Google은 2018년에 Flights API를 종료했지만, 항공권 가격은 지금도 끊임없이 바뀝니다. 국내 노선 하나만 봐도 48시간 동안 최대 17번까지 변동될 수 있습니다(). 이런 데이터를 프로그램으로 다루고 싶다면, 사실상 웹 스크래핑이 거의 유일한 방법입니다.
저는 Google에서 항공편 데이터를 가져오는 여러 방법을 오랫동안 테스트해 왔고, 특히 2025년 1월 Google이 SearchGuard를 배포한 뒤로 상황이 많이 달라졌습니다. 이 가이드에서는 Playwright를 활용해 Google Flights용 Python 스크래퍼를 직접 만드는 방법, 대부분의 사람들이 막히는 안티봇 대응법, 그리고 이를 자동 가격 추적기와 알림 시스템으로 확장하는 방법까지 단계별로 설명합니다. 코드를 전혀 쓰고 싶지 않다면, 를 이용해 약 2분 만에 같은 결과를 얻는 노코드 방법도 함께 소개합니다.
왜 Python으로 Google Flights를 스크래핑해야 할까?
Google Flights는 항공권 검색 시장을 사실상 장악하고 있습니다. 미국 모바일 검색 점유율은 해 주요 OTA를 모두 앞질렀습니다. 이를 뒷받침하는 여행 메타검색 시장은 규모로, 연평균 30.2%씩 성장하고 있습니다. 하지만 QPX Express API가 되면서, 이 데이터를 공식적으로 프로그램에서 가져올 방법은 사라졌습니다.
반면 항공권 가격은 같은 일정이라도 까지 출렁이며, 최저가와 최고가의 평균 차이는 약 20달러에 달합니다. Delta 같은 항공사는 동적 가격 책정을 위해 77개의 요금 구간을 사용합니다. 2026년 초 미국 왕복 평균 항공권 가격은 408달러 수준이며, 항공료는 전년 대비 했습니다.
강력한 플랫폼, 공식 API 부재, 변동성이 큰 요금. 그래서 Python으로 Google Flights를 스크래핑하는 프로젝트가 GitHub와 여행 커뮤니티에서 꾸준히 인기를 끌고 있습니다.
어떤 사람에게 어떤 도움이 되는지도 살펴보겠습니다:
| 사용자 유형 | 활용 사례 | 핵심 이점 |
|---|---|---|
| 개인 여행자 | 특정 노선의 가격을 장기 추적 | 항공편당 평균 $50 절약 |
| 여행사 | 경쟁사 요금 인텔리전스 확보 | 실시간 운임 패리티 모니터링 |
| 기업 출장팀 | 노선별 비용 최적화 | 기업 출장비 10~30% 절감 |
| 개발자 | 항공권 비교 서비스 구축 | 가격 데이터의 프로그램 접근 |
| 연구자 | 항공사 가격 변동성 분석 | 학술 및 시장 조사 |
포럼 사용자들도 왜 스크래핑으로 돌아섰는지 아주 직설적으로 말합니다. *"Google Flights API가 중단돼서 웹 스크래핑을 써야 한다"*는 반응이 반복해서 나오죠. ROI도 분명합니다. 를 주장하고, Expedia의 2026년 데이터에 따르면 출발 8~15일 전에 예약하면 국내선에서 약 할 수 있습니다.
Google Flights에서 어떤 데이터를 수집할 수 있을까?
Google Flights 결과 페이지에는 생각보다 풍부한 데이터가 들어 있습니다. 일반적으로 다음 항목을 가져올 수 있습니다:
- 항공사명(및 로고)
- 출발 시간과 공항 코드
- 도착 시간과 공항 코드
- 총 비행 시간
- 경유 횟수 및 경유지 정보(공항, 체류 시간, 야간 경유 여부)
- 항공권 가격(통화별)
- CO2 배출량(kg CO2e, 일반 항공편 대비 백분율 차이)
- 여행 클래스, 항공편 번호, 기종
- 좌석 공간 정보
- 편의 기능(와이파이, 전원 콘센트, 미디어 스트리밍)
- 가격 수준 표시(낮음/보통/높음)
- 지연 경고("30분 이상 지연되는 경우가 많음")
수집 가능한 데이터는 노선, 날짜, 티켓 유형(편도/왕복)에 따라 달라집니다. 아래는 단일 항공편 기록을 JSON으로 정리한 예시입니다:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Python 환경 설정하기
스크래핑 코드를 작성하기 전에 몇 가지 준비가 필요합니다.
사전 준비:
- 난이도: 중급
- 소요 시간: 전체 튜토리얼 기준 약 1~2시간
- 준비물: Python 3.7 이상, 기본적인 Python 지식, Chrome 기반 브라우저
필요한 라이브러리 설치
브라우저 자동화에는 Playwright를 사용합니다(Google Flights는 100% JavaScript로 렌더링되기 때문에, 단순 HTTP 요청으로는 의미 있는 결과가 나오지 않습니다). 여기에 몇 가지 보조 도구를 더합니다:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — 헤드리스 브라우저 자동화, JavaScript 렌더링 처리, 내장 대기 기능 제공
- playwright-stealth — 흔한 봇 탐지 신호를 보정
- pandas — 이후 데이터 분석과 CSV 내보내기용
Selenium이나 requests 대신 Playwright를 쓰는 이유
Google Flights는 requests + BeautifulSoup만으로는 동작하지 않습니다. 페이지 콘텐츠가 전부 JavaScript로 렌더링되기 때문입니다. 실제 브라우저가 필요합니다.
| 기능 | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| JS 렌더링 | 완전 지원 | 완전 지원 | 없음 |
| 속도 | 전체적으로 42% 더 빠름 | 기준점 | 이 용도에서는 해당 없음 |
| 비동기 지원 | 기본 지원 | 순차 처리만 | 해당 없음 |
| 메모리 사용량 | 30% 더 적음 | 더 높음 | 최소 |
| 봇 탐지 회피 | 양호(stealth 사용 시) | 탐지되기 쉬움 | 해당 없음 |
Playwright는 더 빠르고, 더 현대적이며, 비동기 처리도 뛰어납니다. 특히 Google Flights용으로는 가장 적합한 선택입니다.
단계별 가이드: Python으로 Google Flights 스크래핑하기
이제 본격적인 튜토리얼입니다. 스크래퍼를 하나씩 완성해 보겠습니다.
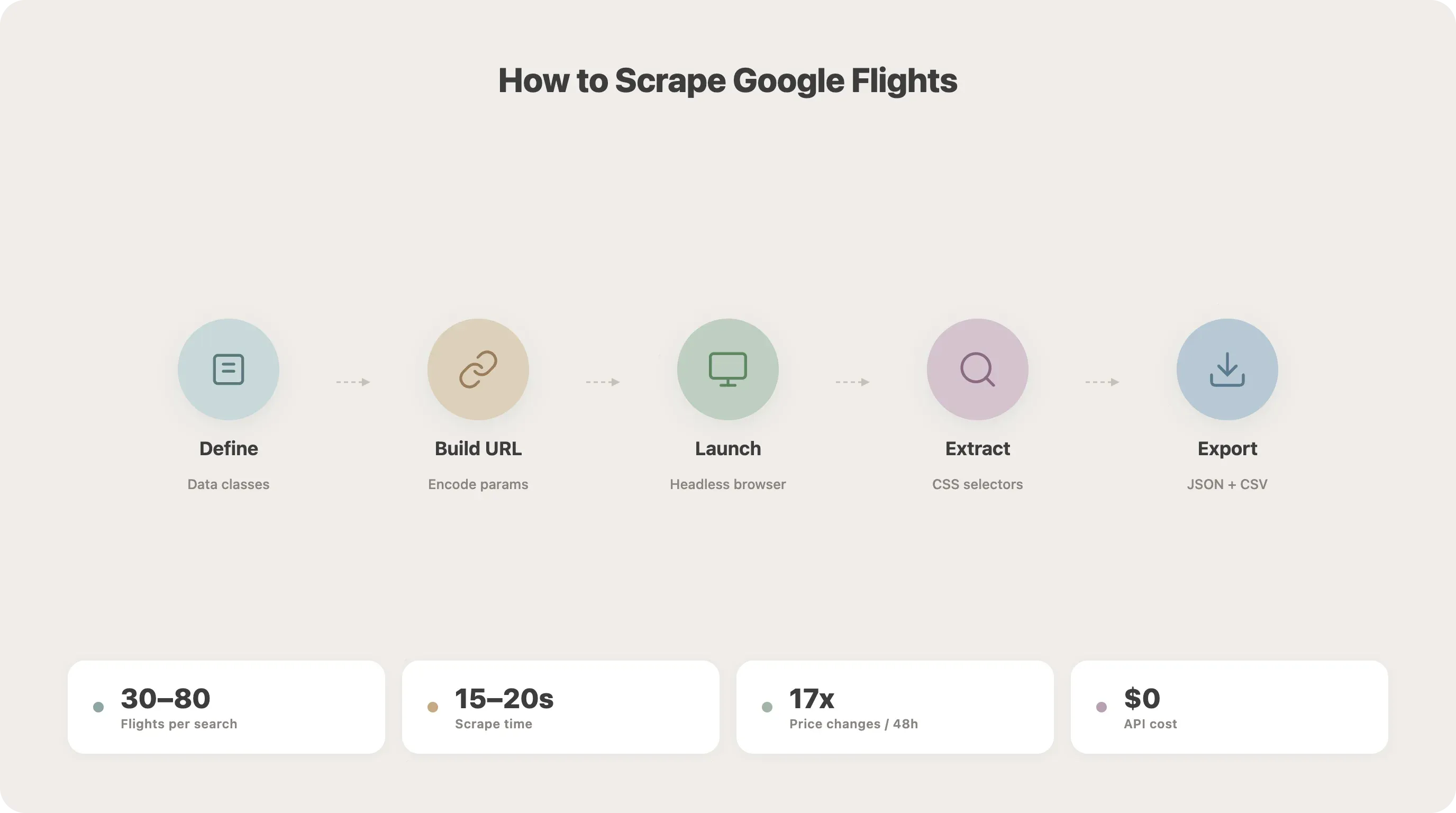
1단계: 데이터 클래스 정의하기
먼저 Python dataclass로 검색 조건과 항공편 데이터를 구조화합니다. 이렇게 해 두면 코드가 깔끔해지고, 나중에 확장하기도 쉽습니다.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # e.g., "SFO"
6 destination: str # e.g., "JFK"
7 departure_date: str # e.g., "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" or "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""각 필드는 페이지에서 추출할 데이터와 직접 연결됩니다. 이런 구조를 미리 잡아두면 나중에 지저분한 딕셔너리를 여기저기 넘기지 않아도 됩니다.
2단계: Google Flights URL 구조 이해하기
Google Flights는 tfs URL 파라미터에 Base64 인코딩된 Protobuf를 사용해 검색 조건을 저장합니다. 이 인코딩을 역공학할 수도 있지만, 더 간단한 방법은 자연어 쿼리 URL을 만드는 것입니다.
가장 쉬운 방식은 검색 쿼리 형식을 사용하는 것입니다:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USD더 세밀하게 제어하고 싶다면 URL을 코드로 생성할 수도 있습니다:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"대안으로 Protobuf 인코딩을 역공학하는 방법도 있지만, 이 방식은 Google이 내부 형식을 바꾸면 쉽게 깨집니다. GitHub의 같은 라이브러리는 Protobuf 디코딩으로 HTML 파싱을 아예 우회하지만, Google이 내부 데이터 형식을 바꾸면 역시 영향을 받을 수 있는 더 고급 접근법입니다.
3단계: 브라우저 실행 후 Google Flights로 이동하기
아래는 Playwright 설정 예시입니다. 시작 단계부터 탐지 위험을 낮추기 위해 playwright-stealth를 사용합니다.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Pre-set cookie consent to skip the popup
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()실서비스에서는 헤드리스 모드로 실행하고(디버깅할 때는 headless=False로 바꾸세요), 현실적인 viewport와 user-agent를 설정하며, SOCS 쿠키를 미리 넣어 동의 팝업을 건너뜁니다. 이 부분은 뒤의 안티봇 섹션에서 더 자세히 설명합니다.
4단계: 검색 결과 페이지로 이동하기
생성한 URL을 열고 항공편 결과가 나타날 때까지 기다립니다:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Wait for flight results to load
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )여기서 타임아웃이 발생한다면 보통 두 가지 이유입니다. 동의 팝업이 페이지를 가로막았거나(3단계의 쿠키 설정 참고), Google이 CAPTCHA를 보여주는 경우입니다. 두 경우 모두 뒤의 안티봇 섹션에서 다룹니다.
5단계: 모든 항공편 결과 불러오기
Google Flights는 추가 결과를 "Show more flights" 버튼 뒤에 숨겨둡니다. 모든 항공편이 보일 때까지 버튼을 반복 클릭해야 합니다:
1 # Click "Show more flights" until all results are loaded
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 break이 루프는 버튼을 클릭한 뒤 2초간 새 결과 렌더링을 기다리고, 더 이상 버튼이 보이지 않으면 종료합니다. 제 테스트 기준으로 대부분의 노선은 1~3페이지 정도 결과가 나옵니다.
6단계: CSS 선택자로 항공편 데이터 추출하기
이제 실제로 로드된 페이지에서 항공편 데이터를 파싱합니다. 아래 선택자는 2026년 4월 기준으로 확인한 값입니다(왜 이 날짜가 중요한지는 아래 유지보수 섹션에서 설명합니다).
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Airline name
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Departure time
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Arrival time
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Duration
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Stops
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Price
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2 emissions
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flights주의할 점이 있습니다. pIav2d, sSHqwe, FpEdX 같은 클래스명은 Google의 Closure Compiler가 생성한 것으로, 빌드가 바뀔 때마다 달라질 수 있습니다. 반면 aria-label 기반 선택자는 훨씬 안정적입니다. 아래에서 전체 유지보수 전략을 설명하겠습니다.
7단계: 결과를 JSON 또는 CSV로 저장하기
마지막으로, 스크래핑한 데이터를 타임스탬프와 함께 저장합니다(나중에 가격 추적할 때 매우 중요합니다):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Also save as CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())이 코드를 실행하면 flights.json과 flights.csv에 결과가 저장됩니다. 제 테스트에서는 SFO-JFK 검색 시 보통 30~80개의 항공편 옵션이 나오고, 전체 실행 시간은 약 15~20초였습니다.
Google Flights 스크래핑을 위한 안티봇 생존 가이드
대부분의 튜토리얼은 여기서 끝납니다. 대부분의 스크래퍼도 여기서 실패하죠. Google은 하면서, 거의 모든 SERP 스크래퍼를 하룻밤 사이에 무력화했습니다. Google은 이를 "수만 시간의 인력과 수백만 달러 투자가 들어간 결과물"이라고 설명합니다. Google Flights는 스크래핑 난이도가 으로 평가됩니다.
경쟁 글들은 이 부분을 깊게 다루지 않지만, 실제로 스크래퍼가 멈추는 가장 큰 이유가 바로 이것입니다. 무엇과 맞서야 하는지, 그리고 어떻게 대응해야 하는지 살펴보겠습니다.

요청 사이에 무작위 지연 넣기
속도 제한을 피하는 가장 기본적인 방법입니다. 코드는 두 줄이면 충분하고, 효과는 중간 정도입니다:
1import time
2import random
3time.sleep(random.uniform(3, 7))페이지 이동 사이사이에 넣으세요. 매번 정확히 5초처럼 고정된 간격은 오히려 의심 신호입니다. 반드시 랜덤화해야 합니다.
User-Agent 로테이션
매 요청마다 같은 user-agent를 보내면 너무 티가 납니다. 여러 문자열을 번갈아 사용하세요:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)헤드리스 탐지 우회
Google은 navigator.webdriver 플래그와 기타 자동화 신호를 확인합니다. playwright-stealth가 대부분을 처리해 주지만, 3단계에서 보여준 실행 인자도 함께 설정해야 합니다. 핵심 플래그는 다음과 같습니다:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]이 정도면 기본 탐지는 어느 정도 넘길 수 있습니다. SearchGuard는 마우스 속도, 키보드 입력 타이밍, 스크롤 패턴까지 더 깊게 봅니다. 하지만 중간 정도의 트래픽이라면 stealth 모드와 현실적인 지연만으로도 충분한 경우가 많습니다.
프록시 로테이션: 데이터센터 vs. 주거용
몇 번 검색하는 수준을 넘어서면 프록시가 필요합니다. 차이가 꽤 큽니다:
보호가 강한 사이트를 스크래핑할 때는 주거용 프록시가 성공 요청 1건당 비용 기준으로 할 수 있습니다. 2026년 기준 제공업체 가격은 Smartproxy $7/GB부터, Bright Data $8.40/GB, Oxylabs $8/GB 수준입니다.
Playwright에 프록시를 추가하려면 이렇게 합니다:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)쿠키 동의 팝업 처리하기
사용자들은 "I agree to terms" 팝업이 가장 큰 방해 요소라고 자주 말합니다. *"처음에 Google이 'I agree to terms and conditions' 팝업을 띄울 것이다"*라는 식이죠. 가장 깔끔한 해결책은 3단계에서 보여준 것처럼 SOCS 쿠키를 미리 설정하는 것입니다. 그래도 안 되면 직접 클릭해서 넘기세요:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # No popup present참고로 버튼 문구는 지역에 따라 다릅니다. 독일어는 "Alle akzeptieren", 프랑스어는 "Tout accepter"입니다.
안티봇 빠른 참고표
| 기술 | 난이도 | 효과 | 코드 필요 여부 |
|---|---|---|---|
| 무작위 지연(2~7초) | 낮음 | 중간 | 2줄 |
| User-agent 로테이션 | 낮음 | 중간 | 5줄 |
| 헤드리스 탐지 우회 | 중간 | 높음 | Playwright 실행 인자 |
| playwright-stealth 플러그인 | 중간 | 기본 사이트에서 60~80% | pip 설치 |
| 프록시 로테이션(데이터센터) | 중간 | 중간 | 설정 필요 |
| 프록시 로테이션(주거용) | 중간 | 85~95% 성공 | 설정 필요 |
| 쿠키 동의 사전 설정(SOCS) | 낮음 | 필수 | 1줄 |
권장 안전 속도는 IP 로테이션을 사용해 요청 간 10~20초 지연을 두는 것입니다. Google의 임계치는 IP당 분당 약 100회 요청이며, 하루 1,000회 이상 지속되면 일시적 차단이 걸릴 수 있습니다.
Google Flights 선택자가 계속 깨지는 이유와 해결 방법
단연코 가장 큰 문제입니다. 포럼에는 "결과가 전부 빈 리스트 14개뿐이다" 같은 글이 넘쳐납니다. 대부분의 튜토리얼은 선택자만 알려주고, 왜 깨지는지는 설명하지 않습니다.
왜 Google Flights 선택자가 바뀌는가
이유는 크게 세 가지입니다.
-
Closure Compiler 난독화. Google은 를 사용해
goog.setCssNameMapping()으로BVAVmf,YMlIz같은 클래스명을 생성합니다. 이런 값은 빌드가 바뀔 때마다 달라집니다. 때로는 매주 바뀌기도 합니다. -
A/B 테스트. 사용자마다 서로 다른 HTML 구조가 동시에 노출됩니다. 내 환경에서는 잘 되는데 다른 지역에서는 실패할 수 있습니다.
-
로케일 차이. EU 사용자는 미국 사용자와 다른 용어, 레이아웃, 데이터 필드를 보게 됩니다.
더 튼튼한 선택자 작성하기
겉모습보다 의미에 연결된 선택자를 우선하세요:
1# Fragile — breaks on every build
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# More resilient — tied to accessibility labels
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Also resilient — text-based matching
6more_btn = page.locator('button:has-text("Show more flights")')선택자 안정성 순서(가장 안정적 → 가장 불안정):
aria-label속성 — 접근성 목적이라 잘 바뀌지 않음data-*속성 — 기능 목적의 명시적 속성role속성 — ARIA 역할은 의미 기반- 텍스트 기반 선택자 — 화면에 보이는 문구와 일치
- 클래스명 부분 일치 — 예:
[class*="price"] - 난독화된 전체 클래스명 — 가능하면 피하세요
검증 함수 추가하기
선택자가 깨져서 빈 데이터가 조용히 저장되게 두지 마세요. 초기에 잡아내야 합니다:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Missing '{field_name}' — selectors may need updating"
11 )
12 valid = False
13 return valid스크래핑한 모든 항공편에 대해 이 검증을 실행하세요. 경고가 뜨기 시작하면 페이지 구조를 다시 확인하고 선택자를 업데이트할 때입니다.
선택자 유지보수 전략
- 매달 한 번, 또는 결과 품질이 떨어지면 즉시 선택자를 점검
- 선택자는 별도 설정 딕셔너리에 분리해 두면 수정이 쉬움
- 이 글의 선택자는 2026년 4월 기준으로 마지막 검증됨
- 대안으로 를 고려할 수 있음. 이 라이브러리는 CSS 선택자 대신 Protobuf 디코딩을 사용해 이 문제를 우회하지만, Google이 내부 데이터 형식을 바꾸면 역시 영향을 받을 수 있음
1회성 스크래핑에서 자동 Google Flights 가격 추적기로 확장하기
대부분의 튜토리얼은 "JSON으로 저장하기"에서 끝납니다. 하지만 이 글의 제목은 "Price Alerts"입니다. 이제 그 부분을 완성해 보겠습니다.
![]()
스크래퍼를 자동 실행되도록 예약하기
옵션 1: Python schedule 라이브러리(가장 간단하고, 플랫폼 독립적):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)옵션 2: cron 작업(Linux/Mac):
1# Run at 6 AM and 6 PM daily
20 6,18 * * * cd /path/to/scraper && python scraper.py옵션 3: Windows 작업 스케줄러 — 원하는 일정으로 python scraper.py를 실행하는 기본 작업을 만드세요.
이 방식들의 공통점은 항상 켜져 있는 머신이 필요하다는 점입니다. 노트북이 잠자기 상태로 들어가면 스크래핑도 놓치게 됩니다.
과거 가격 데이터 저장하기
JSON 파일을 덮어쓰는 방식 대신 SQLite 데이터베이스에 누적 저장하도록 바꿉니다:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()일주일 동안 하루 두 번씩 스크래핑하면, 이제 가격 추세를 보기 시작할 만큼 충분한 데이터가 쌓입니다.
가격 추세 분석하고 알림 설정하기
과거 데이터에서 가장 저렴한 항공권을 찾아봅시다:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Cheapest: ${cheapest['price_usd']:.0f} on "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)가격이 설정한 기준 아래로 내려가면 이메일 알림을 보냅니다:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Price drop alert! {route}: ${price:.0f} "
6 f"(below your ${threshold:.0f} threshold)"
7 )
8 msg["Subject"] = f"Flight Deal: {route} at ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# After each scrape, check for deals
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")권장 스크래핑 빈도는 다음과 같습니다. 개인 가격 추적이라면 하루 두 번이면 충분하고, 탐지 위험도 낮출 수 있습니다(시간은 랜덤하게 두는 것이 좋습니다). 비즈니스 모니터링이라면 4~6시간마다가 적당합니다. 시간당 스크래핑은 단기 세일 기간에만, 그리고 잠시만 사용하는 것이 좋습니다.
쉬운 방법: Thunderbit의 Scheduled Scraper
cron 작업, 항상 켜진 서버, 프록시 설정을 직접 관리하는 것이 너무 번거롭게 느껴진다면, 의 Scheduled Scraper가 같은 일을 훨씬 적은 부담으로 처리합니다. 스크래핑 간격을 자연어로 설명하고, Google Flights URL을 넣기만 하면 됩니다. 그러면 Thunderbit의 클라우드 인프라에서 자동 실행되며, 내장된 안티봇 대응 기능도 함께 제공되고 결과는 로 바로 내보낼 수 있습니다. 물론 전체 Python 방식의 완전한 대체재는 아닙니다(커스터마이징은 줄어듭니다). 하지만 목표가 "가격 추적용 스프레드시트"라면 가장 빠른 해결책입니다. 로도 사용해 볼 수 있습니다.
Python이 과할 때: 노코드로 Google Flights 스크래핑하는 방법
위의 내용을 다 구현하고 나니 솔직히 말씀드리면, 꽤 많은 구성 요소가 들어갑니다. 누구에게나 이 정도 제어가 필요한 것은 아닙니다. 선택자는 깨지고, 프록시는 돌려야 하고, cron은 점검해야 하죠. 목적이 단순히 "항공권 가격을 정기적으로 스프레드시트에 넣는 것"이라면 더 빠른 방법도 있습니다.
비교: 직접 만드는 Python 방식 vs. API 서비스 vs. Thunderbit
| 접근 방식 | 설정 시간 | 코딩 필요 여부 | 안티봇 대응 | 스케줄링 | 비용 |
|---|---|---|---|---|---|
| DIY Playwright(이 튜토리얼) | 1~2시간 | Python(중급) | 수동 설정 | 수동(cron) | 무료 + 프록시 비용 |
| SerpApi Google Flights 엔드포인트 | 15분 | API 호출만 | 처리됨 | API 통해 가능 | 월 약 $50+ |
| Thunderbit Chrome 확장 프로그램 | 2분 | 없음 | 클라우드 스크래핑 | 내장 스케줄러 | 무료 요금제 제공 |
SerpApi에 대해 한 가지 덧붙이면, Google은 2025년 12월 SerpApi를 상대로 DMCA 소송을 제기했으며, 2년 동안 요청량이 25,000% 증가했다고 주장했습니다. API 제공업체를 검토 중이라면 이런 법적 불확실성도 고려할 가치가 있습니다.
Thunderbit로 Google Flights를 스크래핑하는 방법
Chrome에서 Google Flights 검색 결과를 연 뒤 Thunderbit의 "AI 필드 추천" 버튼을 클릭하면, AI가 페이지를 읽고 항공사, 가격, 출발 시간, 경유 횟수 같은 열을 제안합니다. 제안된 필드를 검토한 뒤 "스크래핑"을 누르면 됩니다. 결과는 표로 표시되며, Excel, Google Sheets, Airtable, Notion으로 바로 내보낼 수 있습니다. 에서도 가능합니다.
특히 가격 추적 용도라면 Thunderbit의 Scheduled Scraper와 이(동시에 50페이지를 처리할 수 있음) cron + 프록시 + 서버 인프라 전체를 대체합니다.
Python은 완전한 제어와 무한한 커스터마이징을 제공합니다. Thunderbit은 속도와 유지보수 제로에 가까운 점이 강점입니다. 실제 목적에 맞춰 선택하세요. 노코드 스크래핑 접근법을 더 보고 싶다면 가이드를 참고하세요.

Google Flights 스크래핑은 합법일까? 알아야 할 것들
포럼에서는 이런 질문이 자주 나옵니다. "Google Flights를 직접 스크래핑하면 Google의 이용약관을 위반하는 것 아닌가요?" API가 종료되었고 공식 대안도 없기 때문에, 충분히 걱정할 만한 부분입니다.
약관 위반과 법적 책임은 같은가?
Google의 서비스 약관(2024년 5월 22일 업데이트)에는 사용자가 "자동화된 수단(예: 로봇, 스파이더, 스크래퍼)을 사용해 서비스나 콘텐츠에 접근하거나 사용해서는 안 된다"고 적혀 있습니다. 약관 위반은 계약 위반(민사 문제)일 뿐, 곧바로 불법 행위와 동일하지는 않습니다.
중요한 판례는 hiQ v. LinkedIn(제9순회항소법원, 2022년)으로, 공개 데이터 스크래핑이 Computer Fraud and Abuse Act(CFAA)를 위반하지 않는다고 판단했습니다. 다만 이 사건은 합의로 종료되었고, Google이 2025년 12월 SerpApi를 상대로 제기한 소송은 다른 법적 이론인 DMCA 1201조(기술적 보호조치 우회)를 근거로 하고 있어, 더 심각하게 볼 여지도 있습니다.
책임 있는 스크래핑을 위한 모범 사례
- 요청 속도를 제한하세요 — IP 로테이션과 함께 10~20초 지연
- 개인 정보를 수집하지 마세요 — 항공권 가격은 공개된 집계 데이터입니다
- CAPTCHA를 프로그램으로 우회하지 마세요(DMCA 리스크 영역입니다)
- 데이터는 개인 연구용으로만 사용하고, 적절한 라이선스 없이 경쟁 상용 제품에 쓰지 마세요
- 가능하면 공식 API를 고려하세요
대체 데이터 소스
스크래핑이 너무 위험하게 느껴진다면, 합법적인 API 선택지도 있습니다:
| 제공업체 | 비용 | 무료 요금제 | 참고사항 |
|---|---|---|---|
| SerpApi | 월 $75~$3,750+ | 월 250회 검색 | Google Flights JSON 직접 제공(법적 검토 중) |
| Kiwi Tequila | 무료(제휴 모델) | 무제한 | 스타트업과 테스트에 적합 |
| Amadeus | 사용량 기반 | 월 2,000회 요청 | 400개 이상의 항공사, 예약 기능 포함 |
| Skyscanner | 맞춤형 | 승인 필요 | 52개 시장, 30개 언어 |
더 자세한 내용이 필요하다면 분석 글도 참고하세요.
결론 및 핵심 요약
내용이 많았습니다. 핵심만 정리하면 다음과 같습니다:
- Python + Playwright는 Google Flights 스크래핑에 가장 유연한 방법이지만, 지속적인 유지보수가 필요합니다
- 안티봇 대응(지연, user-agent 로테이션, 주거용 프록시)은 선택이 아니라 필수입니다. 특히 SearchGuard 이후에는 더 그렇습니다
- 선택자는 자주 깨집니다 — 가능하면
aria-label과 텍스트 기반 선택자를 사용하고, 출력값을 검증하며, 유지보수 일정을 잡아두세요 schedule이나 cron으로 자동화하면 1회성 스크래핑을 실제 가격 추적기와 이메일 알림 시스템으로 바꿀 수 있습니다- 는 노코드 대안으로, 내장 스케줄링·클라우드 스크래핑·안티봇 대응을 제공합니다. 코딩 프로젝트보다 가격 추적용 스프레드시트가 목표라면 특히 적합합니다
- 법적 경계를 존중하세요 — 요청 속도를 제한하고, 공개 데이터만 수집하며, 상업적 사용에는 API 대안을 검토하세요
이 튜토리얼의 코드를 가져가서 직접 써도 되고, 빠르게 가고 싶다면 을 설치해도 됩니다. 어느 쪽이든 이제 Google Flights를 새로고침만 반복하는 대신, 항공권 가격을 직접 추적할 수 있습니다.
Python 스크래핑 기법을 더 배우고 싶다면 과 가이드를 확인해 보세요.
자주 묻는 질문
1. Python 없이 Google Flights를 스크래핑할 수 있나요?
네. SerpApi와 Kiwi Tequila 같은 API 서비스는 브라우저 자동화 없이 API 호출만으로 구조화된 항공편 데이터를 제공합니다. 완전한 노코드 방식으로는 을 사용해 브라우저 안에서 Google Flights 결과를 직접 스크래핑하고, AI가 제안한 필드로 한 번에 내보낼 수 있습니다.
2. Google은 항공권 스크래핑을 차단하나요?
Google은 봇 탐지(SearchGuard), CAPTCHA, 속도 제한을 사용합니다. 하지만 무작위 지연, user-agent 로테이션, 주거용 프록시, stealth 브라우저 설정 같은 적절한 안티봇 대응을 적용하면 중간 규모에서는 비교적 안정적으로 스크래핑할 수 있습니다. 구체적인 기법과 기준은 위의 안티봇 섹션을 참고하세요.
3. 가격 추적용으로 Google Flights를 얼마나 자주 스크래핑해야 하나요?
개인적인 가격 확인 목적이라면 하루 두 번, 시간은 랜덤하게 두는 것이 충분하며 탐지 위험도 낮습니다. 비즈니스 모니터링이라면 4~6시간마다, 프록시 로테이션과 함께 운영하세요. 단기 특가 기간이 아니라면 시간당 스크래핑은 피하는 것이 좋습니다. 차단 위험이 크게 올라갑니다.
4. 무료 Google Flights API가 있나요?
공식 Google QPX Express API는 되었으며, 무료 공식 대체 서비스는 없습니다. 가장 가까운 무료 옵션은 로, 제휴 모델이며 검색은 무제한입니다. SerpApi는 월 250회 무료 검색을 제공합니다. 대부분의 사용자에게는 스크래핑이나 Thunderbit 같은 노코드 도구가 현실적인 선택입니다.
5. Google Flights CSS 선택자가 왜 계속 빈 데이터만 반환하나요?
Google은 Closure Compiler로 난독화된 클래스명을 생성하며, 이 값은 빌드마다 바뀝니다. A/B 테스트와 로케일 차이도 사용자마다 HTML 구조를 다르게 만듭니다. 해결책은 클래스명 대신 aria-label 속성과 텍스트 기반 선택자를 쓰고, 검증 함수를 추가해 오류를 초기에 잡으며, 매달 선택자를 점검하는 것입니다. 자세한 전략은 선택자 유지보수 섹션을 참고하세요.
더 알아보기