Zillow는 위에 세워져 있고, 이 데이터를 대규모로 뽑아내는 일은 부동산 데이터 업무에서 가장 자주 요청되면서도 가장 까다로운 작업 중 하나입니다. Zillow를 크롤링해 보다가 매물 목록 대신 CAPTCHA 화면만 뜬 경험이 있다면, 그건 당신만 겪은 일이 아닙니다.
저는 Python으로 하는 방법부터 Thunderbit에서 바로 쓸 수 있는 노코드 방식까지, Zillow 크롤링의 여러 접근법을 꽤 오래 연구하고 직접 테스트해 왔습니다. 이 가이드에서는 두 가지 경로를 모두 다룹니다. 차단 우회 전략까지 포함한 완전한 Python 튜토리얼이 필요하든, 점심시간 전까지 스프레드시트에 매물 200건만 넣으면 되든, 여기서 필요한 답을 찾을 수 있습니다. Zillow 데이터가 왜 중요한지, 사이트가 내부적으로 어떻게 돌아가는지, 단계별 Python 튜토리얼, 크롤러가 깨지는 정확한 이유, 그리고 가격 모니터링을 위한 반복 자동화 방법까지 차근차근 살펴보겠습니다.
왜 Zillow 데이터를 크롤링해야 할까?
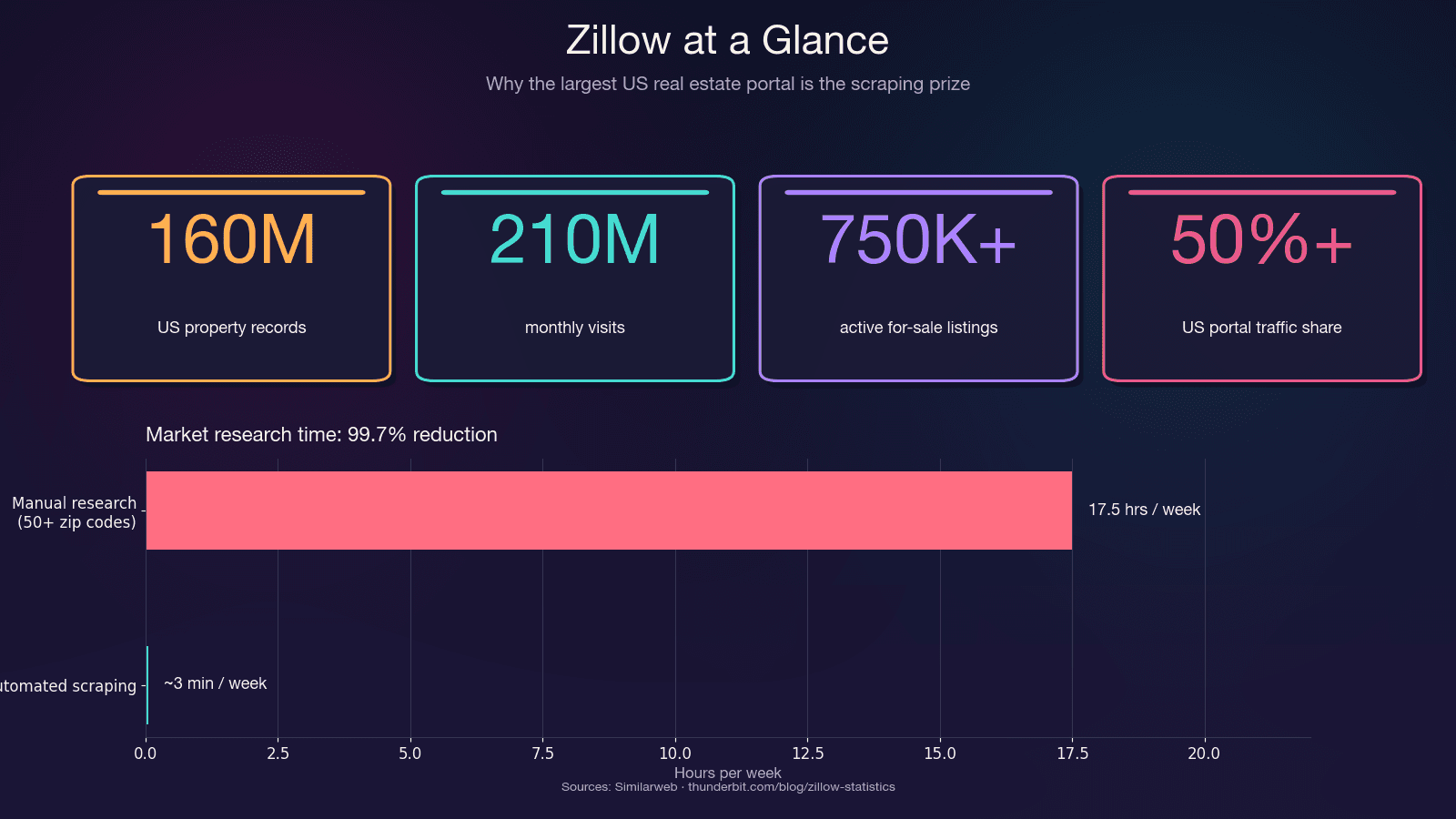
Zillow는 미국 주거용 부동산 데이터의 가장 큰 저장소입니다. 월간 을 기록하고, 현재 매물은 약 75만 건 이상, 임대 매물은 190만 건에 달합니다. 이 플랫폼은 미국 부동산 포털 트래픽의 50% 이상을 차지하며, 다음 경쟁사보다도 두 배 이상 큰 규모를 자랑합니다.
Python 코드로 바로 들어가기 전에, Zillow 크롤링이 Python만의 선택지는 아니라는 점부터 알아두는 게 중요합니다. 방법을 잘못 고르면 몇 시간을 그냥 날릴 수 있습니다. httpx와 BeautifulSoup 같은 Python 도구는 중급 수준의 기술이 필요하고, 헤더와 프록시를 직접 관리해야 하며, 페이지당 1~3초 정도 걸리고, 유지보수도 자주 필요하지만 무료입니다. Selenium이나 Playwright는 JavaScript 렌더링을 지원해서 차단 우회에는 좀 더 유리하지만 더 느리고(페이지당 5~15초) 여전히 관리 부담이 큽니다. ScraperAPI나 ScrapFly 같은 크롤링 API는 차단 대응 기능이 기본으로 들어 있고 유지보수도 비교적 안정적이지만 월 30~599달러가 듭니다. Bridge Interactive를 통한 Zillow 공식 API는 빠르고 유지보수는 적지만 접근이 제한적이고 월 약 500달러 수준입니다. Thunderbit 같은 노코드 도구는 초보자도 쉽게 쓸 수 있고, AI가 페이지 변화에 맞춰 적응하므로 유지보수가 사실상 필요 없으며, 보통 프리미엄 요금제를 제공합니다.
시간 절감 효과만 봐도 차이가 꽤 큽니다. 50개 이상의 우편번호 지역을 직접 조사하면 주당 15~20시간이 사라집니다. 반면 자동 크롤링이면 같은 작업을 몇 분 만에 끝낼 수 있어서, 소요 시간을 99.7%까지 줄일 수 있습니다.
Zillow를 크롤링하는 모든 방법: Python vs. API vs. 노코드 비교
Python 코드로 바로 들어가기 전에, "Python으로 Zillow를 크롤링한다"는 것만이 답은 아니라는 점을 기억하세요. 잘못된 방법을 고르면 몇 시간이 통째로 날아갑니다. 아래 비교표를 보고 자신에게 맞는 방식을 골라보세요.
| 방법 | 필요한 수준 | 차단 대응 | 속도 | 유지보수 | 비용 |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | 중급 | 수동 설정(헤더, 프록시) | 보통(1~3초/페이지) | 높음(셀렉터가 깨짐) | 무료 |
| Python + Selenium/Playwright | 중급 | 더 우수함(JS 렌더링) | 느림(5~15초/페이지) | 높음 | 무료 |
| 크롤링 API (ScraperAPI, ScrapFly) | 중급 | 내장됨 | 빠름 | 중간 | 월 30~599달러 |
| Zillow 공식 API (Bridge Interactive) | 초급~중급 | 해당 없음 | 빠름 | 낮음 | 월 약 500달러, 제한적 접근 |
| 노코드 도구 (Thunderbit) | 초급 | 내장됨(AI가 적응) | 빠름 | 없음(AI가 페이지를 다시 읽음) | 프리미엄 |
지금 당장 코딩 없이 데이터를 얻고 싶다면 Thunderbit부터 시작하세요. 내부 구조를 이해하거나 완전한 커스터마이징이 필요하다면, 아래 Python 가이드를 계속 읽어보세요.
2분 만에 끝내는 방법: Thunderbit로 Zillow 크롤링하기(코드 불필요)
Python 심화 설명에 들어가기 전에, 빠르게 Zillow 데이터만 필요한 분들을 위한 경로를 먼저 소개합니다. Python 설치도, 프록시 설정도, 셀렉터 유지보수도 전혀 필요 없습니다. Thunderbit의 이 워크플로는 엔지니어링 부담 없이 구조화된 부동산 데이터를 가져오도록 특별히 설계되어 있습니다.
난이도: 초급
소요 시간: 약 2분
준비물: Chrome 브라우저, (무료 플랜 사용 가능)
1단계: Thunderbit 설치 후 Zillow 열기
Chrome 웹 스토어에서 Thunderbit 확장 프로그램을 설치하세요. 그다음 예를 들어 휴스턴, 텍사스의 주택 검색 결과 페이지로 이동합니다.
2단계: "AI Suggest Fields" 클릭
Thunderbit 사이드바를 열고 "AI Suggest Fields"를 클릭하세요. AI가 페이지를 읽고 가격, 주소, 침실 수, 욕실 수, 평방피트, Zestimate, 매물 URL 같은 열을 자동으로 제안합니다. 테스트해 보면 보통 별도 설정 없이도 20개 이상의 필드를 감지합니다.
3단계: "Scrape" 클릭
Scrape 버튼을 누르면 확장 프로그램 안의 구조화된 표로 데이터가 채워집니다. Thunderbit는 클릭 기반 페이지네이션과 무한 스크롤을 모두 자동으로 처리합니다.
4단계: 하위 페이지 크롤링으로 데이터 확장
세금 내역, 학군 평점, 가격 변동 내역처럼 상세 페이지 데이터가 필요하신가요? "Scrape Subpages"를 쓰면 표를 더 풍성하게 만들 수 있습니다. Thunderbit가 각 매물 URL을 따라가 추가 필드를 가져오므로 별도 코드가 필요 없습니다.
5단계: 내보내기
Google Sheets, Excel, Airtable, Notion으로 내보낼 수 있습니다. 내보내기는 무료입니다.
Zillow에서 Thunderbit가 잘 작동하는 이유
핵심 장점은 안정성입니다. Thunderbit의 AI는 데이터를 가져올 때마다 페이지 구조를 새로 읽습니다. Zillow가 레이아웃을 자주 바꿔도, 깨지기 쉬운 CSS 셀렉터를 고칠 필요가 없습니다. AI가 자동으로 적응합니다. 이 방식은 코드 기반 크롤러의 구조적 취약성 때문에 고생하는 사용자들에게 꽤 큰 해결책이 됩니다.
Zillow에서 어떤 데이터를 추출할 수 있을까? (20개 이상 필드)
대부분의 가이드는 가격과 주소만 가져오고 끝납니다. 하지만 Zillow 매물에는 생각보다 훨씬 더 많은 추출 가능한 데이터가 있습니다. 아래 표를 참고해 보세요.
| 필드 | 어디서 찾는가 | 추출 난이도 |
|---|---|---|
| 매물 가격 | 검색 결과 + 상세 페이지 | 쉬움 |
| 주소 / 우편번호 | 검색 결과 + 상세 페이지 | 쉬움 |
| Zestimate | 검색 결과 + 상세 페이지 | 쉬움 |
| 가격 이력(각 이벤트) | 상세 페이지 | 어려움(중첩 JSON) |
| 세금 이력 | 상세 페이지 | 어려움(중첩 JSON) |
| 침실 / 욕실 / 면적 | 검색 결과 + 상세 페이지 | 쉬움 |
| 건축 연도 | 상세 페이지 | 쉬움 |
| HOA 비용 | 상세 페이지 | 중간 |
| Walk Score / Transit Score | 상세 페이지(iframe) | 어려움(JS 렌더링 필요) |
| 학군 평점 | 상세 페이지 | 중간 |
| 대지 면적 | 상세 페이지 | 쉬움 |
| Zillow 체류 일수 | 검색 결과 | 쉬움 |
| 매물 담당 에이전트 / 중개사 | 검색 결과 + 상세 페이지 | 중간 |
| MLS 번호 | 상세 페이지 | 쉬움 |
| 부동산 유형 | 검색 결과 + 상세 페이지 | 쉬움 |
| 위도 / 경도 | __NEXT_DATA__ JSON | 중간 |
| 설명 텍스트 | 상세 페이지 | 쉬움 |
| 사진 URL | 검색 결과 + 상세 페이지 | 중간 |
| Rent Zestimate | 상세 페이지 | 중간 |
| 인근 비교 매매 사례 | 상세 페이지 | 어려움 |
여기서 "어려움"으로 표시된 가격 이력, 세금 이력, 비교 매매 데이터는 상세 페이지 안의 중첩 JSON에 들어 있습니다. 아래 Python 섹션에서 이걸 정확히 뽑아내는 방법을 보여드립니다. 코드를 건너뛰고 싶다면, Thunderbit의 AI Suggest Fields가 대부분의 열을 자동 인식하고, Scrape Subpages가 상세 페이지 필드까지 알아서 가져옵니다.
Zillow 크롤링을 위한 Python 환경 설정
난이도: 중급
소요 시간: 설정 5분, 전체 튜토리얼 약 30분
준비물: Python 3.8+, Chrome 브라우저(페이지 확인용), 텍스트 편집기 또는 IDE
필요한 라이브러리를 설치하세요:
1pip install httpx beautifulsoup4 pandas lxml각 라이브러리의 역할은 다음과 같습니다.
- httpx —
requests보다 성능이 좋고 async를 지원하는 HTTP 클라이언트 - beautifulsoup4 + lxml — HTML 파싱
- pandas — CSV/Excel로 데이터 내보내기
- 선택 사항: JavaScript가 많은 페이지를 렌더링해야 한다면 selenium 또는 playwright
크롤링 전에 Zillow 페이지 구조 이해하기
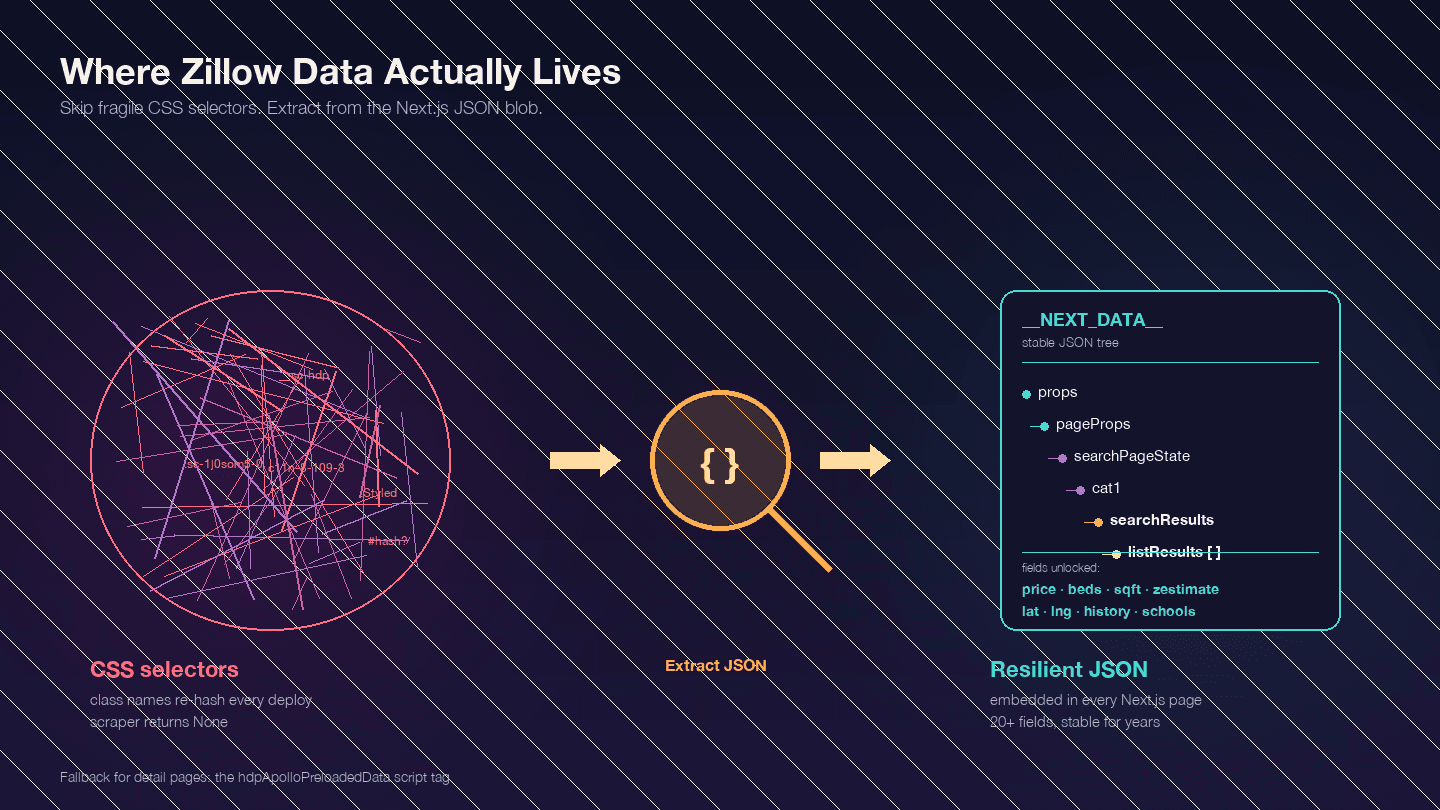
코드를 작성하기 전에 가장 먼저 이해해야 할 핵심입니다. Zillow는 로도 확인되었듯이 Next.js 애플리케이션입니다. 즉, 필요한 데이터 대부분은 눈에 보이는 HTML 요소에 있는 게 아니라, <script id="__NEXT_DATA__"> 안의 JSON 블록에 들어 있습니다.
Zillow의 임의 매물 페이지를 열고 F12를 누른 뒤 Elements 탭에서 __NEXT_DATA__를 검색해 보세요. 가격, 좌표, 부동산 상세 정보, 가격 이력, 세금 기록, 학군 평점 등 매물 데이터를 담은 거대한 JSON 객체를 찾을 수 있습니다.
이 점이 왜 중요할까요? Zillow의 CSS 클래스명은 해시 방식으로 생성되며(styled-components 사용), 배포할 때마다 바뀝니다. 예를 들어 StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 같은 클래스는 다음 주에 완전히 다른 해시값으로 바뀔 수 있습니다. CSS 셀렉터에 의존하는 크롤러는 자주 깨질 수밖에 없습니다.
반면 __NEXT_DATA__ JSON 방식은 HTML 구조에 기대지 않기 때문에 훨씬 안정적입니다.
검색 결과에서 중요한 JSON 경로는 다음과 같습니다.
| 경로 | 내용 |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | 검색 결과 배열 |
props.pageProps.searchPageState.cat1.searchResults.mapResults | 지도 보기 결과 |
props.pageProps.searchPageState.cat1.searchList.totalPages | 전체 페이지 수 |
상세 페이지는 일부가 __NEXT_DATA__를 사용하고, 일부는 대체 방식인 hdpApolloPreloadedData 스크립트 태그를 사용합니다. 아래 코드는 두 경우를 모두 처리합니다.
단계별 가이드: Python으로 Zillow를 크롤링하는 방법
1단계: 즉시 차단을 피하기 위한 HTTP 헤더 설정
기본 httpx.get() 요청을 Zillow에 보내면 매물 데이터가 아니라 CAPTCHA 페이지가 돌아오는 경우가 많습니다. Zillow는 Cloudflare와 함께 PerimeterX(HUMAN Security) 를 사용하며, 크롤링 벤치마크 기준 수준으로 평가됩니다. 이 시스템은 TLS 핑거프린트, HTTP 헤더, IP 평판을 함께 확인합니다.
2025년 기준으로 동작하는 최소 헤더는 다음과 같습니다.
1import httpx
2headers = {
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
5 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
6 "image/avif,image/webp,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
10 "Sec-Ch-Ua-Platform": '"Windows"',
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "none",
14 "Sec-Fetch-User": "?1",
15 "Upgrade-Insecure-Requests": "1",
16}Sec-Ch-Ua 헤더는 특히 중요합니다. 많은 튜토리얼이 이 부분을 빼먹는데, 바로 그 때문에 해당 코드가 PerimeterX 앞에서 먹히지 않는 겁니다.
2단계: Zillow 검색 결과 크롤링하기
Zillow 검색 URL은 예측 가능한 패턴을 따릅니다. 휴스턴, 텍사스 기준으로 보면:
- 1페이지:
https://www.zillow.com/houston-tx/ - 2페이지:
https://www.zillow.com/houston-tx/2_p/ - 3페이지:
https://www.zillow.com/houston-tx/3_p/
각 페이지에는 약 41개의 매물이 있습니다. Zillow는 결과를 최대 20페이지(약 820건)까지만 제공합니다. 더 큰 데이터셋이 필요하다면 지역을 쪼개서 수집해야 합니다(아래에서 설명).
다음 코드는 __NEXT_DATA__ JSON을 추출해서 검색 결과를 크롤링합니다.
1from bs4 import BeautifulSoup
2import json
3import time
4import random
5def scrape_zillow_search(url):
6 """Zillow 검색 결과 페이지에서 매물 데이터를 크롤링합니다."""
7 response = httpx.get(url, headers=headers, timeout=15)
8 if response.status_code != 200:
9 print(f"{url}에서 상태 코드 {response.status_code}를 받았습니다")
10 return []
11 soup = BeautifulSoup(response.text, "lxml")
12 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
13 if not script_tag:
14 print("__NEXT_DATA__를 찾지 못했습니다 — CAPTCHA로 막혔을 수 있습니다")
15 return []
16 next_data = json.loads(script_tag.string)
17 try:
18 results = (
19 next_data["props"]["pageProps"]["searchPageState"]
20 ["cat1"]["searchResults"]["listResults"]
21 )
22 except KeyError:
23 print("예상과 다른 JSON 구조입니다 — Zillow가 형식을 바꿨을 수 있습니다")
24 return []
25 listings = []
26 for item in results:
27 listing = {
28 "zpid": item.get("zpid"),
29 "address": item.get("addressStreet"),
30 "city": item.get("addressCity"),
31 "state": item.get("addressState"),
32 "zipcode": item.get("addressZipcode"),
33 "price": item.get("unformattedPrice") or item.get("price"),
34 "beds": item.get("beds"),
35 "baths": item.get("baths"),
36 "sqft": item.get("area"),
37 "zestimate": item.get("zestimate"),
38 "days_on_zillow": item.get("daysOnZillow"),
39 "listing_url": item.get("detailUrl"),
40 "img_src": item.get("imgSrc"),
41 "property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
42 "latitude": item.get("latLong", {}).get("latitude"),
43 "longitude": item.get("latLong", {}).get("longitude"),
44 }
45 listings.append(listing)
46 return listings여러 페이지를 수집하려면 지연 시간을 두고 루프를 돌리면 됩니다.
1all_listings = []
2base_url = "https://www.zillow.com/houston-tx/"
3for page in range(1, 6): # 처음 5페이지
4 url = base_url if page == 1 else f"{base_url}{page}_p/"
5 print(f"{page}페이지 크롤링 중...")
6 page_listings = scrape_zillow_search(url)
7 all_listings.extend(page_listings)
8 # 3~7초 사이 랜덤 지연
9 delay = random.uniform(3, 7)
10 time.sleep(delay)
11print(f"총 크롤링한 매물 수: {len(all_listings)}")all_listings에 구조화된 매물 데이터가 쌓이는 걸 볼 수 있습니다. 결과가 비어 있다면 아래 "크롤러가 깨지는 이유" 섹션을 확인하세요.
3단계: Zillow 매물 상세 페이지 크롤링하기
검색 결과에서는 기본 정보만 얻을 수 있습니다. 상세 페이지에는 가격 이력, 세금 이력, 학군 평점, 에이전트 정보, 부동산 설명처럼 더 깊은 데이터가 들어 있습니다. 2단계에서 얻은 각 매물 URL이 바로 상세 페이지로 연결됩니다.
Zillow 상세 페이지는 두 가지 데이터 형식을 사용합니다. 두 경우를 모두 처리하는 코드는 아래와 같습니다.
1def scrape_zillow_detail(url):
2 """Zillow 매물 페이지에서 상세 부동산 데이터를 크롤링합니다."""
3 response = httpx.get(url, headers=headers, timeout=15)
4 if response.status_code != 200:
5 return None
6 soup = BeautifulSoup(response.text, "lxml")
7 # 먼저 __NEXT_DATA__ 시도(가장 일반적)
8 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
9 if script_tag:
10 next_data = json.loads(script_tag.string)
11 try:
12 cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
13 cache = json.loads(cache_str)
14 first_key = next(iter(cache))
15 prop = cache[first_key]["property"]
16 return extract_property_fields(prop)
17 except (KeyError, StopIteration):
18 pass
19 # 대체 방식: hdpApolloPreloadedData
20 apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
21 if apollo_tag:
22 raw = json.loads(apollo_tag.string)
23 api_cache = json.loads(raw["apiCache"])
24 for key, value in api_cache.items():
25 if "ForSale" in key or "property" in str(value)[:100]:
26 prop = value.get("property", value)
27 return extract_property_fields(prop)
28 return None
29def extract_property_fields(prop):
30 """Zillow 부동산 JSON 객체에서 구조화된 필드를 추출합니다."""
31 return {
32 "zpid": prop.get("zpid"),
33 "zestimate": prop.get("zestimate"),
34 "rent_zestimate": prop.get("rentZestimate"),
35 "description": prop.get("description"),
36 "year_built": prop.get("yearBuilt"),
37 "lot_size": prop.get("lotSize"),
38 "hoa_fee": prop.get("monthlyHoaFee"),
39 "mls_id": prop.get("mlsid"),
40 "broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
41 "price_history": [
42 {
43 "date": event.get("date"),
44 "event": event.get("event"),
45 "price": event.get("price"),
46 }
47 for event in prop.get("priceHistory", [])
48 ],
49 "tax_history": [
50 {
51 "year": record.get("time"),
52 "tax_paid": record.get("taxPaid"),
53 "value": record.get("value"),
54 }
55 for record in prop.get("taxHistory", [])
56 ],
57 "schools": [
58 {
59 "name": school.get("name"),
60 "rating": school.get("rating"),
61 "distance": school.get("distance"),
62 }
63 for school in prop.get("schools", [])
64 ],
65 }이제 매물 URL들을 지연 시간을 두고 순회하면 됩니다.
1detail_data = []
2for listing in all_listings[:10]: # 우선 10개만 테스트
3 detail_url = listing.get("listing_url")
4 if not detail_url:
5 continue
6 if not detail_url.startswith("http"):
7 detail_url = f"https://www.zillow.com{detail_url}"
8 print(f"상세 페이지 크롤링 중: {detail_url}")
9 detail = scrape_zillow_detail(detail_url)
10 if detail:
11 detail_data.append({**listing, **detail})
12 time.sleep(random.uniform(3, 8))이 단계가 끝나면 각 부동산의 검색 결과 수준 데이터와 상세 페이지 수준 데이터를 함께 담은 딕셔너리 리스트를 갖게 됩니다.
4단계: 여러 페이지를 크롤링하기 위한 페이지네이션 처리
820건(20페이지 제한)을 넘는 지역은 지리적으로 나눠야 합니다. Zillow 내부 API는 mapBounds 파라미터를 받습니다. 전략은 간단합니다. 지도를 사분면으로 나눈 뒤 각각 따로 크롤링하면 됩니다.
1def split_bounds(bounds):
2 """지도 범위를 4개 사분면으로 나눕니다."""
3 mid_lat = (bounds["north"] + bounds["south"]) / 2
4 mid_lng = (bounds["east"] + bounds["west"]) / 2
5 return [
6 {"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
7 {"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
8 {"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
9 {"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
10 ]대부분의 경우, 예를 들어 특정 지역의 50~200개 매물을 모니터링하는 정도라면 일반 URL 페이지네이션이면 충분합니다. 사분면 방식은 도시 전체나 주 전체를 크롤링할 때 더 적합합니다.
5단계: 크롤링한 Zillow 데이터 내보내기
pandas로 CSV 파일로 저장합니다.
1import pandas as pd
2df = pd.DataFrame(detail_data)
3df.to_csv("zillow_houston_listings.csv", index=False)
4print(f"{len(df)}개의 매물을 zillow_houston_listings.csv로 내보냈습니다")JSON으로 내보내려면:
1with open("zillow_houston_listings.json", "w") as f:
2 json.dump(detail_data, f, indent=2)내보내기 단계까지 아예 건너뛰고 싶다면, Thunderbit는 Google Sheets, Airtable, Notion으로 무료 내보내기를 지원합니다. 협업용 포맷이 바로 필요할 때 특히 유용합니다.
Zillow 크롤러가 깨지는 이유와, 더 견고하게 만드는 방법
이 부분은 사실상 생존 가이드입니다.
제 경험상 Zillow 크롤러가 깨지는 이유는 세 가지로 좁혀지고, 각각에 명확한 해결책이 있습니다.
PerimeterX와 CAPTCHA: 왜 요청했는데 빈 데이터가 오는가
Zillow의 PerimeterX 통합은 TLS 핑거프린트, HTTP 헤더, IP 평판, 요청 패턴을 동시에 검사합니다. 자동화가 감지되면 매물 데이터 대신 "Press & Hold" CAPTCHA 페이지를 반환합니다.
정확한 실패 상황: 기본 Python 헤더로 요청을 보냈더니, 응답 HTML에는 부동산 데이터 대신 PerimeterX 챌린지 스크립트만 들어 있습니다. 그 결과 BeautifulSoup으로 파싱해도 __NEXT_DATA__ 태그를 찾지 못합니다.
해결 방법: 1단계에서 소개한 전체 브라우저 모방 헤더를 사용하세요. 수십 건 이상 요청해야 한다면 프록시 로테이션도 필요합니다(아래 설명). 대량 크롤링이라면 impersonate="chrome"를 지원하는 curl_cffi 같은 라이브러리도 고려해 볼 수 있습니다. 실제 Chrome의 TLS 핑거프린트와 가장 비슷하게 맞출 수 있는 Python HTTP 클라이언트입니다.
동적 CSS 셀렉터: 왜 BeautifulSoup이 None을 반환하는가
.list-card-price 같은 CSS 셀렉터나 해시가 붙은 클래스명에 의존하면, Zillow가 새 코드를 배포할 때마다 크롤러가 쉽게 망가집니다.
Zillow는 styled-components를 사용하므로 StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 같은 클래스명이 생성됩니다. 이 해시 부분은 빌드마다 바뀝니다.
해결 방법: 아예 CSS 셀렉터를 쓰지 마세요. 위 코드처럼 __NEXT_DATA__ JSON 블록에서 직접 데이터를 추출하는 게 가장 안전합니다. HTML 마크업은 JSON 구조보다 훨씬 자주 바뀌기 때문에, 이 방식이 수년간 더 안정적이었습니다.
꼭 HTML 파싱을 써야 한다면 data-test 속성(예: data-test="property-card")을 찾거나, [class*="PropertyCard"]처럼 부분 문자열 기반 클래스 매칭을 활용하세요. 그래도 JSON 추출이 더 믿을 만한 방법입니다.
프록시 로테이션과 지수 백오프: IP 차단에도 살아남는 코드
Zillow는 데이터센터 IP를 . 안정적인 접근을 위해서는 주거용 프록시가 필요합니다. 안전한 요청 속도는 IP당 3~8초에 1회 정도, 시간당 500요청 이하가 적당합니다.
아래는 지터가 포함된 지수 백오프 재시도 데코레이터입니다.
1import random
2import time
3def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
4 """AWS 스타일의 full jitter 지수 백오프입니다."""
5 delay = min(max_delay, base_delay * (2 ** attempt))
6 return random.uniform(0, delay)
7def fetch_with_retry(url, max_retries=5):
8 for attempt in range(max_retries):
9 try:
10 response = httpx.get(url, headers=headers, timeout=15)
11 if response.status_code == 200:
12 return response
13 if response.status_code in (403, 429):
14 delay = backoff_with_jitter(attempt, base_delay=5)
15 print(f"차단됨({response.status_code}). {delay:.1f}초 후 재시도합니다...")
16 time.sleep(delay)
17 continue
18 except Exception as e:
19 if attempt == max_retries - 1:
20 raise
21 time.sleep(backoff_with_jitter(attempt))
22 return None간단한 프록시 로테이션 풀은 다음과 같습니다.
1class ProxyPool:
2 def __init__(self, proxies):
3 self.proxies = proxies
4 self.index = 0
5 self.failures = {}
6 def get_next(self):
7 proxy = self.proxies[self.index % len(self.proxies)]
8 self.index += 1
9 return {"http://": proxy, "https://": proxy}
10 def report_failure(self, proxy):
11 self.failures[proxy] = self.failures.get(proxy, 0) + 1
12 if self.failures[proxy] > 3:
13 self.proxies.remove(proxy)
14# 사용 예시:
15pool = ProxyPool(proxies=[
16 "http://user:pass@residential1.example.com:8080",
17 "http://user:pass@residential2.example.com:8080",
18])프록시 제공업체로는 가 주거용 프록시를 약 $1/GB 수준으로 제공해 가장 저렴한 편이고, IPRoyal과 Smartproxy는 GB당 $4~7 수준의 무난한 중간 선택지입니다.
유지보수 없는 대안
Zillow를 자주 크롤링하면서 깨지는 셀렉터를 고치거나 프록시 풀을 관리하는 데 지쳤다면, Thunderbit의 AI는 매번 페이지 구조를 새로 읽습니다. 유지해야 할 셀렉터도, 프록시 설정도 없습니다. 코드 기반 크롤러의 반복적인 골칫거리를 실제로 줄여 줍니다.
Zillow 크롤링 자동화: 예약 실행과 가격 모니터링
제가 만난 모든 부동산 투자자가 원하지만, 다른 Zillow 크롤링 가이드에서는 거의 다루지 않는 기능이 바로 반복 자동 크롤링과 가격 추적입니다.
Python 사용자라면: 크론 작업과 가격 변동 감지
스크래퍼를 매주 실행하고 가격 변동을 표시하는 크론 작업을 설정하세요.
1import pandas as pd
2from datetime import datetime
3def detect_price_changes(new_data, historical_file, threshold=0.05):
4 """새로운 크롤링 결과와 과거 데이터를 비교해 threshold 이상 변화를 표시합니다."""
5 try:
6 old = pd.read_csv(historical_file)
7 except FileNotFoundError:
8 new_data.to_csv(historical_file, index=False)
9 print("첫 실행입니다 — 기준 데이터를 저장했습니다.")
10 return pd.DataFrame()
11 merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
12 merged["price_change_pct"] = (
13 (merged["price_new"] - merged["price_old"]) / merged["price_old"]
14 )
15 alerts = merged[merged["price_change_pct"].abs() > threshold]
16 # 타임스탬프와 함께 새 데이터 추가 저장
17 new_data["scraped_at"] = datetime.now().isoformat()
18 new_data.to_csv(historical_file, mode="a", header=False, index=False)
19 return alerts매주 월요일 오전 6시에 실행되도록 crontab에 추가하세요.
10 6 * * 1 cd /path/to/scraper && python zillow_monitor.py실제 활용 예시: 텍사스 오스틴의 50개 매물을 매주 모니터링합니다. 매주 월요일, 스크립트가 현재 가격을 수집하고 지난주와 비교한 뒤, 5% 이상 가격이 내려간 항목을 CSV로 출력합니다.
비개발자라면: Thunderbit Scheduled Scraper
Thunderbit의 Scheduled Scraper는 "매주 월요일 오전 9시"처럼 자연어로 주기를 입력하고, Zillow 검색 URL을 넣은 뒤 Schedule만 누르면 됩니다. 데이터는 실행할 때마다 Google Sheets로 자동 내보내집니다. Python도, cron도, 서버 관리도 필요 없습니다. 엔지니어 지원 없이도 안정적인 가격 모니터링이 필요한 부동산 중개인이나 운영팀에 특히 유용합니다.
책임감 있게 Zillow를 크롤링하는 팁
선을 넘지 않으면서 작업하려면 몇 가지를 기억하세요.
- 공개된 데이터만 크롤링하세요. 로그인이나 인증 뒤에 있는 페이지는 건드리지 마세요.
- 합리적인 요청 속도를 유지하세요. 요청 사이에 3~8초 간격을 두세요. 서버를 과도하게 두드리지 마세요.
- 개인 또는 민감한 사용자 데이터를 크롤링하지 마세요. 매물에 표시되는 에이전트 이름과 중개사 정보는 공개 정보지만, 사용자 계정 데이터는 아닙니다.
- 데이터를 윤리적으로 저장하고 사용하세요. 시장 조사, 투자 분석, 리드 생성은 정당한 활용입니다. 스팸은 아닙니다.
- 법적 맥락: 은 공개적으로 접근 가능한 데이터를 크롤링하는 것이 CFAA를 위반하지 않는다고 보았습니다. Meta v. Bright Data(2024) 판결도 비슷한 원칙을 확인했습니다. 다만 Zillow의 이용약관은 자동 접근을 제한하고 있고, 실제로는 법적 소송보다 IP 차단과 CAPTCHA로 대응합니다. 항상 최신 가이드를 확인하고 를 존중하세요.
Python으로 Zillow를 크롤링하는 최적의 방법 고르기
가장 좋은 방법은 상황에 따라 다릅니다.
빠르게, 코딩 없이 데이터가 필요하신가요? 를 쓰면 Zillow 검색 페이지에서 구조화된 스프레드시트까지 약 2분이면 도달할 수 있습니다. AI가 레이아웃 변경에 적응하고, 페이지네이션을 처리하며, 무료 내보내기까지 제공합니다. 을 설치해 Zillow 검색 페이지에서 바로 써보세요.
완전한 제어가 필요하신가요? 이 가이드의 Python 코드를 사용하세요. 안정성을 위해 CSS 셀렉터가 아니라 __NEXT_DATA__ JSON에서 추출하세요. 브라우저를 흉내 내는 적절한 헤더를 넣고, 안정성을 위해 주거용 프록시와 지수 백오프를 사용하세요.
더 크게 확장하고 싶으신가요? (Zillow 성공률 99%)나 ScraperAPI 같은 크롤링 API가 프록시와 CAPTCHA 인프라를 대신 처리해 줍니다. 비용은 사용량에 따라 월 30~599달러입니다.
시간에 따라 가격을 추적하고 싶으신가요? 가격 변동 감지 스크립트와 함께 크론 작업을 설정하거나, 유지보수 없는 방식으로 Thunderbit Scheduled Scraper를 사용하세요.
데이터는 이미 존재합니다. 문제는 그 데이터를 꺼내기 위해 얼마나 많은 엔지니어링 시간을 쓸 거냐는 점입니다. 웹 데이터를 스프레드시트로 옮기는 방법이 더 궁금하다면 가이드나 최신 플랫폼 정보를 담은 를 확인해 보세요. 에서도 튜토리얼을 볼 수 있습니다.
자주 묻는 질문
Python으로 Zillow를 무료로 크롤링할 수 있나요?
네. httpx, BeautifulSoup, pandas는 모두 무료 오픈소스입니다. 대신 시간 비용이 들어갑니다. 헤더 설정, 프록시 로테이션, 셀렉터 유지보수를 직접 해야 합니다. 초기 설정에 4~8시간, Zillow가 사이트를 바꿀 때마다 매달 4~10시간 정도의 유지보수를 예상하세요. 코딩 부담 없이 쓰고 싶다면 Thunderbit도 무료 플랜을 제공합니다.
Zillow에 공식 API가 있나요?
Zillow는 2021년 9월에 무료 공개 API를 종료했습니다. 현재는 Bridge Interactive를 통해 접근해야 하며, 승인 절차가 필요하고 비용은 대략 월 500달러이며, 면허를 가진 부동산 전문가를 대상으로 합니다. 대부분의 사용자 — 투자자, 연구자, 시장 분석을 하는 중개인 — 에게는 크롤링이 현실적인 대안입니다. Zillow는 여전히 에서 Zillow Home Value Index와 Zillow Observed Rent Index 같은 무료 연구 데이터를 CSV로 제공합니다.
Zillow 크롤링 시 차단을 피하려면 어떻게 해야 하나요?
세 가지가 핵심입니다. (1) Sec-Ch-Ua를 포함한 현실적인 브라우저 헤더를 사용하세요. 많은 튜토리얼이 빼먹는 헤더이며 PerimeterX가 가장 먼저 확인합니다. (2) 주거용 프록시를 로테이션하세요. 데이터센터 IP는 즉시 블록리스트에 오릅니다. (3) HTML 셀렉터 대신 __NEXT_DATA__ JSON에서 데이터를 추출해 레이아웃 변경으로 인한 깨짐을 피하세요. 요청 속도는 IP당 3~8초에 1회 정도로 유지하세요. 또는 차단 대응을 자동으로 처리하는 Thunderbit 같은 도구를 사용하세요.
코딩 없이 Zillow를 크롤링하는 가장 좋은 방법은 무엇인가요?
Thunderbit의 AI Web Scraper가 가장 빠른 방법입니다. 을 설치하고 Zillow 검색 페이지로 이동한 뒤, "AI Suggest Fields"를 눌러 열을 자동 인식시키고, 그다음 "Scrape"를 클릭하세요. 코딩 없이 Google Sheets, Excel, Airtable, Notion으로 내보낼 수 있습니다. AI가 매번 페이지를 새로 읽기 때문에 Zillow가 레이아웃을 바꿔도 깨지지 않습니다.
Zillow는 사이트 구조를 얼마나 자주 바꾸며, 이것이 크롤러에 어떤 영향을 주나요?
Zillow는 자주 업데이트를 배포하며, 때로는 매주 바뀌기도 합니다. styled-components를 사용하기 때문에 CSS 클래스명은 배포마다 달라지고, CSS 셀렉터 기반 크롤러는 자주 깨집니다. Python에서 가장 견고한 방법은 __NEXT_DATA__ JSON 블록에서 추출하는 것입니다. 이 JSON 구조는 HTML 마크업보다 훨씬 덜 자주 바뀝니다. 유지보수가 전혀 필요 없는 방식으로 가려면, Thunderbit의 AI가 매 크롤링마다 페이지 구조를 다시 읽고 레이아웃 변화에 자동 적응합니다.
더 알아보기