대부분의 eBay 스크래핑 튜토리얼은 수명이 고작 3개월 남짓입니다. Thunderbit 팀은 개발자들이 깨진 코드 조각, 낡은 CSS 선택자, 그리고 겉보기엔 멀쩡해 보이지만 eBay가 두 번이나 개편된 뒤 조용히 멈춰버린 “작동하는” GitHub 저장소를 떠돌아다니는 모습을 수없이 봐왔기 때문에 이 상황을 잘 압니다.
eBay에는 이 있습니다. Amazon 다음으로 오픈 웹에서 가장 큰 롱테일 가격 데이터셋이라고 해도 과언이 아니죠. 이 데이터는 리셀러 가격 책정부터 경쟁사 인텔리전스까지 거의 모든 영역의 바탕이 됩니다. 하지만 이 데이터를 프로그램으로 가져오는 일은 생각보다 훨씬 까다롭습니다. eBay의 React 기반 프런트엔드는 CSS 클래스명을 수시로 바꾸고, A/B 테스트는 사용자마다 다른 DOM 구조를 보여주며, Akamai Bot Manager가 HTML까지 가로막고 있기 때문입니다. 이 가이드는 오늘 기준으로 실제로 작동하는 Python 코드를 제공하고, 스크래퍼가 왜 깨지는지 설명해 더 튼튼한 도구를 만드는 데 도움을 드리며, eBay API와 스크래핑 중 무엇을 선택해야 하는지 현실적으로 비교하고, Python 세팅이 번거로울 때 쓸 수 있는 노코드 대안까지 소개합니다.
Python으로 eBay를 스크래핑한다는 건 무슨 뜻일까?
Python으로 eBay를 스크래핑한다는 것은 스크립트를 작성해 eBay 웹페이지를 프로그램으로 불러오고, HTML(또는 숨겨진 JSON)을 파싱한 뒤, 제목·가격·판매자 정보·판매 날짜·옵션 정보 같은 구조화된 데이터를 CSV, 스프레드시트, 데이터베이스처럼 실제로 활용 가능한 형식으로 뽑아내는 것을 뜻합니다.
스크래핑할 수 있는 eBay 페이지 유형은 여러 가지입니다.
- 검색 결과(예: "AirPods Pro" 전체 리스팅)
- 개별 상품 상세 페이지(전체 사양, 이미지, 판매자 정보)
- 판매 완료/종료 리스팅(실제 거래 가격과 날짜)
- 판매자 프로필과 리뷰
이 작업에는 Python이 가장 많이 쓰입니다. Requests, BeautifulSoup, lxml, pandas 같은 생태계 덕분에 페이지를 가져오고, HTML을 파싱하고, 데이터를 다루는 과정이 비교적 수월하기 때문입니다. 다만 웹페이지 HTML을 직접 긁는 것과 eBay의 공식 API를 사용하는 것 사이에는 분명한 차이가 있는데, 이 부분은 다음에서 살펴보겠습니다.
왜 eBay를 스크래핑할까? 비즈니스 팀을 위한 실제 활용 사례
이 글을 보고 계시다면 아마 이미 이유가 있으실 겁니다. 그래도 논의를 실질적인 비즈니스 가치와 연결해보면 좋습니다. eBay 데이터의 ROI는 정말 인상적이기 때문입니다. Bain은 고 분석했습니다. McKinsey는 리테일에서 동적 가격 책정이 할 수 있다고 봅니다.
가장 흔한 활용 사례는 다음과 같습니다.
| 활용 사례 | 필요한 데이터 | 비즈니스 효과 |
|---|---|---|
| 가격 모니터링 및 재가격 책정 | 활성 리스팅 가격, 배송비, 상품 상태 | 경쟁력 있는 가격 유지, 마진 보호 |
| 경쟁사 분석 | 상품 구색, 프로모션, 배송 조건 | 전략적 포지셔닝, 상품군 공백 파악 |
| 시장 조사 및 트렌드 탐색 | 리스팅 속도, 카테고리 트렌드, 수요 패턴 | 신제품 발굴, 수요 예측 |
| 리셀러 가격 산정 / 감정 | 판매 가격, 판매 날짜, 상태 | 적정 시세 판단, 구매 의사결정 |
| 감성 분석 | 리뷰, 평점, 반품 정책 | 제품 품질 인사이트, 고객 만족도 분석 |
| 리드 생성 | 판매자 프로필, 스토어 정보, 연락처 | 거래액이 큰 B2B 판매자에게 아웃리치 |
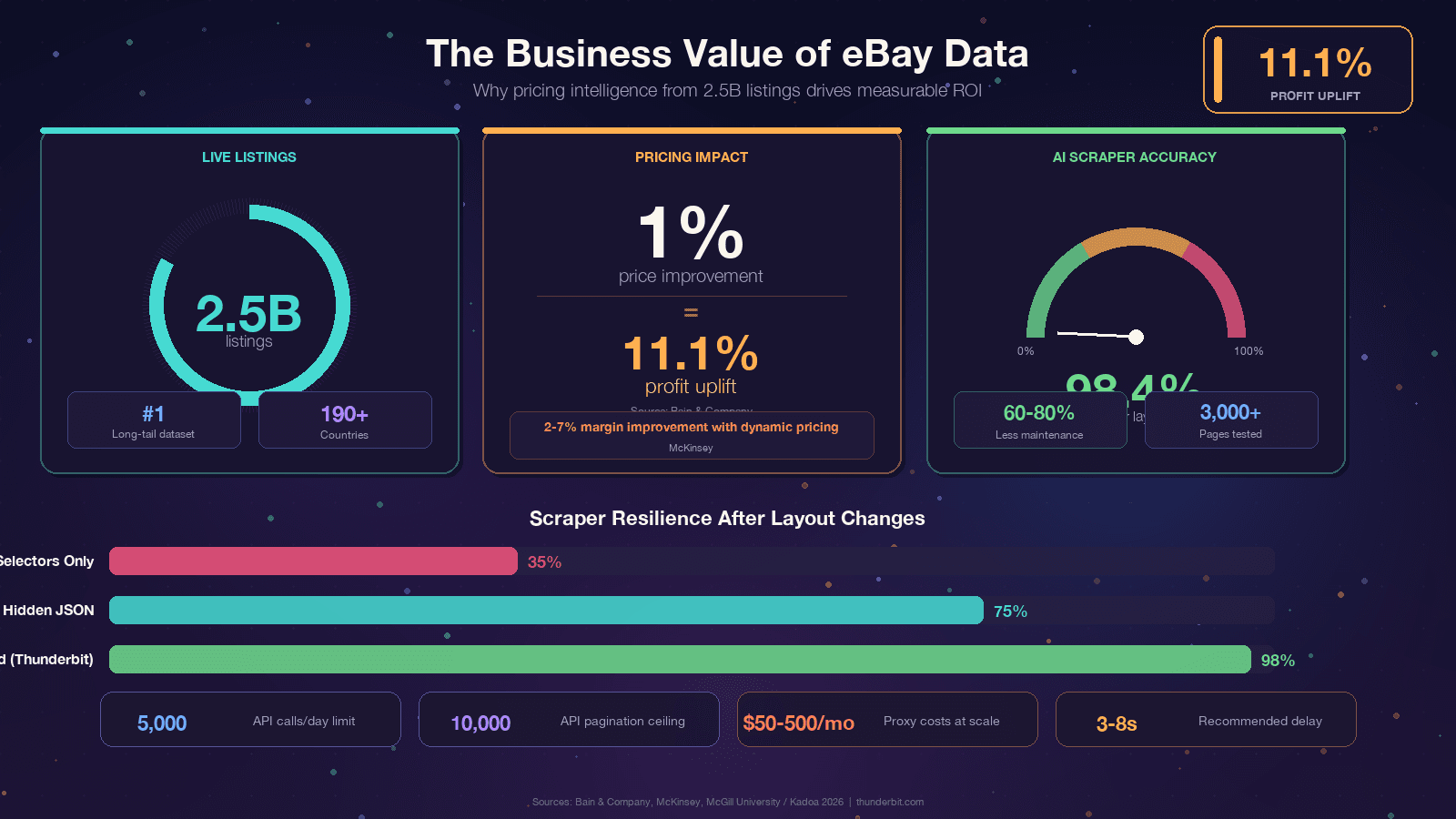
핵심은 같습니다. eBay에는 데이터가 있지만, 그 데이터가 웹페이지 안에 갇혀 있다는 점이죠.
스크래핑은 그 데이터를 경쟁 우위로 바꾸는 방법입니다.
eBay 공식 API vs. Python 웹 스크래핑: 무엇을 선택해야 할까?
이야말로 많은 튜토리얼이 솔직하게 답해주지 않는 질문입니다. eBay는 공식 API, 특히 를 제공하며, 많은 사용자가 API를 쓸지 직접 스크래핑할지 고민합니다. 답은 필요한 데이터에 따라 달라집니다.
| 기준 | eBay Browse/Finding API | Python 웹 스크래핑 |
|---|---|---|
| 판매 완료/종료 리스팅 | 제한적 — Marketplace Insights API가 있지만 접근이 자주 거절됨 | LH_Sold=1&LH_Complete=1 URL 파라미터로 전체 접근 가능 |
| 요청 제한 | 기본 티어에서 하루 5,000회 호출 | 자체 관리(프록시 의존) |
| 데이터 필드 | 사전 정의됨(제목, 가격, 카테고리, 기본 판매자 정보) | 페이지에 보이는 것은 무엇이든 가능(리뷰, 전체 사양, 옵션 매트릭스) |
| 설정 복잡도 | OAuth 2.0, 앱 등록, API 키 | pip install + 코드 |
| 안정성 | 엔드포인트가 안정적 | HTML이 바뀌면 깨짐 |
| 비용 | 무료 티어 제공, 대량 사용은 유료 | 코드는 무료지만 대규모에선 프록시 비용 발생 |
| 옵션/MSKU 데이터 | 부분적 — 많은 경우 부모 SKU만 제공 | 전체 가능(숨겨진 JSON 파싱) |
| 페이지네이션 깊이 | 10,000개 항목 상한 | 이론상 무제한 |
짧게 하나 짚고 가면, 예전 Finding API(findCompletedItems 포함)는 되었습니다. ebaysdk-python이나 Finding 모듈을 호출하는 라이브러리를 쓰고 있다면, 지금 프로덕션에서는 이미 깨져 있을 가능성이 높습니다.
제 추천: 활성 리스팅처럼 안정적이고 중간 규모의 구조화된 카탈로그 조회에는 Browse API를 사용하세요. 판매 완료 가격, 리뷰, 옵션 데이터, 또는 API가 노출하지 않는 필드가 필요하면 Python 스크래핑을 쓰는 것이 좋습니다. 많은 팀은 두 방식을 함께 사용합니다.
Python으로 eBay를 스크래핑할 때 필요한 도구와 라이브러리
코드를 쓰기 전에 먼저 도구부터 보겠습니다. 대부분의 eBay 페이지는 헤드리스 브라우저까지는 필요 없습니다. 데이터가 서버 렌더링 HTML 안에 이미 포함되어 있기 때문입니다.
| 라이브러리 | 용도 |
|---|---|
requests 또는 httpx | eBay 페이지를 내려받는 HTTP 클라이언트 |
curl_cffi | 실제 브라우저 TLS 지문을 흉내 내는 HTTP 클라이언트(Akamai 우회에 중요) |
beautifulsoup4 | CSS 선택자로 추출하기 위한 HTML 파서 |
lxml | BeautifulSoup용 고속 파서 백엔드 |
jmespath | 중첩 JSON 블롭을 조회하는 쿼리 언어 |
pandas | 데이터 처리 및 CSV/Excel 내보내기 |
gspread | Google Sheets 연동 |
한 번에 설치하려면 아래 명령을 사용하세요.
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspread**Python 3.11+**를 사용하세요. pandas 3.0은 3.10 이상이 필요하고, 3.11은 I/O 중심 작업에서 10~60% 성능 향상을 제공합니다.
특히 주목할 라이브러리는 **curl_cffi**입니다. 2026년 기준 eBay 스크래퍼에서 체감할 수 있는 가장 큰 업그레이드라고 해도 과언이 아닙니다. eBay는 를 사용하며, Akamai의 핵심 탐지 방식은 TLS 지문 분석입니다. 일반 requests는 Python 특유의 JA3 지문을 내보내서 거의 즉시 걸립니다. 반면 curl_cffi는 실제 Chrome 브라우저의 TLS 핸드셰이크를 흉내 내므로, 헤드리스 브라우저 없이도 Akamai 보호 대상의 약 90%를 처리할 수 있습니다.
단계별 가이드: Python으로 eBay 검색 결과 스크래핑하기
이 파트가 핵심 튜토리얼입니다. eBay 검색 결과 페이지에서 상품 리스팅을 가져오겠습니다.
- 난이도: 초급~중급
- 소요 시간: 첫 성공까지 약 30분
- 준비물: Python 3.11+, 위에서 소개한 라이브러리, 터미널, 대상 eBay 검색 URL
1단계: Python 프로젝트 준비하기
프로젝트 디렉터리를 만들고 의존성을 설치합니다.
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasscrape_ebay.py라는 파일을 하나 만드세요. 그곳이 작업 공간입니다.
2단계: eBay 검색 URL 만들기
eBay 검색 URL 구조는 단순합니다. 핵심 파라미터는 _nkw(키워드)입니다.
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # 페이지당 항목 수: 60, 120, 또는 240(240은 봇 플래그를 유발할 수 있음)
7 "_pgn": "1", # 페이지 번호
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1자주 쓰는 다른 파라미터는 다음과 같습니다.
LH_BIN=1— Buy It Now만 보기_sacat=175673— 특정 카테고리_sop=12— 베스트 매치 기준 정렬(10 = 가격+배송 최저, 13 = 신규 등록순)LH_Complete=1&LH_Sold=1— 판매 완료/종료 리스팅(아래 전용 섹션에서 다룹니다)
3단계: 요청 보내기와 응답 처리하기
여기서 curl_cffi의 진가가 드러납니다. 일반 requests.get()은 Akamai에서 403을 돌려주는 경우가 많습니다. curl_cffi를 사용하면 실제 Chrome 브라우저처럼 가장할 수 있습니다.
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" 상태 {r.status_code}, {sleep_for:.1f}초 후 재시도...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" 요청 오류: {e}, 재시도 중...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"{max_retries}번 재시도 후 실패: {url}")지수 백오프에 지터를 더하는 방식이 중요합니다. 고정된 대기 시간 자체가 봇 지문이 될 수 있기 때문입니다.
4단계: 검색 페이지에서 상품 리스팅 파싱하기
eBay는 현재 두 가지 검색 결과 레이아웃 사이를 전환하는 중입니다. 튼튼한 스크래퍼라면 둘 다 처리해야 합니다.
| 필드 | 기존 레이아웃 | 새 레이아웃 |
|---|---|---|
| 카드 컨테이너 | li.s-item | li.s-card 또는 div.su-card-container |
| 제목 | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| 가격 | span.s-item__price | .s-card__price |
두 레이아웃을 모두 처리하는 파싱 코드는 다음과 같습니다.
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # 제목 — 두 레이아웃 모두 시도
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # 가짜 "Shop on eBay" 플레이스홀더 카드 제외
11 if not title or "Shop on eBay" in title:
12 continue
13 # 가격
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # 이미지
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # 배송
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return results첫 번째 카드 함정은 전형적인 실수입니다. 많은 eBay 검색 페이지의 첫 li.s-item은 "Shop on eBay"라는 제목만 있는 숨김 플레이스홀더이며, 실제 가격이 없습니다. 꼭 걸러내세요.
5단계: 여러 페이지를 스크래핑하도록 페이지네이션 처리하기
eBay는 _pgn 파라미터로 페이지를 나눕니다. 다음 페이지 링크는 a.pagination__next를 사용합니다.
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"페이지 {page_num} 스크래핑 중: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" {page_num}페이지에 결과가 없습니다. 중단합니다.")
12 break
13 all_results.extend(results)
14 print(f" {len(results)}개 리스팅 발견(누적: {len(all_results)})")
15 # 예의 있는 대기 — 지터 포함 3~8초
16 time.sleep(random.uniform(3, 8))
17 return all_results3~8초의 랜덤 지터는 선택 사항이 아닙니다.
eBay의 Akamai 레이어는 한 IP에서 1초당 1회 이상 지속적으로 요청하면 플래그를 세웁니다.
6단계: 스크래핑한 데이터를 CSV 또는 JSON으로 내보내기
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"{len(df)}개 리스팅을 CSV와 JSON으로 내보냈습니다.")이제 eBay 리스팅이 깔끔한 스프레드시트 형태로 정리됐을 겁니다. 제 환경에서는 3페이지(360개 리스팅)를 스크래핑하는 데 지연 시간을 포함해 약 45초가 걸렸습니다.
Python으로 eBay 상품 상세 페이지를 스크래핑하는 방법
검색 결과는 요약 정보만 보여줍니다. 상품 상세 페이지에는 전체 설명, 판매자 피드백 점수, 상품 상세 사양, 이미지 캐러셀, 옵션 데이터 같은 핵심 정보가 들어 있습니다.
단일 상품 상세 페이지 파싱하기
eBay 상품 페이지는 /itm/<ITEM_ID> 형태의 URL에 있습니다. 가장 안정적인 추출 경로는 JSON-LD입니다. eBay는 거의 모든 CSS 변경을 견디는 Product 스키마 블록을 심어두기 때문입니다.
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — 가장 안정적인 추출 경로
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. JSON-LD에 없는 필드는 CSS 폴백 사용
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. 상품 상세 항목
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return item여기서 중요한 패턴은 JSON-LD를 먼저 쓰고, CSS 폴백을 나중에 쓰는 것입니다. 그래야 분기별로 스크래퍼가 깨지는 일을 크게 줄일 수 있습니다. 아래에서 더 설명하겠습니다.
eBay 상품 옵션(MSKU 데이터) 스크래핑하기
eBay 리스팅 중에는 색상, 사이즈, 저장 용량이 다른 여러 옵션이 있는 경우가 있습니다. 화면에 보이는 DOM은 사용자가 옵션을 클릭하기 전까지 "$899 to $1,099" 같은 가격 범위만 보여줍니다. 실제 옵션별 가격은 MSKU라는 숨겨진 JavaScript 객체에 들어 있습니다.
이 부분은 eBay API가 부모 SKU 정도만 부분적으로 제공하기 때문에, 오히려 스크래핑이 더 나은 영역 중 하나입니다.
1import re, json
2def extract_variants(html):
3 # 비탐욕적 매칭이 핵심입니다 — 탐욕적 .+는 페이지 전체를 먹어버립니다
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skus이 정규식의 비탐욕적 (.+?) 부분이야말로 대부분의 eBay 스크래퍼가 걸려 넘어지는 지점입니다. 탐욕적 .+는 페이지에서 마지막 "QUANTITY"가 나오는 지점까지 전부 삼켜버려 잘못된 JSON을 만들어냅니다. “작동한다”는 튜토리얼에서 이 버그를 적어도 세 번은 봤습니다.
Python으로 eBay 판매 완료 및 종료 리스팅을 스크래핑하는 방법
이건 API 대신 스크래핑을 써야 할 이유를 가장 잘 보여주는 사례입니다. 실제로 무엇이, 얼마에, 언제 팔렸는지 보여주는 판매 완료 데이터는 시장 조사, 리셀러 가격 책정, 감정 평가의 표준 자료입니다. eBay Browse API는 이 데이터를 명시적으로 제공하지 않습니다. 가 이론상 가능하긴 하지만, 접근은 "Limited Release"이며 .
필요한 URL 파라미터는 LH_Complete=1(종료 리스팅)과 LH_Sold=1(실제로 판매된 항목만 필터링)입니다. 반드시 둘 다 넣어야 합니다. LH_Sold=1만 넣으면 일부 카테고리에서는 조용히 활성 리스팅으로 되돌아가는 경우가 있어, 커뮤니티에서 가장 흔한 실수로 꼽힙니다.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"판매 완료 페이지 {page_num} 스크래핑 중...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # 실제로 판매된 항목만 포함(초록색 POSITIVE 가격)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # 팔리지 않은 종료 리스팅은 제외
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # 판매 날짜 파싱
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldHTML에서 핵심 차이점은 판매된 항목은 가격이 초록색(.POSITIVE 래퍼 안)으로 표시되고, 팔리지 않은 종료 리스팅은 빨간색 취소선으로 보인다는 점입니다. 항상 .POSITIVE 클래스를 기준으로 필터링하세요.
eBay 스크래퍼가 깨지는 이유와, 오래 버티는 스크래퍼를 만드는 법
eBay 스크래퍼가 갑자기 멈췄다면, 혼자가 아닙니다. 제가 본 거의 모든 eBay 스크래핑 포럼 스레드에서 가장 큰 고통은 바로 이것이었습니다. 문제는 스크래퍼가 깨질지가 아니라 언제 깨질지입니다.
왜 이런 일이 생길까?
- eBay는 React 기반 렌더링과 함께 배포 때마다 바뀌는 동적 클래스명을 사용합니다.
- A/B 테스트로 서로 다른 DOM 구조를 서로 다른 사용자에게 노출합니다(지금도
s-item/s-card이중 레이아웃이 실제 예시입니다). - 주기적인 사이트 개편이 HTML 중첩 구조를 바꾸며, 데이터 자체는 그대로여도 구조가 달라집니다.
#itemTitle,#prcIsum같은 오래된 선택자는 이미 몇 년 전에 사라졌지만, 여전히 튜토리얼에 남아 있습니다.
에서도 이렇게 말합니다. "eBay 웹 스크래핑의 진짜 과제는 eBay의 CSS 선택자 변경을 처리하는 것이다. eBay는 프런트엔드를 정기적으로 업데이트해 특정 클래스명에 의존하는 스크래퍼를 깨뜨린다."
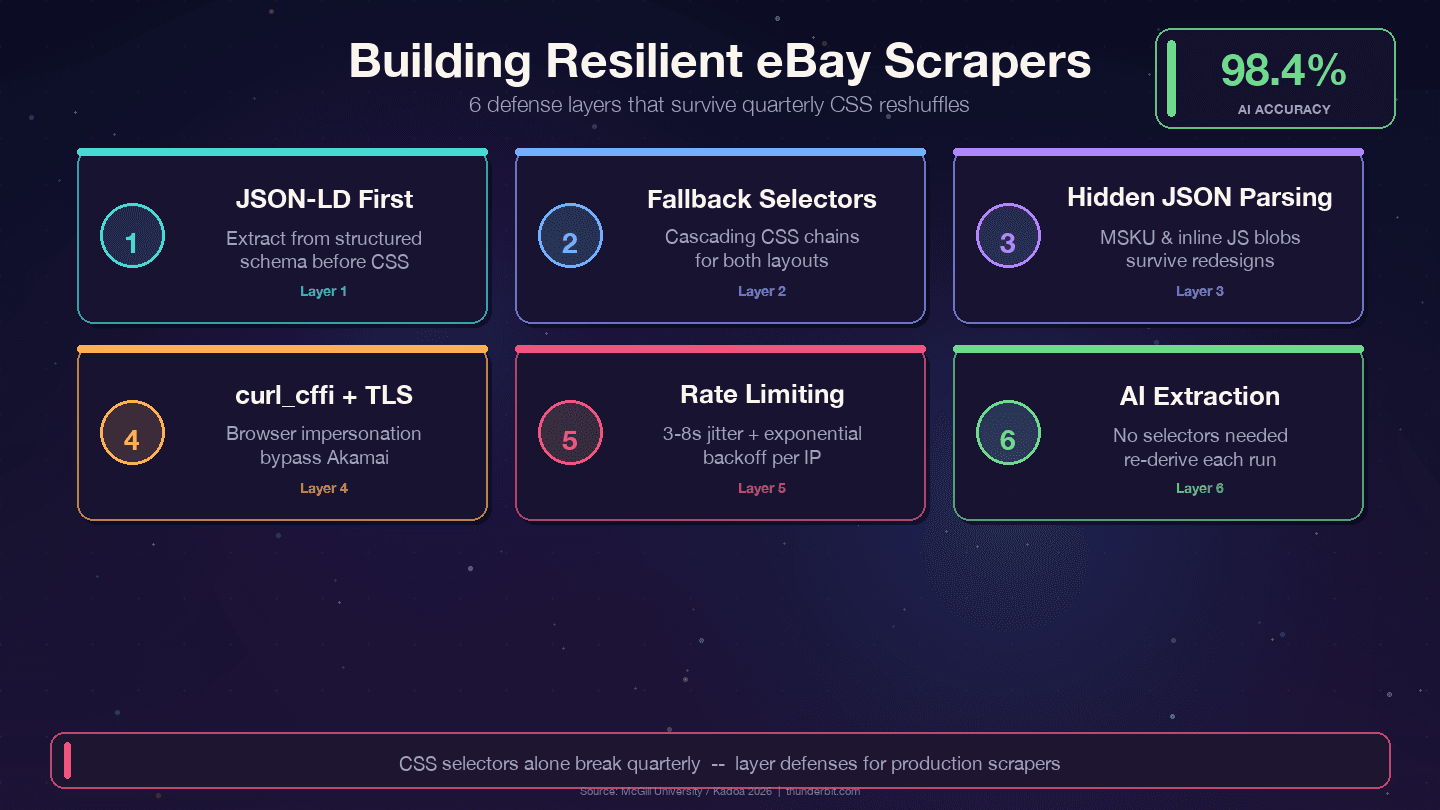
오래가는 eBay 스크래퍼를 위한 방어 전략
eBay의 분기별 구조 개편에도 버티는 네 가지 전략이 있습니다.
1. CSS 선택자보다 JSON-LD를 우선하세요. eBay는 모든 상품 페이지에 구조화된 Product 스키마 데이터를 넣습니다. 데이터 계층은 표현 계층보다 훨씬 덜 바뀝니다. 디자이너들은 분기마다 CSS 클래스를 손보지만, price, name, seller 같은 백엔드 필드명은 내부 API에 매핑돼 있어 이름이 자주 바뀌지 않습니다.
2. 계단식 폴백 선택자를 사용하세요. 단일 CSS 선택자 하나에 기대면 안 됩니다. 항상 대안을 준비하세요.
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. 숨겨진 JSON 블롭을 파싱하세요. MSKU 옵션 객체와 인라인 JavaScript 데이터는 서버 사이드에서 생성되기 때문에 CSS 변경의 영향을 덜 받습니다. <script> 태그에서 정규식으로 추출하는 방식은 초기 작업은 더 들지만, 유지보수 부담을 크게 줄입니다.
4. 선택자 실패를 기록하세요. 데이터가 비어 있다는 사실만 아는 것이 아니라, 언제 선택자가 매칭되지 않았는지 감지할 수 있도록 모니터링을 넣으세요.
1if title is None:
2 print(f"경고: {url}에서 title 선택자 실패")5. 브라우저 impersonation과 함께 curl_cffi를 사용하세요. 헤드리스 브라우저 없이도 Akamai의 TLS 지문 분석을 우회하는 데 도움이 됩니다.
AI 기반 대안: 선택자 유지보수 없이 스크래핑하기
선택자를 몇 달마다 고치는 일이 지겹다면, 완전히 다른 접근법도 있습니다. 같은 도구는 페이지를 매번 새로 읽고, 그때그때 추출 로직을 AI가 직접 도출합니다. McGill University의 연구에서는 AI 방식과 선택자 기반 스크래퍼를 3,000개 페이지에서 비교했을 때, 했으며, 업계 벤치마크에서는 고 보고합니다.
| 접근 방식 | eBay HTML이 바뀌면 깨지나? | 유지보수 노력 |
|---|---|---|
| 하드코딩된 CSS 선택자 | 예, 분기별로 | 높음 — 지속적인 패치 필요 |
| 숨겨진 JSON / JSON-LD 추출 | 드묾 | 낮음 |
| AI 기반 스크래핑(Thunderbit) | 아님 — 매번 AI가 선택자를 다시 도출 | 없음 |
Thunderbit 워크플로는 뒤에서 더 자세히 다루겠습니다. 우선 기억할 점은 이렇습니다. 몇 달 동안 돌릴 스크래퍼를 만든다면 JSON 우선 추출과 폴백 선택자에 투자하세요. 선택자 유지보수 자체를 하고 싶지 않다면 AI 방식도 충분히 고려할 만합니다.
가격 모니터링을 위해 반복적인 eBay 스크래핑 자동화하기
한 번만 스크래핑하는 것도 유용합니다. 하지만 가격 모니터링, 재고 추적, 경쟁사 분석에는 반복적인 데이터 수집이 필요합니다. 경쟁사 글들을 보면 가격 모니터링이 활용 사례로는 꼭 등장하지만, 실제 자동화 방법까지 보여주는 경우는 거의 없습니다.
옵션 1: Cron Job(Linux/macOS) 또는 작업 스케줄러(Windows)
가장 단순한 방법입니다. Python 스크립트를 cron job으로 감싸면 됩니다. cron은 최소 환경에서 실행되므로, 반드시 가상환경 Python의 절대 경로를 사용하세요.
1crontab -e
2# 매일 오전 8시 15분
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Windows에서는 PowerShell을 사용합니다.
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $T이 방식은 항상 켜져 있는 머신이 필요하고, 프록시와 봇 차단 대응도 직접 관리해야 합니다.
옵션 2: 클라우드 함수(Serverless)
AWS Lambda나 Google Cloud Functions를 쓰면 전용 서버 없이 스크래퍼를 실행할 수 있습니다. 다만 설정 난이도는 더 높습니다. 의존성을 패키징해야 하고, 타임아웃(Lambda는 최대 15분)을 처리해야 하며, 프록시 관리도 여전히 필요합니다. 대신 서버 유지보수는 없습니다.
옵션 3: Thunderbit로 노코드 예약 실행하기
의 Scheduled Scraper 기능을 사용하면 "매일 오전 8시"처럼 간단한 자연어로 간격을 지정하고, eBay URL을 넣고, 예약만 누르면 됩니다. 내장된 봇 차단 대응 기능과 함께 클라우드에서 실행됩니다.
| 접근 방식 | 설정 난이도 | 서버 필요 여부 | 봇 차단 대응 |
|---|---|---|---|
| Cron + Python 스크립트 | 중간 | 예(항상 켜진 머신) | 프록시 직접 관리 |
| 클라우드 함수(Lambda) | 높음 | 아니오(serverless) | 프록시 직접 관리 |
| Thunderbit Scheduled Scraper | 낮음(말로 설명) | 아니오(클라우드 기반) | 내장 |
반복 스크래핑 데이터를 저장할 때는 로컬 SQLite 데이터베이스가 가격 이력 관리에 가장 적합합니다. INSERT OR REPLACE는 ON CONFLICT ... DO UPDATE를 사용하세요.
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);코딩 없이 하고 싶다면? Thunderbit로 2분 만에 eBay 스크래핑하기
지금까지 Python 코드를 2,000단어 가까이 설명했습니다. 이제는 언제 Python이 굳이 필요하지 않은지 솔직하게 말씀드리고 싶습니다.
비즈니스 사용자로서 일회성 시장 조사를 하거나, 리셀러로서 비교 시세를 확인하거나, 개발 스프린트 없이 오늘 당장 데이터가 필요한 이커머스 팀이라면 Python은 과할 수 있습니다. 세팅, 선택자 유지보수, 프록시 관리까지 생각하면 "스프레드시트에 리스팅 200개만 넣으면 된다"는 작업치고는 오버헤드가 큽니다.
Thunderbit가 eBay를 스크래핑하는 방식(단계별)
- 을 설치하세요 — 신용카드가 필요 없습니다.
- Chrome에서 eBay 검색 결과나 상품 페이지로 이동합니다.
- Thunderbit 사이드바에서 **"AI Suggest Fields"**를 클릭합니다. AI가 페이지를 읽고 Title, Price, Condition, Shipping, Seller, Rating 같은 열을 제안합니다.
- **"Scrape"**를 클릭합니다. 확장 프로그램이 페이지네이션을 따라가며 데이터 테이블을 채워줍니다. eBay의 경우 Thunderbit에는 이 있어서 한 번만 클릭하면 됩니다.
- Google Sheets, Airtable, Notion, CSV, JSON, Excel로 무료 내보내기를 할 수 있습니다.
전체 과정은 2분도 채 걸리지 않습니다.
직접 재봤습니다.
하위 페이지 보강: 추가 코드 없이 상세 페이지 데이터 가져오기
검색 결과 페이지를 스크래핑한 뒤, Thunderbit는 각 리스팅의 상세 페이지를 방문해 전체 사양, 판매자 정보, 설명, 모든 이미지를 추가로 붙일 수 있습니다. 이렇게 하면 앞에서 작성한 20줄이 넘는 Python 하위 페이지 스크래핑 코드를 버튼 한 번으로 대체할 수 있습니다.
그래도 Python을 써야 하는 경우
다음과 같은 경우에는 Python이 더 유리합니다.
- 대규모 스크래핑(실행당 수만 페이지)
- 아주 세밀한 파싱 로직 또는 데이터 변환
- 기존 데이터 파이프라인(Airflow, dbt, Kafka)에 통합
- 고급 봇 대응을 위한 세밀한 TLS/세션 제어
- 단위 경제성 — 수백만 행 규모에서는 유지보수되는 스택이 크레딧 기반 SaaS보다 유리할 수 있음
대부분의 일회성 또는 중간 규모 프로젝트에서는 Thunderbit가 더 빠르고 간단합니다. 반면 대규모 프로덕션 파이프라인에서는 Python이 완전한 제어권을 제공합니다.
Python으로 eBay를 스크래핑할 때 차단을 피하는 팁
eBay의 Akamai 레이어는 실제로 존재합니다. 실전에서 효과가 있는 방법은 다음과 같습니다.
impersonate="chrome124"와 함께curl_cffi를 사용하세요 — 일반requests보다 가장 큰 개선 효과가 있습니다- 현재 브라우저 버전의 User-Agent 문자열을 순환하세요(Chrome 143, Firefox 124, Safari 26)
- 요청 사이에 3~8초의 랜덤 지연을 넣으세요() — 고정 간격은 지문이 됩니다
- 몇십 페이지를 넘는 작업이라면 레지덴셜 또는 로테이팅 프록시를 사용하세요. AWS, GCP, DigitalOcean 같은 데이터센터 IP는 Akamai에 빠르게 걸립니다.
- robots.txt를 존중하세요 — 대부분의 필터링된 browse URL은 명시적으로 Disallow되어 있지만, 상품 상세 페이지(
/itm/<id>)는 아닙니다 - CAPTCHA에 우아하게 대응하세요 — 감지되면 다른 IP로 재시도하거나 CAPTCHA 해결 서비스를 사용하세요
- 서버를 두드리지 마세요. 판례는 실제로 서버 성능을 떨어뜨리는 스크래핑에 대해 trespass to chattels가 적용될 수 있음을 보여줍니다. IP당 1초 1회 수준을 지키면 그 기준과는 한참 거리가 있습니다.
대규모 상업적 사용이라면 활성 리스팅에는 Browse API를, 판매 완료 비교자료와 API 미노출 데이터에는 타깃 스크래핑만 사용하는 하이브리드 접근이 더 깔끔합니다. 기술적으로도, 법적으로도 더 낫습니다.
Python으로 eBay를 스크래핑하는 건 합법일까?
저는 변호사가 아니며, 이 글은 법률 자문이 아닙니다. 그래서 간단히만 말씀드리겠습니다.
공개 데이터 스크래핑에 유리한 방향으로 법적 환경은 바뀌고 있습니다. 핵심 판례는 다음과 같습니다.
- (제9순회항소법원, 2022): 공개적으로 접근 가능한 데이터를 스크래핑해도 CFAA 위반이 아님
- Van Buren v. United States(미 연방대법원, 2021): CFAA의 "허가된 접근을 초과했다"는 조항을 좁게 해석
- (캘리포니아 북부지방법원, 2024): 로그인하지 않은 상태의 스크래핑은 스크래퍼가 "사용자"가 아니므로 플랫폼 약관 위반이 아님
다만 eBay의 는 "대신 구매 에이전트, LLM 기반 봇, 또는 인간 검토 없이 주문을 시도하는 엔드투엔드 흐름"을 명시적으로 금지합니다. 선은 분명합니다. 공개 페이지의 읽기 전용 스크래핑은 비교적 안전한 영역이지만, 결제를 자동화하는 것은 아닙니다.
실무적으로는 공개적으로 보이는 데이터만 스크래핑하고, 가짜 계정을 만들거나 로그인 벽을 우회하지 말고, 저작권이 있는 리스팅 이미지를 무단으로 대량 재판매하지 말아야 합니다. 상업 규모 프로젝트라면 법률 전문가와 상의하세요.
결론 및 핵심 요약
Python은 eBay를 스크래핑하는 데 가장 유연한 방법이지만, 사이트 HTML이 바뀌는 만큼 지속적인 유지보수가 필요합니다. 선택 기준은 다음과 같습니다.
- 활성 리스팅에 대한 안정적이고 중간 규모의 구조화된 조회에는 eBay Browse API를 사용
- 판매 완료 리스팅, 리뷰, 옵션 데이터, API가 노출하지 않는 정보에는 Python 스크래핑을 사용
- 코드를 작성하거나 유지보수하고 싶지 않다면 를 사용
이 가이드의 코드는 복원력을 우선합니다. JSON-LD를 먼저 추출하고, 그다음 CSS 폴백을 적용하며, 옵션은 숨겨진 JSON을 파싱하는 식입니다. 이렇게 계층화하면 eBay 프런트엔드 팀이 리디자인을 배포하더라도 스크래퍼가 쉽게 죽지 않습니다.
노코드 방식을 시험해보고 싶다면 으로 지금 바로 eBay 페이지에서 테스트할 수 있습니다. 그리고 이 어떻게 동작하는지 보고 싶다면, 클릭 한 번이면 됩니다.
웹 스크래핑 도구에 대해 더 알고 싶다면 , , 가이드를 참고해보세요. 에서도 튜토리얼을 확인할 수 있습니다.
FAQ
1. Python으로 eBay를 무료로 스크래핑할 수 있나요?
네. Requests, BeautifulSoup, curl_cffi, pandas 같은 라이브러리는 모두 무료 오픈소스입니다. 비용은 대규모에서 발생합니다. 고용량 스크래핑용 레지덴셜 프록시는 대역폭에 따라 보통 월 $50~500 정도 듭니다. 소규모 프로젝트(수백 페이지 수준)라면 속도 제한만 조심하면 집 IP로도 스크래핑할 수 있습니다.
2. Python으로 eBay 판매 완료 및 종료 리스팅을 어떻게 스크래핑하나요?
검색 URL 파라미터에 LH_Complete=1&LH_Sold=1를 추가하세요. 두 개를 모두 넣어야 합니다. LH_Sold=1만 넣으면 일부 카테고리에서 조용히 활성 리스팅으로 되돌아갑니다. 실제 판매 여부를 나타내는 가격 요소의 .POSITIVE CSS 클래스를 확인해 결과를 필터링하세요.
3. eBay는 웹 스크래핑을 차단하나요?
eBay는 Akamai Bot Manager를 사용하며, 주로 TLS 지문과 행동 분석으로 스크래퍼를 탐지합니다. 일반 requests 호출은 403 응답을 받는 경우가 많습니다. 브라우저 impersonation이 가능한 curl_cffi, User-Agent 순환, 요청 사이 3~8초 랜덤 지연을 사용하면 대부분의 차단을 우회할 수 있습니다. 대규모 작업에는 레지덴셜 프록시가 도움이 됩니다.
4. eBay API와 웹 스크래핑 중 무엇을 써야 하나요?
활성 리스팅에 대한 안정적이고 중간 규모의 조회에는 Browse API를 사용하세요(하루 최대 5,000회 호출). 판매 가격 이력, 전체 옵션/MSKU 데이터, 리뷰, 또는 API가 제공하지 않는 필드가 필요하면 스크래핑을 사용하세요. Marketplace Insights API가 이론상 판매 완료 데이터를 제공하지만, 접근이 제한적이고 .
5. 코딩 없이 eBay를 스크래핑하는 가장 쉬운 방법은 무엇인가요?
은 AI가 eBay 페이지를 읽고, 데이터 열을 제안하고, 한 번의 클릭으로 리스팅을 추출합니다. 페이지네이션, 하위 페이지 보강, Google Sheets·Excel·Airtable·Notion 내보내기를 지원합니다. 미리 만들어진 을 사용하면 더 빠릅니다.
더 알아보기