2022년에는 잘 돌아가던 Glassdoor 스크래퍼가 지금은 403 에러만 내보낸다면, 당신만 그런 상황이 아닙니다. 각종 포럼에는 같은 질문이 끊임없이 올라옵니다. "이 스크래퍼가 왜 이제 안 되는지 아는 분 있나요?"
짧게 말하면, Glassdoor가 모든 걸 바꿨기 때문입니다. Recruit Holdings는 2025년 7월 Glassdoor를 Indeed에 통합했고, 했으며, 봇 차단 체계를 훨씬 더 강하게 만들었습니다. 그 결과, 기본적인 Selenium이나 requests 기반 스크래퍼는 HTML 첫 바이트가 오기도 전에 막히는 경우가 많습니다. 2026년 2월 기준으로 Glassdoor 로그인은 모두 Indeed Login을 통해 처리됩니다. 그래서 Glassdoor 전용 로그인 폼을 하드코딩한 튜토리얼은 시작부터 구조적으로 깨져 있다고 봐야 합니다. 한편 플랫폼에는 여전히 와 정보가 쌓여 있습니다. 이 데이터는 HR 벤치마킹, 경쟁사 분석, 영업 타깃 발굴에 아주 유용하지만, 실제로 접근할 수 있어야 의미가 있죠. 이 가이드는 이런 변화 이후에도 실제로 동작하는 버전이며, Glassdoor의 세 가지 데이터 유형(채용 공고, 리뷰, 연봉)을 한 번에 다룹니다. Python으로 구현하는 방법을 2025년 기준 코드로 설명하고, 무엇이 막히게 만드는지와 그걸 어떻게 우회하는지 정확히 짚어드리며, 아예 엔지니어링을 건너뛰고 싶은 분들을 위한 노코드 대안도 소개하겠습니다.
2025년에 Python으로 Glassdoor를 크롤링해야 하는 이유
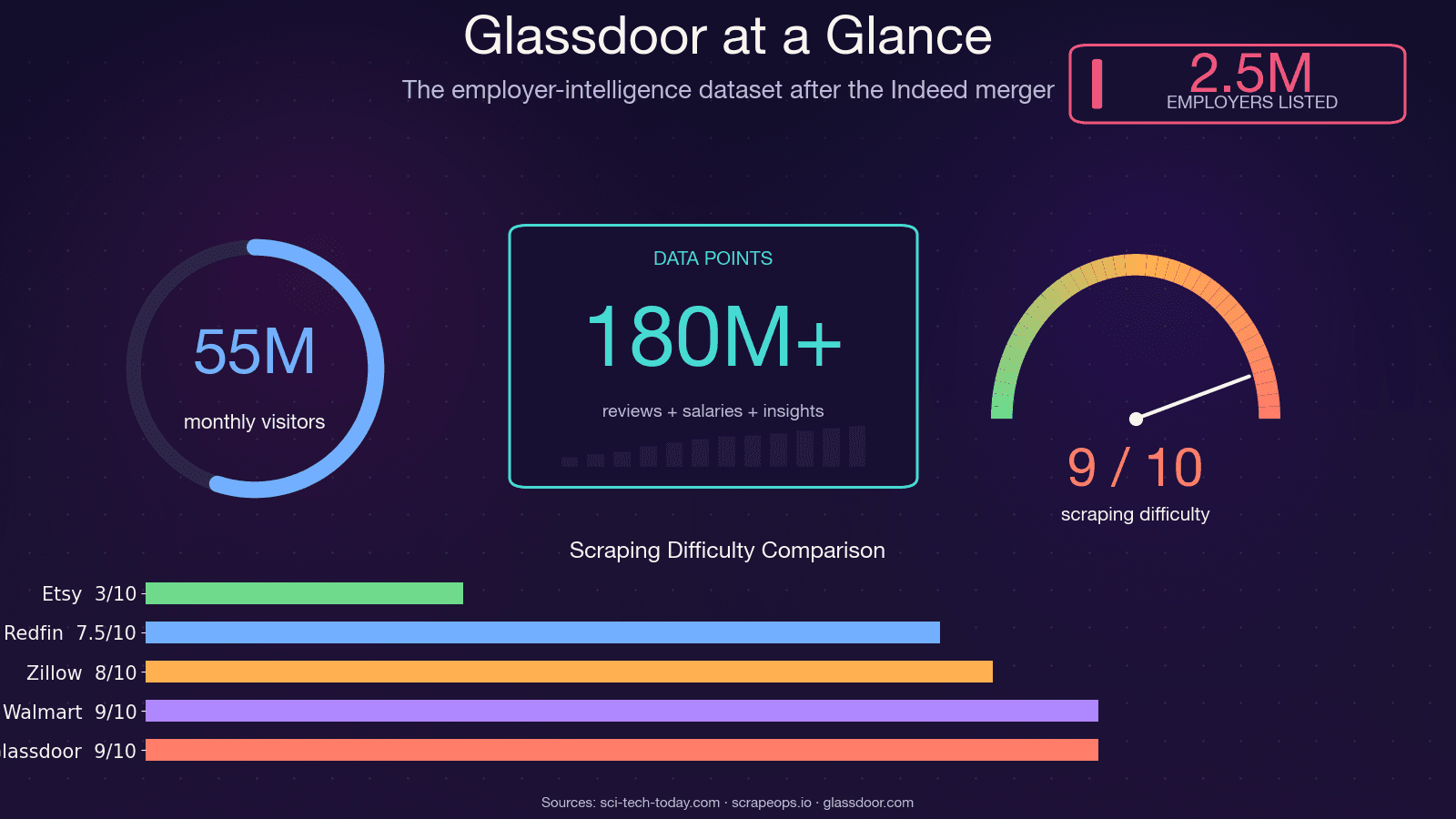
Glassdoor는 단순한 채용 게시판이 아닙니다. 웹에서 가장 풍부한 고용주 인텔리전스 데이터셋 중 하나로, 이 활용하고 있으며 월간 순방문자도 약 5,500만 명에 달합니다. 이 페이지들 뒤에 있는 데이터는 여러 팀의 실제 의사결정을 움직입니다.
팀별로 Glassdoor 데이터를 어떻게 쓰는지 살펴보면 다음과 같습니다:
| 활용 사례 | 필요한 데이터 유형 | 주요 수혜자 |
|---|---|---|
| 연봉 벤치마킹 | 연봉 분포, 표본 수 | HR, 총보상, 운영팀 |
| 경쟁사 채용 추적 | 채용 공고, 게시 빈도 | 영업, 전략, VC/Corp Dev |
| 고용주 브랜드 모니터링 | 리뷰 텍스트, 평점 추이, CEO 승인율 | HR, 마케팅, 커뮤니케이션 |
| 리드 발굴(성장 중인 기업) | 채용 공고 + 회사 정보 | 영업팀, SDR |
| 시장/학술 리서치 | 세 가지 모두 | 분석가, 컨설턴트, 연구자 |
2025년 10월 미국 정부 셧다운으로 BLS가 고용 데이터를 발표하지 못했을 때, Glassdoor의 Economic Research 팀은 자사 데이터셋을 활용해 를 발표했습니다. 이건 지금 기관 분석가들이 이 데이터를 얼마나 진지하게 보는지 보여주는 사례입니다.
Python이 여전히 표준 선택지인 이유는 생태계가 압도적으로 강하기 때문입니다. 브라우저 자동화용 Playwright, 파싱용 parsel/lxml, TLS 지문 우회를 위한 curl_cffi, 그리고 실제로 동작하는 패턴을 공유하는 거대한 커뮤니티까지 갖추고 있죠. 문제는 Python이 아닙니다. 문제는 Glassdoor가 훨씬 더 크롤링하기 어려운 사이트가 되었다는 점입니다.
Glassdoor 데이터를 노코드로 뽑고 싶다면, Thunderbit을 써서 맞춤형 Python 스택을 직접 만들거나 유지보수하지 않고도 채용 공고, 리뷰, 연봉 페이지를 크롤링할 수 있습니다.
실제로 어떤 Glassdoor 데이터를 크롤링할 수 있나?
대부분의 튜토리얼은 채용 공고만 다룹니다. 그런데 제가 포럼 글, GitHub 이슈, Reddit 질문을 계속 추적해 본 결과, 사용자 수요가 가장 높은 건 아무도 제대로 가르쳐 주지 않는 두 가지 데이터 유형, 즉 리뷰와 연봉입니다. 아래에서 세 가지 카테고리별로 추출 가능한 항목을 정리해 보겠습니다.
채용 공고
가장 접근하기 쉬운 데이터 유형입니다. 추출할 수 있는 항목은 직무명, 회사명, 위치, 연봉 추정치, 회사 평점, 게시일, Easy Apply 배지, 채용 링크입니다. 채용 공고는 로그인 없이도 일부 확인 가능하지만, 여러 페이지를 넘기다 보면 Glassdoor가 로그인 팝업을 띄울 수 있습니다.
회사 리뷰
고용주 브랜드 분석에서 가장 흥미로운 영역입니다. 추출 가능한 항목은 전체 평점, 세부 평점(워크라이프 밸런스, 문화 및 가치, 다양성 및 포용, 커리어 기회, 보상 및 복리후생, 경영진), 장점 텍스트, 단점 텍스트, 작성자 직무명, 리뷰 날짜, 고용 상태입니다. 전체 리뷰 텍스트는 로그인 필요 영역이며, 일부 요약만 보이고 전체 장단점은 인증해야 확인할 수 있습니다.
연봉 데이터
가장 많이 찾지만 가장 성가신 데이터 유형입니다. 직무명, 기본 연봉 범위, 총 보상 범위, 연봉 보고 수, 위치를 추출할 수 있습니다. 하지만 연봉 페이지는 완전히 로그인으로 막혀 있고, 경우에 따라 다른 사람의 연봉을 보기 전에 자신의 연봉을 제출해야 하는 "보상 제출 후 열람" 흐름이 추가되기도 합니다. 기존 튜토리얼 중 이 부분까지 실제로 작동하는 코드는 거의 없습니다. 여기서는 그걸 해결해 보겠습니다.
로그인 필요 여부와 비로그인 접근 가능 여부
아래 표를 보면 어떤 페이지가 빈 데이터만 돌려주는지 헛걸음하지 않아도 됩니다.
| 데이터 유형 | 로그인 없이 가능? | 비고 |
|---|---|---|
| 채용 공고 제목 및 기본 정보 | 대부분 가능 | 여러 페이지 후 팝업이 뜰 수 있음 |
| 전체 채용 공고 설명 | 부분 가능 | 보통 2~3회 조회 후 차단됨 |
| 회사 리뷰(전체 텍스트) | 불가 — 로그인 필요 | 요약은 보이지만 전체는 잠김 |
| 연봉 데이터 | 불가 — 로그인 필요 | "제출 후 열람"이 추가로 필요할 수 있음 |
기존 Glassdoor 스크래퍼가 깨졌을 가능성이 높은 이유
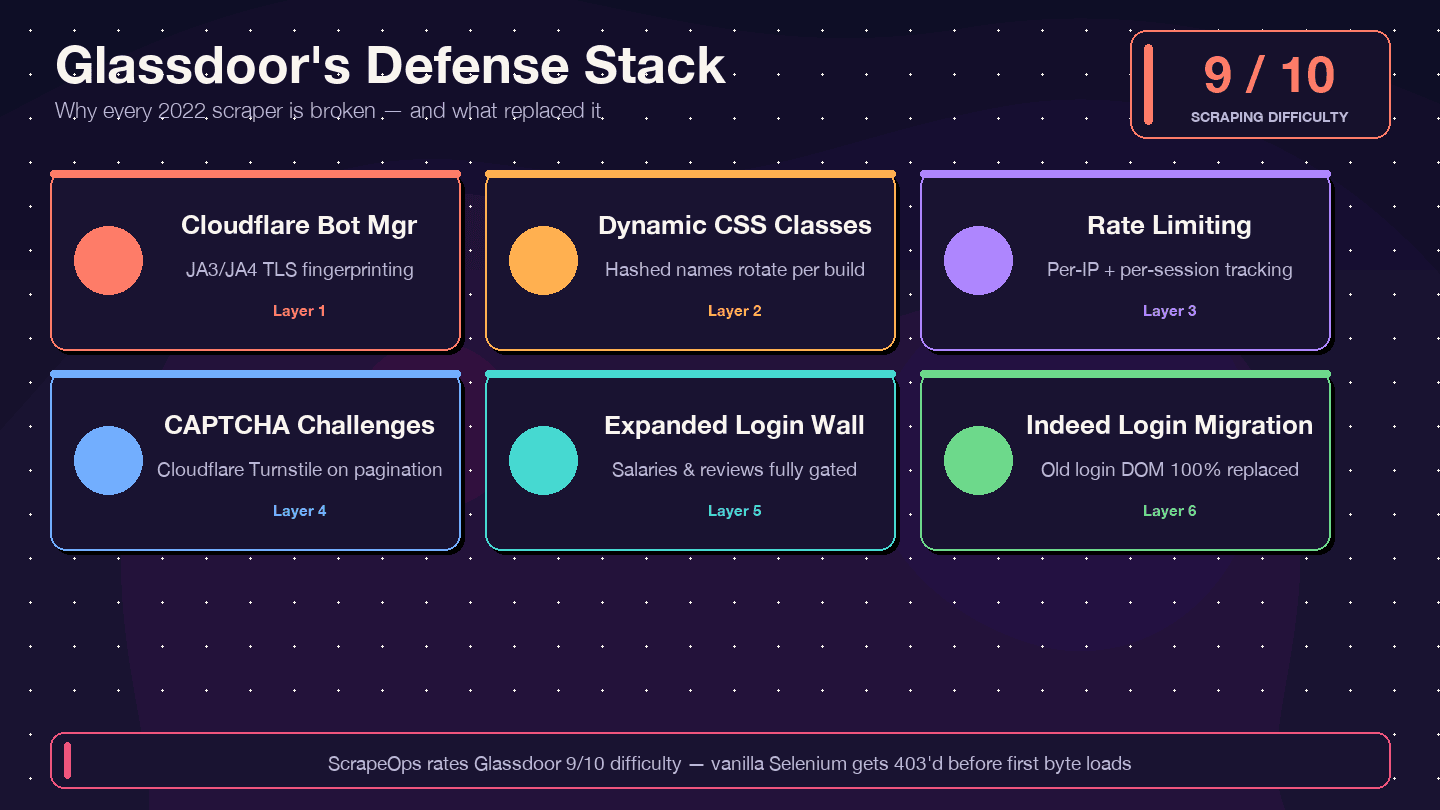
단도직입적으로 말하겠습니다. 2021~2023년 튜토리얼 코드를 그대로 복사하고 있다면 작동하지 않을 겁니다. GitHub에서 가장 많이 별을 받은 기존 Glassdoor Selenium 스크래퍼(, 약 1.4k stars)에는 "Glassdoor 새 UI 디자인", "Cloudflare 안티봇 보호", "NoSuchElementException" 등을 포함해 12개 이상의 미해결 이슈가 남아 있습니다. 사실상 방치된 저장소입니다. 되어 있습니다. 으로, 우회 난이도는 8점으로 평가합니다.
무엇이 바뀌었고 왜 기존 코드가 깨지는지 보겠습니다:
| 방어 레이어 | 변경 사항 | 기존 스크래퍼에 미치는 영향 |
|---|---|---|
| Cloudflare Bot Management | 2024년부터 JA3/JA4 지문 검사가 강화됨 | 기본 requests/Selenium 스크립트가 즉시 403 처리됨 |
| 동적 CSS 클래스명 | 빌드마다 클래스명이 무작위화됨 | 예전 튜토리얼의 CSS 셀렉터가 조용히 실패함 |
| 속도 제한 + 세션 추적 | IP/세션별 제한이 더 엄격해짐 | 더 적은 페이지 후 차단됨 |
| CAPTCHA 챌린지(Cloudflare Turnstile 가능성 높음) | 특히 페이지네이션 중 더 자주 발생 | 헤드리스 브라우저가 챌린지를 유발함 |
| 확대된 로그인 벽 | 더 많은 페이지 유형이 인증 필요 | 연봉/리뷰 페이지가 빈 데이터로 반환됨 |
| Indeed Login 전환(2026년 2월) | Glassdoor 로그인 폼이 완전히 교체됨 | 예전 로그인 DOM을 겨냥한 코드는 전부 무용지물 |
에는 이런 명시적 경고가 있습니다. "Glassdoor는 차단율이 높은 것으로 알려져 있으므로 Python 코드 실행 중 None 값이 나온다면 차단당한 것일 가능성이 높습니다." 또한 은 더 직설적입니다. "requests나 httpx로 보내는 단순 HTTP 요청은 즉시 차단된다."고 말합니다.
제가 아래에서 보여드릴 대응책 — Patchright(Playwright의 스텔스 포크), data-test 속성 셀렉터, 회전형 리버설 프록시, 인증된 영구 세션 — 은 이런 방어 레이어 각각을 처리하도록 설계된 것입니다.
Glassdoor API vs. Python 스크래핑: 먼저 올바른 방식을 선택하자
여러 포럼 스레드에서 "그냥 Glassdoor API를 쓰면 안 되나요?"라고 묻지만, 답은 사실상 "안 됩니다"입니다.
. 개발자 포털은 겉보기엔 아직 남아 있지만 합니다. 공개 리뷰 엔드포인트는 애초에 존재한 적이 없었고, MatthewChatham의 스크래퍼도 명시적으로 "Glassdoor에 리뷰 API가 없기 때문에" 만들어졌습니다. Indeed의 Publisher API로도 리뷰나 연봉을 옮겨올 방법은 없습니다.
솔직한 비교표는 다음과 같습니다:
| 항목 | Glassdoor Partner API v1 | Python 스크래핑 | Thunderbit(노코드) |
|---|---|---|---|
| 접근성 | 신규 신청 불가 | 가능(직접 구현) | 크롬 확장 프로그램 |
| 채용 공고 | 제한적/종료 수순 | 노력하면 가능 | 가능 |
| 회사 리뷰 | 공개 API로는 존재한 적 없음 | 가능(로그인 필요) | 가능(브라우저 모드) |
| 연봉 데이터 | 공개 API로는 존재한 적 없음 | 가능(로그인 필요) | 가능 |
| 요청 제한 | 비공개 | 직접 제어 | 크레딧 기반 |
| 초기 설정 난이도 | 새 앱 등록 불가 | 수시간~수일 | 약 2분 |
| 유지보수 부담 | 해당 없음 | 높음(HTML 변경 시 코드 깨짐) | 낮음(AI가 필드를 다시 제안) |
리뷰나 연봉 데이터가 필요하다면 — 대부분 이 글을 읽는 분들이 여기에 해당할 겁니다 — Python 스크래핑이나 노코드 도구만이 현실적인 선택지입니다.
시작하기 전에
- 난이도: 중급자용(Python과 터미널 사용에 익숙해야 함)
- 소요 시간: 전체 세팅에 약 30~60분, 이후 데이터 유형별로 약 10분
- 준비물:
- Python 3.10 이상(3.11 또는 3.12 권장)
- Chrome 브라우저 설치
- Glassdoor 계정(무료, 연봉/리뷰 데이터에 필요)
- 회전형 리버설 프록시(몇 페이지 이상 크롤링할 경우 필요)
- 선택 사항: 노코드 경로를 원한다면
2025년 Python으로 Glassdoor를 크롤링할 때 쓰는 도구와 라이브러리
도구 생태계는 크게 바뀌었습니다. 지금의 Glassdoor 방어 체계에 실제로 먹히는 것들만 추려보겠습니다.
Glassdoor에 Patchright가 가장 좋은 이유
는 Playwright의 스텔스 포크로, Runtime.Enable CDP 누출을 패치합니다. 이 누출은 일반 Playwright가 Cloudflare 보호 사이트에서 막히는 직접적인 기술적 원인입니다. Playwright와 API가 완전히 같기 때문에 Playwright를 안다면 Patchright도 바로 쓸 수 있습니다. 최신 버전은 1.58.2(2026년 3월)이며 현재도 활발히 유지보수되고 있습니다.
대안들과 비교하면:
- 일반 Playwright: Runtime.Enable 누출 때문에 Glassdoor 로그인 페이지에서 탐지될 수 있음
- Selenium + undetected-chromedriver: undetected-chromedriver의 마지막 릴리스는 2024년 2월로, 사실상 레거시입니다. 에서는 테스트한 모든 도메인에서 실패했다고 나왔습니다.
- requests + BeautifulSoup: JavaScript를 렌더링할 수 없고, Cloudflare의 TLS 지문 검사에 즉시 막힘
- : 초기 HTML에
__NEXT_DATA__가 포함된 페이지에서는 매우 빠른 우회 경로(브라우저보다 10~20배 빠름)지만, 로그인이나 중간 챌린지는 처리할 수 없음
보조 라이브러리
- parsel(1.11.0) 또는 lxml(6.0.4): 빠른 HTML/XPath 파싱
- csv 또는 pandas: 데이터 내보내기
- asyncio: 빠른 페이지네이션을 위한 비동기 스크래핑
프록시: 반드시 리버설 프록시만 사용
Glassdoor의 Cloudflare 레이어는 데이터센터 ASN에 매우 공격적으로 챌린지를 겁니다. . 시작 가격은 또는 기준 1GB당 $3.00 정도입니다. 실제 운영 목적이라면 물량에 따라 1GB당 $3~8 정도를 예산으로 잡는 것이 좋습니다.
프록시 품질과 상관없이 요청 사이에 무작위 지연(최소 3~8초, 긴 작업은 5~15초)을 넣는 것이 필수입니다.
1단계: Python 환경 설정하기
프로젝트 폴더를 만들고 권장 스택을 설치합니다:
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# 핵심 스택
6pip install patchright==1.58.2 parsel==1.11.0
7# 브라우저 바이너리 설치
8patchright install chromium
9# 선택 사항: __NEXT_DATA__ 추출용 빠른 경로
10pip install "curl_cffi==0.15.0"Patchright가 Chromium 바이너리를 내려받는 모습을 볼 수 있어야 합니다. patchright install chromium가 실패하면 디스크 공간이 충분한지(약 300MB 필요), 그리고 Python 버전이 3.10 이상인지 확인하세요.
2단계: Patchright를 실행하고 Glassdoor로 이동하기
Glassdoor의 Cloudflare 레이어를 상대로 잘 동작하는 기본 실행 패턴은 다음과 같습니다:
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # 헤드리스는 여전히 더 잘 탐지됨
6 channel="chrome", # 번들 Chromium이 아니라 실제 Chrome 사용
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # 로그인 오버레이 숨기기 — 실제 데이터는 DOM 안에 남아 있음
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("페이지 로드 완료 — 채용 공고가 표시됩니다.")여기서 기억할 점이 몇 가지 있습니다. channel="chrome" 플래그는 Patchright가 번들 Chromium이 아니라 실제로 설치된 Chrome 바이너리를 사용하게 해 주며, 그만큼 더 자연스러운 브라우저 지문을 만듭니다. add_style_tag 트릭은 아무 것도 클릭하지 않고도 Glassdoor의 로그인 모달(#HardsellOverlay)을 숨깁니다. "실제 데이터는 그대로 있고 단지 오버레이에 가려져 있을 뿐"이라고 확인했습니다. 즉, 모달이 떠 있어도 HTML 안에는 데이터가 존재합니다.
Chrome 창이 열려 Glassdoor 채용 검색 페이지로 이동하고, 로그인 팝업에 가리지 않은 상태로 채용 카드가 보이면 성공입니다.
3단계: Glassdoor 채용 공고 크롤링하기
안정적인 셀렉터 찾기
Glassdoor는 빌드마다 CSS 클래스명을 무작위화합니다. 따라서 2023년 튜토리얼의 .jobCard_xyz123 같은 셀렉터는 오늘날 조용히 아무것도 반환하지 않을 수 있습니다. 대신 Glassdoor 내부 QA 관례인 data-test 속성을 사용하세요. 이 속성은 배포가 바뀌어도 비교적 안정적으로 유지됩니다.
채용 공고 필드용 셀렉터는 다음과 같습니다:
| 필드 | 셀렉터 |
|---|---|
| 채용 카드 컨테이너 | [data-test="jobListing"] |
| 직무명 | [data-test="job-title"] |
| 채용 링크 | a[data-test="job-link"] |
| 회사명 | [data-test="employer-name"] |
| 위치 | [data-test="emp-location"] |
| 연봉 범위 | [data-test="detailSalary"] |
| 회사 평점 | [data-test="rating"] |
| 게시일 | [data-test="job-age"] |
| 다음 페이지 | [data-test="pagination-next"] |
채용 데이터 추출하기
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"{page_num}페이지: 카드가 없습니다 — 차단되었거나 셀렉터가 바뀌었을 수 있습니다.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"{page_num}페이지: {len(cards)}개 채용 공고 추출")
26 # 페이지네이션
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsCSV로 저장하기
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("저장할 채용 공고가 없습니다.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"{filename}에 {len(jobs)}개의 채용 공고를 저장했습니다")페이지네이션 제한에 대한 한 가지 참고사항: Glassdoor는 총 결과 수와 상관없이 검색 결과를 대략 30페이지로 제한합니다. 더 넓은 범위가 필요하다면, 무작정 끝까지 넘기기보다 위치, 직무 유형, 연봉 범위 같은 필터로 검색을 더 잘게 나누는 편이 좋습니다.
제가 테스트했을 때, 채용 공고 5페이지(약 75개)를 무작위 지연과 함께 크롤링하는 데 약 45초가 걸렸습니다. 같은 작업을 수동으로 하면 최소 20분은 복붙해야 합니다.
4단계: Glassdoor 회사 리뷰 크롤링하기
이 섹션은 다른 튜토리얼에서 실제로 동작하는 코드를 거의 제공하지 않는 부분입니다. 리뷰야말로 진짜 고용주 인텔리전스가 담긴 곳입니다. 감성 분석, 문화적 신호, 경영 리스크 등을 읽어낼 수 있죠.
리뷰 페이지로 이동하기
리뷰 URL 패턴은 /Reviews/{Company}-Reviews-E{id}.htm 입니다. Glassdoor에서 회사를 검색한 뒤 URL을 확인하면 고용주 ID를 찾을 수 있습니다.
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)숨겨진 BFF 엔드포인트(가장 깔끔한 경로)
제가 조사하면서 발견한 가장 중요한 점은, Glassdoor 리뷰에는 HTML 파싱을 완전히 건너뛰게 해 주는 내부 JSON API가 실제로 존재한다는 것입니다. 에도 이 엔드포인트가 문서화되어 있으며, DOM을 직접 파싱하는 것보다 훨씬 안정적입니다.
1import json, re, requests
2def get_review_ids(page):
3 """리뷰 페이지 HTML에서 employerId와 dynamicProfileId를 추출합니다."""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Glassdoor 내부 BFF 엔드포인트를 호출해 구조화된 리뷰 데이터를 가져옵니다."""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF가 {pg}페이지에서 {resp.status_code}를 반환했습니다")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"리뷰 {pg}/{total_pages}페이지: {len(reviews)}개 리뷰 수집")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsBFF 엔드포인트를 쓰면 모든 리뷰 필드가 깔끔한 JSON으로 반환됩니다. HTML 파싱도 필요 없고, CSS 셀렉터가 깨질 걱정도 없습니다. 다만 인증된 Playwright 컨텍스트의 세션 쿠키가 필요하고(아래 6단계 참고), 먼저 리뷰 페이지 HTML에서 employerId와 dynamicProfileId를 추출해야 합니다.
리뷰용 HTML 폴백 셀렉터
BFF 엔드포인트가 바뀌거나 DOM 파싱을 선호한다면, 다음 data-test 셀렉터를 사용할 수 있습니다:
| 필드 | 셀렉터 |
|---|---|
| 리뷰 컨테이너 | [data-test="review"] |
| 제목 | [data-test="review-title"] |
| 전체 평점 | [data-test="overall-rating"] |
| 장점 | [data-test="pros"] |
| 단점 | [data-test="cons"] |
| 날짜 | [data-test="review-date"] |
| 작성자 직무 | [data-test="author-jobTitle"] |
5단계: Glassdoor 연봉 데이터 크롤링하기
연봉 페이지는 완전히 로그인으로 막혀 있습니다. 이 코드가 실제 데이터를 반환하려면 먼저 인증된 세션(6단계)이 있어야 합니다.
연봉 페이지로 이동하기
연봉 URL 패턴은 /Salary/{Company}-Salaries-E{id}.htm이며, 페이지네이션은 _P{n}.htm 형식입니다.
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"연봉 페이지 {pg}: 항목이 없습니다 — 로그인 벽 또는 차단일 수 있습니다.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"연봉 페이지 {pg}: {len(items)}개 항목 추출")
25 return all_salaries여기서 [class*="SalaryItem_jobTitle__"] 같은 prefix-match 패턴에 주목하세요. Glassdoor의 연봉 페이지는 SalaryItem_jobTitle__XWGpT처럼 CSS 모듈 해시 클래스명을 사용합니다. 이 해시 접미사는 배포할 때마다 바뀌지만, 앞부분은 유지됩니다. 전체 클래스를 하드코딩하면 안 됩니다.
6단계: Glassdoor 로그인 벽 넘기기
이 단계가 연봉 데이터와 전체 리뷰 텍스트를 열어 주는 핵심입니다. 접근 방식은 간단합니다. 한 번만 눈에 보이는 브라우저에서 수동 로그인한 뒤, 인증 세션 상태를 저장하고 이후에는 그 세션을 계속 재사용하면 됩니다.
인증 세션 저장하기
아래 스크립트를 한 번 실행하세요. Chrome 창이 열리고 Glassdoor 로그인 페이지(현재는 Indeed Login으로 리디렉션됨)로 이동한 뒤, 사용자가 직접 로그인할 때까지 기다립니다.
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("브라우저 창에서 로그인한 뒤 여기서 Enter를 누르세요...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"세션이 {STATE_FILE}에 저장되었습니다")
18 await browser.close()
19asyncio.run(login_and_save())로그인하고 Enter를 누르면 Patchright가 모든 쿠키와 로컬 스토리지를 glassdoor_state.json에 저장합니다. 이 파일에는 gdId, GSESSIONID, cf_clearance, 인증 토큰이 들어 있습니다.
세션을 재사용해 크롤링하기
이후의 모든 크롤링은 저장된 상태를 불러오기만 하면 됩니다. 더 이상 수동 로그인할 필요가 없습니다.
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return html저장된 세션은 일반적으로 활발히 써도 20~30분 정도 지나면 다시 Glassdoor의 재검증을 받을 수 있습니다. 긴 작업을 할 때는, 데이터가 있어야 할 페이지에서 결과가 0개로 나오면 로그인 스크립트를 다시 실행해 상태 파일을 갱신하는 체크를 넣는 게 좋습니다.
로그인 팝업 감지 및 닫기
부분적으로만 막힌 페이지(데이터는 보이지만 모달이 덮는 경우)에서는 앞서 소개한 CSS 주입 방식이 잘 먹힙니다:
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")이 방법은 HTML 안에 실제 데이터가 이미 존재할 때만 유효합니다. 완전히 서버 측에서 막힌 페이지(연봉, 깊이 있는 리뷰 페이지)는 6단계의 인증 세션이 사실상 유일한 해법입니다.
Glassdoor 스크래퍼를 오래 살려두는 팁
Glassdoor는 프론트엔드를 자주 업데이트합니다. 스크래퍼에 회복력을 넣는 방법은 다음과 같습니다.
클래스명보다 data-test 속성을 우선하라
Glassdoor는 CSS 클래스명을 무작위화하지만 data-test 속성은 비교적 안정적으로 유지하는 편입니다. 항상 .jobCard_abc123보다 [data-test="jobListing"]을 우선하세요. data-test가 없는 경우(연봉 필드 클래스처럼)에는 [class*="SalaryItem_jobTitle__"] 같은 prefix-match 패턴을 사용하면 됩니다.
프록시를 순환하고 지연 시간을 무작위화하라
리버설 프록시를 쓰세요. 데이터센터 IP는 거의 즉시 챌린지를 받습니다. 페이지 로드 사이에는 3~8초의 무작위 지연을 넣고, 오래 도는 작업이면 5~15초까지 늘리세요. 가능하다면 미국 업무 시간대는 피하세요. 이 시간에는 Cloudflare의 행동 기반 탐지가 더 공격적입니다.
깨짐을 감시하라
스크래퍼에 간단한 체크를 넣으세요. 데이터가 있어야 할 페이지에서 추출 결과가 0개라면, 빈 데이터가 아니라 셀렉터 실패로 간주하고 알림을 보내야 합니다. 매주 작은 테스트 크롤링을 돌려 조기 이상 징후를 잡는 것도 좋습니다. Glassdoor는 프론트엔드 변경을 공지 없이 배포하곤 합니다.
가능하면 __NEXT_DATA__ 빠른 경로를 써라
Glassdoor는 Next.js + Apollo GraphQL 앱입니다. 많은 페이지가 초기 HTML 안에 전체 GraphQL 캐시를 JSON으로 담은 <script id="__NEXT_DATA__"> 태그를 제공합니다. 이것을 파싱하는 방식은 DOM 스크래핑보다 훨씬 견고하며 합니다:
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return None이 방식은 모든 채용, 리뷰, 연봉 필드가 들어 있는 구조화된 Apollo 캐시를 돌려줍니다. CSS 셀렉터가 전혀 필요 없죠. Glassdoor의 React 프론트엔드를 실제로 구동하는 동일한 데이터를 쓰기 때문에 가장 회복력이 좋습니다.
코드는 건너뛰고 Thunderbit으로 Glassdoor를 크롤링하기(Python 불필요)
이 글을 읽는 모두가 개발자는 아닙니다. HR 팀, 리크루터, 세일즈 오퍼레이션 분석가, 시장조사 담당자도 Glassdoor 데이터가 필요하지만, 그들을 위해 굳이 Playwright 컨텍스트나 프록시 순환을 관리하게 할 필요는 없습니다.
은 AI 웹 스크래퍼 크롬 확장 프로그램으로, 한 줄의 코드도 작성하지 않고 동일한 채용 공고, 리뷰, 연봉 데이터를 추출할 수 있습니다. 저는 Thunderbit 팀에서 일하고 있으니 이 점은 분명히 말씀드리겠습니다. 하지만 여기 소개하는 이유는 Glassdoor 스크래핑에서 가장 어려운 두 가지 문제를 실제로 해결해 주기 때문입니다.
Thunderbit을 Glassdoor에서 사용하는 방법
작업 흐름은 두 번의 클릭이면 끝납니다:
- Chrome에서 아무 Glassdoor 페이지나 엽니다(채용 검색, 회사 리뷰, 연봉 페이지)
- Thunderbit 사이드바에서 AI 필드 추천을 클릭합니다. AI가 페이지 DOM을 읽고 직무명, 회사명, 평점, 연봉 범위, 장점, 단점 등의 컬럼을 제안합니다.
- 스크랩을 클릭하면 CSS 셀렉터나 브라우저 자동화 코드 없이 데이터가 표로 추출됩니다.
Thunderbit에는 이 내장되어 있어, 한 번에 회사당 23개 이상의 필드를 추출할 수 있습니다. 채용 공고, 리뷰, 연봉의 경우에도 일반적인 AI 필드 추천 워크플로우로 어떤 Glassdoor URL이든 처리할 수 있습니다.
코드 없이 로그인 벽 처리하기
Glassdoor에서 Thunderbit의 구조적 장점은 여기서 가장 분명해집니다. 브라우저 모드는 사용자의 Chrome 세션 안에서 동작하므로, 이미 Chrome에서 Glassdoor에 로그인되어 있다면 Thunderbit이 그 쿠키를 자동으로 이어받습니다. 서버 측 스크래퍼를 막는 연봉/리뷰 로그인 벽은 사실상 적용되지 않습니다. 쿠키 관리도, 영구 컨텍스트도, 세션 코드도 필요 없습니다.
하위 페이지 스크래핑으로 데이터 확장하기
목록 페이지(예: 검색 결과에서 30개 회사)를 시작점으로 삼아 Thunderbit이 행을 읽어오게 한 뒤, 을 활성화하면 각 회사의 리뷰 또는 연봉 페이지를 방문해 전체 설명, 리뷰 텍스트, 연봉 세부 정보를 테이블에 확장할 수 있습니다.
비즈니스 도구로 내보내기
CSV나 JSON만 내보내는 Python 스크립트와 달리, Thunderbit은 Google Sheets, Airtable, Notion, Excel로 바로 내보낼 수 있으며 모든 플랜에서 무료입니다. 팀 단위로 데이터를 공유하고 분석해야 하는 경우 특히 유용합니다.
Python vs. Thunderbit: 언제 무엇을 써야 할까?
| 상황 | 권장 방식 |
|---|---|
| 반복되는 데이터 파이프라인 구축 | Python + Patchright |
| 일회성 리서치 또는 소규모 팀 프로젝트 | Thunderbit |
| 모든 필드를 프로그래밍 방식으로 세밀하게 제어해야 함 | Python |
| 오늘 당장 Glassdoor 데이터가 필요한 비개발자 | Thunderbit |
| 1,000페이지 이상을 한 번에 크롤링 | Python + 프록시 |
| 30개 회사를 확장 정보와 함께 크롤링 | 둘 다 가능 — Thunderbit이 설정이 더 빠름 |
Thunderbit 가격은 무료(월 6페이지)부터 시작하며, 입니다. 출력 행당 1크레딧(하위 페이지 스크래핑은 2크레딧)이므로, 월 약 30개 기업 확장 작업을 33회 정도 돌릴 수 있습니다.
Glassdoor를 크롤링하는 것은 합법인가?
짧고 사실적으로 말씀드리겠습니다. Glassdoor의 은 자동화된 스크래핑을 명시적으로 금지합니다. "당사의 명시적인 서면 허가 없이 로봇, 스파이더, 스크래퍼 등을 사용하여 서비스를 어떤 목적으로도 접근할 수 없다"고 되어 있습니다.
다만 법적 환경은 약관 한 줄보다 훨씬 복잡합니다:
- (캘리포니아 북부지방법원, 2024년 1월): 법원은 로그인하지 않았다면 약관에 동의한 적도 없으므로, 로그인하지 않은 공개 데이터 스크래핑은 약관 위반이 아니라고 봤습니다.
- hiQ Labs v. LinkedIn (제9순회): 공개적으로 접근 가능한 데이터의 자동 수집에는 CFAA가 적용되지 않는다는 취지지만, 가짜 계정이나 로그인 후 스크래핑은 다른 문제입니다.
- Van Buren v. United States (미 대법원, 2021): CFAA의 "허가된 접근을 초과했다"는 개념을 좁게 해석했습니다.
실무적으로는, 로그인 없이 공개 채용 공고를 스크래핑하는 행위가 상대적으로 더 안전한 법적 영역에 있습니다. 로그인한 세션으로 스크래핑하는 것은 가입 시 약관에 동의한 것으로 볼 수 있고, 약관상 이를 명시적으로 금지합니다. 이는 Python 스크립트와 Thunderbit의 Browser Mode 모두에 동일하게 적용됩니다.
어떤 방식을 쓰든 지켜야 할 윤리적 가이드라인은 다음과 같습니다:
- 사람보다 훨씬 느린 속도로 요청 제한을 걸 것
- 리뷰어의 개인 식별 정보를 스크래핑하거나 재판매하지 말 것
- robots.txt 지침을 존중할 것
- 실제로 필요한 필드만 가져올 것
결론: 어떤 방법이 당신에게 맞는가?
이 가이드는 Indeed Login 전환, Cloudflare Bot Management, 그리고 기존 튜토리얼을 전부 깨뜨린 CSS 모듈 클래스명 회전까지 고려한 2025년 기준 작동 코드를 바탕으로, Glassdoor의 세 가지 데이터 유형인 채용 공고, 리뷰, 연봉을 모두 다뤘습니다.
의사결정 기준은 다음과 같습니다:
| 당신의 상황 | 최적의 선택 |
|---|---|
| 데이터 파이프라인을 만드는 개발자 | Python + Patchright(위의 단계별 안내 따르기) |
| 일회성 리서치 또는 반복적인 소규모 수집 | Thunderbit(노코드, 브라우저 기반) |
| 기본 채용 공고만 소규모로 필요 | 먼저 Glassdoor API 접근이 아직 가능한지 확인(아마도 불가) |
| 연봉 또는 리뷰 데이터가 특히 필요 | Python 스크래핑 또는 Thunderbit만 가능 — API는 이를 다루지 않음 |
| 공유 데이터가 필요한 비개발자 팀 | Thunderbit → Google Sheets로 내보내기 |
Glassdoor의 방어 체계는 앞으로도 계속 진화할 겁니다. 셀렉터는 깨질 수 있고, 새로운 챌린지가 등장할 수도 있습니다. 이 가이드를 북마크해 두세요. 더 깊이 있는 웹 스크래핑 도구와 기법이 궁금하다면 , , 관련 글도 참고해 보세요. 에서 실습 영상도 볼 수 있습니다.
자주 묻는 질문(FAQ)
1. 로그인 없이 Glassdoor를 크롤링할 수 있나요?
네, 대부분의 채용 공고 데이터와 핵심 회사 평점은 가능합니다. 하지만 전체 연봉 상세나 첫 몇 페이지를 넘는 전체 리뷰 텍스트는 불가능합니다. #HardsellOverlay는 CSS 기반 모달이라 겉으로는 가려져도 첫 페이지 데이터는 HTML에 남아 있지만, 더 깊은 콘텐츠는 Glassdoor의 "제공해야 볼 수 있는" 벽 뒤에 서버 측에서 막혀 있습니다.
2. 2025년에 Glassdoor 크롤링에 가장 잘 맞는 Python 라이브러리는 무엇인가요?
Patchright(Playwright의 스텔스 포크)를 기본 추천합니다. 일반 Playwright가 가진 Runtime.Enable CDP 누출을 패치하며, Cloudflare가 이를 감지합니다. 초기 HTML에 __NEXT_DATA__를 포함하는 목록 페이지는 impersonate="chrome124"와 함께 쓰는 curl_cffi가 10~20배 빠르지만, 로그인 필요 페이지는 처리하지 못합니다.
3. Glassdoor를 크롤링하면서 차단을 피하려면 어떻게 해야 하나요?
Patchright 또는 rebrowser-playwright를 사용하세요(일반 Playwright나 Selenium은 피할 것). 리버설 프록시를 순환 사용하고, 데이터센터 IP는 바로 챌린지를 받는다고 생각하세요. 페이지 사이에는 3~8초의 무작위 지연을 넣고, 쿠키(gdId, cf_clearance, GSESSIONID)를 요청 간 유지하세요. 세션은 보통 20~30분 정도 지나면 재검증이 걸릴 수 있습니다.
4. 스크래핑 대신 쓸 수 있는 Glassdoor API가 있나요?
사실상 없습니다. 기존 Partner API는 , 공개 리뷰 엔드포인트는 한 번도 없었으며, Indeed의 Publisher API로도 옮길 수 있는 경로가 없습니다. 리뷰와 연봉 데이터는 스크래핑이나 Thunderbit 같은 노코드 도구가 현실적인 선택입니다.
5. Glassdoor 스크래퍼는 얼마나 자주 깨지나요?
꽤 자주입니다. Glassdoor는 프론트엔드 변경을 공지 없이 배포하고, CSS 모듈 클래스명 해시는 빌드마다 바뀝니다. 가장 안정적인 추출 전략은 (1) data-test 속성 셀렉터, (2) __NEXT_DATA__ JSON 블록, (3) 내부 BFF 리뷰 엔드포인트입니다. 결과 0개 체크를 넣고, 매주 작은 테스트 크롤링을 돌려 조기 파손을 잡으세요.
더 알아보기