는 AI를 활용해 웹사이트에서 데이터를 수집할 수 있게 도와주는 AI 웹 스크래퍼 Chrome 확장 프로그램입니다. 핵심만 먼저 말하면, ScrapingBee의 가격 페이지는 겉보기엔 꽤 저렴해 보이지만, 실제 운영 환경에서 대량 작업을 돌리기 시작하면 크레딧이 기본 요금 대비 5배에서 75배까지 빠르게 소모될 수 있다는 점입니다. 이 리뷰에서는 보통 글에서 잘 다루지 않는 5가지 관점을 짚어봅니다. 대규모 운영 시 실제 비용, 셀렉터 기반 방식과 AI 추출의 차이, 비개발자 입장에서의 사용성, 스크래핑 이후의 데이터 워크플로, 그리고 2026년 기준 신뢰성 벤치마크까지 하나씩 살펴봅니다. 개발자든, 세일즈 오퍼레이션 담당자든, 혹은 창업자든 팀용으로 ScrapingBee를 검토 중이라면 꼭 필요한 정리입니다.
ScrapingBee란? 빠르게 살펴보기
ScrapingBee는 프록시 순환, JavaScript 렌더링, CAPTCHA 해결을 대신 처리해 주는 웹 스크래핑 API입니다. 개발자가 직접 스크래핑 인프라를 구축하지 않아도 웹사이트에서 데이터를 추출할 수 있게 해 주죠. 파라미터를 넣은 HTTP 요청을 보내면 HTML(일부 엔드포인트는 JSON) 응답을 받을 수 있습니다. 스크래핑을 눈으로 보면서 만드는 클릭형 인터페이스는 없습니다.
주요 기능은 다음과 같습니다.
- 순환 및 프리미엄 프록시(classic, premium, stealth, residential)
- 헤드리스 브라우저 렌더링(전체 Chrome, 기본 활성화)
- 자동 CAPTCHA 우회
- Google Search API(organic 결과, 광고, 지도, 지식 그래프, People Also Ask, 이미지, 뉴스까지 구조화된 JSON 제공)
- 스크린샷 캡처(기본, 전체 페이지, 또는 CSS 선택자 지정 대상)
country_code파라미터를 통한 지역 타깃팅- CSS/XPath 추출 규칙(선언형 JSON 기반, 구조화된 JSON 반환)
- Amazon, Walmart, YouTube, ChatGPT용 전용 API
- AI 추출(~2024~2025 추가):
ai_query,ai_extract_rules,ai_selector파라미터(+5 크레딧/요청) - CLI 도구(~2025~2026 출시): 배치 처리, 크롤링, 사이트맵 파싱, CSV 보강, 예약 cron 작업, 프록시 단계적 상향
2019년 프랑스에서 설립된 ScrapingBee는 2026년 초 기준 약 규모로 성장했고, SAP, Zapier, Deloitte, Zillow를 포함한 2,500개 이상의 고객을 확보했습니다. 놀랍게도 이 모든 걸 직원 4~6명 규모의 부트스트랩 팀으로 해냈습니다. 2025년 6월에는 했습니다. 브랜드와 리더십은 독립성을 유지하고 있으며, 지원팀은 되어 시간대별 대응 범위도 더 좋아졌습니다.
중요한 점 하나: ScrapingBee는 여전히 네이티브 시각적 빌더, 클릭형 GUI, 내장 웹 대시보드 스케줄러가 없습니다. 예약 실행은 CLI 도구, cron 작업, 또는 Zapier, Make, n8n 같은 외부 자동화 도구가 필요합니다. 이들이 말하는 "노코드" 가이드는 네이티브 노코드 UI가 아니라 Make와 Zapier 연동을 활용하는 방법을 뜻합니다.
ScrapingBee는 실제로 누구를 위한 도구인가?
ScrapingBee는 Python이나 cURL 호출을 작성하고, HTML을 읽고, CSS/XPath 선택자를 다룰 수 있는 개발자를 위해 설계되었습니다. 문서도 코드 중심이라 Python과 cURL 예시가 많이 보입니다. 의 한 리뷰어는 "JavaScript 예시는 제공하지 않는다"고 했고, 또 다른 사용자는 문서를 "덩치가 크고, 읽는 데 하루에서 일주일이 걸린다"고 표현했습니다.
하지만 2026년에 "ScrapingBee review"를 찾는 사람은 백엔드 엔지니어만이 아닙니다. 잠재고객 리스트를 만드는 마케팅 매니저, CRM 데이터를 보강하는 세일즈 오퍼레이션 팀, 경쟁사 가격을 모니터링하는 이커머스 운영팀, 팀 도입을 검토하는 창업자까지 포함됩니다. 아래 각 섹션마다 해당 기능이나 한계가 개발자, 비개발자, 혹은 둘 다에게 얼마나 중요한지도 함께 짚어보겠습니다.
ScrapingBee 요금제 한눈에 보기
2026년 4월 기준 ScrapingBee의 현재 요금제는 다음과 같습니다.
| 플랜 | 월 요금 | API 크레딧/월 | 동시 요청 수 |
|---|---|---|---|
| Freelance | $49 | 250,000 | 10 |
| Startup | $99 | 1,000,000 | 50 |
| Business | $249 | 3,000,000 | 100 |
| Business+ | $599 | 8,000,000 | 200 |
| Enterprise | 영업팀 문의 | 4,100만+ | 맞춤형 |
연간 결제 시 이 제공됩니다. 무료 체험은 1,000 API 크레딧을 제공하며 카드 등록도 필요 없습니다. Google Search API는 인수 이후 최근 되었습니다.
겉으로 보이는 크레딧 수치는 넉넉해 보입니다. 하지만 실제는 다릅니다.
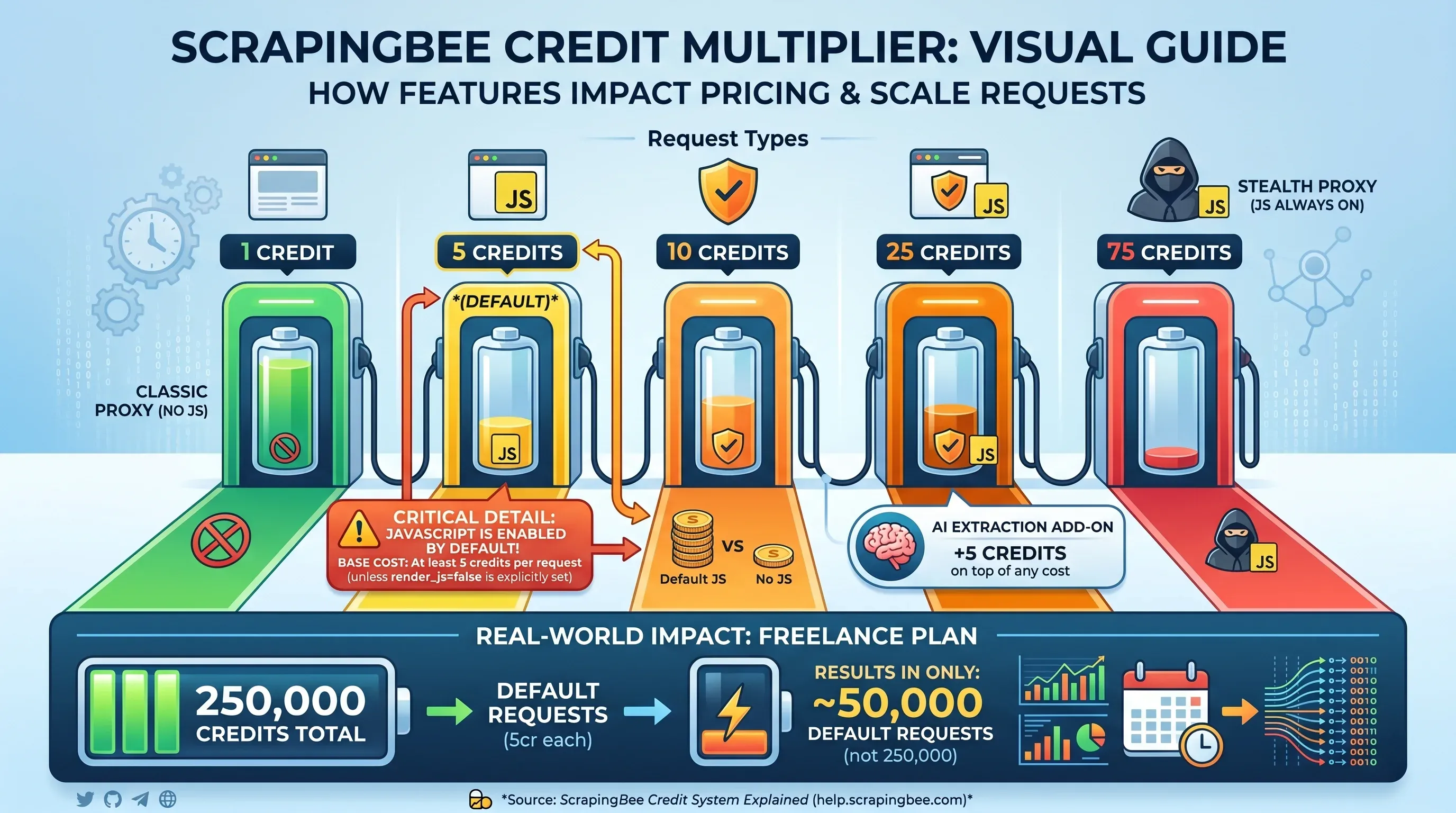
크레딧 배수 표
여기서부터 ScrapingBee의 가격 구조가 복잡해집니다. 표면상의 크레딧 수는 실제로 스크래핑할 수 있는 페이지 수와 같지 않습니다. 요청마다 어떤 기능을 켜느냐에 따라 달라집니다.
| 요청 유형 | 요청당 크레딧 |
|---|---|
클래식 프록시, JS 렌더링 없음 (render_js=false) | 1 크레딧 |
| 클래식 프록시, JS 렌더링 사용(기본값) | 5 크레딧 |
| 프리미엄 프록시, JS 렌더링 없음 | 10 크레딧 |
| 프리미엄 프록시, JS 렌더링 사용 | 25 크레딧 |
| 스텔스 프록시(JS 항상 활성화) | 75 크레딧 |
| AI 추출 추가 기능 | 기본 비용에 +5 크레딧 |
중요한 포인트: JavaScript 렌더링은 . render_js=false를 명시적으로 설정하지 않으면 모든 요청이 최소 5 크레딧을 사용합니다. 즉 Freelance 플랜의 250,000 크레딧은 실제로는 기본 요청 기준 50,000건만 처리할 수 있다는 뜻입니다. 250,000건이 아닙니다.
아무도 잘 보여주지 않는 숨은 크레딧 계산식
10,000페이지를 스크래핑할 때 ScrapingBee 실제 비용이 시나리오와 플랜에 따라 어떻게 달라지는지 보겠습니다.
| 시나리오 | 필요 크레딧 | Freelance ($49/25만) | Startup ($99/100만) | Business ($249/300만) |
|---|---|---|---|---|
| 1만 페이지(정적 HTML, 1크레딧) | 10,000 | ✅ 커버됨 ($0.20/1K) | ✅ 커버됨 ($0.10/1K) | ✅ 커버됨 ($0.08/1K) |
| 1만 페이지(JS 렌더링, 5크레딧) | 50,000 | ✅ 커버됨 ($0.98/1K) | ✅ 커버됨 ($0.50/1K) | ✅ 커버됨 ($0.42/1K) |
| 1만 페이지(프리미엄 프록시 + JS, 25크레딧) | 250,000 | ⚠️ 정확히 한도 도달 ($4.90/1K) | ✅ 커버됨 ($2.48/1K) | ✅ 커버됨 ($2.08/1K) |
| 1만 페이지(스텔스 프록시, 75크레딧) | 750,000 | ❌ 한도 초과 | ✅ 간신히 커버 ($7.43/1K) | ✅ 커버됨 ($6.23/1K) |
같은 10,000페이지라도 프록시와 렌더링 설정에 따라 1,000페이지당 $0.20에서 $7.43까지 비용이 달라집니다. 그리고 어떤 구성이 필요한지는 실제로 시도해 보기 전엔 모를 때가 많습니다.
예산 시나리오: 월 10,000페이지 리드 생성
세일즈 팀이 리드 생성을 위해 매달 10,000개 기업 페이지를 스크래핑한다고 해봅시다. 요즘 대부분의 B2B 사이트는 React나 Vue를 쓰기 때문에 JS 렌더링이 필요합니다.
- 필요 크레딧: 50,000(1만 × 5 크레딧)
- Freelance 플랜($49): 20만 크레딧이 남으므로 충분
- 하지만 대상 사이트에 프리미엄 프록시가 필요하면: 250,000 크레딧이 필요해 Freelance 한도와 정확히 일치, 여유분 없음
- 스텔스 프록시가 필요하면: 750,000 크레딧이 필요하므로 월 $99의 Startup 플랜 필요
예산 시나리오: 월 100,000페이지 이커머스 가격 모니터링
이커머스 팀이 경쟁사 사이트의 제품 페이지 100,000개를 모니터링하는 경우입니다.
| 구성 | 필요 크레딧 | 필요 플랜 | 월 비용 |
|---|---|---|---|
| 정적 HTML(1크레딧) | 100,000 | Freelance | $49 |
| JS 렌더링(5크레딧) | 500,000 | Startup | $99 |
| 프리미엄 프록시 + JS(25크레딧) | 2,500,000 | Business | $249 |
| 스텔스 프록시(75크레딧) | 7,500,000 | Business+ | $599 |
같은 작업이 월 $49에서 $599까지 차이 납니다. 이건 단순한 반올림 오차가 아니라, 설정에 따라 12배까지 벌어지는 비용 차이입니다.
"49달러라는 진입 가격은 스크래핑 API 시장에서 가장 오해를 부르는 숫자다." —
"JavaScript 렌더링이나 고급 기능을 사용하면 크레딧이 빠르게 소진되어, 소규모 프로젝트나 스크래핑량이 들쭉날쭉한 팀에게는 정당화하기 더 어려워진다." — Nick S, 매니저, 컴퓨터 소프트웨어,
그리고 사용하지 않은 크레딧은 .
ScrapingBee 비용은 경쟁사와 비교해 어떤가?

공정한 비교를 위해 중간급 플랜을 사용해 보겠습니다.
| 시나리오(1,000페이지당) | ScrapingBee ($99/100만) | ScraperAPI ($149/100만) | Scrapfly ($100/100만) |
|---|---|---|---|
| 정적 HTML | $0.10 | $0.15 | $0.10 |
| JS 렌더링 페이지 | $0.50 | $1.64 | $0.60 |
| 프리미엄 + JS | $2.48 | $3.73 | $3.00 |
| 스텔스/울트라 프리미엄 + JS | $7.43 | $11.18 | 해당 없음 |
정적 페이지나 JS 렌더링 페이지에서는 ScrapingBee가 대체로 가장 저렴하거나 최소한 비슷한 수준입니다. 는 꾸준히 가장 비싼 편이며, JS 렌더링 비용도 ScrapingBee와 Scrapfly의 +5 크레딧보다 +10 크레딧으로 더 큽니다. 하지만 의 독립 테스트를 보면 실제 사이트 복잡도를 반영했을 때 결과가 달라집니다.
| 서비스 | 평균 1,000요청당 비용 | 성공률 | 평균 응답 시간 |
|---|---|---|---|
| Scrape.do | $0.80 | 98.19% | 4.7초 |
| ScrapingBee | $3.90 | 92.69% | 11.7초 |
| Scrapfly | $4.11 | — | — |
| ZenRows | $4.48 | 92.64% | 10.0초 |
| ScraperAPI | $8.49 | 92.70% | 15.7초 |
Thunderbit의 크레딧 모델: 전혀 다른 접근
은 훨씬 단순한 가격 모델을 사용합니다. 1 크레딧 = 출력 행 1개이며, JS 렌더링, 프록시 종류, 타깃 도메인에 따른 배수는 없습니다. 하위 페이지 스크래핑은 행당 2크레딧입니다.
| 플랜 | 월 요금 | 크레딧 | 행당 비용 |
|---|---|---|---|
| Free | $0 | 월 6페이지 | 무료 |
| Starter | $15 | 500 | $0.030 |
| Pro 1 | $38 | 3,000 | $0.013 |
| Pro 2 | $75 | 6,000 | $0.013 |
| Pro 3 | $125 | 10,000 | $0.013 |
| Pro 4 | $249 | 20,000 | $0.012 |
JS가 많은 이커머스 사이트에서 상품 목록 10,000개를 스크래핑하는 Thunderbit 사용자는, 해당 사이트가 JavaScript 렌더링이나 프리미엄 프록시, 봇 차단 우회 기능을 요구하더라도 월 $125만 냅니다. ScrapingBee에서는 같은 작업이 설정에 따라 $49에서 $599까지 갈 수 있습니다. 예산 예측 가능성은 실제로 중요한 문제입니다.
CSS 선택자 vs. AI 추출: 꼭 알아야 할 유지보수 비용
대부분의 ScrapingBee 리뷰는 이 부분을 아예 건너뜁니다. 하지만 몇 달, 몇 년에 걸쳐 대규모로 스크래핑할 계획이라면 아마 가장 중요한 요소일 수 있습니다.
ScrapingBee는 HTML에서 데이터를 추출할 때 CSS/XPath 선택자를 사용합니다. JSON 객체로 추출 규칙을 정의하면 ScrapingBee가 일치하는 데이터를 반환합니다. 처음에는 잘 작동합니다. 문제는 그다음입니다.
선택자 깨짐 문제
대상 웹사이트가 레이아웃을 바꾸면 — 클래스명, DOM 구조, 프레임워크 버전이 달라지면 — CSS 선택자가 깨집니다. 2,500개 이상의 활성 작업을 운영하는 성숙한 스크래핑 시스템에서 연구 결과 이 나타났고, 이는 추출기가 제대로 작동하도록 유지하는 데만 주당 30~35건의 수정이 필요하다는 뜻입니다. 50개 사이트를 스크래핑하는 조직이라면 연간 유지보수 시간은 850~1,300시간에 달하며, 완전 원가 기준 엔지니어 인건비로 $64,000~$156,000이 듭니다.
팀들은 이 비용을 꾸준히 과소평가합니다. 초기 예상은 보통 월 10~15시간의 유지보수이지만, 실제는 월 40~90시간이 되는 경우가 많습니다. 선택자가 깨졌지만 에러 없이 빈 데이터만 계속 반환하는 단일한 조용한 실패만으로도, 매출 손실과 순위 복구, 직원 시간 손실을 합쳐 약 $38,000~$57,000이 날 수 있습니다.
주요 원인으로는 프레임워크 업데이트 중 CSS 클래스명 변경, 대상 주변에 새로운 컨테이너 삽입, React/Vue/Angular 버전 업그레이드로 인한 DOM 재구성, 동적 클래스명을 쓰는 A/B 테스트, 그리고 스크래핑 방지용 난독화가 있습니다.
AI 기반 추출은 유지보수를 60~80% 줄인다
2025년 DataRobot 연구에 따르면 AI 기반 스크래퍼는 사이트 리디자인 이후 기존 셀렉터 기반 스크래퍼보다 든다고 합니다. 시간 배분도 사실상 뒤집힙니다.
| 지표 | 기존 방식(CSS 선택자) | AI 기반 방식 |
|---|---|---|
| 리디자인 이후 유지보수 | 기준선 | 70% 감소 |
| 시간 비중(설정 : 유지보수) | 20% : 80% | 데이터 기준 5% : 95% |
| 전체 유지보수 감소 | 기준선 | 60~80% 감소 |
| JS 많은 페이지에서 속도 | 기준선 | 30~40% 더 빠름 |
설정 시간: 선택자 작성 vs. AI 추천 필드
ScrapingBee 설정: 페이지 소스 확인 → CSS 선택자 식별 → JSON으로 추출 규칙 작성 → 테스트 및 디버깅 → 페이지 변형에 대한 예외 처리 → 깨짐 모니터링 → 사이트 업데이트 시 깨진 선택자 수정
Thunderbit 설정: Chrome에서 페이지 열기 → "AI Suggest Fields" 클릭 → AI가 페이지를 읽고 적절한 데이터 유형과 함께 컬럼 제안 → "Scrape" 클릭. 선택자 작성도, 소스 코드 검토도 필요 없습니다. Thunderbit의 AI는 여러 파운데이션 모델(ChatGPT, Gemini, Claude, DeepSeek R1)을 활용해 사람처럼 웹페이지를 시각적으로 읽습니다.
Thunderbit의 는 여기에 또 하나의 층을 더합니다. 각 컬럼마다 날짜 포맷 변경, 텍스트 번역, 상품 분류, 이름 분리, 전화번호 정규화 같은 변환 작업을 수행하는 맞춤형 AI 지시문을 붙일 수 있습니다. ScrapingBee 사용자라면 별도로 만들어야 하는 후처리 단계를 없애 줍니다.
구조화된 출력: 원시 HTML vs. 바로 쓸 수 있는 행
| 항목 | ScrapingBee(셀렉터 기반) | Thunderbit(AI 기반) |
|---|---|---|
| 기본 출력 | 원시 HTML | 타입이 지정된 구조화 행 |
| 구조화 추출 | CSS/XPath 규칙 작성 또는 AI 추가 기능(+5 크레딧) 필요 | AI가 필드를 자동 감지 |
| 지원 데이터 유형 | 텍스트(HTML 파싱 필요) | 텍스트, 숫자, 날짜, URL, 이메일, 전화번호, 이미지 |
| 레이아웃 변경 대응력 | ⚠️ 수동 선택자 수정 필요 | ✅ AI가 매번 페이지를 새로 읽음 |
| 필요한 기술 수준 | Python/cURL, CSS 선택자, HTML 이해 | 없음 — 2클릭 워크플로의 Chrome 확장 프로그램 |
| 장기 유지보수 | 지속적 필요(주당 1~2% 깨짐률) | 거의 없음(AI가 자동 적응) |
ScrapingBee는 선택자 유지보수 문제를 일부 완화하기 위해 AI 추출 기능(ai_query, ai_extract_rules)을 추가했습니다. 하지만 이 기능은 기본 비용 위에 요청당 +5 크레딧이 더 붙고, 도구 자체는 여전히 시각적 인터페이스가 없는 API 우선 구조입니다.
비개발자 입장에서 본 ScrapingBee 사용성: 솔직한 체크
ScrapingBee는 비기술 사용자를 위해 만들어진 도구가 아닙니다. API입니다. 코드를 작성해서 사용해야 합니다. 마케팅 매니저나 세일즈 오퍼레이션 담당자가 이 글을 보고 있다면, 사실 여기서 결론은 거의 끝난 셈입니다.
비기술 사용자가 ScrapingBee를 쓸 때 실제로 겪는 과정은 이렇습니다.
- Python, cURL 또는 다른 언어로 API 호출 작성
render_js=true,premium_proxy=true,country_code=us같은 HTTP 파라미터 이해- BeautifulSoup 같은 라이브러리로 원시 HTML 응답 파싱
- 특정 데이터 필드를 추출하기 위한 CSS 선택자 작성
- 맞춤형 크롤링 로직을 작성해 페이지네이션 처리(ScrapingBee는 단일 페이지 요청만 처리)
- 추출한 데이터를 정리하고 구조화하고 저장하는 데이터 파이프라인 구축
드래그 앤 드롭 빌더도, 클릭형 인터페이스도, 내가 무엇을 스크래핑하는지 미리 보여 주는 시각적 미리보기 기능도 없습니다.
"학습 곡선이 있습니다. 문서도 덩치가 커서 읽는 데 하루에서 일주일은 걸립니다." — Arvind K, Proprietor, Financial Services,
"시스템이 꽤 특이해서 코드와 구조를 익히는 데 시간이 꽤 걸립니다." —
개발자들은 이런 방식을 좋아합니다. 한 리뷰어는 "완전히 API 기반이라 아주 현대적이고 세련됐으며, 그냥 잘 작동한다"고 했습니다. 하지만 개발자가 API를 평가할 때의 "사용성"과, 코딩 없이 리드 리스트를 만들려는 사람이 느끼는 "사용성"은 전혀 다른 개념입니다.
노코드 대안이 더 적합한 경우
은 완전히 다른 경험을 제공합니다.
- 확장 프로그램이 설치된 상태로 Chrome에서 웹페이지 열기
- "AI Suggest Fields" 클릭 — AI가 페이지를 스캔해 적절한 데이터 유형과 함께 컬럼(Product Name, Price, Rating, URL 등)을 제안
- 검토 및 수정 — 컬럼 추가/삭제/이름 변경, 변환용 Field AI Prompt 추가
- "Scrape" 클릭 — 구조화된 행으로 데이터 추출
- 내보내기 — Google Sheets, Airtable, Notion, Excel, CSV, JSON으로 원클릭 내보내기(모든 내보내기 무료)
API 호출도, 선택자도, 코드도 필요 없습니다. Thunderbit은 2026년 4월 기준 를 지원합니다.
일반적인 사이트라면 Thunderbit은 도 제공합니다. Amazon, Zillow, Shopify, LinkedIn, Google Maps, Instagram, eBay, Apollo 등용으로 이미 만들어져 유지관리되는 템플릿이 있어서, AI가 필드를 제안하기를 기다릴 필요도 없습니다. 바로 실행하면 됩니다.
또한 Thunderbit은 별도 플랜 없이 쓸 수 있는 도 몇 가지 제공합니다. 이메일 추출기, 전화번호 추출기, 이미지 추출기가 포함되어 있어 빠른 데이터 수집이 필요한 세일즈·마케팅 팀에 유용합니다.
의사결정 프레임워크: 누가 무엇을 써야 하나?
| 당신이… | 가장 적합한 선택 |
|---|---|
| API와 HTML 파싱에 익숙한 개발자 | ScrapingBee 또는 ScraperAPI |
| 셀렉터 작업 없이 구조화된 데이터를 원하는 기술 사용자 | Thunderbit API(Extract 엔드포인트) |
| 코딩이 전혀 없는 비즈니스 사용자(세일즈, 마케팅, 이커머스 운영) | Thunderbit Chrome Extension |
| DevOps 없이 예약 모니터링이 필요한 팀 | Thunderbit Scheduled Scraper(자연어 스케줄링) |
| 깨끗한 마크다운이 필요한 LLM/RAG 파이프라인 구축자 | Thunderbit Distill API 또는 Firecrawl |
| 예산 예측 가능성이 중요하고 크레딧 배수를 원치 않는 사용자 | Thunderbit(1 크레딧 = 1 행) |
스크래핑 이후: 내 데이터는 실제로 어디로 가나?
스크래핑은 일의 절반일 뿐입니다. 나머지 절반, 즉 그 데이터를 실제로 쓸 수 있는 곳으로 옮기는 단계에서 대부분의 ScrapingBee 리뷰는 말을 아낍니다.
ScrapingBee: 원시 HTML 출력, 파이프라인은 직접 구축
ScrapingBee는 기본적으로 원시 HTML을 반환합니다. 이후에는 직접 해야 합니다.
- BeautifulSoup 또는 lxml로 HTML 파싱
- 내비게이션, 푸터, 스크립트, 스타일 제거(를 차지)
- 특정 데이터 필드 추출
- 구조화된 형식으로 변환
- 페이지네이션 및 오류 상태 처리
- 데이터 저장 및 배포
"ScrapingBee는 원시 HTML을 반환합니다. AI 에이전트에는 깨끗한 마크다운, 의미 기반 검색, 웹훅이 필요합니다." —
ScrapingBee도 return_page_markdown=true, return_page_text=true 옵션과 Google Search API의 구조화 JSON을 제공합니다. 하지만 기본 워크플로와 범용 스크래핑 경험은 결국 사용자가 직접 처리해야 하는 원시 HTML입니다.
보통은 BeautifulSoup/lxml 같은 파싱 도구, Pandas 데이터 정리, 예약 실행용 cron/Airflow, 다중 페이지 스크래핑용 맞춤 크롤 로직, 그리고 까지 추가로 필요합니다. "스크래핑했다"와 "실제로 쓸 수 있다" 사이에 들어가는 엔지니어링이 꽤 많습니다.
Thunderbit: 내장 내보내기가 포함된 구조화 출력
Thunderbit은 텍스트, 숫자, 날짜, URL, 이메일, 전화번호, 이미지 등으로 타입이 정의된 구조화 행을 반환하며, 바로 내보낼 수 있습니다. 모든 플랜에서 내보내기는 무료입니다.
| 내보내기 대상 | 비용 |
|---|---|
| Excel (.xlsx) | 무료 |
| Google Sheets | 무료(직접 연동) |
| Airtable | 무료(직접 연동) |
| Notion | 무료(직접 연동) |
| CSV | 무료 |
| JSON | 무료 |
이미 Google Sheets나 Airtable을 CRM 또는 운영 허브로 쓰는 팀이라면, 이 기능만으로도 엔지니어링 한 층을 통째로 없앨 수 있습니다. Notion이나 Airtable로 내보낼 때 이미지는 이미지 라이브러리에 업로드되어 인라인으로 확인할 수 있는데, 작아 보이지만 실제 사용성에서는 꽤 중요한 디테일입니다.
ScrapingBee의 연동 생태계
ScrapingBee는 (8,000개 이상 앱), (3,000개 이상 앱), n8n, Microsoft Power Automate 같은 서드파티 연동을 지원합니다. 원시 HTML과 목적지 도구 사이를 연결해 주지만, 그만큼 비용과 복잡성, 그리고 또 하나의 실패 지점이 늘어납니다.
개발자를 위한 Thunderbit Open API
프로그래밍 방식의 파이프라인을 원하는 독자를 위해 Thunderbit은 두 개의 핵심 엔드포인트를 제공하는 Open API를 제공합니다.
- Distill 엔드포인트 — 페이지를 깨끗한 Markdown으로 변환, LLM/RAG 파이프라인에 적합(호출당 1크레딧)
- Extract 엔드포인트 — 사용자가 정의한 스키마에 맞는 구조화 JSON 반환(호출당 20크레딧)
- 배치 처리 — 요청당 최대 100개 URL
즉 Thunderbit은 같은 AI 엔진 위에서 노코드 사용자(Chrome Extension)와 개발자(Open API)를 모두 지원합니다. "스크래핑이 되느냐"만 묻지 말고, "데이터가 어디로 가느냐"도 함께 물어봐야 합니다.
2026년 신뢰성 점검: ScrapingBee는 운영 환경에서도 버틸까?
예전 Reddit 스레드(2021~2023)에는 ScrapingBee 신뢰성에 대한 불만이 있습니다. 그 불만이 2026년에도 여전히 유효할까요? 저는 6개의 독립 벤치마크 데이터를 모았습니다. 결과는 엇갈렸고, 때로는 서로 모순되기도 했습니다.
Scrapeway 격주 벤치마크(2026년 4월)
전체 성공률: — 테스트한 9개 서비스 중 7위였습니다.
| 웹사이트 | 성공률 |
|---|---|
| Amazon | 48% |
| 41% | |
| Indeed | 38% |
| Etsy | 21% |
| Booking | 17% |
| Realtor | 0% |
| StockX | 0% |
| Twitter/X | 0% |
| Zillow | 0% |
| Walmart | 0% |
| 0% |
Scrapingdog 1:1 비교 테스트(2025)
| 웹사이트 | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100% | 100% | 100% |
| Glassdoor | 0% | 100% | 100% |
| eBay | 100% | 100% | 100% |
| Walmart | 40% | 100% | 100% |
| 90% | 100% | 80% |
Proxyway 벤치마크(2025년 12월)
- 초당 2요청에서
- 초당 10요청에서 72.98% 성공 — 부하가 걸리면 12포인트 하락
- 평균 응답 시간 25.46초 — 벤치마크 그룹 중 가장 느림
Scrape.do 벤치마크(2025~2026)
- 개별 사이트에서는 강세: Amazon 99.11%, Indeed 99.29%, GitHub 100%, X/Twitter 99.6%
- Capterra에서는 약세: 성공률 59%, 응답 시간 36초
패턴 정리
데이터를 보면 패턴이 분명합니다.
- ScrapingBee는 일반적이고 중간 수준으로 보호된 사이트에서 잘 작동합니다. Amazon, eBay, GitHub, Indeed는 꾸준히 90~100% 성공률을 보입니다.
- 강하게 보호된 사이트에서는 완전히 실패합니다. LinkedIn, Zillow, Realtor.com, StockX, Twitter에서는 여러 벤치마크에서 일관되게 0%였습니다.
- 부하가 높아지면 성능이 크게 떨어집니다. 초당 2요청에서 84%였던 수치가 초당 10요청에서는 73%로 내려갑니다.
- 벤치마크 결과는 방법론에 따라 크게 달라집니다. 사이트 구성이 넓은 Scrapeway에서는 33.3%였고, 비교적 무난한 대상을 쓴 Scrape.do에서는 92.69%였습니다.
ScrapingBee의 (리뷰 137개)는 분명 좋은 신호입니다. 다만 초기 설정이 쉽다는 높은 평점이 대규모 운영 환경에서의 장기 신뢰성까지 보장해 주는 것은 아닙니다. 실제로 다른 도구로 옮겨가는 사용자는 처음 설정의 어려움보다, 시간이 갈수록 증가하는 실패율과 비용 상승을 더 자주 언급합니다.
"매우 긍정적입니다. ScrapingBee는 안정적이고 예측 가능하며 운영 환경에 쉽게 통합할 수 있었습니다." — 검증된 리뷰어, CEO,
ScrapingBee는 "일관되지 않은 신뢰성"을 보였고, 특히 "Glassdoor에서 0% 성공률"과 ""를 기록했습니다.
AI 기반 스크래핑은 신뢰성을 다르게 처리한다
Thunderbit의 AI는 렌더링된 페이지를 실시간으로 읽고, 매 세션마다 봇 차단 대응과 레이아웃 변화에 맞춰 적응합니다. 신뢰성 문제를 다루는 두 가지 모드가 있습니다.
- Cloud scraping — Thunderbit 클라우드 서버에서 실행되며 한 번에 최대 50페이지를 처리, Amazon, Zillow, Shopify 같은 대규모 공개 사이트 작업에 적합
- Browser scraping — 사용자의 Chrome 브라우저에서 실행되며, 사용자가 이미 로그인한 세션을 활용합니다. LinkedIn이나 비공개 대시보드, SaaS 플랫폼처럼 인증 뒤 콘텐츠가 있는 사이트에 이상적입니다. ScrapingBee 같은 API 기반 도구는 이 영역에 접근할 수 없습니다.
Thunderbit은 또한 자주 쓰는 사이트용 을 제공하며, 구조가 바뀌어도 계속 동작하도록 미리 구축·유지됩니다. ScrapingBee가 0% 성공률을 보이는 사이트(LinkedIn, Zillow)에서는 Thunderbit의 브라우저 스크래핑 모드가, 로그인한 사용자 세션을 활용한다는 점에서 전혀 다른 접근입니다.
ScrapingBee vs. 주요 대안: 나란히 비교
| 항목 | ScrapingBee | Thunderbit | ScraperAPI | Scrapfly |
|---|---|---|---|---|
| 유형 | API 전용 | Chrome Extension + API | API 전용 | API 전용 |
| 시작 가격 | $49/월 | 무료($0) | $49/월 | $30/월 |
| 크레딧 모델 | 배수(1×~75×) | 1 크레딧 = 1 행(배수 없음) | 배수(1×~75×) | 배수(1×~30×) |
| AI 추출 | 있음(+5 크레딧/요청) | 내장(AI Suggest Fields) | 네이티브 AI 없음 | 있음 |
| 노코드 옵션 | 없음(API 전용) | 있음(Chrome Extension) | 없음(API 전용) | 없음(API 전용) |
| 구조화 출력 | CSS 규칙 또는 AI 추가 기능 필요 | 기본 제공(타입 지정 컬럼) | 특정 사이트용 구조화 엔드포인트 | 제각각 |
| 내보내기 대상 | 원시 HTML/JSON(직접 구축) | Excel, Sheets, Airtable, Notion, CSV, JSON(모두 무료) | 원시 HTML/JSON | 원시 HTML/JSON |
| 하위 페이지 스크래핑 | 수동(크롤 로직 직접 작성) | 내장(2크레딧/행) | 수동 | 수동 |
| 예약 스크래핑 | CLI 전용(대시보드 스케줄러 없음) | 내장(자연어) | 내장 아님 | 내장 아님 |
| 무료 티어 | 1,000 크레딧 체험 | 월 6페이지(영구) | 5,000 크레딧(7일 체험) | 1,000 크레딧 |
| 기본 JS 렌더링 | 켜짐(비용 5배) | 포함(추가 비용 없음) | 꺼짐 | 꺼짐 |
| 학습 곡선 | 높음(API + 선택자) | 낮음(2클릭 워크플로) | 높음(API + 선택자) | 높음(API) |
| 가장 적합한 경우 | 프록시 제어를 원하는 개발자 | 비즈니스 사용자 + 개발자 | 개발자 + 구조화 엔드포인트 | ASP 우회를 원하는 개발자 |
| Capterra 평점 | 4.9/5(137개 리뷰) | — | 4.6/5(62개 리뷰) | 4.9/5(221개 리뷰) |
ScrapingBee vs. Thunderbit: 핵심 차이
가장 큰 차이는 결국 아키텍처와 대상 사용자입니다.
- API 전용 vs. Chrome Extension + API: ScrapingBee는 모든 상호작용에 코드가 필요합니다. Thunderbit은 노코드 사용자를 위한 과 개발자를 위한 Open API를 함께 제공합니다. 같은 AI 엔진, 두 개의 인터페이스입니다.
- 셀렉터 기반 vs. AI 기반 추출: ScrapingBee는 CSS/XPath 선택자를 직접 작성하고 유지해야 합니다. Thunderbit의 AI는 필드를 자동 추천하고, 사이트가 바뀌면 이에 맞춰 적응합니다.
- 원시 HTML 출력 vs. 무료 내보내기가 가능한 구조화 행: ScrapingBee는 파싱이 필요한 HTML을 반환합니다. Thunderbit은 타입과 라벨이 붙은 행을 반환하며 가 가능합니다.
- 하위 페이지 스크래핑: Thunderbit은 AI가 각 상세 페이지를 방문해 메인 테이블을 보강합니다. 이 기능이 기본 내장되어 있고, 별도의 크롤 로직이 필요 없습니다. ScrapingBee는 이를 직접 작성해야 합니다.
- 즉시 사용 가능한 템플릿: Thunderbit은 Amazon, Zillow, Shopify, LinkedIn, Google Maps, eBay 같은 인기 사이트용 템플릿을 바로 쓸 수 있게 제공합니다. ScrapingBee는 Amazon과 Walmart용 전용 API가 있지만, 사용하려면 여전히 코드를 작성해야 합니다.
주목할 만한 다른 대안들
- — 독립 테스트 기준 1,000요청당 $0.80으로 가장 저렴하고 성공률 98.19%; 월 $29부터 시작
- Apify — 액터 기반 플랫폼, G2 리뷰 415개 이상(4.7/5)지만 가장 큰 불만은 "요금제 문제"
- — AI/LLM 네이티브, 원시 HTML보다 67% 적은 토큰을 쓰는 마크다운 반환; 오픈소스 코어; 월 $16부터
- — 7,200만+ IP를 보유한 엔터프라이즈급, 월 $499부터; 정액 요금
- ZenRows — 5,500만 residential IP, Amazon/Walmart/Zillow용 사전 구축 스크래퍼 제공, 월 $69부터
우리 팀에 맞는 스크래핑 도구는?
시나리오별 추천은 다음과 같습니다.
- 커스텀 스크래핑 파이프라인을 만들고 세밀한 프록시 제어가 필요한 개발자라면 → ScrapingBee 또는 ScraperAPI. 세부 HTTP 파라미터, 프록시 유형 선택, 렌더링 제어를 모두 얻을 수 있습니다. 다만 크레딧 배수 비용은 감안해야 합니다.
- 코딩 없이 웹사이트에서 리드가 필요한 세일즈/마케팅 팀이라면 → . 구조화 데이터까지 2클릭, Google Sheets까지 1클릭. API도, 선택자도, 파싱도 없습니다.
- 인기 사이트에서 구조화 데이터를 빠르게 얻고 싶다면 → Thunderbit Instant Templates. Amazon, Zillow, Shopify, LinkedIn 등용으로 미리 만들어져 있고 유지관리도 됩니다. AI 설정조차 필요 없습니다.
- DevOps 없이 일정에 맞춰 가격이나 재고를 모니터링해야 한다면 → Thunderbit Scheduled Scraper. "매주 월요일 오전 9시"처럼 평범한 문장으로 간격을 설명하면 알아서 실행합니다.
- LLM/RAG 파이프라인을 구축하고 대규모로 깨끗한 Markdown이 필요하다면 → Thunderbit Distill API 또는 Firecrawl. 둘 다 AI 소비에 최적화된 마크다운을 반환합니다.
- 예산 예측 가능성이 중요하고 크레딧 배수를 원치 않는다면 → Thunderbit. JS 렌더링이나 프록시 종류와 무관하게 1 크레딧 = 1 행입니다.
총소유비용은 API 가격만으로 끝나지 않습니다. 설정 시간 + 유지보수 시간 + 파싱 엔지니어링 + 데이터 내보내기 워크플로까지 포함해야 합니다. ScrapingBee의 표시 가격은 경쟁력 있습니다. 하지만 전체 비용 그림은 그렇지 않습니다.
이 ScrapingBee 리뷰의 핵심 요약
꼭 기억할 만한 다섯 가지를 정리하면 다음과 같습니다.
- 크레딧 비용은 규모가 커질수록 빠르게 배수로 늘어납니다. $49 시작가도 JS 렌더링과 프리미엄 프록시가 필요해지면 $599 이상으로 뛸 수 있습니다. Thunderbit의 행당 1크레딧 고정 모델은 이런 불확실성을 없애 줍니다.
- CSS 선택자는 지속적인 유지보수 부담이 있지만 AI 추출은 이를 피합니다. AI 기반 도구는 데 도움이 되며, 사이트가 바뀌어도 선택자가 깨질 일이 없습니다.
- 비개발자에게 ScrapingBee는 진입 장벽이 높습니다. 코딩, HTML 확인, 선택자 작성이 필요한 API 전용 도구입니다. 비즈니스 사용자는 노코드 대안을 보는 편이 낫습니다.
- 데이터 내보내기에는 별도 엔지니어링이 필요합니다. ScrapingBee는 원시 HTML을 반환하고, 파이프라인은 직접 만들어야 합니다. Thunderbit은 구조화 데이터를 으로 무료 내보내기할 수 있습니다.
- 일부 사이트에서는 안정적이지만, 다른 사이트에서는 일관성이 떨어집니다. Amazon과 eBay에서는 잘 작동하지만, LinkedIn·Zillow 같은 보호가 강한 대상에서는 0% 성공률이 나옵니다.
ScrapingBee는 프록시 관리형 HTTP 접근과 세밀한 제어를 원하는 개발자에게 여전히 유능한 도구입니다. 하지만 2026년의 웹 스크래핑 시장은 AI 기반 노코드 도구 쪽으로 이동하고 있고, 는 바로 그 흐름에 맞춰 설계되었습니다. 무료 티어(월 6페이지 무료, 또는 무료 체험으로 더 많이)를 사용해 직접 차이를 확인해 보세요.
FAQ
2026년에 ScrapingBee는 쓸 만한가요?
기술 수준과 규모에 따라 다릅니다. 중간 정도 물량의 정적 페이지를 스크래핑하는 개발자라면, ScrapingBee는 문서가 잘 되어 있고 지원도 괜찮은 solid API이며 도 보유하고 있습니다. 하지만 비즈니스 사용자, 대량 스크래핑, 또는 코딩 없이 구조화 데이터가 필요한 팀이라면 Thunderbit 같은 AI 기반 대안이 더 높은 가치를 주고 총소유비용도 훨씬 낮습니다.
ScrapingBee는 코딩 없이 사용할 수 있나요?
아니요. ScrapingBee는 API 전용 도구라 Python, cURL 같은 코드 작성과 HTTP 파라미터 이해가 필요합니다. 스크래핑을 만들 수 있는 시각적 인터페이스는 없습니다. 기술이 없는 사용자는 처럼 코드 한 줄 없이 스크래핑하고 내보낼 수 있는 노코드 옵션을 고려하는 것이 좋습니다.
ScrapingBee의 페이지당 실제 비용은 얼마인가요?
활성화한 기능에 따라 달라집니다. 정적 HTML 페이지는 1크레딧, JS 렌더링 페이지(기본값)는 입니다. 프리미엄 프록시 + JS 페이지는 25크레딧, 스텔스 프록시 페이지는 75크레딧이 듭니다. AI 추출은 여기에 +5 크레딧이 추가됩니다. Freelance 플랜($49/25만 크레딧) 기준으로 보면 정적 페이지 1,000개당 $0.20, 스텔스 프록시 페이지 1,000개당 $14.70 정도입니다. 전체 세부 계산은 위의 비용 표를 참고하세요.
2026년 기준 최고의 ScrapingBee 대안은 무엇인가요?
주요 대안으로는 (AI 기반, 노코드 Chrome Extension + API, 1 크레딧 = 1 행), (특정 사이트용 구조화 엔드포인트를 갖춘 개발자 API), (강력한 봇 차단 우회 기능을 갖춘 개발자 API), (독립 테스트에서 가장 저렴한 요청당 비용), (AI/LLM 네이티브, 깨끗한 마크다운 반환)가 있습니다. 각각 강점이 다릅니다. Thunderbit은 비즈니스 사용자와 비용 예측성에, ScraperAPI와 Scrapfly는 개발자용 프록시 제어에, Firecrawl은 LLM 파이프라인에 적합합니다.
ScrapingBee는 JavaScript가 많은 웹사이트도 스크래핑할 수 있나요?
가능합니다. 하지만 순환 프록시를 쓰면 기본 크레딧의 5배, 프리미엄 프록시를 쓰면 25배가 듭니다. JavaScript 렌더링은 되어 있으므로, 직접 끄지 않는 한 이미 5배 요금을 내고 있는 셈입니다. Thunderbit은 크레딧 배수 없이 JS 렌더링을 자동 처리하며, 페이지 구조와 관계없이 1행당 1크레딧만 사용합니다.
더 알아보기