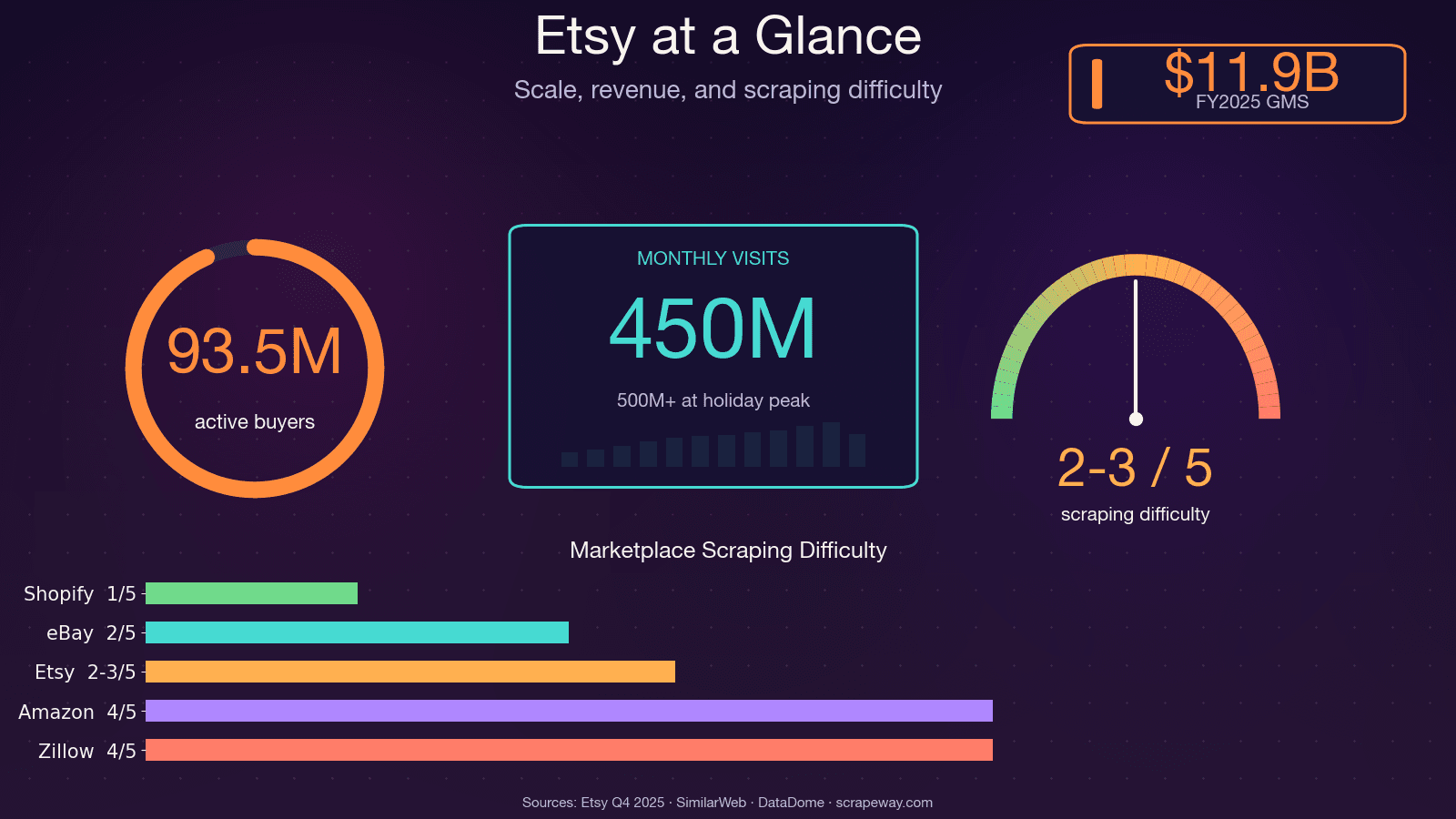
Etsy에는 1억 개가 넘는 활성 상품, 560만 명의 판매자, 그리고 월간 약 4억 5천만 건의 방문이 있습니다. 그만큼 가격, 트렌드, 리뷰, 경쟁사에 대한 공개 데이터도 정말 많다는 뜻이죠. 직접 수집해 본 적이 있다면 그 고생도 잘 아실 거예요.
예전에 시장 조사 프로젝트 때문에 경쟁사 상품을 수동으로 정리하느라 주말을 통째로 쓴 적이 있습니다. 상품 번호가 30쯤 되자, 제가 이 스프레드시트를 만들기까지 어떤 삶의 선택을 해왔는지 진지하게 돌아보게 되더군요. 사실 Etsy 데이터는 가격 분석, 제품 개발, 틈새시장 발굴, 판매자 벤치마킹에 아주 유용합니다. 다만 규모 있게 실제로 가져올 수 있을 때만 그렇죠. 이 가이드의 목적이 바로 그겁니다. Python으로 Etsy를 크롤링하는 방법을 네 가지 주요 페이지 유형(검색 결과, 상품 페이지, 샵 페이지, 리뷰)별로 한 번에 다루고, Etsy의 봇 차단 방어에 대한 솔직한 설명과, 아예 코딩을 건너뛰고 싶은 분들을 위한 노코드 대안까지 함께 소개합니다.
Python으로 Etsy를 크롤링한다는 건 무슨 뜻일까요?
웹 스크래핑은 쉽게 말해, 웹페이지를 방문해서 원하는 데이터를 자동으로 추출하는 코드를 작성하는 것을 뜻합니다. 상품명, 가격, 설명, 이미지, 평점, 리뷰, 샵 정보 등을 가져와 스프레드시트나 데이터베이스 같은 구조화된 형식으로 정리하는 거예요.
이런 작업에는 Python이 가장 많이 쓰입니다. 초보자도 시작하기 쉽고, 커뮤니티가 크며, 스크래핑에 특화된 라이브러리 생태계도 풍부하거든요. 예를 들면 Requests(페이지 요청), BeautifulSoup(HTML 파싱), Selenium과 Playwright(브라우저 자동화), pandas(데이터 정리 및 내보내기)가 있습니다. Python은 Stack Overflow의 연례 개발자 설문에서 꾸준히 가장 인기 있는 상위 3개 언어에 들고, PyPI에서도 스크래핑 라이브러리 다운로드 수가 상위권입니다.
Etsy를 크롤링할 때는 브라우저에 전달되는 HTML(때로는 숨겨진 JSON)에서 데이터를 가져오게 됩니다. 추출할 수 있는 데이터 유형은 다음과 같습니다.
- 상품명, 가격, 설명, 이미지, 옵션
- 판매자/샵 정보(이름, 판매 수, 위치, 평점)
- 평점과 전체 리뷰 텍스트
- 검색 결과 목록, 카테고리, 트렌드 신호
왜 Etsy를 크롤링할까요? ROI를 만드는 실제 활용 사례
Etsy 크롤링은 단순한 기술 연습이 아니라 경쟁 우위가 됩니다. 판매자든, 제품 관리자든, 데이터 분석가든, 구조화된 Etsy 데이터를 바로 활용할 수 있다면 수익에 직접적인 영향을 줄 수 있습니다.
| 활용 사례 | 무엇을 크롤링하나요 | 누가 혜택을 보나요 | 비즈니스 효과 |
|---|---|---|---|
| 경쟁 가격 분석 | 검색 결과 + 상품 가격 | 이커머스 운영, 판매자 | 동적 가격 책정은 평균적으로 수익을 5~22% 높일 수 있음 |
| 틈새시장 및 트렌드 발굴 | 검색 결과, 인기 상품 목록 | 창업자, 분석가 | 유망한 틈새를 조기에 포착 가능(예: "preppy pajamas"의 검색량이 +1,112% 증가) |
| 제품 개발 및 개선 | 리뷰, 상품 상세 | 제품팀 | 한 주방용품 브랜드는 리뷰 감성 데이터를 활용해 60일 만에 #1 베스트셀러를 되찾음 |
| SEO 및 키워드 조사 | 검색 결과, 상품 제목/태그 | 마케팅팀 | 수요는 높고 경쟁은 낮은 키워드 식별 |
| 판매자 벤치마킹 | 샵 페이지, 판매 수 | 세일즈팀, 분석가 | 구매한 리드 목록보다 훨씬 저렴한 건당 $0.01~0.10 수준으로 검증된 리드 리스트 구축 |
| 재고 및 품절 모니터링 | 상품 재고 상태 | 이커머스 운영 | 경쟁사 재고 변동에 더 빠르게 대응 |
이 모든 활용 사례는 서로 다른 Etsy 페이지 유형의 데이터가 필요합니다. 그래서 이 튜토리얼에서 네 가지를 모두 다루는 거예요.
시간 절약: 수작업 vs 자동화
- 수동 Etsy 조사: 상품당 30~45분(100개 상품이면 50~75시간)
- 자동 크롤링: 100개 목록을 2~5분 안에 처리
- AI 기반 스크래핑은 정확도는 최대 99.5%에 달함
Etsy API vs. 웹 스크래핑: 무엇을 선택해야 할까요?
코드를 한 줄도 쓰기 전에 먼저 묻고 싶은 질문이 있습니다. Etsy의 공식 API를 쓸까요, 아니면 사이트를 직접 크롤링할까요? 이 질문은 포럼에서도 정말 자주 보이고, 정답은 필요한 데이터에 따라 달라집니다.
Etsy API가 할 수 있는 것과 못 하는 것
Etsy는 OAuth 2.0 인증을 사용하는 API v3를 제공합니다. 자신의 샵 데이터, 즉 상품 목록, 주문, 영수증에 접근하는 데는 유용합니다. 하지만 한계도 분명합니다.
- 경쟁사 데이터: API는 대부분 자신의 샵으로 제한됩니다. 다른 판매자의 가격, 판매량, 상품 목록을 가져올 수 없습니다.
- 리뷰: 전체 리뷰 텍스트를 대량으로 가져올 수 있는 강력한 엔드포인트가 없습니다.
- 요청 제한: 기본적으로 초당 10회, 하루 10,000회 요청으로 제한됩니다. offset 상한은 12,000개 레코드입니다.
- AI/ML 사용: 앱 검토에서 명시적으로 거부됩니다.
- 문서화: 커뮤니티 불만이 많습니다. 예시는 부족하고, 폐기된 엔드포인트도 있으며, 지원도 느립니다.
웹 스크래핑이 더 나은 경우
경쟁사 인텔리전스, 리뷰 감성 분석, 샵 간 비교, 또는 API가 노출하지 않는 데이터가 필요하다면 스크래핑이 답입니다. 대신 그만큼 Etsy의 봇 차단 방어를 상대해야 하고(아래에서 자세히 설명합니다), 환경도 직접 구축해야 합니다.
비교표: API vs. 스크래핑 vs. 노코드
| 기준 | Etsy 공식 API | Python 웹 스크래핑 | Thunderbit (노코드) |
|---|---|---|---|
| 상품 가격 접근 | ✅ (일부 필드만) | ✅ 전체 HTML/JSON-LD | ✅ AI가 보이는 필드를 모두 추출 |
| 리뷰 데이터 | ❌ 대량 제공 안 됨 | ✅ 리뷰 엔드포인트/HTML 통해 가능 | ✅ 하위 페이지 스크래핑 |
| 경쟁사 샵 데이터 | ❌ 본인 샵만 가능 | ✅ 공개 샵이면 모두 가능 | ✅ 공개 샵이면 모두 가능 |
| 인증 필요 여부 | ✅ OAuth 2.0 | ⚠️ 로그인 데이터는 쿠키 필요 | ⚠️ 로그인은 브라우저 스크래핑으로 처리 |
| 봇 차단 위험 | 없음 | 높음(DataDome) | 처리됨(브라우저 네이티브) |
| 설정 시간 | 중간(API 키, OAuth) | 높음(코드 + 프록시) | 약 2분 |
경쟁사 데이터, 리뷰, 샵 간 분석이 필요하다면 API만으로는 부족합니다. 이건 솔직한 현실이에요.
코드를 쓰기 전에 Python 스크래핑 방식을 먼저 고르세요
Reddit과 Stack Overflow에서 정말 자주 보는 질문이 있습니다. "Requests + BeautifulSoup을 써야 하나요, Selenium을 써야 하나요, 프록시 API를 써야 하나요, 아니면 전혀 다른 걸 써야 하나요?" 정답은 기술 수준, 예산, 사용 사례에 따라 달라집니다.
| 방식 | 가장 적합한 경우 | 학습 난이도 | JS 처리 가능? | 봇 차단 대응 | 비용 |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | 완전한 제어를 원하는 개발자 | 중간 | ❌ | 수동 처리(헤더, 프록시) | 무료 + 프록시 비용 |
| Selenium / Playwright | JS가 많은 페이지, 로그인 흐름 | 높음 | ✅ | 일부만 대응(브라우저 지문) | 무료 + 프록시 비용 |
| 프록시 API 서비스 | 대규모 + 봇 차단 우회 | 중간 | ✅(API 통해) | ✅ 내장 | 월 $49+ |
| Thunderbit (노코드) | 비개발자, 빠른 추출 | 매우 낮음 | ✅(브라우저 네이티브) | ✅(브라우저 세션) | 무료 플랜 제공 |
완전한 제어가 필요하고 Python에 익숙하다면 Requests + BeautifulSoup이 좋습니다. JS 렌더링이나 로그인 흐름이 필요하면 Selenium을 쓰세요. 대규모 봇 차단 우회가 필요하면 프록시 서비스를 고려하면 됩니다. 그리고 Etsy 데이터를 코드 작성이나 유지보수 없이 얻고 싶다면 Thunderbit도 충분히 볼 가치가 있습니다. 이 부분은 뒤에서 더 설명할게요.
Etsy는 어떻게 막아낼까요: DataDome 봇 차단 방어 이해하기
대부분의 스크래핑 가이드는 "프록시만 쓰면 된다"고 하고 넘어갑니다. Etsy에서는 그걸로 부족합니다. Etsy는 웹에서 가장 공격적인 봇 차단 시스템 중 하나인 DataDome을 사용합니다. 에서도 Etsy를 성공 사례로 소개하며, 예전에는 스크래퍼가 Etsy 컴퓨팅 비용의 약 1%를 차지했다고 밝히고 있습니다.
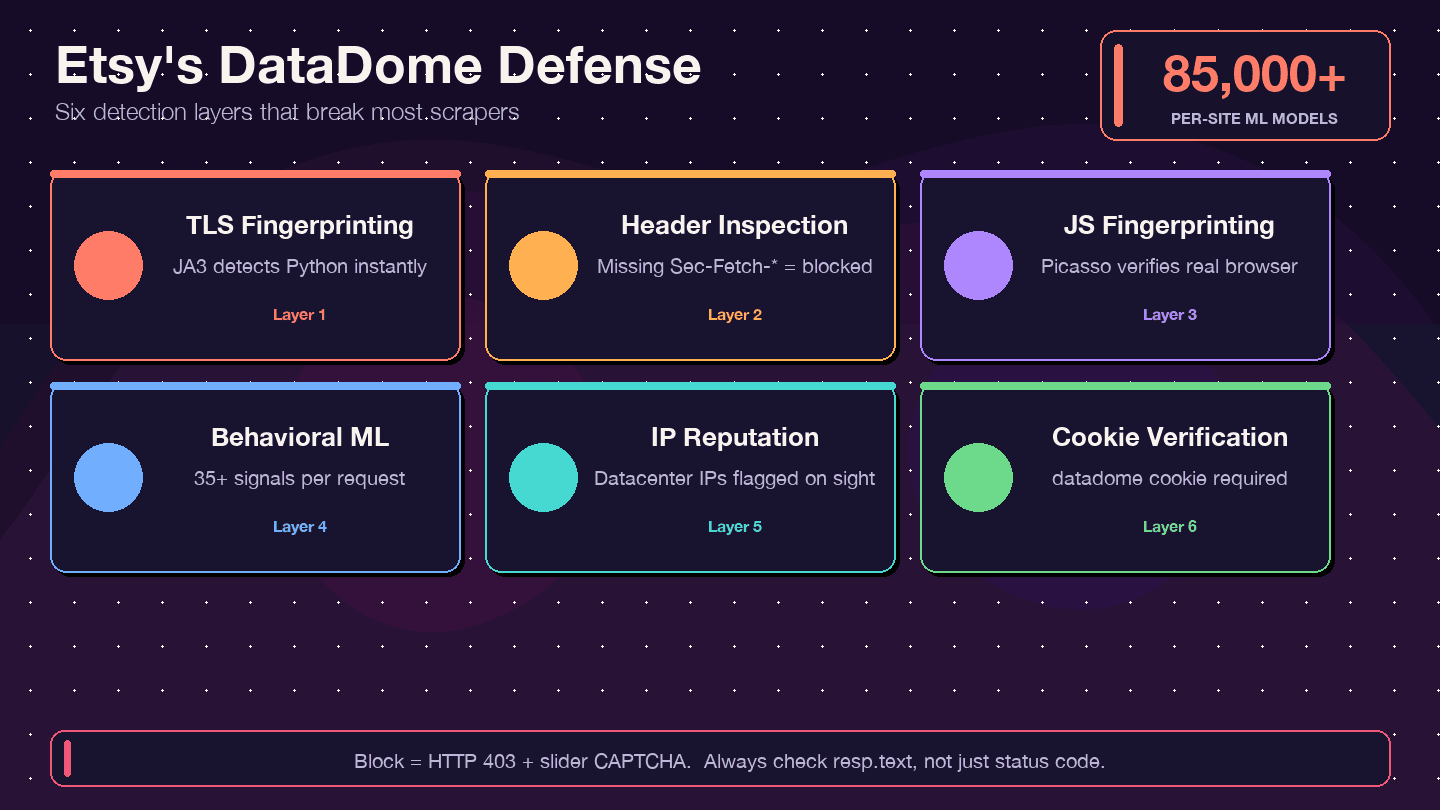
DataDome은 무엇이고 어떻게 작동할까요?
DataDome은 단순히 IP 주소만 확인하지 않습니다. 여러 겹의 탐지 스택을 실행합니다.
- TLS 지문 인식(JA3): Python의
requests라이브러리는 DataDome이 즉시 식별할 수 있는 고유한 TLS 서명을 갖고 있습니다. - HTTP 헤더/프로토콜 검사: 완전하고 일관된 브라우저 헤더를 확인합니다. 누락되거나 순서가 이상한 헤더는 경고 신호입니다.
- JavaScript 지문 인식(Picasso 프로토콜): 브라우저에서 JS 챌린지를 실행해 실제 사용자 여부를 검증합니다.
- 행동 기반 ML: 요청당 35개 이상의 신호를 분석하고, 사이트별 모델을 85,000개 이상 사용합니다.
- IP 평판 점수화: 데이터센터 IP는 즉시 표시됩니다.
- 쿠키 검증:
datadome쿠키가 존재하고 유효해야 합니다.
차단되었는지 확인하는 신호와 확인 방법
가장 흔한 함정 중 하나는 200 OK 응답을 받았는데, 실제로는 원하던 데이터가 아니라 CAPTCHA 페이지가 내려오는 경우입니다. 다른 신호도 있습니다.
- 403 Forbidden 오류
- 리다이렉트 루프
- 응답 본문에
ddJavaScript 객체나 슬라이더 CAPTCHA HTML이 포함됨
상태 코드만 보지 말고 항상 응답 본문까지 확인하세요. 간단한 체크 예시는 이렇습니다.
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("차단되었습니다! 데이터 대신 CAPTCHA 페이지를 받았습니다.")탐지를 줄이는 헤더와 쿠키
차단을 100% 피할 수 있다고 보장할 수는 없지만, 현실적인 헤더와 쿠키 관리는 큰 도움이 됩니다.
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})또한 다음도 중요합니다.
requests.Session()을 사용해 요청 간 쿠키를 유지하세요.- 요청 사이에 랜덤 지연(2~7초)을 넣으세요.
- 리퍼러 체인을 흉내 내세요. 홈페이지를 먼저 방문하고, 검색 페이지, 그다음 상품 페이지 순서로 이동하는 식입니다.
- 대규모 작업에서는 주거용 프록시 로테이션이 필수입니다. 데이터센터 IP는 거의 즉시 표시됩니다.
이런 기법은 탐지를 줄여 주지만 없애 주지는 않습니다. 대량 크롤링이라면 결국 프록시 서비스나 브라우저 기반 접근이 필요할 가능성이 큽니다.
Etsy를 크롤링하기 위한 Python 환경 설정
시작하기 전에:
- 난이도: 중급
- 소요 시간: 약 30~60분(설정 + 첫 크롤링)
- 준비물: Python 3.8+, pip, 코드 에디터, Chrome 브라우저(DevTools 확인용)
의존성 설치
프로젝트 폴더를 만들고 가상 환경을 설정한 뒤 필요한 라이브러리를 설치하세요.
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — 웹페이지 요청
- beautifulsoup4 — HTML 파싱
- lxml — 더 빠른 HTML 파서(선택 사항이지만 권장)
- pandas — 데이터를 CSV/Excel로 정리 및 내보내기
나중에 로그인이나 JS가 많은 페이지 때문에 브라우저 자동화가 필요하다면 이것도 설치하세요.
1pip install selenium코드를 쓰기 전에 Etsy 페이지 구조를 이해하세요
시간을 정말 많이 아껴 주는 팁이 있습니다. Etsy는 대부분의 페이지에서 <script type="application/ld+json"> 태그 안에 구조화된 상품 데이터를 넣어 둡니다. 이 JSON-LD 데이터는 상품명, 가격, 평점, 이미지처럼 이미 정리되어 있으므로, 각 필드마다 불안정한 CSS 선택자와 씨름할 필요가 없습니다.
아무 Etsy 상품 페이지나 열고, 마우스 오른쪽 버튼을 눌러 "페이지 소스 보기"를 선택한 뒤 application/ld+json을 검색해 보세요. 필요한 대부분의 데이터를 담은 @type: Product 블록을 찾을 수 있습니다. 검색 결과 페이지에는 @type: ItemList가 있습니다.
CSS 선택자는 배송 정보나 리뷰 텍스트처럼 JSON-LD에 없는 데이터를 가져올 때 유용한 대체 수단이지만, 첫 번째 선택지는 JSON-LD여야 합니다.
1단계: Python으로 Etsy 검색 결과 크롤링하기
검색 결과는 대부분의 Etsy 크롤링 프로젝트의 출발점입니다. 틈새시장을 모니터링하든, 경쟁 가격을 추적하든, 상품 데이터베이스를 만들든 마찬가지예요.
검색 URL 만들기
Etsy 검색 URL은 다음 형식을 따릅니다.
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}여러 단어로 된 검색어는 공백을 URL 인코딩해야 합니다(예: handmade+jewelry 또는 handmade%20jewelry). ref=pagination 파라미터는 요청이 더 실제 브라우저 이동처럼 보이게 해줍니다.
추가로 유용한 파라미터는 order(most_relevant, price_asc, price_desc, date_desc), min_price, max_price, ship_to, free_shipping=true입니다. 각 페이지는 48개 항목을 반환합니다.
요청 보내고 HTML 파싱하기
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"\{page\}페이지에서 차단되었습니다. 지연 시간이나 프록시를 추가해 보세요.")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsJSON-LD에서 상품 목록 데이터 추출하기
itemListElement 배열에는 각 상품의 이름, URL, 이미지, 가격, 통화가 들어 있습니다. 별점이나 결과 수처럼 JSON-LD에 항상 들어 있지 않은 정보가 더 필요하면 CSS 선택자로 보완하세요.
- 목록 카드:
.v2-listing-card - 제목:
h3.v2-listing-card__title - 가격:
span.currency-value - 링크:
a.listing-link(href)
페이지네이션 처리하기
페이지를 반복하면서 요청 사이에 랜덤 지연을 추가하세요. Etsy는 보통 쿼리에 따라 20~250페이지 정도까지 반환합니다.
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"{len(results)}개의 상품을 크롤링했습니다.")5페이지를 크롤링하는 데 제 테스트에서는 약 20초가 걸렸습니다. 수동으로 복사-붙여넣기 하는 데 30분 이상 걸리는 것과 비교하면 엄청난 차이죠.
2단계: Python으로 Etsy 상품 페이지 크롤링하기
검색 결과에서 상품 URL 목록을 얻었다면, 다음 단계는 각 상품 페이지에서 상세 데이터를 가져오는 것입니다.
상품 페이지 가져오기
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return None가격 변형 처리하기
일부 상품은 offers.price 하나만 갖고 있습니다. 반면 크기나 색상 같은 옵션이 있는 상품은 offers.lowPrice와 offers.highPrice를 사용합니다. 위 코드는 price가 없으면 lowPrice로 넘어가도록 해서 두 경우를 모두 처리합니다.
CSS 선택자로 추가 필드 파싱하기
JSON-LD에 없는 데이터, 예를 들어 배송 정보, 옵션, 판매자 세부 정보는 CSS 선택자가 필요합니다.
- 제목:
h1[data-buy-box-listing-title] - 옵션:
select[data-selector-id]또는div[data-option-set] - 배송: 배송 섹션 근처의
div.wt-text-caption
트레이드오프는 이렇습니다. JSON-LD는 더 깔끔하고 레이아웃 변경에도 훨씬 안정적입니다. CSS 선택자는 더 취약하지만 더 많은 필드를 다룰 수 있습니다.
3단계: Python으로 Etsy 샵 페이지 크롤링하기
이 부분은 많은 경쟁 가이드가 아예 건너뛰는 영역인데, 세일즈팀과 경쟁 분석가에게는 어쩌면 가장 가치 있는 파트입니다.
샵 URL 만들고 페이지 가져오기
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # HTML에서 샵 메타데이터 추출(JSON-LD에는 없음)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # JSON-LD에서 상품 목록 추출
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_data샵 페이지에서 추출할 수 있는 것
샵 페이지의 JSON-LD는 @type: ItemList입니다. 상품 목록은 포함하지만, 판매 수나 위치, 평점 같은 샵 수준 메타데이터는 포함하지 않습니다. 그 부분은 CSS 선택자가 필요합니다.
| 데이터 포인트 | 선택자 | 비고 |
|---|---|---|
| 샵 이름 | h1 또는 메타 제목 | 보통 페이지 제목에 있음 |
| 총 판매 수 | div.shop-sales-reviews a | "12,345 sales" 같은 텍스트 |
| 별점 | input[name="initial-rating"]의 value | 숫자 1~5 |
| 위치 | div.shop-location | 도시, 국가 |
| 가입 시점 | div.shop-info | 날짜 텍스트 |
샵 데이터는 리드 리스트 구축, 경쟁사 벤치마킹, 특정 틈새의 상위 판매자 찾기에 특히 유용합니다.
4단계: Python으로 Etsy 리뷰 크롤링하기
리뷰는 Etsy에서 가장 가치 있으면서도 가장 까다로운 데이터 중 하나입니다. 전체 리뷰 텍스트, 평점, 날짜는 초기 페이지 HTML에 들어 있지 않고 내부 API 엔드포인트를 통해 로드됩니다.
방법 1: Etsy 내부 리뷰 API 엔드포인트 찾기
Chrome에서 상품 페이지를 열고 DevTools(F12)를 연 다음 Network 탭으로 이동해 리뷰 섹션까지 내려가 보세요. 다음과 비슷한 POST 요청을 볼 수 있습니다.
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews이 엔드포인트는 리뷰 카드가 들어 있는 HTML 조각을 반환합니다. 사용하려면 다음이 필요합니다.
- listing_id — 상품 URL에서 가져오는 숫자 ID
- shop_id — 정규식으로 상품 페이지 HTML에서 추출
- csrf_nonce — 페이지의
<meta>태그에서 추출
ID와 CSRF 토큰 추출하기
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrf페이지네이션으로 리뷰 크롤링하기
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviews방법 2: HTML에서 리뷰 파싱하기(대체 방법)
API 방식이 실패하면(예: CSRF 토큰 문제) 상품 페이지 HTML에서 첫 번째 리뷰 묶음을 직접 파싱할 수 있습니다. 한계는 정적 HTML에 초기 리뷰 일부만 있다는 점입니다. 더 많은 리뷰를 가져오려면 API나 Selenium 같은 브라우저 자동화 도구가 필요합니다.
로그인 필요한 데이터 다루기: 내 Etsy 샵 크롤링하기
이건 다른 튜토리얼에서는 거의 다루지 않지만 실제로 매우 필요한 부분입니다. 특히 Etsy 판매자가 자신의 주문, 매출, 통계를 추출하고 싶을 때 그렇죠.
문제는 requests만으로는 Etsy 대시보드에 접근할 수 없다는 점입니다. 로그인 세션 쿠키를 들고 있지 않기 때문입니다.
옵션 1: Selenium으로 수동 로그인 후 쿠키 캡처
Selenium으로 브라우저를 열고 수동으로 로그인한 뒤(또는 로그인 자동화 후) 인증된 상태에서 계속 크롤링할 수 있습니다.
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# 브라우저 창에서 수동으로 로그인한 다음:
5input("로그인 후 Enter를 누르세요...")
6cookies = driver.get_cookies()
7# 이제 driver.get()으로 대시보드 페이지로 이동하면서 크롤링Selenium 세션에서 쿠키를 저장해 두었다가, 초기 로그인 이후에는 requests.Session()과 함께 재사용하면 더 빠르고 가벼운 크롤링도 가능합니다.
옵션 2: 브라우저 쿠키를 내보내 Requests에 사용하기
브라우저 확장 프로그램(예: "EditThisCookie")으로 현재 Etsy 세션 쿠키를 내보낸 뒤 Requests 세션에 넣을 수 있습니다.
1import requests
2session = requests.Session()
3# 브라우저에서 내보낸 쿠키 추가
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... 필요한 다른 세션 쿠키도 추가
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)쉬운 길: Thunderbit의 브라우저 스크래핑 모드
는 Chrome 브라우저 안에서 실행되기 때문에 현재 Etsy 세션을 자동으로 그대로 사용합니다. 인증 코드도, 쿠키 내보내기도 필요 없습니다. 그냥 Etsy 대시보드로 이동해서 바로 크롤링하면 됩니다. 주문, 매출, 통계, 기타 판매자 전용 데이터를 스크립트 없이 추출할 때 정말 유용합니다.
크롤링한 Etsy 데이터를 내보내고 활용하기
CSV 또는 JSON으로 저장하기
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)권장 사항: 파일명에 타임스탬프를 포함하고, UTF-8 인코딩을 사용하며, 상품명에 포함된 특수문자는 잘 처리하세요(Etsy 판매자는 이모지와 악센트 문자를 정말 좋아하거든요).
Google Sheets, Airtable, Notion으로 내보내기
Python 사용자라면 gspread(Google Sheets)나 Airtable API 같은 라이브러리로 데이터를 프로그래밍 방식으로 보낼 수 있습니다. 하지만 를 사용한다면 Google Sheets, Excel, Airtable, Notion으로의 내보내기가 모두 무료이고 원클릭입니다. API 키도, OAuth 설정도 필요 없습니다.
코딩 없이 Etsy를 크롤링하는 방법: Thunderbit 노코드 대안
모든 사람이 Python 스크립트를 작성하고, 프록시 설정을 관리하고, 새벽 2시에 CSS 선택자 디버깅을 하고 싶어 하는 건 아닙니다. 만약 당신이 그런 분이라면, 로 Etsy 데이터를 가져오는 방법을 소개할게요.
Thunderbit Chrome 확장 프로그램 설치하기
로 가서 Thunderbit을 설치하세요. 무료 계정을 만들면 무료 플랜으로 를 사용할 수 있고, 내보내기도 모두 무료입니다.
어떤 Etsy 페이지든 AI 추천 필드 사용하기
Etsy 검색, 상품, 샵 페이지로 이동하세요. Thunderbit 사이드바에서 **"AI Suggest Fields"**를 클릭하면 AI가 페이지를 스캔해 상품명, 가격, 평점, 이미지, 샵 이름, 태그, 배송 정보 같은 열을 추천합니다. 필요에 따라 열을 조정하거나 추가하면 됩니다.
스크랩하고 내보내기 클릭하기
**"Scrape"**를 클릭하면 현재 페이지의 데이터를 추출할 수 있습니다. 여러 페이지 결과라면 Thunderbit의 페이지네이션 스크래핑을 사용하세요. 상품 URL 목록을 각 상품 페이지의 상세 정보(설명, 리뷰, 배송 정보)로 풍부하게 만들고 싶다면 하위 페이지 스크래핑을 사용하면 됩니다. Thunderbit이 각 링크를 방문해 추가 데이터를 자동으로 가져옵니다.
Excel, Google Sheets, Airtable, Notion으로 모두 무료 내보내기가 가능합니다.
Etsy 스크래핑에서 Thunderbit가 Python보다 유리한 경우
- 프록시 설정이나 봇 차단 코드가 필요 없습니다. Thunderbit은 실제 Chrome 브라우저에서 실행되므로 세션을 그대로 이어받고 DataDome에는 일반 사용자처럼 보입니다.
- AI가 레이아웃 변화에 자동 적응합니다. Etsy가 프론트를 바꿔도 깨진 선택자를 고칠 필요가 없습니다.
- 일회성 리서치, 경쟁 분석, 비기술 팀원에게 특히 좋습니다. 빠르게 데이터셋만 필요하다면 Python 환경 자체가 필요 없죠.
- 하위 페이지 스크래핑을 쓰면 중첩 루프를 작성하지 않고도 상품 URL 목록에 상세 데이터를 더할 수 있습니다.
사용법은 에서도 확인할 수 있습니다.
Python vs. Thunderbit: 6개월 비용 비교
| 항목 | Python 직접 구축 | Thunderbit |
|---|---|---|
| 설정 시간 | 8~20시간 | 5분 이내 |
| 6개월 비용(인건비, 프록시 포함) | $2,720~9,450 | $90~228 |
| 월간 유지보수 | 4~10시간 이상(선택자 업데이트가 오버헤드의 80% 이상) | 0~1시간 |
| 봇 차단 대응 | 일반 비용의 85배 수준 주거용 프록시 필요 | 브라우저 기반, DataDome를 네이티브로 우회 |
| 데이터 품질 | 높음(노력 필요) | 높음(AI 기반) |
Python이 틀린 선택이라는 말은 아닙니다. 완전한 제어, 맞춤 로직, 더 큰 파이프라인과의 통합이 필요하다면 코드는 여전히 강력합니다. 하지만 대부분의 비즈니스 사용자는 그냥 Etsy 데이터만 있으면 되므로, ROI를 따져 보면 노코드 도구가 더 유리합니다.
Etsy 크롤링 시 법적·윤리적 팁
모든 스크래핑 글마다 합법성 질문을 받기 때문에, 짧게 정리해 드리면 이렇습니다.
- Etsy의 이용약관은 자동 접근을 명시적으로 금지합니다. 다만 Etsy는 소송보다 기술적 차단(DataDome)에 더 의존하고 있으며, 스크래퍼를 직접 겨냥한 Etsy 전용 소송 사례는 알려진 바 없습니다.
- 공개 데이터만 크롤링하세요. 인증을 우회하거나 본인이 소유하지 않은 비공개 판매자 대시보드에 접근하지 마세요.
- 합리적인 요청 속도를 지키세요. 요청 간 2~7초 지연을 두고, Etsy 서버를 과도하게 두드리지 마세요.
robots.txt를 존중하세요. Etsy는 검색 페이지는 허용하지만 일부 경로는 제한합니다.- GDPR 같은 개인정보 보호법에 따라 개인 데이터를 책임감 있게 다루세요.
- 상업적 규모의 크롤링 프로젝트라면 법률 자문을 받으세요.
추가 배경이 필요하다면 관련 글도 참고해 보세요. 여기에는 공개 데이터 스크래핑이 인정된 Meta v. Bright Data(2024) 사례도 포함되어 있습니다.
마무리: 핵심 요약
오늘 정말 많은 내용을 다뤘습니다. 꼭 가져가셨으면 하는 핵심은 다음과 같습니다.
- Etsy의 JSON-LD 구조화 데이터 덕분에 대부분의 필드는 원시 HTML 파싱보다 훨씬 깔끔하게 추출할 수 있습니다.
- DataDome는 실제 장벽입니다. Python으로 대규모 크롤링을 하려면 올바른 헤더, 지연, 쿠키 관리, 주거용 프록시가 필요합니다.
- Etsy API는 제한적입니다. 리뷰, 경쟁사 샵, 판매자 간 분석이 필요하다면 실용적인 방법은 스크래핑입니다.
- Thunderbit은 노코드 대안으로, 봇 차단과 인증을 네이티브로 처리합니다. 스크립트를 유지보수하고 싶지 않다면 한 번 써볼 만합니다.
- 항상 책임감 있게 크롤링하고 Etsy의 약관을 존중하세요.
코드를 쓰지 않고 시작하고 싶다면 . 아니면 이 튜토리얼의 Python 코드를 활용해 자신만의 커스텀 스크래퍼를 만들어 보세요. 그리고 금요일 오후에 선택자가 절대 깨지길 바라지 않길요.
더 많은 스크래핑 가이드는 와 정리 글을 확인해 보세요.
자주 묻는 질문
1. Python으로 Etsy를 크롤링하는 건 합법인가요?
공개적으로 이용 가능한 데이터를 크롤링하는 것은 일반적으로 최근 판례(예: Meta v. Bright Data, hiQ v. LinkedIn)에서 허용되는 편입니다. 다만 Etsy의 이용약관은 자동 접근을 금지하므로, 크롤링 전에 항상 ToS와 robots.txt를 확인하세요. 대규모 또는 상업적 용도라면 법률 자문을 받는 것이 좋습니다.
2. 차단되지 않고 Etsy를 크롤링할 수 있나요?
Etsy는 매우 강력한 봇 차단 시스템인 DataDome을 사용합니다. 현실적인 헤더, 요청 지연, 쿠키 유지, 주거용 프록시 로테이션이 차단을 줄이는 데 도움이 됩니다. Thunderbit의 브라우저 네이티브 방식은 실제 Chrome 세션 안에서 동작하므로 대부분의 탐지를 피할 수 있습니다.
3. 스크래핑 대신 사용할 수 있는 Etsy API가 있나요?
네. Etsy는 API v3를 제공합니다. 하지만 대부분 자신의 샵 데이터로 제한되고, 강력한 리뷰 접근 기능은 없습니다. 경쟁 인텔리전스와 샵 간 분석의 대부분은 스크래핑이 필요합니다.
4. Etsy를 크롤링하려면 어떤 Python 라이브러리가 필요한가요?
최소한 requests, beautifulsoup4, pandas(내보내기용), json(내장)을 사용하면 됩니다. JS가 많거나 로그인 필요한 페이지라면 selenium을 추가하세요. 더 빠른 HTML 파싱이 필요하면 lxml을 사용하세요.
5. Etsy 리뷰만 따로 어떻게 크롤링하나요?
Etsy 리뷰는 내부 API 엔드포인트(/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews)를 통해 로드됩니다. 상품 페이지에서 listing ID, shop ID, CSRF 토큰을 추출한 뒤, 페이지네이션과 함께 엔드포인트에 POST 요청을 보내야 합니다. 대체 방법으로는 상품 페이지 HTML에서 첫 번째 리뷰 묶음을 파싱할 수 있습니다. 이 튜토리얼에서 두 방법 모두 단계별로 다룹니다.
더 알아보기