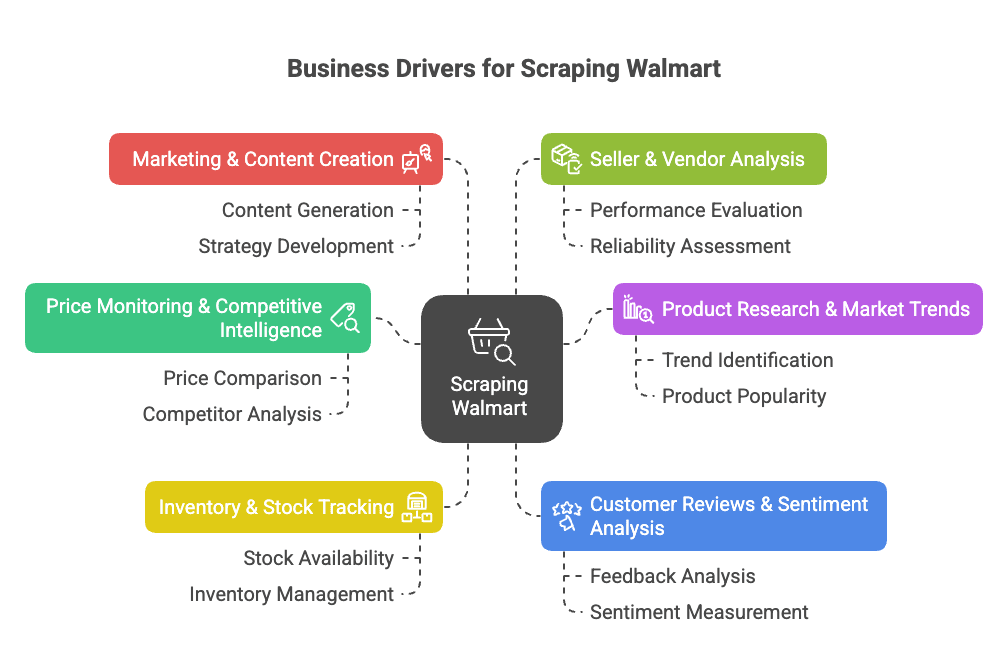
walmart 데이터를 수집해야 하는 주요 이유는 다음과 같아요:
- 가격 모니터링 & 경쟁사 분석: Walmart의 가격, 프로모션, 카탈로그 변동을 실시간으로 추적해 내 상품 전략에 반영할 수 있습니다().
- 상품 리서치 & 시장 트렌드 파악: Walmart의 상품 구성, 사양, 카테고리 트렌드를 분석해 새로운 기회를 포착할 수 있습니다().
- 재고 및 품절 현황 추적: 재고 상태를 모니터링해 공급망을 최적화하거나, 경쟁사 품절 시 기회를 잡을 수 있습니다().
- 고객 리뷰 & 감성 분석: 리뷰를 모아 분석하면 상품 개선이나 고객 불만 포인트를 파악할 수 있습니다().
- 마케팅 & 콘텐츠 전략: '베스트셀러' 상품, 상품 소개 방식, 전환을 이끄는 콘텐츠 유형을 파악할 수 있습니다().
- 셀러 및 벤더 분석: 상위 판매자나 비공식 판매자를 식별할 수 있습니다().
아래 표는 주요 활용 사례, 수혜자, 기대 효과를 한눈에 정리한 거예요:
| 활용 사례 | 수혜 부서 | 기대 효과 및 ROI |
|---|---|---|
| 가격 모니터링 | 가격/영업팀 | 실시간 경쟁사 가격 파악, 동적 가격 전략, 마진 보호 |
| 상품/카탈로그 분석 | 상품기획, MD | 상품군 공백 파악, 신상품 기획, 카탈로그 완성도 향상 |
| 재고 추적 | 운영/공급망 | 수요 예측, 품절 방지, 물류 최적화 |
| 리뷰/감성 분석 | 상품개발, 고객경험 | 데이터 기반 상품 개선, 만족도 향상 |
| 시장 트렌드 분석 | 전략/시장조사 | 트렌드 조기 포착, 전략 수립, 신시장 진입 |
| 콘텐츠/가격 전략 | 마케팅/이커머스 | 가격 전략 고도화, 고성과 콘텐츠 벤치마킹 |
| 셀러 모니터링 | 영업/파트너십 | 파트너 발굴, 브랜드 보호, 비공식 셀러 감시 |
결국, walmart 데이터 수집은 시간 절약, 매출 증대, 데이터 기반 경쟁력 확보에 큰 도움이 됩니다. 매일 50개 페이지를 직접 확인하는 대신, 스크립트 한 번이면 수천 개 상품 정보를 몇 분 만에 모을 수 있죠().
walmart 데이터 수집은 이커머스, 영업, 시장조사팀에 혁신적인 변화를 가져옵니다. 제대로 된 도구만 있다면, 반복적인 데이터 수집 대신 인사이트 도출에 집중할 수 있어요.
Python으로 Walmart 데이터 수집: 준비물 체크리스트
시작하기 전에 Python 환경을 세팅해야겠죠? 필요한 도구는 아래와 같습니다:
- Python 3.9 이상 (2025년 기준 3.11 또는 3.12 추천)
- Requests: 웹페이지 요청용
- BeautifulSoup (bs4): HTML 파싱용
- pandas: 데이터 정리 및 내보내기
- json: JSON 데이터 처리 (내장)
- 개발자 도구가 있는 웹 브라우저: Walmart 페이지 구조 확인용 (F12)
- pip: 패키지 설치용
설치 명령어:
1pip install requests beautifulsoup4 pandas프로젝트를 깔끔하게 관리하고 싶다면 가상환경을 추천해요:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Mac/Linux
3# 또는
4walmart-scraper\\Scripts\\activate.bat # Windows설치 확인:
1import requests, bs4, pandas
2print("라이브러리 정상 로드!")이 메시지가 뜨면 준비 완료!
1단계: Python Walmart 웹 스크래퍼 프로젝트 세팅
정리부터 시작해볼게요:
- 프로젝트 폴더 생성 (예:
walmart_scraper/) - 코드 에디터 열기 (VSCode, PyCharm, Notepad++ 등)
- 새 스크립트 파일 만들기 (예:
walmart_scraper.py)
기본 템플릿 예시:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import json이제 Walmart 상품 페이지를 불러올 준비가 끝났습니다.
2단계: Python으로 Walmart 상품 페이지 불러오기
Walmart에서 데이터를 수집하려면 상품 페이지의 HTML을 가져와야 해요. 하지만 주의! Walmart는 봇 차단이 정말 강력합니다. 단순히 requests.get(url)만 쓰면, '로봇인가요?'라는 메시지를 금방 보게 될 거예요.
해결법? 실제 브라우저처럼 보이게 헤더를 설정하세요. 즉, User-Agent와 Accept-Language를 Chrome이나 Firefox처럼 지정해야 합니다.
예시:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.text팁: requests.Session()을 사용하면 쿠키가 유지되어 더 자연스럽게 보입니다:
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # 쿠키 세팅용 홈 방문
4response = session.get(product_url)response.status_code가 200인지 항상 확인하세요. 이상한 페이지나 CAPTCHA가 뜨면 속도를 늦추거나, IP를 바꾸거나, 잠시 쉬는 게 좋습니다. Walmart의 봇 차단은 정말 만만치 않아요().
Walmart의 봇 차단 우회 방법
Walmart는 Akamai, PerimeterX 등 다양한 솔루션으로 IP, 헤더, 쿠키, TLS 지문까지 체크합니다. 우회 팁은 아래와 같아요:
- 항상 실제 브라우저와 유사한 헤더 사용
- 요청 간 3~6초 대기
- 지연 시간 랜덤화
- 대량 수집 시 프록시 사용
- CAPTCHA가 뜨면 잠시 중단
더 정교하게 하려면 curl_cffi 같은 라이브러리로 요청을 실제 브라우저처럼 만들 수도 있습니다(). 하지만 대부분의 경우, 헤더와 인내심만으로도 충분합니다.
3단계: BeautifulSoup으로 Walmart 상품 데이터 추출
이제 본격적으로 원하는 데이터를 뽑아볼 차례입니다. Walmart는 Next.js 기반이라, 상품 정보가 <script id="__NEXT_DATA__"> 태그의 대형 JSON에 담겨 있어요.
추출 방법:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)이제 Python 딕셔너리 형태로 상품 정보를 다룰 수 있습니다. 일반적으로 상품 정보는 다음 위치에 있어요:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]필요한 데이터 추출 예시:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")왜 JSON을 쓰냐고요? 구조화되어 있고, HTML이 바뀌어도 잘 깨지지 않으며, 페이지에 보이지 않는 정보까지 포함된 경우가 많기 때문입니다().
동적 콘텐츠와 JSON 데이터 다루기
리뷰나 재고 정보 등 일부 데이터는 JavaScript나 별도 API로 동적으로 불러올 수 있습니다. 다행히 초기 JSON에 대부분 필요한 정보가 담겨 있어요. 부족하다면 브라우저 개발자 도구의 Network 탭에서 API 엔드포인트를 찾아 요청을 흉내낼 수 있습니다.
대부분의 상품 데이터는 __NEXT_DATA__ JSON에서 쉽게 찾을 수 있습니다.
4단계: Walmart 데이터 저장 및 내보내기
데이터를 추출했다면, CSV, Excel, JSON 등 구조화된 파일로 저장하는 게 좋겠죠. pandas를 활용한 예시:
1import pandas as pd
2product_record = {
3 "상품명": name,
4 "가격(USD)": current_price,
5 "평점": average_rating,
6 "리뷰 수": review_count,
7 "설명": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)여러 상품을 수집할 경우, 각 레코드를 리스트에 추가한 뒤 마지막에 DataFrame으로 만드세요.
Excel로 저장하려면 df.to_excel("walmart_products.xlsx", index=False) (openpyxl 필요), JSON은 df.to_json("walmart_products.json", orient="records", indent=2)를 사용하세요.
팁: 내보낸 데이터가 실제 사이트와 일치하는지 꼭 확인하세요. 필드명이 바뀌면 데이터가 모두 'None'이 될 수 있습니다.
5단계: Walmart 스크래퍼 확장하기
여러 상품 페이지를 수집하려면 아래처럼 할 수 있습니다:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...더 많은 URL
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...앞서 설명한 방식으로 데이터 추출...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # 예의 지키기!URL 목록이 없다면, 검색 결과 페이지에서 상품 링크를 추출해 각 상품을 순차적으로 수집할 수도 있습니다().
주의: 수백~수천 페이지를 빠르게 수집하면 IP가 차단될 수 있습니다. 이럴 땐 프록시가 필요해요.
Walmart용 프록시 및 스크래퍼 API 활용
프록시는 IP를 바꿔가며 수집할 수 있게 해줍니다. 실제 사용자처럼 보이는 주거용 프록시나 프록시 풀을 구매해 사용할 수 있습니다. 예시:
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)대규모 수집이 필요하다면 스크래퍼 API를 활용하는 것도 방법입니다. 이 서비스들은 프록시, CAPTCHA, JavaScript 렌더링까지 자동으로 처리해줍니다. Walmart URL만 보내면, 데이터(종종 JSON 형태)로 응답을 받을 수 있습니다.
간단 비교표:
| 방식 | 장점 | 단점 | 추천 대상 |
|---|---|---|---|
| 직접 Python + 프록시 | 완전한 제어, 소규모에 저렴 | 유지보수, 프록시 비용, 차단 위험 | 개발자, 맞춤형 필요시 |
| 서드파티 스크래퍼 API | 쉽고, 봇 차단 자동 처리, 확장성 | 대규모시 비용, 유연성 제한, 외부 의존 | 비즈니스, 대량 수집, 빠른 결과 |
개발자가 아니거나 빠르게 데이터가 필요하다면 처럼 클릭 몇 번으로 모든 과정을 자동화할 수 있는 도구를 추천합니다.
Walmart 데이터 수집 시 자주 겪는 문제와 해결법
walmart 데이터 수집이 항상 순탄한 건 아닙니다. 대표적인 문제와 해결책은 아래와 같아요:
- 강력한 봇 차단: IP, 헤더, 쿠키, TLS 지문, JS 체크 등 다양한 방식으로 탐지합니다. 해결: 실제 브라우저와 유사한 헤더, 세션 사용, 지연 추가, 프록시 활용().
- CAPTCHA: CAPTCHA가 뜨면 잠시 중단 후 재시도하세요. 반복된다면 CAPTCHA 우회 서비스도 있지만, 비용과 복잡도가 증가합니다().
- 사이트 구조 변경: Walmart는 사이트 구조를 자주 바꿉니다. 스크래퍼가 깨지면 JSON 구조를 다시 확인하고 코드를 수정하세요. 모듈화된 코드가 도움이 됩니다.
- 페이지네이션/하위 페이지: 대량 데이터 수집 시 페이지네이션 처리가 필요합니다. 반복문에 종료 조건을 명확히 두세요().
- 대용량 데이터/속도 제한: 대규모 수집 시 요청을 배치로 나누고, 중간 결과를 저장하세요. 한 번에 10만 개 상품을 메모리에 올리지 마세요.
- 법적/윤리적 이슈: 공개 데이터만 수집하고, Walmart의 이용약관을 준수하며, 서버에 과부하를 주지 마세요. 비즈니스 목적이라면 반드시 법적 검토를 하세요.
언제 관리형 솔루션으로 전환해야 할까? CAPTCHA와의 싸움에 시간을 너무 많이 쓴다면 Thunderbit 같은 도구나 스크래퍼 API로 전환하는 게 현명합니다. 비개발자라면 노코드 도구가 훨씬 효율적이에요().
Python으로 Walmart 데이터 수집: 전체 예제 코드
지금까지 배운 내용을 하나로 합쳐볼게요. 아래는 Walmart 상품 페이지를 수집하는 전체 Python 예제 코드입니다:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# 세션 및 헤더 설정
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# 쿠키 세팅을 위해 홈 방문
14session.get("<https://www.walmart.com/>")
15# 수집할 상품 URL 목록
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # 필요시 추가
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"\{url\} 요청 오류: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"\{url\} 불러오기 실패 (상태 \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"\{url\}에서 데이터 스크립트 미발견 - 차단 또는 페이지 구조 변경 가능.")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"\{url\} JSON 파싱 오류: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"\{url\} JSON에서 상품 데이터 미발견.")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "상품명": name,
59 "브랜드": brand,
60 "가격": price,
61 "통화": currency,
62 "원래가격": orig_price,
63 "평점": avg_rating,
64 "리뷰수": review_count,
65 "설명": desc
66 }
67 all_products.append(product_record)
68 # 탐지 방지를 위한 랜덤 대기
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)커스터마이즈 팁:
product_urls에 원하는 만큼 URL 추가- 추출 필드 조정
- 대기 시간 조절
결론 및 핵심 요약
정리하자면:
- walmart 데이터 수집은 가격, 상품, 리뷰 등 핵심 정보를 확보하는 강력한 방법입니다. 2025년 경쟁력 확보, 가격 전략, 상품 개발에 필수죠.
- Python이 최적의 도구입니다. Requests, BeautifulSoup, pandas만으로도 충분히 강력한 스크래퍼를 만들 수 있어요.
- 봇 차단 우회가 중요합니다. 브라우저 헤더 흉내, 세션 사용, 지연 추가, 프록시 활용이 필수입니다.
__NEXT_DATA__JSON에서 데이터 추출이 가장 안정적입니다.- pandas로 데이터 내보내기 (CSV, Excel, JSON 등)
- 확장 시 프록시/스크래퍼 API 고려. 비개발자라면 로 Walmart(및 다양한 사이트) 데이터를 클릭 두 번에 추출할 수 있습니다. Excel, Google Sheets, Airtable, Notion으로 무료 내보내기도 지원합니다().
추천:
처음엔 소규모로 시작해 데이터 정확성을 꼭 확인하세요. Walmart의 정책을 준수하고, 서버에 무리를 주지 마세요. 필요가 커지면 관리형 도구나 API로 전환해 시간과 리스크를 줄이세요. Python 디버깅이 지칠 땐, Thunderbit로 Walmart(및 거의 모든 사이트) 데이터를 AI가 알아서 수집해줍니다().
웹 스크래핑, 데이터 자동화, AI 생산성에 대해 더 깊이 배우고 싶다면 에서 다양한 가이드를 확인해보세요.
즐거운 데이터 수집 되시길 바랍니다. 신선하고 정확한 데이터, 그리고 CAPTCHA 없는 하루가 되시길!
P.S. 새벽 2시에 Walmart를 스크래핑하며 혼잣말을 하게 되더라도, 데이터 담당자라면 누구나 겪는 성장통이니 걱정 마세요.
자주 묻는 질문(FAQ)
1. Python으로 Walmart 데이터를 수집하는 것이 합법인가요?
공개된 데이터를 개인적/비상업적 분석 목적으로 수집하는 건 일반적으로 허용되지만, 비즈니스 목적일 경우 법적·윤리적 문제가 발생할 수 있습니다. Walmart의 이용약관을 반드시 확인하고, 과도한 요청이나 민감 정보 수집은 피하세요.
2. Python 스크래핑으로 Walmart에서 어떤 데이터를 추출할 수 있나요?
상품명, 가격, 브랜드, 설명, 고객 리뷰, 평점, 재고 상태 등 다양한 정보를 추출할 수 있습니다. 특히 <script id="__NEXT_DATA__"> 태그의 구조화된 JSON을 파싱하면 더욱 풍부한 데이터를 얻을 수 있어요.
3. Walmart 데이터 수집 시 차단을 피하려면 어떻게 해야 하나요?
실제 브라우저와 유사한 헤더 사용, 세션 유지, 요청 간 랜덤 지연(3~6초), 프록시 활용, 과도한 요청 자제 등이 필요합니다. 대규모 프로젝트라면 스크래퍼 API나 Thunderbit 같은 도구를 활용해 자동으로 차단을 우회할 수 있습니다.
4. 수백~수천 개 Walmart 상품 페이지를 대량 수집할 수 있나요?
가능하지만, 프록시 관리, 요청 속도 조절, 스크래퍼 API 활용 등 추가적인 준비가 필요합니다. Walmart의 봇 차단이 강력하니, 준비 없이 대량 수집하면 차단이나 CAPTCHA에 걸릴 수 있어요.
5. 코딩을 몰라도 Walmart 데이터를 쉽게 수집할 수 있나요?
Thunderbit AI 웹 스크래퍼 크롬 확장 프로그램 등 도구를 사용하면, 코딩 없이도 Walmart 상품 페이지 데이터를 손쉽게 추출할 수 있습니다. 자동으로 봇 차단을 우회하고, Excel, Notion, Sheets 등으로 데이터 내보내기도 지원해 비개발자나 비즈니스팀에 딱 맞아요.