Walmart는 일부 상품의 가격을 하루에도 바꿔요. 이걸 프로그램으로 추적해 본 적이 있다면 그 고생을 잘 아실 거예요. 스크립트가 20분쯤 멀쩡히 돌아가다가, 아무 문제 없어 보이는 200 OK 응답처럼 위장한 CAPTCHA 페이지를 조용히 반환하기 시작하거든요.
저는 에서 데이터 추출 작업을 하면서 Walmart의 안티봇 방어를 꽤 오래 다뤄 왔고, 그 과정에서 배운 걸 모두 공유하고 싶어요. 실제로 2025년에 통하는 방법, 데이터를 망치는 조용한 실패, 직접 스크래퍼를 만드는 것과 스크래핑 API를 쓰는 것, 그리고 노코드 도구를 쓰는 것 사이의 솔직한 트레이드오프까지요. 이 가이드는 세 가지 추출 방법(HTML 파싱, __NEXT_DATA__ JSON, 내부 API 가로채기), 대부분의 튜토리얼이 아예 건너뛰는 운영용 오류 처리, 그리고 상황에 맞는 접근법을 고르는 현실적인 의사결정 프레임워크를 다뤄요. Python으로 직접 만들든, 점심 전까지 가격표가 잔뜩 들어간 스프레드시트만 원하든, 도움이 될 거예요.
왜 Python으로 Walmart를 스크래핑해야 할까요?
Walmart는 매출 기준으로 세계 최대 소매업체예요. FY2025 기준 에 달했고, 를 지키고 있어요. 사이트에는 대략 이 있고, Walmart CFO는 마켓플레이스에 가 있다고 언급했어요. 이 목록의 약 가 올린 것이어서 카탈로그가 매우 유동적이에요. 판매자는 계속 바뀌고, 옵션은 수정되며, 재고도 매일 뒤바뀌죠.
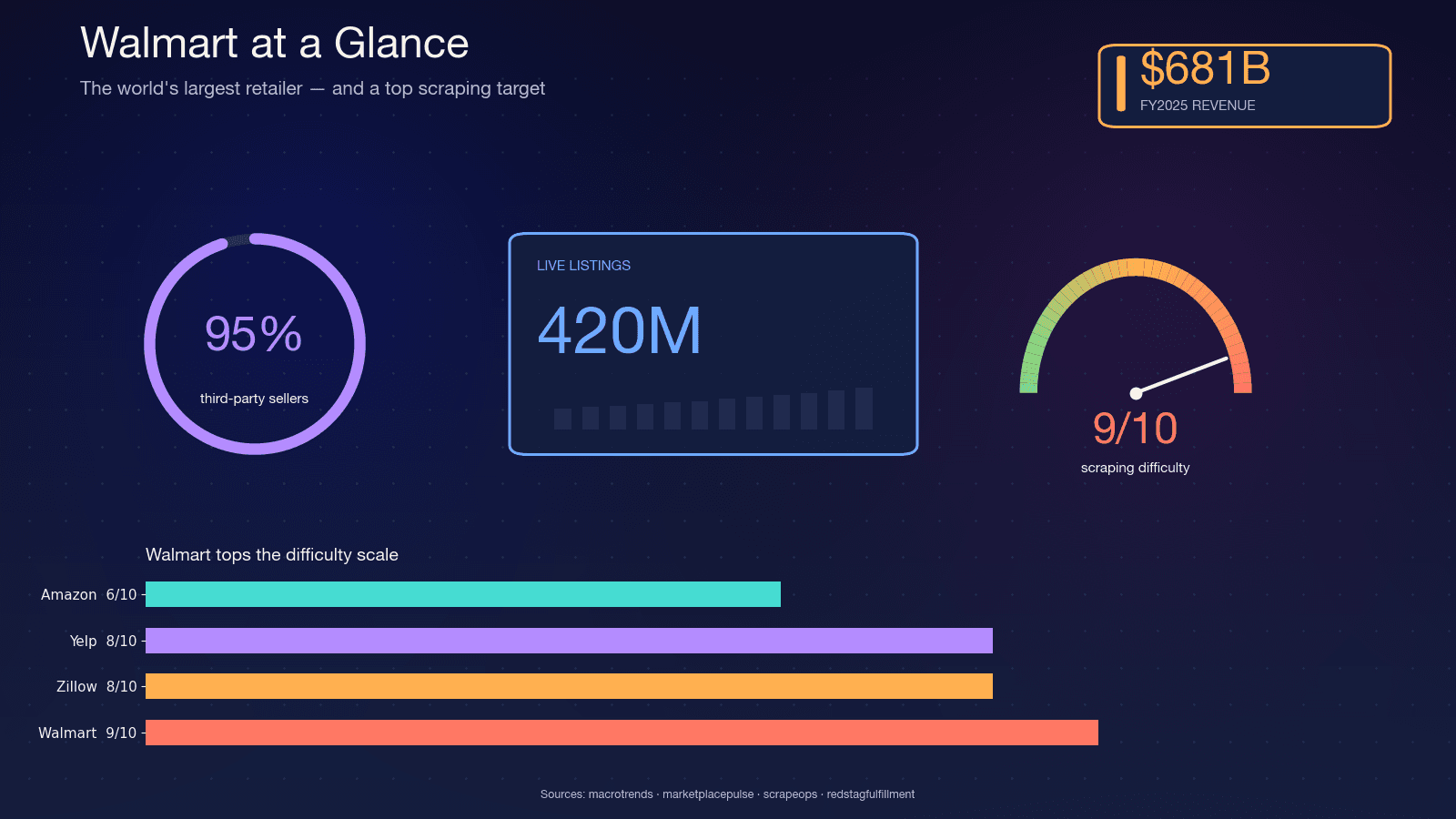
바로 그 변동성 때문에 스크래핑이 중요해요. 분기별 보고서로는 밤새 돌린 스크래퍼가 잡아내는 변화를 담아낼 수 없거든요. 제가 자주 보는 대표적인 활용 사례는 아래와 같아요:
| 활용 사례 | 필요한 사람 | 추출 항목 |
|---|---|---|
| 경쟁사 가격 모니터링 | 이커머스 운영팀, 가격 재조정 도구 | 가격, 프로모션, MAP 준수 여부 |
| 상품 카탈로그 보강 | 영업 및 머천다이징 팀 | 설명, 이미지, 사양, 옵션 |
| 재고 가용성 추적 | 공급망, 드롭쉬퍼 | 재고 상태, 판매자 정보 |
| 시장 조사 및 트렌드 분석 | 마케팅, 제품 관리자 | 평점, 리뷰, 카테고리 구성 |
| 리드 생성 | 영업팀 | 판매자 이름, 상품 수, 카테고리 |
경쟁사 가격 모니터링 소프트웨어 시장만 해도 에 도달했고, 2033년까지 50억 9천만 달러로 성장할 전망이에요. 소비자 행동도 이 지출을 받쳐 줘요. 하고, 83%는 여러 사이트를 오가며 비교 쇼핑을 해요.
이 작업의 기본 언어는 Python이에요. Apify의 2026 인프라 보고서에 따르면 으로 이뤄지고, 핵심 라이브러리(requests)는 주당 돼요. 어느 정도 규모 이상으로 스크래핑한다면, 거의 확실히 Python으로 하고 있다고 보면 돼요.
Walmart가 가장 스크래핑하기 어려운 사이트 중 하나인 이유
Walmart가 특히 어려운 이유는 두 개의 상용 안티봇 제품을 연달아 사용하기 때문이에요. 엣지 WAF 및 TLS 핑거프린팅 계층으로 를 쓰고, 그다음 행동 기반 JavaScript 챌린지 계층으로 를 사용해요. Scrape.do는 이 조합을 “우회하기 매우 드물고, 극도로 어렵다”고 표현해요.
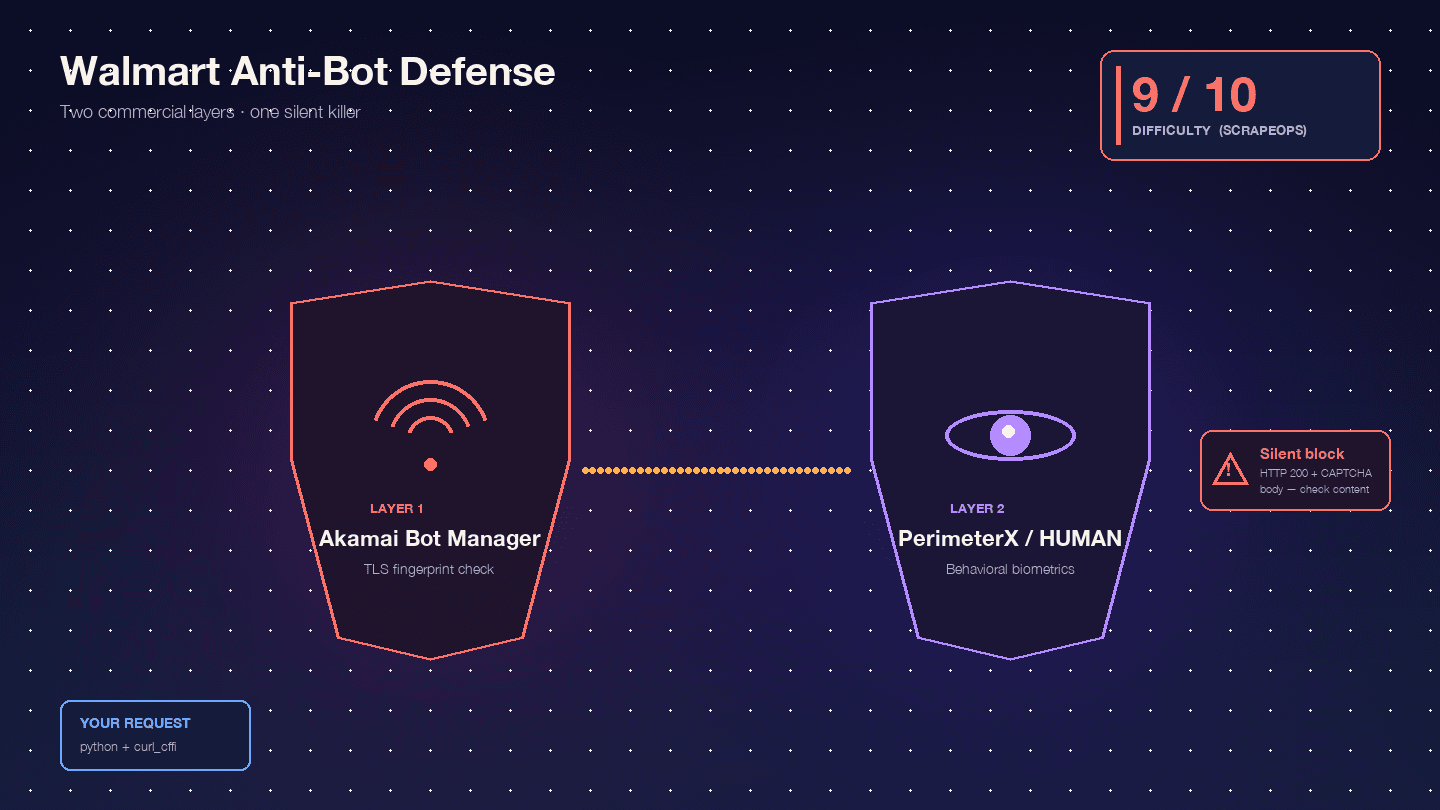
했고, Akamai만 따져도 9/10이에요. 제 경험상 그 평가는 꽤 맞아요.
실제로 마주치는 방어는 이렇습니다:
Akamai Bot Manager는 TLS 핑거프린트(JA3/JA4 해시), HTTP/2 프레임 순서, 헤더 순서와 대소문자, 세션 쿠키(_abck, ak_bmsc)를 검사해요. 기본 Python requests 호출은 실제 브라우저가 절대 만들지 않는 TLS 핑거프린트를 내보내기 때문에, 요청이 Walmart 서버에 도달하기도 전에 Akamai가 차단해요.
PerimeterX/HUMAN은 Akamai 이후에 실행되며, navigator 속성, canvas 렌더링, WebGL, 오디오 컨텍스트, 행동 생체 신호(마우스 움직임, 스크롤 속도, 키 입력 패턴)를 확인하는 JavaScript 핑거프린팅(px.js)을 돌려요. 눈에 보이는 실패는 악명 높은 예요. 약 10초간 버튼을 눌러야 하며, 그동안 행동 신호를 샘플링하죠. Oxylabs는 “Walmart는 PerimeterX가 제공하는 ‘Press & Hold’ 방식의 CAPTCHA를 사용하며, 코드로 풀기는 거의 불가능하다고 알려져 있다”고 단언해요.
진짜 위험한 건 조용한 차단이에요. Walmart는 403 대신 CAPTCHA 본문이 포함된 HTTP 200을 돌려줘요. : “Walmart는 CAPTCHA 페이지를 제공할 때도 200 OK 상태 코드를 반환해요. 요청이 성공했는지는 상태 코드만으로 판단할 수 없어요.” 스크립트는 CAPTCHA HTML을 “상품 없음”으로 착각하고 계속 진행해요. 데이터의 절반이 쓰레기가 되는데도, 본인은 그 사실을 몰라요.
게다가 매장 범위 데이터 문제도 있어요. Walmart의 가격과 재고는 위치에 따라 달라지고, locDataV3와 assortmentStoreId 같은 쿠키로 제어돼요. 올바른 쿠키가 없으면, 겉보기엔 완전해 보이지만 실제 쇼핑객이 보는 내용과는 맞지 않는 “기본 전국 데이터”를 받아요. 쿠키 누락은 차단 페이지를 만들지 않아요. 대신 티 나지 않는 잘못된 데이터를 만들죠. 이건 더 나빠요.
Walmart에서 데이터를 추출하는 3가지 방법과 비교
단계별 설명에 들어가기 전에, 주요 추출 방식 세 가지를 먼저 볼게요. 경쟁사 튜토리얼은 보통 하나나 둘만 다루거든요. 여기서는 세 가지를 모두 살펴보고, 상황에 맞는 방법을 고를 수 있게 해드릴게요.
| 방법 | 신뢰성 | 데이터 완성도 | 안티봇 난이도 | 유지보수 부담 |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ 낮음(배포마다 셀렉터가 깨짐) | 보통 | 높음 | 높음 |
__NEXT_DATA__ JSON | ✅ 좋음 | 높음 | 중상 | 중간 |
| 내부 API 가로채기 | ✅ 가장 좋음 | 최고(옵션, 재고, 리뷰 포함) | 중상 | 낮음(구조화된 JSON) |
| Thunderbit (노코드) | ✅ 좋음 | 높음 | 낮음(AI가 처리) | 없음 |
Walmart에는 HTML 파싱이 최악의 선택이에요. 사이트가 해시된 CSS 클래스명과 함께 Next.js 번들을 배포하는데, 이 클래스명은 배포할 때마다 바뀌거든요. __NEXT_DATA__ JSON 방식은 2024~2026년의 진지한 오픈소스 Walmart 스크래퍼들이 모두 사용하는 현실적인 선택이에요. 내부 API 가로채기는 가장 강력하지만, 대부분의 튜토리얼이 슬쩍 넘어가는 주의점이 있어요. 그리고 맞춤형 파이프라인이 전혀 필요 없다면 Thunderbit가 정답이에요.
Walmart 스크래핑을 위한 Python 환경 설정
준비물은 이렇습니다:
- 난이도: 중급
- 소요 시간: 설정 약 30분 + 코딩 시간
- 필요한 것: Python 3.10+, pip, 코드 에디터, 그리고(운영용이라면) 프록시 서비스 또는 스크래핑 API
프로젝트 폴더와 가상 환경을 만드세요:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # Windows에서는: venv\Scripts\activate필요한 라이브러리를 설치하세요:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi는 2025년의 까다로운 대상 사이트 스크래핑 표준이에요. 정확한 브라우저 TLS 핑거프린트를 흉내 낼 수 있는 libcurl 바인딩이거든요. : “Walmart는 봇 탐지의 일부로 TLS 핑거프린팅을 사용하며, User-Agent만 실제 브라우저처럼 바꾼다고 해서 우회되지는 않아요.” 일반 requests나 httpx는 어떤 헤더를 넣어도 Akamai를 통과할 수 없어요. impersonate="chrome124"를 사용하는 curl_cffi가 차이를 만들어 줘요.
나중에 설명할 운영 패턴을 위해 json(기본 내장), csv(기본 내장), time, random, logging도 함께 쓰게 될 거예요.
단계별: Python으로 Walmart 상품 페이지 스크래핑하기
1단계: Walmart 상품 페이지 가져오기
첫 번째 할 일은 바로 차단되지 않는 HTTP 요청을 만드는 거예요. 아래는 2024~2026년 Scrapfly, Scrapingdog, Oxylabs, ScrapeOps 전반에서 사용되는 표준 헤더 세트예요:
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)impersonate="chrome124" 매개변수가 여기서 핵심이에요. curl_cffi가 Chrome 124의 정확한 TLS ClientHello, HTTP/2 프레임 순서, pseudo-header 순서를 맞추도록 해주거든요. 이게 없으면 Akamai는 Python 전용 JA3 해시를 보고, 요청이 Walmart 애플리케이션 계층에 도달하기도 전에 차단해요.
차단된 응답은 이렇게 보여요: 응답 HTML 제목에 "Robot or human?"가 보이거나, 응답이 walmart.com/blocked로 리디렉션되면 차단된 거예요. 까다로운 점은 Walmart가 종종 CAPTCHA 본문과 함께 200 상태 코드를 돌려준다는 거예요. 그래서 response.ok만 확인하면 안 돼요.
운영 환경이나 반복 사용을 한다면 주거용 프록시가 필요해요. 데이터센터 IP는 Akamai의 IP 평판 시스템에 의해 바로 소진돼요. 자세한 오류 처리와 프록시 전략은 아래 운영 섹션에서 다룰게요.
2단계: __NEXT_DATA__ JSON에서 상품 데이터 파싱하기
Walmart.com은 Next.js 애플리케이션이고, 서버 렌더링 HTML은 전체 하이드레이션 페이로드를 단일 script 태그 안에 넣어요: <script id="__NEXT_DATA__" type="application/json">. 이게 핵심이에요.
: “2026년의 Walmart는 __NEXT_DATA__ script 태그 안에 구조화된 JSON을 담은 Next.js를 사용하므로, 숨겨진 데이터 추출이 기존 CSS 셀렉터 파싱보다 더 안정적이에요.” 모든 유명 오픈소스 Walmart 스크래퍼 — , , — 가 이 방식을 사용해요.
추출 방법은 이렇습니다:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})대부분의 튜토리얼은 여기서 끝나요. 하지만 아래는 실제로 필요한 필드를 위한 완전한 JSON 경로 맵이에요. 2024~2026년의 실제 Walmart 페이지를 기준으로 검증했어요:
| 데이터 필드 | JSON 경로(initialData 아래) | 유형 | 비고 |
|---|---|---|---|
| 상품명 | data > product > name | 문자열 | — |
| 브랜드 | data > product > brand | 문자열 | — |
| 현재 가격(숫자) | data > product > priceInfo > currentPrice > price | 실수 | 매장 쿠키에 따라 다를 수 있음 |
| 현재 가격(문자열) | data > product > priceInfo > currentPrice > priceString | 문자열 | 예: "$9.99" 형태 |
| 짧은 설명 | data > product > shortDescription | HTML 문자열 | 텍스트로 쓰려면 BeautifulSoup으로 파싱 |
| 긴 설명 | data > idml > longDescription | HTML 문자열 | product 안이 아니라 idml에 있음 — 예전 튜토리얼이 자주 틀리는 함정 |
| 모든 이미지 | data > product > imageInfo > allImages | 배열 | {id, url} 객체 목록 |
| 평균 평점 | data > product > averageRating | 실수 | 키는 rating이 아니라 averageRating |
| 리뷰 수 | data > product > numberOfReviews | 정수 | — |
| 옵션 | data > product > variantCriteria | 배열 | 크기, 색상 같은 옵션 그룹 |
| 재고 상태 | data > product > availabilityStatus | 문자열 | IN_STOCK, OUT_OF_STOCK, LIMITED_STOCK |
| 판매자 | data > product > sellerDisplayName | 문자열 | — |
| 제조사 | data > product > manufacturerName | 문자열 | — |
longDescription 경로가 사람들이 자주 빠지는 함정이에요. 2023년 ScrapeHero 글은 product.longDescription에 있다고 했지만, 2024년 이후 자료들은 일관되게 형제 키인 idml에 넣어요. 항상 먼저 idml.longDescription을 읽고, 옛 페이지에 한해 product.longDescription으로 대체하세요.
.get() 체인을 사용한 안전한 추출 패턴은 아래와 같아요:
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }JSON 경로를 직접 다루고 싶지 않은 사용자라면, 가 이 필드를 자동으로 식별하고 구조화해 줘요. 수동 경로 매핑이 전혀 필요 없어요. “AI 필드 추천”을 누르면 페이지를 읽고 표를 만들어 줘요. 하지만 맞춤형 파이프라인을 만든다면, 위의 맵이 기준이 돼요.
3단계: 더 풍부한 데이터를 위해 Walmart의 내부 API 엔드포인트 가로채기
이 방법을 제대로 다룬 경쟁 글은 거의 없어요. 가장 강력한 추출 경로이지만, 가장 복잡하기도 해요.
Walmart 프런트엔드는 를 호출해요. 엔드포인트는 www.walmart.com/orchestra/* 아래에 있어요:
/orchestra/pdp/graphql/...— 상품 상세 하이드레이션 + 옵션 전환/orchestra/snb/graphql/...— 검색 및 탐색 페이지네이션/orchestra/reviews/graphql/...— 페이지가 나뉜 리뷰
이들은 __NEXT_DATA__가 가끔 잘라내는 데이터까지 포함한 깨끗하고 구조화된 JSON을 반환해요. 옵션별 가격, 실시간 재고 수량, 전체 리뷰 페이지네이션 같은 데이터죠.
블로그 글들이 빙빙 돌며 피하는 핵심 문제: Walmart는 를 사용해요. 요청 본문에는 쿼리 텍스트가 아니라 SHA-256 해시(persistedQuery.sha256Hash)만 들어가요. 서버가 그 해시를 모르면 PersistedQueryNotFound가 떠요. Walmart는 배포 때마다 이 해시를 바꿔요. 그래서 유명 오픈소스 Walmart 스크래퍼들이 /orchestra/ 코드를 그대로 붙여넣을 수 있게 공개하지 않는 거예요.
이 방법을 실용적으로, 솔직하게 쓰는 방식은 DevTools 연습이에요:
- Chrome에서 Walmart 상품 페이지를 엽니다
- DevTools → Network 탭을 열고 “Fetch/XHR”로 필터링합니다
- 페이지를 정상적으로 탐색합니다 — 옵션을 누르고, 리뷰까지 스크롤하고, 매장 위치를 바꿔 보세요
- 상품 데이터를 반환하는
/orchestra/*엔드포인트 요청을 찾습니다 - 요청을 오른쪽 클릭 → “Copy as cURL”을 선택합니다
curl_cffi를 사용해 cURL 명령을 Python으로 변환합니다
재생한 API 호출은 이렇게 생겼어요:
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# 먼저 상품 페이지를 방문해 세션을 워밍업합니다
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# 그런 다음 내부 API 호출을 재생합니다(DevTools에서 복사)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "복사해 둔 correlation-id",
14}
15payload = {
16 # DevTools에서 정확한 요청 본문을 붙여 넣으세요
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "복사한 해시값"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()세션 워밍업 단계가 정말 중요해요. Walmart의 PerimeterX 쿠키(_px3, _pxhd, ACID)는 API 호출이 성공하기 전에 초기 HTML 가져오기로 설정돼야 해요. 없으면 412나 403을 받게 돼요.
이 방법을 언제 써야 할까요? __NEXT_DATA__에 없는 데이터가 필요할 때예요. 상세 옵션 가격, 첫 배치 이상의 페이지가 있는 리뷰, 실시간 재고 수량 같은 경우죠. 대부분의 활용 사례에는 __NEXT_DATA__만으로도 충분하고 훨씬 간단해요.
Walmart 검색 결과와 여러 페이지 스크래핑하기
검색 결과도 비슷한 __NEXT_DATA__ 패턴을 따르지만, JSON 경로는 달라요:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# 광고 상품 제외
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))페이지네이션은 page 매개변수를 늘리면 돼요: &page=1, &page=2 식으로요. 하지만 문서화되지 않은 제한이 하나 있어요. Walmart는 실제 총 페이지 수와 상관없이 검색 결과를 25페이지로 제한해요. : “Walmart는 총 페이지 수와 관계없이 접근 가능한 결과 페이지 수의 최대치를 25로 설정해요.”
더 깊게 커버하려면 아래 우회법을 써요:
- 정렬 순서 바꾸기: 같은 검색어를
&sort=price_low와&sort=price_high로 각각 실행해 약 50페이지 분량 확보 - 가격 범위 분할:
&min_price=X&max_price=Y를 추가해 카탈로그를 더 작은 구간으로 나누기 - 카테고리 분할: 사이트 전체가 아니라 특정 카테고리 안에서 검색하기
itemStacks는 배열이라는 점도 기억하세요. Scrapfly는 레포에서 [0]을 하드코딩하지만, 카테고리와 탐색 페이지에는 종종 여러 스택(“Top picks”, “More results”)이 있어요. 더 견고한 패턴은 모든 스택을 순회하는 거예요:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # item 처리
5 pass또 하나 알아둘 점은 Walmart의 robots.txt가 한다는 거예요. 상품 상세 페이지(/ip/...)와 대부분의 카테고리 페이지(/cp/...)는 금지 대상이 아니에요. 준수 측면이 걱정된다면, 검색 페이지보다 상품 페이지와 카테고리 트리부터 시작하세요.
조용한 차단이 데이터를 망치지 않게 하세요: 운영용 오류 처리
대부분의 튜토리얼은 여기서 무너져요. 한 페이지를 가져오고, 한 상품을 파싱하고, 끝내거든요. 하지만 운영에서는 수천 페이지를 가져와야 하고, Walmart는 적극적으로 막으려 해요. 데모용 스크래퍼와 실제로 작동하는 스크래퍼의 차이는 실패를 어떻게 다루느냐에 있어요.
데이터가 오염되기 전에 조용한 차단 감지하기
Walmart 스크래퍼에서 가장 중요한 함수는 차단 감지기예요. , , , 의 공통된 견해를 바탕으로, 독립적인 4가지 검사를 해야 해요:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. 전용 차단 엔드포인트로 리디렉션됨
10 if "/blocked" in str(response.url):
11 return True
12 # 2. 명시적 상태 코드
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. CAPTCHA 본문이 포함된 200 OK(조용한 차단 사례)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. 응답 길이 점검 — 실제 PDP는 보통 300~900KB
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return False네 번째 검사인 응답 길이 확인은, 눈에 띄는 CAPTCHA 표시는 없지만 필요한 상품 데이터도 없는 축약 페이지를 Walmart가 줄 때를 잡아내요.
지수적 백오프와 지터를 포함한 재시도 로직
요청이 실패했을 때 바로 Walmart를 두드리면 안 돼요. 표준 패턴은 지수적 백오프와 지터를 사용해 재시도 타이밍을 분산시키는 거예요:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttled: \{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("조용한 차단 감지")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"시도 {attempt + 1} 실패: \{e\}. {wait:.1f}초 후 재시도합니다")
20 time.sleep(wait)
21 return None지터(random.uniform(0, 3))는 보기 좋으라고 넣는 게 아니에요. 여러 작업자가 같은 초에 동시에 재시도해 Akamai의 속도 감지기에 걸리는 걸 막기 위해서예요.
속도 제한
와 모두 Walmart에 대해서는 요청당 3~6초의 무작위 지연으로 수렴해요. “페이지를 불러올 때마다 3~6초 기다리고 지연 시간을 랜덤화하라”는 거예요.
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return response규모가 커지면 비동기 속도 제한을 위해 aiolimiter를 고려하세요:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 분당 10회 요청데이터 검증
응답이 차단되지 않았더라도, 파싱된 데이터가 틀릴 수 있어요(잘못된 매장, 저하된 페이로드). 출력에 쓰기 전에 검증하세요:
1def validate_product(product):
2 """상품 데이터가 그럴듯하면 True를 반환합니다."""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return True세션 로깅
세션별 성공률을 추적하세요. 10분 동안 80% 아래로 떨어지면 무언가 바뀐 거예요. IP가 소진됐거나, 쿠키가 만료됐거나, Walmart가 새로운 안티봇 규칙을 배포했을 수 있어요.
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"성공률이 {self.success_rate:.1f}%로 떨어졌어요 — 프록시를 교체하거나 잠시 멈추는 것을 고려하세요")멋져 보이진 않아요. 하지만 데이터를 깨끗하게 유지해 줘요.
직접 Python으로 할까, 스크래핑 API를 쓸까, 노코드를 쓸까: Walmart 스크래핑 방식 고르기
많은 개발자들이 이게 맞는 선택인지 묻지 않고 곧바로 맞춤형 스크래퍼를 만들기 시작해요. 해요. 포럼 사용자들도 “기본적으로 9/10”이라고 말하면서 “전용 웹 스크래핑 API가 과한가?”를 고민하죠. 답은 물량, 예산, 엔지니어링 역량에 달려 있어요.
| 요소 | DIY Python(requests + 프록시) | 스크래핑 API(Oxylabs, Bright Data 등) | 노코드 도구(Thunderbit) |
|---|---|---|---|
| 첫 행까지 걸리는 설정 시간 | 몇 시간 | 15~60분 | 약 2분 |
| 운영 가능 상태까지 걸리는 시간 | 40~80시간 | 4~16시간 | 약 30분 |
| 안티봇 처리 | 직접 관리(어려움) | 제공업체가 처리 | 자동 처리 |
| 소규모 비용(<월 1K 페이지) | 낮음(프록시 비용 약 $4~8/GB) | $40~$49/월 시작 요금 | 무료~$15/월 |
| 대규모 비용(월 10만+ 페이지) | 요청당 더 저렴 | 요청당 더 비쌈 | 달라짐 |
| 커스터마이징 | 완전 제어 | API 매개변수 | UI/필드 범위 내 제한 |
| 지속 유지보수 | 월 4~8시간 | 거의 없음 | 없음(AI가 적응) |
| 가장 적합한 대상 | 맞춤형 파이프라인을 만드는 개발자 | 중간 규모 운영 스크래핑 | 비즈니스 사용자, 빠른 단발성 추출 |
DIY Python이 맞는 경우
이미 프록시 계약이 있고, 헤더, 우편번호 타겟팅, 판매자 집단을 엄격하게 제어해야 하거나, 월 수백만 페이지를 인덱싱해서 레코드당 API 요금이 쌓일 때, 혹은 온프레미스나 컴플라이언스 보장이 필요할 때 DIY가 유리해요. 대신 실제 엔지니어링 시간이 들어가요. 페이지네이션, 재시도, 프록시 로테이션, TLS 위장, 여러 페이지 유형 스키마를 갖춘 운영용 Scrapy 스파이더는 이 걸리고, Walmart가 핑거프린트를 바꿀 때마다 월 4~8시간의 유지보수도 필요해요.
스크래핑 API가 시간을 절약해 주는 경우
스크래핑 API는 안티봇 계층을 대신 처리해 줘요. 에 따르면 Walmart에서 , **Scrape.do는 98%**의 성공률을 보여요. , , 같은 도구의 입문 요금은 월 $40~$49 수준이에요. 엔지니어 2~5명 규모의 팀이고 월 1만~100만 페이지를 스크래핑한다면, API가 거의 항상 맞는 선택이에요. 요청당 비용을 내는 대신 유지보수는 거의 없애는 거죠.
노코드가 맞는 경우
는 완전히 다른 유형에 맞아요. 이번 오후 안에 — 다음 스프린트가 아니라 — Walmart 상품 데이터를 스프레드시트로 가져와야 하는 PM, 애널리스트, 이커머스 운영자라면, 노코드 도구가 솔직한 답이에요.
작업 흐름은 이렇습니다. 을 설치하고, Walmart 상품 또는 검색 페이지로 이동한 뒤, “AI 필드 추천”을 클릭하세요. 그러면 Thunderbit의 AI가 페이지를 읽고 상품명, 가격, 평점 같은 열을 제안해 줘요. “스크래핑”을 누르면 데이터가 표로 채워져요. Excel, Google Sheets, Airtable, Notion으로 모두 무료 내보내기가 가능해요. 결제벽도 없어요.
Thunderbit는 클라우드에서 안티봇을 처리하므로 CAPTCHA, 프록시, TLS 핑거프린팅을 직접 다룰 필요가 없어요. AI가 레이아웃 변경에 자동으로 적응하므로 유지보수도 없어요. JSON 경로를 아예 다루고 싶지 않은 사용자에게는 가장 부담이 적은 경로예요.
솔직한 한계도 있어요. Thunderbit는 하루 10만+ 페이지용으로 만들어진 도구는 아니에요. 크레딧 예산과 클라우드 상한 때문에 대량 수집은 원시 API보다 경제적이지 않을 수 있어요. 또, 도구가 지원하지 않는 한 특정 우편번호나 ASN을 고정할 수도 없어요. 지속적이고 대규모인 파이프라인이라면 DIY나 스크래핑 API가 여전히 더 적합해요.
대략적인 비용 계산: Thunderbit로 Walmart 상품 1,000행을 스크래핑하면 대략 2,000 크레딧이 필요하고, Starter/Pro 요금제 기준 약 $0.60~$1.10 정도예요. 낮은 물량에서는 Oxylabs의 Walmart API와 비슷하고, 대부분의 저가형 스크래핑 API보다 저렴해요. 최신 내용은 를 확인하세요.
스크래핑한 Walmart 데이터 내보내기
데이터를 얻었다면, 이제 유용한 곳에 저장해야 해요. 보통은 세 가지 형식이면 충분해요:
CSV — 분석가들이 실제로 여는 가장 기본적인 형식이에요:
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Excel 호환을 위해 utf-8-sig 인코딩을 사용하세요. BOM 마커가 Excel의 문자 깨짐을 막아 줘요.
JSONL — 스크래핑 파이프라인의 운영 표준 형식이에요:
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(쓰기 도중 중단돼도 마지막 줄만 잃음), 일정한 메모리로 스트리밍할 수 있고, 옵션과 리뷰 같은 중첩 데이터도 그대로 유지해 줘요.
Excel — 한 번 넘기는 분석용이에요:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["이름", "가격", "재고 상태", "평점", "리뷰 수", "판매자"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)Thunderbit는 Python을 쓰지 않는 사용자에게도 내보내기 흐름을 제공해요. Google Sheets, Airtable, Notion, Excel, CSV, JSON으로 한 번에 내보낼 수 있고, 기본 요금제에서는 모두 무료예요. 지속적 모니터링이 필요하다면 Thunderbit의 예약 스크래퍼 기능으로 반복 추출도 자동 실행할 수 있어요.
스케줄링에서 한 가지 주의점이 있어요. . GitHub Actions 러너는 Walmart의 안티봇이 즉시 차단하는 Azure IP 대역에 있어요. VPS에서 APScheduler를 쓰거나, 모든 트래픽을 주거용 프록시로 보내세요.
Walmart 스크래핑의 법적·윤리적 가이드라인
포럼 사용자들도 이 점을 분명히 걱정해요. “개발자들과 숨바꼭질하는 건 괜찮지만, 법무팀과 상대하는 건 조심스럽다”는 식이죠.
Walmart 이용약관은 해요. “사전 서면 동의 없이” 어떤 로봇, 스파이더, 기타 수동/자동 장치를 사용해 자료를 가져오고, 인덱싱하고, ‘scrape’하거나, ‘data mine’하거나, 기타 방식으로 수집하는 행위를 금지하죠.
Walmart의 robots.txt는 , /account, /api/, 그리고 수십 개의 내부 엔드포인트를 해요. 상품 상세 페이지(/ip/...)와 리뷰(/reviews/product/)는 금지 대상이 아니에요.
hiQ 대 LinkedIn 판례(제9연방순회항소법원, )는 공개적으로 접근 가능한 데이터의 스크래핑이 연방 CFAA를 위반하지 않을 가능성이 높다고 정리했어요. 하지만 같은 법원은 나중에 고 판결하고, 을 내렸어요. 더 최근인 2024년 판결들(, )은 CFAA 적용 범위를 더 좁히고 저작권 선점 방어를 인정했지만, 그 판결들은 Walmart에 깔끔하게 대응되지 않는 특정 이용약관 문구에 좌우됐어요.
실무 지침: 서버를 과도하게 누르지 마세요. 속도 제한을 지키세요. 개인 정보나 사용자 데이터를 스크래핑하지 마세요. 데이터를 책임 있게 사용하세요. 개인 연구 목적으로 공개 Walmart 상품 페이지를 적당한 속도로 스크래핑하는 것과, Walmart 약관을 상대로 상업 규모로 추출하는 것은 전혀 다른 위험 프로필이에요. Walmart 데이터를 기반으로 제품을 만들 계획이라면, 변호사와 상의하고 Walmart의 공식 도 살펴보세요.
면책 고지: 이 내용은 교육용 정보이며, 법률 자문이 아니에요.
결론과 핵심 요약
Python으로 Walmart를 스크래핑하는 일은 이중 방어 체계인 Akamai + PerimeterX 때문에 수준이에요. 불가능한 건 아니지만, 올바른 도구와 패턴이 필요해요.
핵심 요약:
- 대부분의 경우
__NEXT_DATA__JSON 추출이 가장 현실적인 선택이에요. 2024~2026년의 진지한 오픈소스 Walmart 스크래퍼들이 모두 쓰는 방식이죠. PDP의 기본 경로는props.pageProps.initialData.data.product, 검색/탐색은searchResult.itemStacks예요. impersonate="chrome124"를 사용하는curl_cffi는 필수예요. 일반requests나httpx는 헤더와 상관없이 Akamai의 TLS 핑거프린팅을 통과할 수 없어요.- 진짜 위험은 조용한 차단이에요. Walmart는 CAPTCHA 본문과 함께 200 OK를 반환해요. 상태 코드만 보지 말고 응답 내용을 확인하세요.
- 운영용 스크래퍼에는 성공 경로 코드만으로는 부족해요. 지터가 있는 지수적 백오프, 4가지 신호를 이용한 차단 감지, 요청당 3~6초 속도 제한, 데이터 검증, 세션 상태 모니터링이 모두 필수예요.
/orchestra/*를 통한 내부 API 가로채기는 강력하지만 취약해요. 주요 추출 방식이 아니라, 특정 데이터가 필요할 때 DevTools 연습용으로 쓰세요.- Walmart는 검색 결과를 25페이지로 제한해요. 정렬 순서 변경과 가격 범위 분할로 더 넓게 커버하세요.
- 솔직하게 방식을 고르세요: 맞춤형 요구와 대량 처리에는 DIY Python. 스크래핑 엔지니어가 없는 중간 규모 팀에는 스크래핑 API. 오늘 오후에 Google Sheets로 데이터를 가져오고 싶은 비즈니스 사용자에게는 가 적합해요.
노코드 방식을 시험해 보고 싶다면, 에는 무료 플랜이 있어요. Walmart 페이지 몇 개를 스크래핑해 결과를 직접 확인할 수 있죠. Python 경로를 택한다면, 이 글의 코드 패턴은 운영 환경에서 검증된 것들이에요. 어느 쪽이든 이제 Walmart의 방어 체계와 그 안을 통과하는 세 가지 길을 알게 된 셈이에요.
웹 스크래핑 기법을 더 배우고 싶다면, , , 가이드를 확인해 보세요. 에서 튜토리얼도 볼 수 있어요.
자주 묻는 질문
Walmart 상품 데이터를 스크래핑하는 것은 합법인가요?
Walmart 이용약관은 서면 동의 없는 자동 스크래핑을 금지해요. 제9연방순회항소법원의 hiQ 대 LinkedIn 판결(2022)은 연방 CFAA가 공개 페이지 스크래핑에 적용될 가능성이 낮다고 정리했지만, 같은 사건은 스크래퍼에 대한 로 끝났어요. 개인 연구 목적으로 공개 상품 페이지를 적당한 속도로 스크래핑하는 것과, 상업 규모로 추출하는 것은 위험도가 전혀 달라요. Walmart 데이터를 기반으로 사업을 만들고 있다면 변호사와 상의하세요.
왜 제 Walmart 스크래퍼는 계속 차단되나요?
가장 흔한 원인은 일반 requests나 httpx 사용(Python 고유의 TLS 핑거프린트가 Akamai에 바로 걸림), 잘못됐거나 누락된 헤더, 프록시 로테이션 없음, 페이지당 3~6초보다 빠른 요청 속도, 세션 쿠키(_px3, _abck, locDataV3) 누락이에요. 이 글에서 설명한 impersonate="chrome124"의 curl_cffi로 바꾸고, 주거용 프록시를 사용하며, 차단 감지와 재시도 패턴을 구현하세요.
Python으로 Walmart에서 어떤 데이터를 스크래핑할 수 있나요?
상품명, 가격(현재가 및 할인 전 가격), 이미지, 짧은 설명과 긴 설명, 평점, 리뷰 수, 재고 상태, 판매자 이름, 제조사 정보, 옵션(사이즈, 색상), 카테고리 위치를 가져올 수 있어요. __NEXT_DATA__ 방식을 쓰면 이 모든 정보가 구조화된 JSON으로 제공돼요. 내부 API 가로채기를 사용하면 옵션별 가격, 실시간 재고 수량, 페이지가 나뉜 리뷰 데이터도 추가로 얻을 수 있어요.
Walmart를 스크래핑하려면 프록시가 필요한가요?
네, 운영 환경이나 반복 사용에서는 필요해요. 해요. 헤더를 완벽하게 맞춰도 비주거용 IP는 Akamai의 IP 평판 시스템에 걸려요. 주거용 또는 모바일 프록시가 필요하고, 데이터센터 IP는 거의 즉시 소진돼요. 프록시 제공업체와 요금제에 따라 1,000페이지당 대략 $3~$17를 예상하면 돼요.
코드 없이 Walmart를 스크래핑할 수 있나요?
네. 는 AI 기반 Chrome 확장 프로그램으로 Walmart를 두 번의 클릭으로 스크래핑해요. “AI 필드 추천”으로 상품 데이터 열을 자동 감지하고, 이어서 “스크래핑”으로 데이터를 추출하죠. 안티봇 챌린지는 클라우드에서 처리하고, Excel, Google Sheets, Airtable, Notion으로 바로 내보낼 수 있어요 — 모두 무료예요. 빠르게 데이터를 얻어야 하는 애널리스트, PM, 비즈니스 사용자에게 가장 적합하고, 맞춤형 파이프라인이 필요하거나 고도로 커스터마이즈된 스크래핑에는 Python이나 스크래핑 API가 더 잘 맞아요.
더 알아보기