Redfin은 미국 신규 MLS 매물의 합니다. 이렇게 빠르게 데이터가 갱신된다는 건, 부동산 데이터 파이프라인을 만드는 사람이라면 누구나 눈독 들일 만한 포인트죠. 바로 그 이유 때문에, 많은 스크래퍼가 Redfin을 건드렸다가 몇 분 만에 차단당하곤 합니다.
저는 에서 데이터 추출 도구를 오래 만들어 왔습니다. 그래서 자신 있게 말할 수 있습니다. “Redfin을 크롤링하는 방법”과 “차단 안 당하고 Redfin을 크롤링하는 방법” 사이의 간극에서 대부분의 튜토리얼은 무너집니다. 보통은 BeautifulSoup 코드만 보여주고, Cloudflare가 요청을 막아버리는 핵심 구간은 슬쩍 넘긴 채, 결국 403 페이지만 멍하니 보게 만들죠. 이 가이드는 다릅니다. HTML 파싱, Redfin의 숨겨진 API, 그리고 Thunderbit을 활용한 노코드 방식까지 세 가지 실전 접근법을 소개하고, 특히 중요한 안티봇 방어 전략을 깊게 다룹니다. 끝까지 읽으면, 자신의 기술 수준, 필요한 규모, 그리고 유지보수에 들일 수 있는 수고에 맞는 방법이 무엇인지 정확히 알 수 있을 겁니다.
Redfin이란 무엇이며, 왜 그 데이터가 중요한가?
Redfin은 기술 기반 부동산 중개 플랫폼으로, 급여를 받는 에이전트가 MLS 피드에서 매물 정보를 직접 가져옵니다. 를 커버하고, 월간 방문자 수는 거의 5천만 명에 이릅니다. 단순 집계형 포털과 달리, Redfin의 데이터는 에이전트 검증을 거치며, 독자적인 Redfin Estimate AVM은 을 대상으로 하고, 시장에 나온 매물 기준 중앙값 오차가 1.96%에 불과합니다.
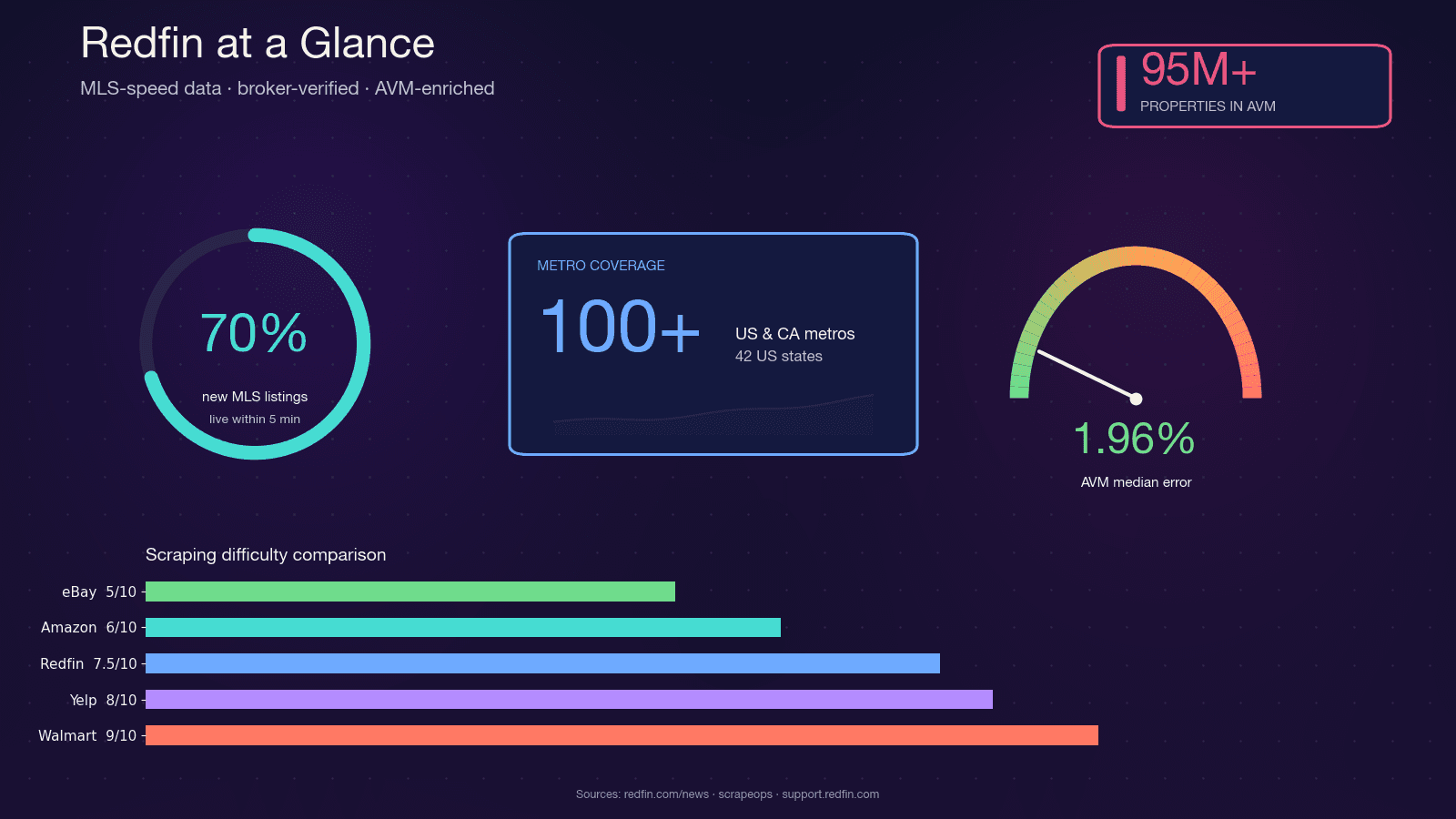
이처럼 MLS급 속도의 갱신, 중개사 검증 품질, 정교한 AVM이 결합되어 있어서, 부동산 투자자, 에이전트, 프롭테크 스타트업, 데이터 분석가 모두 Redfin 데이터에 프로그래매틱하게 접근하고 싶어 합니다. Python이 자연스러운 선택인 이유도 분명합니다. requests, BeautifulSoup, Selenium, Playwright 같은 스크래핑 생태계가 잘 갖춰져 있고, 커뮤니티 지원도 탄탄하며, pandas와 Jupyter로 바로 분석까지 이어갈 수 있기 때문입니다.
왜 Python으로 Redfin을 크롤링해야 할까?
활용 사례는 데이터를 필요로 하는 사람만큼이나 다양합니다. 아래는 서로 다른 사용자들이 Redfin 데이터를 어떻게 활용하는지 보여주는 예시입니다.
| 대상 | 주요 수집 목적 | 활용 예시 |
|---|---|---|
| 부동산 에이전트 | 리드 생성, 시장 인사이트 | 서비스 지역의 신규 매물 및 만료 매물, 경쟁사 벤치마킹용 에이전트 디렉터리 |
| 부동산 투자자 | 딜 파이프라인, 캡레이트 분석 | 임대 수익률 검토, 저평가 매물 탐지, 신규 매물 일일 알림 |
| 프롭테크 스타트업 | 제품용 데이터 파이프라인 | AVM 학습 데이터, 시장 대시보드, iBuyer 매입 엔진 |
| 데이터 분석가 | 시장 조사, BI | ZIP 코드별 중간 가격 추세, 시장 체류 기간 시계열, 매매가 대비 호가 비율 |
| 홀세일러 / 플리퍼 | 어려운 매물 추적 | 가격 인하 탐지, 압류 물건, 오프마켓 비교 사례 |
더 큰 흐름도 이를 뒷받침합니다. 이 이미 예측 분석으로 기회를 찾고 리스크를 관리하고 있습니다. 또한 프롭테크 시장은 2025년에 규모, 연평균 성장률 16.4%에 이를 것으로 예상됩니다. 이제 구조화된 부동산 데이터는 있으면 좋은 수준이 아니라, 사실상 기본 전제입니다.
크롤링 가능한 Redfin 데이터 필드 전체 목록
코드를 한 줄도 쓰기 전에, 실제로 무엇을 가져올 수 있는지 먼저 알아야 합니다. 저는 Redfin의 검색 결과 페이지, 매물 상세 페이지, 에이전트 프로필을 직접 살펴봤고, , 같은 오픈소스 Stingray API 래퍼도 함께 확인했습니다. 그 결과 페이지 유형 전체를 합치면 117개의 고유 필드가 나옵니다.
이 표는 북마크해 둘 만합니다. 코딩 전에 데이터 스키마를 먼저 이해하면 셀렉터 찾느라 허비하는 시간을 크게 줄일 수 있습니다.
검색 결과 페이지 필드
이 값들은 매물 카드에 바로 보이는 가벼운 필드들로, 전체 JS 렌더링 없이도 추출 가능한 경우가 많습니다.
| 필드 | 데이터 유형 | 비고 |
|---|---|---|
| Property ID | Number | Redfin 내부 정수값, href의 /home/{id}에서 추출 |
| List price | Number | |
| Full address | Text | |
| Beds / Baths / SqFt | Number | 순서대로 3개 값 |
| Property type | Single Select | SFH, Condo, Townhouse, Multi |
| Status | Text | Active, Pending, Contingent |
| Days on market | Number | |
| Price cut indicator | Number | 최초 호가 대비 차이 |
| Primary photo | Image URL | 카드당 사진 1장 |
| Hot Home badge | Boolean | |
| Open house date/time | Text | |
| Brokerage attribution | Text |
매물 상세 페이지 필드
상세 페이지에는 진짜 핵심 정보가 들어 있습니다. 이 중 상당수는 JavaScript 렌더링이나 Stingray API가 필요합니다.
| 필드 | 데이터 유형 | 비고 |
|---|---|---|
| Redfin Estimate (on-market) | Number | /stingray/api/home/details/avm 통해 제공 |
| Redfin Estimate (off-market) | Number | /stingray/api/home/details/owner-estimate 통해 제공; 중앙값 오차 7.52% |
| Year built / renovated | Number | |
| Lot size | Number | |
| HOA dues | Number | 해당되는 경우 월 단위 |
| Property tax (annual) | Number | |
| Tax assessed value | Number | |
| Sale history table | Table | 가격, 날짜, 이벤트 유형 |
| Property description | Text | 마케팅용 설명문 |
| Photo URLs (carousel) | Image URLs | 매물당 20장 이상 |
| Listing agent name, phone, email | Text / Phone / Email | 전화번호는 종종 마스킹됨 |
| School ratings (elementary/middle/high) | Number | 학군명 포함 |
| Walk / Transit / Bike Score | Number | |
| Climate risk scores | Number | 홍수, 화재, 폭염, 강풍 |
| Similar active / sold / nearby homes | URLs | 캐러셀 데이터 |
| Parking, garage, heating, cooling | Text | 편의시설 그룹 |
에이전트 프로필 필드
| 필드 | 데이터 유형 | 비고 |
|---|---|---|
| Agent name, photo, brokerage, bio | Text / Image | |
| Phone, contact form | Phone / Text | 클릭하면 노출 |
| Active listings count | Number | |
| Sales last 12 months / total volume | Number | |
| Avg list-to-sale ratio | Number | |
| Star rating / review count | Number | |
| Years of experience / license # | Text / Number |
Thunderbit의 AI Suggest Fields 기능을 Redfin 페이지에서 사용하면, 이런 컬럼 대부분을 자동으로 감지하고 알맞은 데이터 유형까지 알아서 지정합니다. CSS 셀렉터를 하나하나 맞출 필요가 없습니다. 이 부분은 뒤에서 더 자세히 설명하겠습니다.
Redfin의 안티봇 방어, 제대로 해부하기("프록시 쓰세요" 수준이 아님)
많은 튜토리얼이 차단 문제를 대충 넘기고 바로 “스폰서에게서 프록시를 사세요”로 넘어가는데, 그건 별 도움이 안 됩니다. Redfin이 스크래퍼를 어떻게 잡아내는지 이해하지 못하면, 프록시 비용만 태우고 결국 또 막히게 됩니다. 으로 평가하고, 으로 분류합니다. 즉, “Zillow의 엔터프라이즈 WAF만큼 공격적이진 않지만, 커스텀 레이트 리미팅과 JavaScript 챌린지를 쓴다”는 뜻입니다.
Redfin은 여러 겹의 방어 체계를 돌립니다. 엣지에서는 Cloudflare가 JS 챌린지, Turnstile, TLS/JA3 핑거프린팅을 처리하고, 애플리케이션 계층에서는 Redfin 전용 레이트 리미터가 작동합니다. robots.txt에는 Crawl-delay 지시문이 없는데, 실제 차단은 WAF 레벨에서 일어나기 때문입니다.
왜 단순한 requests + BeautifulSoup는 Redfin에서 실패하는가
기본 헤더만 넣은 requests.get()으로 Redfin 매물 페이지를 요청하면, 보통 아래 중 하나가 발생합니다.
- HTTP 403 — Cloudflare의 JS 챌린지를 통과하지 못해, 매물 대신 챌린지 페이지만 받는 경우
- 중간 챌린지 페이지(interstitial) — HTML 본문에 매물 데이터 대신 Cloudflare Turnstile 위젯이 들어 있는 경우
- HTTP 200이지만 HTML이 일부만 있음 —
root.__reactServerState.InitialContext아래에 큰 JSON 블롭은 있지만, 미리 렌더링된 검색 카드, 가격 기록, 학교 평점은 없는 경우
Redfin은 자체 를 사용합니다(Next.js가 아닙니다). 그리고 hydration 키도 Redfin 특유의 구조인 root.__reactServerState.InitialContext이며, 매물 데이터는 ReactServerAgent.cache.dataCache 아래에 중첩됩니다. 즉, __NEXT_DATA__도 아니고, window.__INITIAL_STATE__도 아닙니다.
조용한 403의 가장 흔한 원인 하나는? Sec-Fetch-* 헤더 누락입니다. Redfin/Cloudflare는 Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest, Sec-Fetch-User를 명시적으로 검증합니다. 이 헤더들이 없으면 바로 의심 대상으로 분류됩니다.
대응 전략: 딜레이, 헤더, 프록시, 세션
아래는 방어 요소별 분석과 각각의 대응 방법입니다.
| Redfin 방어 요소 | 동작 방식 | 탐지 신호 | 대응 전략 |
|---|---|---|---|
| Cloudflare JS challenge | cf_clearance 쿠키를 발급하는 중간 페이지 | 403 + Cloudflare HTML 본문 | curl_cffi와 impersonate="chrome120"; 홈페이지로 세션 예열; 미국 리저널 프록시 |
| Cloudflare Turnstile | 위험도가 높은 세션에 띄우는 인터랙티브 CAPTCHA | 403 + Turnstile 위젯 | 스텔스 기능이 있는 헤드리스 브라우저 + 리저널 프록시 |
| Cloudflare Error 1020 (ASN 차단) | WAF에서 의심 IP/ASN 차단 | 본문에 "Error 1020 Access Denied" | 리저널/모바일 프록시로 전환; 데이터센터 ASN은 사용 금지 |
| TLS/JA3 핑거프린팅 | 브라우저가 아닌 TLS 스택 탐지 | 헤더가 완벽해도 조용히 403 | curl_cffi 임퍼서네이션 또는 실제 브라우저 |
| HTTP/2 핑거프린팅 | HTTP/2 SETTINGS, HPACK 순서 확인 | 조용한 차단 | curl_cffi는 Chrome처럼 HTTP/2를 사용 |
| 헤더 검증 (UA, Sec-Fetch-*) | 브라우저와 일치하는 헤더 집합 확인 | 첫 요청에서 403 | Sec-Fetch-Site/Mode/Dest/User 포함한 완전한 Chrome 헤더, 현실적인 Referer |
| 쿠키/세션 연속성 | cf_clearance, RF_BROWSER_ID 추적 | 깊은 URL을 바로 치면 챌린지 발생 | 지속 세션 사용; 먼저 홈페이지 방문 |
| 앱 계층 레이트 제한 | IP별 요청 제한 | 429 | 2~5초 지연 + 지터; 지수 백오프 |
| 데이터센터 IP 평판 | 알려진 DC ASN 차단 | 즉시 1020/403 | 미국 리저널 또는 모바일 프록시만 사용 |
| 동시성 탐지 | 한 IP에서 여러 요청이 병렬 발생 | 갑작스러운 Turnstile 강화 | IP당 동시 요청은 2개 이하 |
커뮤니티 테스트에서 확인된 실전 기준:
- 안전한 속도: IP당 2~3초에 1회 요청
- 단일 데이터센터 IP에서 분당 20~30회 이상 지속되면 몇 분 내 챌린지 발생
- 트래픽이 멈추면 소프트 레이트 리밋은 5~15분 안에 해제
- 데이터센터 IP 차단(AWS, GCP, Azure, OVH)은 수시간에서 수일까지 지속될 수 있음
기본 Python requests(urllib3 + OpenSSL)는 를 만들어내며, 헤더가 완벽해도 조용히 차단당할 수 있습니다. 업계에서 흔히 쓰는 해결책은 **curl_cffi와 impersonate="chrome120"**를 사용하는 것입니다. 이렇게 하면 Chrome에 맞는 TLS와 HTTP/2를 흉내 낼 수 있습니다.
Python으로 Redfin을 크롤링하는 세 가지 방법(그리고 무엇을 선택할지)
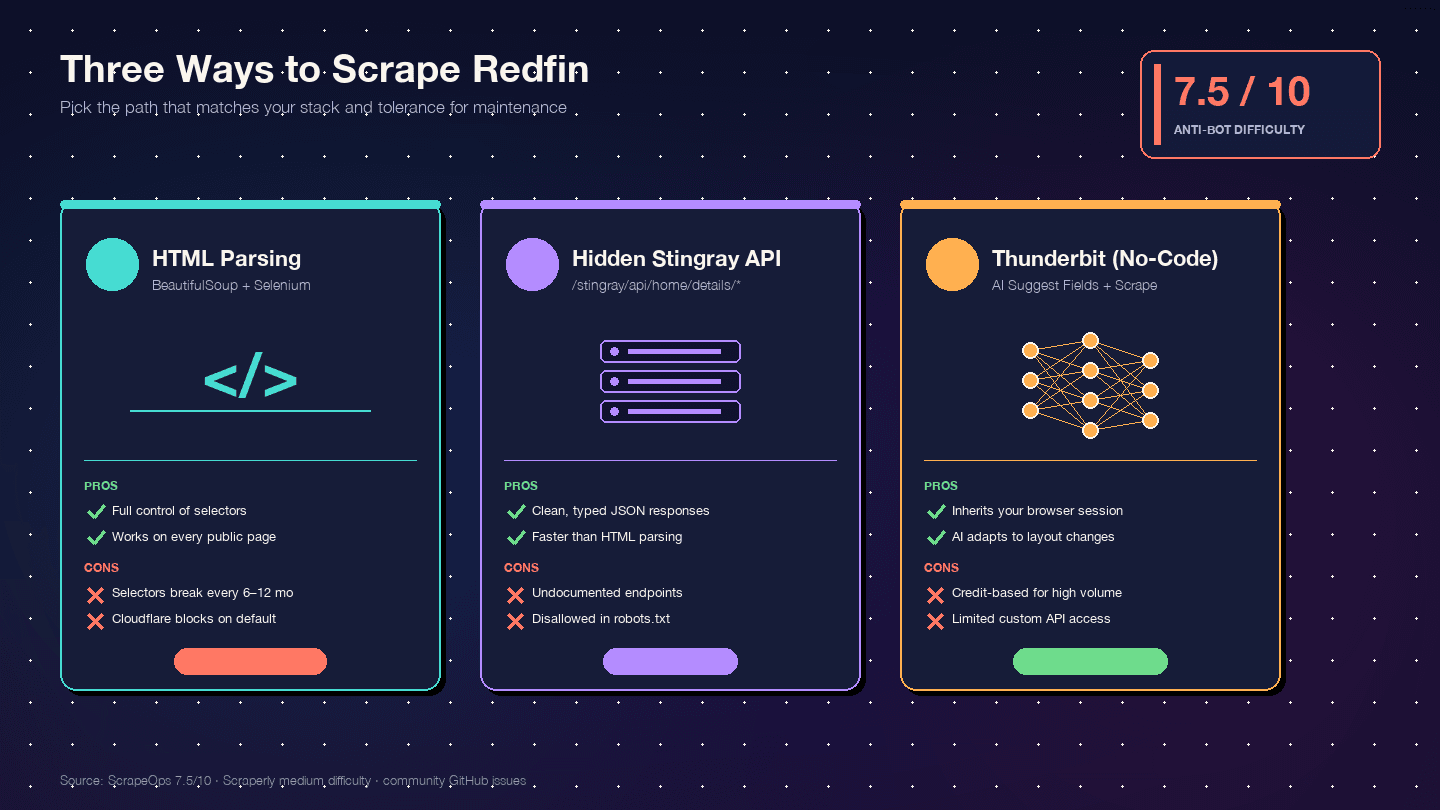
세 가지 접근법을 한눈에 비교한 튜토리얼은 거의 못 봤습니다. 아래가 의사결정 표입니다.
| 기준 | HTML 파싱(BS4 + Selenium) | Stingray 숨은 API | Thunderbit(노코드) |
|---|---|---|---|
| 설정 난이도 | 중간(Python 환경 + 브라우저 드라이버) | 높음(엔드포인트 리버스 엔지니어링) | 낮음(Chrome 확장 설치) |
| 안티봇 리스크 | 높음(DOM 요청이 가장 눈에 띔) | 중간(API형 요청은 더 깔끔함) | 가장 낮음(실제 브라우저 세션 사용) |
| 데이터 구조 품질 | 중간(비정형 HTML → 수동 파싱) | 매우 우수(이미 구조화된 JSON) | 높음(AI가 필드와 타입 자동 감지) |
| 유지보수 부담 | 높음 — 레이아웃이 바뀌면 셀렉터가 깨짐 | 중간 — 예고 없이 엔드포인트가 바뀔 수 있음 | 가장 낮음 — AI가 레이아웃 변화에 적응 |
| 확장성 | 낮음~중간(프록시를 쓰면 수백 건 가능) | 중간~높음(수천 건, 더 깔끔한 요청) | 중간(클라우드 스크래핑으로 배치당 50페이지) |
| 적합한 사용자 | 완전한 제어를 원하는 개발자 | 깔끔한 JSON이 필요한 개발자 | 비개발자, 빠른 프로젝트, 개발 리소스 없이 지속적 데이터가 필요한 경우 |
유지보수 관점은 특히 중요합니다. Redfin은 카드 DOM을 두 세대에 걸쳐 바꿔 왔습니다. 예전에는 homecardV2Price, 지금은 span.bp-Homecard__Price--value를 씁니다. GitHub 이슈 기록을 보면 CSS 셀렉터가 깨지는 주기가 대략 6~12개월입니다. 이런 일이 생기면 BeautifulSoup 스크래퍼는 하룻밤 사이에 고장납니다. 반면 AI 기반 필드 감지 방식은 스스로 적응합니다.
시작하기 전에
- 난이도: 중급(방법 1 & 2), 초급(방법 3)
- 소요 시간: 방법 1 또는 2는 약 30분, 방법 3은 약 5분
- 준비물:
- Python 3.8+ 및 pip(방법 1 & 2)
- Chrome 브라우저(모든 방법)
- (방법 3)
- 대규모 수집 시 미국 리저널 프록시(방법 1 & 2)
방법 1: HTML 파싱으로 Python에서 Redfin 크롤링하기(BeautifulSoup + Selenium)
이 방법은 “완전 제어” 방식입니다. 셀렉터는 직접 쓰고, 브라우저는 직접 관리하고, 에러도 직접 처리합니다.
가장 교육적인 방법이기도 하지만, 동시에 가장 쉽게 깨지는 방법이기도 합니다.
1단계: Python 환경 설정하기
가상 환경을 만들고 필요한 라이브러리를 설치합니다.
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # Windows에서는: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cffi여기서 curl_cffi는 사실상 필수입니다. 이 라이브러리가 있어야 HTTP 요청이 Cloudflare에 바로 막히는 기본 Python requests 지문이 아니라, 실제 Chrome TLS 지문처럼 동작할 수 있습니다.
2단계: 브라우저 헤더와 세션 구성하기
이 단계에서 초보자 대부분이 막힙니다. Redfin/Cloudflare가 명시적으로 검증하는 Sec-Fetch-* 헤더를 포함한 완전한 Chrome 헤더 세트가 필요합니다.
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# 세션 예열 — cf_clearance와 RF_BROWSER_ID 쿠키 확보
17session.get("https://www.redfin.com/")세션 예열은 정말 중요합니다. 쿠키도 없고 Referer도 없는 상태에서 깊은 매물 URL을 바로 열면 Cloudflare 점수에서 불리해집니다.
항상 홈페이지부터 시작하세요.
3단계: Redfin 검색 결과 크롤링하기
세션을 예열한 뒤에는 도시 검색 페이지를 가져와 매물 카드를 파싱할 수 있습니다. 현재 세대 셀렉터(2024–2026 기준)는 다음과 같습니다.
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # 1~5페이지
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"페이지 {page_num}에서 차단됨: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # 2~5초의 랜덤 지연
28 time.sleep(random.uniform(2, 5))
29print(f"{len(listings)}개의 매물을 수집했습니다")각 San Francisco 매물의 가격, 주소, 침실/욕실/면적, 상세 URL이 담긴 딕셔너리 리스트가 쌓이는 걸 볼 수 있습니다. 만약 카드가 0개라면 HTTP 상태 코드를 먼저 확인하세요. 403이면 Cloudflare가 막은 것이고, 리저널 프록시가 필요할 가능성이 큽니다.
4단계: 개별 매물 상세 페이지 크롤링하기
검색 결과는 기본 정보만 줍니다. 상세 페이지에는 Redfin Estimate, 준공 연도, HOA, 매매 기록, 에이전트 정보, 사진이 들어 있습니다. 이런 페이지는 JavaScript 렌더링이 필요하므로 Selenium으로 전환합니다.
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # 처음 10개만 보강
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # JS 렌더링 대기
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()이 단계가 끝나면 처음 10개 매물에 Redfin Estimate와 준공 연도 정보가 보강되어 있어야 합니다. 중첩된 편의시설 필드에는 CSS보다 XPath가 더 견고하지만, 그래도 DOM 구조가 바뀌면 깨질 수밖에 없습니다.
5단계: 차단과 오류 처리하기
지수 백오프가 포함된 재시도 로직을 구현하세요.
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"차단됨({resp.status_code}). {wait:.1f}초 후 재시도...")
10 time.sleep(wait)
11 else:
12 print(f"예상치 못한 상태 코드: {resp.status_code}")
13 break
14 return None차단당했다는 신호는 다음과 같습니다. 본문에 Cloudflare HTML이 포함된 HTTP 403, HTTP 429(명시적 레이트 리밋), 빈 응답 본문, 또는 페이지 내용에 "Error 1020 Access Denied"가 나타나는 경우입니다. 이런 현상이 계속되면 리저널 프록시를 추가하거나 API 방식으로 전환할 때입니다.
방법 2: 숨겨진 Stingray API로 Python에서 Redfin 크롤링하기
제가 가장 선호하는 방식입니다. Redfin 프런트엔드는 내부 JSON API인 /stingray/api/home/details/*와 통신하며, 응답은 깔끔한 타입화 JSON으로 돌아옵니다. HTML 파싱이 전혀 필요 없습니다.
Redfin의 숨은 API 엔드포인트를 찾는 방법
Chrome DevTools → Network 탭 → Fetch/XHR로 필터링 → 아무 Redfin 매물 페이지로 이동해 보세요. 다음 같은 엔드포인트 요청을 볼 수 있습니다.
api/home/details/initialInfo— URL → propertyId, listingId 매핑api/home/details/aboveTheFold— 가격, 침실, 욕실, 면적, 사진, 상태, 에이전트, MLS 번호api/home/details/belowTheFold— 편의시설, HOA, 세금, 주차, 준공 연도, 대지, 이력api/home/details/avm— 시장 내 Redfin Estimateapi/home/details/owner-estimate— 시장 외 Redfin Estimateapi/home/details/descriptiveParagraph— 마케팅 설명문
임대 페이지의 경우, rentalId(36자 UUID)는 <meta property="og:image"> 태그의 URL에서 추출됩니다.
Stingray API로 매물 데이터 추출하기
중요한 특이점이 하나 있습니다. Stingray JSON 응답은 CSRF 방지용으로 {}&&라는 문자열이 앞에 붙습니다. 파싱하기 전에 반드시 제거해야 합니다.
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# 세션 예열
6session.get("https://www.redfin.com/")
7# 쿠키와 property ID를 얻기 위해 매물 페이지 요청
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# 이제 Stingray API 호출
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# CSRF 방지 접두어 제거
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# 구조화된 데이터 추출
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))응답에는 가격은 정수, 침실/욕실은 숫자, 사진 URL은 배열, 에이전트 정보는 중첩 객체처럼 타입이 보존된 필드가 들어 있습니다. BeautifulSoup 파싱도, CSS 셀렉터도, 추측도 필요 없습니다.
숨은 API 방식의 장점과 한계
장점:
- 이미 구조화된 JSON이라 HTML 파싱보다 훨씬 깔끔함
- 요청당 더 빠름(작은 페이로드, 렌더링 부담 없음)
- 차단 위험이 낮음(API형 요청은 더 자연스럽게 보임)
한계:
- 공식 문서가 없어 엔드포인트가 예고 없이 바뀔 수 있음
robots.txt가 와일드카드 사용자 에이전트에 대해/stingray/를 명시적으로 금지함- 새 엔드포인트를 찾으려면 리버스 엔지니어링이 필요함
- Cloudflare를 피하려면 여전히 세션 예열과 적절한 헤더가 필요함
노코드 대안: Thunderbit으로 Redfin 크롤링하기
Redfin 데이터가 필요하지만 Python 스크립트를 계속 유지보수하고 싶지 않거나, 그냥 5분 안에 결과를 보고 싶다면 이 방법부터 시작하세요. 우리는 바로 그런 용도로 을 만들었습니다. 코딩 없이 어떤 웹사이트든 구조화된 데이터를 추출할 수 있습니다.
1단계: Thunderbit 설치 후 Redfin으로 이동하기
Chrome 웹 스토어에서 을 설치하세요. Redfin을 열고 검색 결과 페이지로 이동합니다. 예를 들어 샌프란시스코 매물 목록처럼요.
2단계: "AI Suggest Fields" 클릭하기
브라우저 툴바에서 Thunderbit 아이콘을 클릭한 뒤 **"AI Suggest Fields"**를 누르세요. AI가 Redfin 페이지를 읽고 "Address", "Price", "Beds", "Baths", "SqFt", "Property Type", "Listing Photo" 같은 컬럼을 자동으로 제안하며, 데이터 유형도 함께 맞춰 줍니다.
필요 없는 컬럼은 지울 수 있고, **"+ Add Column"**을 눌러 "listing agent name"이나 "days on market"처럼 원하는 항목을 자연어로 입력해 새 컬럼을 추가할 수도 있습니다.
설정한 컬럼이 채워질 준비가 된 테이블 미리보기가 보일 겁니다.
3단계: "Scrape"를 눌러 데이터 수집하기
"Scrape" 버튼을 클릭하세요. Thunderbit이 현재 보이는 매물들을 처리해 테이블을 채워 줍니다. 페이지가 나뉜 결과도 자동으로 처리하므로 루프 코드를 직접 짤 필요가 없습니다.
제가 테스트했을 때 50행짜리 테이블은 약 45초 만에 채워졌습니다. 바로 내보낼 수 있는 구조화된 데이터죠.
Thunderbit이 Redfin의 안티봇 방어를 처리하는 방식
Thunderbit은 사용자의 브라우저 안에서 돌아가기 때문에, 이미 갖고 있는 Redfin 쿠키, 세션, 브라우저 지문을 그대로 활용합니다. Cloudflare 입장에서는 그냥 Redfin을 둘러보는 일반 사용자처럼 보입니다. 실제로 그렇기 때문입니다. 헤드리스 브라우저도, 데이터센터 IP도, TLS 지문 불일치도 없습니다. 공개된 페이지라면 Thunderbit의 클라우드 스크래핑 모드로 한 번에 50페이지까지 처리할 수 있습니다.
서버에서 Python 스크립트로 requests를 보내는 방식과는 완전히 다릅니다.
이미 당신의 브라우저 세션은 신뢰받고 있습니다.
Thunderbit으로 Redfin 하위 페이지까지 크롤링하기
검색 결과를 수집한 뒤에는 **"Scrape Subpages"**를 눌러 각 매물 상세 URL을 방문하게 하고, Redfin Estimate, 준공 연도, HOA 비용, 에이전트 정보, 매물 사진, 매매 이력 같은 추가 필드로 테이블을 보강할 수 있습니다.
방법 1에서 Selenium으로 40줄 정도 짜야 했던 루프를, 클릭 한 번과 유지보수 제로로 바꾸는 셈입니다.
Redfin이 DOM을 homecardV2Price에서 span.bp-Homecard__Price--value로 바꿔도 AI는 알아서 따라갑니다. 하지만 Python 셀렉터는 그렇지 못하죠.
CSV를 넘어: Redfin 데이터를 Google Sheets, Airtable, Notion으로 내보내기
대부분의 튜토리얼은 df.to_csv()에서 끝납니다. 일회성 분석이라면 충분하죠. 하지만 부동산 팀이라면 누군가의 데스크톱에 먼지만 쌓이는 정적 파일보다, 함께 쓰는 살아 있는 데이터가 필요합니다.
Python으로 내보내기(gspread + Airtable API)
gspread를 이용한 Google Sheets:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# IMAGE() 수식을 사용해 매물 사진을 셀 안에 표시
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')참고로 Sheets는 스프레드시트당 1,000만 셀 제한이 있고, API는 프로젝트당 을 허용합니다. 수십 행을 넘는 작업은 셀별 루프 대신 ws.batch_update()를 쓰는 편이 좋습니다.
pyairtable를 이용한 Airtable:
중요한 2024년 변경사항이 있습니다. Airtable은 했습니다. 이제는 Personal Access Token(PAT)을 사용해야 하며, 아직도 api_key=...를 쓰는 튜토리얼은 작동하지 않습니다.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable이 가져와서 재호스팅
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)Airtable의 레이트 리밋은 이며, 위반 시 30초 잠금이 걸립니다. 첨부 파일 필드는 [{"url": ...}] 형식을 받으며, Airtable 서버가 URL을 가져와 자체 CDN에 재호스팅하고 썸네일까지 자동으로 생성합니다.
Thunderbit으로 내보내기(1번 클릭으로 Sheets, Airtable, Notion)
Thunderbit은 Google Sheets, Airtable, Notion으로 바로 내보내는 1클릭 기능을 기본으로 제공하며, 제가 정말 자랑스럽게 생각하는 부분이 바로 이것입니다. 부동산 사진이 Notion과 Airtable에 인라인 이미지로 업로드되어 렌더링됩니다. =IMAGE() 수식 꼼수도 필요 없고, 깨진 CDN 링크도 없습니다. “Export to Airtable”을 누르면, 팀이 휴대폰으로도 볼 수 있는 썸네일이 딸린 시각적 부동산 데이터베이스를 바로 받을 수 있습니다.
시각적으로 매물을 골라야 하는 부동산 팀에게는, 이게 유용한 도구와 그냥 CSV 목록의 차이입니다.
Redfin 크롤링은 합법일까? ToS, robots.txt, 판례가 말하는 것
저는 변호사가 아니며, 아래 내용은 법률 자문이 아닙니다. 하지만 데이터 추출 분야에 오래 있으면서 확실히 배운 게 있습니다. “합법인가?”는 모두가 묻지만, 대부분의 튜토리얼이 피해 가는 질문이라는 점입니다.
Redfin의 robots.txt
Redfin의 는 꽤 상세합니다. 핵심은 아래와 같습니다.
- 완전히 차단된 봇:
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent— Redfin은 LLM 시대의 유명 스크래핑 서비스까지 직접 적어 놓고 있습니다. - 와일드카드
User-agent: *에서 금지된 경로:/stingray/(내부 API 전체),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - 어떤 사용자 에이전트에도
Crawl-delay:지시문 없음 - 50개 이상의 사이트맵 선언 — 사이트맵은 WAF 부담이 적고 URL을 나열하기 좋은 방식입니다.
Redfin의 이용약관
에는 이렇게 적혀 있습니다. "You may not automatedly crawl or query the Services for any purpose or by any means... unless you have received prior express written permission." (사전의 명시적 서면 허가 없이 어떤 목적이나 방식으로도 서비스를 자동으로 크롤링하거나 질의할 수 없습니다.)
이건 browsewrap 형태의 약관입니다. 즉, 클릭해서 동의하는 방식이 아니라 계속 사용함으로써 동의한 것으로 간주됩니다. 미국 법원은 실제 인지가 없었던 사용자에게 browsewrap을 집행하는 데 역사적으로 신중한 태도를 보여 왔습니다(예: Nguyen v. Barnes & Noble, 9th Cir. 2014).
관련 판례 요약
- Van Buren v. United States(미 대법원, 2021): CFAA의 “허가를 넘는 접근”은 “문이 열려 있느냐 닫혀 있느냐” 기준으로 판단합니다. 열려 있는 문을 원치 않는 목적으로 사용했다고 해서 연방 해킹이 되는 건 아닙니다.
- hiQ Labs v. LinkedIn(9th Cir., 2022): 공개된 데이터의 크롤링은 CFAA 위반이 아닙니다. 다만 hiQ는 결국 50만 달러를 주고 합의했는데, LinkedIn 계정을 만들고 “I agree”를 클릭했기 때문에 계약 위반 책임이 문제됐습니다.
- Meta Platforms v. Bright Data(N.D. Cal., 2024년 1월): 법원은 Bright Data에 대해 약식판결을 내렸고, 로그아웃 상태에서 공개 데이터를 크롤링한 행위만으로 Bright Data가 Meta의 ToS에 구속되는 “사용자”가 되지는 않는다고 봤습니다.
- X Corp. v. Bright Data(N.D. Cal., 2024년 5월): Alsup 판사는 X의 주장을 기각했고, 공개 콘텐츠의 복제를 통제하려는 주법 청구는 저작권법에 의해 선점(preempted)된다고 판시했습니다.
실무상 가이드
- 공개 접근 가능한 데이터만 수집하세요. 계정을 만든 뒤 크롤링하는 건 피하세요(그렇게 되면 클릭랩 계약 리스크가 생깁니다).
- 레이트 리밋을 존중하세요. 과도한 요청량은 동산침해(trespass-to-chattels) 주장으로 이어질 수 있습니다.
- 원본 데이터나 사진을 대규모로 재게시하지 마세요. 소송(2025년 7월 제기, 손해배상액 10억 달러 초과 가능성)은 사진 저작권이 얼마나 중요한지 다시 보여줍니다.
- Thunderbit의 브라우저 기반 방식은 자신의 인증 세션에서 수동 탐색을 기계 속도로 하는 것에 가깝습니다. 완전히 머리 없는 데이터센터 봇보다 훨씬 방어 가능한 포지션이며, 라이선스 API를 쓰지 않는 한 가장 무난한 접근입니다.
팁과 흔한 실수
추출 도구를 만들면서, 그리고 수천 명의 사용자가 부동산 사이트를 크롤링하는 걸 지켜보며 얻은 교훈 몇 가지를 공유합니다.
- 세션은 항상 예열하세요. 깊은 URL을 열기 전에 먼저
redfin.com/에 접속하세요. 바로 깊은 주소를 치는 게 Cloudflare 챌린지를 가장 자주 유발합니다. - User-Agent는 현실적으로 순환하세요. 하나만 쓰지 말고 최신 Chrome/Firefox UA 5~10개를 번갈아 사용하세요. 다만 너무 과하게 바꾸면 안 됩니다(요청마다 UA가 달라지면 오히려 수상해 보입니다).
- property ID로 중복 제거하세요. Redfin 페이지네이션은 종종 겹칩니다. 각 매물 URL의
/home/{id}를 파싱해 보강 전에 중복을 제거하세요. - 가능하면 피크 시간대는 피하세요. 제 경험상 미국 현지 심야나 새벽이 WAF 감시가 덜한 편입니다.
- 429를 받으면 지수 백오프하세요. 바로 재시도하면 안 됩니다. 소프트 레이트 리밋이 하드 IP 차단으로 악화되는 지름길입니다.
- 대규모 프로젝트(1,000페이지 이상)라면 리저널 프록시 예산을 잡으세요. 데이터센터 IP(AWS, GCP, Azure, OVH)는 Cloudflare의 ASN 평판 시스템에서 블랙리스트에 올라 있을 가능성이 높습니다. 거의 즉시 Error 1020을 만날 수 있습니다.
Redfin을 크롤링할 올바른 방법 선택하기
그렇다면 어떤 방법을 골라야 할까요? 결국 당신이 누구인지, 무엇이 필요한지에 따라 다릅니다.
HTML 파싱(BeautifulSoup + Selenium): 모든 걸 직접 제어하고 싶고, CSS 셀렉터 유지보수에 익숙하며, Redfin의 DOM 변화에 맞춰 다시 손볼 수 있는 개발자에게 적합합니다. 6~12개월마다 코드를 다시 점검해야 할 것으로 예상하세요.
숨겨진 Stingray API: 깔끔하고 구조화된 JSON이 필요하고, 문서화되지 않은 엔드포인트를 직접 파헤칠 수 있는 개발자에게 적합합니다. HTML 파싱보다 유지보수는 덜하지만, 예고 없이 바뀔 수 있다는 점은 여전합니다. 또 /stingray/는 robots.txt에서 명시적으로 금지되어 있다는 점도 기억하세요.
Thunderbit(노코드): 비개발자, 빠른 프로젝트, 그리고 개발 리소스 없이 꾸준히 Redfin 데이터가 필요한 팀에 가장 적합합니다. AI가 레이아웃 변화에 적응하고, 하위 페이지 크롤링으로 한 번에 데이터를 보강하며, , Airtable, Notion으로의 내보내기가 기본 제공됩니다. 일회성 CSV 덤프가 아니라 살아 있는 부동산 데이터베이스가 필요한 팀이라면, 이 방법이 가장 덜 번거로운 길입니다.
어떤 경로를 고르든, 시작하기 전에 Redfin의 안티봇 방어를 이해하고, 필요한 필드를 명확히 정리하고, 팀 워크플로에 맞는 내보내기 형식을 고르며, 안에서 움직이세요.
노코드 경로를 바로 시도해 보고 싶다면, 으로 Redfin 크롤링을 직접 실험하고 몇 분 안에 결과를 확인할 수 있습니다. Python 방식의 경우 위 코드 조각들이 실제로 작동하는 출발점입니다. 여기에 프록시와 인내심만 더하면 됩니다.
FAQ
Redfin에 공개 API가 있나요?
아니요. Redfin은 공식 공개 API를 제공하지 않습니다. 숨겨진 Stingray API(/stingray/api/home/details/*)는 구조화된 JSON을 반환하고 Redfin 자체 프런트엔드가 사용하지만, 비공식이고 문서화되어 있지 않으며 예고 없이 변경될 수 있고, Redfin의 robots.txt에서도 명시적으로 금지되어 있습니다. 같은 오픈소스 래퍼가 Python 접근을 제공하긴 하지만, 위험을 이해한 상태에서 써야 합니다.
Python 없이 Redfin을 크롤링할 수 있나요?
네. 은 브라우저 세션을 그대로 활용해 안티봇에 강한 AI Chrome 확장입니다. 설치한 뒤 Redfin으로 이동해 "AI Suggest Fields"를 클릭하고, Excel, Google Sheets, Airtable, Notion으로 내보내면 됩니다. 대안으로 살펴볼 수 있는 다른 노코드 스크래핑 도구와 사전 구축 데이터셋 제공업체도 시장에 있습니다.
Redfin은 웹사이트 레이아웃을 얼마나 자주 바꾸나요?
커뮤니티 GitHub 이슈 기록을 보면 CSS 셀렉터가 대략 6~12개월마다 깨집니다. Redfin은 카드 DOM을 두 세대로 바꿔 왔습니다. 예전 버전은 (homecardV2Price, homeAddressV2), 현재 버전은 (bp-Homecard__Price--value, bp-Homecard__Address)입니다. 성숙한 스크래퍼는 두 셀렉터를 순서대로 시도합니다.
Thunderbit 같은 AI 기반 도구는 CSS 셀렉터가 아니라 콘텐츠를 기준으로 필드를 감지하기 때문에 합니다.
Redfin 크롤링에 가장 좋은 프록시 유형은 무엇인가요?
대규모 수집에는 미국 리저널 프록시가 가장 적합합니다. 커뮤니티 벤치마크 기준 성공률은 약 80%입니다. 데이터센터 프록시는 Cloudflare Error 1020에 거의 즉시 걸리며, AWS, GCP, Azure, OVH IP 대역은 블랙리스트에 올라 있습니다. 모바일 프록시는 성공률이 가장 높지만 비용이 5~10배 더 비쌉니다.
소규모 개인 수집(<100페이지)이라면, 적절한 헤더 + curl_cffi 임퍼서네이션 + 2~5초 지연만으로도 프록시 없이 가능할 수 있습니다.
Redfin에서 판매 완료되었거나 오프마켓인 부동산 데이터도 크롤링할 수 있나요?
네. 판매 완료 매물 데이터와 시장 외 Redfin Estimate(중앙값 오차 )는 같은 방식으로 상세 페이지에서 가져올 수 있습니다. 다만 활성 매물과 필드 구성이 다릅니다. 오프마켓 페이지에는 판매가, 판매일, 부동산 이력, owner-estimate 엔드포인트가 노출되지만, 현재 호가, 시장 체류 일수, 오픈하우스 정보는 없습니다. 시장 외 추정치용 Stingray API 엔드포인트는 api/home/details/avm이 아니라 api/home/details/owner-estimate입니다.
더 알아보기