요약
는 정책 질문을 던졌습니다. 전 세계에서 가장 많이 방문되는 웹사이트들 중 얼마나 많은 곳이 AI 크롤러에게 무엇을 할 수 있고 무엇을 할 수 없는지 알려주고 있을까요?
이번 후속편은 그 뒤에 있는 운영 질문을 묻습니다. 지금 정책을 실어 나르라고 요구받고 있는 인프라로서 robots.txt는 얼마나 신뢰할 수 있을까요?
답은 편하지 않습니다. robots.txt는 여전히 공개되어 있고, 비용이 적게 들며, 기계가 읽을 수 있고, 크롤러도 이미 이해하고 있기 때문에 작동합니다. 동시에 원래 설계된 범위를 훨씬 넘어서는 역할까지 맡고 있습니다. 2026년의 같은 일반 텍스트 파일 안에는 SEO 크롤링 제어, 사이트맵 인덱스, 오래된 검색엔진 확장 규칙, AI 학습 제외 설정, Cloudflare가 주입한 정책 어휘, 저작권 유보 문구, 그리고 향후 분쟁을 염두에 둔 법적 표현이 함께 들어갈 수 있습니다.
그건 설정 부채입니다.
이 리포트의 데이터셋은 원래 AI 크롤러 연구에서 사용한 Tranco Top 10,000 크롤과 동일합니다. 10,000개 도메인 중 6,638개가 읽을 수 있는 robots.txt를 반환했고, 추가로 610개는 404를 반환했는데 프로토콜상 이는 암묵적 허용으로 처리됩니다. 이를 통해 봇 접근 결정에 대해 분석 가능한 사이트는 7,248개, 설정 복잡도 분석을 위한 실제 파일은 6,638개가 되었습니다.
두드러지는 발견은 여섯 가지입니다.
-
대부분의
robots.txt는 작지만, 긴 꼬리는 극도로 복잡합니다. 중앙값 파일은 겨우 834바이트, 31줄입니다. 하지만 1,005개 파일은 최소 5KB, 273개는 최소 20KB, 28개는 최소 100KB입니다. 샘플에서 가장 큰 파일은 248KB입니다. -
상위 웹사이트 수백 곳은 정책 메모라기보다 운영 설정 파일에 가까운 파일을 돌리고 있습니다. 중앙값 파일에는
Disallow지시문이 9개입니다. 하지만 707개 사이트는Disallow규칙이 최소 100개, 13개는 최소 1,000개이며, 240개는 사용자 에이전트를 최소 50개, 110개는 최소 100개까지 명시합니다. -
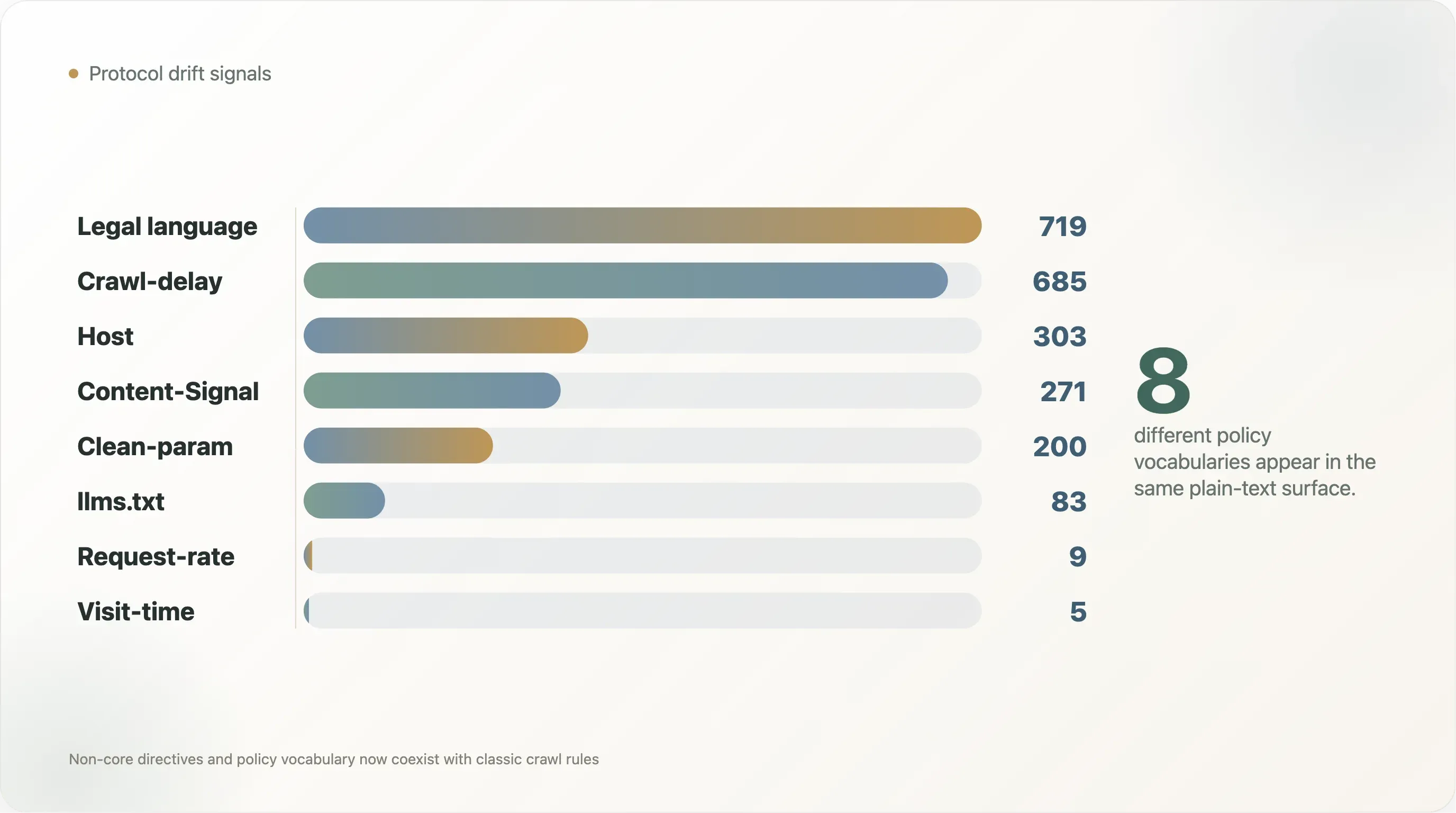
프로토콜 드리프트는 이론이 아닙니다. 읽을 수 있는 6,638개 파일 중 685개에는
Crawl-delay, 303개에는Host, 200개에는Clean-param, 9개에는Request-rate, 5개에는Visit-time, 271개에는 Cloudflare식Content-Signal문구가 있습니다. 이 모든 것이 같은 깨끗한 표준의 일부는 아닙니다. 누적된 크롤러 관습입니다. -
Googlebot은 특별 대우를 받습니다. 분석 가능한 562개 도메인이 적어도 하나의 전통적인 검색 크롤러를 차단합니다. 그중 404건에서는 Googlebot은 허용하면서 다른 최소 하나의 검색 크롤러를 차단합니다. AI 크롤러 차별은 중립적인 생태계에서 갑자기 등장한 것이 아니었습니다.
robots.txt는 이미 검색엔진 위계를 인코딩하고 있었습니다. -
AI 정책은 그 부채를 더 분명하게 드러냅니다. 읽을 수 있는 파일 1,377개에는 AI 정책 언어가 들어 있고, 719개에는 저작권, 이용약관, 라이선스, 허가 관련 문구가 있으며, 501개에는 둘 다 들어 있습니다. 이 파일은 기계 인터페이스이자 법적 문서가 되었습니다. 유용하지만 취약합니다.
-
가장 위험한 파일이 항상 가장 반(反)AI적인 파일은 아닙니다. 이커머스, 여행, 소셜, 금융, 학계, 뉴스는 각기 다른 이유로 복잡한 파일을 만듭니다. 크롤 예산 제어, 오래된 경로, 사용자 생성 콘텐츠, 권리 유보, 봇별 예외 때문입니다. AI 규칙은 이미 복잡해진 기반 위에 더해지고 있습니다.
핵심 결론은 이렇습니다. robots.txt는 여전히 공개 웹에서 가장 중요한 크롤러 정책 접점이지만, 크롤러 신원, AI 사용 어휘, 정책 감사 가능성을 표준화하지 않는 한 고위험 AI 거버넌스를 떠받치기에는 약한 기반입니다.
방법론
이 리포트는 Tranco Top 10,000 도메인에 대한 AI 크롤러 정책의 원래 Thunderbit 분석 데이터셋을 재사용합니다.
입력 자료는 다음과 같습니다.
tranco_top10k.csv— 원본 Tranco Top 10K 도메인 목록out/fetch_meta.csv— 가져오기 상태, 바이트 수, 스킴, 리디렉션 결과, 오류 메타데이터out/sites.csv— 도메인, 순위, 카테고리, 언어,robots.txt상태out/site_meta.csv— 템플릿 클래스, AI 차단 플래그, 파일 크기, 봇 정책 요약 필드를 포함한 사이트별 분석 행out/bot_status.csv— 도메인과 크롤러별 행으로, 해당 봇이 차단되는지와 특정 규칙이 존재하는지 포함raw_robots/— 상태200을 반환한 6,638개 사이트의 캐시된robots.txt본문
이번 후속 분석에서는 읽을 수 있는 각 robots.txt 파일을 다음 항목으로 스캔했습니다.
- 파일 크기와 줄 수
- 활성 비주석 줄
User-agent,Disallow,Allow,Sitemap지시문 개수Crawl-delay,Host,Clean-param,Request-rate,Visit-time같은 레거시 또는 비핵심 지시문Content-Signal,llms.txt, AI, LLM, 머신러닝, TDM,2019/790같은 AI 시대 어휘- copyright, terms of service, licensing, permission, rights-reservation 같은 법적 어휘
- Googlebot, Bingbot, DuckDuckBot, Slurp, Baiduspider, YandexBot에 대한 검색 크롤러 처리 방식
또한 triage를 위한 간단한 설정 부채 점수도 정의합니다. 이 점수는 파일 크기, 사용자 에이전트 수, Disallow 수, Allow 수, 비표준 지시문 수, 그리고 AI 정책 언어와 법적 언어의 혼합을 결합합니다. 이 점수는 보편적인 정답성 척도로 의도된 것이 아닙니다. 유지, 검토, 추론이 어려울 가능성이 높은 파일을 찾기 위한 방법입니다.
모든 파생 표와 차트는 전달 폴더에 포함되어 있습니다.
발견 1: 중앙값 파일은 단순하지만, 꼬리는 단순하지 않습니다
상위 웹에서 일반적인 robots.txt 파일은 여전히 작습니다.
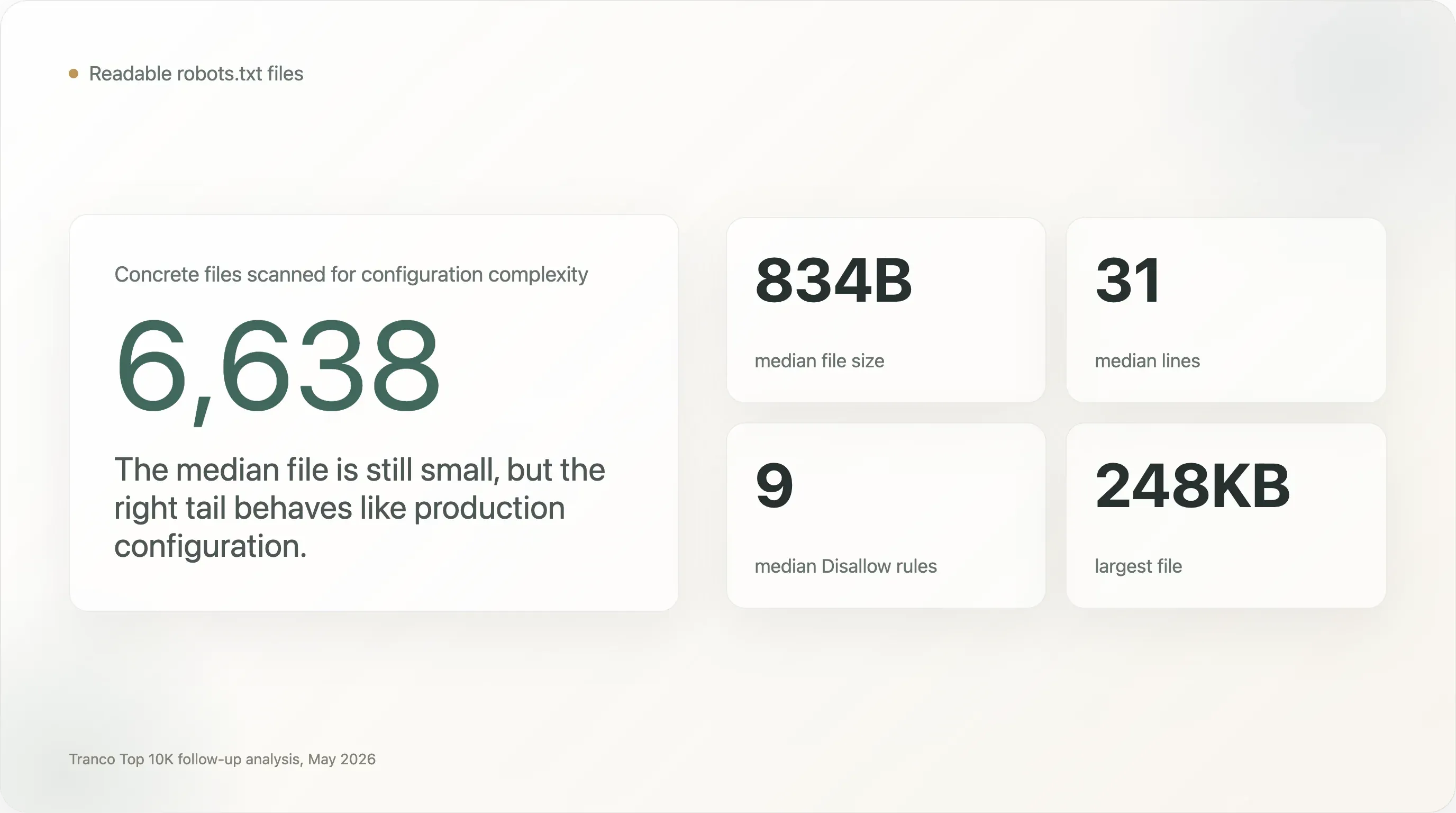
읽을 수 있는 6,638개 파일 전체에서:
| 지표 | 중앙값 | P90 | P95 | P99 | 최대값 |
|---|---|---|---|---|---|
| 파일 크기 | 834바이트 | 6.7KB | 15.8KB | 76.0KB | 248.3KB |
| 줄 수 | 31 | 238 | 332 | 1,008 | 4,998 |
| 활성 줄 수 | 23 | 198 | 282 | 837 | 4,998 |
User-agent 지시문 | 1 | 21 | 39 | 137 | 823 |
Disallow 지시문 | 9 | 103 | 176 | 422 | 4,997 |
Allow 지시문 | 1 | 17 | 33 | 69 | 890 |
이 분포가 중요한 이유는 robots.txt가 종종 작은 선언문처럼 이야기되기 때문입니다.
1User-agent: *
2Disallow: /private/그런 정신적 모델은 트래픽이 많은 웹의 의미 있는 일부에는 맞지 않습니다.
이번 데이터셋에서:
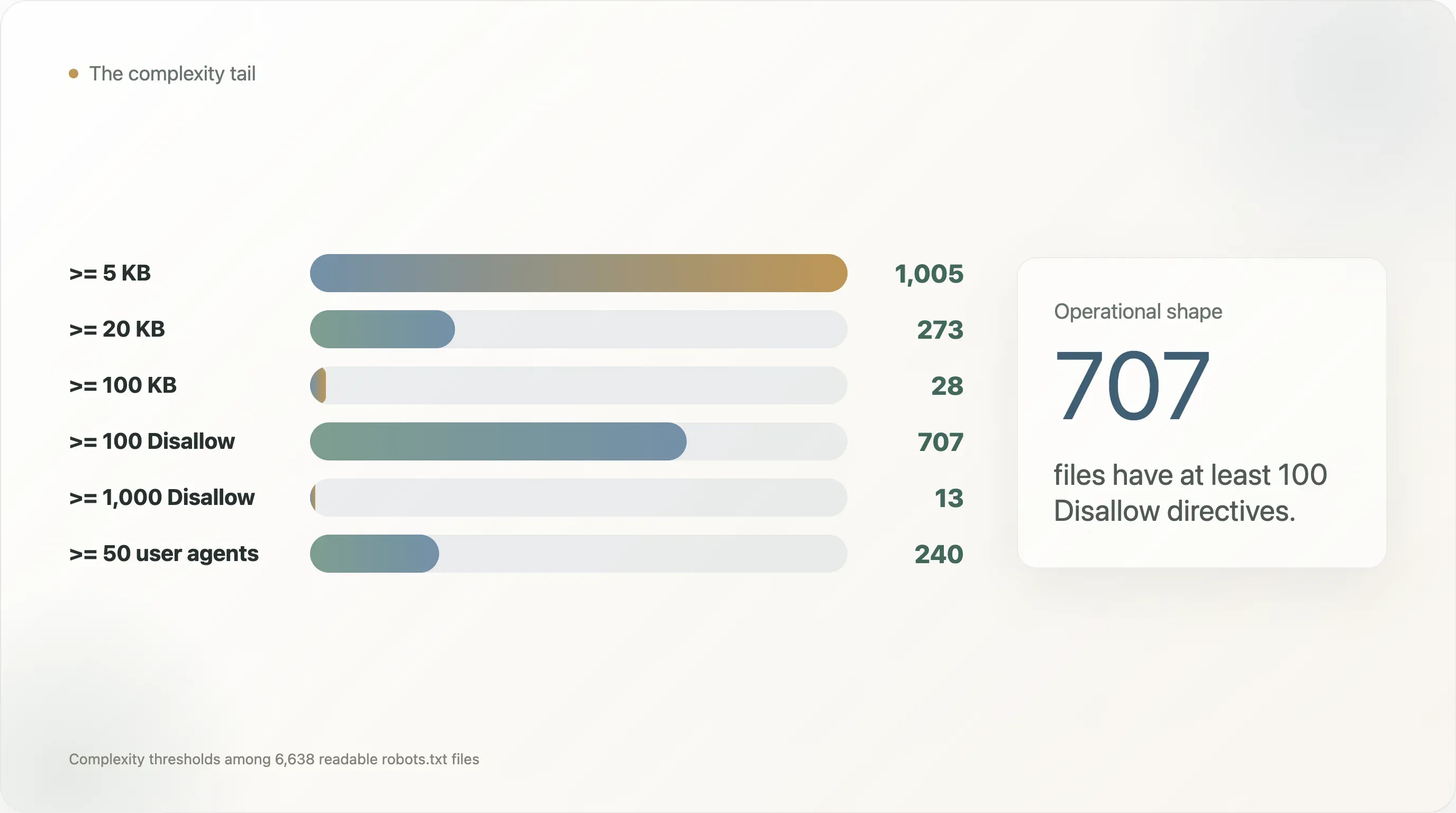
| 복잡도 기준 | 사이트 수 |
|---|---|
robots.txt가 5KB 이상 | 1,005 |
| 20KB 이상 | 273 |
| 100KB 이상 | 28 |
User-agent 지시문이 최소 50개 | 240 |
User-agent 지시문이 최소 100개 | 110 |
Disallow 지시문이 최소 100개 | 707 |
Disallow 지시문이 최소 1,000개 | 13 |
Allow 지시문이 최소 100개 | 40 |
가장 크고 복잡한 파일이 학술적 호기심거리에 그치지는 않습니다. 실제로 트래픽이 큰 서비스들의 것입니다.
| 도메인 | 순위 | 카테고리 | 바이트 | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | 소셜 | 114,341 | 76 | 4,184 | 281 |
runescape.com | 5,226 | 알 수 없음 | 113,393 | 1 | 4,997 | 0 |
academia.edu | 832 | 학계 | 57,384 | 63 | 2,044 | 227 |
etsy.com | 286 | 이커머스 | 51,320 | 3 | 1,621 | 120 |
thepaper.cn | 9,395 | 뉴스 | 56,867 | 1 | 1,496 | 0 |
opentable.com | 4,137 | 알 수 없음 | 70,494 | 32 | 1,683 | 176 |
alfabank.ru | 2,625 | 금융 | 73,158 | 2 | 1,566 | 133 |
이런 파일은 정책 구호라기보다 운영 라우팅 테이블에 가깝습니다. 여러 해의 제품 출시, 오래된 경로, 차단된 매개변수 패턴, 크롤러 예외, SEO 실험, CDN 결정, 그리고 이제는 AI 크롤러 규칙까지 인코딩합니다.
긴 꼬리는 AI 이야기만은 아닙니다. 20KB 이상인 273개 파일 중 131개는 AI 정책 언어를 포함하고, 142개는 그렇지 않습니다. Disallow 지시문이 100개 이상인 707개 파일 중 AI 정책 언어를 포함한 것은 207개뿐입니다. 즉, AI가 대용량 파일 문제를 만든 것이 아닙니다. 오래된 일반 웹 운영이 이미 경로 규칙, 사이트맵 참조, 크롤러 예외로 파일을 채워 놓은 뒤 AI가 들어온 것입니다.
유지보수성은 의도만이 아니라 형태에 달려 있기 때문에 이 점이 중요합니다. 직접적인 AI 차단이 들어간 작은 파일은 감사하기 쉽습니다. 70KB짜리 이커머스나 여행 파일은 AI에 대해 아무 말이 없더라도 감사하기 어려울 수 있습니다. 위험은 큰 파일이 모두 잘못됐다는 데 있지 않습니다. 실제 정책이 그것을 책임지는 사람들이 확인하기엔 너무 복잡해질 수 있다는 데 있습니다.
운영상의 위험은 간단합니다. robots.txt가 커질수록 발행자, 플랫폼 엔지니어, 법무 담당, SEO 리드가 기본 질문에 답하기 어려워집니다. 이 파일은 실제로 무엇을 허용하는가?
그 질문은 이제 전혀 사소하지 않습니다. RFC식 파싱에서는 크롤러가 User-agent: *보다 더 구체적인 사용자 에이전트 그룹을 매칭할 수 있고, 더 긴 경로 일치가 더 짧은 경로를 덮어쓸 수 있으며, Allow와 Disallow 지시문은 우선순위로 상호작용하고, 일반적인 전면 차단 규칙은 파일이 작성되었을 당시에는 존재하지 않았던 새 크롤러를 실수로 포착할 수 있습니다.
30줄 파일이라면 사람이 그걸 이해할 수 있습니다. 수십 개의 명명된 봇이 있는 4,000줄 파일이라면 아무도 그래서는 안 됩니다.
발견 2: robots.txt는 크롤링 규칙보다 더 많은 것을 담고 있습니다
AI 크롤러 논쟁은 robots.txt를 정치적으로 가시적인 대상으로 만들었지만, 그 기반이 된 파일은 이미 서로 무관한 책임을 축적하고 있었습니다.
현대적인 상위 사이트의 robots.txt에는 다음이 들어갈 수 있습니다.
- 크롤러 경로 제어
- 사이트맵 발견
- 검색엔진 전용 확장
- 크롤 속도 힌트
- 호스트 정규화 힌트
- URL 매개변수 정리 힌트
- CDN이 주입한 정책 어휘
- 저작권 유보 문구
- AI 학습 제외 설정
- 사람이 읽을 수 있는 법적 설명
데이터셋은 이 층위를 분명하게 보여줍니다.
| 신호 | 파일 수 | 읽을 수 있는 파일 대비 비율 |
|---|---|---|
Crawl-delay | 685 | 10.3% |
Host | 303 | 4.6% |
Clean-param | 200 | 3.0% |
Content-Signal | 271 | 4.1% |
Request-rate | 9 | 0.1% |
Visit-time | 5 | 0.1% |
llms.txt 언급 | 83 | 1.3% |
| copyright, terms, licensing, 또는 permission 언어 | 719 | 10.8% |
| AI 정책 언어 | 1,377 | 20.7% |
이 지시문들 중 일부는 특정 크롤러가 널리 인식합니다. 일부는 오래된 관행입니다. 일부는 벤더 전용입니다. 일부는 실제로 크롤러 지시문이라기보다 주석에 들어간 법적 또는 제품 언어입니다.
그게 바로 프로토콜 드리프트의 모습입니다.
Crawl-delay는 좋은 예입니다. 많은 사이트 운영자에게 익숙하지만, 주요 크롤러들 사이에서 지원은 고르지 않습니다. Host와 Clean-param은 역사적으로 Yandex 동작과 연관되어 왔습니다. Content-Signal은 Cloudflare의 AI 시대 정책 어휘의 일부입니다. llms.txt는 보편적으로 존중되는 표준이 아니라, 인접한 발견 형식으로 제안된 것입니다. 그런데도 이 모든 것이 같은 종류의 파일에, 종종 전통적인 User-agent와 Disallow 규칙 옆에 함께 들어갑니다.
숫자는 오래된 관행과 새로운 관행이 이제 공존한다는 점도 보여줍니다. Crawl-delay는 685개 파일에 나타나며, 이는 Content-Signal이 있는 271개 파일의 두 배가 넘습니다. Host는 303개, Clean-param은 200개 파일에 나타나며 대부분 검색 시대의 관행을 반영합니다. AI 검색계에서 많이 논의되는 llms.txt는 읽을 수 있는 파일 중 83개에서만 언급됩니다. 실제 웹은 하나의 어휘로 수렴하고 있지 않습니다. 어휘들을 쌓고 있습니다.
문제는 개별 확장 하나하나가 틀렸다는 데 있지 않습니다. 문제는 이 파일이 여러 겹치는 거버넌스 체계를 담는 버전 관리 없는 컨테이너가 되었다는 점입니다.
그 결과 세 가지 부채가 생깁니다.
- 의미 부채. 서로 다른 크롤러가 같은 파일을 다르게 해석할 수 있습니다.
- 소유 부채. SEO, 법무, 인프라, 보안, 제품 팀이 모두 파일을 수정할 이유가 있지만, 전체 정책을 책임지는 단일 팀은 없을 수 있습니다.
- 감사 부채. 사이트는 의도적으로 작성된 것처럼 보이는 정책을 공개하지만, 실제 동작은 파서만 결정할 수 있습니다.
AI가 이를 더 중요하게 만드는 이유는 이해관계가 달라졌기 때문입니다. 오래된 크롤 속도 힌트가 무시되면 결과는 추가 트래픽일 수 있습니다. 하지만 AI 학습 제외가 모호하면 저작권이나 라이선스 분쟁의 증거가 될 수 있습니다.
발견 3: 파일은 기계 인터페이스이자 법적 문서가 되었습니다
원래 AI 크롤러 리포트는 분석 가능한 사이트의 17.0%가 명시적인 AI 전용 규칙을 작성했다고 보여주었습니다. 이번 후속편은 그 정책들이 추가하는 텍스트 부담을 살펴봅니다.
읽을 수 있는 robots.txt 파일 6,638개 중:
- 1,377개는 AI 정책 언어를 포함합니다.
- 719개는 copyright, terms, licensing, rights, 또는 permission 언어를 포함합니다.
- 271개는
Content-Signal을 포함합니다. - 83개는
llms.txt를 언급합니다.
겹침이 생기는 지점에서 이야기가 더 흥미로워집니다.
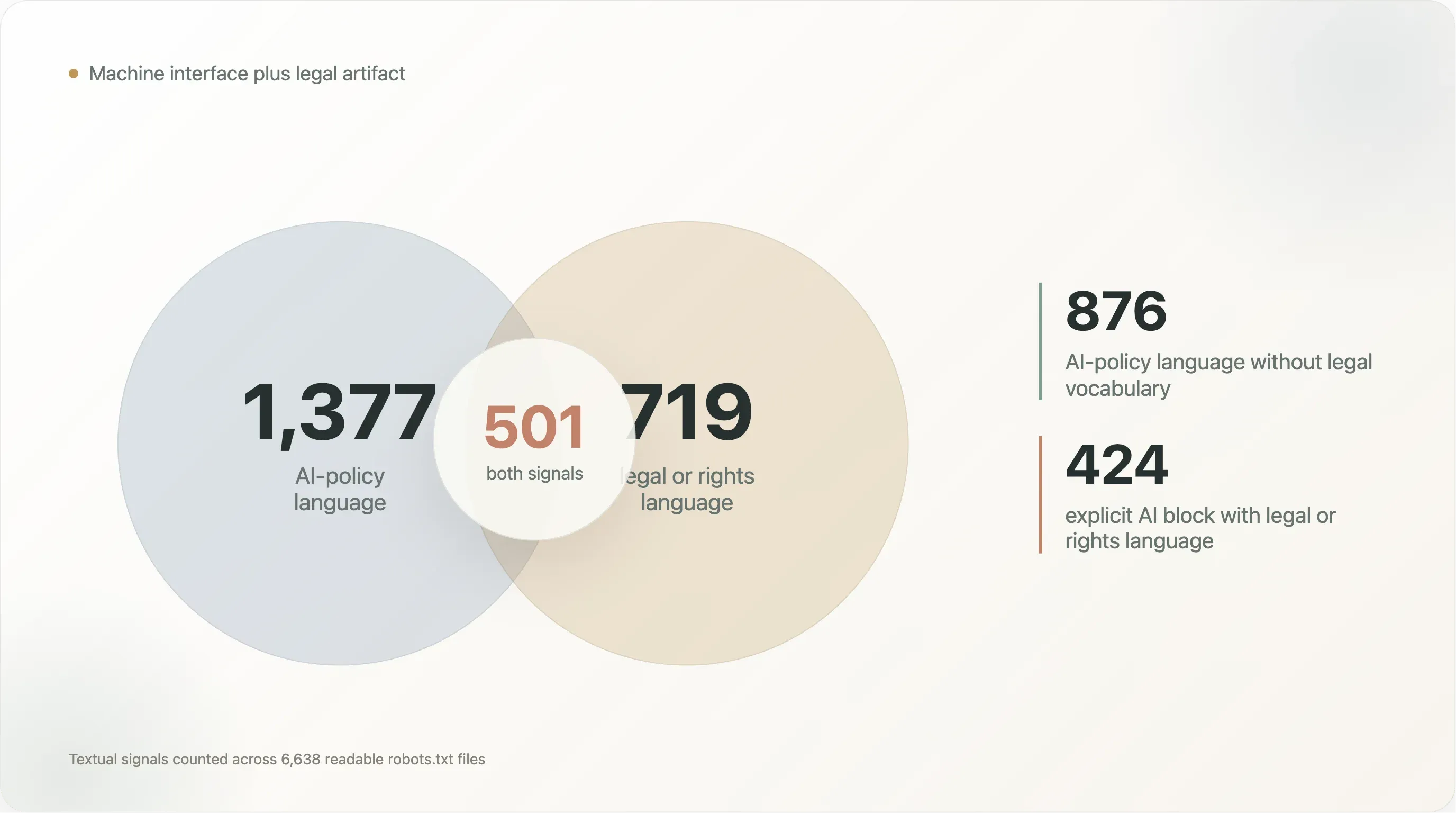
| 텍스트 패턴 | 파일 수 |
|---|---|
| AI 정책 언어와 법적/권리 언어를 모두 포함 | 501 |
| AI 정책 언어는 있지만 법적/권리 언어는 없음 | 876 |
| 법적/권리 언어는 있지만 AI 정책 언어는 없음 | 218 |
법적/권리 언어가 포함된 Content-Signal | 242 |
| 명시적 AI 차단과 법적/권리 언어 | 424 |
이건 새로운 종류의 파일입니다.
전통적인 robots.txt는 크롤러를 향합니다. 법적 서문이 들어간 robots.txt는 최소 네 가지 대상을 동시에 향합니다.
- 기계 판독 가능한 지시문이 필요한 크롤러 운영자
- 정책 신호가 필요한 검색 및 AI 벤더
- 권리 유보를 명시하고 싶은 변호사
- 주석을 의도 증거로 읽을 수 있는 미래의 감사인, 법원, 기자
이처럼 여러 대상을 염두에 둔 설계는 일부 파일이 정책 문서처럼 읽히는 이유를 설명합니다. 그러나 동시에 크롤러가 파싱할 수 있는 것과 인간 법무 담당이 선언하고 싶은 것 사이의 깔끔한 분리를 약화시킵니다.
AI 정책 언어는 있지만 법적 어휘는 없는 876개 파일은 주로 기계 정책 파일입니다. 봇 이름, Disallow 차단, 템플릿 언어가 중심입니다. AI와 법적 언어를 모두 포함한 501개 파일은 다릅니다. 크롤러 지시와 권리 유보를 동시에 하려는 것입니다. 법적 언어는 있지만 AI 어휘는 없는 218개 파일은 이 패턴이 LLM으로 시작된 것이 아님을 보여줍니다. robots.txt는 이미 약관, 허용 범위, 권리 주장를 적는 장소로 사용되고 있었습니다.
예를 들어 주석에는 머신러닝이 금지된다고 적혀 있지만 실제 지시문 블록은 알려진 일부 사용자 에이전트만 차단할 수 있습니다. 사이트는 전반적인 권리를 주장하면서도 몇몇 크롤러만 이름으로 적을 수 있습니다. CDN 템플릿이 운영자가 직접 작성하지 않은 법적 문구에 AI 관련 어휘를 주입할 수도 있습니다. 사이트는 광범위한 User-agent: * 규칙을 작성해 미래 크롤러를 의도치 않게 차단할 수도 있습니다.
거버넌스 관점에서 robots.txt는 공개되어 있고 기계가 읽을 수 있기 때문에 특히 매력적입니다. 하지만 담는 정책이 많아질수록 한계도 더 중요해집니다.
- 특정 정책이 권리자에 의해 검토된 것인지, 아니면 인프라에서 물려받은 것인지 증명하는 인증 계층이 없습니다.
- 기본 버전 기록이 없습니다.
- 학습, 검색, 인덱싱, 요약, 캐시, 모델 평가처럼 의도된 사용을 위한 구조화된 필드가 없습니다.
- AI 크롤러 신원에 대한 보편적인 등록부가 없습니다.
- 집행 메커니즘이 없습니다.
이것이 파일을 쓸모없게 만들지는 않습니다. 다만 취약하게 만들 뿐입니다.
더 나은 해석은 robots.txt가 공적 통지 계층이 되어가고 있다는 것입니다. 선호와 의도를 공개적으로, 검토 가능하게 선언하는 층입니다. 그 자체로 완전한 권리 관리 시스템은 아닙니다.
발견 4: AI가 오기 전에도 검색은 이미 불평등했습니다
원래 리포트의 가장 강한 발견 중 하나는 많은 발행자가 AI 학습 크롤러와 검색 크롤러를 구분한다는 점이었습니다. CCBot, GPTBot, Google-Extended는 차단하면서 Google 검색 가시성은 유지합니다.
이번 후속편은 다른 점을 더합니다. 전통적인 검색 크롤러도 서로 동등하게 취급되지는 않습니다.
다음 여섯 검색 크롤러를 확인했습니다.
- Googlebot
- Bingbot
- DuckDuckBot
- Slurp
- Baiduspider
- YandexBot
분석 가능한 7,248개 사이트 전체에서:
| 검색 크롤러 처리 | 사이트 수 |
|---|---|
| 적어도 하나의 검색 크롤러를 차단 | 562 |
| Googlebot은 허용하지만 다른 최소 하나의 검색 크롤러는 차단 | 404 |
| 확인한 여섯 검색 크롤러를 모두 차단 | 152 |
차단된 봇 수는 고르게 분포하지 않습니다.
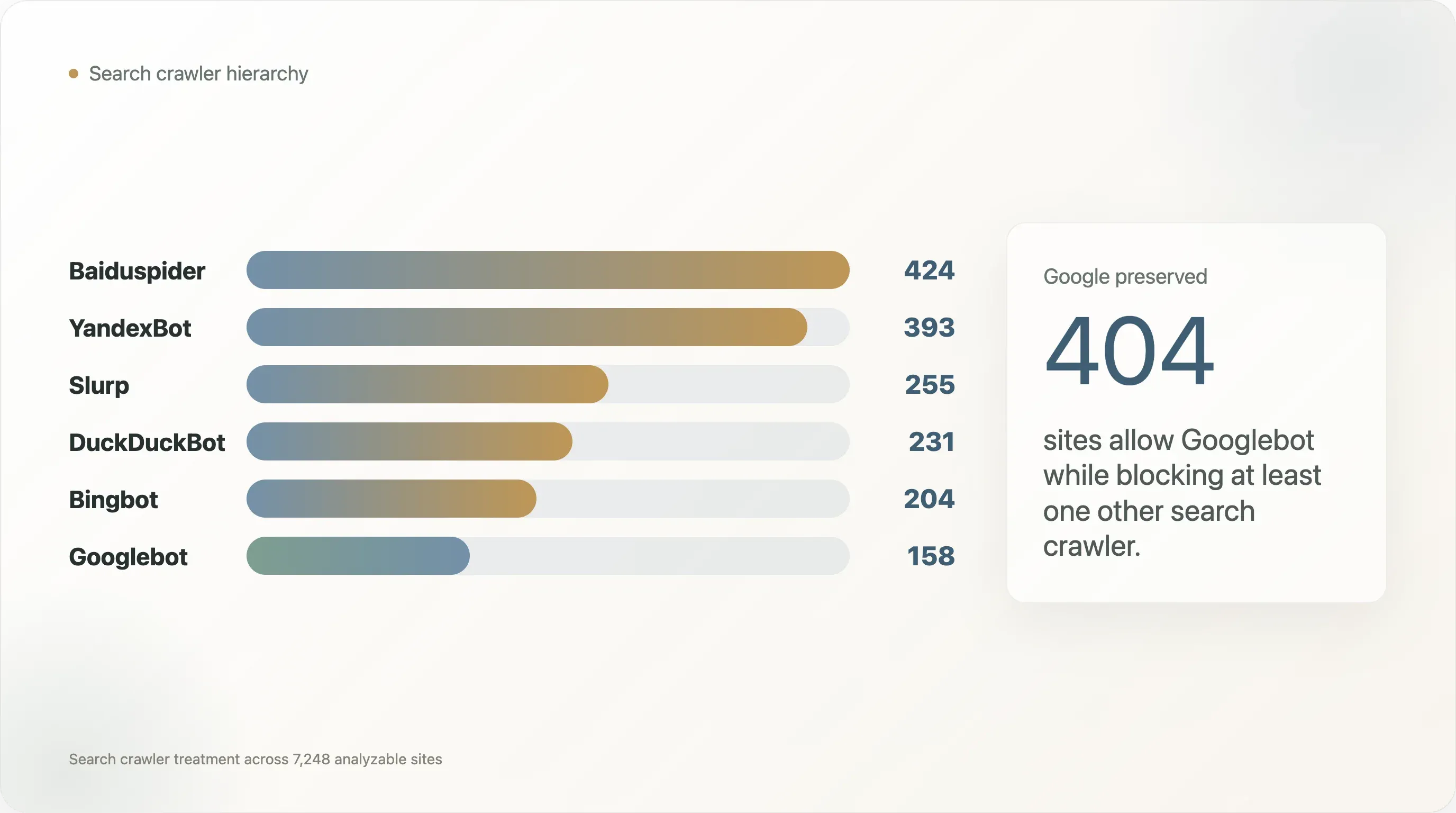
| 검색 크롤러 | 차단한 사이트 수 |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
이 집합에서 Googlebot은 가장 적게 차단된 크롤러입니다. Baiduspider와 YandexBot은 훨씬 더 자주 차단되며, 그런 경우의 대부분에서도 Googlebot은 허용됩니다. Googlebot은 허용하면서 다른 검색 크롤러를 차단하는 404개 사이트 중 269개는 Baiduspider를, 240개는 YandexBot을 차단합니다.
대표 사례도 있습니다.
| 도메인 | Googlebot은 허용하면서 차단한 검색 크롤러 |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
이 점이 AI 논쟁에서 중요한 이유는, LLM 크롤러가 오기 전에도 robots.txt가 중립적인 보편 접근 프로토콜이 아니었음을 보여주기 때문입니다. 공개 웹에는 이미 위계가 있었습니다.
- Google 검색 트래픽은 너무 소중해서 위험을 감수하기 어렵기 때문에 Googlebot은 자주 보존됩니다.
- 지역 크롤러나 경쟁사 크롤러는 더 쉽게 차단됩니다.
- 일부 사이트는 검색 크롤러 접근을 시장별 또는 벤더별 결정으로 다룹니다.
AI 크롤러는 이미 차등 접근이 일반적인 생태계에 들어왔습니다.
그래서 정책 전환을 이해하기가 쉬워집니다. Google-Extended는 차단하고 Googlebot은 허용한다고 쓰는 발행자는 새로운 형태의 차별을 발명하는 것이 아닙니다. 오래된 패턴을 새로운 크롤러 범주에 적용하는 것입니다. 배포는 유지하고, 추출은 제한합니다.
남은 질문은 이 오래된 패턴이 얼마나 확장될 수 있느냐입니다. 검색 시대에는 경제적으로 중요한 크롤러가 몇 개 안 됐습니다. AI 시대에는 크롤러 신원이 모델 벤더, 검색/검색보조 봇, 데이터 중개업자, 학술 크롤러, 합성 브라우저 에이전트, 인프라 수준의 fetcher로 파편화되어 있습니다. 목적 기반 신호의 수가 더 작은 집합으로 통합되지 않는 한, 명명된 사용자 에이전트는 계속 늘어날 것입니다.
그게 설정 부채가 누적되는 방식입니다.
발견 5: 복잡도는 섹터별로 다르지만, AI 차단율이 갈리는 방식과는 다릅니다
원래 리포트는 AI 차단에서 큰 섹터 차이를 보여주었습니다. 뉴스는 높은 비율로 차단하고, 통신, 정부, SaaS는 낮은 비율로 차단합니다.
설정 복잡도는 웹을 다른 방식으로 가릅니다.
유용한 비교가 가능한 충분한 읽기 가능한 robots.txt 파일이 있는 일부 카테고리에서는 다음과 같습니다.
| 카테고리 | n | 중앙값 바이트 | P90 바이트 | 중앙값 Disallow | P90 Disallow | 중앙값 User-agent | P90 User-agent |
|---|---|---|---|---|---|---|---|
| 이커머스 | 215 | 1,738 | 10,388 | 37 | 164 | 3 | 49 |
| 여행 | 63 | 2,074 | 27,368 | 41 | 779 | 5 | 34 |
| 뉴스 | 647 | 1,534 | 7,039 | 19 | 114 | 6 | 68 |
| 금융 | 121 | 1,002 | 8,337 | 17 | 132 | 2 | 23 |
| 학계 | 253 | 839 | 3,959 | 14 | 75 | 1 | 11 |
| 정부 | 151 | 1,227 | 3,263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12,606 | 4 | 56 | 1 | 10 |
| 개발 도구 | 119 | 273 | 9,255 | 3 | 58 | 1 | 10 |
P90 Disallow by category chart here<<<<<<<<<<<<<<<<<<<<<<<<<
뉴스는 명시적 AI 규칙과 법적 문구를 쓰기 때문에 정치적으로 복잡합니다. 하지만 이커머스와 여행은 대규모 카탈로그, 패싯 내비게이션, 검색 결과 페이지, 필터, 계정 경로, 매개변수화된 URL 때문에 운영적으로 복잡합니다.
이 구분이 중요합니다.
여행은 가장 분명한 예입니다. 이 카테고리 절편에는 읽을 수 있는 파일이 63개뿐이지만 P90 robots.txt는 27.4KB이고, P90 Disallow 개수는 779개로 뉴스보다 훨씬 많습니다. 그렇다고 여행 사이트의 AI 정책이 더 발전했다는 뜻은 아닙니다. 크롤러 운영자가 예산을 낭비하기 쉬운 표면이 더 많다는 뜻입니다. 날짜 검색, 예약 가능성 페이지, 리뷰 페이지네이션, 예약 흐름, 필터 조합, 지역화된 재고 경로가 그렇습니다.
SaaS는 반대 유형의 놀라움입니다. 중앙값 파일은 겨우 485바이트지만 P90 파일은 12.6KB로 뛰어오릅니다. 대부분의 SaaS 사이트는 열려 있고 가볍지만, 일부는 긴 경로 제어 파일을 갖고 있습니다. 문서, 로그인 화면, 앱 라우트, 마케팅 페이지가 같은 도메인 아래에 있기 때문입니다.
뉴스는 운영적으로는 중간쯤이지만 정치적으로는 상위권입니다. 이 표에서 P90 User-agent 개수는 68로, 이커머스, 여행, 금융, 학계, 정부, SaaS, 개발 도구보다 높습니다. 이는 단순한 경로 정리가 아니라 봇별 정책의 신호입니다.
발행자의 robots.txt가 복잡한 이유는 권리 정책일 수 있습니다. 마켓플레이스의 파일이 복잡한 이유는 크롤 예산 관리일 수 있습니다. 대학의 파일이 복잡한 이유는 오래된 경로가 수천 개 누적되었기 때문일 수 있습니다. 소셜 플랫폼의 파일은 일부 표면은 공개하고 다른 것은 억제해야 하기 때문에 복잡할 수 있습니다.
AI 정책은 그 위에 얹힙니다. 기존에 파일이 복잡한 이유를 대체하지 않습니다.
이 점이 AI 시대의 robots.txt 거버넌스가 보편적 차단 목록 하나로 해결될 수 없음을 설명합니다. 기반 파일들은 각자 다른 일을 하고 있습니다.
- 이커머스는 중복 경로와 재고 표면을 관리합니다.
- 여행 사이트는 목록, 달력, 리뷰, 동적 검색 페이지를 관리합니다.
- 뉴스 사이트는 저작권, 아카이브, 라이선스 태도를 관리합니다.
- SaaS와 개발 도구 사이트는 AI 가시성을 원하기도 합니다.
- 정부는 공개 접근이 필요하지만 민감한 시스템은 제외해야 할 수 있습니다.
- 소셜 플랫폼은 사용자 생성 콘텐츠, 프로필 표면, 남용 방지 문제를 관리합니다.
같은 AI 크롤러 규칙도 환경마다 다른 의미를 갖습니다.
발견 6: 설정 부채 지수는 도덕적 실패가 아니라 검토 위험을 식별합니다
이번 분석에서는 검토가 어려울 가능성이 높은 robots.txt 파일을 찾기 위한 간단한 설정 부채 점수를 만들었습니다.
점수는 다음을 가중합니다.
- 파일 크기
User-agent지시문 수Disallow지시문 수Allow지시문 수- 비핵심 지시문 수
- AI 정책 언어의 존재 여부
- 명시적 AI 차단과 법적 또는 저작권 언어의 혼합
이것은 정답성 점수가 아닙니다. 복잡한 파일이 매우 의도적일 수 있습니다. 단순한 파일도 여전히 잘못될 수 있습니다. 목적은 triage입니다. 파일이 크고, 정책 위주이고, 봇별이고, 예외가 많다면 더 강한 검토 규율이 필요합니다.
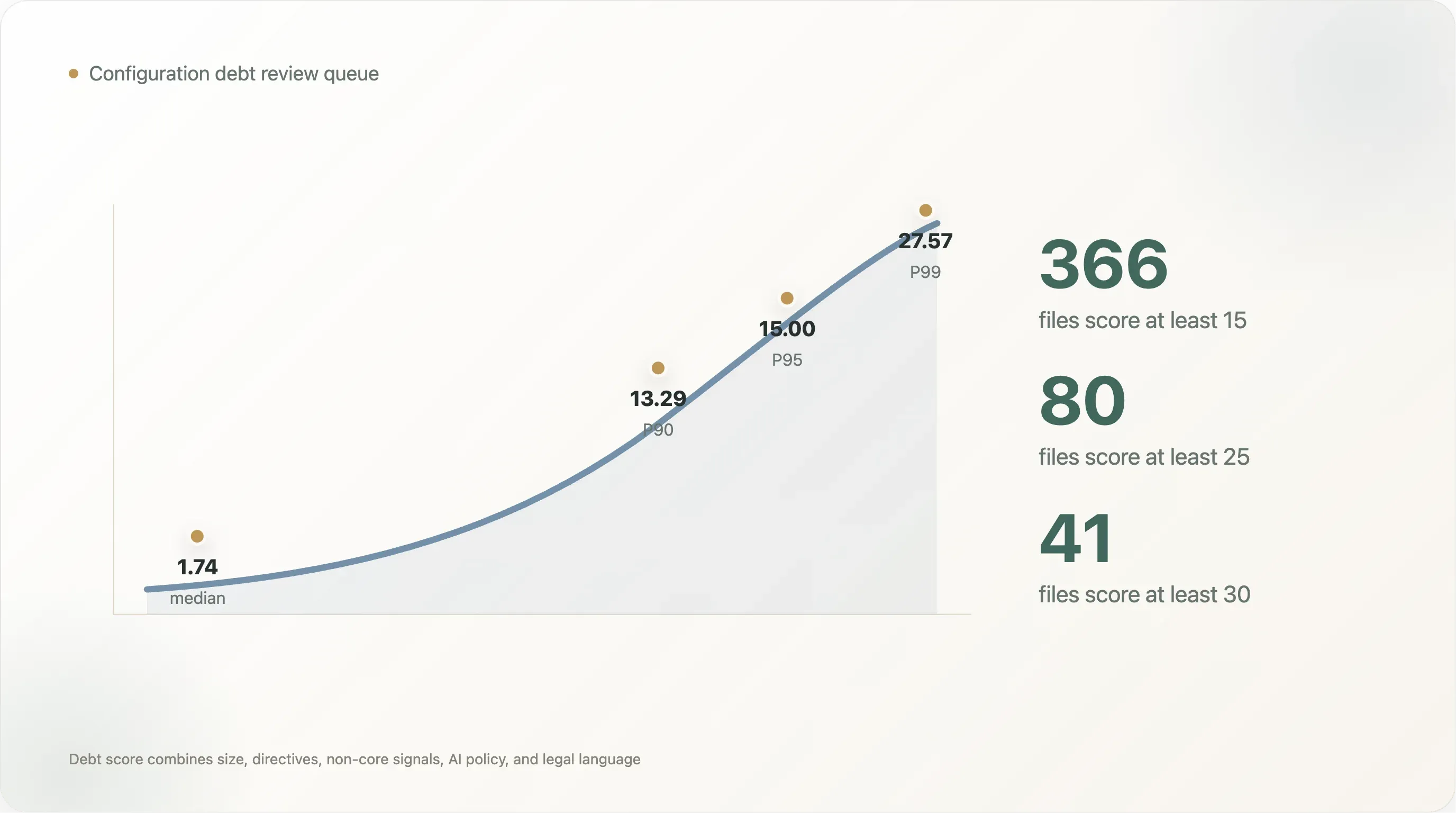
점수 분포는 가파릅니다. 읽을 수 있는 파일의 중앙값 점수는 1.74입니다. P90은 13.29, P95는 15.00, P99는 27.57입니다. 점수가 15 이상인 파일은 366개, 25 이상은 80개, 30 이상은 41개뿐입니다. 이것이 실제 검토 대기열입니다. 모든 사이트가 거버넌스 프로젝트가 필요한 것은 아니지만, 상위 꼬리는 그렇습니다.
카테고리 관점도 단일 "AI 차단기" 라벨이 너무 평면적임을 보여줍니다.
| 카테고리 | 중앙값 점수 | P90 점수 |
|---|---|---|
| 여행 | 4.92 | 28.94 |
| 검색 | 2.97 | 24.23 |
| 소셜 | 2.25 | 15.00 |
| 뉴스 | 4.91 | 14.92 |
| 금융 | 1.67 | 12.61 |
| SaaS | 0.98 | 11.85 |
| 이커머스 | 3.88 | 10.87 |
| 정부 | 1.57 | 6.38 |
여행과 검색은 일부 파일이 매우 크고 규칙이 많아지기 때문에 P90 점수가 가장 높습니다. 뉴스는 정책 언어와 봇별 처리가 카테고리 전반에 더 흔하기 때문에 중앙값 점수가 가장 높은 편입니다. 이커머스는 Disallow 중앙값이 높지만, 복잡성이 혼합 정책/법적 신호보다 경로 규칙에 더 집중되어 있어서 P90 부채 점수는 여행보다 낮습니다.
이 데이터셋에서 점수가 가장 높은 파일에는 다음이 포함됩니다.
| 도메인 | 높은 점수를 받는 이유 |
|---|---|
linkedin.com | 매우 큰 파일, 수천 개의 경로 규칙, 많은 명명된 사용자 에이전트, 명시적 AI 정책 언어 |
lnkd.in | LinkedIn 단축 링크 인프라와 같은 정책 표면 |
fragrantica.com | 수백 개의 명명된 사용자 에이전트 차단과 AI 정책 언어 |
sovcombank.ru | 수백 개의 사용자 에이전트 차단과 법적/정책 언어 |
academia.edu | 큰 allow/disallow 매트릭스와 명시적 AI 차단 정책 |
opentable.com | 큰 경로 규칙 집합, 많은 사이트맵 지시문, AI 관련 정책 표면 |
etsy.com | 1,600개가 넘는 Disallow 규칙을 가진 대형 이커머스 경로 제어 파일 |
runescape.com | 하나의 사용자 에이전트 그룹 아래 거의 5,000개의 Disallow 지시문 |
이 파일들이 복잡하다고 비웃어서는 안 됩니다. 복잡성은 종종 실제 비즈니스 필요를 반영합니다. 하지만 robots.txt 정책도 다른 운영 설정과 같은 엔지니어링 규율이 필요하다는 점을 보여줍니다.
- 소유권은 명시적이어야 합니다.
- 변경 사항은 검토되어야 합니다.
- 생성된 섹션은 라벨이 붙어야 합니다.
- 가능하다면 법적 주석은 기계 지시문과 분리되어야 합니다.
- 핵심 크롤러에 대해 기대되는 봇 접근을 테스트 케이스가 검증해야 합니다.
- 버전 기록은 보존되어야 합니다.
- 오래된 봇 이름은 폐기하거나 문서화해야 합니다.
- AI 학습, AI 검색, 검색 인덱싱, 아카이빙은 서로 다른 목적으로 취급해야 합니다.
마지막 점이 가장 중요합니다. 현재 문법은 사용자 에이전트 우선입니다. 봇 이름을 적으라고 요구합니다. AI 시대에 필요한 것은 목적 우선입니다. 어떤 용도를 허용하는지 말하라고 요구합니다.
이 둘은 같은 것이 아닙니다.
그 불일치 때문에 더 긴 차단 목록은 오래가지 못합니다. 발행자는 오늘 GPTBot, ClaudeBot, CCBot, Google-Extended, Bytespider, Applebot-Extended, PerplexityBot를 추가할 수 있지만, 내일은 다음 크롤러 이름, 검색 보조 에이전트, 데이터셋 중개업자가 나타날 수 있습니다. 목적 기반 정책이라면 robots.txt를 봇 주소록으로 만들지 않고도 "검색 인덱싱은 허용, AI 학습은 금지, 사용자 트리거 검색은 경우에 따라 허용" 같은 표현을 할 수 있습니다.
이것이 AI 거버넌스에 의미하는 것
공개 논쟁은 종종 robots.txt를 의미 있는 것 아니면 구식인 것으로 봅니다. 데이터는 좀 더 실용적인 답을 시사합니다.
robots.txt는 의미가 있지만, 과부하 상태입니다.
의미가 있는 이유는 주요 사이트들이 이를 사용하고, 크롤러가 이를 파싱할 수 있으며, 정책 선택이 연구자, 기자, 벤더, 법원에게 보이기 때문입니다. 원래 리포트는 분석 가능한 상위 사이트의 17.0%가 의도적인 AI 전용 규칙을 가지고 있음을 발견했습니다. 이는 상징적 잡음이 아닙니다.
과부하인 이유는 이제 파일이 봇 접근 그 이상을 표현해야 하기 때문입니다.
- "이 콘텐츠로 학습하지 마세요."
- "이 콘텐츠는 검색 인덱싱에 사용할 수 있습니다."
- "이 콘텐츠는 실시간 검색에 사용할 수 있습니다."
- "캐시된 데이터셋을 만들 수는 없습니다."
- "이 법적 유보는 EU 텍스트 및 데이터 마이닝 법에 따라 적용됩니다."
- "이 CDN 관리 사이트는
Content-Signal: ai-train=no를 보냅니다." - "이 사이트는 Googlebot은 원하지만 YandexBot은 원하지 않습니다."
- "이 사이트에는 크롤링하면 안 되는 1,000개의 오래된 URL 경로가 있습니다."
이 문법은 그만큼 많은 일을 하도록 설계되지 않았습니다.
설정 부채를 줄이려면 세 가지 변화가 필요합니다.
-
크롤러 신원에는 등록부가 필요합니다. 사이트 운영자가
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Applebot-Extended,Bytespider,OAI-SearchBot,ChatGPT-User등 끝없이 늘어나는 목록을 직접 관리해서는 안 됩니다. 등록부가 없으면 정책은 항상 크롤러 동작을 따라가지 못합니다. -
AI 사용에는 구조화된 어휘가 필요합니다. 학습, 검색, 인덱싱, 요약, 데이터셋 재판매, 모델 평가, 사용자 트리거 브라우징은 서로 다른 사용입니다. 이를 벤더별 사용자 에이전트 이름으로 표현하는 것은 취약합니다.
-
정책에는 감사 가능성이 필요합니다. 웹은 권리자가 직접 검토한 권리 유보와, 인프라에서 물려받은 CDN 기본값, 생성된 CMS 템플릿, 오래된 레거시 규칙, 우연한 전면 차단을 구별할 방법이 필요합니다. 이 구별은 신뢰와 소송 모두에 중요합니다.
이 모든 것이 robots.txt를 당장 대체해야 한다는 뜻은 아닙니다. 더 나은 경로는 계층화입니다. robots.txt는 발견과 호환성의 접점으로 유지하되, AI 전용 사용을 위한 인접한 기계 판독 가능한 정책을 표준화하는 것입니다.
llms.txt는 그 시도 중 하나이지만, 이번 데이터셋에서 채택은 여전히 매우 적습니다. 읽을 수 있는 파일 중 83개만 언급합니다. Content-Signal은 Cloudflare가 인프라를 통해 배포할 수 있기 때문에 더 잘 보이며, 이번 스캔에서 Content-Signal이 있는 271개 파일은 모두 AI 정책 언어와도 일치했습니다. 그래도 배포와 합의는 같은 것이 아닙니다. 지속 가능한 해법은 아마도 지루한 표준화 기계가 필요합니다. 명확한 필드, 명확한 의미론, 크롤러의 약속, 공개 테스트 스위트가 그것입니다.
결론
AI 크롤러 논쟁은 robots.txt를 거버넌스 문서로 바꾸어 놓았습니다. 유용하지만 위험한 변화입니다.
유용한 이유는 파일이 공개되어 있기 때문입니다. 연구자는 감사할 수 있고, 발행자는 수정할 수 있고, 크롤러는 존중할 수 있고, 법원은 읽을 수 있으며, 인프라 제공자는 대규모로 배포할 수 있습니다.
위험한 이유는 너무 많은 일을 떠맡고 있기 때문입니다.
Tranco Top 10K의 중앙값 robots.txt는 아직도 이해할 수 있을 만큼 작습니다. 하지만 트래픽이 많은 웹의 긴 꼬리에는 크고, 오래되고, 층층이 쌓였고, 벤더별이며, 법적 무게를 띤 파일들이 가득합니다. 이제 수백 개 사이트가 단순한 크롤러 힌트가 아니라 운영 정책 시스템으로 이해해야 할 robots.txt 구성을 유지합니다.
핵심 교훈은 robots.txt가 실패했다는 것이 아닙니다. 웹이 그것을 리팩터링하지 않은 채 승격시켰다는 것입니다.
AI 접근 정책이 기계가 읽을 수 있는 공개 선언에 의존할 것이라면, 다음 단계는 또 다른 더 긴 차단 목록이 아닙니다. 더 나은 정책 인프라입니다. 목적 기반 허용, 안정적인 크롤러 신원, 검토 가능한 템플릿, 감사 추적이 그것입니다.
그때까지 공개 웹의 AI 거버넌스 층은 이런 무게를 지우도록 만들어지지 않은 텍스트 파일 위에 계속 기대게 될 것입니다.
재현성 노트
전달 폴더에는 다음이 포함됩니다.
source_data/analysis.json— 원본 집계 지표source_data/site_meta.csv— 원본 사이트별 분석 표source_data/bot_status.csv— 원본 도메인별 봇 정책 표source_data/fetch_meta.csv— 원본 가져오기 메타데이터source_data/sites.csv— 원본 도메인/카테고리/상태 표derived_data/robots_complexity_by_site.csv— 이번 리포트용으로 생성한 사이트별 복잡도 지표derived_data/search_bot_treatment.csv— 검색 크롤러 처리 매트릭스derived_data/category_complexity_summary.csv— 카테고리 수준 복잡도 요약derived_data/top_config_debt_sites.csv— 위에서 설명한 triage 점수 기준 상위 사이트derived_data/summary_metrics.json— 이 리포트에서 인용한 모든 핵심 지표
방법론 수정, 데이터셋 문제, 후속 분석 제안은 support@thunderbit.com *으로 보내주세요. 이 리포트는 Thunderbit의 상업적 입장과 무관하게 발행되었으며, 우리는 AI 기반 웹 스크래퍼를 만들고 있고, 공개 웹에서 robots.txt가 의미 있는 기계 판독 가능 계약으로 계속 남아 있기를 구조적으로 원합니다. 이 리포트의 데이터는 그 자체로 독립적입니다. — Thunderbit 연구팀, 2026년 5월.