

웹은 예전의 웹이 아니에요. 요즘 사이트는 거의 다 JavaScript로 돌아가고, 콘텐츠도 그때그때 불러와요. 무한 스크롤, 팝업, 몇 번을 눌러야 속을 보여주는 대시보드를 떠올려 보세요. 실제로 지금 전체 웹사이트의 무려 98.7%가 JavaScript를 쓰니, 정적 HTML만 읽던 옛 도구로는 값진 데이터를 한참 놓쳐요. 최신 이커머스에서 가격을 긁거나 인터랙티브 지도에서 매물을 빼내려 했던 분이라면 그 답답함을 잘 아실 거예요. 정작 원하는 데이터가 소스 코드엔 없으니까요.
이럴 때 필요한 게 Selenium 스크래핑이에요. 자동화 도구를 오래 만들고 적잖은 사이트를 긁어 온 입장에서, 최신 동적 데이터를 다뤄야 하는 사람에게 Selenium 숙련은 일종의 슈퍼파워예요. 이 실습형 튜토리얼에선 환경 설정부터 자동화까지 핵심 단계를 풀고, 바로 내보낼 수 있는 구조화 데이터를 만들려고 Selenium과 Thunderbit를 어떻게 같이 쓰는지도 보여드릴게요. 분석가든, 세일즈 담당자든, Python이 궁금한 분이든, 실용 기술에 더해 웃을 거리도 조금 챙겨 가실 거예요. XPath 선택자 디버깅이 사람을 단련시킨다는 건 다들 아시잖아요.
Selenium이란 무엇이고, 웹 스크래핑에 왜 사용할까요?
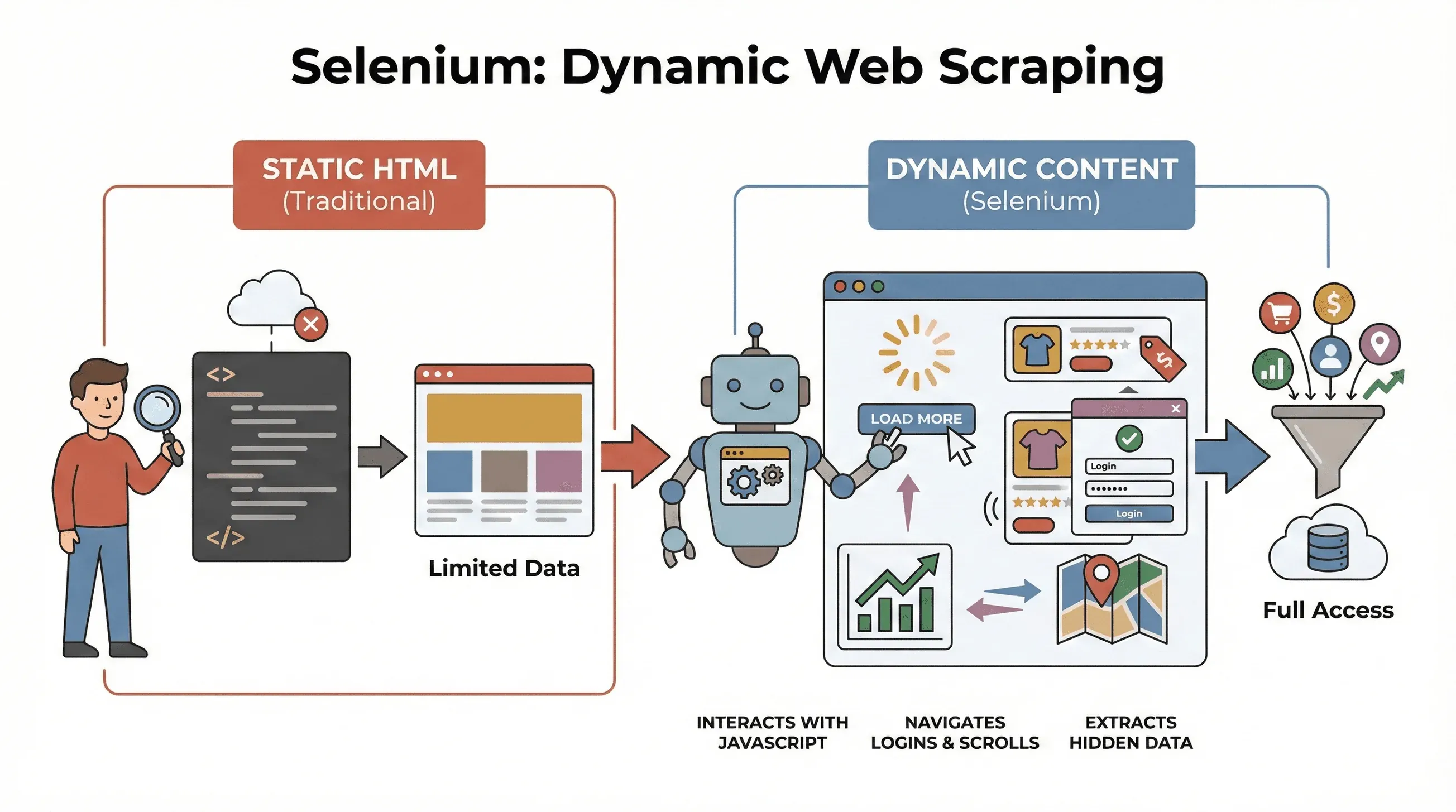 기본부터 볼게요. Selenium은 코드로 Chrome이나 Firefox 같은 실제 브라우저를 조종하게 해주는 오픈소스 프레임워크예요. 사람처럼 페이지를 열고, 버튼을 누르고, 폼을 채우고, 스크롤하고, JavaScript까지 실행하는 로봇이라고 보면 돼요. 중요한 건 요즘 사이트 대부분이 모든 데이터를 처음에 한 번에 보여주지 않는다는 점이에요. 페이지와 상호작용한 뒤에야 콘텐츠를 동적으로 불러오는 경우가 많거든요.
기본부터 볼게요. Selenium은 코드로 Chrome이나 Firefox 같은 실제 브라우저를 조종하게 해주는 오픈소스 프레임워크예요. 사람처럼 페이지를 열고, 버튼을 누르고, 폼을 채우고, 스크롤하고, JavaScript까지 실행하는 로봇이라고 보면 돼요. 중요한 건 요즘 사이트 대부분이 모든 데이터를 처음에 한 번에 보여주지 않는다는 점이에요. 페이지와 상호작용한 뒤에야 콘텐츠를 동적으로 불러오는 경우가 많거든요.
데이터 스크래핑이란 무엇이고, 2026년에는 어떻게 할까요 Get Started Free
왜 스크래핑에서 이게 중요할까요? BeautifulSoup이나 Scrapy 같은 전통 도구는 정적 HTML엔 아주 강하지만, 최초 로드 이후 JavaScript로 불러온 내용은 “볼” 수 없어요. 반면 Selenium은 페이지와 실시간으로 주고받을 수 있어서 이런 작업에 딱 맞아요.
- “더 보기”를 눌러야 나타나는 상품 목록 스크래핑
- 동적으로 갱신되는 가격이나 리뷰 가져오기
- 로그인 폼, 팝업, 무한 스크롤 탐색
- 대시보드, 지도, 그 밖의 인터랙티브 요소에서 데이터 추출
한마디로, 페이지가 완전히 로드된 뒤나 사용자의 동작 이후에야 나타나는 데이터를 긁어야 할 때 가장 먼저 떠오르는 도구가 Selenium이에요.
Python Selenium 웹 스크래핑의 핵심 단계
Selenium 스크래핑은 결국 핵심 세 단계로 정리돼요.
| 단계 | 하는 일 | 중요한 이유 |
|---|---|---|
| 1. 환경 설정 | Selenium, WebDriver, Python 라이브러리 설치 | 도구를 준비하고 설정 스트레스를 줄이기 위해 |
| 2. 요소 찾기 | ID, 클래스, XPath 등으로 원하는 데이터 찾기 | JavaScript 뒤에 숨은 정보도 정확히 집어내기 위해 |
| 3. 데이터 추출 및 저장 | 텍스트, 링크, 표를 가져와 CSV/Excel로 저장 | 웹 데이터를 실제로 활용할 수 있는 형태로 바꾸기 위해 |
이제 각 단계를 실용 예제와 함께 볼게요. 그대로 복사해 조금만 손본 뒤 친구들에게 자랑할 수도 있어요.
1단계: Python Selenium 환경 설정하기
가장 먼저 Selenium과 브라우저 드라이버(예: Chrome용 ChromeDriver)를 깔아야 해요. 다행히 이제는 예전보다 훨씬 쉬워졌어요.
Selenium 설치하기
터미널을 열고 아래 명령어를 실행하세요.
pip install selenium
WebDriver 준비하기
- Chrome: ChromeDriver를 받으세요. Chrome 버전과 맞는지 꼭 확인하세요.
- Firefox: GeckoDriver를 받으세요.
팁: Selenium 4.6 이상에선 Selenium Manager가 드라이버를 자동으로 받아줘서, 예전처럼 PATH 변수를 직접 만질 필요가 없을 수도 있어요. (문서)
첫 번째 Selenium 스크립트
Selenium으로 짜는 간단한 “Hello World”는 이런 모습이에요.
from selenium import webdriver
driver = webdriver.Chrome() # 또는 webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
문제 해결 팁:
- “driver not found” 오류가 뜨면 PATH를 확인하거나 Selenium Manager를 써보세요.
- 브라우저 버전과 드라이버 버전이 맞는지 확인하세요.
- GUI 없는 헤드리스 서버에서 돌린다면 아래 헤드리스 모드 팁을 참고하세요.
2단계: 웹 요소를 찾아 데이터 추출하기
이제 재미있는 부분이에요. 어떤 데이터를 원하는지 Selenium에게 알려주는 거죠. 웹사이트는 div, span, table 같은 다양한 요소로 짜여 있고, Selenium은 이를 찾는 여러 방법을 줘요.
자주 쓰는 요소 찾기 방법
By.ID: 고유 ID가 있는 요소 찾기By.CLASS_NAME: CSS 클래스 기준으로 요소 찾기By.XPATH: XPath 표현식 사용하기(아주 유연하지만 깨지기 쉬워요)By.CSS_SELECTOR: CSS 선택자 사용하기(복잡한 조건에 좋음)
예시는 이래요.
from selenium.webdriver.common.by import By
# ID로 찾기
price = driver.find_element(By.ID, "price").text
# XPath로 찾기
title = driver.find_element(By.XPATH, "//h1").text
# CSS 선택자로 모든 상품 이미지 찾기
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
팁: 늘 가장 단순하고 안정적인 선택자를 쓰세요. 우선순위는 ID > class > CSS > XPath예요. 그리고 데이터가 지연 로딩되는 페이지를 긁을 땐 명시적 대기를 쓰세요.
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
이러면 데이터가 잠깐 늦게 나타나도 스크립트가 바로 멈추지 않아요.
3단계: 데이터 추출하고 저장하기
요소를 찾았으면 이제 데이터를 가져와 쓸모 있는 곳에 저장할 차례예요.
텍스트, 링크, 표 추출하기
예를 들어 상품 표를 긁는다고 해볼게요.
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
Pandas로 CSV 저장하기
import pandas as pd
df = pd.DataFrame(data, columns=["Name", "Price", "Stock"])
df.to_csv("products.csv", index=False)
Excel로 저장할 수도 있고(df.to_excel("products.xlsx")), API로 Google Sheets에 바로 보낼 수도 있어요.
전체 예시: 상품 제목과 가격 스크래핑하기
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["Title", "Price"])
df.to_csv("products.csv", index=False)
Selenium vs. BeautifulSoup와 Scrapy: Selenium이 특별한 이유는?
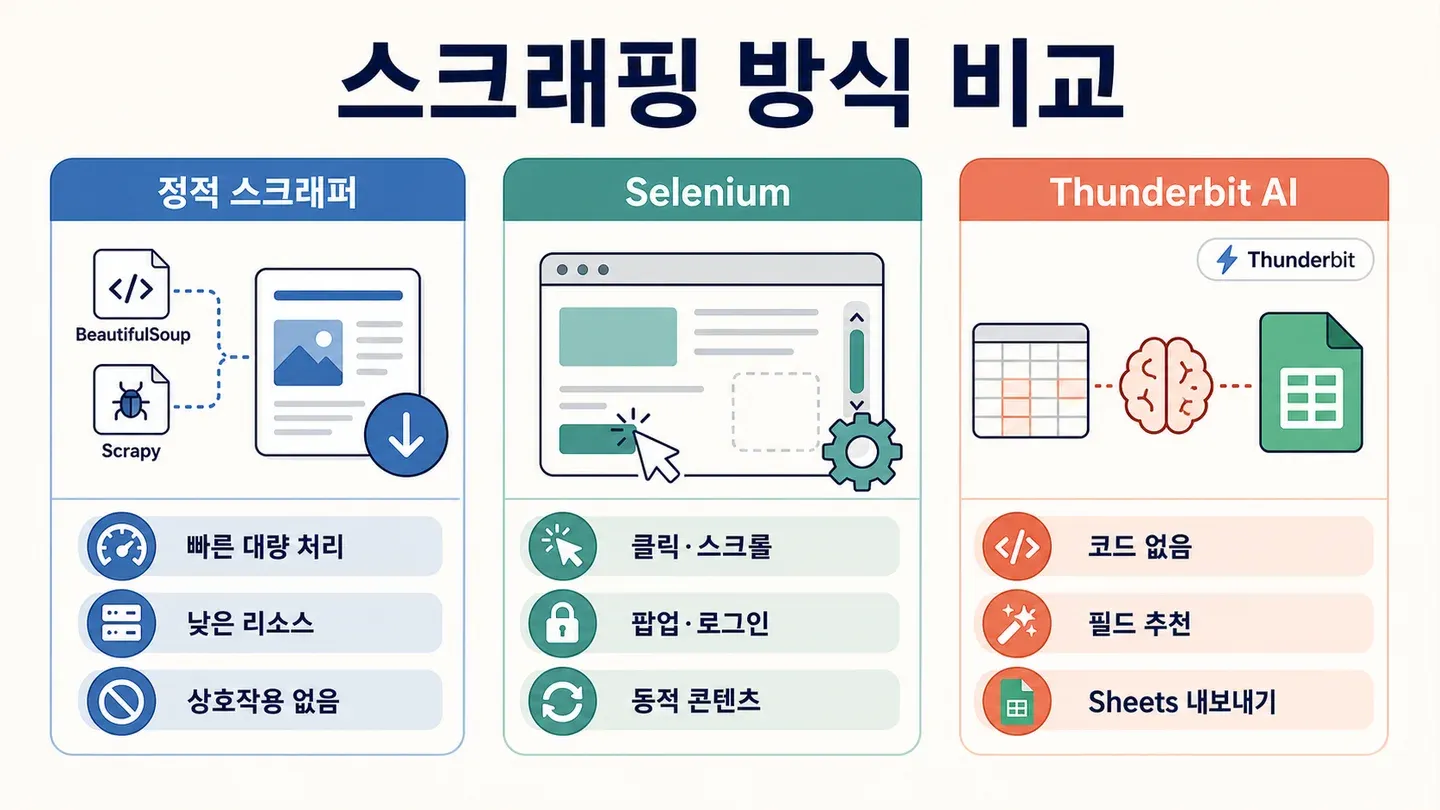 이제 논쟁을 정리해 볼게요. 언제 Selenium을 쓰고, 언제 BeautifulSoup이나 Scrapy가 나을까요? 간단히 비교하면 이래요.
이제 논쟁을 정리해 볼게요. 언제 Selenium을 쓰고, 언제 BeautifulSoup이나 Scrapy가 나을까요? 간단히 비교하면 이래요.
| 도구 | 가장 적합한 용도 | JavaScript 처리? | 속도 및 리소스 사용량 |
|---|---|---|---|
| Selenium | 동적/인터랙티브 사이트 | 예 | 느리고 메모리 사용량이 많음 |
| BeautifulSoup | 단순한 정적 HTML 스크래핑 | 아니오 | 매우 빠르고 가벼움 |
| Scrapy | 대량의 정적 사이트 크롤링 | 제한적* | 매우 빠름, 비동기, RAM 적게 사용 |
| Thunderbit | 노코드 비즈니스 스크래핑 | 예(AI) | 소규모/중간 규모 작업에 빠름 |
*Scrapy도 플러그인을 쓰면 일부 동적 콘텐츠를 다룰 수 있지만, 본래 강점은 아니에요 (ScrapingBee).
Selenium을 써야 할 때:
- 클릭, 스크롤, 로그인 뒤에야 데이터가 나타날 때
- 팝업, 무한 스크롤, 동적 대시보드와 상호작용해야 할 때
- 정적 스크래퍼로는 원하는 결과가 안 나올 때
BeautifulSoup/Scrapy를 써야 할 때:
- 데이터가 초기 HTML에 이미 들어 있을 때
- 수천 개 페이지를 빠르게 긁어야 할 때
- 리소스 사용을 최소화하고 싶을 때
코딩을 아예 건너뛰고 싶다면, Thunderbit으로 AI를 써서 동적 사이트도 긁을 수 있어요. “AI 필드 제안”만 누르고 Google Sheets, Notion, Airtable로 내보내면 돼요. 이건 아래에서 더 자세히 볼게요.
AI로 어떤 웹사이트든 스크래핑하는 방법 Get Started Free
Selenium과 Python으로 웹 스크래핑 작업 자동화하기
솔직히 새벽 2시에 스크래핑 스크립트를 직접 돌리러 일어나고 싶은 사람은 없어요. 다행히 Python의 스케줄링 도구나 운영체제 스케줄러(Linux/Mac의 cron, Windows의 작업 스케줄러)로 Selenium 작업을 자동화할 수 있어요.
schedule 라이브러리 사용하기
import schedule
import time
def job():
# 여기에 스크래핑 코드 작성
print("스크래핑 중...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
또는 Cron 사용하기(Linux/Mac)
매시간 돌리려면 crontab에 아래를 추가하세요.
0 * * * * python /path/to/your_script.py
자동화 팁:
- GUI 팝업을 피하려면 Selenium을 헤드리스 모드로 돌리세요(아래 참고).
- 오류를 기록하고, 문제가 생기면 알림을 보내도록 설정하세요.
- 리소스를 확보하려면 항상
driver.quit()으로 브라우저를 닫으세요.
효율 높이기: 더 빠르고 안정적인 Selenium 스크래핑 팁
Selenium은 강력하지만, 조심하지 않으면 느리고 리소스를 많이 잡아먹어요. 속도를 올리고 흔한 문제를 피하는 방법은 이래요.
1. 헤드리스 모드로 실행하기
Chrome 창이 열렸다 닫혔다 하는 걸 백 번씩 볼 필요는 없어요. 헤드리스 모드는 브라우저를 백그라운드에서 돌려요.
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. 이미지와 불필요한 콘텐츠 차단하기
텍스트만 긁는다면 이미지를 굳이 불러올 필요가 없어요. 로딩 속도를 높이려면 막으세요.
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. 효율적인 선택자 사용하기
- 복잡한 XPath보다 ID나 단순한 CSS 선택자를 먼저 쓰세요.
time.sleep()보다 명시적 대기(WebDriverWait)를 쓰세요.
4. 지연 시간을 랜덤하게 두기
사람처럼 둘러보는 것처럼 보이게 랜덤한 일시정지를 넣어 차단 가능성을 줄이세요.
import random, time
time.sleep(random.uniform(1, 3))
5. 사용자 에이전트와 IP 바꾸기(필요한 경우)
대량으로 긁는다면 사용자 에이전트 문자열을 바꾸고, 단순한 봇 차단을 피하려고 프록시 사용도 고려해 보세요.
6. 세션과 오류 관리하기
try/except블록으로 누락된 요소를 부드럽게 처리하세요.- 오류를 기록하고, 디버깅용 스크린샷도 남기세요.
더 많은 최적화 팁은 BrowserStack 가이드를 참고하세요.
고급: Selenium과 Thunderbit를 결합해 구조화된 데이터로 내보내기
여기서부터가 진짜 흥미로워져요. 특히 데이터 정리와 내보내기에 드는 시간을 아끼고 싶다면요.
Selenium으로 원시 데이터를 긁은 뒤 Thunderbit를 쓰면 이런 게 가능해요.
- 필드 자동 감지: Thunderbit의 AI가 긁은 페이지나 CSV를 읽고 열 이름을 제안해 줘요("AI 필드 제안").
- 하위 페이지 스크래핑: 상품 페이지처럼 URL 목록이 있다면, Thunderbit가 각 페이지를 방문해 표를 더 풍부하게 채워 줘요. 추가 코드가 필요 없어요.
- 데이터 보강: 데이터를 그 자리에서 번역, 분류, 분석할 수 있어요.
- 어디로든 내보내기: Google Sheets, Airtable, Notion, CSV, Excel로 한 번에 내보내요.
작업 흐름 예시:
- Selenium으로 상품 URL과 제목 목록을 긁어요.
- 데이터를 CSV로 내보내요.
- Thunderbit를 열고 CSV를 불러온 뒤 AI가 필드를 제안하게 해요.
- Thunderbit의 하위 페이지 스크래핑으로 각 상품 URL에서 이미지나 사양 같은 정보를 더 가져와요.
- 최종 구조화 데이터셋을 Sheets나 Notion으로 내보내요.
이 조합이면 몇 시간씩 걸리던 수작업 정리를 줄이고, 지저분한 데이터 대신 분석에 집중할 수 있어요. 더 알고 싶다면 Thunderbit의 Selenium 가이드를 확인해 보세요.
Thunderbit AI로 Selenium 데이터 내보내기
Selenium 웹 스크래핑을 위한 모범 사례와 문제 해결
웹 스크래핑은 낚시랑 비슷해요. 월척을 낚을 때도, 잡초에 걸릴 때도 있죠. 스크립트를 안정적이면서 윤리적으로 굴리는 방법은 이래요.
모범 사례
- robots.txt와 사이트 이용약관을 존중하세요: 스크래핑이 허용되는지 늘 확인하세요.
- 요청 속도를 조절하세요: 서버에 과부하를 주지 말고, 지연을 넣고 HTTP 429 오류도 주의하세요.
- 가능하면 API를 쓰세요: 데이터가 API로 공개돼 있다면 그게 더 안전하고 믿을 만해요.
- 공개 데이터만 긁으세요: 개인정보나 민감 정보는 피하고, 개인정보 보호법도 염두에 두세요.
- 팝업과 CAPTCHA를 처리하세요: Selenium으로 팝업은 닫을 수 있지만, CAPTCHA는 자동화가 어려우니 조심하세요.
- 사용자 에이전트와 지연 시간을 랜덤화하세요: 탐지와 차단을 피하는 데 도움이 돼요.
자주 발생하는 오류와 해결 방법
| 오류 | 의미 | 해결 방법 |
|---|---|---|
NoSuchElementException | 요소를 찾을 수 없음 | 선택자를 다시 확인하고, 대기를 사용하세요 |
| 타임아웃 오류 | 페이지나 요소 로딩이 너무 오래 걸림 | 대기 시간을 늘리고, 네트워크 속도를 확인하세요 |
| 드라이버/브라우저 불일치 | Selenium이 브라우저를 실행하지 못함 | 드라이버와 브라우저 버전을 업데이트하세요 |
| 세션 충돌 | 브라우저가 예기치 않게 종료됨 | 헤드리스 모드를 사용하고 리소스를 관리하세요 |
더 많은 문제 해결 팁은 Thunderbit의 Selenium 튜토리얼을 참고하세요.
결론 및 핵심 요약
동적 웹 스크래핑은 이제 하드코어 개발자만의 영역이 아니에요. Python Selenium이면 어떤 브라우저든 자동화하고, 가장 까다로운 JavaScript 사이트와도 상호작용하며, 세일즈·리서치·호기심을 위해 필요한 데이터를 가져올 수 있어요. 기억해 두세요.
- Selenium은 동적이고 인터랙티브한 사이트에 가장 맞는 도구예요.
- 핵심 3단계는 환경 설정, 요소 찾기, 추출 및 저장이에요.
- 정기적인 데이터 갱신을 위해 스크립트를 자동화하세요.
- 헤드리스 모드, 스마트한 대기, 효율적인 선택자로 속도와 안정성을 높이세요.
- Selenium과 Thunderbit를 결합하면 데이터 구조화와 내보내기가 쉬워져요. 스프레드시트 정리에 시간을 뺏기기 싫을 때 특히 유용하고요.
직접 해볼 준비가 되셨나요? 위 코드 예제부터 시작해 보세요. 한 단계 더 나아가고 싶다면 Thunderbit로 AI 기반 데이터 정리와 내보내기를 바로 경험해 보세요. 더 궁금하다면 심층 분석, 튜토리얼, 최신 웹 자동화 소식을 다루는 Thunderbit Blog도 확인해 보세요.
즐겁게 스크래핑하세요. 선택자가 늘 원하는 걸 정확히 짚어 주길 바랄게요.
Thunderbit AI 웹 스크래퍼를 무료로 사용해 보기 Get Started Free
자주 묻는 질문
1. BeautifulSoup나 Scrapy 대신 Selenium으로 웹 스크래핑을 해야 하는 이유는 무엇인가요?
Selenium은 사용자 동작이나 JavaScript 실행 뒤에 콘텐츠가 로드되는 동적 사이트를 긁는 데 이상적이에요. BeautifulSoup과 Scrapy는 정적 HTML엔 더 빠르지만, 동적 요소와 상호작용하거나 클릭·스크롤을 흉내 내진 못해요.
2. Selenium 스크래퍼를 더 빠르게 실행하려면 어떻게 해야 하나요?
헤드리스 모드를 쓰고, 이미지와 불필요한 리소스를 막고, 효율적인 선택자를 쓰고, 사람처럼 보이도록 랜덤 지연을 넣으세요. 더 많은 팁은 BrowserStack 가이드를 참고하세요.
3. Selenium 스크래핑 작업을 자동으로 예약 실행할 수 있나요?
네! Python의 schedule 라이브러리나 운영체제 스케줄러(cron 또는 작업 스케줄러)로 정해진 간격마다 스크립트를 돌릴 수 있어요. 스크래핑을 자동화하면 데이터를 최신으로 유지하는 데 도움이 돼요.
4. Selenium으로 스크래핑한 데이터를 가장 잘 내보내는 방법은 무엇인가요?
Pandas로 데이터를 CSV나 Excel로 저장하면 돼요. 더 고급 내보내기(Google Sheets, Notion, Airtable)가 필요하다면 데이터를 Thunderbit에 가져와 원클릭 내보내기를 쓰세요.
5. Selenium에서 팝업과 CAPTCHA는 어떻게 처리하나요?
팝업은 닫기 버튼을 찾아 누르면 돼요. CAPTCHA는 훨씬 까다로워서, 마주쳤다면 수동 우회나 캡차 해결 서비스를 고려하고, 항상 사이트 이용약관을 존중하세요.
더 많은 스크래핑 튜토리얼, AI 자동화 팁, 비즈니스 데이터 도구 소식을 보고 싶다면 Thunderbit Blog를 구독하거나 실전 데모가 있는 YouTube 채널을 확인해 보세요.
더 알아보기




