Indeed에서 채용 공고 제목을 스프레드시트에 복사해 붙여넣기를 쉰 번째쯤 하던 무렵, 문득 제 커리어 선택에 의문이 들기 시작했습니다. Indeed에서 구조화된 데이터를 프로그램으로 가져오려 해본 적이 있다면 이미 결론을 알고 계실 거예요. 403 오류는 버그가 아니라 Indeed 방어 시스템의 기능입니다.
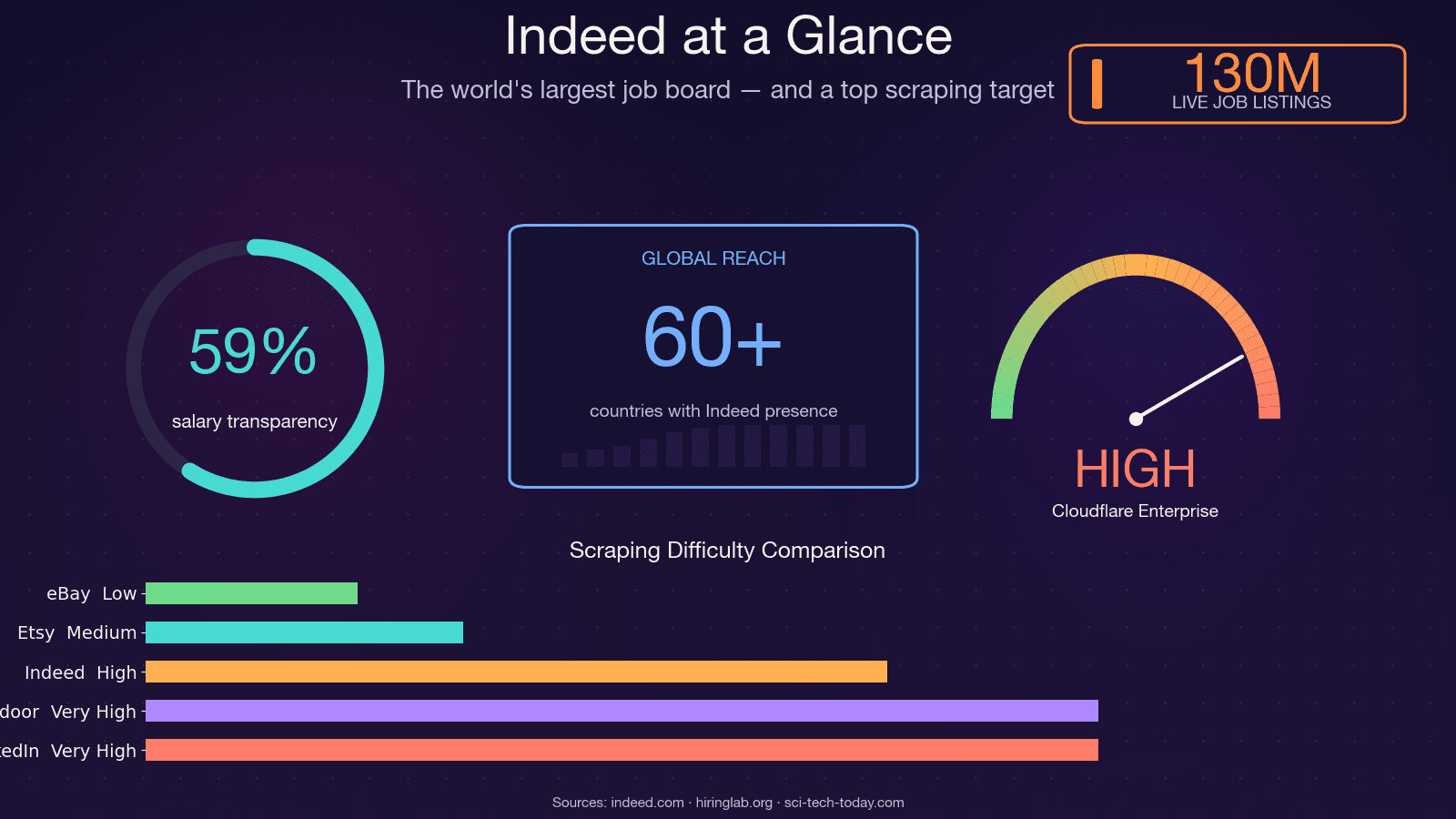
Indeed는 전 세계 최대 채용 사이트로, 월간 순 방문자가 약 , 수시로 에 이르는 채용 공고를 보유하고 있으며, 에서 운영되고 있습니다. 그만큼 지구상에서 가장 풍부한 채용 시장 데이터 소스 중 하나이자, 동시에 가장 스크래핑하기 어려운 사이트 중 하나이기도 합니다. 오픈소스 스크래퍼 JobFunnel(깃허브 스타 수천 개)은 안티봇과의 지루한 싸움 끝에 2025년 12월 결국 했습니다. 유지 관리자의 표현을 그대로 옮기면, *"모든 사용자가 일부 채용 공고를 스크래핑할 수는 있지만 금방 캡차에 걸리고, 스크래핑은 실패해서 결과적으로 공고를 얻지 못한다"*는 것이었습니다. 다른 기여자는 첫 요청부터 CAPTCHA가 도 보고했습니다. 그러니 네, 이건 전혀 만만한 스크래핑 대상이 아닙니다. 이 가이드에서는 Python으로 Indeed를 스크래핑하는 실용적인 모든 방법을 살펴보고, 403 방어선을 실제로 어떻게 뚫고 지나갈 수 있는지 보여드릴게요. 그리고 디버깅은 아예 건너뛰고 싶으신 분들을 위해서는 를 활용한 노코드 대안도 함께 소개하겠습니다.
Python으로 Indeed를 스크래핑한다는 것은 무슨 뜻일까?
웹 스크래핑은 본질적으로 웹페이지에서 구조화된 데이터를 자동으로 추출하는 작업입니다. Python으로 Indeed를 스크래핑한다는 건, Indeed의 검색 결과 페이지와 채용 공고 상세 페이지에 접근하는 스크립트를 작성한 뒤, 내부 HTML(또는 포함된 데이터)을 읽어 들여 직무명, 회사, 위치, 급여, 설명 같은 항목을 CSV, 데이터베이스, Google Sheet처럼 활용 가능한 형식으로 뽑아내는 것을 의미합니다.
보통 사용되는 Python 라이브러리는 Requests(HTTP 요청), BeautifulSoup(HTML 파싱), Selenium 또는 Playwright(브라우저 자동화)입니다. 하지만 Indeed는 단순한 정적 사이트가 아닙니다. 서버 렌더링된 HTML에 JSON 상태 블롭이 포함된 하이브리드 구조이고, Cloudflare Bot Management가 앞단에서 보호하고 있습니다. 즉, 스크래퍼는 자바스크립트 렌더링 콘텐츠, 바뀌는 CSS 클래스명, 강력한 안티봇 보호를 모두 처리해야 합니다. 그러고 나서야 비로소 채용 공고 제목 하나를 파싱할 수 있죠.
게다가 2026년 현재 공식적이고 무료인 읽기 전용 Indeed API도 없습니다. 예전 Publisher Jobs API는 2020년 무렵 폐기되었고, 현재 남아 있는 것은 고용주용 기능(직무 동기화, 스폰서 공고)뿐입니다. 그래서 스크래핑하거나, 제3자 데이터 제공업체에 비용을 지불하는 것만이 현실적인 선택지입니다.
왜 Indeed 채용 데이터를 스크래핑할까?
Indeed를 스크래핑하는 비즈니스적 이유는 분명합니다. 수천 건의 목록을 일일이 사람이 훑는 건 비현실적이고, 그 안의 데이터는 실제로 매우 가치 있기 때문입니다.
| 사용 사례 | 도움이 되는 대상 | 예시 |
|---|---|---|
| 리드 생성 | 영업팀, 채용팀 | 연락처가 포함된 채용 중인 회사 목록 만들기 |
| 채용 시장 조사 | 분석가, HR 팀 | 유행 기술과 지역별 급여 기준 파악하기 |
| 경쟁사 인텔리전스 | 고용주, 채용 대행사 | 경쟁사의 채용 패턴과 제시 급여 모니터링하기 |
| 개인 구직 자동화 | 구직자 | 여러 지역의 조건에 맞는 공고 모으기 |
| ML 모델 학습 데이터 | 데이터 과학자 | 과거 데이터를 바탕으로 급여 예측 모델 구축하기 |
Indeed Hiring Lab의 자체 연구도 하듯, 공고 데이터는 BLS JOLTS와 매우 유사하게 움직이며 미국 노동시장 상황을 거의 실시간으로 보여주는 대리 지표가 될 수 있습니다. 헤지펀드는 채용 공고 증가 속도를 대체 데이터 신호로 사용합니다. HR 팀은 스크래핑한 급여 범위를 활용해 보상 수준을 벤치마킹합니다. 채용 담당자는 실제로 채용 중인 회사를 기반으로 잠재 고객 목록을 만듭니다.
한 가지 실무 팁을 드리면, Indeed의 급여 데이터는 점점 나아지고 있지만 아직 완전하지는 않습니다. 2025년 중반 기준으로 미국 공고의 약 가 급여 정보를 포함하지만, 실제 정확한 금액을 적어두는 비율은 약 에 불과하고 나머지는 범위 형태입니다. Indeed 데이터를 바탕으로 급여를 분석할 때는 이런 공백을 반드시 감안해야 합니다.
Python으로 Indeed를 스크래핑할 방법 고르기
Indeed를 스크래핑하는 단 하나의 “정답”은 없습니다. 최선의 방법은 본인의 숙련도, 필요한 데이터 양, 감당할 유지보수 수준에 따라 달라집니다. 주요 네 가지 접근법을 직접 테스트해 봤는데, 비교하면 이렇습니다.
| 기준 | BS4 + Requests | Selenium | 숨겨진 JSON (window.mosaic) | 노코드(Thunderbit) |
|---|---|---|---|---|
| 난이도 | 초급 | 중급 | 중급~상급 | 없음(2번 클릭) |
| 속도 | 빠름 | 느림(브라우저 렌더링) | 빠름 | 빠름(클라우드 스크래핑) |
| JS 렌더링 콘텐츠 | 아니오 | 예 | 예(내장 데이터) | 예 |
| 안티봇 회피력 | 낮음 | 중간(탐지 가능) | 중간~높음 | 높음(자동 처리) |
| HTML 변경 시 유지보수 | 높음(셀렉터가 깨짐) | 높음 | 중간(JSON 구조가 더 안정적) | 없음(AI가 적응) |
| 적합한 경우 | 빠른 프로토타입 | 동적 페이지, 로그인 게이트 | 대량 구조화 데이터 | 비개발자, 빠른 결과 |
이 가이드는 각 방법을 차례대로 다룹니다. Python 개발자라면 BS4, 숨겨진 JSON, Selenium 섹션을 읽어보시면 되고, 코딩이 익숙하지 않거나 403 디버깅에 지치셨다면 Thunderbit 섹션으로 바로 넘어가셔도 됩니다.
시작하기 전에
- 난이도: 초급~중급(Python 섹션), 없음(Thunderbit 섹션)
- 예상 소요 시간: Python 설정 및 첫 스크래핑까지 약 20~60분, Thunderbit은 약 2분
- 준비물: Python 3.9 이상, 코드 에디터, Chrome 브라우저, 그리고 노코드 경로의 경우
Indeed 스크래핑을 위한 Python 환경 설정
스크래핑 코드를 쓰기 전에 먼저 개발 환경부터 준비해 봅시다.
필요한 라이브러리 설치하기
가상 환경을 만들고 필요한 패키지를 설치하세요.
1python -m venv indeed_env
2source indeed_env/bin/activate # Windows에서는: indeed_env\Scripts\activate
3# HTTP + 파싱 방식용
4pip install requests beautifulsoup4 lxml httpx
5# 숨겨진 JSON 방식용(권장)
6pip install curl_cffi parsel tenacity
7# 브라우저 자동화 방식용
8pip install selenium몇 가지 참고 사항:
- **
curl_cffi**는 2026년 기준 Cloudflare로 보호되는 사이트를 스크래핑할 때의 기본 선택지입니다. 실제 브라우저의 TLS 지문을 흉내 내기 때문에, 일반requests와httpx로는 할 수 없는 일을 해냅니다. 안티봇 섹션에서 왜 중요한지 더 자세히 설명하겠습니다. - Selenium 4.6 이상에는 Selenium Manager가 포함되어 있어, 이제 ChromeDriver를 수동으로 내려받을 필요가 없습니다. 브라우저 바이너리를 자동으로 관리해 줍니다.
- BeautifulSoup의 파서 백엔드로는 **
lxml**을 쓰세요. 표준 라이브러리html.parser보다 약 .
프로젝트 구조 만들기
간단하게 유지하면 됩니다.
1indeed_scraper/
2├── scraper.py
3├── requirements.txt
4└── output/아래의 모든 코드 예시는 scraper.py를 기반으로 합니다.
BeautifulSoup으로 Python에서 Indeed 스크래핑하는 방법
이 방법은 초보자 친화적입니다. requests로 페이지를 가져오고 BeautifulSoup으로 HTML을 파싱합니다. 설정은 가장 빠르지만, Indeed에서는 가장 취약하기도 합니다.
1단계: Indeed 검색 URL 만들기
Indeed의 검색 URL은 예측 가능한 패턴을 따릅니다.
1https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>예를 들어 "Austin, TX"에서 "data analyst"를 검색하고 첫 페이지를 가져오려면:
1from urllib.parse import urlencode
2params = {
3 "q": "data analyst",
4 "l": "Austin, TX",
5 "start": 0,
6}
7url = f"https://www.indeed.com/jobs?{urlencode(params)}"
8print(url)
9# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0Indeed는 10개 단위로 페이지를 나누며, 최대 1,000개 결과(start <= 990)까지만 제공합니다. 990을 넘는 오프셋은 조용히 같은 페이지를 다시 반환합니다.
2단계: 적절한 헤더로 HTTP 요청 보내기
기본 Python 사용자 에이전트 문자열로 요청하면 Indeed는 바로 차단합니다. 현실적인 헤더가 필요합니다.
1import requests
2headers = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
5 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.indeed.com/",
11}
12response = requests.get(url, headers=headers, timeout=30)
13print(response.status_code)200이 나오면 일단 들어간 것입니다. 하지만 403이 나오면 Cloudflare에 걸린 겁니다. (이걸 어떻게 버티는지는 아래에서 설명합니다.)
3단계: HTML에서 채용 공고 파싱하기
BeautifulSoup으로 공고 카드 요소를 선택합니다. Indeed의 무작위 CSS 클래스명보다 data-testid 속성을 타깃으로 하세요. 더 안정적입니다.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(response.text, "lxml")
3cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
4jobs = []
5for card in cards:
6 title_el = card.find("h2", class_="jobTitle")
7 title = title_el.get_text(strip=True) if title_el else None
8 company = card.find(attrs={"data-testid": "company-name"})
9 location = card.find(attrs={"data-testid": "text-location"})
10 link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
11 jobs.append({
12 "title": title,
13 "company": company.get_text(strip=True) if company else None,
14 "location": location.get_text(strip=True) if location else None,
15 "url": f"https://www.indeed.com\{link\}" if link else None,
16 })
17print(f"{len(jobs)}개의 채용 공고를 찾았습니다")4단계: 페이지네이션 처리하기
start 파라미터를 증가시키면서 페이지를 순회합니다.
1import time, random
2all_jobs = []
3for page in range(0, 50, 10): # 처음 5페이지
4 params["start"] = page
5 url = f"https://www.indeed.com/jobs?{urlencode(params)}"
6 response = requests.get(url, headers=headers, timeout=30)
7 # ... 위와 같이 파싱 ...
8 all_jobs.extend(jobs)
9 time.sleep(random.uniform(3, 6))이 방법의 한계
솔직히 말씀드리면, BS4 + Requests는 2026년 기준 Indeed에서 가장 약한 방법입니다. 일반 requests는 Python 표준 라이브러리 TLS를 사용하기 때문에, Cloudflare가 즉시 “브라우저가 아님”을 알아채는 을 만듭니다. 또 Indeed가 제공하는 HTTP/2도 지원하지 않습니다. 몇 페이지 지나지 않아 차단될 가능성이 큽니다. 그리고 CSS 셀렉터는요? Indeed는 css-1m4cuuf, jobsearch-JobComponent-embeddedBody-1n0gh5s 같은 클래스명을 바꾸므로, 그런 클래스를 타깃으로 한 셀렉터는 시한폭탄과 같습니다.
이 방법은 한 페이지를 빠르게 프로토타입할 때만 쓰세요. 규모가 조금이라도 커지면 숨겨진 JSON 방식을 쓰는 편이 낫습니다.
숨겨진 JSON 데이터를 사용해 Python으로 Indeed를 스크래핑하는 방법
대부분의 Python 개발자에게 가장 추천하는 방법입니다. 깨지기 쉬운 HTML 요소를 파싱하는 대신, Indeed 페이지 소스에 포함된 JavaScript 변수 window.mosaic.providerData["mosaic-provider-jobcards"]에서 구조화된 데이터를 추출합니다.
직무명, 회사, 위치, 급여, 공고 키, 게시 날짜, 원격 여부처럼 필요한 모든 필드는 이미 이 JSON 블롭 안에 들어 있습니다. 자바스크립트 실행도 필요 없습니다. 스키마는 이라 DOM 셀렉터보다 훨씬 튼튼합니다.
1단계: 페이지 HTML 가져오기
requests 대신 curl_cffi를 사용하세요. 실제 브라우저의 TLS 지문을 흉내 내기 때문에 Cloudflare를 통과하는 데 핵심적입니다.
1from curl_cffi import requests as cffi_requests
2response = cffi_requests.get(
3 "https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
4 impersonate="chrome124",
5 headers={
6 "Accept-Language": "en-US,en;q=0.9",
7 "Referer": "https://www.indeed.com/",
8 },
9 timeout=30,
10)
11print(response.status_code, len(response.text))왜 curl_cffi일까요? 이것은 curl-impersonate를 감싼 Python 바인딩으로, 실제 브라우저의 정확한 TLS ClientHello, HTTP/2 SETTINGS 프레임, 헤더 순서를 재현합니다. 하는 현재 유일한 적극 유지보수 Python HTTP 클라이언트라고 봐도 됩니다. 지원되는 impersonation 대상에는 chrome120, chrome124, chrome131, Safari, Edge 변형이 포함됩니다.
2단계: 정규식으로 JSON 추출하기
JSON 블롭은 <script> 태그 안에 삽입되어 있습니다. 정규식으로 꺼내세요.
1import re, json
2MOSAIC_RE = re.compile(
3 r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
4 re.DOTALL,
5)
6match = MOSAIC_RE.search(response.text)
7if match:
8 data = json.loads(match.group(1))
9 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
10 print(f"숨겨진 JSON에서 {len(results)}개의 채용 공고를 찾았습니다")
11else:
12 print("숨겨진 JSON을 찾지 못했습니다 — 차단되었거나 페이지 구조가 바뀌었을 수 있습니다")3단계: JSON에서 공고 필드 파싱하기
results 안의 각 항목은 페이지에 보이는 것보다 더 많은 정보를 담고 있습니다.
1jobs = []
2for job in results:
3 jobs.append({
4 "jobkey": job["jobkey"],
5 "title": job["title"],
6 "company": job.get("company"),
7 "location": job.get("formattedLocation"),
8 "remote": job.get("remoteLocation"),
9 "salary": (job.get("salarySnippet") or {}).get("text"),
10 "posted": job.get("formattedRelativeTime"),
11 "job_type": job.get("jobTypes"),
12 "easy_apply": job.get("indeedApplyEnabled"),
13 "url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
14 })이 JSON에는 종종 급여 추정치, 분류 속성(스킬 태그), 회사 평점처럼 렌더링된 HTML에는 항상 보이지 않는 정보도 들어 있습니다.
4단계: 여러 페이지 스크래핑하기
총 결과 수를 파악하려면 JSON 안의 tierSummaries를 참고한 뒤 루프를 돌리세요.
1import time, random
2all_jobs = []
3for start in range(0, 50, 10): # 처음 5페이지
4 url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=\{start\}&sort=date"
5 response = cffi_requests.get(
6 url,
7 impersonate="chrome124",
8 headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
9 timeout=30,
10 )
11 match = MOSAIC_RE.search(response.text)
12 if match:
13 data = json.loads(match.group(1))
14 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
15 all_jobs.extend([{
16 "jobkey": j["jobkey"],
17 "title": j["title"],
18 "company": j.get("company"),
19 "location": j.get("formattedLocation"),
20 "salary": (j.get("salarySnippet") or {}).get("text"),
21 "url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
22 } for j in results])
23 time.sleep(random.uniform(3, 7))
24print(f"총 {len(all_jobs)}개의 공고를 스크래핑했습니다")숨겨진 JSON이 더 튼튼한 이유
window.mosaic.providerData 구조는 CSS 클래스명보다 훨씬 덜 자주 바뀝니다. 지저분한 HTML을 파싱하지 않아도 깨끗하고 구조화된 데이터를 얻을 수 있죠. 다만 그래도 안티봇 회피(헤더, 딜레이, 프록시)는 필요하며, 이는 다음 섹션에서 다루겠습니다.
Selenium으로 Python에서 Indeed를 스크래핑하는 방법
Selenium은 브라우저 자동화 방식입니다. 공고 상세 패널을 클릭해 들어가야 하거나, 로그인해야 볼 수 있는 콘텐츠를 다뤄야 하거나, 초기 HTML에 없는 동적 로딩 설명을 스크래핑해야 할 때 유용합니다.
HTTP 클라이언트 대신 Selenium을 써야 할 때
- Indeed가 일부 콘텐츠를 동적으로 로드할 때(오른쪽 패널의 전체 공고 설명)
- 세션 상태나 로그인이 필요한 페이지를 스크래핑할 때
- 속도가 중요하지 않은 소규모 스크래핑일 때
간단한 실행 예시
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.chrome.options import Options
4import time
5options = Options()
6options.add_argument("--disable-blink-features=AutomationControlled")
7# options.add_argument("--headless=new") # 헤드리스는 더 탐지되기 쉬움 — 주의해서 사용하세요
8driver = webdriver.Chrome(options=options)
9driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
10time.sleep(3)
11cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
12for card in cards:
13 try:
14 title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
15 company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
16 location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
17 print(f"\{title\} | \{company\} | \{location\}")
18 except Exception:
19 continue
20driver.quit()한계
Selenium은 느립니다. 페이지마다 브라우저 렌더링이 완전히 필요하기 때문입니다. 헤드리스 Chrome은 . Cloudflare는 navigator.webdriver, WebGL 벤더 문자열, 플러그인 개수 등을 확인합니다. undetected-chromedriver조차 탐지를 잠시 늦출 뿐, 영구적으로 막아주지는 않습니다. BS4와 마찬가지로, Indeed가 UI를 바꾸면 셀렉터도 깨집니다.
대부분의 사용 사례에서는 숨겨진 JSON 방식이 같은 데이터를 더 빠르고 유지보수 적게 가져다줍니다. 진짜로 브라우저가 필요한 특수 상황에서만 Selenium을 쓰세요.
Python으로 Indeed를 스크래핑할 때 403 오류를 피하는 방법
이 부분이 가장 중요합니다. 답답해서 Google 검색 끝에 여기까지 오셨다면, 제대로 오셨습니다.
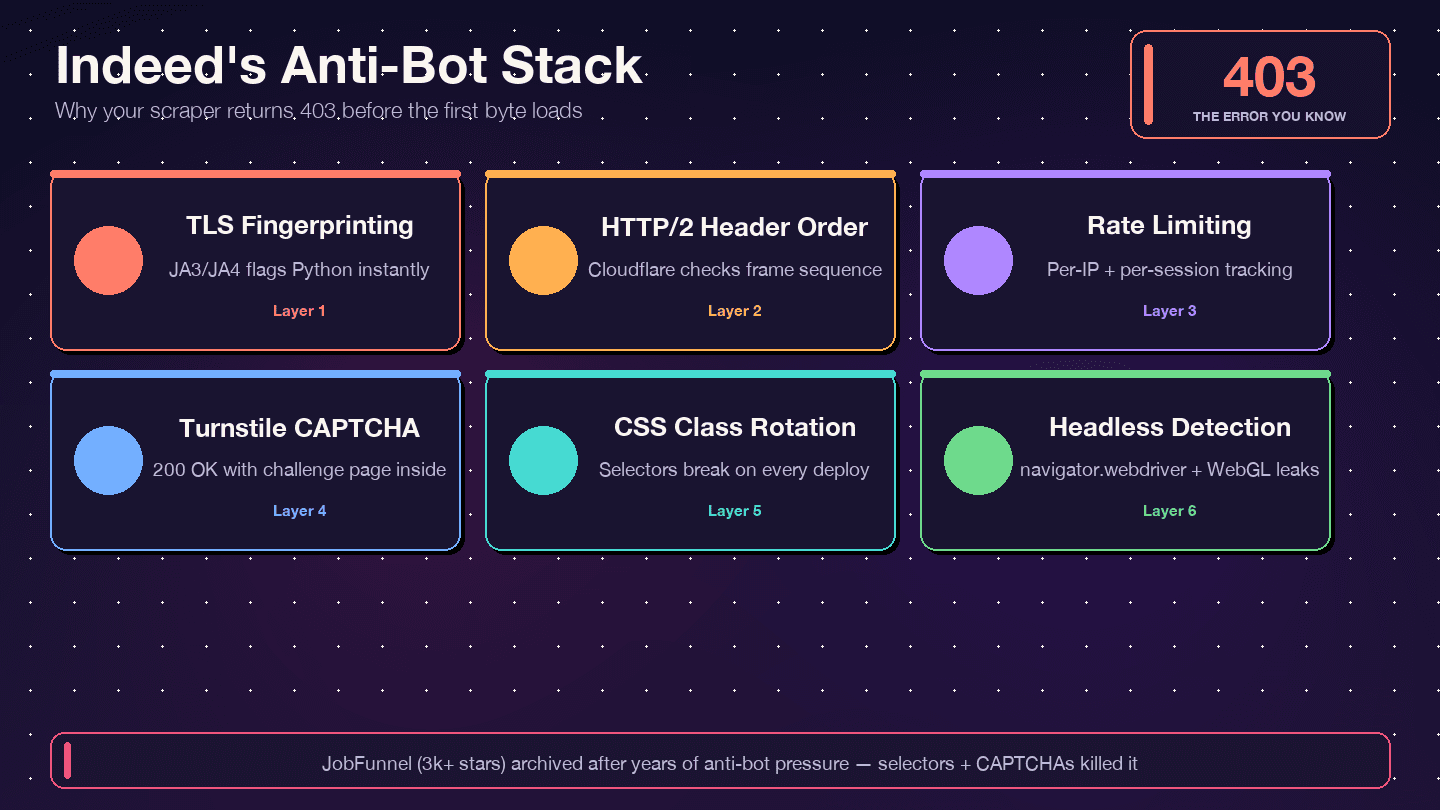
Indeed가 스크래퍼를 차단하는 이유
Indeed는 를 사용합니다. DataDome도 아니고, PerimeterX도 아닙니다. 응답 헤더만 봐도 알 수 있습니다. server: cloudflare, cf-ray, 그리고 봇 관리 쿠키 __cf_bm이 들어 있습니다. Cloudflare는 TLS 지문(JA3/JA4), HTTP/2 헤더 순서, 요청 패턴, 브라우저 행동 신호를 검사합니다. 그중 하나라도 사람 같지 않으면 403, 429, 503이 뜨거나, 가장 교묘한 경우에는 실제 공고 데이터 대신 Turnstile 챌린지 페이지가 포함된 200 OK를 받게 됩니다.
User-Agent와 요청 헤더를 돌려가며 사용하기
하나의 고정된 User-Agent는 차단되는 가장 빠른 길입니다. 현실적인 최신 문자열 풀에서 랜덤으로 선택하세요. 중요한 점: Chrome의 마이너 버전 필드는 User-Agent 축소 이후 되어 있습니다. 존재하지 않는 숫자를 만들면 안티봇이 바로 잡아냅니다.
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
6 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
7 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
8 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
9 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
10 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
11 "(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
12]
13headers = {
14 "User-Agent": random.choice(USER_AGENTS),
15 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
16 "Accept-Language": "en-US,en;q=0.9",
17 "Accept-Encoding": "gzip, deflate, br, zstd",
18 "Referer": "https://www.indeed.com/",
19 "Sec-Fetch-Dest": "document",
20 "Sec-Fetch-Mode": "navigate",
21 "Sec-Fetch-Site": "same-origin",
22}또한 sec-ch-ua Client Hints가 UA 버전과 일치하는지 확인하세요. Chrome 145라고 주장하는 User-Agent 옆에 sec-ch-ua: "Chrome";v="131"가 붙어 있으면 바로 수상 신호입니다.
요청 사이에 랜덤 지연 넣기
고정 간격은 패턴 감지에 걸립니다. 랜덤 지터를 사용하세요.
1import time, random
2# 각 요청 사이
3time.sleep(random.uniform(3, 6))
4# 차단 후 재시도할 때
5def backoff_sleep(attempt):
6 base = 4
7 sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
8 time.sleep(min(sleep_time, 60))와 의 공통된 실무 의견은 IP당 요청 간 3~6초, 세션당 대략 100 요청을 넘기기 전에 IP를 바꾸는 것입니다.
프록시 로테이션 사용하기
성공 여부를 좌우하는 가장 큰 요소는 이것입니다. AWS/GCP 대역의 데이터센터 프록시는 Cloudflare Enterprise 대상에서 성공률이 약 5~15% 수준이라 사실상 Indeed에서는 쓸 수 없습니다. 반면 주거용 프록시와 올바른 TLS 지문을 함께 쓰면 성공률이 80~95%까지 올라갑니다.
1PROXIES = [
2 "http://user:pass@us.residential.example:7777",
3 "http://user:pass@us.residential.example:7778",
4 "http://user:pass@us.residential.example:7779",
5]
6proxy = random.choice(PROXIES)
7response = cffi_requests.get(
8 url,
9 impersonate="chrome124",
10 headers=headers,
11 proxies={"https": proxy},
12 timeout=30,
13)2026년 기준 주거용 프록시 가격은 제공업체와 약정 수준에 따라 대략 입니다. Indeed 전용으로는 작은 풀부터 시작해 필요에 따라 확장하는 것이 좋습니다.
403, 429, 503 상태 코드를 우아하게 처리하기
무작정 재시도만 하지 마세요. 상태 코드마다 의미가 다릅니다.
1def fetch_with_retry(url, proxy_pool, max_retries=5):
2 for attempt in range(max_retries):
3 proxy = random.choice(proxy_pool)
4 headers["User-Agent"] = random.choice(USER_AGENTS)
5 try:
6 r = cffi_requests.get(
7 url,
8 impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
9 headers=headers,
10 proxies={"https": proxy},
11 timeout=30,
12 )
13 # 교묘한 "200이지만 챌린지 페이지" 사례 확인
14 if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
15 return r
16 if r.status_code == 403:
17 print(f"403 — 차단됨. 프록시를 바꾸고 재시도 {attempt + 1}회")
18 elif r.status_code == 429:
19 print(f"429 — 요청 제한에 걸림. 속도를 늦춥니다.")
20 elif r.status_code == 503:
21 print(f"503 — 서버 과부하 또는 JS 챌린지입니다.")
22 backoff_sleep(attempt)
23 except Exception as e:
24 print(f"요청 오류: \{e\}")
25 backoff_sleep(attempt)
26 raise RuntimeError(f"\{max_retries\}번 재시도 후 실패했습니다: \{url\}")가장 까다로운 건 200인데 챌린지 페이지가 온 경우입니다. 200을 성공으로 처리하기 전에 응답 본문에서 cf-turnstile이나 Just a moment 같은 표시를 항상 확인하세요.
더 쉬운 대안: Thunderbit가 안티봇을 대신 처리하게 하세요
프록시 풀 관리, 헤더 로테이션, TLS 지문 위장을 직접 만들고 유지하기 싫다면, 의 클라우드 스크래핑이 CAPTCHA, 프록시 로테이션, 안티봇 보호를 자동으로 처리합니다. 프록시 설정도 필요 없고, curl_cffi 설정도 필요 없고, CAPTCHA 해결 라이브러리도 필요 없습니다. 그냥 데이터가 필요할 때 가장 덜 저항이 큰 경로입니다.
왜 내 Indeed 스크래퍼는 자꾸 깨질까? 그리고 어떻게 고칠까?
403 장벽은 급성 통증입니다. 만성 통증은 유지보수예요. 오늘은 잘 돌아가던 스크래퍼가 다음 주에는 조용히 빈 데이터나 오래된 결과만 돌려줄 수 있습니다.
Indeed가 셀렉터를 깨뜨리는 방식
Indeed는 CSS 클래스명을 공격적으로 바꿉니다. Bright Data 가이드는 css-1m4cuuf, css-1rqpxry 같은 클래스가 “무작위로 생성된 것처럼 보이며, 빌드 시점에 생성된 것으로 추정된다”고 합니다. A/B 테스트 때문에 사용자마다 서로 다른 레이아웃을 볼 수도 있습니다. DOM 구조가 예고 없이 바뀌는 일도 흔합니다.
JobFunnel 사례가 좋은 교훈입니다. 한 기여자는 이렇게 말했습니다. "CaptchaBuster가 캡차는 잘 완화했지만, 여전히 페이지를 제대로 스크래핑하지 못한 이유는 오래된 Beautiful Soup 셀렉터 때문입니다." 즉, 스크래퍼가 차단된 게 아니라 잘못된 요소를 파싱하고 있었던 겁니다.
전략: DOM 파싱보다 숨겨진 JSON을 우선하기
window.mosaic.providerData 블롭은 적어도 2023년부터 스키마가 안정적이었습니다. metaData.mosaicProviderJobCardsModel.results[] 경로는 2026년에도 입니다. DOM 셀렉터는 매달 깨질 수 있지만, JSON 추출은 잘 깨지지 않습니다.
전략: 클래스명보다 데이터 속성 사용하기
DOM을 건드려야 한다면 기능적 속성을 타깃으로 삼으세요.
| 셀렉터 | 용도 |
|---|---|
[data-testid="slider_item"] | 각 채용 공고 카드 컨테이너 |
[data-testid="job-title"] 또는 h2.jobTitle > a | 직무명 링크 |
[data-testid="company-name"] | 고용주 이름 |
[data-testid="text-location"] | 위치 텍스트 |
각 카드의 data-jk="<jobkey>" | 2019년부터 변하지 않은 가장 안정적인 훅 |
셀렉터가 오래됐는지 알아내는 단언문 추가하기
스크래퍼가 결과 0개를 조용히 반환하게 두지 마세요. 매번 가져온 뒤 검사를 추가하세요.
1results = parse_hidden_json(html)
2assert len(results) > 0, (
3 f"Indeed가 start=\{start\}에서 빈 결과를 반환했습니다 — "
4 "차단, CAPTCHA, 또는 셀렉터 변화 가능성. "
5 f"응답 앞 500자: {html[:500]}"
6)실패 시 원시 응답의 처음 500~2000자를 로그에 남기세요. 그러면 Turnstile 챌린지인지, 로그인 벽인지, 스키마 변경인지 즉시 알 수 있습니다. q=python&l=remote처럼 고정된 쿼리로 매일 CI 수준의 스모크 테스트를 돌려, 결과가 0이 아닌지 확인하는 것도 좋습니다.
AI 대안: 절대 깨지지 않는 스크래퍼
Thunderbit의 AI는 매번 페이지 구조를 새로 읽기 때문에 하드코딩된 셀렉터나 정규식 패턴에 의존하지 않습니다. Indeed가 HTML을 바꾸면 Thunderbit도 자동으로 적응합니다. 이는 포럼 사용자들이 늘 최우선 불만으로 꼽는 유지보수 부담을 직접 해결해 줍니다. 아침에 Slack 메시지로 “또 빈 행만 반환하네”라는 말을 받아본 적이 있다면, 유지보수가 필요 없는 가치가 무엇인지 잘 아실 겁니다.
Python 없이 Indeed 스크래핑하기: 노코드 대안
대부분의 경쟁 가이드는 Python 코드를 작성할 것을 전제로 합니다. 하지만 포럼의 실제 이야기는 다릅니다. 사용자들은 *"버그와 오류가 끊이지 않아서 정말 너무 어렵다"*고 말하고, 어떤 사람들은 데이터를 얻기 위해 Fiverr에서 사람을 고용하라고까지 제안합니다. 그게 익숙하게 들린다면, 이 섹션이 탈출구입니다.
Thunderbit로 Indeed를 스크래핑하는 방법(단계별)
1단계: Chrome Web Store에서 을 설치하세요. 무료로 시작할 수 있습니다.
2단계: 브라우저에서 Indeed 검색 결과 페이지로 이동하세요. 예를 들어 https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX 같은 페이지입니다.
3단계: 브라우저 툴바의 Thunderbit 아이콘을 클릭한 뒤 **"AI 항목 추천"**을 누르세요. Thunderbit의 AI가 페이지를 스캔해 직무명, 회사, 위치, 급여, 공고 URL, 게시 날짜 같은 열을 자동으로 감지합니다. 추천된 필드는 검토하고 조정할 수 있습니다. 필요 없는 열은 제거하고, 원하는 내용을 평이한 영어로 설명해 커스텀 열을 추가할 수도 있습니다.
4단계: **"스크래핑"**을 클릭하세요. Thunderbit가 페이지에서 데이터를 추출해 구조화된 테이블로 보여줍니다. 설정한 필드가 들어간 채용 공고 행들이 보일 것입니다.
하위 페이지 스크래핑으로 데이터 확장하기
목록 페이지를 스크래핑한 뒤 **"하위 페이지 스크래핑"**을 클릭하면 Thunderbit가 각 개별 공고 상세 페이지를 방문합니다. 전체 공고 설명, 자격 요건, 복리후생, 지원 링크를 가져오며 추가 설정은 필요 없습니다. 각 /viewjob?jk=<jobkey> URL을 방문하는 두 번째 Python 스크래퍼를 따로 작성하는 것과 같은 효과인데, 클릭 한 번이면 됩니다.
페이지네이션 자동 처리
Thunderbit는 Indeed의 클릭 기반 페이지네이션을 자동으로 처리합니다. 오프셋 URL을 직접 만들거나 페이지 루프를 작성할 필요가 없습니다. 페이지를 넘기며 결과를 자동으로 모아 줍니다.
즐겨 쓰는 도구로 내보내기
스크래핑한 데이터는 CSV, Excel, Google Sheets, Airtable, Notion으로 내보낼 수 있으며 입니다. csv.writer()나 pandas.to_csv() 코드를 작성할 필요가 없습니다.
Python과 Thunderbit, 언제 무엇을 써야 할까?
| 상황 | 최적 도구 |
|---|---|
| cron/Airflow로 자동화하는 커스텀 데이터 파이프라인 | Python |
| 더 큰 코드베이스에 통합해야 할 때 | Python |
| 매우 세밀한 파싱 로직이 필요할 때 | Python |
| 일회성 리서치나 시장 분석 | Thunderbit |
| 비기술 팀원도 데이터를 써야 할 때 | Thunderbit |
| 403 디버깅 없이 지금 바로 데이터가 필요할 때 | Thunderbit |
| 추가 설정 없이 하위 페이지까지 확장 수집할 때 | Thunderbit |
시간 비교를 해보면, Python 설정 + 안티봇 디버깅 = 몇 시간에서 며칠입니다(특히 처음이라면). Thunderbit = 같은 데이터를 2분 이내에 얻을 수 있습니다. Python이 틀렸다는 말이 아닙니다. 무엇이 필요한지에 따라 다르다는 뜻입니다.
Indeed 스크래핑은 합법일까? 알아야 할 것들
상위권 Indeed 스크래핑 가이드들은 대부분 합법성 문제를 다루지 않는데, 포럼에서 *"Indeed 스크래핑은 합법인가요?"*라는 질문이 자주 나오는 걸 생각하면 다소 의외입니다. 아래 내용은 법률 자문은 아니지만, 현재의 전체적인 상황은 이렇습니다.
Indeed의 이용약관
Indeed의 서비스 약관()에는 포괄적인 “스크래핑 금지” 조항이 없습니다. 명시적으로 자동화를 금지하는 부분은 A.3.5항뿐인데, 여기서는 *"Indeed Apply 프로세스를 자동화하기 위한 자동화, 스크립팅, 봇의 사용"*을 금지합니다. 이는 공개 채용 목록을 수동적으로 읽는 행위가 아니라 Apply 흐름에만 좁게 적용됩니다. Indeed의 주된 집행 수단은 법정이 아니라 기술적 차단, 즉 Cloudflare 챌린지, IP 차단, 디바이스 지문 식별입니다.
관련 판례
가장 많이 언급되는 미국 판례는 hiQ Labs v. LinkedIn입니다. 9순회 항소법원은 공개적으로 접근 가능한 데이터를 스크래핑하는 행위가 “CFAA(컴퓨터 사기 및 남용 방지법)를 위반하지 않을 가능성이 높다”고 판시했습니다. 다만 hiQ는 이후 가짜 LinkedIn 프로필을 만들고 약관에 동의한 직원들 때문에 을 지게 되었습니다.
보다 최근의 Meta v. Bright Data(캘리포니아 북부지법, 2024년 1월)는 더 분명한 판단을 남겼습니다. Chen 판사는 Facebook과 Instagram의 약관이 “로그아웃 상태의 공개 데이터 스크래핑을 막지 않는다”고 했습니다. Meta는 이듬달 나머지 청구를 자발적으로 취하했습니다.
Indeed의 robots.txt
Indeed의 는 기본 User-agent: *에 대해 /jobs/와 /job/를 광범위하게 금지하지만, Googlebot과 Bingbot에는 개별 공고 상세 페이지인 /viewjob? 접근을 명시적으로 허용합니다. AI 학습 크롤러(GPTBot, CCBot, anthropic-ai)는 강하게 제한됩니다. robots.txt는 미국에서 법적으로 구속력은 없지만, 이를 존중하는 것은 좋은 관행이자 선의의 증거입니다.
책임 있는 스크래핑을 위한 실무 지침
- 공개적으로 접근 가능한 데이터만 스크래핑하세요. 로그인하지 말고, 가짜 계정을 만들지도 마세요.
- 속도 제한을 지키세요. IP당 3~6초에 1회, 동시성은 한 자릿수가 적당합니다.
- 스크래핑한 데이터를 자신만의 채용 사이트인 것처럼 재게시하지 마세요.
- 데이터를 개인 연구나 내부 분석에 사용하세요. 허가 없이 상업적 재판매에 쓰지 마세요.
- 필요 없는 PII는 폐기하거나 해시 처리하고, 개인 정보에 가까운 데이터에는 보존 한도를 두세요.
- 대규모 운영이거나 EU/영국을 대상으로 한다면 변호사와 상담하세요. GDPR 제14조의 투명성 의무는 스크래핑한 개인정보에도 적용됩니다.
위험도 스펙트럼으로 보면, 개인 구직 자동화는 낮은 편이고, Indeed 데이터를 대규모로 상업 재판매하는 것은 높은 편입니다.
결론 및 핵심 요약
Python으로 Indeed를 스크래핑하는 것은 가능합니다. 다만 주말에 한 번 만들고 끝나는 프로젝트는 아닙니다. Indeed의 Cloudflare 보호, 바뀌는 셀렉터, 강력한 안티봇 대응을 생각하면, 올바른 도구와 기대치를 가지고 접근해야 합니다.
이번 글에서 가져가면 좋을 점은 다음과 같습니다.
- Indeed는 웹상에서 가장 풍부한 채용 시장 데이터 소스입니다. 월간 방문자 3억 5천만 명, 공고 1억 3천만 개 수준이지만, 스크래퍼에는 강하게 맞섭니다.
- 숨겨진 JSON 추출(
window.mosaic.providerData)이 가장 튼튼한 Python 방식입니다. 스키마는 수년간 안정적이었지만, CSS 셀렉터는 매달 깨집니다. - 브라우저 impersonation과 함께 쓰는
curl_cffi가 2026년 기준 Cloudflare 보호 사이트의 기본 HTTP 클라이언트입니다. 일반requests와httpx는 TLS 지문만으로 차단될 수 있습니다. - 403 오류를 피하려면 항상 헤더 로테이션, 랜덤 지연, 주거용 프록시를 사용하세요. 데이터센터 프록시는 Cloudflare Enterprise 앞에서 거의 쓸모가 없습니다.
- 셀렉터가 깨졌는지, 아니면 챌린지 페이지를 받고 있는지 즉시 알 수 있도록 단언문 검사를 추가하세요.
- 비기술 사용자나 빠른 결과가 필요한 사람에게는, 가 프록시, 디버깅, 유지보수 없이 사이트 변화에 자동 적응하는 노코드 AI 경로를 제공합니다.
노코드 경로를 시험해 보고 싶다면, 를 제공하니 부담 없이 Indeed에서 테스트해 볼 수 있습니다. Python으로 가신다면 위의 코드 예제들이 좋은 출발점이 될 거예요. 다만 안티봇 회피를 사후 문제가 아니라 핵심 요소로 다뤄야 한다는 점만 꼭 기억하세요.
웹 스크래핑 접근법과 도구에 대해 더 알고 싶다면 , , 가이드를 확인해 보세요. 또한 에서도 튜토리얼을 보실 수 있습니다.
자주 묻는 질문
Indeed를 스크래핑할 때 어떤 Python 라이브러리가 가장 좋나요?
HTTP 요청에는 2026년 기준 curl_cffi가 가장 강력한 선택입니다. 실제 브라우저의 TLS 지문을 흉내 내며, Cloudflare 우회에 필수적입니다. 덜 보호된 대상이라면 HTTP/2를 지원하는 httpx도 괜찮은 대안입니다. HTML 파싱에는 lxml과 함께 쓰는 BeautifulSoup4가 여전히 표준입니다. 브라우저 자동화는 Playwright(playwright-stealth 포함)나 undetected-chromedriver가 잘 작동하지만, 둘 다 점점 더 탐지되고 있습니다. 숨겨진 JSON 정규식 방식(window.mosaic.providerData)을 쓰면 무거운 파싱 자체를 거의 피할 수 있습니다.
Indeed를 스크래핑할 때 왜 계속 403 오류가 뜨나요?
Indeed는 Cloudflare Bot Management를 사용하며, TLS 지문(JA3/JA4), HTTP/2 헤더 순서, 요청 패턴, 브라우저 행동을 검사합니다. 일반 requests를 쓰고 있다면 TLS 지문만으로도 바로 Python 스크립트로 식별되어, 헤더를 읽기도 전에 403이 떨어집니다. 이를 해결하려면 브라우저 impersonation이 가능한 curl_cffi로 바꾸고, 현실적인 User-Agent 문자열을 로테이션하며, 랜덤 지연(3~6초)을 넣고, 주거용 프록시를 사용하세요. 또 “200인데 Turnstile 챌린지인 경우”도 확인해야 합니다. 응답 본문에서 cf-turnstile 표시를 검색하세요.
코딩 없이 Indeed를 스크래핑할 수 있나요?
네. 같은 도구를 쓰면 몇 번의 클릭만으로 Indeed 채용 목록을 추출할 수 있습니다. Chrome 확장 프로그램을 설치하고, Indeed 검색 페이지로 이동한 뒤, "AI 항목 추천"을 누르고, 그다음 "스크래핑"을 클릭하면 됩니다. Thunderbit의 AI가 직무명, 회사, 위치, 급여 같은 필드를 자동 감지합니다. 페이지네이션, 하위 페이지 확장 수집(전체 공고 설명), 안티봇 보호도 자동으로 처리합니다. CSV, Google Sheets, Airtable, Notion으로 무료 내보내기도 가능합니다.
Indeed는 HTML 구조를 얼마나 자주 바꾸나요?
Indeed는 CSS 클래스명(css-1m4cuuf 같은 무작위 해시 문자열)을 자주 바꾸고, DOM 요소 구조도 예고 없이 재편합니다. A/B 테스트 때문에 서로 다른 사용자가 동시에 다른 레이아웃을 볼 수 있습니다. 숨겨진 JSON 방식(window.mosaic.providerData)은 훨씬 안정적이며, 적어도 2023년부터 스키마가 일관적이었습니다. DOM 셀렉터를 써야 한다면 CSS 클래스보다 data-testid 속성과 data-jk(job key)를 우선하세요.
Indeed를 스크래핑하는 건 합법인가요?
미국에서는 9순회 항소법원의 hiQ v. LinkedIn(2022) 판결과 Meta v. Bright Data(2024) 결정에 비춰볼 때, 로그아웃 상태에서 공개적으로 접근 가능한 Indeed 공고 URL을 스크래핑하는 행위가 CFAA 책임으로 이어질 가능성은 낮습니다. Indeed의 약관은 공개 목록의 수동적 열람이 아니라 Apply 프로세스 자동화만을 구체적으로 금지합니다. 그렇다고 해도 항상 책임 있게 스크래핑해야 합니다. 로그인하지 말고, 가짜 계정을 만들지 말고, 속도 제한을 지키고, 데이터를 자신만의 채용 사이트처럼 재게시하지 말고, 수집한 개인정보(채용 담당자 이름, 이메일)는 GDPR/CCPA 기준에 따라 신중히 다루세요. 상업적 규모라면 변호사 상담을 권합니다.
더 알아보기